196
Statistic˘ a Matematic˘ a Note de curs Iulian Stoleriu

Statistica Matematica
Note de curs
Iulian Stoleriu

Copyright © 2019 Iulian Stoleriu

Cuprins
1 Introducere . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.0.1 Scurt istoric . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.0.2 Modelare statistica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.0.3 Populatie statistica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.0.4 Variabile . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131.0.5 Parametrii populatiei . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
1.1 Exercitii rezolvate 161.2 Exercitii propuse 21
2 Elemente de Statistica descriptiva . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.1 Organizarea si descrierea datelor statistice 252.1.1 Gruparea datelor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.2 Reprezentarea datelor statistice 292.2.1 Reprezentare prin puncte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 292.2.2 Reprezentarea stem-and-leaf . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 292.2.3 Reprezentarea cu bare (bar charts) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.2.4 Histograme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 312.2.5 Reprezentare prin sectoare de disc (pie charts) . . . . . . . . . . . . . . . . . . . . . . . . . 332.2.6 Poligonul frecventelor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 332.2.7 Ogive . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 342.2.8 Diagrama Q-Q sau diagrama P-P . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 342.2.9 Diagrama scatter plot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.3 Masuri descriptive ale datelor statistice 342.3.1 Date negrupate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 352.3.2 Date grupate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40

2.4 Transformari de date 41
2.5 Exercitii rezolvate 42
2.6 Exercitii propuse 45
3 Notiuni din Teoria selectiei statistice . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.1 Introducere 493.1.1 Statistici uzuale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.2 Statistici de ordine 55
3.3 Selectii aleatoare dintr-o colectivitate normala 57
3.4 Exercitii rezolvate 66
3.5 Exercitii propuse 71
4 Notiuni din Teoria estimatiei . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
4.1 Estimatori punctuali. Definitii 73
4.2 Informatia Fisher 77
4.3 Metoda verosimilitatii maxime 83
4.4 Metoda momentelor (K. Pearson) 85
4.5 Metoda celor mai mici patrate 86
4.6 Metoda minimului lui χ2 87
4.7 Intervale de încredere 894.7.1 O singura selectie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 894.7.2 Doua selectii . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
4.8 Exercitii rezolvate 100
4.9 Exercitii propuse 113
5 Testarea ipotezelor statistice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
5.1 Intoducere 117
5.2 Tipuri de teste statistice 120
5.3 Etapele unei testari parametrice 121
5.4 Testul cel mai puternic 122
5.5 Teste parametrice 1245.5.1 Testul Z pentru medie (o selectie) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1245.5.2 Testul Z pentru egalitatea mediilor a doua populatii . . . . . . . . . . . . . . . . . . . 1265.5.3 Testul t pentru medie (o selectie) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1285.5.4 Testul t pentru egalitatea mediilor a doua populatii . . . . . . . . . . . . . . . . . . . . 1295.5.5 Testul t pentru date perechi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1325.5.6 Testul χ2 pentru dispersie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1325.5.7 Testul F pentru egalitatea dispersiilor a doua populatii . . . . . . . . . . . . . . . . . . 1335.5.8 Teste pentru proportii într-o populatie binomiala . . . . . . . . . . . . . . . . . . . . . . . . 134

5
5.6 Recapitulare (teste parametrice) 1375.7 Exercitii rezolvate 1395.8 Exercitii propuse 143
6 Teste de concordanta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
6.1 Testul χ2 de concordanta 1476.1.1 Cazul neparametric . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1486.1.2 Cazul parametric . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
6.2 Exercitii rezolvate 1506.3 Exercitii propuse 154
7 Corelatie si regresie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
7.1 Introducere 1577.2 Corelatie si coeficient de corelatie 1587.2.1 Coeficient teoretic de corelatie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1587.2.2 Coeficient empiric de corelatie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1597.2.3 Test statistic pentru coeficientul de corelatie . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
7.3 Coeficientul de corelatie Spearman 1637.4 Regresia 1657.5 Regresie liniara simpla 1677.5.1 Caracteristici ale parametrilor de regresie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1717.5.2 Validarea parametrilor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 174
7.6 Validitatea modelului de regresie liniara simpla 1757.7 Predictie prin regresie 1777.8 Exercitii rezolvate 1797.9 Exercitii propuse 184
8 Anexa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
Bibliografie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193


1. Introducere
1.0.1 Scurt istoricStatistica este o ramura a stiintelor ce se preocupa de procesul de colectare de date si informatii,de organizarea si interpretarea lor, în vederea explicarii unor fenomene reale. În Economiesi Business, informatiile extrase din datele statistice vor fi utile în evaluarea afacerilor sau amediului economic în care activeaza, ajutându-i astfel în luarea deciziilor. În general, prin date(sau date statistice) întelegem o multime de numere sau atribute care au o anumita însemnatatepentru utilizator. Utilizatorul este interesat în a extrage informatii legate de multimea de date pecare o are la îndemâna. Datele statistice pot fi legate între ele sau nu. Studiul acestor date are cascop întelegerea anumitor relatii între diverse trasaturi ce masoara datele culese.De regula, oamenii au anumite intuitii despre realitatea ce ne înconjoara, pe care le doresca fi confirmate într-un mod cât mai exact. De exemplu, daca într-o anumita zona a tarii ratasomajului este ridicata, este de asteptat ca în acea zona calitatea vietii persoanelor de acolo sa nufie la standarde ridicate. Totusi, ne-am dori sa fim cât mai precisi în evaluarea legaturii dintrerata somajului si calitatea vietii, de aceea ne-am dori sa construim un model matematic ce sane confirme intuitia. Un alt gen de interes este urmatorul: ardem de nerabdare sa aflam cineva fi noul presedinte, imediat ce sectiile de votare au închis portile (exit-pole). Chestionareatuturor persoanelor ce au votat, colectarea si unificarea tuturor datelor într-un timp record nueste o masura deloc practica. În ambele probleme mentionate, observatiile si culegerea de dateformeaza primul pas spre întelegerea fenomenului studiat. De cele mai multe ori, realitatea nupoate fi complet descrisa de un astfel de model, dar scopul este de a oferi o aproximare cât maifidela, având totodata costuri relativ mici. Totusi, în urma unei analize statistice pot aparea eroride modelare, erori care tin de caracterul aleator al datelor. De aceea, ne-am dori sa putem descriedatele statistice cu ajutorul variabilelor aleatoare.Plecând de la colectiile de date obtinute dintr-o colectivitate, Statistica introduce metode depredictie si prognoza pentru descrierea si analiza proprietatilor întregii colectivitati. Aria deaplicabilitate a Statisticii este foarte mare: stiinte exacte sau sociale, umanistica, arte sau afacerietc. O disciplina strâns legata de Statistica este Econometria. Aceasta ramura a Economiei sepreocupa de aplicatii ale teoriilor economice, ale Matematicii si Statisticii în estimarea si testarea

8 Capitolul 1. Introducere
unor parametri economici, sau în prezicerea unor fenomene economice.
Statistica a aparut în secolul al XVIII - lea, din nevoile guvernelor de a colecta date desprepopulatiile pe care le reprezentau sau de a studia mersul economiei locale, în vederea unei maibune administrari. Datorita originii sale, Statistica este considerata de unii ca fiind o stiinta desine statatoare, ce utilizeaza aparatul matematic, iar de multe ori nu este privita ca o subramura aMatematicii. Dar nu numai originile sale au fost motivele pentru care Statistica tinde sa devina ostiinta separata de Teoria Probabilitatilor. Datorita revolutiei computerelor, Statistica a evoluatfoarte mult în directia computationala, pe când Teoria Probabilitatilor mai putin. Asa cum DavidWilliams scria în [23], "Teoria Probabilitatilor si Statistica au fost odata casatorite; apoi s-auseparat; în cele din urma au divortat. Acum abia ca se mai întâlnesc".Din punct de vedere etimologic, cuvântului statistica îsi are originile în expresia latina statisticumcollegium (însemnând consiliul statului) si cuvântul italian statista, însemnând om de stat saupolitician. În 1749, germanul Gottfried Achenwall a introdus termenul de Statistik, desemnatpentru a analiza datele referitoare la stat. Mai târziu, în secolul al XIX-lea, Sir John Sinclair aextrapolat termenul la colectii si clasificari de date.Metodele statistice sunt astazi aplicate într-o gama larga de discipline. Amintim aici câteva:
• în Agricultura, de exemplu, pentru a studia care culturi sunt mai potrivite pentru a fifolosite pe un anumit teren arabil;
• în Economie, pentru studiul rentabilitatii unor noi produse introduse pe piata, pentrucorelarea cererii cu oferta, sau pentru a analiza cum se schimba standardele de viata;
• în Contabilitate, pentru realizarea operatiunilor de audit pentru clienti;• în Biologie, pentru clasificarea din punct de vedere stiintific a unor specii de plante sau
pentru selectarea unor noi specii;• în Stiintele educatiei, pentru a gasi cel mai eficient mod de lucru pentru elevi sau pentru a
studia impactul unor teste nationale asupra diverselor categorii de persoane ce lucreaza înînvatamânt;
• în Meteorologie, pentru a prognoza vremea într-un anumit tinut pentru o perioada de timp,sau pentru a studia efectele încalzirii globale;
• în Medicina, pentru testarea unor noi medicamente sau vaccinuri;• în Psihologie, în vederea stabilirii gradului de corelatie între timiditate si singuratate;• în Politologie, pentru a verifica daca un anumit partid politic mai are sprijinul populatiei;• în Stiintele sociale, pentru a studia impactul crizei economice asupra unor anumite clase
sociale;• etc.
Pentru a analiza diverse probleme folosind metode statistice, este nevoie de a identifica mai întâicare este colectivitatea asupra careia se doreste studiul. Aceasta colectivitate (sau populatie)poate fi populatia unei tari, sau numai elevii dintr-o scoala, sau totalitatea produselor agricolecultivate într-un anumit tinut, sau toate bunurile produse într-o uzina etc. Daca se doreste studiulunei trasaturi comune a tuturor membrilor colectivitatii, este de multe ori aproape imposibilde a observa aceasta trasatura la fiecare membru în parte, de aceea este mult mai practic de astrânge date doar despre o submultime a întregii populatii si de a cauta metode eficiente de aextrapola aceste observatii la toata colectivitatea. Exista o ramura a statisticii ce se ocupa cudescrierea acestei colectii de date, numita Statistica descriptiva. Aceasta descriere a trasaturilorunei colectivitati poate fi facuta atât numeric (media, dispersia, mediana, cuantile, tendinte etc),cât si grafic (prin puncte, bare, histograme etc). De asemenea, datele culese pot fi procesateîntr-un anumit fel, încât sa putem trage concluzii foarte precise despre anumite trasaturi aleîntregii colectivitati. Aceasta ramura a Statisticii, care trage concluzii despre caracteristici ale

9
întregii colectivitati, studiind doar o parte din ea, se numeste Statistica inferentiala. În contulStatisticii inferentiale putem trece si urmatoarele: luarea de decizii asupra unor ipoteze statistice,descrierea gradului de corelare între diverse tipuri de date, estimarea caracteristicilor numericeale unor trasaturi comune întregii colectivitati, descrierea legaturii între diverse caracteristici etc.
Statistica Matematica este o ramura a Matematicii ce se preocupa de baza teoretica abstracta aStatisticii. Din datele culese pe cale experimentala, Statistica Matematica va cauta sa extragainformatii si sa le interpreteze. Un cercetator într-un domeniul teoretic al Statisticii, cum este siStatistica Matematica, va cauta sa îmbunatateasca metodele teoretice existente sau sa introducaaltele noi. Aceasta va utiliza notiuni din Teoria probabilitatilor, dar si notiuni din alte ramuri aleMatematicii, cum ar fi: Algebra liniara, Analiza matematica, Teoria optimizarii. De asemenea,partea computationala este deosebit de utila în studiul Statisticii moderne, fara de care cercetareaar fi îngreunata sau, uneori, chiar imposibil de realizat.
1.0.2 Modelare statisticaDe obicei, punctul de plecare este o problema din viata reala, e.g., care partid are o sustinere maibuna din partea populatiei unei tari, daca un anumit medicament este relevant pentru boala pentrucare a fost creat, daca este vreo corelatie între numarul de ore de lumina pe zi si depresie. Apoi,trebuie sa decidem de ce tipuri date avem nevoie sa colectam, pentru a putea da un raspuns laîntrebarea ridicata si cum le putem colecta. Modurile de colectare a datele pot fi diverse: putemface un sondaj de opinie, sau prin experiment, sau prin simpla observare a caracteristicilor. Estenevoie de o metoda bine stabilita de colectare a datelor si sa construim un model statistic potrivitpentru analiza acestora. În general, datele (observatiile) culese pot fi potrivite într-un modelstatistic prin care
Data observata = f (x, θ)+ eroare de aproximare, (1.0.1)
unde f este o functie ce verifica anumite proprietati si este caracteristica modelului, x estevectorul ce contine variabilele masurate si θ e un parametru (sau un vector de parametri), carepoate fi determinat sau nedeterminat. Termenul de eroare apare deseori în pratica, deoareceunele date culese au caracter stochastic (nu sunt deterministe). Modelul astfel creat este testat, sieventual revizuit, astfel încât sa se potriveasca într-o masura cât mai precisa datelor culese.
1.0.3 Populatie statisticaO populatie (colectivitate) statistica este o multime de elemente ce poseda o trasatura comuna ceurmeaza a fi studiata. Aceasta poate fi finita sau infinita, reala sau imaginara. In acest materialvom nota populatia statistica cu Ω. Din punct de vedere matematic, Ω este o multime nevida.Elementele ce constituie o colectivitate statistica se vor numi unitati statistice sau indivizi. Vomnota cu ω o unitate statistica. Daca populatia este finita, atunci numarul N al unitatilor statisticece o compun (i.e., |Ω|) îl vom numi volumul colectivitatii (sau volumul populatiei).Caracteristica (variabila) unei populatii statistice este o anumita proprietate urmarita la indiviziiei în procesul prelucrarii statistice si care constituie obiectul masurarii. Spre exemplu, inaltimeabarbatilor dintr-o anumita tara, rata infiltrarii apei in solul urban, media la Bacalaureat, altitudinea,culoarea frunzelor, nationalitatea participantilor la un congres international etc. Din punct devedere matematic, caracteristica este reprezentata printr-o variabila aleatoare definita pe Ω.Spre exemplu, daca populatia statistica este multimea tuturor studentilor dintr-o universitateînrolati în anul întâi de master, atunci o caracteristica a sa ar fi media la licenta obtinuta de fiecare

10 Capitolul 1. Introducere
dintre acesti studenti. Teoretic, multimea valorilor acestei caracteristici este intervalul [6, 10], iaraceasta variabila poate lua orice valoare din acest interval.Caracteristicile pot fi: cantitative (sau masurabile sau numerice) (e.g., 2, 3, 5.75, 1/3, . . . ) saucalitative (categoriale sau atribute) (e.g., albastru, foarte bine, german etc). La rândul lor,variabilele cantitative pot fi discrete (numarul de sosiri ale unui tramvai în statie) sau continue(timpul de asteptare între doua sosiri ale tramvaiului în statie). Caracteristicile pot depinde deunul sau mai multi parametri, parametrii fiind astfel proprietati numerice ale colectivitatii.Vom numi date (sau date statistice) informatiile obtinute în urma observatiei valorilor uneicaracteristici a unei populatii statistice. Exista mai multe tipuri de date statistice, în functie detipul caracteristicii asupra careia s-au facut observatii. Amintim aici doar câteva:
• calitative (se mai numesc si categoriale) sau cantitative, dupa cum caracteristica (sauvariabila) observata este calitativa (exprima o calitate sau o categorie) sau, respectiv,cantitativa (are o valoare numerica).
• date de tip discret, daca sunt obtinute în urma observarii unei caracteristici discrete (ovariabila aleatoare discreta, sau o variabila ale carei posibile valori sunt in numar finitsau cel mult numarabil), sau date continue, daca aceasta caracteristica este continua (ovariabila aleatoare de tip continuu, sau o variabila ce poate lua orice valoare dintr-uninterval sau chiar de pe axa reala). În cazul în care variabila studiata este media de lalicenta, atunci datele rezultate vor fi cantitative si continue.
• nominale sau ordinale (valabil doar pentru date calitative). Datele nominale au niveledistincte (categorii), fara a considera o anumita ordine între ele. De exemplu, culoareaparului sau genul unei persoane. Pe de alta parte, datele ordinale fac referire la o anumitaordine. De cele mai multe ori, aceasta grupare si ordonare în categorii este naturala,desi de multe ori nu se cunosc distantele între categorii. De exemplu: schimbarea stariiunui pacient dupa un anumit tratament (aceasta poate fi: îmbunatatire semnificativa,îmbunatatire moderata, nicio schimbare, înrautatire moderata, înrautatire semnificativa).Exista situatii când datele calitative (sau categoriale) pot fi exprimate numeric. Se potatribui coduri numerice unor date calitative, ce permit prelucrarea lor cu ajutorul metodelorstatistice. De exemplu, atribuirea numerica a calificativelor oferite de catre studentiprofesorilor, de la dezacord total (1), pâna la acord total (5).
• univariate, bivariate sau multivariate, atunci când datele statistice sunt observatii asupraunei variabile, a doua variabile sau a mai multor variabile, respectiv.
• temporale sau spatiale, dupa cum variabila studiata este dependenta de timp (se obtinastfel serii de timpi) sau de spatiu (e.g., aciditatea solului în diverse locatii dintr-un areal).
În Statistica, se obisnuieste a se nota variabilele (caracteristicile) cu litere mari, X , Y, Z, . . ., sivalorile lor cu litere mici, x, y, z, . . ..In general, volumul colectivitatii poate fi foarte mare sau chiar infinit, astfel ca efectuareaunui recensamânt (i.e., observarea caracteristicii de interes pentru toate elementele ce compuncolectivitatea) este fie foarte costisitoare sau imposibila. Pentru a efectua o analiza a caracteristiciide interes sau chiar a repartitiei datelor observate, este suficienta analiza unei selectii de volumsuficient de mare, formata din observatii ale caracteristicii, urmand ca aceasta analiza sa fieextrapolata (folosind metode statistice specifice) pentru întreaga populatie.O selectie (sau esantion) este o colectivitate partiala de elemente extrase (la întâmplare sau nu)din colectivitatea generala, în scopul cercetarii lor din punctul de vedere al unei caracteristici.Daca extragerea se face la întâmplare, atunci spunem ca am facut o selectie aleatoare. Numarulindivizilor din selectia aleasa se va numi volumul selectiei. Daca se face o enumerare sau olistare a fiecarui element component al unei populatii statistice, atunci spunem ca am facut un

11
recensamânt. Selectia ar trebui sa fie reprezentativa pentru populatia din care face parte. Numimo selectie repetata (sau cu repetitie) o selectie în urma careia individul ales a fost reintrodus dinnou în colectivitate. Altfel, avem o selectie nerepetata. Selectia nerepetata nu prezinta interesdaca volumul colectivitatii este finit, deoarece în acest caz probabilitatea ca un alt individ safie ales într-o extragere nu este aceeasi pentru toti indivizii colectivitatii. Pe de alta parte, dacavolumul întregii populatii statistice este mult mai mare decât cel al esantionului extras, atunciputem presupune ca selectia efectuata este repetata, chiar daca în mod practic ea este nerepetata.Spre exemplu, daca dorim sa facem o prognoza pentru a vedea cine va fi noul presedinte înurma alegerilor din toamna, esantionul ales (de altfel, unul foarte mic comparativ cu volumulpopulatiei cu drept de vot) se face, în general, fara repetitie, dar îl putem considera a fi o selectierepetata, în vederea aplicarii testelor statistice.Selectiile aleatoare se pot realiza prin diverse metode, în functie de urmatorii factori: disponibili-tatea informatiilor necesare, costul operatiunii, nivelul de precizie al informatiilor etc. Mai josprezentam câteva metode de selectie.
• selectie simpla de un volum dat, prin care toti indivizii ce compun populatia au aceeasisansa de a fi alesi. Aceasta metoda mininimizeaza riscul de a fi partinitor sau favorabilunuia dintre indivizi. Totusi, aceasta metoda are neajunsul ca, în anumite cazuri, nu reflectacomponenta întregii populatii. Se aplica doar pentru colectivitati omogene din punctul devedere al trasaturii studiate.
• selectie sistematica, ce presupune aranjarea populatiei studiate dupa o anumita schemaordonata si selectând apoi elementele la intervale regulate. (e.g., alegerea a fiecarui al10-lea numar dintr-o carte de telefon, primul numar fiind ales la întâmplare (simplu) dintreprimele 10 din lista).
• selectie stratificata, în care populatia este separata în categorii, iar alegerea se face laîntâmplare din fiecare categorie. Acest tip de selectie face ca fiecare grup ce compunepopulatia sa poata fi reprezentat în selectie. Alegerea poate fi facuta si în functie demarimea fiecarui grup ce compune colectivitatea totala (e.g., aleg din fiecare judet unanumit numar de persoane, proportional cu numarul de persoane din fiecare judet).
• selectie ciorchine, care este un esantion stratificat construit prin selectarea de indivizi dinanumite straturi (nu din toate).
• selectia de tip experienta, care tine cont de elementul temporal în selectie. (e.g., diversitimpi de pe o encefalograma).
• selectie de convenienta: e.g., alegem dintre persoanele care trec prin fata universitatii.• selectie de judecata: cine face selectia decide cine ramâne sau nu în selectie.• selectie de cota: selectia ar trebui sa fie o copie a întregii populatii, dar la o scara mult
mai mica. Asadar, putem selecta proportional cu numarul persoanelor din fiecare rasa,de fiecare gen, origine etnica etc) (e.g., persoanele din Parlament ar trebui sa fie o copiereprezentativa a persoanelor întregii tari, într-o scara mult mai mica).
Parametrii sunt masuri descriptive numerice ce reprezinta populatia. Deoarece nu avem accesla intreaga populatie, parametrii sunt niste constante necunoscute, ce urmeaza a fi explicatesau estimate pe baza datelor. Spre exemplu, pentru variabilele cantitative ale populatiei, putemavea: parametri care sa descrie tendinta centrala a populatiei (e.g., media, mediana, momente),parametri care sa descrie dispersia datelor (e.g., dispersia, deviatia standard, coeficient de varia-tie), parametri de pozitie (e.g., cuantile), parametri ce descriu forma (e.g., skewness, kurtosis).Pentru date bidimensionale, datele pot fi descrise de parametrii ce descriu legatura intre variabile:corelatia sau coeficientul de corelatie. Pentru date calitative (categoriale), cei mai des utilizatiparametri sunt: π− proportia din populatie ce are caracteristica de interes (e.g., numarul de

12 Capitolul 1. Introducere
fumatori din tara), cote (sanse teoretica pentru observarea caracteristicii de interes la intreagapopulatie) (e.g., exista 70% sanse sa ploua maine).Pe baza unei selectii, putem construi diversi indicatori statistici care sa estimeze parametriinecunoscuti, obtinand descrieri numerice pentru populatie. Astfel de indicatori se numescstatistici. Prin intermediul statisticilor putem trage concluzii despre populatia din care a provenitesantionul observat. Teoria probabilitatilor ofera procedee de determinare a repartitiei asimptoticea unei statistici, sau chiar, in anumite cazuri, a statisticii exacte. Repartitia exacta este acearepartitie ce poate fi determinata pentru orice volum al selectiei. În general, daca se lucreazacu selectii de volum redus (n < 30), atunci repartitia exacta ar trebui sa fie cunoscuta a priori,daca se doreste luarea de decizii prin inferenta. Repartitia asimptotica este repartitia limita astatisticii când n→ ∞, iar utilizarea acesteia conduce la rezultate bune doar pentru n≥ 30.In concluzie, plecand de la o multime de date, Statistica isi propune sa extraga informatii dinacestea. Mai concret, detine metodele necesare de a realiza urmatoarele cerinte: sa descriecat mai fidel si sugestiv acele date (prin grafice sau indicatori statistici), sa estimeze anumitiparametri de interes (e.g., media teoretica, deviatia standard, asimetria ale caracteristicii), saverifice prin inferenta ipotezele ce se pot face referitoare la anumiti parametri ai caracteristiciisau chiar la forma acesteia.
Baza de comparatie Populatie (colectivitate) Esantion (selectie)colectia tuturor elementelor care un subgrup al membrilor
ce este? poseda caracteristici comune, populatiei, alesi pentruce sunt de interes în studiu a participa la studiu
ce include? fiecare membru (unitate) doar o submultimedin grup din membrii grupului
caracteristica parametru statisticacolectarea datelor recensamânt selectie sau sondaj
interes în descrierea caracteristicilor luarea de decizii în cesi a parametrilor priveste populatia (inferenta)
Tabela 1.1: Populatie vs. Esantion

13
1.0.4 Variabile
În general, rezultatul posibil al unui experiment aleator poate fi asociat unei valori numerice sauunui atribut, precizând regula de asociere. O astfel de regula de asociere se numeste variabilaaleatoare (prescurtat, v.a.). Se numeste ”variabila” deoarece poate lua valori diferite, se numeste”aleatoare” deoarece valorile observate depind de rezultatele experimentului aleator. Dacavaloarea numerica este un numar real, atunci variabila aleatoare va fi ”reala”. Asadar, din punctde vedere euristic, o variabila aleatoare este o cantitate ce poate avea orice valoare dintr-omultime data, fiecarei valori atribuindu-se o anumita pondere (frecventa relativa). În viata de zicu zi întâlnim numeroase astfel de functii, e.g., numerele ce apar la extragerea loto, rezultatulmasurarii fertilitatii solului in diverse locatii, numarul clientilor deserviti la un anumit ghiseuîntr-o anumita perioada, timpul de asteptare a unei persoane într-o statie de autobuz pâna lasosirea acestuia, calificativele obtinute de elevii de clasa a IV-a la un test de matematica etc. Deregula, variabilele aleatoare sunt notate cu litere de la sfârsitul alfabetului, X , Y, Z sau ξ ,η , ζ
etc.Variabilele aleatoare (prescurtat v.a.) pot fi discrete sau continue. Variabilele aleatoare discretesunt cele care pot lua o multime finita sau cel mult numarabila (adica, o multime care poate finumarata) de valori. O variabila aleatoare se numeste variabila aleatoare continua (sau de tipcontinuu) daca multimea tuturor valorilor sale este totalitatea numerelor dintr-un interval real(posibil infinit) sau toate numerele dintr-o reuniune disjuncta de astfel de intervale, cu precizareaca pentru orice posibila valoare c, P(X = c) = 0.Pentru a specifica o v.a. discreta, va trebui sa enumeram toate valorile posibile pe care aceastale poate lua, împreuna cu probabilitatile corespunzatoare. Suma tuturor acestor probabilitativa fi întotdeauna egala cu 1, care este probabilitatea realizarii evenimentului sigur. Când seface referire la repartitia unei v.a. discrete, se întelege modul în care probabilitatea totala 1 estedistribuita între toate posibilele valori ale variabilei aleatoare.O variabila aleatoare continua poate lua orice valoare intr-un interval, sau chiar din R. Deoarecein aceste multimi exista o infinitate de valori, nu mai putem defini o variabila aleatoare continuala fel ca in cazul discret, precizandu-i fiecare valoare pe care o ia si ponderea corespunzatoare. Inschimb, pentru o variabila aleatoare continua, putem preciza multimea in care aceasta ia valori sio functie care sa descrie repartizarea acestor valori. O astfel de functie se numeste functie dedensitate a repartitiei, sau simplu, densitate de repartitie (en., probability density function).O repartitie poate depinde de unul sau mai multi parametri reali. Spre exemplu, repartitia normalaare doi parametri, µ si σ .
1.0.5 Parametrii populatiei
O colectivitate statistica poate fi descrisa folosind una sau mai multe variabile. Pentru fiecaredintre aceste variabile se pot determina anumite cantitati sau calitati specifice, numite parametri.Astfel, acesti parametri sunt niste trasaturi caracteristice colectivitatii, ce pot fi determinate sauestimate pe baza unor masuratori (observatii) ale variabilelor. In continuare vom prezenta cativaparametri numerici importanti pentru o variabila aleatoare, folositi in analiza statistica. Vomdenumi acesti parametri caracteristici numerice ale unei variabile aleatoare.
• media (sau valoarea asteptata). Pentru o variabila, media este o masura a tendinteicentrale a valorilor sale. De remarcat faptul ca exista variabile (atat discrete cat si continue)care nu admit o valoare medie. Pentru o variabila X , vom nota media sa teoretica prinµ = EX . Daca X admite medie, atunci se defineste prin:

14 Capitolul 1. Introducere
µ = ∑i∈I
xi pi
(in cazul unei v.a. discrete)
µ =∫
∞
−∞
x f (x)dx
(in cazul unei v.a. continue)
În cazul în care poate fi pericol de confuzie (spre exemplu, atunci când lucram cu maimulte variabile în acelasi timp), vom folosi notatia µX . Pentru media teoretica a uneivariabile aleatoare se mai folosesc si notatiile: m, M(X) sau E(X).
• dispersia (sau varianta). Dispersia variabilei (sau varianta) este o masura a împrastieriivalorile aceste variabile sunt in jurul valorii medii. Dispersia va fi notata prin σ2 sauVar(X). Este definita prin Var(X) = E[(X−µ)2] = E(X2)− [EX ]2. În cazul în care poatefi pericol de confuzie (spre exemplu, atunci când lucram cu mai multe variabile în acelasitimp), vom folosi notatia σ2
X .
σ2 = ∑
i∈I(xi−µ)2 pi
(in cazul unei v.a. discrete).
σ2 =
∫∞
−∞
(x−µ)2 f (x)dz
(in cazul unei v.a. continue).
• abaterea standard (sau deviatia standard). Se defineste prin σ =√
σ2. Are avantajul caunitatea sa de masura este aceeasi cu a variabilei X .
• coeficientul de variatie. Este definit prin CV = σ
µsau, scris sub forma de procente,
CV = 100σ
µ%. Este util in compararea variatiilor a doua sau mai multe seturi de date ce
tin de aceeasi variabila. Daca variatiile sunt egale, atunci vom spune ca setul de observatiice are media mai mica este mai variabil decat cel cu media mai mare.
• momente centrate. Pentru o v.a. X (discreta sau continua), ce admite medie, momentelecentrate sunt valorile asteptate ale puterilor lui X−µ . Definim astfel µk(X) =E((X−µ)k).In particular,
µk(X) = ∑i∈I
(xi−µ)k pi;
(in cazul unei v.a. discrete).
µk(X) =∫
∞
−∞
(x−µ)k f (x)dx;
(in cazul unei v.a. continue).
Momente speciale:– µ2(X) = σ2. Se observa ca al doilea moment centrat este chiar dispersia.
– γ1 =µ3(X)
σ3 este coeficientul de asimetrie (en., skewness);Coeficientul γ1 este al treilea moment centrat standardizat. O repartitie este simetricadaca γ1 = 0. Vom spune ca asimetria este pozitiva (sau la dreapta) daca γ1 > 0 sinegativa (sau la stânga) daca γ1 < 0.
– K =µ4(X)
σ4 −3 este excesul (coeficientul de aplatizare sau boltire) (en., kurtosis).
Este o masura a boltirii distributiei (al patrulea moment standardizat). Termenul (−3)apare pentru ca indicele kurtosis al distributiei normale sa fie egal cu 0. Vom aveao repartitie mezocurtica pentru K = 0, leptocurtica pentru K > 0 sau platocurticapentru K < 0. Un indice K > 0 semnifica faptul ca, în vecinatatea modului, curbadensitatii de repartitie are o boltire (ascutire) mai mare decât clopotul lui Gauss.Pentru K < 0, în acea vecinatate curba densitatii de repartitie este mai plata decâtcurba lui Gauss.
• cuantile. Consideram X o variabila aleatoare cu functia de repartitie F(x) = P(X ≤ x).

15
Pentru α ∈ (0, 1), definim cuantila de ordin α ca fiind valoarea xα ∈ R astfel încât:
xα = infx ∈ R; F(x)≥ α.
În particular, daca X este o variabila aleatoare de tip continuu, atunci cuantila de ordin α
este valoarea reala xα ∈ R pentru care
F(xα) = α.
Cuantile speciale:– pentru α = 1/2, obtinem mediana. Mediana (notata Me) este valoarea care imparte
repartitia in doua parti in care variabila X ia valori cu probabilitati egale. Daca X estede tip continuu, atunci:
P(X ≤Me) = P(X > Me) = 0.5.
Pentru o variabila care nu este simetrica, mediana este un indicator mai bun decatmedia pentru tendinta centrala a valorilor variabilei.
– pentru α = i/4, i ∈ 1, 2, 3, obtinem cuartilele. Prima cuartila, Q1, este aceavaloare pentru care probabilitatea ca X sa ia o valoare la stanga ei este 0.25. DacaX este de tip continuu, scriem asta astfel: P(X ≤ Q1) = 0.25. Cuartila a douaeste chiar mediana, deci Q2 = Me. Cuartila a treia, Q3, este acea valoare pentrucare probabilitatea ca X sa ia o valoare la stanga ei este 0.75. Scriem asta astfel:P(X ≤ Q3) = 0.75.
– pentru α = j/10, j ∈ 1, 2, . . . , 9, obtinem decilele. Prima decila este acea valoarepentru care probabilitatea ca X sa ia o valoare la stanga ei este 0.1. S.a.m.d.
– pentru α = j/100, j ∈ 1, 2, . . . , 99, obtinem centilele. Prima centila este aceavaloare pentru care probabilitatea ca X sa ia o valoare la stanga ei este 0.01. S.a.m.d.
Daca X ∼N (0, 1), atunci cuantilele de ordin α le vom nota prin zα .• modul. (valoarea cea mai probabila) Este valoarea cea mai probabila pe care o lua
variabila aleatoare X . Cu alte cuvinte, este acea valoare x∗ pentru care f (x∗) (densitatea derepartitie sau functia de probabilitate) este maxima. O repartitie poate sa nu aiba niciunmod, sau poate avea mai multe module.
• covarianta. Conceptul de covarianta este legat de modul în care doua variabile aleatoaretind sa se modifice una fata de cealalta; ele se pot modifica fie în aceeasi directie (caz încare vom spune ca X1 si X2 sunt direct <sau pozitiv> corelate) sau în directii opuse (X1 siX2 sunt invers <sau negativ> corelate).Daca variabilele X1, X2 admit medii, respectiv, µ1, µ2, atunci covarianta variabilelor X1 siX2, notata prin cov(X1, X2), este definita prin
cov(X1, X2) = E[(X1−µ1)(X2−µ2)].
• Coeficientul de corelatie este tot o masura a legaturii dintre doua variabile. Acesta estefoarte utilizat în stiinte ca fiind o masura a dependentei liniare între doua variabile. Senumeste coeficient de corelatie al variabilelor aleatoare X1 si X2 cantitatea
ρX1,X2 =cov(X1, X2)
σ1σ2,
unde σ1 si σ2 sunt deviatiile standard pentru X1, respectiv, X2.

16 Capitolul 1. Introducere
1.1 Exercitii rezolvateExercitiu 1.1.1 Cineva a înregistrat zilnic timpul între doua sosiri succesive ale tramvaiuluiîntr-o anumita statie si a gasit ca, în medie, acesta este de 20 de minute. Se stie ca acest timp estedistribuit exponential. Daca o persoana a ajuns în statie exact când tramvaiul pleca, aflati caresunt sansele ca ea sa astepte cel putin 15 minute pâna vine urmatorul tramvai.R: Notam cu T timpul de asteptare în statie între doua sosiri succesive ale tramvaiului si cu FTfunctia sa de repartitie. Stim ca T ∼ exp(λ ), unde λ = 20. Asadar, avem de calculat P(T ≥ 15),care este:
P(T ≥ 15) = 1−P(T < 15) = 1−FT (15) =∫
∞
015e−15x dx≈ 0.4724,
ceea ce implica 47.24% sanse.
Exercitiu 1.1.2 Sa presupunem ca X este o variabila aleatoare continua ce reprezinta înaltimea(în cm) barbatilor dintr-o tara. Se stie ca P(X ≤ 170) = 0.1. Stiind ca X este normal distribuita,cu media m = 175, sa se determine dispersia lui X .R: Consider variabila aleatoare standardizata Z = X−175
σ∼N (0, 1). Atunci,
0.1 = P(X ≤ 170) = P(
X−175σ
≤ 170−175σ
)= P
(Z ≤− 5
σ
),
de unde − 5σ
este cuantila de ordin 0.1 pentru Z ∼N (0, 1). Aceasta este z0.1 =−1.28, de undeσ = 3.9.Exercitiu 1.1.3 Daca U este o variabila aleatoare repartizata U (0, 1), determinati repartitiavariabilei aleatoare Y =−λ ln(U), λ > 0.R: Densitatea de repartitie a lui U este
fU(x) =
1, daca x ∈ (0, 1)0, daca x 6∈(0, 1).
Functia de repartitie a lui Y este
FY (y) = P(Y ≤ y) = P(−λ ln(U)≤ y) =
=
P(ln(U)≥− y
λ
), daca y > 0,
0, daca y≤ 0=
1−P
(U < e−
yλ
), daca y > 0,
0, daca y≤ 0
=
1−FU
(e−
yλ
), daca y > 0,
0, daca y≤ 0.
Atunci, densitatea de repartitie a lui Y este
fY (y)=F ′Y (y)=
fU(
e−yλ
) 1λ
e−yλ , daca y > 0,
0, daca y≤ 0.=
1λ
e−yλ , daca y > 0,
0, daca y≤ 0.Se observa ca Y ∼ exp(λ ).

1.1 Exercitii rezolvate 17
Exercitiu 1.1.4 (a) În magazinul de la coltul strazii intra în medie 20 de clienti pe ora. Stiind canumarul clientilor pe ora este o variabila aleatoare repartizata Poisson, sa se determine care esteprobabilitatea ca într-o anumita ora sa intre în magazin cel putin 15 clienti?(b) Care este probabilitatea ca, într-o anumita zi de lucru (de 10 ore), în magazin sa intre celputin 200 de clienti?
R: (a) Probabilitatea este
P1 = P(X ≥ 15) = 1−P(X < 15) = 1−P(X ≤ 14) = 1−FX(14) = 0.8951.
(b) P2 =P(10
∑k=1
Xk≥ 200) = 1−P(10
∑k=1
Xk < 200) = 1−P(10
∑k=1
Xk≤ 199) = 1−FY (199) = 0.5094.
Unde Y =10
∑k=1
Xk ∼P(200), deoarece avem o suma de v.a. independente, identic repartizate
Poisson.
Exercitiu 1.1.5 Daca X ∼N (0, 1), determinati densitatea de repartitie a variabilei aleatoareX2. (repartitia obtinuta este χ2(1)).R: Functia densitate de repartitie pentru X este data de
fX(x) =1√2π
e−x22 , x ∈ R.
Notam cu FX2(y) functia de repartitie pentru X2 si cu fX2(y) densitatea sa de repartitie. Nu putemfolosi formula de la curs deoarece functia g(x) = x2, x ∈ R, nu este bijectiva. Pentru a calculadensitatea lui X2, putem proceda astfel:
FX2(y) = P(X2 ≤ y) =
0 , y≤ 0;P(−√y≤ X ≤√y) , y > 0,
de unde
fX2(y) = F ′X2(y) =
0 , y≤ 0;1
2√
y[ fX(√
y)+ fX(−√
y)] , y > 0,
=
0 , y≤ 0;1√y
fX(√
y) , y > 0.
=
0 , y≤ 0;1√2πy
e−y2 dy , y > 0.
Exercitiu 1.1.6 Aratati ca daca X1, X2, . . . , Xn sunt variabile aleatoare independente, identic
repartizate N (µ, σ), atunci variabila aleatoare H =1
σ2
n
∑i=1
(Xi−µ)2 urmeaza repartitia χ2(n).
R: Daca Xi ∼N (µ, σ), atunci Yi =Xi−µ
σ∼N (0, 1). Deoarece Xin
i=1 sunt independente,
atunci si Y 2i n
i=1 sunt independente. Daca X ∼N (0, 1), atunci X2 are densitatea de repartitie
fX2(x) =
1√2πx
e−x2 dx , x > 0.
0 , x≤ 0.

18 Capitolul 1. Introducere
Functia generatoare de momente pentru Y = X2 este
MY (t)=E(etY )=∫
∞
0ety 1√
2πye−
y2 dy=
√2π(1−2t)−1/2
∫∞
0e−
u22 du=(1−2t)−1/2, t < 1/2.
Folosind independenta variabilelor Y 2i n
i=1, obtinem ca functia generatoare de momente a lui Heste
MH(t) =n
∏i=1
(1−2t)−1/2 = (1−2t)−n/2, t < 1/2,
care este functia generatoare de momente pentru o variabila aleatoare χ2(n).Exercitiu 1.1.7 Daca X si Y sunt variabile aleatoare independente si identic repartizate N (0, 1),(a) determinati repartitia variabilei aleatoare Z = X/Y ,(b) calculati probabilitatea P(X > Y ),(c) calculati probabilitatea P(X > 0|Y < 1).R: (a) Densitatile de repartitie pentru X si Y sunt
fX(x) =1√2π
e−x2/2, x ∈ R, fY (y) =1√2π
e−y2/2, y ∈ R.
Deoarece sunt independente, densitatea de repartitie a vectorului (X , Y ) este:
fX ,Y (x) =1
2πe−(x
2+y2)/2, (x, y) ∈ R×R.
Pentru a determina repartitia ceruta, folosim transformarea u = x/y, v = y, care transforma (X , Y )în (U,V ) = (X/Y, Y ). Transformarea inversa x = uv, y = v. Jacobianul transformarii inverseeste J = v. Folosind formula de schimbare de variabile, obtinem:
fU,V (u, v) = fX ,Y (uv, v)|v|= 12π
e−v2(u2+1)/2|v|, (u, v) ∈ R×R.
Densitatea de repartitie marginala a primei componente se obtine integrând în raport cu a douavariabila. Obtinem:
fX/Y (u) = fU(u) =∫
∞
−∞
fU,V (u, v)dv =∫
∞
−∞
12π
e−v2(u2+1)/2|v|dv =1
π(u2 +1), u ∈ R.
(b) Deoarece X si Y sunt independente,
P(X > Y ) = P(Y > X) =12.
(c) Deoarece X si Y sunt independente,
P(X > 0|Y < 1) = P(X > 0) =∫
∞
0fX(x)dx =
1√2π
∫∞
0e−x2/2 dx =
12.
Exercitiu 1.1.8 Timpul de deservire la un anumit ghiseu dintr-o banca este o variabila aleatoarerepartizata exponential, cu media de 2 minute. Stiind ca în fata mai sunt înca 36 persoane ceasteapta sa fie servite (prima persoana la rând abia a fost chemata) si ca timpii de servire suntindependenti, sa se calculeze probabilitatea de a astepta mai mult de o ora la rând.

1.1 Exercitii rezolvate 19
R: Notam cu Ti timpul de deservire pentru persoana din rând de pe pozitia i (i = 1, 36). Atunci
Ti sunt variabile aleatoare independente si identic repartizate exp(2). Notam cu S36 =36
∑i=1
Ti.
Probabilitatea cautata este
P(S36 > 60) = 1−P(S36 ≤ 60) = 1−FS36(60).
Pentru o variabila aleatoare exponentiala exp(2), media este µ = 2 si deviatia standard esteσ = 2. Deoarece n = 36 > 30, aplicând teorema limita centrala, putem concluziona ca Sn ∼N (nµ, σ
√n). Asadar, S36 ∼N (72, 12). Probabilitatea dorita va fi:
P(S36 > 60) = 1−P(S36 ≤ 60) = 1−P(
S36−7212
≤ 60−7212
)= 1−Θ(−1) = 0.8413.
Observatie 1.1.1 Putem chiar determina si repartitia exacta a variabilei aleatoare S36.Suma a n variabile aleatoare independente identic repartizate exp(λ ) este o variabila Γ(n,λ ).În cazul de fata, vom avea: S36 ∼ Γ(36,2). Asadar, probabilitatea cautata este (exact) 1−FS36(60), care poate fi usor calculata in MATLAB prin:
1 - gamcdf(60, 36, 2) = 0.8426.
Exercitiu 1.1.9 Un cetatean turmentat pleaca de la bar spre casa. Sa presupunem ca punctulde plecare este punctul O de pe axa orizontala si se misca doar pe aceasta axa astfel: în fiecareunitate de timp, acesta ori face un pas în fata, cu probabilitatea 0.5, ori face un pas în spate, cuprobabilitatea 0.5, independent de pasii anteriori. Folosind Teorema limita centrala, estimatiprobabilitatea ca, dupa 100 de pasi, acesta nu a ajuns la mai mult de doi pasi de punctul de plecare.
R: Fie Xi variabila aleatoare ce reprezinta pasul pe care cetateanul îl face la momentul i(i ∈ N). Sa atribuim X = −1, daca face un pas în spate, si X = 1, daca face un pas în fata.Asadar, X este o variabila aleatoare discreta ce poate lua doar doua valori, −1 si 1, ambele cuprobabilitatea 0.5. Se calculeaza cu usurinta, E(X) = 0 si Var(X) = 1. Suntem interesati sa
aflam ce se întâmpla dupa 100 de pasi. Consideram mai întâi Sn =n
∑i=1
Xi. Atunci,
E(Sn) =n
∑i=1
E(Xi) = 0 si Var(Sn) =n
∑i=1
Var(Xi) = n,
deoarece Xii=1,n sunt independente. Pentru n≥ 30, Teorema limita centrala spune ca
Sn−E(Sn)
σ(Sn)=
Sn√n∼N (0, 1),
echivalent cu Sn ∼N (0,√
n).
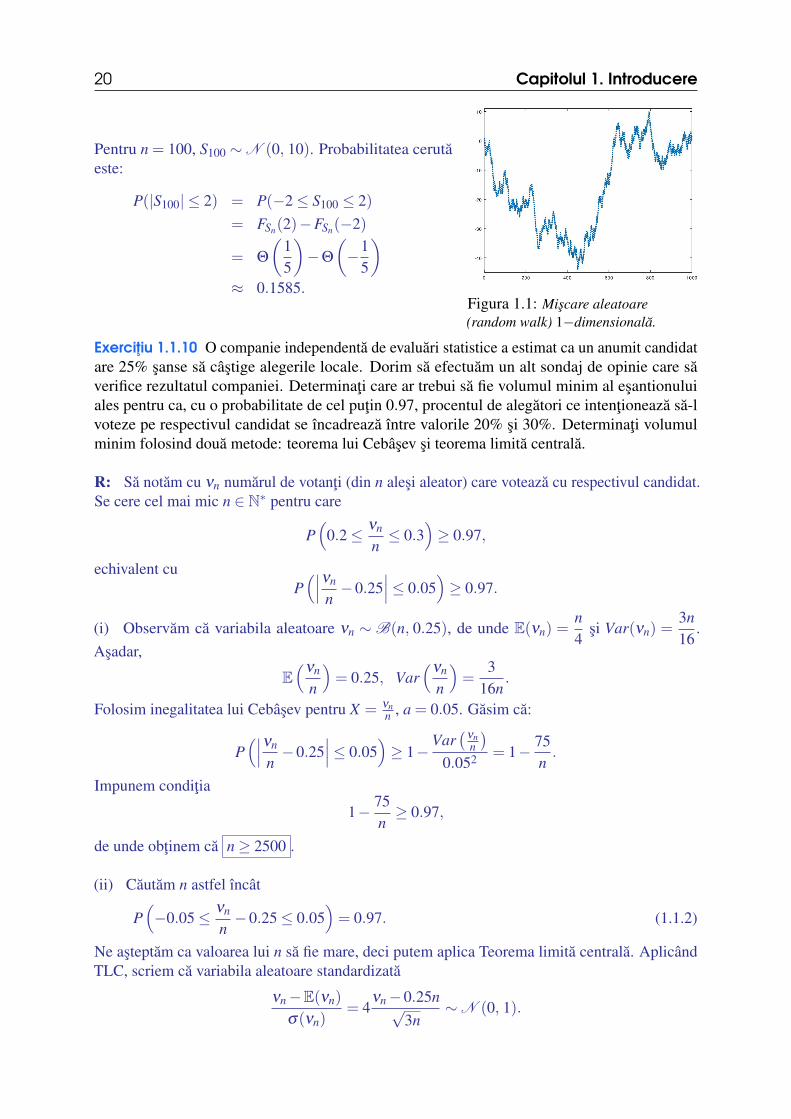
20 Capitolul 1. Introducere
Pentru n = 100, S100 ∼N (0, 10). Probabilitatea cerutaeste:
P(|S100| ≤ 2) = P(−2≤ S100 ≤ 2)= FSn(2)−FSn(−2)
= Θ
(15
)−Θ
(−1
5
)≈ 0.1585.
Figura 1.1: Miscare aleatoare(random walk) 1−dimensionala.
Exercitiu 1.1.10 O companie independenta de evaluari statistice a estimat ca un anumit candidatare 25% sanse sa câstige alegerile locale. Dorim sa efectuam un alt sondaj de opinie care saverifice rezultatul companiei. Determinati care ar trebui sa fie volumul minim al esantionuluiales pentru ca, cu o probabilitate de cel putin 0.97, procentul de alegatori ce intentioneaza sa-lvoteze pe respectivul candidat se încadreaza între valorile 20% si 30%. Determinati volumulminim folosind doua metode: teorema lui Cebâsev si teorema limita centrala.
R: Sa notam cu νn numarul de votanti (din n alesi aleator) care voteaza cu respectivul candidat.Se cere cel mai mic n ∈ N∗ pentru care
P(
0.2≤ νn
n≤ 0.3
)≥ 0.97,
echivalent cuP(∣∣∣νn
n−0.25
∣∣∣≤ 0.05)≥ 0.97.
(i) Observam ca variabila aleatoare νn ∼B(n, 0.25), de unde E(νn) =n4
si Var(νn) =3n16
.Asadar,
E(
νn
n
)= 0.25, Var
(νn
n
)=
316n
.
Folosim inegalitatea lui Cebâsev pentru X = νnn , a = 0.05. Gasim ca:
P(∣∣∣νn
n−0.25
∣∣∣≤ 0.05)≥ 1− Var
(νnn
)0.052 = 1− 75
n.
Impunem conditia
1− 75n≥ 0.97,
de unde obtinem ca n≥ 2500 .
(ii) Cautam n astfel încât
P(−0.05≤ νn
n−0.25≤ 0.05
)= 0.97. (1.1.2)
Ne asteptam ca valoarea lui n sa fie mare, deci putem aplica Teorema limita centrala. AplicândTLC, scriem ca variabila aleatoare standardizata
νn−E(νn)
σ(νn)= 4
νn−0.25n√3n
∼N (0, 1).

1.2 Exercitii propuse 21
Folosind aceasta, rescriem egalitatea (1.1.2) astfel:
0.97 = P(−0.05≤ νn
n−0.25≤ 0.05
)= P
(−0.05 ·4
√n3≤ 4
νn−0.25n√3n
≤ 0.05 ·4√
n3
)= Θ
(0.2√
n3
)−Θ
(−0.2
√n3
)= Θ
(0.2√
n3
)−[
1−Θ
(0.2√
n3
)]= 2Θ
(0.2√
n3
)−1
de unde Θ(0.2√n
3
)= 0.985 si 0.2
√n3 = z0.985 ≈ 2.17 (cuantila de ordin 0.985 pentru repartitia
normala standard). Din ultima egalitate gasim ca n≈ 353.1969. Asadar, pentru ca relatia dinenunt sa aiba loc, va trebui ca n≥ 354 .Observam ca aceasta valoare este mult mai mica decât cea gasita anterior.
1.2 Exercitii propuseExercitiu 1.2.1 Notam cu X procentul de timp necesar unui student (ales la întâmplare) pentru arezolva un anumit test într-un interval de timp fix. Densitatea de repartitie a lui X este f : R→R,
f (x; θ) =
(θ +1)xθ , 0≤ x≤ 1,0 , altfel.
(a) Pentru ce valori ale parametrului θ functia f este o densitate de repartitie?(b) Determinati media si dispersia variabilei X .(c) Pentru θ = 2, calculati probabilitatile: P(X < 0.5), P(X = 0.5), P(X > 0.2).Exercitiu 1.2.2 Consideram o variabila aleatoare X de tip continuu, având functia de repartitie
F(x) =
0 ,x≤ 0;x4
[1+ ln
(4x
)],x ∈ [(0, 4];
1 ,x > 4.
Calculati:(a) P(X ≤ 1), P(X = 1);(b) E(X);(c) P(1≤ X < 3).
Exercitiu 1.2.3 Consideram functia
f (x) =
acos2x, x ∈
(0, π
4
),
0, x 6∈(0, π
4
).
(a) Aflati valoarea parametrului real a pentru care f (x) este o densitate de repartitie.(b) Fie X variabila aleatoare asociata. Determinati functia sa de repartitie.(c) Calculati probabilitatea P(X ≥ π
8 ).Exercitiu 1.2.4 Folositi tabelele de cuantile pentru a gasi urmatoarele:
(a) z0.975 (b) t0.975,12 (c) χ20.9,5 (d) f0.95,12,10.

22 Capitolul 1. Introducere
Exercitiu 1.2.5 Temperatura T (0C) dintr-un anumit proces chimic are repartitia U (−5, 5).Calculati P(T < 0); P(−2.5 < T < 2.5); P(−2≤ T ≤ 3).Exercitiu 1.2.6 Temperatura de topire a unui anumit material este o variabila aleatoare cu mediade 120 oC si deviatia standard de 2 oC. Determinati temperatura medie si deviatia standard în oF ,stiind ca oF = 1.8 oC+32.Exercitiu 1.2.7 Daca Z ∼N (0, 1), calculati:
P(Z ≤ 1.35); P(0≤ Z ≤ 1); P(1≤ Z); P(|Z|> 1.5).Exercitiu 1.2.8 O companie de asigurari ofera angajatilor sai diverse polite de asigurare. Pentruun asigurat ales aleator, notam cu X numarul de luni scurs între doua plati succesive. Functia derepartitie a lui X este:
F(x) =
0 , x < 1;0.3 , 1≤ x < 3;0.4 , 3≤ x < 4;0.45 , 4≤ x < 6;0.65 , 6≤ x < 12;1 , 12≤ x.
(a) Determinati functia de probabilitate a lui X .(b) Calculati P(3≤ X ≤ 6) si P(4≤ X).Exercitiu 1.2.9 Un anumit comerciant vinde trei tipuri de congelatoare: de 160 litri, de 190 litrisi de 230 litri. Fie X variabila aleatoare care reprezinta alegerea unui client ales la întâmplare, ceare tabelul de repartitie:
x 160 190 230p(x) 0.2 0.5 0.3
(a) Calculati E(X), Var(X).(b) Daca pretul unui frigider se calculeaza dupa formula P = 7X − 9.5, calculati valoareaasteptata a pretului platit de urmatorul client care cumpara un congelator.(c) Calculati Var(P).(d) Presupunem ca, desi capacitatea afisata este X , capacitatea reala a unui congelator esteh(X) = X−0.01X2. Care este valoarea medie a capacitatii reale pentru un congelator cumparatde urmatorul client?Exercitiu 1.2.10 Daca X este o variabila aleatoare repartizata U (0, 1), determinati repartitiavariabilei aleatoare Y = 1−X .Exercitiu 1.2.11 Daca X este o variabila aleatoare repartizata U (0, 1), determinati repartitiavariabilei aleatoare Y = eX .Exercitiu 1.2.12 Latura unui patrat este o variabila aleatoare ce are densitatea de repartitie f (x)=x8 , x ∈ (0, 4). Determinati densitatea de repartitie a ariei patratului. Care este probabilitatea caaria patratului sa fie mai mare decât 10?Exercitiu 1.2.13 Fie X si Y doua variabile aleatoare independente, identic repartizate N (0, 1).Determinati raza cercului cu centrul în origine astfel încât P((X , Y ) ∈ D(0, r)) = 0.95, undeD(0, r) = (x, y) ∈ R, x2 + y2 ≤ r2.Exercitiu 1.2.14 Distanta X la care sunt aruncate mingile aruncate de o masina automata de servitmingi de tenis este o variabila aleatoare repartizata normal. Media distantei este necunoscuta,dar deviatia standard este 1.2 m.(a) Stiind ca P(X ≤ 20) = 0.95, sa se gaseasca valoarea asteptata a distantei (adica, E(X)).
(b) Stabiliti repartitia v.a. Z =X−E(X)
1.2si calculati probabilitatea P(Z2 ≤ 2).

1.2 Exercitii propuse 23
Exercitiu 1.2.15 Fie X si Y doua variabile aleatoare independente si identic repartizate N (0, σ).Aratati ca variabilele aleatoare U = X2 +Y 2 si V = X
Y sunt, de asemenea, independente.Exercitiu 1.2.16 Daca X ∼P(1), determinati cel mai mic numar natural n pentru care P(X <n)≥ 0.99.Exercitiu 1.2.17 Aruncam o moneda ideala în conditii identice si notam cu νn frecventa absolutade aparitie a fetei cu stema din cele n repetitii ale experimentului. Care este numarul minim dearuncari ce trebuie efectuate pentru ca
P(∣∣∣νn
n−0.5
∣∣∣≤ 0.1)≥ 0.98.
Determinati n prin doua metode:(i) Folosind inegalitatea lui Cebâsev;(ii) Folosind Teorema limita centrala.
Exercitiu 1.2.18 Aflati repartitia unei sume de variabile aleatoare independente, identic reparti-zate exp(λ ), λ > 0.Exercitiu 1.2.19 Pentru evaluarea rezultatelor obtinute la teza de Matematica de catre elevii uneianumite scoli, se face un sondaj de volum 35 printre elevii scolii, iar notele lor sunt sumarizatein Tabelul 1.2.
note 4 5 6 7 8 9 10frecventa 3 6 7 8 5 4 2
Tabela 1.2: Medii generale si frecvente
(i) Sa se scrie si sa se reprezinte grafic functia de repartitie asociata.(ii) Notam cu X variabila aleatoare ce are acest tabel de repartitie. Utilizand selectia de mai sus,sa se aproximeze probabilitatea P(6≤ X ≤ 8).Exercitiu 1.2.20 Erorile a 10 masuratori sunt variabile aleatoare εi ∼N (0, 1), i = 1, 2, . . . , n.
(1) Aratati (folosind functia generatoare de momente) ca variabila aleatoare H =10
∑i=1
ε2i urmeaza
repartitia χ2, i.e. H ∼ χ2(10).(2) Determinati probabilitatile urmatoare:
P(H ≤ 7); P(9.25≤ H ≤ 10.75); P(H > 12).
Exercitiu 1.2.21 Se arunca un zar ideal în mod repetat. Daca X este numarul de aruncarinecesare pentru a obtine fiecare fata cel putin o data, aflati un interval (a, b) astfel încât P(a <X < b)≥ 0.9.Exercitiu 1.2.22 Variabila aleatoare H reprezinta masa corporala a unei persoane de gen mas-culin dintr-o anumita regiune a tarii este o variabila normala. Sansele ca masa unei persoanealese aleator sa aiba mai putin de 70kg este 0.1, iar sansele ca masa unei persoane alese aleatorsa aiba mai mult de 100kg este 0.2. Sa se determine media si dispersia lui H.Exercitiu 1.2.23 (a) Daca T1 ∼ exp(λ1) si T2 ∼ exp(λ2) sunt independente, determinati reparti-tia variabilei minT1, T2.(b) Andrei si Barbu se asaza simultan la pescuit, fiecare la un alt lac. Daca timpii de prindere acâte unui peste din fiecare lac sunt repartizati exponential, independenti, de medii 15 si 20 deminute, aflati probabilitatea ca primul peste prins sa apara în mai putin de 18 minute.


2. Elemente de Statistica descriptiva
Statistica descriptiva este acea ramura a Statisticii care se preocupa de descrierea datelor statistice,prin gruparea, reprezentarea grafica si calcularea unor masuri empirice ale formei sau tendinteidatelor. Este primul pas pe care îl face un statistician ce urmareste sa extraga informatii dintr-unset de date.Daca datele statistice sunt negrupate, atunci se prefera o grupare a lor in clase, pentru o maibuna observare a lor. Dupa gruparea in clase (care este la latitudinea statisticianului), datele suntasezate in tabele de frecvente. Aceste tabele pot contine, pe langa clasele construite, frecventeabsolute, frecvente relative, frecvente cumulate, frontierele claselor, valorile de mijloc. Uneoridoar un singur tip de frecvente este suficient pentru a continua analiza datelor. Un exemplu detabel de frecvente este Tabelul 2.4.Exista mai multe optiuni pentru reprezentarea grafica a datelor, in functie de tipul de date pe carele avem. Spre exemplu, pentru date discrete sunt preferate reprezentarile cu bare sau cu sectoarede disc. Dupa caz, mai pot fi folosite reprezentari cu puncte sau stem&leaf. Pentru date continuese folosesc histograme sau sectoare de disc.
2.1 Organizarea si descrierea datelor statisticePresupunem ca avem o colectivitate statistica, careia i se urmareste o anumita caracteristica (sauvariabila). Spre exemplu, colectivitatea este multimea tuturor studentilor dintr-o universitateînrolati în anul întâi de master, iar caracteristica este media la licenta obtinuta de fiecare dintreacesti studenti. Teoretic, multimea valorilor acestei caracteristici este intervalul [6, 10], iaraceasta variabila poate lua orice valoare din acest interval.Vom numi date (sau date statistice) informatiile obtinute în urma observarii valorilor acesteicaracteristici. In cazul mentionat mai sus, datele sunt mediile la licenta observate. În general,datele pot fi calitative (se mai numesc si categoriale) sau cantitative, dupa cum caracteristica (sauvariabila) observata este calitativa (exprima o calitate sau o categorie) sau, respectiv, cantitativa(are o valoare numerica). Totodata, aceste date pot fi date de tip discret, daca sunt obtinute înurma observarii unei caracteristici discrete (o variabila aleatoare discreta, sau o variabila ale

26 Capitolul 2. Elemente de Statistica descriptiva
carei posibile valori sunt in numar finit sau cel mult numarabil), sau date continue, daca aceastacaracteristica este continua (o variabila aleatoare de tip continuu, sau o variabila ce poate luaorice valoare dintr-un interval sau chiar de pe axa reala). În cazul din exemplul de mai sus, datelevor fi cantitative si continue.În Statistica se obisnuieste a se nota variabilele (caracteristicile) cu litere mari, X , Y, Z, . . ., sivalorile lor cu litere mici, x, y, z, . . .. Daca in exemplul de mai sus notam cu Z variabila medie lalicenta, atunci un anume z observat va fi media la licenta pentru un student din colectivitate alesaleator.Primul pas în analiza datelor empirice observate este o analiza descriptiva, ce consta in ordo-narea si reprezentarea grafica a datelor, dar si în calcularea anumitor caracteristici numericepentru acestea. Datele înainte de prelucrare, adica exact asa cum au fost culese, se numesc datenegrupate. Un exemplu de date negrupate (de tip continuu) sunt cele observate in Tabelul 2.1,reprezentând timpi (în min.sec) de asteptare pentru primii 100 de clienti care au asteptat la unghiseu pâna au fost serviti.
1.02 2.01 2.08 3.78 2.03 0.92 4.08 2.35 1.30 4.50 4.06 3.55 2.63 1.76
0.13 5.32 3.97 3.36 4.31 3.58 5.64 1.95 0.91 1.26 0.74 3.64 4.77 2.14
2.98 4.33 5.08 4.67 0.79 3.14 0.99 0.78 2.34 4.51 3.53 4.55 1.89 3.28
0.94 3.44 1.35 3.64 2.92 2.67 2.86 2.41 3.19 5.41 5.14 2.75 1.67 3.89
1.12 4.75 2.88 4.30 4.55 5.87 0.70 5.04 5.33 2.40 1.50 0.83 3.74 4.85
3.79 1.48 2.65 1.55 3.95 5.88 1.58 5.49 0.48 2.77 3.20 2.51 5.80 4.12
3.12 0.71 2.76 1.95 0.10 4.22 5.69 5.41 1.68 2.46 1.40 2.16 4.98 0.88
5.36 1.32
Tabela 2.1: Date statistice negrupate
De cele mai multe ori, enumerarea tuturor datelor culese este dificil de realizat, de aceea seurmareste a se grupa datele, pentru o mai usoara gestionare. Imaginati-va ca enumeram toatevoturile unei selectii întâmplatoare de 15000 de votanti, abia iesiti de la vot. Mai degraba, ar fimai util si practic sa grupam datele dupa numele candidatilor, precizând numarul de voturi ce l-aprimit fiecare. Asadar, pentru o mai buna descriere a datelor, este necesara gruparea lor in clasede interes.
2.1.1 Gruparea datelorDatele prezentate sub forma de tabel (sau tablou) de frecvente se numesc date grupate. Datelede selectie obtinute pot fi date discrete sau date continue, dupa cum caracteristicile studiate suntvariabile aleatoare discrete sau, respectiv, continue.
1. Date de tip discret: Daca datele de selectie sunt discrete (e.g., z1, z2, . . . , zn), esteposibil ca multe dintre ele sa se repete. Presupunem ca valorile distincte ale acestor date suntz′1, z′2, . . . , z′r, r ≤ n. Atunci, putem grupa datele într-un asa-numit tabel de frecvente (veziexemplul din Tabelul 2.2). Alternativ, putem organiza datele negrupate într-un tabel de frecvente,dupa cum urmeaza:
data z′1 z′2 . . . z′rfrecventa f1 f2 . . . fr
(2.1.1)
unde fi este frecventa aparitiei valorii z′i, (i = 1, 2, . . . , r), si se va numi distributia empirica deselectie a lui Z. Aceste frecvente pot fi absolute sau de relative. Un tabel de frecvente (sau o
2.1 Organizarea si descrierea datelor statistice 27
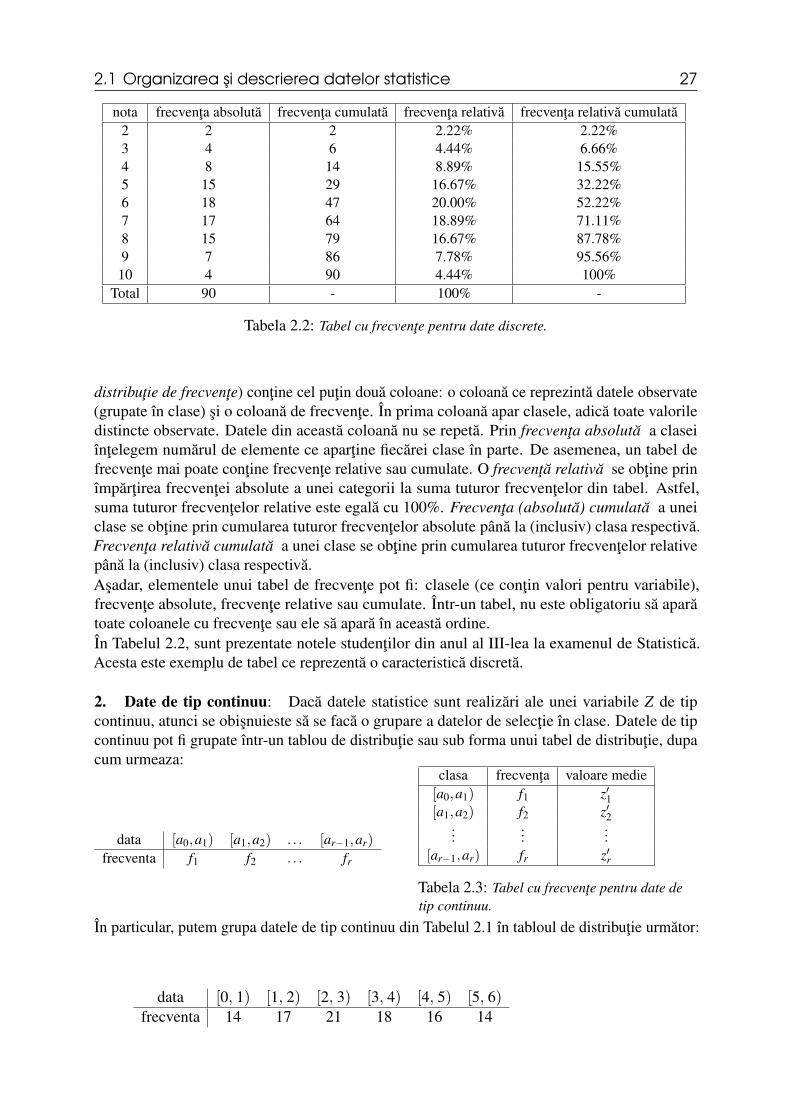
nota frecventa absoluta frecventa cumulata frecventa relativa frecventa relativa cumulata2 2 2 2.22% 2.22%3 4 6 4.44% 6.66%4 8 14 8.89% 15.55%5 15 29 16.67% 32.22%6 18 47 20.00% 52.22%7 17 64 18.89% 71.11%8 15 79 16.67% 87.78%9 7 86 7.78% 95.56%10 4 90 4.44% 100%
Total 90 - 100% -
Tabela 2.2: Tabel cu frecvente pentru date discrete.
distributie de frecvente) contine cel putin doua coloane: o coloana ce reprezinta datele observate(grupate în clase) si o coloana de frecvente. În prima coloana apar clasele, adica toate valoriledistincte observate. Datele din aceasta coloana nu se repeta. Prin frecventa absoluta a claseiîntelegem numarul de elemente ce apartine fiecarei clase în parte. De asemenea, un tabel defrecvente mai poate contine frecvente relative sau cumulate. O frecventa relativa se obtine prinîmpartirea frecventei absolute a unei categorii la suma tuturor frecventelor din tabel. Astfel,suma tuturor frecventelor relative este egala cu 100%. Frecventa (absoluta) cumulata a uneiclase se obtine prin cumularea tuturor frecventelor absolute pâna la (inclusiv) clasa respectiva.Frecventa relativa cumulata a unei clase se obtine prin cumularea tuturor frecventelor relativepâna la (inclusiv) clasa respectiva.Asadar, elementele unui tabel de frecvente pot fi: clasele (ce contin valori pentru variabile),frecvente absolute, frecvente relative sau cumulate. Într-un tabel, nu este obligatoriu sa aparatoate coloanele cu frecvente sau ele sa apara în aceasta ordine.În Tabelul 2.2, sunt prezentate notele studentilor din anul al III-lea la examenul de Statistica.Acesta este exemplu de tabel ce reprezenta o caracteristica discreta.
2. Date de tip continuu: Daca datele statistice sunt realizari ale unei variabile Z de tipcontinuu, atunci se obisnuieste sa se faca o grupare a datelor de selectie în clase. Datele de tipcontinuu pot fi grupate într-un tablou de distributie sau sub forma unui tabel de distributie, dupacum urmeaza:
data [a0,a1) [a1,a2) . . . [ar−1,ar)
frecventa f1 f2 . . . fr
clasa frecventa valoare medie[a0,a1) f1 z′1[a1,a2) f2 z′2
......
...[ar−1,ar) fr z′r
Tabela 2.3: Tabel cu frecvente pentru date detip continuu.
În particular, putem grupa datele de tip continuu din Tabelul 2.1 în tabloul de distributie urmator:
data [0, 1) [1, 2) [2, 3) [3, 4) [4, 5) [5, 6)frecventa 14 17 21 18 16 14

28 Capitolul 2. Elemente de Statistica descriptiva
vârsta frecventa frecventa relativa frecventa cumulata vârsta medie[18,25) 34 8.83% 8.83% 21.5[25,35) 76 19.74% 28.57% 30[35,45) 124 32.21% 60.78% 40[45,55) 87 22.60% 83.38% 50[55,65) 64 16.62% 100.00% 60
Total 385 100% - -
Tabela 2.4: Tabel cu frecvente pentru rata somajului.
Aceasta grupare nu este unica; intervalele ce reprezinta clasele pot fi modificate dupa cum doresteutilizatorul. Uneori, tabelul de distributie pentru o caracteristica de tip continuu mai poate fi scrissi sub forma unui tabel ca in (2.1.1), unde
• z′i =ai−1 +ai
2este elementul de mijloc al clasei [ai−1, ai);
• fi este frecventa aparitiei valorilor din [ai−1, ai), (i = 1, 2, . . . , r),r
∑i=1
fi = n.
Pentru definirea claselor unui tabel de frecvente, nu exista o regula precisa. Fiecare utilizatorde date îsi poate crea propriul tabel de frecvente. Scopul final este ca acest tabel sa scoata înevidenta caracteristicele datelor, cum ar fi: existenta unor grupe (clase) naturale, variabilitateadatelor într-un anumit grup (clasa), informatii legate de existenta unor anumite date statistice carenu au fost observate in selectia data etc. În general, aceste caracteristici nu ar putea fi observateprivind direct setul de date negrupate. Totusi, pentru crearea tabelelor de frecvente, se recomandaurmatorii pasi:
1. Determinarea numarului de clase (disjuncte). Este recomandat ca numarul claselor sa fieîntre 5 si 20. Daca volumul datelor este mic (e.g., n < 30), se recomanda constituirea a 5sau 6 clase. De asemenea, daca este posibil, ar fi util ca fiecare clasa sa fie reprezentata decel putin 5 valori (pentru un numar mic de clase). Daca numarul claselor este mai mare,putem avea si mai putine date într-o clasa, dar nu mai putin de 3. O clasa cu prea putinevalori (0, 1 sau 2) poate sa nu fie reprezentativa.
2. Determinarea latimii claselor. Daca este posibil, ar fi bine daca toate clasele ar avea aceeasilatime. Acest pas depinde, în mare masura, de alegerea din pasul anterior.
3. Determinarea frontierelor claselor. Frontierele claselor sunt construite astfel încât fiecaredata statistica sa apartine unei singure clase.
În practica, un tabel de frecvente se realizeaza prin încercari, pâna avem convingerea ca grupareafacuta poate surprinde cât mai fidel datele observate.Asadar, daca ne este data o însiruire de date ale unei caracteristici discrete sau continue, atuncile putem grupa imediat în tabele sau tablouri de frecvente. Invers (avem tabelul sau tabloul derepartitie si vrem sa enumeram datele) nu este posibil, decât doar în cazul unei caracteristici detip discret. De exemplu, daca ni se da Tabelul 2.4, ce reprezinta rata somajului într-o anumitaregiune a tarii pe categorii de vârste, nu am putea sti cu exactitate vârsta exacta a persoanelorcare au fost selectionate pentru studiu.Observam ca acest tabel are 5 clase: [18, 25), [25, 35), [35, 45), [45, 55), [55, 65). Vom numivaloare de mijloc pentru o clasa, valoarea obtinuta prin media valorilor extreme ale clasei. Încazul Tabelului 2.4, valorile de mijloc sunt scrise în coloana cu vârsta medie. Frecventa cumulataa unei clase este suma frecventelor tuturor claselor cu valori mai mici.
2.2 Reprezentarea datelor statistice 29
2.2 Reprezentarea datelor statisticeUn tabel de frecvente sau o distributie de frecvente (absolute sau relative) sunt de cele mai multeori baza unor reprezentari grafice, pentru o mai buna vizualizare a datelor. Aceste reprezentaripot fi facute în diferite moduri, dintre care amintim pe cele mai uzuale.
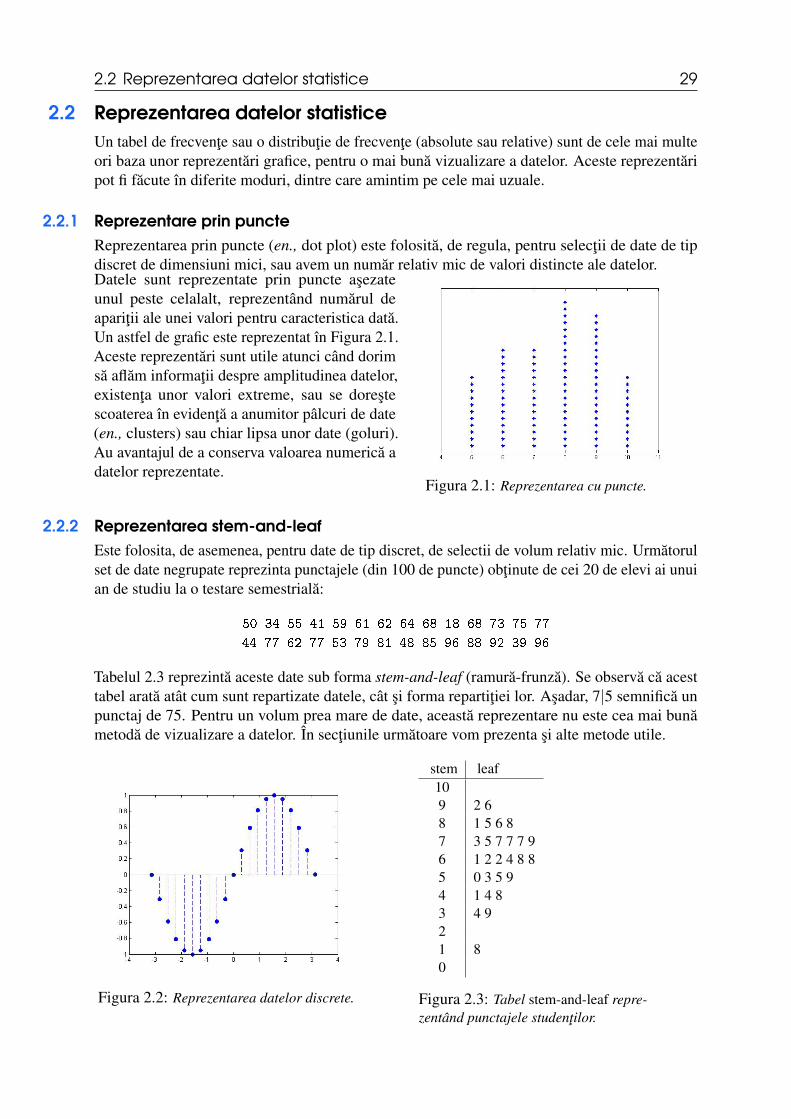
2.2.1 Reprezentare prin puncteReprezentarea prin puncte (en., dot plot) este folosita, de regula, pentru selectii de date de tipdiscret de dimensiuni mici, sau avem un numar relativ mic de valori distincte ale datelor.Datele sunt reprezentate prin puncte asezateunul peste celalalt, reprezentând numarul deaparitii ale unei valori pentru caracteristica data.Un astfel de grafic este reprezentat în Figura 2.1.Aceste reprezentari sunt utile atunci când dorimsa aflam informatii despre amplitudinea datelor,existenta unor valori extreme, sau se dorestescoaterea în evidenta a anumitor pâlcuri de date(en., clusters) sau chiar lipsa unor date (goluri).Au avantajul de a conserva valoarea numerica adatelor reprezentate.
Figura 2.1: Reprezentarea cu puncte.
2.2.2 Reprezentarea stem-and-leafEste folosita, de asemenea, pentru date de tip discret, de selectii de volum relativ mic. Urmatorulset de date negrupate reprezinta punctajele (din 100 de puncte) obtinute de cei 20 de elevi ai unuian de studiu la o testare semestriala:
50 34 55 41 59 61 62 64 68 18 68 73 75 77
44 77 62 77 53 79 81 48 85 96 88 92 39 96
Tabelul 2.3 reprezinta aceste date sub forma stem-and-leaf (ramura-frunza). Se observa ca acesttabel arata atât cum sunt repartizate datele, cât si forma repartitiei lor. Asadar, 7|5 semnifica unpunctaj de 75. Pentru un volum prea mare de date, aceasta reprezentare nu este cea mai bunametoda de vizualizare a datelor. În sectiunile urmatoare vom prezenta si alte metode utile.
Figura 2.2: Reprezentarea datelor discrete.
stem leaf109 2 68 1 5 6 87 3 5 7 7 7 96 1 2 2 4 8 85 0 3 5 94 1 4 83 4 921 80
Figura 2.3: Tabel stem-and-leaf repre-zentând punctajele studentilor.
30 Capitolul 2. Elemente de Statistica descriptiva
2.2.3 Reprezentarea cu bare (bar charts)
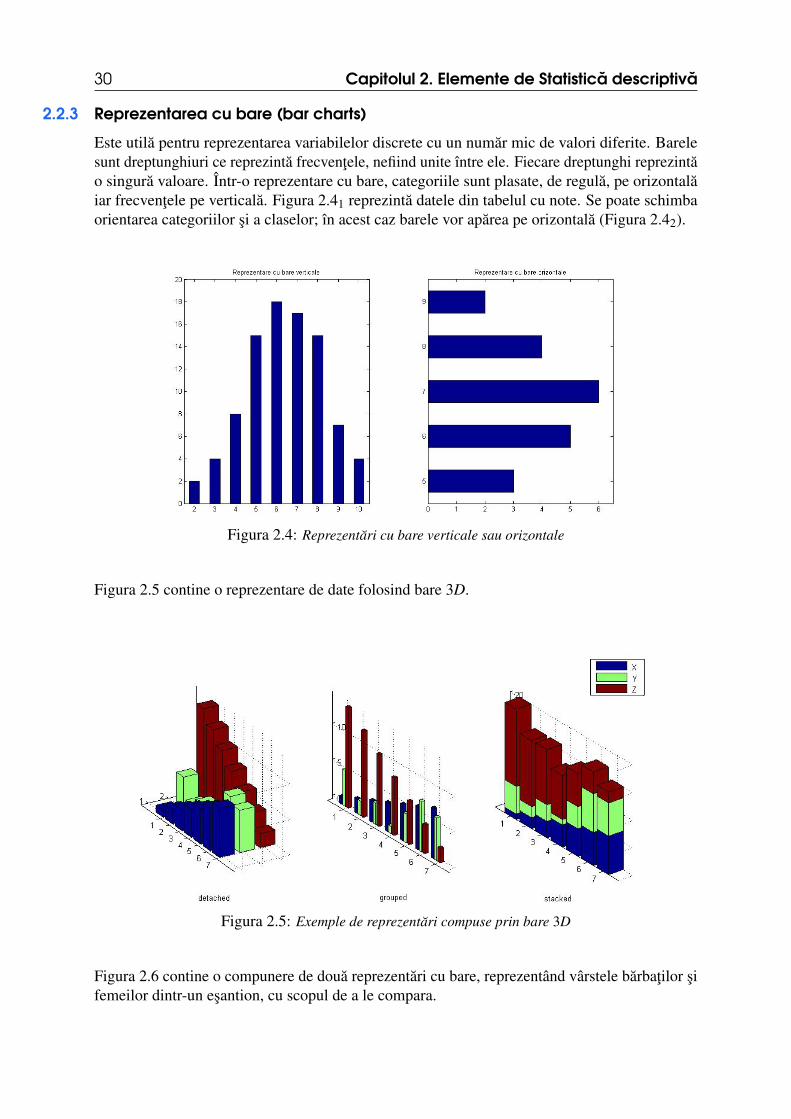
Este utila pentru reprezentarea variabilelor discrete cu un numar mic de valori diferite. Barelesunt dreptunghiuri ce reprezinta frecventele, nefiind unite între ele. Fiecare dreptunghi reprezintao singura valoare. Într-o reprezentare cu bare, categoriile sunt plasate, de regula, pe orizontalaiar frecventele pe verticala. Figura 2.41 reprezinta datele din tabelul cu note. Se poate schimbaorientarea categoriilor si a claselor; în acest caz barele vor aparea pe orizontala (Figura 2.42).
Figura 2.4: Reprezentari cu bare verticale sau orizontale
Figura 2.5 contine o reprezentare de date folosind bare 3D.
Figura 2.5: Exemple de reprezentari compuse prin bare 3D
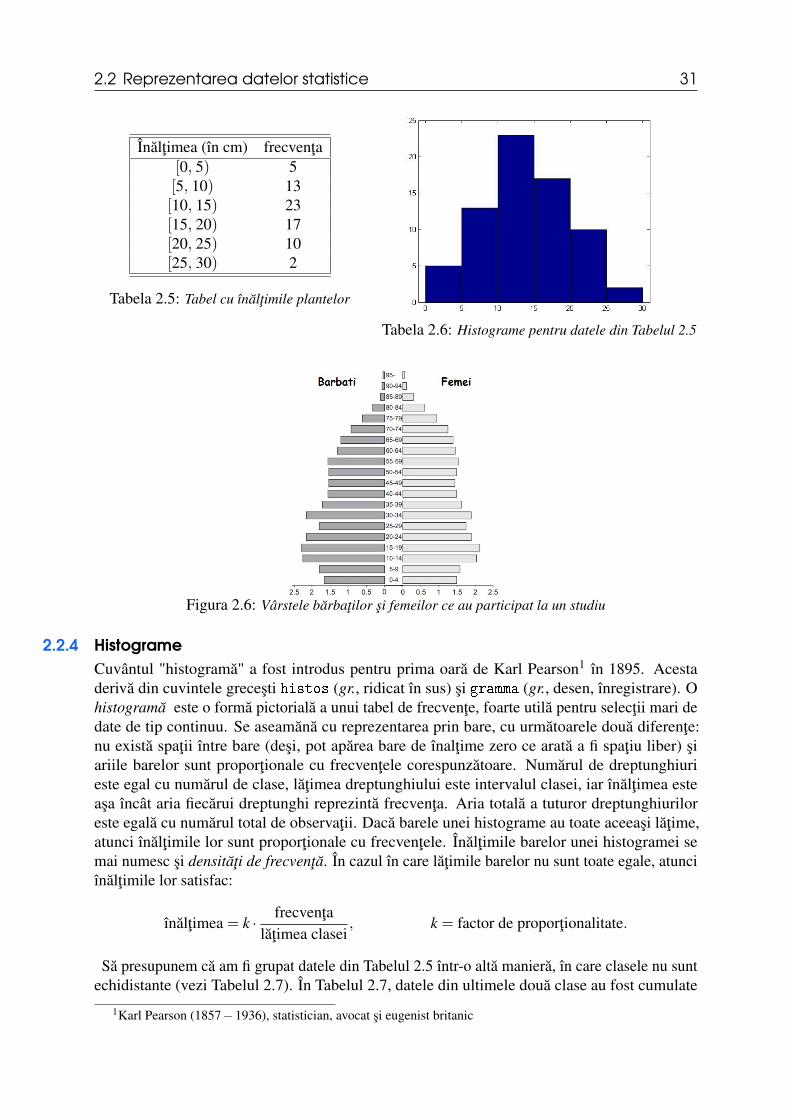
Figura 2.6 contine o compunere de doua reprezentari cu bare, reprezentând vârstele barbatilor sifemeilor dintr-un esantion, cu scopul de a le compara.
2.2 Reprezentarea datelor statistice 31
Înaltimea (în cm) frecventa[0, 5) 5[5, 10) 13[10, 15) 23[15, 20) 17[20, 25) 10[25, 30) 2
Tabela 2.5: Tabel cu înaltimile plantelor
Tabela 2.6: Histograme pentru datele din Tabelul 2.5
Figura 2.6: Vârstele barbatilor si femeilor ce au participat la un studiu
2.2.4 HistogrameCuvântul "histograma" a fost introdus pentru prima oara de Karl Pearson1 în 1895. Acestaderiva din cuvintele grecesti histos (gr., ridicat în sus) si gramma (gr., desen, înregistrare). Ohistograma este o forma pictoriala a unui tabel de frecvente, foarte utila pentru selectii mari dedate de tip continuu. Se aseamana cu reprezentarea prin bare, cu urmatoarele doua diferente:nu exista spatii între bare (desi, pot aparea bare de înaltime zero ce arata a fi spatiu liber) siariile barelor sunt proportionale cu frecventele corespunzatoare. Numarul de dreptunghiurieste egal cu numarul de clase, latimea dreptunghiului este intervalul clasei, iar înaltimea esteasa încât aria fiecarui dreptunghi reprezinta frecventa. Aria totala a tuturor dreptunghiuriloreste egala cu numarul total de observatii. Daca barele unei histograme au toate aceeasi latime,atunci înaltimile lor sunt proportionale cu frecventele. Înaltimile barelor unei histogramei semai numesc si densitati de frecventa. În cazul în care latimile barelor nu sunt toate egale, atunciînaltimile lor satisfac:
înaltimea = k · frecventalatimea clasei
, k = factor de proportionalitate.
Sa presupunem ca am fi grupat datele din Tabelul 2.5 într-o alta maniera, în care clasele nu suntechidistante (vezi Tabelul 2.7). În Tabelul 2.7, datele din ultimele doua clase au fost cumulate
1Karl Pearson (1857−1936), statistician, avocat si eugenist britanic
32 Capitolul 2. Elemente de Statistica descriptiva
într-o singura clasa, de latime mai mare decât celelalte, deoarece ultima clasa din Tabelul 2.5nu avea suficiente date. Histograma ce reprezinta datele din Tabelul 2.7 este cea din Figura 2.8.Conform cu regula proportionalitatii ariilor cu frecventele, se poate observa ca primele patru bareau înaltimi egale cu frecventele corespunzatoare, pe când înaltimea ultimei bare este jumatatedin valoarea frecventei corespunzatoare, deoarece latimea acesteia este dublul latimii celorlalte.În general, pentru a construi o histograma, vom avea în vedere urmatoarele:
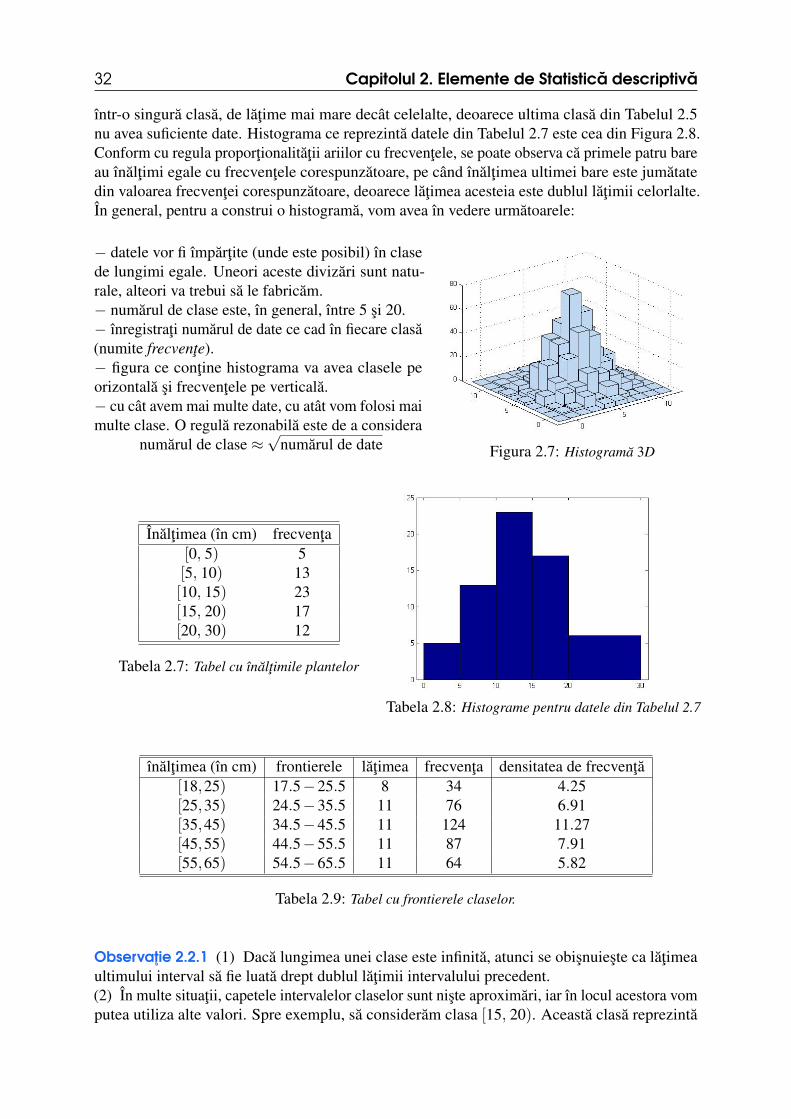
− datele vor fi împartite (unde este posibil) în clasede lungimi egale. Uneori aceste divizari sunt natu-rale, alteori va trebui sa le fabricam.− numarul de clase este, în general, între 5 si 20.− înregistrati numarul de date ce cad în fiecare clasa(numite frecvente).− figura ce contine histograma va avea clasele peorizontala si frecventele pe verticala.− cu cât avem mai multe date, cu atât vom folosi maimulte clase. O regula rezonabila este de a considera
numarul de clase ≈√
numarul de date Figura 2.7: Histograma 3D
Înaltimea (în cm) frecventa[0, 5) 5[5, 10) 13[10, 15) 23[15, 20) 17[20, 30) 12
Tabela 2.7: Tabel cu înaltimile plantelor
Tabela 2.8: Histograme pentru datele din Tabelul 2.7
înaltimea (în cm) frontierele latimea frecventa densitatea de frecventa[18,25) 17.5−25.5 8 34 4.25[25,35) 24.5−35.5 11 76 6.91[35,45) 34.5−45.5 11 124 11.27[45,55) 44.5−55.5 11 87 7.91[55,65) 54.5−65.5 11 64 5.82
Tabela 2.9: Tabel cu frontierele claselor.
Observatie 2.2.1 (1) Daca lungimea unei clase este infinita, atunci se obisnuieste ca latimeaultimului interval sa fie luata drept dublul latimii intervalului precedent.(2) În multe situatii, capetele intervalelor claselor sunt niste aproximari, iar în locul acestora vomputea utiliza alte valori. Spre exemplu, sa consideram clasa [15, 20). Aceasta clasa reprezinta
2.2 Reprezentarea datelor statistice 33
clasa acelor plante ce au înaltimea cuprinsa între 15cm si 20cm. Deoarece valorile înaltimilorsunt valori reale, valorile 15 si 20 sunt, de fapt, aproximarile acestor valori la cel mai apropiatîntreg. Asadar, este posibil ca aceasta clasa sa contina acele plante ce au înaltimile situateîntre 14.5cm (inclusiv) si 20.5cm (exclusiv). Am putea face referire la aceste valori ca fiindvalorile reale ale clasei, numite frontierele clasei. În cazul în care am determinat frontiereleclasei, latimea unei clase se defineste ca fiind diferenta între frontierele ce-i corespund. Înconcluzie, în cazul clasei [15, 20), aceasta are frontierele 14.5 - 20.5, latimea 6 si frecventa 17
6 .Pentru exemplificare, în Tabelul 2.9 am prezentat frontierele claselor, latimile lor si densitatilede frecventa pentru datele din Tabelul 2.4.
2.2.5 Reprezentare prin sectoare de disc (pie charts)
Se poate reprezenta distributia unei caracteristici si folosind sectoare de disc (diagrame circulare)(en., pie charts), fiecare sector de disc reprezentând câte o frecventa relativa. Aceasta variantaeste utila în special la reprezentarea datelor calitative. Exista si posibilitatea de a reprezentadatele prin sectoare 3 dimensionale. În Figura 2.9 am reprezentat datele din Tabelul 2.4.
Figura 2.8: Reprezentarea pe disc a frecventelorrelative ale notelor din tabelul cu note
Figura 2.9: Reprezentare pe disc 3D
2.2.6 Poligonul frecventelor
Un poligon de frecventa este similar cu o reprezentarecu bare, dar în loc sa foloseasca barele, se creeazaun poligon prin trasarea frecventelor si conectareaacestor puncte cu o serie de segmente.
Figura 2.10: Exemplu de poligon alfrecventelor
34 Capitolul 2. Elemente de Statistica descriptiva
2.2.7 Ogive
Pentru frecventele cumulate pot fi folosite ogive. Oogiva reprezinta graficul unei frecvente cumulate(absoluta sau relativa).
Figura 2.11: Ogiva pentru frecventeleabsolute cumulate din Tabelul 2.2
2.2.8 Diagrama Q-Q sau diagrama P-PQ-Q plot (diagrama cuantila-cuantila) si P-P plot(diagrama probabilitate-probabilitate) sunt utilizatein a determina apropierea dintre doua seturi de date(repartitii). Daca datele provin dintr-o acceasi repar-titie, atunci ele se aliniaza dupa o dreapta desenatain figura. Diagrama Q-Q este bazata pe rangurilevalorilor, iar diagrama P-P este bazata pe functiilede repartitie empirice.
Figura 2.12: Exemplu de diagrama Q-Q plot
2.2.9 Diagrama scatter plotDaca (xk, yk), k ∈ 1, 2, . . . , n este un set de datebidimensionale, ce reprezinta observatii asupra vec-torului aleator (X , Y ), atunci o masura a legaturiidintre variabilele X si Y este coeficientul de corela-tie empiric introdus de K. Pearson. Primul pas înanaliza regresionala este vizualizarea datelor. Pen-tru aceasta se foloseste reprezentarea scatter plot.
Figura 2.13: Exemplu de scatter plot
În concluzie, exista mai multe optiuni pentru reprezentarea grafica a datelor, in functie de tipul dedate pe care le avem. Spre exemplu, pentru date discrete sunt preferate reprezentarile cu bare saucu sectoare de disc. Dupa caz, mai pot fi folosite reprezentari cu puncte sau stem&leaf. Pentrudate continue se folosesc histograme sau sectoare de disc.
2.3 Masuri descriptive ale datelor statisticeSa consideram o populatie statistica de volum N si o caracteristica a sa, X , ce are functia derepartitie F . Asupra acestei caracteristici facem n observatii, în urma carora culegem un setde date statistice. Dupa cum am vazut anterior, datele statistice pot fi prezentate într-o forma

2.3 Masuri descriptive ale datelor statistice 35
grupata (descrise prin tabele de frecvente) sau pot fi negrupate, exact asa cum au fost culeseîn urma observarilor. Pentru analiza acestora, pot fi utilizate diverse tehnici de organizaresi reprezentare grafica a datelor statistice însa, de cele mai multe ori, aceste metode nu suntsuficiente pentru o analiza detaliata. Suntem interesati în a atribui acestor date anumite valorinumerice reprezentative. Pot fi definite mai multe tipuri de astfel de valori numerice, e.g.,masuri ale tendintei centrale (media, modul, mediana), masuri ale dispersiei (dispersia, deviatiastandard), masuri de pozitie (cuantile, distanta intercuantilica) etc. În acest capitol, vom introducediverse masuri descriptive numerice, atât pentru datele grupate, cât si pentru cele negrupate.Înainte de a introduce indicatorii statistici specifici datelor, facem unele precizari. Exista anumitetipuri de date pentru care unii dintre indicatorii de mai jos nu sunt utilizati în practica. Spreexemplu, pentru datele norminale (date grupate în categorii, fara o anumita ordine între ele) nuputem calcula media (si alti indicatori care deriva din ea, e.g., dispersia, deviatia standard etc) saumediana. Pentru datele statistice ordinale (date grupate în categorii, între care este consideratao ordine) nu putem calcula media, deoarece distantele dintre clase nu sunt cunoscute. Pentrudatele statistice de tip continuu putem calcula atât media, cât si mediana si modul.
2.3.1 Date negrupateConsideram un set de date statistice negrupate, x1, x2, . . . , xn (xi ∈ R, i = 1, 2 . . . , n, n≤ N), cecorespund unor observatii facute asupra variabilei X . Pe baza acestor observatii, definim urma-toarele masuri descriptive ale datelor, in scopul de a estima parametrii reali ai caracteristicilorpopulatiei. Deoarece ele se bazeaza doar pe observatiile culese, aceste masuri se mai numesc simasuri empirice.
• Valoarea medieEste o masura a tendintei centrale a datelor. Pentru o selectie x1, x2, . . . , xn, definim:
x =1n
n
∑i=1
xi,
ca fiind media datelor observate. Aceasta medie empirica este un estimator pentru mediateoretica, µ = EX , daca aceasta exista.
• Pentru fiecare i, cantitatea di = xi− x se numeste deviatia valorii xi de la medie. Aceastanu poate fi definita ca o masura a gradului de împrastiere a datelor, deoarece
n
∑i=1
(xi− x) = 0.
• MomentelePentru k ∈ N∗, momentele initiale de ordin k se definesc astfel:
ak =1n
n
∑i=1
xki .
Pentru fiecare k ∈ N∗, momentele centrate de ordin k se definesc astfel:
mk =1n
n
∑i=1
(xi− x)k.

36 Capitolul 2. Elemente de Statistica descriptiva
• DispersiaAceasta este o masura a gradului de împrastiere a datelor în jurul valorii medii. Pentru oselectie x1, x2, . . . , xn, definim dispersia astfel:
s2 =1
n−1
n
∑i=1
(xi− x)2
(=
1n−1
[n
∑i=1
x2i −n(x)2]
).
• Deviatia standardEste tot o masura a împrastierii datelor în jurul valorii medii. Pentru o selectie x1, x2, . . . , xn,definim deviatia standard:
s =
√1
n−1
n
∑i=1
(xi− x)2.
• Coeficientul de variatie (sau de dispersie)Acest coeficient (de obicei, exprimat în procente) este util atunci când comparam douarepartitii având unitati de masura diferite. Nu este folosit atunci când x sau µ este foartemic. Pentru doua populatii care au aceeasi deviatie standard, gradul de variatie a dateloreste mai mare pentru populatie ce are media mai mica.
cv =sx, coeficient de variatie,
• Amplitudinea (plaja de valori, range)Pentru un set de date, amplitudinea (en., range) este definita ca fiind diferenta dintrevaloarea cea mai mare si valoarea cea mai mica a datelor, i.e., xmax− xmin.
• Scorul zEste numarul deviatiilor standard pe care o anumita observatie, x, le are sub sau deasupramediei. Pentru o selectie x1, x2, . . . , xn, scorul X este definit astfel:
x =x− x
s.
• Corelatia (covarianta)Daca avem n perechi de observatii, (x1, y1), (x2, y2), . . . , (xn, yn), definim corelatia (cova-rianta):
cov(x,y) =1
n−1
n
∑i=1
(xi− x)(yi− y). (2.3.2)
• Coeficientul de corelatie
r =cov(x,y)
sxsy, coeficient de corelatie,
• Functia de repartitie empiricaSe numeste functie de repartitie empirica asociata unei variabile aleatoare X si uneiselectii x1, x2, . . . , xn, functia F∗n : R−→ [0, 1], definita prin
F∗n (x) =cardi; xi ≤ x
n. (2.3.3)
Propozitia de mai jos arata ca functia de repartitie empirica aproximeaza functia derepartitie teoretica (vezi Figura 2.14).
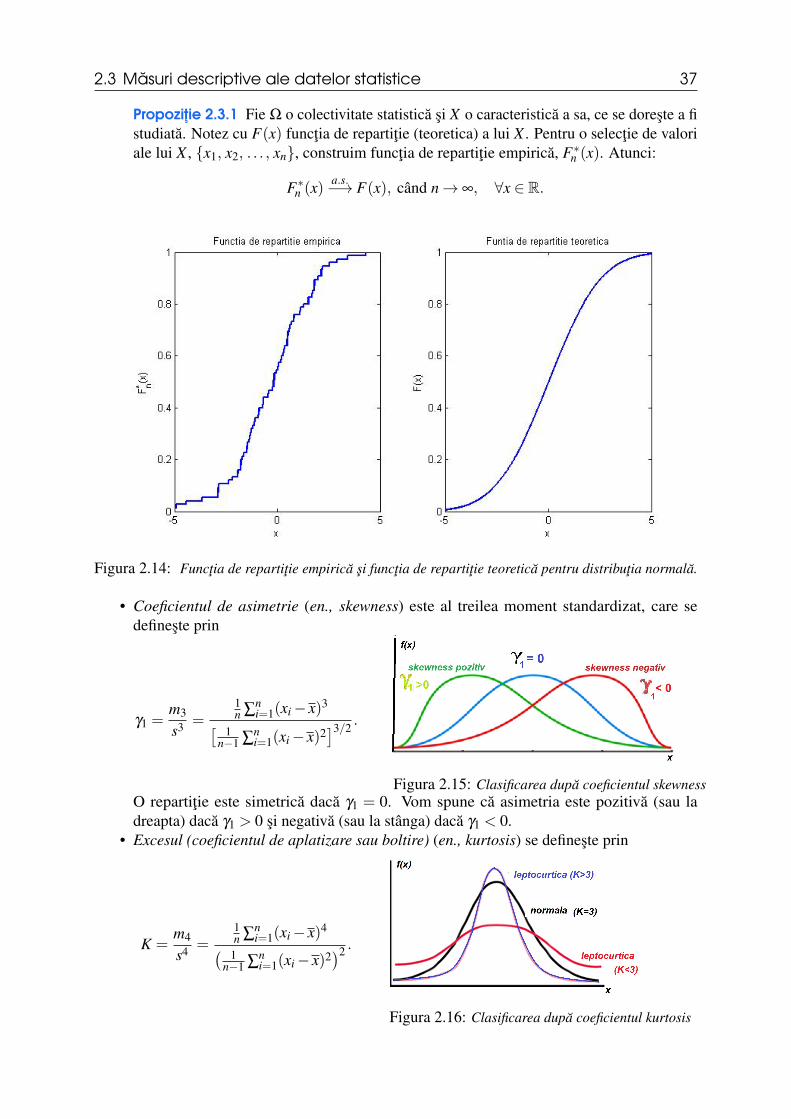
2.3 Masuri descriptive ale datelor statistice 37
Propozitie 2.3.1 Fie Ω o colectivitate statistica si X o caracteristica a sa, ce se doreste a fistudiata. Notez cu F(x) functia de repartitie (teoretica) a lui X . Pentru o selectie de valoriale lui X , x1, x2, . . . , xn, construim functia de repartitie empirica, F∗n (x). Atunci:
F∗n (x)a.s.−→ F(x), când n→ ∞, ∀x ∈ R.
Figura 2.14: Functia de repartitie empirica si functia de repartitie teoretica pentru distributia normala.
• Coeficientul de asimetrie (en., skewness) este al treilea moment standardizat, care sedefineste prin
γ1 =m3
s3 =1n ∑
ni=1(xi− x)3[ 1
n−1 ∑ni=1(xi− x)2
]3/2 .
Figura 2.15: Clasificarea dupa coeficientul skewnessO repartitie este simetrica daca γ1 = 0. Vom spune ca asimetria este pozitiva (sau ladreapta) daca γ1 > 0 si negativa (sau la stânga) daca γ1 < 0.
• Excesul (coeficientul de aplatizare sau boltire) (en., kurtosis) se defineste prin
K =m4
s4 =1n ∑
ni=1(xi− x)4( 1
n−1 ∑ni=1(xi− x)2
)2 .
Figura 2.16: Clasificarea dupa coeficientul kurtosis

38 Capitolul 2. Elemente de Statistica descriptiva
Este o masura a boltirii distributiei (al patrulea moment standardizat). Vom avea o repartitiemezocurtica pentru K = 3, leptocurtica pentru K > 3 sau platocurtica pentru K < 3. Unindice K > 3 semnifica faptul ca, în vecinatatea modului, curba densitatii de repartitie areo boltire (ascutire) mai mare decât clopotul lui Gauss. Pentru K < 3, în acea vecinatatecurba densitatii de repartitie este mai plata decât curba lui Gauss.În unele cazuri, în definitia excesului apare termenul −3, pentru a centra în 0 valoarea luiK pentru repartitia normala standard.
• CuantileCuantilele (de ordin q) sunt valori ale unei variabile aleatoare care separa repartitia ordonataîn q parti egale.Pentru q = 2, cuantila xq se numeste mediana, notata prin x0.5 sau me.Presupunem ca observatiile sunt ordonate, x1 < x2 < · · · < xn. Pentru aceasta ordine,definim valoarea mediana:
x0.5 =
x(n+1)/2 , daca n = impar;(xn/2 + xn/2+1)/2 , daca n = par;
Pentru q = 4, cuantilele se numesc cuartile (sunt în numar de 3). Prima cuartila, notatax0.25 sau q1, se numeste cuartila inferioara, a doua cuartila este mediana, iar ultimacuartila, notata x0.75 sau q3, se numeste cuartila superioara. Diferenta iqr = q3−q1 senumeste distanta intercuartilica.Pentru q = 10 se numesc decile (sunt în numar de 9), pentru q = 100 se numesc percentile(sau centile sunt în numar de 99), pentru q = 1000 se numesc permile (sunt în numar de999). Sunt masuri de pozitie, ce masoara locatia unei anumite observatii fata de restuldatelor.
• ModulModul (sau valoarea modala) este acea valoare x∗ din setul de date care apare cel maides. Un set de date poate avea mai multe module. Daca apar doua astfel de valori, atuncivom spune ca setul de date este bimodal, pentru trei astfel de valori avem un set de datetrimodal etc. În cazul în care toate valorile au aceeasi frecventa de aparitie, atunci spunemca nu exista mod. De exemplu, setul de date
1 3 5 6 3 2 1 4 4 6 2 5
nu admite valoare modala. Nu exista un simbol care sa noteze distinctiv modul unui set dedate.
• Valori extreme (sau aberante, en. outliers)Valorile extreme sunt valori statistice observate care sunt îndepartate de marea majoritate acelorlalte observatii. Ele pot aparea din cauza unor masuratori defectuoase sau în urmaunor erori de masurare. De cele mai multe ori, ele vor fi excluse din analiza statistica.Însa, sunt cazuri în care ele nu trebuie excluse, e.g., atunci când studiem daca un anumitparametru depaseste sau nu o valoare critica. Din punct de vedere matematic, valorileextreme sunt valorile care se afla în afara intervalului
[q1−1.5(q3−q1), q3 +1.5(q3−q1)]
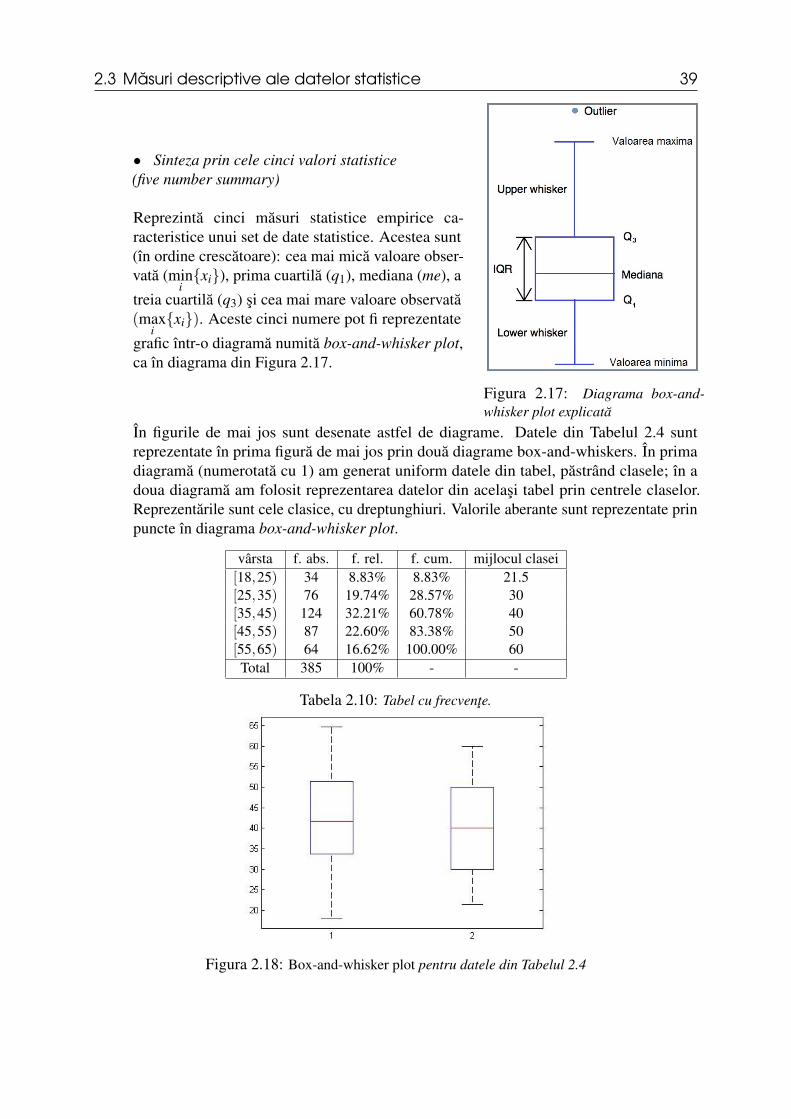
2.3 Masuri descriptive ale datelor statistice 39
• Sinteza prin cele cinci valori statistice(five number summary)
Reprezinta cinci masuri statistice empirice ca-racteristice unui set de date statistice. Acestea sunt(în ordine crescatoare): cea mai mica valoare obser-vata (min
ixi), prima cuartila (q1), mediana (me), a
treia cuartila (q3) si cea mai mare valoare observata(max
ixi). Aceste cinci numere pot fi reprezentate
grafic într-o diagrama numita box-and-whisker plot,ca în diagrama din Figura 2.17.
Figura 2.17: Diagrama box-and-whisker plot explicata
În figurile de mai jos sunt desenate astfel de diagrame. Datele din Tabelul 2.4 suntreprezentate în prima figura de mai jos prin doua diagrame box-and-whiskers. În primadiagrama (numerotata cu 1) am generat uniform datele din tabel, pastrând clasele; în adoua diagrama am folosit reprezentarea datelor din acelasi tabel prin centrele claselor.Reprezentarile sunt cele clasice, cu dreptunghiuri. Valorile aberante sunt reprezentate prinpuncte în diagrama box-and-whisker plot.
vârsta f. abs. f. rel. f. cum. mijlocul clasei[18,25) 34 8.83% 8.83% 21.5[25,35) 76 19.74% 28.57% 30[35,45) 124 32.21% 60.78% 40[45,55) 87 22.60% 83.38% 50[55,65) 64 16.62% 100.00% 60
Total 385 100% - -
Tabela 2.10: Tabel cu frecvente.
Figura 2.18: Box-and-whisker plot pentru datele din Tabelul 2.4

40 Capitolul 2. Elemente de Statistica descriptiva
În Figura 2.19, am reprezentat cu box-and-whisker un set de date discrete ce continedoua valori aberante. Aici dreptunghiul afost crestat (notched box-and whisker plot);lungimea crestaturii oferind un interval deîncredere pentru mediana. Valorile aberantesunt reprezentate in figura prin puncte in afararange-ului datelor.
Figura 2.19: Box-and-whisker plot pentru un set dedate discrete
. Q: What did the box-and-whisker plot say to the outlier?
. A: "Don’t you dare get close to my whisker!!"
2.3.2 Date grupateConsideram un set de date statistice grupate (de volum n), ce reprezinta observatii asupravariabilei X . Pentru o selectie cu valorile de mijloc x1, x2, . . . , xr si frecventele absolute
corespunzatoare, f1, f2, . . . , fr, cur
∑i=1
fi = n, definim:
x f =1n
r
∑i=1
xi fi, media (empirica) de selectie, (sau, media ponderata)
s2f =
1n−1
r
∑i=1
fi(xi− x f )2 =
1n−1
(r
∑i=1
x2i fi−n x2
f
), dispersia (varianta) empirica,
s f =√
s2f , deviatia empirica standard.
Formule similare se pot da si pentru masurile descriptive ale întregii populatii.mediana pentru un set de date grupate este acea valoare ce separa toate datele în doua parti egale.Se determina mai întâi clasa ce contine mediana (numita clasa mediana), apoi presupunem caîn interiorul fiecarei clase datele sunt uniform distribuite. O formula dupa care se calculeazamediana este:
me = l +n2 −Fme
fmec,
unde: l este limita inferioara a clasei mediane, n este volumul selectiei, Fme este suma frecventelorpâna la (exclusiv) clasa mediana, fme este frecventa clasei mediane si c este latimea clasei.Similar, formulele pentru cuartile sunt:
q1 = l1 +n4 −Fq1
fq1
c si q3 = l3 +3n4 −Fq3
fq3
c,
unde l1 si l3 sunt valorile inferioare ale intervalelor in care se gasesc cuartilele respective, iar FQeste suma frecventelor pâna la (exclusiv) clasa ce contine cuartila, fQ este frecventa clasei undese gaseste cuartila.

2.4 Transformari de date 41
Pentru a afla modul unui set de date grupate, determinam mai întâi clasa ce contine aceastavaloare (clasa modala), iar modul va fi calculat dupa formula:
mo = l +d1
d1 +d2c,
unde d1 si d2 sunt frecventa clasei modale minus frecventa clasei anterioare si, respectiv, frecventaclasei modale minus frecventa clasei posterioare, l este limita inferioara a clasei modale si c estelatimea clasei modale.
2.4 Transformari de date
Uneori valorile masurate nu sunt normale si este necesara o transformare a lor pentru a obtinevalori apropiate de normalitate. Transformarile uzuale sunt: logaritmarea valorilor observate(folosind functiile ln sau log10, daca valorile sunt toate pozitive), radacina patrata a valorilor,transformarea Box-Cox, transformarea logit, radacini de ordin superior etc. In Tabelul 2.11 amsugerat tipul de transformare ce poate fi utilizat in functie de coeficientul de skewness γ1.
În ce conditii. . . skewness formuladate aproape simetrice −0.5 < γ1 < 0.5 nicio transformareskewness moderat pozitiv, date nenegative 0.5≤ γ1 < 1 yi =
√xi
skewness moderat pozitiv, exista date < 0 0.5≤ γ1 < 1 yi =√
xi +Cskewness moderat negativ −1 < γ1 ≤ 0.5 yi =
√C− xi
skewness mare negativ γ1 ≤−1 yi = ln(C− xi)skewness mare pozitiv, date pozitive γ1 ≥ 1 yi = lnxiskewness mare pozitiv, exista date ≤ 0 γ1 ≥ 1 yi = ln(xi +C)
Tabela 2.11: Exemple de transformari de date statistice
Aici, C > 0 este o constanta ce poate fi determinata astfel incat datele transformate sa aibaun skewness cat mai aproape de 0. Aceasta constanta va fi aleasa astfel incat functia ce facetransformarea este definita. În loc de functia ln se poate folosi si logaritmul în alta baza, e.g.,functia log10.De exemplu, presupunem ca datele observate sunt x1, x2, . . . , xn si acestea nu sunt toate pozitive,cu un coeficient de asimetrie (skewness) γ1 = 1.3495. Ne uitam la valoarea minima a datelor;aceasta este xmin =−0.8464. Pentru a obtine un set de valori pozitive, vom adauga valoarea 1la toate datele observate. Apoi, logaritmam valorile obtinute. Cele doua procedee cumulatesunt echivalente cu folosirea directa a formulei ln(1+ xi) (adunand valoarea 1, am facut toateargumentele logaritmului pozitive). Obtinem astfel un nou set de date, si anume y1, y2, . . . , yn,unde yi = ln(1+ xi). Un exemplu este cel din Figura 2.20. Se observa ca datele logaritmate suntaproape normale. O analiza statistica poate fi condusa pentru datele yi, urmand ca, eventual, lafinal sa aplicam transformarea inversa xi = eyi−1 pentru a transforma rezultatele pentru dateleinitiale.
42 Capitolul 2. Elemente de Statistica descriptiva
Figura 2.20: Datele intiale si datele logaritmate
Dupa transformarea datelor si analiza datelor transformate (de exemplu, prezicerea valorilorin punctele neselectate), de multe ori este necesara transformarea inversa a datelor, pentru adetermina proprietatile datelor originale. De aceea, ar fi potrivit de a exprima indicatorii statisticiatat pentru datele transformate, cat si pentru datele originale. Un exemplu este cel din Tabelul2.12.
Indicatorul datele originale datele tranformatexi yi = ln(1+ xi)
Minimum −0.8464 −1.8734Maximum 14.1107 2.7154media 6.02142 1.51Cuartila q1 3.1152 0.6532mediana 6.5200 1.2512Cuartila q3 8.7548 1.5785Deviatia standard 5.2511 0.7524Dispersia 27.5741 0.5661Skewness 6.2322 0.0233Kurtosis 78.6077 2.9786Numarul de observatii 100 100χ2 pentru testul de normalitate (7 grade de libertate) − 7.1445
Tabela 2.12: Exemplu de indicatori pentru datele originale si pentru datele transformate
2.5 Exercitii rezolvateExercitiu 2.5.1 Urmatorul set de date reprezinta preturile (în mii de euro) a 20 de case, vânduteîntr-o anumita regiune a unui oras:
113 60.5 340.5 130 79 475.5 90 100 175.5 100
111.5 525 50 122.5 125.5 75 150 89 100 70
(a) Determinati amplitudinea, media, mediana, modul, deviatia standard, cuartilele si distantaintercuartilica pentru aceste date. Care valoare este cea mai reprezentativa?

2.5 Exercitii rezolvate 43
(b) Desenati diagrama box-and-whiskers si comentati-o. Exista valori aberante?(c) Calculati coeficientii de asimetrie si de aplatizare.
R: Rearanjam datele în ordine crescatoare:
50 60.5 70 75 79 89 90 100 100 100 111.5
113.5 122.5 125.5 130 150 175.5 340.5 475.5 525
Amplitudinea este 525−50 = 475, media lor este
154.15, mediana este100+111.5
2= 105.75,
modul este 100, cuartila inferioara este
q1 =79+89
2= 84, q2 = me, cuartila supe-
rioara este q3 =130+150
2= 140 si distanta
intercuartilica este d = q3−q1 = 56.mediana este valoarea cea mai reprezentativa înacest caz, deoarece cele mai mari trei preturi,anume 340.5, 475.5, 525, maresc media si o facmai putin reprezentativa pentru celelalte date. Încazul în care setul de date nu este simetric, valoareamediana este cea mai reprezentativa valoare adatelor.
Figura 2.21: box-and-whisker plot pentrudatele din Exercitiul 2.5.1
Deviatia standard este s =
√1
n−1
n
∑i=1
(xi− x)2 = 133.3141. Folosind formulele, gasim ca γ1 =
1.9598 (asimetrie la dreapta) si K = 5.4684 (boltire pronuntata). Valorile aberante sunt cele cese afla in afara intervalului
[q1−1.5(q3−q1), q3 +1.5(q3−q1)] = [0, 224].
Se observa ca valorile 340.5,475.5 si 525 sunt valori aberante, reprezentate prin puncte in figura.Exercitiu 2.5.2 Consideram datele din Tabelul 2.5.(a) Determinati amplitudinea, media, mediana, modul, dispersia si distanta intercuartilica pentruaceste date.(b) Desenati diagrama box-and-whiskers si comentati-o. Exista valori aberante?
R: Amplitudinea este a = 30. Folosind centrele claselor, media este
x =∑(x · f )
n=
170
(2.5 ·5+7.5 ·13+12.5 ·23+17.5 ·17+22.5 ·10+27.5 ·2) = 13.9286.
Dispersia este:
s2 =1
n−1(∑(x2 · f )−n · x2)
=1
69(2.52 ·5+7.52 ·13+12.52 ·23+17.52 ·17+22.52 ·10+27.52 ·2 − 70 ·13.92862)
= 37.06.

44 Capitolul 2. Elemente de Statistica descriptiva
Clasa mediana este clasa [10, 15). Deoarece în clasele anterioare ([0, 5) si [5, 10)) se afla deja5+13 = 18 date mai mici decât mediana, pentru a afla valoarea mediana a plantelor (i.e., aceavaloare care este mai mare decât alte 35 de valori la stanga ei si mai mica decât alte 35 de plantede la dreapta sa), va trebui sa determinam acea valoare din clasa mediana ce este mai mare decâtalte 17 valori din aceasta clasa. Asadar, avem nevoie de a determina o fractie 17
23 dintre valorileclasei mediane. În concluzie, valoarea mediana este
me = 10+35−18
23×5 = 13.6957.
Clasa modala este [10, 15), iar modul este mo = 10+ 1010+6 ×5 = 13.125.
Calculam acum prima cuartila dupa formula q1 = l1 +n4 −Fq1
fq1
× c. Clasa in care se gaseste
prima cuartila este [5, 10) (o valoare din acest interval va avea la stanga sa 70/4 dintre valorileobservate). Avem: Fq1 = 5, fq1 = 13, c = 5, de unde q1 = 9.8077.Similar, clasa in care se gaseste a treia cuartila este [15, 20) (o valoare din acest interval va aveala dreapta sa 70/4 dintre valori. Avem: Fq3 = 41, fq3 = 10, c = 5, de unde q3 = 18.3824.Exercitiu 2.5.3 O companie de asigurari a înregistrat numarul de accidente pe saptamâna ce auavut loc într-un anumit sat, în decurs de un an (52 de saptamâni). Acestea sunt, în ordine:
1, 0, 2, 3, 4, 1, 4, 0, 4, 2, 3, 0, 3, 3, 1, 2, 3, 0, 1, 2, 3, 1, 3, 2, 3, 2
4, 3, 4, 2, 3, 4, 4, 3, 2, 4, 1, 2, 0, 1, 3, 2, 0, 4, 1, 0, 2, 2, 4, 1, 2, 2
(a) Construiti un tabel de frecvente care sa contina numarul de accidente, frecventele absolute sirelative.(b) Gasiti media empirica, mediana si deviatia standard empirica.(c) Reprezentati prin bare rezultatele din tabelul de frecvente.(d) Gasiti si reprezentati grafic (cdfplot) functia de repartitie empirica a numarului de accidente.
R: (a) Tabelul de frecvente este Tabelul 2.13. (b) Avem:
numarul 0 1 2 3 4frecv. abs. 7 9 14 12 10frecv. rel. 0.1346 0.1731 0.2692 0.2308 0.1923
Tabela 2.13: Tabel de frecvente pentru Exercitiu 2.5.3
x =1
52
52
∑i=1
xi = 2.1731, s =
√√√√ 151
52
∑i=1
(xi− x)2 = 1.3094, me = 2.
(c) Reprezentarea prin bare a numarului de accidente si graficul lui F∗n (x) sunt reprezentate înFigura 2.22.
2.6 Exercitii propuse 45
(d) Functia de repartitie empirica este:
F∗n (x) =
0, daca x < 0;7
52 , daca x ∈ [0, 1);1652 , daca x ∈ [1, 2);3052 , daca x ∈ [2, 3);4252 , daca x ∈ [3, 4);1, daca x≥ 4.
Figura 2.22: Reprezentarea numarului de accidente
2.6 Exercitii propuseExercitiu 2.6.1 Pentru un set de 5 valori, media empirica este x = 50 si dispersia empirica estes2 = 4. Daca trei dintre valori sunt 48, 51, 52, determinati si celelalte doua valori.Exercitiu 2.6.2 Într-o scoala, 2
5 dintre elevi studiaza limba engleza, 14 dintre elevi studiaza limba
germana, 15 dintre elevi studiaza limba franceza, iar restul elevilor studiaza alte limbi. Desenati
un grafic potrivit pentru a ilustra aceste informatii.Exercitiu 2.6.3 Se considera urmatoarea selectie de note obtinute de elevii unei scoli la teza deMatematica.
5, 7, 8, 6, 9, 7, 10, 4, 7, 9, 6, 5, 7, 8, 7
6, 10, 8, 6, 9, 4, 7, 5, 8, 8, 7, 5, 4, 8, 6
(a) Determinati media, deviatia standard si mediana pentru aceasta selectie.(b) Grupati datele si scrieti functia de repartitie empirica.(c) Reprezentati un box-and-whisker plot pentru date.Exercitiu 2.6.4 Pentru evaluarea rezultatelor obtinute la proba de Matematica a examenului deBacalaureat de catre elevii unei scoli, s-a facut un sondaj de volum 30 printre elevii scolii, notelefiind urmatoarele:
3.72 7.45 4.65 6.95 5.00 4.30 8.93 7.14 8.24 6.67
9.33 9.05 5.86 6.75 7.20 7.28 6.65 5.90 7.75 4.33
7.18 8.00 5.50 7.70 4.12 8.40 7.00 6.90 5.00 7.80
(a) Descrieti datele folosind o reprezentare stem& leaf.(b) Calculati media, dispersia si mediana pentru selectia considerata, precizând formulelefolosite.(c) Determinati cele cinci masuri statistice din five number summary(d) Reprezentati un box-and-whisker plot pentru date.(e) Ionel a obtinut nota 8.45 la examen. Determinati scorul sau.Exercitiu 2.6.5 Tabelul de mai jos contine notele la Matematica a 10 elevi dintr-o anumita scoalaobtinute la: testul de simulare a examenului de Bacalaureat (T) si la examenul Bacalaureat (B).
T 6.15 5.75 8.45 8.90 7.83 6.50 10 4.50 9.25 7.65B 7.23 6.00 7.76 9.63 6.90 6.33 9.90 3.24 8.67 7.90

46 Capitolul 2. Elemente de Statistica descriptiva
(a) Reprezentati cele doua seturi de date prin câte un box-and-whisker plot, în aceeasi figura.(b) Reprezentati datele din tabel printr-o diagrama scatter.(c) Calculati coeficientul de corelatie empirica între T si B si comentati rezultatul.
Exercitiu 2.6.6 Tabelul alaturat contine repartitia pe grupe de vârstasi gen a unei selectii aleatoare de 385 de someri dintr-o anumita regiunea tarii.(a) Calculati vârsta medie si deviatia standard pentru selectia data.(b) Aflati mediana, modul si quartilele pentru selectia data.(c) Reprezentati datele prin bare si sectoare de disc.(d) Construiti diagrama box-and-whiskers pentru acest set de date.
vârsta frecventa[18,25) 34[25,35) 76[35,45) 124[45,55) 87[55,65) 64
Exercitiu 2.6.7 Consideram diagrama stem-and-leaf din Figura 2.3. Raspundeti la urmatoarelecerinte:(a) Aflati cuartilele si distanta interquartilica;(b) Exista valori extreme pentru acest set de date?(c) Construiti diagrama box-and-whiskers pentru acest set de date;(d) Care este valoarea maxima cu care putem înlocui cea mai mica observatie fara a afectavaloarea primei cuartile?Exercitiu 2.6.8O companie foloseste doua masini pentru a producebatoane de ciocolata. Pentru a controla calibrareamasinilor, au fost alese aleator câte 30 de batoane deciocolata produse de fiecare masina. Datele rezultate înurma cântaririi acestor batoane sunt reprezentate graficîn diagrama alaturata. Comparati si comentati datele dincele doua esantioane.
Exercitiu 2.6.9 Tabelul 6.2 contine distributia nu-marului de goluri înscrise într-un meci la campio-natul mondial de fotbal din 2006.(a) Determinati cuartilele pentru aceste date.(b) Desenati o diagrama box-and-whisker pentrudate.(c) Care este probabilitatea ca, într-un meci alesaleator, numarul de goluri marcate sa fie mai micdecât ultima cuartila?
Nr. de goluri pe meci Nr. de meciuri0 81 132 183 114 105 26 2
Tabela 2.14: Tabel cu numarul de goluripe meci la FIFA WC 2006
Exercitiu 2.6.10 Un grup de persoane au participat la un studiustatistic. Vârstele participantilor sunt înregistrate în tabeluldalaturat.(a) Valoarea mediana este 42. Determinati valoarea lui x.(b) Desenati o diagrama box-and-whisker pentru date.(c) Aflati vârsta medie a participantilor la studiu ce au cel putin45 de ani.
Vârsta Frecventa[18, 25) 10[25, 35) 39[35, 45) x[45, 55) 53[55, 65) 21[65, 75) 7
Tabela 2.15: Tabel cu vârste
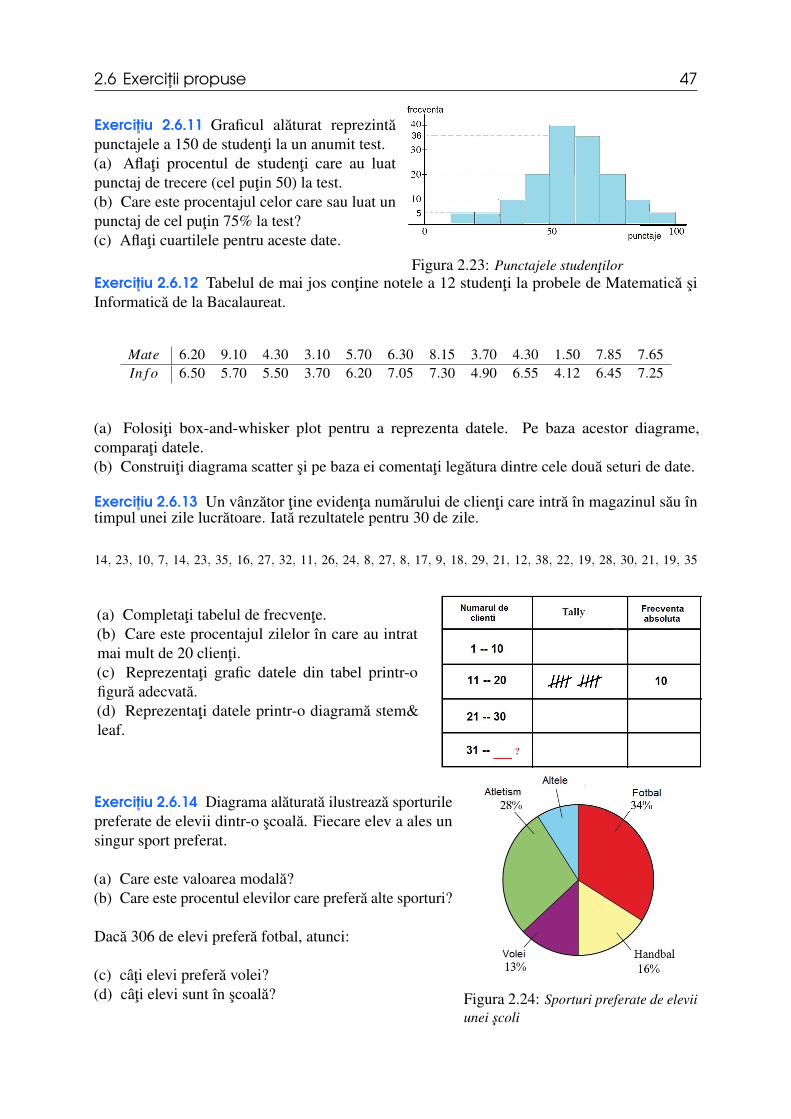
2.6 Exercitii propuse 47
Exercitiu 2.6.11 Graficul alaturat reprezintapunctajele a 150 de studenti la un anumit test.(a) Aflati procentul de studenti care au luatpunctaj de trecere (cel putin 50) la test.(b) Care este procentajul celor care sau luat unpunctaj de cel putin 75% la test?(c) Aflati cuartilele pentru aceste date.
Figura 2.23: Punctajele studentilorExercitiu 2.6.12 Tabelul de mai jos contine notele a 12 studenti la probele de Matematica siInformatica de la Bacalaureat.
Mate 6.20 9.10 4.30 3.10 5.70 6.30 8.15 3.70 4.30 1.50 7.85 7.65In f o 6.50 5.70 5.50 3.70 6.20 7.05 7.30 4.90 6.55 4.12 6.45 7.25
(a) Folositi box-and-whisker plot pentru a reprezenta datele. Pe baza acestor diagrame,comparati datele.(b) Construiti diagrama scatter si pe baza ei comentati legatura dintre cele doua seturi de date.
Exercitiu 2.6.13 Un vânzator tine evidenta numarului de clienti care intra în magazinul sau întimpul unei zile lucratoare. Iata rezultatele pentru 30 de zile.
14, 23, 10, 7, 14, 23, 35, 16, 27, 32, 11, 26, 24, 8, 27, 8, 17, 9, 18, 29, 21, 12, 38, 22, 19, 28, 30, 21, 19, 35
(a) Completati tabelul de frecvente.(b) Care este procentajul zilelor în care au intratmai mult de 20 clienti.(c) Reprezentati grafic datele din tabel printr-ofigura adecvata.(d) Reprezentati datele printr-o diagrama stem&leaf.
Exercitiu 2.6.14 Diagrama alaturata ilustreaza sporturilepreferate de elevii dintr-o scoala. Fiecare elev a ales unsingur sport preferat.
(a) Care este valoarea modala?(b) Care este procentul elevilor care prefera alte sporturi?
Daca 306 de elevi prefera fotbal, atunci:
(c) câti elevi prefera volei?(d) câti elevi sunt în scoala? Figura 2.24: Sporturi preferate de elevii
unei scoli
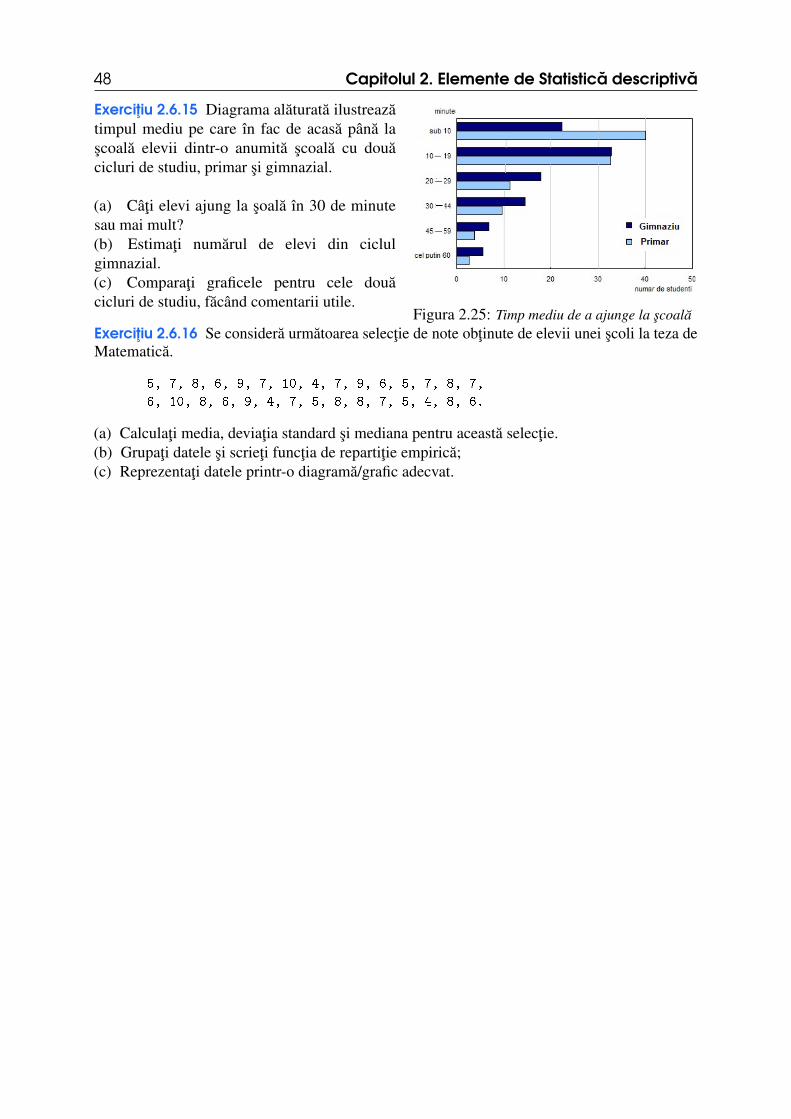
48 Capitolul 2. Elemente de Statistica descriptiva
Exercitiu 2.6.15 Diagrama alaturata ilustreazatimpul mediu pe care în fac de acasa pâna lascoala elevii dintr-o anumita scoala cu douacicluri de studiu, primar si gimnazial.
(a) Câti elevi ajung la soala în 30 de minutesau mai mult?(b) Estimati numarul de elevi din ciclulgimnazial.(c) Comparati graficele pentru cele douacicluri de studiu, facând comentarii utile.
Figura 2.25: Timp mediu de a ajunge la scoalaExercitiu 2.6.16 Se considera urmatoarea selectie de note obtinute de elevii unei scoli la teza deMatematica.
5, 7, 8, 6, 9, 7, 10, 4, 7, 9, 6, 5, 7, 8, 7,
6, 10, 8, 6, 9, 4, 7, 5, 8, 8, 7, 5, 4, 8, 6.
(a) Calculati media, deviatia standard si mediana pentru aceasta selectie.(b) Grupati datele si scrieti functia de repartitie empirica;(c) Reprezentati datele printr-o diagrama/grafic adecvat.

3. Notiuni din Teoria selectiei statistice
3.1 Introducere
Definitie 3.1.1 Numim colectivitate statistica (sau populatie) o multime nevida Ω de elementecare este cercetata din punct de vedere al uneia sau mai multor caracteristici. Elementelecolectivitatii le vom numi indivizi (sau unitati statistice). Vom nota cu ω o unitate statistica.Daca populatia este finita, atunci numarul N al unitatilor statistice ce o compun (i.e., card(Ω)= N)îl vom numi volumul colectivitatii (sau volumul populatiei).Consideram o populatie (colectivitate statistica) Ω. Studiem populatia Ω din punctul de vedereal unei caracteristici a sale, X . Aceasta caracteristica este o anumita proprietate urmarita laindivizii ei în procesul prelucrarii statistice si o vom asimila cu o variabila aleatoare definita peΩ. Problema esentiala a Statisticii Matematice este de a stabili legea de probabilitate pe careo urmeaza caracteristica X . Pentru a gasi aceasta lege (repartitie), avem nevoie mai întâi deun numar reprezentativ de observatii asupra colectivitatii Ω. Pe baza acestor observatii, vomdetermina prin inferenta o lege care sa reprezinte variabila X .Definitie 3.1.2 Vom numi selectie (sau esantion, sondaj) o subcolectivitate a colectivitatiicercetate Ω. Numarul elementelor selectiei poarta numele de volumul selectiei (esantionului).Selectiile pot fi repetate sau nerepetate. O selectie se numeste repetata (sau bernoulliana) dacadupa examinarea individului acesta se reintroduce în colectivitate; în caz contrar avem o selectienerepetata. În practica, volumul colectivitatii Ω este mult mai mare decât volumul selectiei. Înaceste cazuri, selectia nerepetata poate fi considerata ca fiind selectie repetata. Selectiile pe carele vom considera în continuare sunt numai selectii repetate din colectivitatea statistica.
Dorim acum sa introducem un cadru matematic abstract pentru aceste selectii repetate (pentru oabordare mai detaliata, se poate consulta [14]).
Consideram spatiul masurabil (Ω, F ), unde F este o σ−algebra (o submultime a lui P(Ω)ce contine pe Ω si este închisa la complementariere si la reuniune numarabila). CaracteristicaX urmarita poate fi reprezentata de o variabila aleatoare definita pe (Ω, F ). Dorim sa definim

50 Capitolul 3. Notiuni din Teoria selectiei statistice
matematic o selectie repetata de volum n. Euristic, ideea este urmatoarea: a efectua n selectiirepetate dintr-o multime Ω, este echivalent cu a considera o singura selectie dintr-o populatie degenul "Ω multiplicat de n ori". Construim astfel:
Ω(n) = Ω×Ω×·· ·×Ω, F (n) = F ×F ×·· ·×F ,
produs cartezian de n ori. Un element al lui Ω(n) va fi
ω(n) = (ω1, ω2, . . . , ωn),
numita selectie repetata de volum n. Cuplul (Ω(n), F (n)) se numeste spatiul selectiilor repetatede volum n. Consideram variabilele aleatoare
Xi : Ω(n)→ R, Xi(ω
(n)) = X(ωi), ∀i = 1, n.
Acestea sunt variabile aleatoare definite pe (Ω(n), F (n)), sunt independente stochastic (pentruca v.a. X(ωi)i=1,2, ...,n sunt independente) si sunt identic repartizate, cu functia de repartitiecomuna FX (se verifica usor ca FXi = FX , ∀i = 1, 2, . . . , n). Vom numi Xi, i = 1, 2, . . . , n,variabile aleatoare de selectie repetata de volum n. Vom numi vector de selectie repetata devolum n, vectorul Y , astfel încât:
Y : Ω(n)→ R, Y (ω(n)) = (X1(ω
(n)), X2(ω(n)), . . . , Xn(ω
(n))).
Pentru un ω(n) fixat, componentele vectorului Y (ω(n)) se numesc valori de selectie repetata devolum n. Vom nota cu
Ln = Y (Ω(n))⊂ Rn,
si-l vom numi spatiul valorilor de selectie repetata de volum n. Elementele lui Ln le vom notaprin
x = (x1, x2, . . . , xn),
(xi = Xi(ω(n)), pentru ω(n) fixat, i = 1, 2, . . . , n).
Definitie 3.1.3 Vom numi statistica (sau functie de selectie) variabila aleatoare
Sn(X) = g(X1, X2, . . . , Xn),
unde g este o functie g : Rn→R masurabila (echivalent cu ∀B deschis în R, g−1(B) este deschisîn Rn).Ca o observatie, numele de "statistica" este folosit în literatura de specialitate atât pentruvariabila aleatoare de mai sus, cât si pentru valoarea ei, întelesul exact desprinzându-se dincontext. Repartitia unei statistici se mai numeste si repartitia (distributia) de selectie.
Notatie 3.1.1 În literatura, pentru o statistica se foloseste una dintre urmatoarele notatii:
Sn(X), S(X , ω(n)), S(X , n), S(X1, X2, . . . , Xn), S(X).
(sau cu alte litere specifice, în loc de S).Valoarea numerica
Sn(x) = g(x1, x2, . . . , xn)
se numeste valoarea functiei de selectie pentru un ω(n) fixat.

3.1 Introducere 51
Observatie 3.1.1 Asadar, o statistica este o functie de variabilele aleatoare de selectie. Prinintermeniul statisticilor putem trage concluzii despre populatia Ω, din care a provenit esantionulω(n). Teoria probabilitatilor ne ofera procedee de determinare atât a repartitiei exacte a lui Sn(X),cât si a repartitiei asimptotice a lui Sn(X). Repartitia exacta este acea repartitie ce poate fideterminata pentru orice volum al selectiei. În general, daca se lucreaza cu selectii de volumredus (n < 30), atunci repartitia exacta ar trebui sa fie cunoscuta a priori, daca se doreste luareade decizii prin inferenta. Repartitia asimptotica este repartitia limita a Sn(X) când n→ ∞, iarutilizarea acesteia conduce la rezultate bune doar pentru n≥ 30.De cele mai multe ori, o functie de selectie (statistica) este utilizata în urmatoarele cazuri:
• în probleme de estimare punctuala a parametrilor;• în obtinerea intervalelor de încredere pentru un parametru necunoscut;• ca o statistica test pentru verificarea ipotezelor statistice.
3.1.1 Statistici uzualeFie (Ω, F ) o colectivitate statistica si X o caracteristica cercetata a sa. Sa notam cu f (x) si F(x)densitatea de repartitie (sau functia de probabilitate), respectiv, functia de repartitie pentru X .Acestea pot fi cunoscute sau necunoscute a priori si le vom numi functii teoretice (densitate derepartitie teoretica, functie de probabilitate teoretica sau functie de repartitie teoretica). Daca secunoaste f (x), atunci putem determina µ = E(X) si σ2 =Var(X), daca acestea exista, si le vomnumi medie teoretica si dispersie teoretica.În cazul în care una sau mai multe caracteristici teoretice corespunzatoare lui X nu ne sunt apriori cunoscute, vom cauta sa le determinam prin inferenta, adica prin extragerea unor selectiide date din colectivitate, calculând caracteristicile respective pentru selectiile considerate si apoiextrapolând (în anumite conditii si dupa anumite criterii) la întreaga colectivitate.
Sa consideram ω(n) o selectie repetata de volum n din colectivitatea data si Xi, i = 1, n,variabilele aleatoare de selectie. Cu ajutorul acestora, putem construi diverse functii de selectie.
1. Media de selectie
Definitie 3.1.4 Numim medie de selectie (repetata de volum n), statistica
X(ω(n)) =1n
n
∑i=1
Xi(ω(n)), ω
(n) ∈Ω(n). (3.1.1)
Pentru un ω(n) fixat, sa notam cu x1, x2, . . . , xn valorile de selectie corespunzatoare variabileloraleatoare de selectie X1, X2, . . . , Xn. Atunci valoarea mediei de selectie pentru un ω(n) fixateste:
x =1n
n
∑i=1
xi (media empirica).
Propozitie 3.1.1 Media de selectie satisface urmatoarele proprietati:
1. E(X) = µ, Var(X) =σ2
n,
2.1n
n
∑i=1
Xia.s.−→ µ, când n→ ∞.

52 Capitolul 3. Notiuni din Teoria selectiei statistice
Demonstratie.
E(X) = E
(1n
n
∑i=1
Xi
)=
1n
n
∑i=1
E(Xi) = E(X) = µ.
Var(X) =Var
(1n
n
∑i=1
Xi
)i.s.=
1n2
n
∑i=1
Var(Xi) =Var(X)
n=
σ2
n.
2. Convergenta este o consecinta imediata a legii tari a numerelor mari.
Observatie 3.1.2 (1) În capitolele urmatoare vom scrie relatia (3.1.1) sub forma restrânsa:
X =1n
n
∑i=1
Xi.
Pentru simplitatea formulelor, de acum înainte vom face abstratie de dependenta de ω(n) înformule, care se va subîntelege.(2) Propozitia 3.3.2 precizeaza care este repartitia mediei de selectie pentru variabile aleatoarede selectie dintr-o colectivitate normala, iar Propozitia 3.3.4 precizeaza care este repartitiaasimptotica a mediei de selectie pentru variabile de selectie într-o colectivitate oarecare.(3) Valoarea
σX =σ√
nse mai numeste si eroarea standard a mediei de selectie. Daca selectia se face dintr-o populatiede volum comparabil cu cel al populatiei (n > 0.05N), atunci ipoteza de selectie fara repetitie nuva mai fi valida. În acest caz, un termen de corectie se aplica pentru eroarea standard si scriem:
σX =σ√
n
√N−nN−1
.
Atunci când n N, atunci√
N−nN−1 ≈ 1 si obtinem formula anterioara.
2. Dispersia de selectie
Definitie 3.1.5 Numim dispersie de selectie (repetata de volum n), statistica
Var(X ,ω(n)) =1n
n
∑i=1
[Xi(ω(n))−X(ω(n))]2.
Pentru simplitate, o vom nota cu Var(X) (sau Var), iar valoarea acesteia pentru un ω(n) fixateste:
d2(x) =1n
n
∑i=1
[xi− x]2 (dispersia empirica)
De cele mai multe ori, în locul lui Var(X) se utilizeaza statistica S2(X), definita prin:
S2(X) =1
n−1
n
∑i=1
[Xi−X ]2.
Aceasta se mai numeste si dispersie de selectie modificata, iar valoarea ei pentru un ω(n) fixateste:
s2 = S2(x) =1
n−1
n
∑i=1
[xi− x]2 (dispersia empirica modificata)

3.1 Introducere 53
Propozitia 3.3.11 precizeaza care este repartitia statisticii S2.În continuare, daca nu este dubiu în ce priveste caracteristica X , vom folosi notatia simplificataS2 în loc de S2(X).
Propozitie 3.1.2 Dispersiile de selectie verifica urmatoarele relatii:
E(Var(X)) =n−1
nσ
2, E(S2) = σ2,
Var(X)a.s.−→ σ
2, S2 a.s.−→ σ2, când n→ ∞.
Demonstratie. Notam cu µ = E(X). Avem ca:
E(Var(X)) = E
(1n
n
∑i=1
(Xi−X)2
)=
1nE
(n
∑i=1
(Xi−µ +µ−X)2
)
=1nE
(n
∑i=1
(Xi−µ)2−2(X−µ)n
∑i=1
(Xi−µ)+n
∑i=1
(X−µ)2
)
=1n
[n
∑i=1
E[(Xi−µ)2]−2nE
[(X−µ)2]+nE
[(X−µ)2]]
=1n
[nE[(X−µ)2]−nE
[(X−µ)2]]= 1
n
[nVar(X)−nVar(X)
]= Var(X)− Var(X)
n=
n−1n
Var(X).
E(S2) = σ2 se arata la fel. Pentru convergenta, vezi Exercitiul (3.4.2).
Observatie 3.1.3 (i) Statistica S =√
S2 se numeste deviatie standard de selectie. Valoarea sapentru o selectie data este deviatie standard empirica, data de s =
√s2.
(ii) Dupa cum vom vedea în capitolul urmator, primele doua relatii arata ca statistica S2(X)este un estimator nedeplasat pentru dispersia teoretica, pe când Var(X) este estimator deplasat.Asadar, se poate spune ca, pentru selectii de volum mic, statistica S2 ofera o aproximare maibuna pentru dispersie decât ofera statistica Var, de aceea S2 este mai des utilizat în practica.Totusi, daca volumul selectiei este mare, atunci diferentele dintre valorile celor doua statisticisunt mici.(iii) Daca media teoretica a colectivitatii este cunoscuta a priori, E(X) = µ ∈R, atunci dispersiade selectie Var(X) devine:
D2(X) =1n
n
∑i=1
[Xi−µ]2.
Propozitia 3.3.8 precizeaza care este repartitia acestei statistici.
3. Functia de repartitie de selectie
Definitie 3.1.6 Fie X1, X2, . . . , Xn variabile aleatoare de selectie repetata de volum n. Numimfunctie de repartitie de selectie (repetata de volum n), functia
F∗n : R×Ω(n)→ [0, 1], F∗n (x, ω
(n)) =n(x)
n, ∀(x, ω
(n)) ∈ R×Ω(n),

54 Capitolul 3. Notiuni din Teoria selectiei statistice
unde n(x) = card i, Xi(ω(n)) ≤ x reprezinta numarul de elemente din selectie mai mici sau
egale cu x. Relatia din definitie poate fi scrisa si sub forma:
F∗n (x) =1n
n
∑i=1
χ(−∞,x](Xi), ∀x ∈ R, (3.1.2)
unde χA este functia indicatoare a multimii A.Pentru un x ∈ R fixat, nF∗n (ω
(n)) este o variabila aleatoare repartizata binomial B(n, F(x)).Pentru fiecare ω(n) ∈Ω(n) fixat, F∗n (x) ia valorile:
F∗n (x) =card i, xi ≤ x
n,
(i.e., este functia de repartitie empirica definita prin (2.3.3)).
Propozitie 3.1.3 Functia de repartitie de selectie satisface urmatoarele relatii:
E(F∗n (x)) = F(x), ∀x ∈ R;
Var(F∗n (x)) =1n[F(x)(1−F(x))], ∀x ∈ R.
Demonstratie. Avem ca:
E(F∗n (x)) =1n
n
∑i=1
E(χ(−∞,x](Xi)
)=
1n
n
∑i=1
P(Xi ≤ x) =1n
n
∑i=1
P(X ≤ x) =1n
n
∑i=1
F(x) = F(x),
si
Var(F∗n (x))i.s.=
1n
n
∑i=1
Var(χ(−∞,x](Xi)
)=
1n2
n
∑i=1
F(x)[1−F(x)] =1n[F(x)(1−F(x))],
pentru orice x real.
În Statistica, exista o serie de criterii care permit sa se aprecieze apropierea lui F∗n (x) de F(x).Mai jos, amintim doar câteva dintre ele.
Propozitie 3.1.4 Functia de repartitie de selectie satisface convergenta
F∗n (x)a.s.−−−→
n→∞F(x), x fixat în R.
Demonstratie. Rezultatul este o consecinta directa a legii tari a numerelor mari. Într-adevar,deoarece F∗n (x) se poate scrie sub forma (3.1.2) (i.e., o suma de variabile aleatoare identicrepartizate si independente stochastic), LTNM implica
F∗n (x)a.s.−−−→
n→∞E(χ(−∞,x](X1)) = P(X ≤ x) = F(x), x fixat în R.
Propozitie 3.1.5 Pentru n ∈ N suficient de mare, functia de repartitie de selectie satisfaceproprietatea
√n(F∗n (x)−F(x)) ∼ N (0,
√F(x)(1−F(x))), x fixat în R.

3.2 Statistici de ordine 55
Demonstratie. Rezultatul este o consecinta directa a teoremei limita centrale. Într-adevar,deoarece
E(F∗n (x)) = F(x) si Var(F∗n (x)) =1n[F(x)(1−F(x))],
vom avea ca, pentru n suficient de mare,
F∗n (x)−F(x)√F(x)(1−F(x))√
n
∼ N (0, 1), x fixat în R.
3.2 Statistici de ordineDefinitie 3.2.1 Daca variabilele aleatoare din selectia X1, X2, . . . , Xn le rearanjam în ordineamarimii lor si scriem
X(1) ≤ X(2) ≤ ·· · ≤ X(n),
atunci vom numi variabila aleatoare X(i) statistica de ordine de ordin i, pentru orice i= 1, 2, . . . , n.Pentru o selectie data, valoarea statisticii de ordine de ordin i o vom nota prin x(i), pentru oricei = 1, 2, . . . , n.Statistica X(1) se numeste prima statistica de ordine si reprezinta minimumul selectiei, i.e.,
X(1) = minX1, X2, . . . , Xn.
Statistica X(n) se numeste ultima statistica de ordine si reprezinta maximumul selectiei, i.e.,
X(n) = maxX1, X2, . . . , Xn.
De exemplu, daca avem valorile de selectie
x1 = 8, x2 = 7, x3 = 9, x4 = 5, x5 = 3,
atuncix(1) = 3, x(2) = 5, x(3) = 7, x(4) = 8, x(5) = 9.
Daca n = 2m+ 1, atunci X(m) = X( n+12 ), adica mediana de selectie este o statistica de ordine
în acest caz. Daca n = 2m, atunci avem doua valori de mijloc, X(m) si X(m+1). DeoareceMe = 1
2(X(m)+X(m+1)), mediana de selectie nu este statistica de ordine pentru n par.Definim amplitudinea (range) selectiei ca fiind statistica A = X(n)−X(1). Statisticile X(n)−Mesi Me−X(1) se numesc deviatiile extreme ale selectiei.Ca o observatie importanta, desi variabilele aleatoare de selectie sunt independente, totusistatisticile de ordine sunt dependente.Sa presupunem ca F(x) este functia de repartitie a selectiei date si f (x) densitatea de repartitie.Urmatoarea propozitie stabileste functiile de repartitie pentru statisticile de ordine.
Propozitie 3.2.1 Pentru un k = 1, 2, . . . , n fixat, functia de repartitie pentru X(k) este:
FX(k)(x) =n
∑j=k
C jnF(x) j[1−F(x)]n− j, pentru orice x ∈ R.

56 Capitolul 3. Notiuni din Teoria selectiei statistice
Demonstratie. Avem succesiv:
FX(k)(x) = P(X(k) ≤ x)
= P(cel putin k v.a. din cele n nu depasesc pe x)= P(cel putin k succese în n încercari)
=n
∑j=k
C jn[P(X ≤ x)] j[1−P(X ≤ x)]n− j
=n
∑j=k
C jnF(x) j[1−F(x)]n− j, pentru orice x ∈ R.
În particular, pentru k = 1, obtinem ca functia de repartitie a celui mai mic element al selectiei:
FX(1)(x) = 1− [1−F(x)]n, pentru orice x ∈ R.
Astfel, densitatea de repartitie asociata este:
fX(1)(x) = F ′X(1)(x) = n[1−F(x)]n−1 f (x), pentru orice x ∈ R.
Functia de repartitie a celui mai mare element al selectiei este:
FX(n)(x) = [F(x)]n, pentru orice x ∈ R,
iar densitatea de repartitie asociata este:
fX(n)(x) = F ′X(n)(x) = n[F(x)]n−1 f (x), pentru orice x ∈ R.
Exemplu 3.2.1 La finala de 100m viteza masculin din cadrul campionatelor mondiale deatletism în aer liber, timpii de sosire ai celor 8 sportivi calificati sunt variabile aleatoareindependente stochastic, identic repartizate U (9.5s, 10.5s). Calculati urmatoarele probabilitati:(1) Probabilitatea ca recordul mondial de 9.58s sa cada;(2) Probabilitatea ca toti candidatii sa termine cursa cu timpi de sosire pâna în 10s.(3) Probabilitatea ca macar trei atleti sa termine cursa sub 9.7s.
R: Deoarece T ∼U (9.5s, 10.5s), avem ca F(x) =
0, daca x≤ 9.5x−9.5, daca 9.5 < x < 10.51, daca x≥ 10.5
Atunci:
P1 = P(T(1) ≤ 9.58) = FT(1)(9.58) = 1− [1−F(9.58)]8 = 1−0.928 ≈ 0.4868.
P2 = P(T(8) ≤ 10) = FT(8)(10) = [F(10)]8 = 0.58 ≈ 0.004.
P3 = P(T(3) ≤ 9.7) = FT(3)(9.7) =8
∑j=3
C j8F(9.7) j[1−F(9.7)]8− j ≈ 0.4049.

3.3 Selectii aleatoare dintr-o colectivitate normala 57
3.3 Selectii aleatoare dintr-o colectivitate normalaRezultatele acestui paragraf vor fi utile în determinarea repartitilor unor statistici uzuale (e.g.,media de selectie, dispersia de selectie), cât si în a altor statistici utile în Statistica inferentiala.Sa consideram Ω o colectivitate statistica si X o caracteristica a sa, ce urmeaza a fi studiatadin punct de vedere statistic. Fie X1, X2, . . . , Xn variabile aleatoare de selectie repetata devolum n. În cele mai multe cazuri practice, X urmeaza o repartitie normala (gaussiana). Deregula, daca volumul populatiei este mic (n < 30), atunci consideram doar populatii normale,iar pentru n ≥ 30, datorita rezultatului teoremei limita centrala, putem considera orice tip derepartitie pentru colectivitate. Mai jos, prezentam câteva rezultate utile referitoare la selectiadintr-o colectivitate gaussiana.
Propozitie 3.3.1 (repartitia unei combinatii liniare de variabile normale)Daca ξi ∼N (µi, σi) sunt variabile aleatoare independente stochastic si ai ∈ R, i = 1, 2, . . . , n,
atunci variabila aleatoare ξ =n
∑i=1
aiξi satisface proprietatea:
ξ ∼N
(n
∑i=1
aiµi,
√n
∑i=1
a2i σ2
i
).
Demonstratie. Demonstratia este bazata pe metoda functiei caracteristice. Reamintim faptul cafunctia caracteristica pentru o repartitie normala X ∼N (µ, σ) este ϕX(t) = eiµt− 1
2 σ2t2. Aratam
ca functia caracteristica ϕξ (t) are aceasta forma si, invocând faptul ca functia caracteristicadetermina în mod unic repartitia, obtinem concluzia dorita. Tinând cont ca variabilele ξkk suntindependente stochastic, putem scrie:
ϕξ (t) = E(
eitξ)= E
(eit ∑
nk=1 akξk
)= E
(n
∏k=1
eitakξk
)i.s.=
n
∏k=1
E(
eitakξk)
=n
∏k=1
ϕξk(akt) =
n
∏k=1
eitakµk−a2k σ2
k2 t2
= e(∑nk=1 akµk)it− 1
2 (∑nk=1 a2
kσ2k )t
2, t ∈ C,
de unde rezulta concluzia.
Propozitie 3.3.2 (repartitia mediei de selectie pentru o selectie gaussiana)Daca X ∼N (µ, σ) si Xk, k = 1, 2, . . . , n, sunt variabilele aleatoare de selectie, atunci statisticaX satisface:
X ∼N
(µ,
σ√n
), n = 1, 2, . . .
Demonstratie. Pentru demonstratie, folosim rezultatul propozitiei anterioare pentru ξk = Xk si
ak =1n.
O consecinta directa a acestei propozitii este urmatoarea:

58 Capitolul 3. Notiuni din Teoria selectiei statistice
Propozitie 3.3.3 Daca Xk ∼ N (µ, σ), k = 1, 2, . . . , n, sunt variabile aleatoare de selectie,atunci
Z =X−µ
σ√n
∼N (0, 1).
Propozitie 3.3.4 (repartitia mediei de selectie pentru o selectie oarecare)Daca X1, X2, . . . , Xn, variabile aleatoare de selectie repetata de volum n, ce urmeaza o repartitiedata, atunci pentru un volum n suficient de mare, statistica X satisface:
X ∼N
(µ,
σ√n
), n≥ 30.
Demonstratie. Acest rezultat este o consecinta imediata a concluziei teoremei limita centrala.
Observatie 3.3.1 Când selectia se face fara revenire dintr-o populatie de volum mai mic decât30 si X nu este neaparat normal repartizata, atunci putem spune doar ca
E(X) = µ si Var(X) =σ√
n
√N−nN−1
,
fara a putea preciza care este repartitia lui X . Aici N este volumul populatiei si n > 0.05N.
Propozitie 3.3.5 (repartitia unei combinatii liniare de medii de selectie)Fie ξi ∼N (µi, σi) variabile aleatoare independente stochastic si ai ∈R, i = 1, 2, . . . , m. Pentrufiecare caracteristica ξi consideram câte o selectie repetata de volum ni, si notam cu ξi mediade selectie corespunzatoare fiecarei selectii. Atunci statistica Y = a1ξ1 + a2ξ2 + . . . + anξmsatisface proprietatea:
Y ∼N
(m
∑i=1
aiµi,
√m
∑i=1
a2i
σ2i
ni
).
Demonstratie. Deoarece ξi ∼N (µi, σi), din Propozitia 3.3.2 obtinem ca media de selectiecorespunzatoare, ξi, satisface:
ξi ∼N
(µi,
σi√ni
).
Aplicând rezultatul Propozitiei 3.3.1 variabilelor aleatoare independente ξ1, ξ2, . . . , ξm, obti-nem concluzia dorita.
Urmatoarea propozitie este un caz particular al Propozitiei 3.3.5.

3.3 Selectii aleatoare dintr-o colectivitate normala 59
Propozitie 3.3.6 (repartitia diferentei mediilor de selectie pentru colectivitati gaussiene)Consideram o selectie de volum n1 dintr-o populatie normala N (µ1, σ1) si o selectie de volumn2 dintr-o colectivitate N (µ2, σ2), cele doua selectii fiind alese independent una de cealalta.Notam cu X1 si, respectiv, X2 mediile de selectie corespunzatoare selectiilor alese. Atunci
X1−X2 ∼ N
µ1−µ2,
√σ2
1n1
+σ2
2n2
.
Demonstratie. Aplicam rezultatul Propozitiei 3.3.5 pentru cazul particular în care avem doardoua variabile aleatoare, X1 si X2, iar a1 = 1, a2 =−1.
Observatie 3.3.2 (1) Concluzia propozitiei anterioare se mai poate scrie astfel:
Z =(X1−X2)− (µ1−µ2)√
σ21
n1+
σ22
n2
∼ N (0, 1).
(2) Sa presupunem ca avem doua populatii statistice normale, Ω1 si Ω2, iar X este o caracteris-tica comuna a celor doua populatii, ce urmeaza a fi studiata. (De exemplu, populatiile statisticesa fie multimea pieselor produse de doua strunguri într-o zi de lucru, iar caracteristica comunasa fie masa lor). Sa mai presupunem ca deviatiile standard ale caracteristicilor considerate suntcunoscute (i.e., deviatiile sunt date deja în cartea tehnica a celor doua strunguri). Pentru fiecaredintre cele doua colectivitati, consideram câte o selectie repetata, de volume n1, respectiv, n2(adica, vom selecta n1 dintre piesele produse de strungul întâi si n2 piese produse de cel de-aldoilea strung). Sa notam cu X1, respectiv, X2 mediile de selectie corespunzatoare. Propozitiaanterioara precizeaza care este repartitia diferentei standardizate ale celor doua medii de selectie.Aceasta ne va fi deosebit de utila, spre exemplu, în verificarea ipotezei ca masele medii alepieselor produse de cele doua strunguri coincid.
Propozitie 3.3.7 (repartitia sumei patratelor unor variabile normale)Daca X ∼N (0, 1) si Xkn
k=1 sunt variabilele aleatoare de selectie repetata de volum n, atuncivariabila aleatoare
H2 =n
∑i=1
X2k ∼ χ
2(n).
Demonstratie. Pentru a demonstra propozitia, folosim metoda functiei generatoare de momente.Pentru aceasta, avem nevoie de functia generatoare de momente pentru X2, unde X ∼N (0, 1).Sa notam cu f (x) functia densitate de repartitie pentru X . Notam cu G(y) functia de repartitiepentru X2 si cu g(y) densitatea sa de repartitie. Avem:
G(y) = P(X2 ≤ y) =
0 , y≤ 0;P(−√y≤ X ≤√y) , y > 0,
de unde
g(y) = G′(y) =
0 , y≤ 0;
12√
y [ f (√
y)+ f (−√y)] , y > 0,

60 Capitolul 3. Notiuni din Teoria selectiei statistice
=
0 , y≤ 0;
1√y f (√
y) , y > 0.
Asadar, daca X ∼N (0, 1), atunci X2 are densitatea de repartitie
fX2(x) =
1√2πx
e−x2 , x > 0.
0 , x≤ 0.
Functia caracteristica pentru X2 este
ϕX2(t) = E(eitX2) =
∫∞
0eitx2 1√
2πxe−
x2 dx = (1−2it)−1/2, t ∈ C.
Folosind independenta variabilelor X2i n
i=1, obtinem ca functia generatoare de momente a luiH2 este
ϕH2(t) =n
∏i=1
(1−2it)−1/2 = (1−2it)−n/2, t ∈ C,
care este functia caracteristica pentru o variabila aleatoare χ2(n).
Observatie 3.3.3 O consecinta imediata a acestei propozitii este ca, daca X ∼N (0, 1), atunciv.a. X2 ∼ χ2(1). Urmatoarea propozitie este tot o consecinta directa a Propozitiei 3.3.7.
Propozitie 3.3.8 (repartitia dispersiei de selectie când media colectivitatii este cunoscuta)Daca X ∼N (µ, σ) si µ < ∞, atunci variabila aleatoare
D2 =1
σ2
n
∑i=1
(Xi−µ)2 ∼ χ2(n).
Demonstratie. Pentru fiecare i = 1, 2, . . . , n, consideram variabilele aleatoare
Yi =Xi−µ
σ.
Conform Propozitiei 3.3.3, avem Yi ∼N (0, 1), ∀i = 1, 2, . . . , n. Aplicam rezultatul propozitiei3.3.7 pentru variabilele aleatoare Y1, Y2, . . . , Yn si obtinem concluzia dorita.
Lema 3.3.9 Daca X si Y sunt variabile aleatoare independente stochastic, astfel încât X ∼ χ2(n)si X +Y ∼ χ2(n+m), atunci Y ∼ χ2(m).
Demonstratie. Demonstratia se bazeaza pe metoda functiei caracteristice, folosind faptul ca
ϕX(t) ·ϕY (t) = ϕX+Y (t), ∀t ∈ C.

3.3 Selectii aleatoare dintr-o colectivitate normala 61
Lema 3.3.10 Fie X caracteristica unei colectivitati statistice N (µ, σ), X media de selectie devolum n si S2 dispersia de selectie. Atunci, statisticile
X−µ
σ√n
=
√n
σ(X−µ) si
n−1σ2 S2 =
1σ2
n
∑i=1
(Xi−X)2 sunt independente stochastic.
Demonstratie. Vezi Exercitiul (3.5.1). Aceasta lema este demonstrata si în [4] (Teorema I.2.5).
Propozitie 3.3.11 Fie X ∼N (µ, σ) caracteristica unei populatii statistice. Atunci statistica
χ2 =
1σ2
n
∑i=1
(Xi−X)2 ∼ χ2(n−1).
Demonstratie. Putem scrie:
1σ2
n
∑i=1
(Xi−µ)2 =1
σ2
n
∑i=1
(Xi−X)2 +n
σ2 (X−µ)2 (3.3.3)
sau,n
∑i=1
Z2i =
n−1σ2 S2 +Z2
, (3.3.4)
unde:
Zi =Xi−µ
σ∼N (0, 1) si Z =
X−µ
σ√n∼N (0, 1).
Utilizând Propozitia 3.3.8, observam ca membrul stang al egalitatii (3.3.3) este o variabilaaleatoare repartizata χ2(n). Folosind Observatia 3.3.3, concluzionam ca al doilea termen dinmembrul drept este repartizat χ2(1). Utilizând lema anterioara, deducem ca variabilele aleatoareZ2 si n−1
σ2 S2 sunt independente stochastic. Facem apel la Lema 3.3.9, si ajungem la concluziapropozitiei.
Observatie 3.3.4 (repartitia dispersiei de selectie când media este necunoscuta)Din Propozitia 3.3.11, deducem repartitia dispersiei de selectie S2:
n−1σ2 S2 ∼ χ
2(n−1). (3.3.5)
Lema 3.3.12 Daca X si Y sunt variabile aleatoare independente stochastic, cu X ∼N (0, 1) siY ∼ χ2(n), atunci statistica
T =X√
Yn
∼ t (n).

62 Capitolul 3. Notiuni din Teoria selectiei statistice
Demonstratie. Fie f (x) si g(y) densitatile de repartitie pentru X , respectiv, Y . Avem:
f (x) =1√2π
e−x22 , x ∈ R,
g(y) =
y
n2−1 e−
y2
2n2 Γ( n
2),y > 0;
0 ,y≤ 0.
Din independenta, gasim ca densitatea de repartitie a vectorului (X , Y ) este:
h(x, y) = f (x)g(y) =y
n2−1 e−
x2+y2
2n+1
2√
π Γ(n
2
) , (x, y) ∈ R× (0, ∞).
Consideram o transformare a acestui vector,
τ :
t =
x√yn
v = y,
în vectorul (T, Y ). Densitatea de repartitie a acestui vector este:
k(t, v) =v
n2−1 e−
v2 (1+
t2n )
2n+1
2√
π Γ(n
2
) √vn, (t, v) ∈ R× (0, ∞).
Densitatea de repartitie marginala pentru T este:
k1(t) =∫
∞
0k(t, v)dv
=Γ(n+1
2
)√
nπ Γ(n
2
) (1+t2
n
)− n+12
, t ∈ R,
adica tocmai densitatea de repartitie a unei variabile aleatoare t(n).
Propozitie 3.3.13 Daca X ∼N (µ, σ) este caracteristica unei colectivitati statistice, atunci
t=X−µ
S√n
∼ t(n−1).
(t(n−1) este repartitia Student cu n−1 grade de libertate, S este deviatia stantard de selectie)
Demonstratie. Aplicam lema anterioara pentru variabilele aleatoare
X =X−µ
σ√n∼N (0, 1) si Y =
n−1σ2 S2 ∼ χ
2(n−1).

3.3 Selectii aleatoare dintr-o colectivitate normala 63
Observatie 3.3.5 Aceasta propozitie va fi folosita pentru verificarea ipotezelor statistice, înproblema testarii mediei teoretice când dispersia teoretica este necunoscuta a priori.
Propozitie 3.3.14 Daca variabilele aleatoare X0, X1, . . . , Xn sunt independente stochastic,identic repartizate N (0, 1), atunci variabila aleatoare
T =X0√
X21 +X2
2 + ...+X2n
n
∼ t(n).
Demonstratie. Concluzia rezulta prin aplicarea Propozitiei 3.3.7 si Lemei 3.3.12.
Propozitie 3.3.15 (repartitia diferentei mediilor de selectie când dispersiile sunt necunoscute,egale) Consideram o selectie de volum n1 dintr-o populatie normala N (µ1, σ1) si o selectiede volum n2 dintr-o colectivitate N (µ2, σ2), cele doua selectii fiind alese independent una decealalta. Notam cu X1, X2 si S2
1 = S2X1
, S22 = S2
X2mediile de selectie si dispersiile de selectie
corespunzatoare selectiilor alese. În plus, presupunem ca σ21 = σ2
2 = σ2. Atunci
T =(X1−X2)− (µ1−µ2)√(n1−1)S2
1 +(n2−1)S22
√n1 +n2−2
1n1+ 1
n2
∼ t(n1 +n2−2).
Demonstratie. Consideram variabila aleatoare
U =(X1−X2)− (µ1−µ2)
σ
√1n1+ 1
n2
.
Se verifica cu usurinta ca U ∼N (0, 1). Fie variabila aleatoare
V =(n1−1)S2
1σ2 +
(n2−1)S22
σ2 .
Conform relatiei (3.3.5), avem ca (n1−1)S21
σ2 ∼ χ2(n1− 1) si (n2−1)S22
σ2 ∼ χ2(n2− 1). Deoareceaceste doua statistici sunt independente, atunci ca suma lor, statistica V , satisface V ∼ χ2(n1 +n2−2). Concluzia propozitiei rezulta prin simpla aplicare a Lemei 3.3.12 variabilelor aleatoareU si V .
Propozitie 3.3.16 (repartitia diferentei mediilor de selectie când dispersiile sunt necunoscute sidiferite) Consideram o selectie de volum n1 dintr-o populatie normala N (µ1, σ1) si o selectiede volum n2 dintr-o colectivitate N (µ2, σ2), cele doua selectii fiind alese independent una decealalta. Notam cu X1, X2 si S2
1 = S2X1
, S22 = S2
X2mediile de selectie si dispersiile de selectie
corespunzatoare selectiilor alese. Presupunem ca σ21 6= σ2
2 . Atunci
T =(X1−X2)− (µ1−µ2)√
S21
n1+
S22
n2
∼ t(N). (3.3.6)

64 Capitolul 3. Notiuni din Teoria selectiei statistice
unde
N =
(s2
1n1
+s2
2n2
)2
(s2
1n1
)2 1n1−1
+
(s2
2n2
)2 1n2−1
− 2(s2
1 = s2(x1), s22 = s2(x2)
)(3.3.7)
Observatie 3.3.6 În practica se foloseste un test statistic pentru testarea egalitatii dispersiilornecunoscute ale celor doua caracteristici.
Propozitie 3.3.17 Daca X ∼ χ2(m) si Y ∼ χ2(n) sunt variabile aleatoare independente, atuncivariabila aleatoare
F =nm
XY∼ F (m, n).
Demonstratie. Fie f (x) si g(y) densitatile de repartitie pentru X si, respectiv, Y . Avem:
f (x) =
x
m2 −1 e−
x2
2m2 Γ(m
2 ),x > 0;
0 ,x≤ 0.
g(y) =
y
n2−1 e−
y2
2n2 Γ( n
2),y > 0;
0 ,y≤ 0.
Din independenta celor doua variabile aleatoare, gasim ca densitatea de repartitie a vectorului(X , Y ) este:
h(x, y) = f (x)g(y) =x
m2−1y
n2−1 e−
x+y2
2m+n
2 Γ(m
2
)Γ(n
2
) , (x, y) ∈ (0, ∞)× (0, ∞).
Consideram o transformare a acestui vector,
τ :
t =nm
xy
v = y,
în vectorul (F, Y ). Densitatea de repartitie a acestui vector este:
k(u, v) =
(mn
)m2 u
m2−1v
m+n2 −1 e−
v2 (1+
mn u)
2m+n
2 Γ(m
2
)Γ(n
2
) , (t, v) ∈ (0, ∞)× (0, ∞).
Densitatea de repartitie marginala pentru F este:
k1(u) =∫
∞
0k(u, v)dv
=
(mn
)m2 Γ(m+n
2
)Γ(m
2
)Γ(n
2
) um2−1
(1+
mn
u)−m+n
2, u > 0,
adica tocmai densitatea de repartitie a unei variabile aleatoare F (m, n).

3.3 Selectii aleatoare dintr-o colectivitate normala 65
Propozitie 3.3.18 Daca X1, X2, . . . , Xm+n sunt variabile aleatoare independente, identic repar-tizate N (0, 1), atunci variabila aleatoare
F =nm
X21 +X2
2 + . . . +X2m
X2m+1 +X2
m+2 + . . . +X2m+n
∼ F (m, n).
Demonstratie. Demonstratia rezulta imediat prin aplicarea rezultatelor Propozitiilor 3.3.7 si3.3.17.
Propozitie 3.3.19 (repartitia raportului dispersiilor pentru colectivitati gaussiene)Fie X1 ∼N (µ1, σ1) si X2 ∼N (µ2, σ2) caracteristicile a doua populatii statistice, Ω1 si Ω2.Din fiecare populatie extragem câte o selectie repetata, de volume n1, respectiv, n2, si consideramS2
1 = S2X1
si S22 = S2
X2dispersiile de selectie corespunzatoare celor doua selectii repetate. Atunci
F =σ2
2σ2
1
S21
S22∼ F (n1−1, n2−1).
Demonstratie. Rescriem F în forma echivalenta:
F =n2−1n1−1
χ21
χ22,
unde
χ21 =
1σ2
1
n1
∑i=1
(X1 i−X1)2, χ
22 =
1σ2
2
n2
∑j=1
(X2 j−X2)2,
X1 ii=1,n1si X2 ii=1,n2
sunt variabile de selectie repetata de volume n1, respectiv, n2, ceurmeaza repartitia variabilelor aleatoare X1, respectiv, X2. Statisticile X1 si X2 sunt mediile deselectie corespunzatoare.Folosind concluzia Propozitiei 3.3.11, avem ca
χ21 ∼ χ
2(n1−1), χ22 ∼ χ
2(n2−1).
Concluzia acestei propozitii urmeaza în urma aplicarii rezultatului Propozitiei 3.3.18.
Propozitie 3.3.20 (repartitia raportului dispersiilor pentru colectivitati gaussiene)Suntem în conditiile Propozitiei 3.3.19, cu mentiunea ca mediile teoretice µ1 si µ2 sunt cunoscutea priori. Atunci
σ22
σ21
D21
D22∼ F (n1, n2),
unde D21 si D2
2 sunt date de:
D21 =
1n1
n1
∑i=1
(X1 i−µ1)2 ∼ χ
2(n1), D22 =
1n2
n2
∑j=1
(X2 j−µ2)2 ∼ χ
2(n2).
Demonstratie. Demonstratia este similara cu cea de mai înainte. Se folosesc rezultatele Propozi-tiilor 3.3.8 si 3.3.18.

66 Capitolul 3. Notiuni din Teoria selectiei statistice
3.4 Exercitii rezolvateExercitiu 3.4.1 Aratati ca
Var(X) =1n
n
∑i=1
X2i −
(1n
n
∑i=1
Xi
)2
=1n
n
∑i=1
X2i −
(X)2
si
S2(X) =1
n−1
[n
∑i=1
X2i −n
(X)2
].
R: Avem ca
Var(X) =1n
n
∑i=1
[Xi−X
]2=
1n
n
∑i=1
[X2
i −2XXi +(X)2]
=1n
n
∑i=1
X2i −2X2
+X2=
1n
n
∑i=1
X2i −
1n
(n
∑i=1
Xi
)2 .
A doua relatie se demonstreaza la fel.Exercitiu 3.4.2 Daca Xii≥1 sunt i.i.d., cu media µ si dispersia σ2 finite, demonstrati caS2(X)
a.s.−→ σ2, pentru n→ ∞.R: Din exercitiul anterior,
S2(X) =1
n−1
n
∑i=1
X2i −
1n
(n
∑i=1
Xi
)2=
nn−1
1n
n
∑i=1
X2i −
(1n
n
∑i=1
Xi
)2
Din faptul ca Xii≥1 sunt i.i.d., obtinem ca X2i i≥1 sunt, de asemenea, i.i.d., cu media E(X2) =
µ2 +σ2 < ∞. Folosind LTNM, avem ca
1n
n
∑i=1
Xia.s.−→ µ si
1n
n
∑i=1
X2i
a.s.−→ µ2 +σ
2 pentru n→ ∞.
Din acestea, si din faptul ca nn−1 −→ 1 când n→ ∞, rezulta concluzia.
Exercitiu 3.4.3 Presupunem ca masa medie a unor batoane de ciocolata produse de o masina esteo caracteristica X ∼N (100, 0.65). În vederea verificarii parametrilor masinii, dintre batoaneleprimite într-un depozit s-au ales la întâmplare 1000 de bucati.(i) Calculati media si deviatia standard ale mediei de selectie, X .(ii) Calculati P(98 < X < 102).(iii) Un baton este declarat rebut daca masa sa este sub 98 de grame sau peste 102 de grame.Calculati procentul de rebuturi avute.R: (i) Stim ca media de selectie X urmeaza repartitia N (100, 0.65/
√1000). Asadar,
µX = 100, σX ≈ 0.02.
(ii) Probabilitatea P1 = P(98 < X < 102) este
P1 = P(X < 102)−P(X ≤ 98) = FX(102)−FX(98)
= P(
X−1000.65/
√1000
<102−100
0.65/√
1000
)−P
(X−100
0.65/√
1000<
98−1000.65/
√1000
)= Θ
(2
0.65/√
1000
)−Θ
( −20.65/
√1000
)≈ Θ(97.301)−Θ(−97.301)≈ 1.

3.4 Exercitii rezolvate 67
(iii) Probabilitatea de a avea un rebut este:
P2 = P(X < 98
⋃X > 102
)= P(X < 98)+P(X > 102)= FX(98)+1−FX(102)
= Θ
( −20.65
)+1−Θ
(2
0.65
)≈ 0.002091,
de unde, procentul de rebuturi este
r = P2 ·100% ≈ 0.2091%,
adica aproximativ 2 rebuturi la 1000 de batoane.Exercitiu 3.4.4 Samponul marca FAIRHAIR se vinde acum în supermarket în trei marimi(volume): 250ml, 500ml si 1 litru. Treizeci la suta dintre cumparatorii acestui produs cumparaflaconul de 250ml, 50% pe cel de 500ml, iar restul pe cel de 1 litru. Notam cu X volumul unuiflacon de FAIRHAIR. Fie X1 si X2 volumele flacoanelor cumparate de doi dintre clienti, alesi laîntâmplare.(a) Determinati repartitia pentru X . Calculati media E(X) si comparati-o cu µ = E(X).(b) Calculati Var(X) si comparati-o cu σ2 =Var(X).(c) Calculati probabilitatea P(X ≥ 500).(d) Care ar trebui sa fie volumul minim de cumparatori pentru ca media de selectie sa satisfacarelatia P(X ≥ 500)> 0.75?R: Fie v.a. X ce reprezinta volumul ales de un cumparator. Atunci distributia lui X este:
x 250 500 1000p(x) 0.3 0.5 0.2
.
Deoarece X1 si X2 sunt variabile aleatoare de selectie, ele sunt independente si au aceeasirepartitie ca X . Avem ca µ = E(X) = 525 si σ = D(X) = 25
√109.
(a) Media de selectie este X = (X1 +X2)/2. Repartitia sa este:
x 250 375 500 625 750 1000p(x) 0.09 0.3 0.25 0.12 0.2 0.04
.
Media este µX = E(X) = E(X) = µ = 525.
(b) σX =σ√
2= 25
√1092
< σ .
(c) P(X ≥ 500) = 0.25+0.12+0.2+0.04 = 0.61.
(d) Presupunem ca n este mare. Atunci, conform teoremei limita centrala, X ∼N
(µ,
σ√n
),
de unde gasim caX−µ
σ√n∼N (0, 1). Asadar,
0.75 < P(X ≥ 500) = 1−P(X ≤ 500) = 1−P
(X−µ
σ√n≤ 500−µ
σ√n
)
= 1−Θ
(500−µ
σ√n
)= 1−Θ
(−√
n109
),

68 Capitolul 3. Notiuni din Teoria selectiei statistice
de unde
Θ
(−√
n109
)< 0.25 si −
√n
109< Θ
−1(0.25) = z0.25 =−0.6745,
de unde n > 109 · z20.25 ≈ 50.
Exercitiu 3.4.5 În vederea studierii unei caracteristici X ce are densitatea de repartitie
f (x) =
2x, x ∈ (0, 1);0, x 6∈(0, 1).
s-a efectuat o selectie repetata de volum n = 100. Se cere sa se determine probabilitateaP(X < 0.65), unde X este media de selectie.R: Se observa cu usurinta ca f (x) îndeplineste conditiile unei densitati de repartitie, adica estemasurabila, nenegativa si ∫
Rf (x)dx =
∫ 1
02xdx = 1.
Pentru a calcula probabilitatea ceruta, avem nevoie de E(X) si Var(X). Avem:
E(X) =∫R
x f (x)dx =∫ 1
02x2 dx =
23,
Var(X) = E(X2)− (E(X))2 =∫R
x2 f (x)dx− 49=
118
.
Asadar, repartitia mediei de selectie X este
X ∼N
(23,
1√18 ·√
100
).
Putem acum calcula probabilitatea ceruta. Ea este:
P(X < 0.65) = FX(0.65) = Θ
(0.65−2/31/(30
√2)
)≈Θ(−0.70711)≈ 0.2398.
Exercitiu 3.4.6 Notam cu P1, P2, . . . , P9 preturile oferite de 9 ofertanti la o licitatie publicapentru vinderea unui anumit tablou. Presupunem ca acestea sunt variabile aleatoare reparti-zate uniform U (1000, 2000). Obiectul se va vinde celui care vine cu oferta cea mai mare.Determinati valoarea asteptata a pretului obtinut pentru acest tablou.R: Deoarece P∼U (1000, 2000), atunci
f (x) =
1
1000 , daca 1000 < x < 20000, daca x 6∈(1000, 2000)
si F(x)=
0, daca x≤ 1000x−1000
1000 , daca 1000 < x < 20001, daca x≥ 2000
Functia de repartitie a statisticii de ordine M = P(9) = maxP1, P2, . . . , P9 este
FP(9)(x) = [F(x)]9, x ∈ R.
Densitatea de repartitie a statisticii de ordine M este
fP(9)(x) = F ′P(9)(x) = 9[F(x)]8 f (x), x ∈ R.

3.4 Exercitii rezolvate 69
Pretul de vânzare asteptat este media variabilei aleatoare M,
E(M) =
∞∫−∞
x fP(9)(x)dx =9
1000
2000∫1000
x(
x−10001000
)8
dx = 1900.
Exercitiu 3.4.7 Cantitatea de apa consumata de Ana în fiecare zi se presupune a fi o v.a. normalacu media 2 l si deviatia standard 300ml, independenta de zi. Ana a cumparat azi un bax de 6sticle a câte 2.5 litri de apa fiecare. Presupunând ca Ana bea doar din apa cumparata azi, caresunt sansele ca ea sa mai aiba apa din acest stoc si dupa o saptamâna (7 zile, inclusiv cea de azi)?R: Notam cu Xk, k = 1, 2, . . . , 7, cantitatea de apa batuta de Ana în ziua de rang k. Acestevariabile sunt independente între ele. Din ipoteza, Xk ∼N (2, 0.3). Ea va mai avea apa din stoc
dupa cele 7 zile daca7
∑k=1
Xk < 15. Dar7
∑k=1
Xk ∼N (14, 0.3√
7). Sansele ca acest eveniment sa
aiba loc sunt
P
(7
∑k=1
Xk < 15
)= P
(∑
7k=1 Xk−14
0.3√
7<
15−140.3√
7
)= P
(Z <
103√
7
)= P(Z < 1.26)≈ 0.8961.
Exercitiu 3.4.8 Becurile produse de un manufacturier A au timpul mediu de functionare de 1400ore, cu deviatia standard de 200 ore, în timp ce timpul mediu de functionare al becurilor produsede un manufacturier B au timpul mediu de functionare de 1200 ore, cu deviatia standard de 100ore. Se face o selectie de 125 becuri din fiecare tip si se testeaza becurile alese.(a) Pentru selectiile date, care este probabilitatea ca becurile produse de A sa aiba un timpmediu de viata mai mare cu 250 de ore decât timpul mediu de functionare al becurilor produsede B?(b) Care este probabilitatea ca timpul mediu de functionare al becurilor selectate din tipul A safie cuprins între 1375 de ore si 1425 de ore?(c) Presupunem ca timpul mediu de functionare al becurilor produse de A este o v.a. normala.Alegem la întâmplare un bec de tipul A. Care este probabilitatea ca timpul sau mediu defunctionare sa fie cuprins între 1375 de ore si 1425 de ore?R: Notam cu T1 si T2 cei doi timpi de functionare. Avem ca
µT1 = 1400, σT1 = 200 si µT2 = 1200, σT2 = 100.
Pentru o selectie de volum n = 125 (vom considera ca selectia este repetata, deoarece volumulselectiei este mult mai mic decât numarul becurilor produse de fiecare manufacturier), avem ca:
T1 ∼N (1400,2005√
5) si T2 ∼N (1200,
1005√
5).
Diferenta mediilor de selectie este o v.a. repartizata astfel:
T1−T2 ∼N (200,20).
P(T1−T2 > 250) = 1−FT1−T2(250)
= 1−Θ
(250−200
20
)≈ 0.0062.

70 Capitolul 3. Notiuni din Teoria selectiei statistice
(b) Probabilitatea ceruta este:
P(1375≤ T1 ≤ 1425) = FT1(1425)−FT1
(1375)
= Θ
(1425−1400
8√
5
)−Θ
(1375−1400
8√
5
)≈ 0.8377.
(c) Probabilitatea ceruta este:
P(1375≤ T1 ≤ 1425) = FT1(1425)−FT1(1375)
= Θ
(1425−1400
200
)−Θ
(1375−1400
200
)≈ 0.0995.
Exercitiu 3.4.9 Doua avioane zboara în aceeasi directie pe doua coridoare paralele. La momentult = 0, primul avion are un avans de 6km în fata celui de-al doilea. Presupunem ca viteza primuluiavion (masurata în km/h) este o variabila aleatoare repartizata normal, cu media 510 si deviatiastandard 10, iar viteza celui de-al doilea avion este normal repartizata, cu media 500 si deviatiastandard 10.(a) Care sunt sansele ca, dupa 4 ore de zbor, al doilea avion sa nu îl fi ajuns pe primul?(b) Determinati probabilitatea ca, dupa 4 ore de zbor, distanta dintre cele doua avioane sa fie decel mult 5km.R: Notam cu V1 si V2 cele doua viteze. Avem ca
V1 ∼N (510,10) si V2 ∼N (500,10).
Dupa 4 ore de zbor (adica avem câte o selectie de volum 4 pentru fiecare variabila aleatoare,anume V1ii, V2kk, i, k = 1, 4), mediile de selectie vor satisface:
V1 ∼N (510,5) si V2 ∼N (500,5).
Diferenta mediilor de selectie este o variabila aleatoare repartizata astfel:
V1−V2 ∼N (10,5√
2).
(a) Dupa o ora de zbor, distanta parcursa de primul avion este D11 =V11 kmh ·1h, iar dupa 4 ore
de zbor, distanta parcursa de primul avion va fi D1 = ∑4i=1V1i · 1km. Similar pentru al doilea
avion. Evenimentul ca, dupa 4 ore de zbor, al doilea avion sa nu îl fi ajuns pe primul este
4
∑i=1
V1i +6−4
∑k=1
V2k > 0= 4V1−4V2 +6 > 0.
Probabilitatea acestui eveniment este:
P(4V1−4V2 +6 > 0) = P(V1−V2 >−32) = 1−P(V1−V2 ≤−
32)
= 1−FV1−V2(−3
2)
= 1−Θ
(−3/2−105√
2
)≈ 0.9481.

3.5 Exercitii propuse 71
(b) Evenimentul ca, dupa 4 ore de zbor, distanta dintre cele doua avioane sa fie de cel mult 5kmeste |4V1−4V2 +6| ≤ 5. Probabilitatea acestui eveniment este:
P(|4V1−4V2 +6| ≤ 5
)= P
(−11
4≤V1−V2 ≤−
14
)= FV1−V2
(−1
4
)−FV1−V2
(−11
4
)= Θ
(−1/4−105√
2
)−Θ
(−11/4−105√
2
)≈ 0.0379.
3.5 Exercitii propuseExercitiu 3.5.1 Aratati ca media de selectie X si dispersia de selectie S2 sunt variabile aleatoareindependente.Indicatie: Folositi urmatoarea identitate:
1σ2
n
∑k=1
(Xk−µ)2 =1
σ2
n
∑k=1
(Xk−X)2 +1
σ2 (X−µ)2.
Exercitiu 3.5.2 Sa se arate ca dispersia statisticii dispersie de selectie S2 este
Var(S2) =2
n−1σ
4.
Indicatie: Folositi forma repartitiei statisticii S2.Exercitiu 3.5.3 Daca X ∼N (3, 2), calculati:(a) P(2≤ X ≤ 4),(b) P(2≤ X ≤ 4), pentru o selectie de volum 16,(c) probabilitatea ca media de selectie sa depaseasca valoarea 4 pentru o selectie de volum 16.Exercitiu 3.5.4 Consideram εi ∼N (0, 1), i = 1, 2, . . . , 45, un set de masuratori independente.Calculati probabilitatea ca suma patratelor erorilor sa fie mai mare decât 50.Exercitiu 3.5.5 Daca X ∼N (1, 2) si Y ∼N (3, 4), cu X , Y independente, aflati P(X +Y ≤ 5).Exercitiu 3.5.6 Un anumit component electric, care este strict necesar pe un satelit ce orbiteazaPamântul, are durata medie de functionare continua de 10 zile.(a) Care este probabilitatea ca durata de functionare continua a unui astfel de component sadepaseasca 10 zile? (se considera ca timpul de functionare este o v.a. exponentiala).(b) De îndata ce se defecteaza, acest component va trebui înlocuit imediat cu unul nou, identic.Care este numarul minim de componente de acest tip ce trebuie luate la plecarea într-o misiunede un an, pentru ca probabilitatea ca satelitul sa devina inoperativ din cauza epuizarii tuturorrezervelor functionabile sa fie mai mica de 0.02?Exercitiu 3.5.7 Consideram functia f : R−→ R, data prin
f (x) =
ae−x , x > 0;0 , x≤ 0.
(i) Gasiti valoarea parametrului a pentru care f (x) este o densitate de repartitie;(ii) Fie X v.a. ce are densitatea de repartitie gasita. Calculati probabilitatea P(X > 1);(ii) Fie X1, X2, . . . , X100 variabilele aleatoare de selectie repetata asupra lui X si fie X mediade selectie. Calculati P
(X > 1
)si P
(X = a
).

72 Capitolul 3. Notiuni din Teoria selectiei statistice
Exercitiu 3.5.8 Presupunem ca timpul necesar pescuirii unui peste dintr-un anumit iaz este ovariabila aleatoare repartizata exp(10min). La un concurs, sapte pescari se întrec în a prinde câteun peste, câstigând cel care l-a prins primul.(i) Care este probabilitatea ca primul peste sa fie prins în mai putin de 7 minute?(ii) Care este probabilitatea ca toti cei 7 pescari sa fi prins câte un peste în mai putin de 15minute?Exercitiu 3.5.9 Aratati ca daca U ∼U (0, 1), atunci
X = µ +λ tan[
π
(U− 1
2
)]∼ C (λ , µ).
Exercitiu 3.5.10 Masa unui bagaj ce trece pe la serviciul de check-in al aeroportului din Iasipentru cursa de Viena este o v.a. cu media 21kg si deviatia standard 3.5kg pentru pasagerii de laclasa economic si o v.a. cu media 12kg si deviatia standard 4.5kg pentru pasagerii de la clasabusiness. Presupunem ca aceste valori sunt ale unor variabile aleatoare independente de la unpasager la altul, indiferent de clasa.(a) Daca într-o anumita cursa se afla 16 pasageri la clasa business si 81 pasageri la clasaeconomic, care este valoarea asteptata si deviatia standard a masei totale de bagaje ale pasagerilordin acel avion?(b) Care este probabilitatea ca masa totala de bagaje ale celor 97 de pasageri pentru aceastacursa sa nu depaseasca 2000kg?(c) Se aleg la întâmplare bagajele a 6 pasageri de la clasa economic si a 10 pasageri de la clasabusiness si se cântaresc. Care este probabilitatea ca diferenta maselor bagajelor dintre cele douaclase sa fie mai mica de 20kg?Exercitiu 3.5.11 Batoanele de ciocolata produse de o anumita firma cântaresc fiecare 50 g, cudeviatia standard 0.2 g. Se aleg la întâmplare doua loturi de batoane de ciocolata, fiecare având100 de bucati. Care este probabilitatea ca masele totale ale celor doua loturi sa nu difere prinmai mult de 5 g?Exercitiu 3.5.12 Presupunem ca timpul de asteptare a autobuzului în statie este o v.a. repartizataN (10, 2) pentru orele diminetii, iar timpul de asteptare a autobuzului în statie la orele serii esteo v.a. repartizata N (8, 1.5). Toti timpii sunt independenti între ei.(a) Daca într-o anumita saptamâna luati autobuzul în fiecare zi (5 zile lucratoare), care estetimpul total mediu pe care va asteptati sa-l petreceti în statia de autobuz în întreaga saptamâna?(b) Care este abaterea standard a timpului total petrecut în statia de autobuz în întreaga sap-tamâna?(c) Determinati valoarea medie si abaterea standard a diferentei dintre timpul total petrecutdimineata si timpul total petrecut seara în statia de autobuz în întreaga saptamâna?Exercitiu 3.5.13 Fie X1, X2, . . . , X10 o selectie repetata de volum 10 de v.a. repartizate U (0, 1).Gasiti media si deviatia standard pentru primele doua statistici de ordine, X(1) si X(2).Exercitiu 3.5.14 Variabilele aleatoare X1, X2, X3 sunt astfel încât X3 =X1+X2, X1∼ ξ 2(n1), X3∼ξ 2(n3) (n3 > n1). Daca, în plus, X1 si X2 sunt independente, aratati ca X2 ∼ ξ 2(n3−n1).

4. Notiuni din Teoria estimatiei
4.1 Estimatori punctuali. Definitii
În Matematica, suntem obisnuiti sa obtinem rezultate exacte pentru anumite calcule. Însa, demulte ori în practica, obtinerea unui rezultat exact este ori imposibila (numarul de stele dinUnivers), ori greu de realizat (distanta de la Pamânt la o anumita stea), ori fara utilitate (cantitateamedie exacta de ploaie cazuta într-o zi de toamna). De aceea, se pune problema de a estimavalorile unor parametri ai unei populatii de interes pe baza unor observatii.Sa presupunem ca avem un set de observatii aleatoare x1, x2, . . . , xn asupra unei caracteristiciX a unei populatii statistice. Legea de distributie (i.e., functia de probabilitate sau densitatea derepartitie) a caracteristicii X poate fi:
• complet specificata, de exemplu, X ∼U (0, 1);• specificata, dar cu macar un parametru necunoscut. De exemplu, X ∼P(λ ) sau X ∼
N (1, σ);• necunoscuta, caz în care se poate pune problema de a fi estimata.
În mod evident, în primul caz de mai sus nu avem nimic de estimat. Daca functia de probabili-tate (densitatea de repartitie) este deja cunoscuta, dar cel putin unul dintre parametrii sai estenecunoscut a priori, se pune problema sa estimam valoarea parametrilor de care aceasta depinde.Vom spune astfel ca avem o problema de estimare parametrica. În acest capitol, ne vom ocupade estimarea parametrilor unei repartitii date.Sa presupunem ca avem caracteristica X care urmeaza repartitia data de functia de probabilitate(sau densitate de repartitie) f (x, θ), unde θ este un parametru necunoscut. În general, acestparametru poate fi un vector (θ ∈Θ⊂ Rp), ale carui componente sunt parametrii repartitiei luiX . Mai sus, f este functia de probabilitate daca variabila aleatoare X este de tip discret, iar feste densitatea de repartitie a lui X , daca este o variabila aleatoare de tip continuu.Scopul teoriei estimatiei este de a evalua parametrii de care depinde f , folosind datele de selectiesi bazându-ne pe rezultatele teoretice prezentate în capitolele anterioare.Fie X1, X2, . . . , Xn variabile aleatoare de selectie repetata de volum n, ce urmeaza repartitia luiX . Presupunem totodata ca X admite medie si notam cu µ = E(X) si σ2 =Var(X).

74 Capitolul 4. Notiuni din Teoria estimatiei
(1) Se numeste functie de estimatie (punctuala) sau estimator al lui θ , o functie de selectie(statistica)
θ = θ(X1, X2, . . . , Xn),
cu ajutorul careia dorim sa îl aproximam pe θ . Uneori, acest estimator se mai noteaza si cu θn.Daca x1, x2, . . . , xn sunt date observate, atunci θ(x1, x2, . . . , xn) se numeste estimatie a lui θ .Asadar, o estimatie pentru un parametru necunoscut este valoarea estimatorului pentru selectiaobservata. Prin abuz de notatie, vom nota atât estimatorul cât si estimatia cu θ si vom facediferenta între ele prin precizarea variabilelor de care depind.
Ne-am dori sa stim în ce sens si cât de buna este aceasta aproximatie.(2) Fie θ un estimator pentru parametrul θ , bazat pe un esantion x1, x2, . . . , xn. Pentru un xkfixat, se numeste eroarea estimatorului θ de la parametrul θ cantitatea
ε(xk) = θ(xk)−θ .
Aceasta eroare depine de estimator si de esantion.
(3) O statistica θ este un estimator nedeplasat (en., biased estimator) pentru θ daca
E(θ) = θ , pentru orice valoare a lui θ .
Altfel, spunem ca θ este un estimator deplasat pentru θ , iar deplasarea (distorsiunea) se definesteastfel:
b(θ , θ) = E(θ)−θ = E(θ −θ) = E(ε).Astfel, b(θ , θ) este o masura a erorii pe care o facem în estimarea lui θ prin θ . Asadar, unestimator nedeplasat θ pentru un parametru necunoscut θ este o statistica care, în medie, iavaloarea parametrului θ .Exemplu 4.1.1 Dispersia de selectie modificata
S2 =1
n−1
n
∑i=1
[Xi−X ]2
este un estimator nedeplasat pentru dispersia teoretica σ2 =Var(X), iar dispersia de selectie
S2∗ =
1n
n
∑i=1
[Xi−X ]2
este un estimator deplasat pentru σ2 =Var(X), deplasarea fiind
b(s2, σ2) =−σ2
n.
(4) O alta masura a incertitudinii cu care un estimator aproximeaza parametrul este eroareastandard (en., standard error), notata aici prin σ(θ) sau σ
θ. Prin definitie,
σ(θ) =
√E[(θ −E(θ))2].
Spre exemplu, daca parametrul de estimat este µ si estimatorul µ este X , atunci
σX =σ√
n,

4.1 Estimatori punctuali. Definitii 75
unde σ este deviatia standard a unei singure observatii.Un estimator pentru eroarea standard (en., estimated standard error), notata aici prin σ(θ) sauσ
θsau s
θ. Spre exemplu, daca estimatorul θ este X , atunci un estimator pentru eroarea standard
estesX =
s√n,
unde s este estimatorul pentru deviatia standard.
(5) Numim eroare în medie patratica a unui estimator θ pentru θ (en., mean squared error)cantitatea
MSE(θ , θ) = E([
θ −θ]2)
.
Observatie 4.1.1 Putem scrie:
MSE(θ , θ) = E([
θ −E(θ)+E(θ)−θ]2)
= Var(θ)+2E([
θ −E(θ)] · [E(θ)−θ])
+
+ E([
E(θ)−θ]2)
= Var(θ)+0+(b(θ , θ))2.
Asadar, MSE pentru un estimator nedeplasat este Var(θ). Figura 4.1: Relatia dintre MSE,Var si b
(6) Fie θ1 si θ2 doi estimatori pentru θ . Atunci, valoarea
MSE(θ1, θ)
MSE(θ2, θ)
se numeste eficienta relativa (en., relative efficiency) a lui θ1 în raport cu θ2. Vom spune caun estimator θ1 este mai eficient decât θ2 daca MSE(θ1, θ) ≤ MSE(θ2, θ) pentru toate valorileposibile ale lui θ ∈Θ si MSE(θ1, θ)< MSE(θ2, θ) pentru macar un θ .
(7) Un estimator nedeplasat θ pentru θ , θ ∈Θ, se numeste estimator nedeplasat uniform dedispersie minima (en., Uniformly Minimum Variance Unbiased Estimator - UMVUE) daca pentruorice alt estimator nedeplasat pentru θ , notat cu θ ∗, avem
Var(θ)≤Var(θ ∗), ∀θ ∈Θ.
Spre exemplu, estimatorul µ = X este un UMVUE pentru parametrul µ .
(8) Estimatorul θ pentru θ este un estimator consistent daca
θ(X1, X2, . . . , Xn)prob−→ θ , când n−→ ∞.
În acest caz, valoarea numerica a estimatorului, θ(x1, x2, . . . , xn), se numeste estimatie consis-tenta pentru θ .Valoarea numerica a estimatorului, θ(x1, x2, . . . , xn), se numeste estimatie consistenta pentru θ .Spre exemplu, µ = X si S2 sunt estimatori consistenti pentru µ si σ2, respectiv.

76 Capitolul 4. Notiuni din Teoria estimatiei
Daca un anumit estimator da erori foarte mari, nu implica faptul ca estimatorul este deplasat. Pede alta parte, daca anumite erori pe care le da estimatorul sunt egale cu zero, nu înseamna caestimatorul este neaparat nedeplasat. Proprietatea de nedeplasare caracterizeaza media teoreticaa tuturor valorilor estimatorului. În mod ideal, ar fi de dorit ca estimatorul pentru un anumitparametru sa fie nedeplasat si de dispersie minima.
(9) Estimatorul θ pentru θ este un estimator absolut corect daca
(i) E(θ) = θ , ∀θ ∈Θ;(ii) lim
n→∞Var(θ) = 0.
În acest caz, valoarea numerica a estimatorului, θ(x1, x2, . . . , xn), se numeste estimatie absolutcorecta pentru θ .
(10) Estimatorul θ pentru θ este un estimator corect daca
(i) limn→∞
E(θ) = θ , ∀θ ∈Θ;
(ii) limn→∞
Var(θ) = 0.
În acest caz, valoarea numerica a estimatorului, θ(x1, x2, . . . , xn), se numeste estimatie corectapentru θ .
Propozitie 4.1.1 Statistica S2 = 1n−1
n
∑i=1
[Xi−X ]2 este un estimator absolut corect pentru σ2, iar
statistica V 2 = 1n
n
∑i=1
[Xi−X ]2 este un estimator corect, dar nu absolut corect, pentru σ2.
Demonstratie. Conform Propozitiei 3.1.2, avem ca
E(S2) = E
(1
n−1
n
∑i=1
[Xi−X ]2
)= σ
2,
Relatia (3.3.5) spune can−1σ2 S2 ∼ χ
2(n−1).
Folosind faptul ca dispersia unei variabile χ2(n−1) este 2(n−1), vom deduce ca
Var(
n−1σ2 S2
)=
(n−1)2
σ4 Var(S2) = 2(n−1),
de unde
Var(S2) =2σ4
n−1→ 0, când n→ ∞.
În mod similar,
E(V 2) = E
(1n
n
∑i=1
[Xi−X ]2
)=
n−1n
σ2 n→∞−→ σ
2,
Var(V 2) =2(n−1)σ4
n2 → 0, când n→ ∞.

4.2 Informatia Fisher 77
Propozitie 4.1.2 Daca θ este un estimator absolut corect pentru θ , atunci estimatorul esteconsistent.
Demonstratie. Utilizam inegalitatea lui Cebâsev în forma:
P(|θ −θ | ≤ ε)≥ 1− Var(θ)ε2 , ∀ε > 0. (4.1.1)
Tinând cont ca limn→∞
Var(θ) = 0 obtinem concluzia dorita.
Observatie 4.1.2 • În general, h(θ) 6= h(θ), i.e., o functie de estimator nu este totuna cuestimatorul functiei de parametru. În exemplul de mai jos, justificam faptul ca patratul unuiestimator θ pentru θ nu este, în general, estimator pentru θ 2.• Daca θ este un estimator pentru θ si h(x) este o functie bijectiva, atunci h(θ) = h(θ). Încazul în care h(x) nu este bijectiva, atunci relatia anterioara nu este neaparat valabila.• Presupunem ca X ∼N (0, 1) si avem urmatoarele 30 de observatii asupra lui X :
0.3617; -2.0587; -2.3320; -0.3709; 1.2857; 0.5570; -0.1802; -0.0357; 1.9344; 1.3056
0.0831; -0.3277; -0.3558; 0.4334; -1.2230; -1.0381; -2.7359; -0.0312; 2.0718; -0.5944
0.6286; -0.5350; 2.2090; -0.6057; 1.4352; 1.1948; 0.7431; -0.1214; 0.8678; -1.0030
Un estimator absolut corect pentru media teoretica a lui X , i.e., pentru µX = 0, este X .(pentru selectia data, X = 0.0521). Variabila aleatoare X2 urmeaza repartitia χ2(1) si are mediaµX2 = 1 (vezi repartitia χ2). Un estimator absolut corect pentru µX2 este X2. Pe de alta parte,pentru selectia data avem ca X2 ≈ 1.4755 iar
(X)2 ≈ 0.0027.
Asadar, în general X2 6=(X)2.
4.2 Informatia FisherDupa cum am vazut mai sus, un estimator θ pentru parametrul necunoscut θ trebuie sa aibaanumite proprietati pentru a putea fi util în estimarea parametrului dorit. Dintre acestea, oproprietate importanta este convergenta acestuia catre parametrul pe care îl estimeaza. Deasemenea, este de dorit ca estimatorul θ pentru θ sa fie nedeplasat, adica E
(θ)= θ .
Însa, pentru un anumit parametru pot exista mai multi estimatori absolut corecti. De exemplu,pentru parametrul λ din repartitia Poisson P(λ ) exista urmatorii estimatori: X si S2. Aceasta sedatoreaza faptului ca E(X) =Var(X) = λ .Daca ne restrângem la clasa estimatorilor nedeplasati, o întrebare naturala ar fi
Cum alegem pe cel mai bun estimator si pe ce criteriu?
Daca utilizam inegalitatea lui Cebîsev în forma (4.1.1), atunci ar fi firesc ca "cel mai bun estima-tor" sa fie cel de dispersie minima. În acest context, teorema Rao-Cramér ne va furniza o valoareminima tangibila pentru dispersia unui estimator nedeplasat.
Observatie 4.2.1 În Figura 4.2 am reprezentat printr-un pictorial câteva încercari de a nimerio tinta fixa, si anume, centrul unui disc, folosind o sageata de darts. Ne putem imagina tintafixa ca fiind un parametru de interes al caracteristicii unei populatii statistice, sageata de dartsca fiind estimatorul pentru acest parametru, iar locatiile unde unde sageata a lovit sa reprezinte

78 Capitolul 4. Notiuni din Teoria estimatiei
valori independente ale estimatorului (estimatii). Ideal ar fi sa nimerim cât mai aproape decentrul discului, adica locatiile unde sageata a lovit sa fie strâns grupate în jurul centrului. Dacatraducem în limbajul din teoria estimatiei, ar fi de dorit ca estimatorul ales sa fie nedeplasat si dedispersie mica, chiar minima, daca este posibil.
Figura 4.2: Estimatori deplasati/nedeplasati de dispersie mica/mare
(11) Consideram variabila aleatoare X ce are legea de distributie f (x,θ ) dependenta de para-metrii necunoscuti θ = (θ1, θ2, . . . ,θp), p ≥ 1. De asemenea, fie X1, X2, . . . , Xn variabilelealeatoare de selectie asociate.
Se numeste functie de verosimilitate (sau, simplu, verosimilitate), statistica (privita ca o functiede θ !)
L (X , θ) =n
∏k=1
f (Xk, θ).
Pentru Xk = xk, k = 1, 2, . . . , n, functia L (x, θ) (aici, x = (x1, x2, . . . , xn)) este densitatea derepartitie pentru vectorul aleator V = (X1, X2, . . . , Xn).
În continuare, vom considera doar cazul unui singur parametru, θ .Functia de verosimilitate reprezinta probabilitatea de a observa selectia data, stiind valorileparametrului. Intuitiv, prin maximizarea acestei functii, putem obtine valorile parametruluipentru care selectia observata are probabilitatea cea mai mare de a fi observata. Daca aceastafunctie de verosimilitate are anumite proprietati de regularitate, atunci punctele de maxim pentruL (X , θ) se vor afla printre solutiile ecuatiei
∂
∂θL (X ; θ) = 0 ⇐⇒ ∂
∂θlnL (X ; θ) = 0.
Sa notam ca, de cele mai multe ori, este mai usor de derivat logaritmul functiei de verosimilitatedecât functia însasi. Cantitatea l(X ; θ) = ∂
∂θlnL (X ; θ) se numeste scor. Dupa cum vom
observa mai jos, valoarea medie a acestui scor este 0. Astfel, daca θ este valoare de maxim afunctiei de verosimilitate, atunci scorul corespunzator acestei valori este zero.Pentru a determina cât de precisa este estimarea valorii reale a parametrului θ , ar fi util sa aveminformatii legate de curbura functiei de verosimilitate în jurul valorii maxime. Astfel, daca ea

4.2 Informatia Fisher 79
este mare, atunci avem o anumita certitudine ca valoarea obtinuta este de extrem, iar daca estemica, atunci avem o incertitudine în ce priveste valoarea de extrem. O masura probabilistica acurburii functiei de verosimilitate în jurul valorii critice este dispersia acestui scor. Dispersiascorului se numeste informatie Fisher. Vom vedea în propozitia urmatoare forme echivalente aleacestei informatii, care în alte materiale sunt considerate drept definitii.
(12) Presupunem ca X1, X2, . . . , Xn este o selectia repetata de volum n pentru variabila X ,definita prin legea de distributie f (X , θ), iar functia lnL (X ; θ) este de clasa C1 în θ . Urmatoareaexpresie,
In(θ) =Var(
∂
∂θlnL (X ; θ)
), (4.2.2)
se numeste informatie Fisher bazata pe selectia respectiva.
Din punct de vedere practic, informatia Fisher reprezinta cantitatea de informatie pe care ocontine selectia repetata X1, X2, . . . , Xn relativa la un parametru necunoscut al unei repartitiice modeleaza caracteristica X a unei populatii.Propozitia urmatoare ne furnizeaza trei egalitati bazate pe informatia Fisher.
Propozitie 4.2.1 În ipotezele de mai sus, avem:
(1) E(
∂
∂θlnL (X ; θ)
)= 0. Astfel, In(θ) = E
([∂
∂θlnL (X ; θ)
]2)
; n≥ 1,
(2) In(θ) =−E(
∂ 2
∂θ 2 lnL (X ; θ)
); n≥ 1,
(3) In(θ) = nI1(θ) =−nE(
∂ 2
∂θ 2 ln f (X ; θ)
); n≥ 1.
Demonstratie. (1) Din faptul ca L (x; θ) este o densitate de repartitie în Rn, avem ca∫Rn
L (x; θ)dx = 1, unde dx = dx1dx2 . . .dxn.
Prin derivarea acestei relatii, obtinem ca
∂
∂θ
∫Rn
L (x; θ)dx =∫Rn
∂
∂θL (x; θ)dx
=∫Rn
[∂
∂θlnL (x; θ)
]L (x; θ)dx (4.2.3)
= E(
∂
∂θlnL (X ; θ)
)= 0.
Folosind definitia dispersiei, gasim prima formula echivalenta pentru In(θ).(2) Prin derivarea relatiei (4.2.3) în raport cu θ , gasim ca∫
Rn
[(∂ 2
∂θ 2 lnL (x; θ)
)L (x; θ)+
(∂
∂θlnL (x; θ)
)∂
∂θL (x; θ)
]dx = 0,

80 Capitolul 4. Notiuni din Teoria estimatiei
echivalent cu∫Rn
[(∂ 2
∂θ 2 lnL (x; θ)
)L (x; θ)+
(∂
∂θlnL (x; θ)
)2
L (x; θ)
]dx = 0,
sau ∫Rn
[(∂ 2
∂θ 2 lnL (x; θ)
)+
(∂
∂θlnL (x; θ)
)2]
L (x; θ)dx = 0,
de unde E(
∂ 2
∂θ 2 lnL (X ; θ)
)+ In(θ) = 0.
(3) Relatia (3) spune ca informatia Fisher continuta într-un esantion de volum n este de n oriinformatia Fisher continuta într-o singura observatie.Plecând de la (1), avem sirul de egalitati:
In(θ) = E
([∂
∂θlnL (X ; θ)
]2)
= E
[ n
∑k=1
∂
∂θln f (Xk; θ)
]2
= E
(n
∑k=1
[∂
∂θln f (Xk; θ)
]2
+2 ∑1≤i< j≤n
∂
∂θln f (Xi; θ) · ∂
∂θln f (X j; θ)
)
= E
(n
∑k=1
[∂
∂θln f (Xk; θ)
]2)+2 ∑
1≤i< j≤nE(
∂
∂θln f (Xi; θ)
)·E(
∂
∂θln f (X j; θ)
)
=n
∑k=1
E
([∂
∂θln f (Xk; θ)
]2)+0
= nI1(θ).
Aici, am folosit faptul ca f (x; θ) este o functie de masa (densitate de repartitie), de unde (similar
cu punctul (1)), deducem ca E(
∂
∂θln f (Xk; θ)
)= 0, ∀k.
Dupa cum mentionam mai sus, teorema Rao-Cramér ne furnizeaza o valoare minima tangibilapentru dispersia unui estimator nedeplasat. Rezultatul este valabil pentru conditii de regularitategenerale.
Teorema 4.2.2 (Rao1- Cramér2)Consideram caracteristica X cu legea de distributie (functia de probabilitate sau densitatea derepartitie) f (x, θ), astfel încât suppθ = x, f (x; θ)> 0 este independent de θ , iar ∂ f (x;θ)
∂θexista
si este finita. Consideram θ = θ(X1, X2, . . . , Xn), un estimator nedeplasat pentru θ . Atunci,
Var(θ)≥ 1In(θ)
. (4.2.4)

4.2 Informatia Fisher 81
Demonstratie. Vom calcula covarianta dintre estimatorul nedeplasat θ si V (θ)not= ∂
∂θlnL (X ; θ).
Reamintim faptul ca am demonstrat anterior urmatorul rezultat:
E(V (θ)) = E(
∂
∂θlnL (X ; θ)
)= 0.
Atunci,cov(θ ,V (θ)) = E(θ ·V (θ))−E(θ) ·E(V (θ)) = E(θ ·V (θ)),
de unde
cov(θ ,V (θ)) =∫Rn
θ(x)(
∂
∂θlnL (x; θ)
)L (x, θ)dx
=∫Rn
θ(x)(
1L (x; θ)
∂
∂θL (x; θ)
)L (x, θ)dx
=∂
∂θ
(∫Rn
θ(x)L (x, θ)dx)
=∂
∂θ
(E(θ)
)=
∂θ
∂θ= 1.
Aplicam inegalitatea Cauchy-Schwarz:
1 = [cov(θ ,V (θ))]2 = [cov(θ −θ ,V (θ))]2
= [E((θ −θ) ·V (θ))]2 ≤ E((θ −θ)2) ·E(V (θ)2)
= Var(θ) ·Var(V (θ)) =Var(θ) · In(θ),
de unde concluzia.
Observatie 4.2.2 I. Din relatia (4.2.4), deducem ca minimizarea dispersiei unui estimatorînseamna, de fapt, maximizarea informatiei pe care o detinem relativa la parametrul estimat.Acest fapt ajuta în proiectarea statistica optima a experimentelor (eng., optimal experimentaldesign).II. Daca estimatorul θ este un estimator posibil deplasat pentru θ , cu E(θ) = s(θ), unde s(x)este o functie derivabila, atunci inegalitatea Rao- Cramér devine:
Var(θ)≥ (s′(θ))2
In(θ). (4.2.5)
(13) Numim eficienta unui estimator absolut corect θ pentru θ , valoarea:
e(θ) =I−1n (θ)
Var(θ). (4.2.6)
(14) Un estimator nedeplasat θ pentru θ se numeste estimator eficient daca e(θ) = 1, adica
Var(θ) = I−1n (θ).
Exemplu 4.2.1 Fie X ∼P(λ ), cu λ > 0, si Xknk=1 variabilele aleatoare de selectie de volum
n. Atunci, X =1n
n
∑k=1
Xk este un estimator eficient pentru parametrul λ .

82 Capitolul 4. Notiuni din Teoria estimatiei
R: Functia de masa pentru X este
f (x, λ ) = e−λ λ x
x!, x ∈ N.
Avem ca E(X) = E(X) = λ (X nedeplasat) si Var(X) =σ2
Xn
=λ
n. Pentru a calcula informatia
Fisher, scriem:
ln f (x, λ )=−λ +x lnλ− ln(x!),∂
∂λln f (x, λ )=−1+
xλ,
∂ 2
∂λ 2 ln f (x, λ )=− xλ 2 , x∈N,
de unde
In(λ ) = nI1(λ ) =−nE[
∂ 2
∂λ 2 ln f (X , λ )
]= n
EXλ 2 =
nλ.
Cum Var(X) = I−1n (λ ), deducem ca e(X) = 1, deci X este un estimator eficient pentru λ .
(15) Vom spune ca o statistica T = T (X1, X2, . . . , Xn) este statistica suficienta (sau exhaustiva)pentru (a face inferente referitoare la) parametrul necunoscut θ al unei populatii, daca repartitiavectorului de selectie V = (X1, X2, . . . , Xn) conditionata de evenimentul T = t nu depinde de θ ,pentru orice valoare a lui t. O teorema de caracterizare este urmatoarea:
Propozitie 4.2.3 (teorema de factorizare Fisher3-Neyman4)Consideram variabila aleatoare X si Xk, k = 1, 2, . . . , n variabile aleatoare de selectie devolum n. Fie L (x) = L (x1, x2, . . . , xn; θ) densitatea de repartitie comuna a acestor variabile deselectie. Atunci, statistica T = T (X1, X2, . . . , Xn) este o statistica suficienta pentru parametrulnecunoscut θ daca si numai daca L (x) = L (x1, x2, . . . , xn; θ) se poate scrie în forma:
L (x; θ) = g(x)h(T (x), θ), (4.2.7)
unde g : Rn→ R+ este o functie ce nu depinde de θ , iar functia h : R×R→ R+ depinde deobservatii doar prin intermediul lui T (x).
Functiile g si h nu sunt unice. Mai mult, statistica suficienta nu este unica. Din punct de vederepractic, o statistica este suficienta pentru un parametru θ daca aceasta statistica contine toatainformatia relevanta despre θ ce se poate obtine din selectia considerata. Cu alte cuvinte, pentrua estima un anumit parametru este suficienta cunoasterea unei statistici suficiente, nefiind nevoiede întreaga selectie.Exemplu 4.2.2 Fie X ∼P(λ ), cu λ > 0, si Xkn
k=1 variabilele aleatoare de selectie de volum
n. Atunci, statistica S(X) =n
∑k=1
Xk este o statistica suficienta pentru parametrul λ .
R: Functia de masa pentru X este
f (x, λ ) = e−λ λ x
x!, x ∈ N.
Atunci, functia de masa comuna a variabilelor de selectie este
L (x; λ ) =n
∏k=1
(e−λ λ xk
xk!
)=
1∏
nk=1 xk!
e−nλλ ∑
nk=1 xk = g(x)h(S(x), λ ),

4.3 Metoda verosimilitatii maxime 83
unde g(x) = (∏nk=1 xk!)−1.
În continuare, discutam urmatoarele metode de estimare punctuala a parametrilor:• metoda verosimilitatii maxime;• metoda momentelor;• metoda minimului lui χ2;• metoda celor mai mici patrate;• metoda intervalelor de încredere.
4.3 Metoda verosimilitatii maximeFie caracteristica X studiata, care are legea de distributie f (x; θ) (unde θ = (θ1,θ2, . . . , θp) suntparametri necunoscuti). Sa presupunem ca avem n observatii asupra caracteristicii X , adica amales o selectie de date,
x1, x2, . . . , xn.
Fie X1, X2, . . . , Xn variabilele aleatoare de selectie repetata de volum n.
Definitie 4.3.1 (1) Numim estimator de verosimilitate maxima (maximum likelihood estimator)pentru θ o statistica θ = θ(X1, X2, . . . , Xn) pentru care se obtine valoarea maxima a functiei deverosimilitate,
L (X ; θ) =n
∏k=1
f (Xk, θ).
(2) Valoarea unei astfel de statistici pentru o observatie data se numeste estimatie de verosimili-tate maxima pentru θ .
Observatie 4.3.1 Aceasta metoda estimeaza "valoarea cea mai verosimila" pentru parametrul θ .
Nu este necesar ca∂L
∂θsa existe pentru ca estimatorul de verosimilitate maxima sa fie calculat.
Daca aceasta exista, atunci acest estimator se obtine ca solutia θ a sistemului de ecuatii:
∂L (X ; θ)
∂θk= 0, k = 1, 2, . . . , p, (4.3.8)
care este echivalent cu urmatorul sistem:
∂ lnL (X ; θ)
∂θk=
n
∑i=1
∂ ln f (Xi; θ)
∂θk= 0, k = 1, 2, . . . , p. (4.3.9)
Propozitie 4.3.1 (consistenta)Un estimator MLE pentru converge în probabilitate la parametrul pe care îl estimeaza, i.e.,
θprob−→ θ , când n→ ∞..
Propozitie 4.3.2 (principiul invariantei)Fie θ1, θ2, . . . , θp estimatori MLE pentru setul de parametri θ1, θ2, . . . , θp, respectiv. Atunci,estimatorul de verosimilitate maxima pentru orice functie h(θ1, θ2, . . . , θp) este h(θ1, θ2, . . . , θp).

84 Capitolul 4. Notiuni din Teoria estimatiei
Observatie 4.3.2 Din pacate, daca θ este un estimator nedeplasat de verosimilitate maximapentru θ , atunci estimatorul de verosimilitate maxima h(θ) pentru h(θ) nu mai este neaparatnedeplasat. Spre exemplu, X este un estimator nedeplasat de verosimilitate maxima pentru µX ,dar(X)2 este un estimator deplasat pentru amedia lui X2, µX2 .
Propozitie 4.3.3 (distributia asimptotica a unui estimator MLE)Fie X1, X2, . . . , Xn variabilele aleatoare de selectie pentru o caracteristica X ce este definita prinlegea f (x, θ), unde θ este un parametru necunoscut. Daca θ este un estimator de verosimilitatemaxima pentru θ , atunci, pentru un n suficient de mare, avem ca:
θ ∼N
(θ ,
1√In(θ)
).
Aceasta relatie este echivalenta cu
√n(θ −θ
)∼N
(0,
1√I1(θ)
), n 1.
Spre exemplu, daca θ = µ < ∞ este parametrul necunoscut, atunci θ = X . Daca σ este cunoscut,atunci In(µ) =
nσ2 , de unde
X ∼N
(µ,
σ√n
), n≥ 30.
Exemplu 4.3.1 Tabelul de mai jos contine numarul de pesti pescuiti într-o singura ora de oselectie aleatoare de 30 de pescari amatori.
nr. pesti/ora (xk) 0 1 2 3 4 5 ≥ 6frecventa (nk) 2 3 5 7 9 4 0
Se presupune ca numarul de pesti pescuiti de o persoana într-o singura ora este o variabilaPoisson. Estimati parametrul distributiei Poisson folosind metoda verosimilitatii maxime si apoiaflati valoarea acestui estimator pentru esantionul dat.R: Pentru X ∼P(λ ), probabilitatea asociata valorii k ∈ N este
pk(λ ) = e−λ λ k
k!, k = 0, 1, 2, . . . .
Pentru un esantion x1, x2, . . . , xn, functia de verosimilitate este
L (λ ) =n
∏k=1
e−λ λ xk
xk!= e−nλ λ ∑
nk=1 xk
∏nk=1 xk!
,
de unde
lnL (λ ) =−nλ +
(n
∑k=1
xk
)lnλ − ln
(n
∏k=1
xk!
).
Atunci,∂
∂λlnL (λ ) =−n+
∑nk=1 xk
λ= 0 =⇒ λ =
1n
n
∑k=1
xk = x = 3.
Se observa ca∂ 2
∂λ 2 lnL (λ ) |λ=x =−nx< 0,
deci avem o valoare de maxim pentru verosimilitate.

4.4 Metoda momentelor (K. Pearson) 85
4.4 Metoda momentelor (K. Pearson)În anumite cazuri, valorile critice pentru functia de verosimilitate sunt dificil de calculat. Deaceea, e nevoie de alte metode pentru a gasi estimatori pentru parametri.Fie caracteristica X care are legea de distributie f (x; θ) (unde θ= (θ1,θ2, . . . , θp) sunt parametrinecunoscuti) ce admite momente pâna la ordinul p (adica, αp = E(X p)< ∞). Dorim sa gasimestimatori (estimatii) punctuale ale parametrilor necunoscuti. Pentru aceasta, efectuam observatiiasupra caracteristicii, adica alegem o selectie de date,
x1, x2, . . . , xn.
Fie X1, X2, . . . , Xn variabilele aleatoare de selectie repetata de volum n. Metoda momentelorconsta în estimarea parametrilor necunoscuti din conditiile ca momentele initiale de selectie safie egale cu momentele initiale teoretice respective, ale lui X . Aceasta înseamna ca avem derezolvat un sistem de ecuatii în care necunoscutele sunt parametrii ce urmeaza a fi estimati.
Definitie 4.4.1 Numim estimator (punctual) pentru θ obtinut prin metoda momentelor solutiaθ = (θ1, θ2, . . . , θp) (aici θk = θk(X1, X2, . . . , Xn), k = 1, 2, . . . , p) a sistemului:
α1(X) = α1(X), (4.4.10)α2(X) = α2(X),
...α p(X) = αp(X),
unde αk(X) sunt momentele de selectie de ordin k pentru X ,
αk(X) =1n
n
∑i=1
Xki ,
iar αk(X) sunt momentele teoretice pentru X (care depind de θ), adica:
αk = E(Xk), k = 1, 2, . . . , p.
O estimatie (punctuala) pentru θ va fi o realizare a estimatorului θ = (θ1, θ2, . . . , θp), undecomponentele sunt θk = θk(x1, x2, . . . , xn), k = 1, 2, . . . , p).
Observatie 4.4.1 Aceasta metoda este fundamentata teoretic pe faptul ca momentele de selectiesunt estimatori absolut corecti pentru momentele teoretice corespunzatoare. Metoda nu poate fiaplicata repartitiilor care nu admit medie (e.g., repartitia Cauchy).Exemplu 4.4.1 Estimati parametrul λ din Exemplul 4.3.1 prin metoda momentelor.R: Egalând primul moment empiric cu media teoretica, obtinem ca x = λ , de unde λ = x = 3.
Exemplu 4.4.2 Estimati media si dispersia unei repartitii N (µ, σ) prin metoda momentelor.R: Deoarece avem doi parametri, vom avea de rezolvat sistemul de ecuatii
α1(X) = α1(X) si α2(X) = α2(X),
de unde
X = µ si1n
n
∑i=1
X2i = E(X2).

86 Capitolul 4. Notiuni din Teoria estimatiei
Dar, σ2 = E(X2)− (EX)2. Astfel, estimatorii pentru µ si σ2 obtinuti prin metoda momentelorsunt
µ = X si σ2 =1n
n
∑i=1
X2i −
(1n
n
∑i=1
Xi
)2
=1n
n
∑i=1
[Xi−X
]2.
4.5 Metoda celor mai mici patrateEste o metoda de estimare a parametrilor în cazul modelelor liniare, adica atunci când avemun set de variabile aleatoare Yi, i = 1, 2, . . . , n, ce depind liniar de parametrii necunoscuti. Fieθ = (θ1, θ2, . . . , θp) vectorul ce contine parametrii necunoscuti si presupunem ca Yi depind deacestia dupa urmatorul sistem:
Yi =p
∑j=1
xi jθ j + εi, i = 1, 2, . . . , n, (4.5.11)
sau, scris sub forma matriceala:
Y = X ·θ+ε, X = (xi j) ∈ Rn×p.
Variabilele aleatoare εi sunt erori, despre care presupunem ca:
E(εi) = 0Var(εi) = σ
2, i = 1, 2, . . . , n;cov(εi, ε j) = 0, ∀i 6= j. (4.5.12)
Metoda celor mai mici patrate consta în determinarea parametrilor θi astfel încât suma patratelorerorilor sa fie minima. Asta înseamna ca avem de rezolvat problema de minim:
minθ
n
∑i=1
ε2i = min
θ
n
∑i=1
(Yi−
p
∑j=1
xi jθ j
)2
.
Astfel, un estimator θ = (θ1, θ2, . . . , θp) prin metoda celor mai mici patrate este solutiasistemului:
∂
∂θk
n
∑i=1
(Yi−
p
∑j=1
xi jθ j
)2
= 0, k = 1, 2, . . . , p,
echivalent,n
∑i=1
p
∑j=1
xikxi jθ j =n
∑i=1
xikYi, k = 1, 2, . . . , p.
Ultimul sistem poate fi scris sub forma matriceala:
X′ ·X ·θ = X′ ·Y,
de unde gasim ca estimatorul θ este
θ = (X′ ·X)−1 ·X′ ·Y.

4.6 Metoda minimului lui χ2 87
Exemplu 4.5.1 Fie X o caracteristica ce admite medie, µ =E(X), si fie X1, X2, . . . , Xn variabilelealeatoare de selectie repetata de volum n. Statistica µ = X este estimatorul obtinut prin metodacelor mai mici patrate pentru media teoretica µ , adica este solutia problemei de minimizare
minµ
n
∑i=1
(Xi−µ)2. (4.5.13)
R: Deoarece µ este media variabilelor aleatoare de selectie, putem considera ca fiecare variabilao putem scrie sub forma
Xi = µ + εi, i = 1, 2, . . . , n, (4.5.14)
cu εi satisfacând conditiile (4.5.12). Solutia problemei (4.5.13) este solutia ecuatiei
∂
∂ µ
n
∑i=1
(Xi−µ)2 = 0,
adica
µ =1n
n
∑i=1
Xi.
Se observa ca derivata a doua în raport cu µ este 2n > 0, deci valoarea extrema obtinuta este deminim.Exemplu 4.5.2 Estimati parametrul λ din Exemplul 4.3.1 prin metoda celor mai mici patrate.R: Suma patratelor erorilor va fi
30
∑k=1
(xk−µ)2 = 2(0−µ)2 +3(1−µ)2 +5(2−µ)2 +7(3−µ)2 +9(4−µ)2 +4(5−µ)2
= 30[(µ−3)2 +2].
Valoarea minima se obtine pentru µ = 3.
4.6 Metoda minimului lui χ2
Consideram caracteristica X ce urmeaza a fi studiata, ce urmeaza legea de probabilitate data def (x, θ), unde θ = (θ1, θ2, . . . , θp) ∈ Θ ⊂ Rp sunt parametri necunoscuti. Fie X1, X2, . . . , Xn
variabilele aleatoare de selectie repetata de volum n. Pentru a obtine un estimator θ prin metodaminimului lui χ2 pentru θ, procedam dupa cum urmeaza.Descompunem multimea valorilor lui X , X(Ω), în clase, astfel:
X(Ω) =κ⋃
i=1
Oi, Oi⋂
O j =∅, ∀i 6= j.
Construim evenimentele
Ai = ω(n) ∈Ω(n); X(ωi) ∈ Oi, i = 1, 2, . . . , κ.
Se observa cu usurinta ca
Ω(n) =
κ⋃i=1
Ai, Ai⋂
A j =∅, ∀i 6= j.

88 Capitolul 4. Notiuni din Teoria estimatiei
Notam cupi(θ) = P(n)(Ai), i = 1, 2, . . . , κ,
i.e., probabilitatea ca un individ luat la întâmplare sa apartina clasei Oi. Atunci,
κ
∑i=1
pi(θ) = 1.
Mai facem urmatoarele notatii:− ni = frecventa absoluta a evenimentului Ai în orice selectie repetata de volum n;− Ni = variabilele aleatoare de selectie corespunzatoare lui ni (i = 1, 2, . . . , κ).Observatie 4.6.1 Vectorul aleator N = (N1, N2, . . . , Nκ) urmeaza o repartitie multinomiala deparametri pi(θ), i = 1, 2, . . . , κ , i.e.,
P((N1, N2, . . . , Nκ) = (n1, n2, . . . , nκ)) =n!
n1!n2! · . . . ·nκ !p1(θ)
n1 · p2(θ)n2 · . . . · pκ(θ)
nκ .
Definitie 4.6.1 Statistica θ se numeste estimator obtinut prin metoda minimului lui χ2 pentru θdaca θ este solutie a problemei de minim
minθ
κ
∑i=1
[Ni−n · pi(θ)]2
n · pi(θ)
= min
θ
κ
∑i=1
[observate în clasa i− asteptate în clasa i]2
asteptate în clasa i
.
Propozitie 4.6.1 Repartitia urmatoarei statistici este
κ
∑i=1
[Ni−n · pi(θ)]2
n · pi(θ)∼ χ
2(κ− p−1).
Exemplu 4.6.1 Estimati parametrul λ din Exemplul 4.3.1 prin metoda minimului lui χ2.R: Aici avem κ = 7 clase. Pentru a estima pe λ prin metoda minimului lui χ2, avem deminimizat statistica
H(λ ) =κ
∑k=1
[nk−n · pk(λ )]2
n · pk(λ )=
[2−30 · e−λ λ 0
0! ]2
30 · e−λ λ 0
0!
+[3−30 · e−λ λ 1
1! ]2
30 · e−λ λ 1
1!
+[5−30 · e−λ λ 2
2! ]2
30 · e−λ λ 2
2!
+
+[7−30 · e−λ λ 3
3! ]2
30 · e−λ λ 3
3!
+[9−30 · e−λ λ 4
4! ]2
30 · e−λ λ 4
4!
+[4−30 · e−λ λ 5
5! ]2
30 · e−λ λ 5
5!
+
+[0−30 · (1−∑
5k=0 e−λ λ k
k! )]2
30 · (1−∑5k=0 e−λ λ k
k! )
=eλ
30λ 5 (1920+1944λ +294λ2 +50λ
3 +9λ4 +4λ
5)−30.
Punctul critic pozitiv al lui H(λ ) este λ = 3.17952, care este un punct de minim.Reamintim faptul ca estimatorul obtinut prin primele trei metode este λ = x = 3. Daca se va doria testa ipoteza ca X ∼P(λ ) folosind testul χ2 al lui Pearson, atunci estimatorul dat de metodaminimului lui χ2 va fi un candidat mai bun decât x.

4.7 Intervale de încredere 89
4.7 Intervale de încredere4.7.1 O singura selectie
Sa consideram o caracteristica X a carei lege de probabilitate este data de f (x, θ), cu θ parametrunecunoscut. Pentru a estima valoarea reala a lui θ , efectuam n observatii, obtinând selectia:
x1, x2, . . . , xn.
Dupa cum am vazut anterior, putem gasi o estimatie punctuala a parametrului, θ(x1, x2, . . . , xn).Însa, o estimatie punctuala nu ne precizeaza cât de aproape se gaseste estimatia θ(x1, x2, . . . , xn)fata de valoarea reala a parametrului θ . De exemplu, daca dorim sa estimam masa medie a unorproduse alimentare fabricate de o anumita masina, atunci putem gasi un estimator punctual (e.g.,media de selectie) care sa ne indice ca aceasta este de 500 de grame. Ideal ar fi daca aceastainformatie ar fi prezentata sub forma: masa medie este 500g±10g.Putem obtine astfel de informatii daca vom construi un interval în care, cu o probabilitate destulde mare, sa gasim valoarea reala a lui θ .Sa consideram o selectie repetata de volum n, X1, X2, . . . , Xn, ce urmeaza repartitia lui X . Dorimsa gasim un interval aleator care sa acopere cu o probabilitate mare (e.g., 0.95, 0.98, 0.99 etc)valoarea posibila a parametrului necunoscut.
Definitie 4.7.1 Fie α ∈ (0, 1), foarte apropiat de 0 (de exemplu, α = 0.01, 0.02, 0.05 etc).Numim interval de încredere (en., confidence interval) pentru parametrul θ cu probabilitatea deîncredere 1−α , un interval aleator (θ , θ), astfel încât
P(θ < θ < θ) = 1−α, (4.7.15)
unde θ(X1, X2, . . . , Xn) si θ(X1, X2, . . . , Xn) sunt statistici.Pentru o observatie ω(n) fixata, capetele intervalului (aleator) de încredere vor fi functii devalorile de selectie. De exemplu, pentru datele observate, x1, x2, . . . , xn, intervalul(
θ(x1, x2, . . . , xn), θ(x1, x2, . . . , xn))
se numeste valoare a intervalului de încredere pentru θ . Pentru simplitate însa, vom folositermenul de "interval de încredere" atât pentru intervalul propriu-zis, cât si pentru valoareaacestuia, întelesul desprinzându-se din context.Valoarea α se numeste nivel de semnificatie sau probabilitate de risc.
Observatie 4.7.1 (1) Relatia (4.7.15) se citeste astfel: “probabilitatea cu care intervalul(θ , θ) acopera valoare lui θ este 1−α”. Exprimarea “probabilitatea cu care θ se afla înintervalul (θ , θ) este 1−α” este gresita, deoarece θ este o constanta, intervalul aleator variaza.(2) Pentru a determina un interval de încredere, metoda de lucru este dupa cum urmeaza: se vaconsidera o statistica S(X1, X2, . . . , Xn; θ), convenabil aleasa, care sa urmeze o lege cunoscuta siindependenta de θ . Sa notam cu g(s) aceasta repartitie. Se determina apoi valorile s1 si s2 (caredepind de α), astfel încât
P(s1 < S < s2) =
s2∫s1
g(s)ds = 1−α. (4.7.16)

90 Capitolul 4. Notiuni din Teoria estimatiei
Cum statistica S depinde de θ , relatia (4.7.16) determina un interval aleator (θ , θ) ce satisface(4.7.15). Intervalul de încredere variaza de la o selectie la alta.
Cu cât α este mai mic (de regula, α = 0.01 sau 0.02 sau 0.05), cu atât sansa (care este (1−α) ·100%) ca valoarea reala a parametrului θ sa se gaseasca în intervalul gasit este mai mare.Desi sansele 99% sau 99.99% par a fi foarte apropiate si ar da rezultate asemanatoare, suntcazuri în care fiecare sutime conteaza. De exemplu, sa presupunem ca într-un an calendaristic uneveniment are sansa de 99% de a se realiza, în orice zi a anului, independent de celelalte zile.Atunci, sansa ca acest eveniment sa se realizeze în fiecare zi a anului în tot decursului acestuian este de 0.99365 ≈ 2.55%. Daca sansa de realizare în fiecare zi ar fi fost de 99.99%, atuncirezultatul ar fi fost 0.9999365 ≈ 96.42%, ceea ce înseamna o diferenta foarte mare generata de odiferenta initiala foarte mica.Intervalul de încredere pentru valoarea reala a unui parametru nu este unic. Daca ni se dauconditii suplimentare (e.g., fixarea unui capat), atunci putem obtine intervale infinite la un capatsi finite la celalalt capat.
Dupa cum se observa din Figura 4.3, se poate în-tâmpla ca un interval de încredere generat sa nucontina valoarea pe care acesta ar trebui sa o esti-meze. Aceasta nu contrazice teoria, deoarece pro-babilitatea cu care valoarea estimata este acoperitade intervalul de încredere este
P(
µ < µ < µ
)= 1−α 6= 1,
deci exista sanse de a gresi în estimare, în cazul defata de 100α%.
Figura 4.3: 50 de realizari ale interva-lului de încredere pentru µ
În continuare, vom cauta intervale de încredere pentru parametrii unor caracteristici normale.Daca θ este un parametru necunoscut, atunci se va determina, mai întâi, un estimator punctual θ
pentru θ . Apoi, un interval de încredere pentru θ va fi de forma[θ −qα · sθ
, θ +qα · sθ
],
unde qα este o cuantila de ordin α pentru repartitia folosita în determinarea intervalului de încre-dere, iar s
θeste estimarea erorii standard a estimatorului θ . În cazuri speciale (toti parametrii
ce intra în formula de calcul a erorii estimatorului sunt cunoscuti), sθ= σ
θeste chiar eroarea
standard a estimatorului.
Interval de încredere pentru medie, când dispersia este cunoscuta
Fie X ∼ N (µ, σ) caracteristica unei populatii statistice, unde µ este necunoscut si σ estecunoscut. Pentru a construi un interval de încredere pentru media teoretica µ , efectuam o selectierepetata de volum n si fixam nivelul de încredere 1−α ≈ 1, α ∈ (0, 1). Alegem urmatoareastatistica:
Z =X−µ
σ√n
∼N (0, 1) (conform Propozitiei 3.3.3). (4.7.17)

4.7 Intervale de încredere 91
Putem determina un interval numeric (z1, z2) astfel încât
P(z1 < Z < z2) = Θ(z2)−Θ(z1) = 1−α, (4.7.18)
unde Θ : R→ [0, 1] este functia lui Laplace,
Θ(x) =1√2π
∫ x
−∞
e−y22 dy. (4.7.19)
De îndata ce intervalul (z1, z2) este determinat, putem scrie:
P
z1 <X−µ
σ√n
< z2
= 1−α,
echivalent cu
P(
X− z2σ√
n< µ < X− z1
σ√n
)= 1−α,
de unde intervalul de încredere pentru µ cu nivelul de semnificatie (1−α) este
(µ, µ) =
(X− z2
σ√n, X− z1
σ√n
).
Mai ramâne de stabilit cum determinam valorile z1 si z2. Distingem trei cazuri:(1) Daca nu se cunoaste o alta informatie suplimentara despre µ , atunci alegem (z1, z2) ca
fiind interval de lungime minima pentru α fixat. Aceasta se obtine când z1 =−z2 (veziObservatia 4.7.2), de unde:
Θ(z2)−Θ(−z2) = 1−α.
Tinând cont ca Θ(−z) = 1−Θ(z), ultima relatie se reduce la
Θ(z2) = 1− α
2,
de unde gasim pe z2 ca fiind cuantila de ordin 1− α
2 , si anume z1−α
2.
Asadar,z1 =−z1−α
2, z2 = z1−α
2,
si intervalul de încredere pentru media teoretica µ când σ este cunoscut este:
(µ, µ) =
(X− z1−α
2
σ√n, X + z1−α
2
σ√n
). (4.7.20)
(2) Daca pentru media teoretica nu se precizeaza o limita superioara, atunci în (4.7.18) alegintervalul aleator (z1, z2) de forma (−∞, z2). Înlocuind în (4.7.18) obtinem:
P(−∞ < Z < z2) = Θ(z2)−Θ(−∞)︸ ︷︷ ︸= 0
= 1−α,
de unde z2 = z1−α . În acest caz, intervalul de încredere este:

92 Capitolul 4. Notiuni din Teoria estimatiei
(µ, ∞) =
(X− z1−α
σ√n, ∞
).
(3) Daca pentru media teoretica nu se precizeaza o limita inferioara, atunci în (4.7.18) alegintervalul aleator (z1, z2) de forma (z1, ∞). Înlocuind în (4.7.18) obtinem:
P(z1 < Z < ∞) = Θ(∞)︸ ︷︷ ︸= 1
−Θ(z1) = 1−α,
de unde z1 = zα =−z1−α . În acest caz, intervalul de încredere este:
(−∞, µ) =
(−∞, X + z1−α
σ√n
).
Observatie 4.7.2 În cazul (1) de mai sus, am ales intervalul aleator de lungime minima, undeaceasta lungime este
l =σ√
n(z2− z1).
Pentru a gasi acest interval, avem de rezolvat problema:min
σ√
n(z2− z1)
z2∫
z1
g(z)dz = 1−α,
unde g este densitatea de repartitie pentru N (0, 1).Pentru a o rezolva, folosim metoda multiplicatorilor lui Lagrange. Fie functia
L(z1, z2; λ ) =σ√
n(z2− z1)+λ
(∫ z2
z1
g(z)dz+α−1). (4.7.21)
Dorim sa aflam z1 si z2 ce realizeaza minL(z1, z2; λ ). Acestea sunt solutiile sistemului:
∂L∂ z1
= 0
∂L∂ z2
= 0,
∂L∂λ
= 0,
de unde − σ√
n−λg(z1) = 0
σ√n+λg(z2) = 0.∫ z2
z1
g(z)dz = 1−α
Deoarece functia g este simetrica, solutiile sunt z1 = z2 (ce nu convine) si z1 =−z2.

4.7 Intervale de încredere 93
Observatie 4.7.3 (1) În cazul în care volumul selectiei este mare (de cele mai multe ori înpractica, aceasta înseamna n≥ 30) metoda de determinare a unui interval de încredere prezentatamai sus se poate aplica si pentru selectii dintr-o colectivitate ce nu este neaparat normala. Aceastaeste o consecinta faptului ca, pentru n mare, statistica Z urmeaza repartitia N (0, 1) pentruorice forma a repartitiei caracteristicii X (conform teoremei limita centrala).(2) Intervalele de încredere determinate mai sus sunt valide pentru selectia (repetata sau nere-petata) dintr-o populatie infinita, sau pentru selectii repetate dintr-o populatie finita. În cazulselectiilor nerepetate din colectivitati finite, în estimarea intervalelor de încredere vom tine contsi de volumul N al populatiei. De exemplu, daca selectia de volum n se face dintr-o populatiefinita de volum N si n≥ 0.05N, un interval de încredere centrat pentru media populatiei este:
(µ, µ) =
(X− z1−α
2
σ√n
√N−nN−1
, X + z1−α
2
σ√n
√N−nN−1
). (4.7.22)
Interval de încredere pentru medie, când dispersia este necunoscuta
Ne aflam în conditiile din sectiunea precedenta (i.e., o caracteristica normala, X ∼N (µ, σ)),mai putin faptul ca σ este cunoscut. Daca deviatia standard σ nu este cunoscuta, atunci ea vatrebui estimata. Stim deja ca o estimatie absolut corecta pentru σ este statistica S), data prin
S =
√1
n−1
n
∑i=1
(Xi−X)2.
Pentru a estima media teoretica necunoscuta µ printr-un interval de încredere, alegem statistica
T =X−µ
S√n
∼ t(n−1), (conform Propozitiei 3.3.13). (4.7.23)
În mod analog cu cazul precedent, gasim intervalul de încredere în functie de cele trei cazuriamintite mai sus:
(1) Daca nu se cunoaste o alta informatie suplimentara despre µ , atunci intervalul de încrederepentru media teoretica µ când σ este necunoscut este:
(µ, µ) =
(X− t1−α
2 ;n−1S√n, X + t1−α
2 ;n−1S√n
)(4.7.24)
(2) Daca pentru media teoretica nu se precizeaza o limita superioara, atunci intervalul deîncredere este:
(µ, ∞) =
(X− t1−α;n−1
S√n, ∞
)

94 Capitolul 4. Notiuni din Teoria estimatiei
(3) Daca pentru media teoretica nu se precizeaza o limita inferioara, atunci intervalul deîncredere este:
(−∞, µ) =
(−∞, X + t1−α;n−1
S√n
)
Aici, prin tα;n−1 am notat cuantila de ordin α pentru repartitia t cu (n−1) grade de libertate.Observatie 4.7.4 Formulele din aceasta sectiune sunt practice atunci când selectia se facedintr-o colectivitate gaussiana de volum n mic. Când n este mare (e.g., n ≥ 250), atunci va fio diferenta foarte mica între valorile z1−α
2si t1−α
2 ;n−1, de aceea am putea folosi z1−α
2în locul
valorii t1−α
2 ;n−1. Mai mult, pentru un n mare, intervalele de încredere obtinute mai sus ramânaceleasi pentru orice forma a repartitiei caracteristicii X , nu neaparat pentru una gaussiana.Asadar, pentru o selectie de volum mare dintr-o colectivitate oarecare, un interval de încrederepentru media populatiei, când dispersia nu este cunoscuta, este:
(µ, µ) =
(X− z1−α
2
S√n, X + z1−α
2
S√n
), n≥ 250. (4.7.25)
Interval de încredere pentru dispersie, când media este cunoscuta
Fie X ∼ N (µ, σ) o caracteristica a unei populatii studiate, pentru care cunoastem mediateoretica µ dar nu si dispersia σ2. Dorim sa estimam dispersia prin construirea unui interval deîncredere. Alegem o selectie repetata X1, X2, . . . , Xn ce urmeaza repartitia lui X . Fixam nivelulde semnificatie α .Pentru estimarea punctuala a lui σ2 când media este cunoscuta folosim statistica D2 definita prin
D2 =1n
n
∑i=1
[Xi−µ]2.
Intervalul de încredere pentru dispersie se construieste cu ajutorul statisticii
nσ2 D2 =
1σ2
n
∑i=1
(Xi−µ)2 ∼ χ2(n), (conform Propozitiei 3.3.8).
Determinam intervalul aleator din conditia:
P(
χ21 <
nσ2 D2 < χ
22
)= Gn(χ
22 )−Gn(χ
21 ) = 1−α,
unde aici Gn(x) reprezinta functia de repartitie teoretica pentru repartitia χ2 cu n grade delibertate.În functie de faptul daca avem sau nu informatii suplimentare despre dispersie (analog caanterior), gasim ca intervalul de încredere pentru σ2, dupa cum urmeaza:
(1) nu avem informatii suplimentare despre dispersie:
(σ2, σ2) =
(nD2
χ21−α
2 ;n
,nD2
χ2α
2 ;n
)(4.7.26)

4.7 Intervale de încredere 95
(2) avem informatii ca dispersia este nemarginita superior:
(σ2, σ2) =
(nD2
χ21−α;n
, +∞
)(4.7.27)
(3) avem informatii ca dispersia este nemarginita inferior:
(σ2, σ2) =
(0,
nD2
χ2α;n
)(4.7.28)
unde prin χ2α;n am notat cuantila de ordin α pentru repartitia χ2 cu n grade de libertate.
Interval de încredere pentru dispersie, când media este necunoscuta
Fie X ∼N (µ, σ) o caracteristica a unei populatii studiate, pentru care nu cunoastem mediasau dispersia. De exemplu, X reprezinta timpul de producere a unei reactii chimice. Dorimsa estimam dispersia prin construirea unui interval de încredere. Alegem o selectie repetataX1, X2, . . . , Xn ce urmeaza repartitia lui X . Fixam nivelul de semnificatie α .Pentru estimarea punctuala a lui σ2 când media este necunoscuta folosim statistica S2 definitaprin
S2 =1
n−1
n
∑i=1
[Xi−X ]2.
Intervalul de încredere pentru dispersie se construieste cu ajutorul statisticii
n−1σ2 S2 =
1σ2
n
∑i=1
(Xi−X)2 ∼ χ2(n−1), (conform Propozitiei 3.3.11).
Determinam intervalul aleator din conditia:
P(
χ21 <
n−1σ2 S2 < χ
22
)= Gn−1(χ
22 )−Gn−1(χ
21 ) = 1−α,
unde Gn−1(x) reprezinta functia de repartitie teoretica pentru repartitia χ2 cu (n−1) grade delibertate.În functie de faptul daca avem sau nu informatii suplimentare despre dispersie, gasim ca intervalulde încredere pentru σ2 este:
(1) nu avem informatii suplimentare despre dispersie:
(σ2, σ2) =
((n−1)S2
χ21−α
2 ;n−1
,(n−1)S2
χ2α
2 ;n−1
)(4.7.29)
unde χ2α;n−1 este cuantila de ordin α pentru repartitia χ2 cu (n−1) grade de libertate.

96 Capitolul 4. Notiuni din Teoria estimatiei
(2) avem informatii ca dispersia este nemarginita superior:
(σ2, σ2) =
((n−1)S2
χ21−α;n−1
, +∞
)(4.7.30)
(3) avem informatii ca dispersia este nemarginita inferior:
(σ2, σ2) =
(0,
(n−1)S2
χ2α;n−1
)(4.7.31)
Observatie 4.7.5 Intervale de încredere pentru deviatia standard se obtin prin extragerea rada-cinii patrate din capetele de la intervalele de încredere pentru dispersie.
Interval de încredere pentru proportii într-o populatie binomiala
Pentru o populatie statistica, prin proportie a populatiei vom întelege procentul din întreagacolectivitate ce satisface o anumita proprietate (sau are o anumita caracteristica) (e.g., proportiade studenti integralisti dintr-o anumita facultate). Pe de alta parte, prin proportie de selectieîntelegem procentajul din valorile de selectie ce satisfac o anumita proprietate (e.g., proportia destudenti integralisti dintr-o selectie aleatoare de 40 de studenti ai unei facultati). Proportia uneipopulatii este un parametru (pe care îl vom nota cu p), iar proportia de selectie este o statistica(pe care o notam aici prin p).Fie X o caracteristica binomiala a unei colectivitati, cu probabilitatea de succes p (e.g., numarulde steme aparute la aruncarea unei monede ideale, caz în care p = 0.5). Dorim sa construim uninterval de încredere pentru proportia populatiei, p. Pentru aceasta, avem nevoie de selectii devolum mare din aceasta colectivitate. Un estimator potrivit pentru p este proportia de selectie,adica
p = p =Xn.
Printr-un "volum mare" vom întelege un n ce satisface: n≥ 30, n p > 5 si n(1− p)> 5. Mediavariabilei aleatoare X este E(X) = np, iar dispersia este Var(X) = np(1− p). Putem scrie pe X
ca fiind X =n
∑i=1
Xi, unde Xi sunt variabile aleatoare Bernoulli B(1, p). Pentru un volum n mare,
variabila aleatoare X satisface (conform teoremei limita centrala aplicata sirului Xii):
X−n p√n p(1− p)
=Xn − p√p(1− p)
n
=p − p√p(1− p)
n
∼ N (0, 1).
Pe baza acestui rezultat, putem construi un interval de încredere pentru p, de forma:
(p− z1− α
2
√p(1− p)
n, p+ z1− α
2
√p(1− p)
n
). (4.7.32)

4.7 Intervale de încredere 97
Deoarece p nu este a priori cunoscut, p a fost înlocuit sub radical cu estimatorul sau. Valoarea
E = z1−α
2
√p(1− p)
n(4.7.33)
este eroarea care se face prin estimarea lui p prin intervalul de încredere dat de (4.7.32).Observatie 4.7.6 Folosind formula (4.7.33), se poate determina volumul minim al esantionuluipentru care se obtine estimarea proportiei p printr-un interval de încredere cu o eroare maximaE (ceea ce este echivalent cu faptul ca lungimea intervalului este E ).Daca am ghici proportia populatiei, p, atunci gasim urmatoarea estimare a volumului selectiei:
n =
⌈p(1− p)
(z1−α
2
E
)2⌉, (4.7.34)
unde dxe este cel mai apropiat întreg mai mare sau egal cu x.Daca p nu poate fi ghicit, atunci folosim faptul ca p(1− p) este maxim pentru p = 0.5 si estimampe n prin
n =
⌈14
(z1−α
2
E
)2⌉.
Observatie 4.7.7 Acest interval de încredere este valabil pentru selectie dintr-o populatieinfinita (sau n N, de regula n < 0.05N) sau pentru selectia cu repetitie dintr-o populatie finita.Daca selectia se realizeaza fara repetitie dintr-o populatie finita (cu N astfel înât n ≥ 0.05N),atunci intervalul de încredere este:
(p− z1−α
2
√p(1− p)
n
√N−nN−1
, p+ z1−α
2
√p(1− p)
n
√N−nN−1
)(4.7.35)
4.7.2 Doua selectiiInterval de încredere pentru diferenta mediilor
Fie X1 si X2 caracteristicile a doua populatii normale, N (µ1, σ1), respectiv, N (µ1, σ1), pentrucare nu se cunosc mediile teoretice. Alegem din prima populatie o selectie repetata de volum n1,notata prin (X1k)k=1,n1
, ce urmeaza repartitia lui X1, iar din a doua populatie alegem o selectierepetata de volum n2, notata prin (X2k)k=1,n2
, ce urmeaza repartitia lui X2. Fixam nivelul desemnificatie α . Sa notam dispersiile de selectie pentru fiecare caracteristica prin
S21 =
1n1−1
n1
∑i=1
(X1k−X1)2 si S2
2 =1
n2−1
n2
∑i=1
(X2k−X2)2.
Pentru a gasi un interval de încredere pentru diferenta mediilor, precizam mai întâi statisticilecare stau la baza construirii intervalului. Putem avea urmatoarele trei cazuri:

98 Capitolul 4. Notiuni din Teoria estimatiei
(1) dispersiile σ21 si σ2
2 sunt cunoscute a priori. Alegem statistica (vezi Propozitia 3.3.5)
Z =(X1−X2)− (µ1−µ2)√
σ21
n1+
σ22
n2
∼ N (0, 1). (4.7.36)
Intervalul de încredere pentru diferenta mediilor este:X1−X2− z1− α
2
√σ2
1n1
+σ2
2n2
, X1−X2 + z1− α
2
√σ2
1n1
+σ2
2n2
(2) dispersiile σ21 = σ2
2 = σ2 si necunoscute. Pentru a gasi un interval de încredere pentrudiferenta mediilor, alegem statistica (vezi Propozitia 3.3.15):
T =(X1−X2)− (µ1−µ2)√(n1−1)S2
1 +(n2−1)S22
√n1 +n2−2
1n1+ 1
n2
∼ t(n1 +n2−2) (4.7.37)
Intervalul de încredere pentru µ1−µ2 este:X1−X2− t1− α
2 ; n1+n2−2
√(n1−1)S2
1 +(n2−1)S22
(n1 +n2−2
1n1+ 1
n2
)− 12
,
X1−X2 + t1− α
2 ; n1+n2−2
√(n1−1)S2
1 +(n2−1)S22
(n1 +n2−2
1n1+ 1
n2
)− 12 .
În acest caz, un estimator pentru dispersia comuna, σ2, este:
S2 =(n1−1)S2
1 +(n2−1)S22
n1 +n2−2.
(3) dispersiile σ21 6= σ2
2 , necunoscute. Pentru un interval de încredere pentru µ1−µ2, alegemstatistica
T =(X1−X2)− (µ1−µ2)√
S21
n1+
S22
n2
∼ t(m), (4.7.38)
unde
m =
(s2
1n1
+s2
2n2
)2
(s2
1n1
)2 1n1−1
+
(s2
2n2
)2 1n2−1
− 2. (4.7.39)
În acest caz, un interval de încredere pentru µ1−µ2 la nivelul de semnificatie α este:

4.7 Intervale de încredere 99
X1−X2− t1− α
2 ; m
√S2
1n1
+S2
2n2
, X1−X2 + t1− α
2 ; m
√S2
1n1
+S2
2n2
Observatie 4.7.8 Pentru esantioane de volume mari (n1≥ 30, n2≥ 30), intervalele de încredereobtinute mai sus ramân aceleasi pentru orice forma a repartitiilor caracteristicilor X1 si X2, nuneaparat pentru repartitii gaussiane.
Interval de încredere pentru raportul dispersiilor
Fie X1 si X2 caracteristicile a doua populatii normale, N (µ1, σ1), respectiv, N (µ2, σ2), pentrucare nu se cunosc mediile si dispersiile teoretice. Alegem din prima populatie o selectie repetatade volum n1 ce urmeaza repartitia lui X1, iar din a doua populatie alegem o selectie repetata devolum n2 ce urmeaza repartitia lui X2. Fixam nivelul de semnificatie α . Pentru a gasi un intervalde încredere pentru raportul dispersiilor,
σ21 /
σ22
consideram statistica
F =σ2
2σ2
1
S21
S22∼ F (n1−1, n2−1), (conform Propozitiei 3.3.19). (4.7.40)
Determinam apoi un interval aleator ( f1, f2) astfel încât
P( f1 < F < f2) = Fn1−1,n2−1( f2)−Fn1−1,n2−1( f1) = 1−α,
unde Fn,m este functia de repartitie pentru repartitia Fisher cu (n, m) grade de libertate. Alegem:
f1 = f α
2 ,n1−1,n2−1 si f2 = f1−α
2 ,n1−1,n2−1,
unde fn,m;α reprezinta cuantila de ordin α pentru repartitia Fisher cu (n, m) grade de libertate.Intervalul de încredere pentru raportul dispersiilor, σ2
1/σ22 este:
(S2
1
S22
f α
2 ,n1−1,n2−1,S2
1
S22
f1− α
2 ,n1−1,n2−1
)(4.7.41)
Daca mediile µ1 si µ2 sunt cunoscute, atunci intervalul de încredere pentru raportul dispersiilorla nivelul de semnificatie α este:
(D2
1
D22
f α
2 ,n1,n2 ,D2
1
D22
f1− α
2 ,n1,n2
), (4.7.42)

100 Capitolul 4. Notiuni din Teoria estimatiei
unde
D21 =
1n1
n1
∑i=1
(X1 i−µ1)2 ∼ χ
2(n1), D22 =
1n2
n2
∑j=1
(X2 j−µ2)2 ∼ χ
2(n2).
Interval de încredere pentru diferenta proportiilor într-o populatie binomiala
Fie X1 si X2 doua caracteristici binomiale independente ale unei populatii, cu volumele siprobabilitatile de succes n1, p1 si, respectiv, n2, p2. Dorim sa aflam un interval de încrederepentru diferenta proportiilor, p1− p2. Pentru a reusi aceasta, avem nevoie de selectii mari, deaceea utilizarea testului Z este oportuna. Conditiile testului sunt:
n1 ≥ 30, n2 ≥ 30, n1 p1 > 5, n2 p2 > 5, n1(1− p1)> 5, n2(1− p2)> 5.
Ultimele patru relatii sunt necesare pentru semnificatia fiecareia dintre cele patru clase.Intervalul de încredere pentru p1− p2 la nivelul de semnificatie α este:
p1− p2− z1− α
2
√p1 (1− p1)
n1+
p2 (1− p2)
n2, p1− p2 + z1− α
2
√p1 (1− p1)
n1+
p2 (1− p2)
n2
În cazul în care se testeaza egalitatea a doua proportii, p1 = p2 = p, se mai poate folosi siurmatorul interval de încredere pentru diferenta proportiilor:
(p1− p2− z1− α
2
√p∗(1− p∗)
(1n1
+1n2
), p1− p2 + z1− α
2
√p∗(1− p∗)
(1n1
+1n2
)),
undep∗ =
n1 p1 +n2 p2
n1 +n2.
este un estimator pentru p, si anume, este frecventa relativa a numarului de succese cumulate în cele douaselectii.
4.8 Exercitii rezolvateExercitiu 4.8.1 (a) Calculati informatia Fisher pentru repartitia Bernoulli B(1, p).(b) Aratati ca X este un estimator eficient pentru parametrul p.(c) Aratati ca X este un estimator absolut corect pentru parametrul p.(d) Determinati o statistica suficienta pentru parametrul p.R: (a) Daca X ∼B(1, p), atunci functia sa de probabilitate este f (x, p) = px(1− p)1−x,unde x ∈ 0, 1. Media sa este E(X) = p, iar dispersia sa este Var(X) = p(1− p). Functia deverosimilitate asociata unei selectii aleatoare de volum n este
L (p) =n
∏k=1
pXk(1− p)1−Xk = p∑nk=1 Xk(1− p)n−∑
nk=1 Xk , Xk ∈ 0, 1,

4.8 Exercitii rezolvate 101
de unde
lnL (p) =
(n
∑k=1
Xk
)ln p+
(n−
n
∑k=1
Xk
)ln(1− p) = nX ln p+n(1−X) ln(1− p).
Atunci, informatia Fisher va fi:
In(p) = −E(
∂ 2
∂ p2 lnL (X ; p))
= −E(−nX
1p2 −n(1−X)
1(1− p)2
)=
np2E(X)+
n(1− p)2E(1−X)
(folosim E(X) = E(X) = p
)=
np(1− p)
.
(b) Din E(X) = p deducem ca estimatorul X pentru p este nedeplasat. Deoarece
Var(X) =p(1− p)
n= I−1
n (p),
deducem ca X este estimator eficient pentru p.(c) Estimatorul X pentru p este nedeplasat si dispersia sa tinde la 0 când n→ ∞, deci esteabsolut corect.(d) Functia de masa pentru X este
f (x, p) = px(1− p)1−x, x ∈ 0, 1.
Atunci, functia de masa comuna a variabilelor de selectie este
L (x; p) =n
∏k=1
pxk(1− p)1−xk = p∑nk=1 xk(1− p)n−∑
nk=1 xk = pS(x)(1− p)n−S(x) = g(x)h(S(x), p),
unde g(x) ≡ 1. Folosind teorema de factorizare, deducem ca S(x) este o statistica suficientapentru p. Similar, se poate arata ca
←−X este o statistica suficienta pentru p.
Exercitiu 4.8.2 Calculati informatia Fisher pentru repartitia normala N (µ, σ), unde σ esteparametru cunoscut, iar µ este parametru necunoscut.
R: Daca X ∼N (µ, σ), atunci densitatea sa de repartitie este f (x, µ) = 1σ√
2πe−
12σ2 (x−µ)2
.
Media sa este E(X) = µ , iar dispersia sa este Var(X) = σ2. Functia de verosimilitate asociataunei selectii aleatoare de volum n este
L (µ) =n
∏k=1
1σ√
2πe−
12σ2 (Xk−µ)2
=1
σn(2π)n/2 e−1
2σ2 ∑nk=1(Xk−µ)2
,
de unde
lnL (µ) =− 12σ2
n
∑k=1
(Xk−µ)2−n lnσ − n2
ln(2π).

102 Capitolul 4. Notiuni din Teoria estimatiei
Atunci, informatia Fisher va fi:
In(µ) =−E(
∂ 2
∂ µ2 lnL (X ; µ)
)=− 1
2σ2E
(n
∑k=1
∂ 2
∂ µ2 (Xk−µ)2
)=− 1
2σ2E(−2n) =n
σ2 .
Dupa cum se observa, cantitatea informationala creste cu descresterea lui σ .
Exercitiu 4.8.3 Presupunem timpul de asteptare la un ghiseu este o variabila aleatoare U (0, θ).Determinati o statistica suficienta pentru θ .R: Densitatea de repartitie pentru U ∼U (0, θ) este
f (u; θ) = θ−11(0,θ)(u), u ∈ R.
Consideram o selectie aleatoare de volum n. Atunci, functia de verosimilitate este
L (U ; θ) =1
θ n
n
∏k=1
1(0,θ)(Uk) =1
θ n 1(0,θ)
(max
k=1,2,...,nUk
)1(0,∞)
(min
k=1,2,...,nUk
)= g(U) ·h(M(U), θ).
Aici,
M(U) = maxk=1,2,...,n
Uk, g(U) = 1(0,∞)
(min
k=1,2,...,nUk
)h(M(U), θ) =
1θ n 1(0,θ)
(max
k=1,2,...,nUk
).
Folosind teorema de factorizare, se observa ca M(U) este o statistica suficienta pentru θ . Astfel,daca stim M(U) = maxkUk, este suficient pentru a afla informatiile necesare despre θ .
Exercitiu 4.8.4 (a) Determinati informatia Fisher relativa la σ2 pentru o caracteristica N (µ, σ),cu µ cunoscuta si σ2 necunoscuta.(b) Determinati valoarea minima pentru dispersia oricarui estimator pentru σ2.(c) Determinati mediile si dispersiile urmatorilor estimatori pentru σ2:
S2 =1
n−1
n
∑i=1
[Xi−X ]2, V 2 =1n
n
∑i=1
[Xi−X ]2 si D2 =1n
n
∑i=1
[Xi−µ]2
Pe care estimator dintre cei trei îl vom alege pentru a estima eficient pe σ2?R: (a) Notez cu θ = σ2. Functia de verosimilitate asociata unei selectii aleatoare de volum n(cu µ cunoscuta si θ necunoscuta) este
L (θ) =n
∏k=1
1√2πθ
e−1
2θ(Xk−µ)2
=1
θ n/2(2π)n/2 e−1
2θ ∑nk=1(Xk−µ)2
,
de unde
lnL (θ) =− 12θ
n
∑k=1
(Xk−µ)2− n2
lnθ − n2
ln(2π).
Atunci, informatia Fisher relativa la θ va fi:
In(θ) = −E(
∂ 2
∂θ 2 lnL (θ)
)=−E
(−
n
∑k=1
(Xk−µ)2
θ 3 +n
2θ 2
)=
nθ 3E
((X−µ)2)− n
2θ 2 =n
θ 3 θ − n2θ 2 =
n2θ 2 .

4.8 Exercitii rezolvate 103
(b) Astfel, valoarea minima pentru dispersia unui estimator pentru σ2 va fi (conform Rao-Cramér)
Varmin(σ2) =2θ 2
n=
2σ4
n.
(c) Se stie ca
E(S2) = σ2, E(V 2) = σ
2− σ2
n.
Pe de alta parte,
E(D2) =1n
n
∑k=1
E[(Xk−µ)2] =1n
n
∑k=1
σ2 = σ
2.
Se observa ca S2 si D2 sunt estimatori nedeplasati pentru σ2, iar V 2 este estimator deplasatpentru σ2. Din faptul ca
n−1σ2 S2 ∼ χ
2(n−1),
rezulta ca
Var(
n−1σ2 S2
)= 2(n−1),
de unde
Var(S2) =2σ4
n−1>
2σ4
n=Varmin(σ2), ∀n≥ 1.
Deoarece nV 2 = (n−1)S2, gasim ca
Var(V 2) =2(n−1)σ4
n2 <2σ4
n=Varmin(σ2), ∀n≥ 1.
Pe de alta parte,n
σ2 D2 =1
σ2
n
∑i=1
[Xi−µ]2 ∼ χ2(n),
de unde
Var(D2) =2σ4
n=Varmin(σ2).
În concluzie, desi se pare ca estimatorul V 2 pentru σ2 are dispersia mai mica decât Varmin(σ2)data de inegalitatea Rao-Cramér, acesta este deplasat, deci nu poate fi prea util în practica. Dintreceilalti doi estimatori ramasi, S2 si D2, ambii estimatori nedeplasati pentru σ2, alegem pe D2,care are dispersia minima posibila, deci este estimator eficient pentru σ2.Asadar, daca parametrul µ este a priori cunoscut, atunci statistica dispersie de selectie D2 vaavea dispersia minima posibila, deci informatia Fisher maxima relativa la parametrul σ2.
Exercitiu 4.8.5 Fie X o variabila Pareto5, care are densitatea de repartitie
f (x) =
θxθ
mxθ+1 , x≥ xm,
0 , x < xm,
5Vilfredo Federico Damaso Pareto (1848−1923) a fost un inginer, sociolog, filosof, economist italian. DistributiaPareto s-a aplicat initial la descrierea distributiei averii într-o societate, potrivindu-se tendintei ca o mare parte aaverii este detinuta de o mica parte din populatie (regula “80-20”).

104 Capitolul 4. Notiuni din Teoria estimatiei
unde xm > 0 este dat, iar θ > 0 (indicele Pareto).(a) Aflati informatia Fisher relativa la parametrul θ continuta într-un esantion de volum n.(b) Determinati distributia asimptotica a estimatorului de verosimilitate maxima pentru θ .R: (a) Avem ca
ln f (x; θ) = lnθ +θ lnxm− (θ +1) lnx,
de unde∂
∂θln f (x; θ) =
1θ+ ln
xm
x,
∂ 2
∂θ 2 ln f (x; θ) =− 1θ 2 .
Astfel,
In(θ) = nI1(θ) =−nE[
∂ 2
∂θ 2 ln f (x; θ)
]=
nθ 2 .
(b) Distributia asimptotica a estimatorului de verosimilitate maxima θ pentru θ va fi
θ ∼N
(θ ,
θ 2
n
), n≥ 30.
Exercitiu 4.8.6 Fie X o caracteristica ce are legea de distributie
f (x; θ) =1θ
e−x/θ , x > 0.
(a) Determinati informatia Fisher relativa la θ continuta într-un esantion de volum n.(b) Demonstrati ca X este un estimator eficient pentru θ .(c) Determinati o statistica suficienta pentru parametrul θ .R: (a) Avem ca
ln f (x; θ) =− xθ− lnθ ,
∂
∂θln f (x; θ) =
xθ 2 −
1θ,
∂ 2
∂θ 2 ln f (x; θ) =− 2xθ 3 +
1θ 2 .
Astfel,
In(θ) = nI1(θ) =−nE[
∂ 2
∂θ 2 ln f (x; θ)
]=−nE
[− 2x
θ 3 +1
θ 2
]=
2nθ
θ 3 −n
θ 2 =n
θ 2 .
(b) Din E(X) = θ si Var(X) = θ 2
n = 1In(θ)
, gasim ca X este nedeplasat si realizeaza egalitateaîn inegalitatea Rao-Cramér, deci este eficient.
Exercitiu 4.8.7 Estimati prin metoda verosimilitatii maxime parametrii unei caracteristici nor-male X ∼N (µ, σ).R: Legea de probabilitate pentru X ∼N (µ, σ) este
f (x, µ, σ) =1
σ√
2πe−
(x−µ)2
2σ2 , x ∈ R.
Fie Xknk=1 variabilele aleatoare de selectie repetata de volum n.
Parametrii caracteristicii X sunt θ = (µ, σ) si functia de verosimilitate asociata selectiei este
L (X ; µ, σ) = ∏k=1
f (Xk, µ, σ)
=1
σn(2π)n2
e−
n
∑k=1
(Xk−µ)2
2σ2.

4.8 Exercitii rezolvate 105
Astfel,
lnL (X ; µ, σ) = ln(
1σn(2π)
n2
)− 1
2σ2
n
∑k=1
(Xk−µ)2.
Asadar, pentru a gasi estimatorii de verosimilitate maxima pentru µ si σ , avem de rezolvatsistemul:
∂ lnL
∂ µ=
1σ2
n
∑k=1
(Xk−µ) = 0;
∂ lnL
∂σ=− n
σ+
1σ3
n
∑k=1
(Xk−µ)2 = 0.
Se observa cu usurinta ca solutia sistemului ce convine (tinem cont ca σ > 0) este
µ =1n
n
∑k=1
Xk = X , σ =
√1n
n
∑k=1
(Xk−X)2 not= V (X). (4.8.43)
Verificam acum daca valorile gasite sunt valori de maxim. Pentru aceasta, matricea hessianacalculata pentru valorile obtinute trebuie sa fie negativ definita. Mai întâi, calculam matriceahessiana. Aceasta este:
H(µ, σ) =∂ 2 lnL
∂ µ∂σ=
− n
σ2 − 2σ3
n
∑k=1
(Xk−µ)
− 2σ3
n
∑k=1
(Xk−µ)n
σ2
(1− 3
nσ2
n
∑k=1
(Xk−µ)2
) .
Acum calculam H(µ, σ).
H(µ, σ) =∂ 2 lnL
∂ µ∂σ|µ=µ,σ=σ =
− nσ2 0
0 − 2nσ2
,
care este o matrice negativ definita, deoarece valorile sale proprii, adica radacinile polinomuluicaracteristic
det(H(µ, σ)−λ I2) = 0,
sunt
λ1 =−n
σ2 < 0 si λ2 =−2nσ2 < 0.
Deci, estimatorii µ si σ obtinuti prin metoda verosimilitatii maxime sunt
µ = X si σ =V (X).
Observatie 4.8.1 De remarcat faptul ca estimatorul D(X) obtinut prin metoda verosimilitatiimaxime nu este absolut corect, ci doar corect.

106 Capitolul 4. Notiuni din Teoria estimatiei
Exercitiu 4.8.8 Consideram functia
f (x, θ) =
1
θ 2 xe−xθ , x > 0;
0 , x≤ 0.
(a) Pentru ce valori ale lui θ functia f (x, θ) este o densitate de repartitie?Fie X variabila aleatoare ce are densitatea de repartitie f (x, θ).(b) Gasiti un estimator pentru parametrul necunoscut θ (folosind metoda momentelor si metodaverosimilitatii maxime);(c) Calculati media si dispersia estimatorului. Este estimatorul consistent?R: (a) f este densitate de repartitie daca:
• f− masurabila (este, fiind continua),• f este nenegativa (se vede cu ochiul liber),
•∞∫∞
f (x)dx = 1.
Din ultima conditie gasim ca:
1θ 2
∫∞
0xe−x/θ dx =− 1
θxe−x/θ
∣∣∣∣∞0︸ ︷︷ ︸
=0, pt. θ>0
+1θ
∫∞
0e−x/θ dx =−e−x/θ
∣∣∣∣∞0= 1, pentru orice θ > 0.
(b) (I) Metoda momentelor: Deoarece avem doar un parametru, metoda momentelor revinela:
X = E(X).
Dar, media v.a. X este:
E(X) =∫R
x f (x)dx =1
θ 2
∫∞
0x2 e−
xθ dx = 2θ .
Asadar, estimatorul pentru θ este
θ =X2=
12n
n
∑k=1
Xk, ((Xk)k−variabile aleatoare de selectie).
(II) Metoda verosimilitatii maxime: Functia de verosimilitate este:
L (X , θ) =n
∏k=1
(1
θ 2 e−Xkθ
)=
1θ 2n e− 1
θ
n
∑k=1
Xk=
1θ 2n e−
nXθ .
∂ lnL (X , θ)
∂θ=
∂
∂θ
(−2n lnθ − n
θX)=−2n
θ+
nθ 2 X .
Ecuatia∂ lnL (X , θ)
∂θ= 0 implica
θ =X2=
12n
n
∑k=1
Xk.

4.8 Exercitii rezolvate 107
Se verifica apoi ca∂ 2 lnL (X , θ)
∂θ 2
∣∣∣∣θ=θ
=− 8n
X2 < 0,
si astfel, θ este punct de maxim, deci estimator de verosimilitate maxima pentru θ .(ii) Avem:
E(θ) = E(
X2
)=
E(X)
2= θ , =⇒ estimator nedeplasat.
Var(θ) =Var(
X2
)=
14
Var(X) =14n
Var(X) =θ 2
2nn→∞−→ 0.
Am folosit faptul ca
Var(X) = E(X2)− [EX ]2 =1
θ 2
∫∞
0x3 e−
xθ dx−4θ
2 = 6θ2−4θ
2 = 2θ2.
Asadar, estimatorul θ = X2 este absolut corect, deci este si consistent.
Exercitiu 4.8.9 La un laborator, cinci elevi au cântarit în mod independent un obiect, obtinândvalorile (în grame): 2.25, 2.31, 2.30, 2.29, 2.30. Estimati masa reala a acestui obiect folosindmetoda celor mai mici patrate.R: Fie µ masa reala a obiectului. Atunci, suma patratelor erorilor va fi
5
∑k=1
(xk−µ)2 = (2.25−µ)2 +(2.31−µ)2 +(2.30−µ)2 +(2.29−µ)2 +(2.30−µ)2
= 5µ2−22.9µ +26.2222.
Valoarea minima este µ = 2.29.
Exercitiu 4.8.10 (1) Determinati un estimator de verosimilitate maxima pentru parametrul pal distributiei geometrice G eo(p).(2) Verificati daca acest estimator este deplasat.(3) Un numar de 25 de copii au tras în mod independent la o tinta. Fiecare copil arunca la tintapâna o nimereste, apoi se opreste. Tabelul de mai jos contine rangurile încercarilor la care tinta afost atinsa pentru prima data de catre copii. Estimati probabilitatea ca tinta sa fie atinsa.(4) Determinati o estimatie pentru p obtinuta prin metoda minimului lui χ2.
rangul (xk) 2 3 4 5frecventa (nk) 4 7 8 6
R: (1) Daca X ∼ G eo(p), atunci f (x; p) = (1− p)x−1 p, x = 1, 2, 3, . . .. Atunci, pentru unesantion X1, X2, . . . , Xn, functia de verosimilitate este:
L (p) =n
∏k=1
(1− p)Xk−1 p = pn(1− p)∑nk=1 Xk−n.
De aici,
lnL (p) = n ln p+
(n
∑k=1
Xk−n
)ln(1− p) = n ln p+n(X−1) ln(1− p),

108 Capitolul 4. Notiuni din Teoria estimatiei
si∂
∂ plnL (p) =
np− n(X−1)
1− p= 0 =⇒ p =
1X.
(2) Avem ca
E(p) = E(
1X
)6= 1
E(X)=
11/p
= p,
deci estimatorul este deplasat.(3) Estimarea dorita este
p =1
(2 ·4+3 ·7+4 ·8+5 ·6)/25=
2591≈ 0.2747.
(4) Tinem cont de cele κ = 6 clase, si anume: 1, 2, 3, 4, 5,≥ 6. Statistica de interes este
H(p) =(0−25p)2
25p+
(4−25p(1− p)1)2
25p(1− p)1 +(7−25p(1− p)2)2
25p(1− p)2 +(8−25p(1− p)3)2
25p(1− p)3
+(6−25p(1− p)4)2
25p(1− p)4 +0−25[1− p(1+(1− p)+(1− p)2 +(1− p)3 +(1− p)4)]2
25[1− p(1+(1− p)+(1− p)2 +(1− p)3 +(1− p)4)]
= −25− 16p3−97p2 +210p−16525p(1− p)4 .
Valoarea de minim local pentru aceasta functie este p = 0.25254.
Exercitiu 4.8.11 Fie X ∼U (a, b) caracteristica unei populatii, unde a < b sunt numere reale.Utilizând metoda momentelor, determinati estimatori pentru capetele intervalului.R: Daca X ∼U (a, b), atunci
E(X) =a+b
2, Var(X) =
(b−a)2
12,
de unde
E(X2) =Var(X)+ [E(X)]2 =a2 +ab+b2
3.
Sistemul (4.4.10) se scrie astfel în acest caz:
α1(X1, X2, . . . , Xn) = E(X) (4.8.44)α2(X1, X2, . . . , Xn) = E(X2),
unde
α1 =1n
n
∑i=1
Xi, α2 =1n
n
∑i=1
X2i .
Inlocuind în relatiile (4.8.44), avem de gasit solutia (a, b) a urmatorului sistem:
a+b = 2α1
a ·b = 4α21−3α2.
Aceasta este:a = α1−
√3√
α2−α21; b = α1 +
√3√
α2−α21.

4.8 Exercitii rezolvate 109
Facând calculele si tinând cont ca α1 = X , obtinem estimatorii pentru a si, respectiv, b:
a = X−√
3V ; b = X +√
3V,
unde
X =1n
n
∑i=1
Xi si V =
√1n
n
∑i=1
(Xi−X)2.
Estimatiile punctuale pentru a si b sunt:
a =1n
n
∑i=1
xi −√
3n
n
∑i=1
(xi− x)2, b =1n
n
∑i=1
xi +
√3n
n
∑i=1
(xi− x)2
Exercitiu 4.8.12 Consideram urmatorul joc de noroc: Se arunca o moneda pentru care probabili-tatea de aparitie a fetei cu banul este θ . Daca la o aruncare a monedei apare fata cu banul, atuncijucatorul pierde 1RON si jocul se încheie. Altfel, pentru fiecare aparitie consecutiva a fetei custema câstiga 1RON si are posibilitatea sa arunce din nou moneda. Jocul continua pâna la aparitiafetei cu banul, când jocul se opreste.Notam cu X suma (câstigata sau pierduta) la acest joc de noroc si presupunem ca functia saprobabilitate este:
f (x; θ) =
θ , x =−1;(1−θ)2θ x , x = 0, 1, 2, . . .
(a) Verificati daca f (x; θ) este o functie de probabilitate legitima. Calculati E(X) (valoareaasteptata a câstigului).(b) Determinati un estimator pentru parametrul θ .(c) Un numar de 10 persoane au participat la acest joc, urmatoarele fiind sumele rezultateîn fiecare caz: 1,−1, 0, 1, 2, 3,−1, 1, 2, 0. Folositi aceste observatii pentru a determina oestimare pentru probabilitatea de a pierde la acest joc.R: (a) Mai întâi, observam ca θ ∈ (0, 1). Aratam ca suma probabilitatilor este 1. Avem:
θ +∞
∑x=0
(1−θ)2θ
x = θ +(1−θ)2∞
∑x=0
θx = θ +(1−θ)2 1
1−θ= 1.
Media variabilei aleatoare X este:
E(X) =−θ +∞
∑x=0
(1−θ)2xθx =−θ +(1−θ)2
∞
∑x=0
xθx =−θ +(1−θ)2 θ
(1−θ)2 = 0.
Observam ca nu putem utiliza metoda momentelor pentru a determina un estimator pentru θ ,deoarece E(X) nu depinde de θ (nu contine nicio informatie despre θ ).(b) Notam cu Y variabila aleatoare ce reprezinta numarul de insuccese (i.e., numarul variabileloraleatoare de selectie pentru care Xi =−1). Atunci, functia de verosimilitate este:
L (θ) =n
∏i=1
f (Xi; θ) = θY
n−Y
∏i=1
(1−θ)2θ
Xi = θ
Y+n−Y
∑i=1
Xi(1−θ)2(n−Y ).
Logaritmând, obtinem:
lnL (θ) = (Y +n−Y
∑i=1
Xi) lnθ +2(n−Y ) ln(1−θ)

110 Capitolul 4. Notiuni din Teoria estimatiei
Punctele critice pentru aceasta functie verifica ecuatia:
lnL (θ)
∂θ= 0,
de unde gasim ca
θ =
Y +n−Y
∑i=1
Xi
2n−Y +n−Y
∑i=1
Xi
.
Se verifica faptul ca derivata a doua a acestei functii în raport cu θ este negativa, deci punctulobtinut este de maxim.Pentru urmatoarele observatiile date, gasim ca Y = 2 si valoarea estimatorului este θ = 2+10
20−2+10 =37 , ceea ce înseamna ca probabilitatea de a pierde la acest joc este 3
7 .Mai mult, observam ca estimatia lui θ bazata pe un sir de n observatii toate egale cu −1 este
θ = 1 (deoarece, în acest caz, Y = n,n−Y
∑i=1
Xi = 0), adica estimarea sansei de a pierde bazata pe
cele n observatii pierdante este 1.
Exercitiu 4.8.13 Timpii de deservire la un anumit ghiseu pentru 7 clienti sunt (în minute.fractiunide minut): 3.14, 4.63, 2.71, 4.85, 4.37, 5.12, 3.49. Presupunem ca acestea sunt valori ale uneicaracteristici uniforme U (0, θ).(a) Determinati estimatori pentru parametrul θ prin metoda momentelor si prin metoda verosi-militatii maxime. Calculati valorile estimatorilor pentru selectia data.(b) Verificati daca estimatorii gasiti sunt (sau nu) corecti sau absolut corecti. Care estimatoreste mai bun?(c) Scrieti erorile standard pentru estimatorii gasiti.(d) Determinati o statistica suficienta pentru parametrul θ .R: (a) Densitatea de repartitie pentru o variabila aleatoare X ∼U (0, θ) este
f (x; θ) =
1θ
,x ∈ [0, θ ];
0 , în rest
Metoda momentelor: Egalând momentul teoretic de ordinul întâi (α1(X) =E(X)) cu momentulde selectie de ordinul întâi (α1(X) = X), obtinem:
θ
2= E(X) = X ,
de unde estimatorul obtinut prin metoda momentelor este θ1 = 2X . Pentru selectia data, valoareaacestuia este θ1 = 8.0886.Metoda verosimilitatii maxime: Functia de verosimilitate este
L (θ) =
1
θ n , Xi ∈ [0, θ ], ∀i;0 , în rest
=
1
θ n , θ ≥ maxi=1,2, ...,n
Xi ≥ mini=1,2, ...,n
Xi ≥ 0
0 , în rest

4.8 Exercitii rezolvate 111
Observam ca aceasta functie admite un maxim doar în cazul în care toate variabilele aleatoarede selectie iau valori în (0, θ), caz în care max
i=1,2, ...,nXi ≤ θ . Dar, functia de verosimilitate este o
functie descrescatoare în θ , asadar maximumul lui L (θ) pe intervalul θ ∈ [ maxi=1,2, ...,n
Xi, ∞) se
obtine atunci când θ2 = maxi=1,2, ...,n
Xi.
Pentru observatiile date, estimatia de verosimilitate maxima este θ2 = 5.12.Desi valorile celor doi estimatori sunt diferite, totusi, daca numarul de observatii este foartemare (n→ ∞), atunci estimatiile date de θ1 si θ2 vor fi sensibil egale. Pentru un numar mic deobservatii, aceste valori nu sunt neaparat uniform distribuite într-un interval, deci nu ne putemastepta la valori egale pentru θ1 si θ2.(b) Pentru estimatorul θ1 = 2X , bazat pe o selectie de volum n, avem:
E(θ1) = E(2X) = 2E(X) = 2E(X) = 2θ
2= θ ; (estimator nedeplasat)
Var(θ1) = 4Var(X) = 4σ2
Xn
=θ 2
3nn→∞−→ 0,
deci θ1 este un estimator absolut corect pentru θ . Mai mult, el este si consistent, i.e., θ1prob−→ θ ,
când n→ ∞.Statistica de ordine X(n) = max
i=1,2, ...,nXi are densitatea de repartitie
fX(n)(x) = n[FX(x)]n−1 fX(x) =
n xn−1
θ n , daca 0 < x < θ ,
0, altfel.
Pentru estimatorul θ2 = maxi=1,2, ...,n
Xi, bazat pe o selectie de volum n, avem:
E(θ2) = E( maxi=1,2, ...,n
Xi) =∫
θ
0x fX(n)(x)dx = n
∫θ
0
xn
θ n dx =n
n+1θ
n→∞−→ θ ; (estimator deplasat)
Var(θ1) = E(θ 21 )− [E(θ1)]
2 =∫
θ
0x2 fX(n)(x)dx− n2
(n+1)2 θ2
=n
n+2θ
2− n2
(n+1)2 θ2 =
n(n+2)(n+1)2 θ
2 n→∞−→ 0,
deci θ2 este doar un estimator corect pentru θ . Astfel, dintre cei doi estimatori pentru θ , θ1 estemai bun.(c) Erorile standard pentru estimatorii θ1 si θ2 sunt
σθ1=
√Var(θ1) =
θ√3n
si σθ2=
√Var(θ2) =
√n(n+2)
(n+1)(n+2)θ .
(d) Putem scrie functia de verosimilitate astfel:
L (θ) =
(1
θ n ·1θ≥maxiXi
)·1miniXi≥0 = h(T (X), θ) ·g(X).
Pe baza teoremei de factorizare Fisher-Neyman, deducem ca statistica T (X) = maxi=1,2, ...,n
Xi= θ2
este o statistica suficienta pentru θ .

112 Capitolul 4. Notiuni din Teoria estimatiei
Exercitiu 4.8.14 Într-un institut politehnic, s-a determinat ca dintr-o selectie aleatoare de 100 destudenti înscrisi, doar 67 au terminat studiile, obtinând o diploma. Gasiti un interval de încrederecare, cu o confidenta de 90%, sa determine procentul de studenti absolventi dintre toti studentiice au fost înscrisi.Exercitiu 4.8.15 Dintr-o selectie de 200 de elevi ai unei scoli cu 1276 de elevi, 65% afirma cadetin cel putin un telefon mobil. Sa se gaseasca un interval de încredere pentru procentul de copiidin respectiva scoala ce detin cel putin un telefon mobil, la nivelul de semnificatie α = 0.05.Exercitiu 4.8.16 (1) Un studiu sustine ca 37% dintre elevii de liceu din tara fumeaza. Cât demare ar trebui sa fie volumul unei selectii dintre elevii de liceu pentru a estima procentul real deelevi ce fumeaza, cu o eroare de estimare maxima de 0.5%. Se va alege nivelul de semnificatieα = 0.1.(2) Aceeasi cerinta ca la (1), folosind informatia ca între 35% si 40% dintre elevii de liceu dintara fumeaza.(3) Aceeasi cerinta ca la (1), fara vreo alta informatie suplimentara.Exercitiu 4.8.17 Într-o scoala sunt 200 de elevi declasa a XII-a care au sustinut teza la Matematica.Tabelul alaturat contine o selectie aleatoare de 36de note la aceasta teza.
note 4 5 6 7 8 9 10frecventa 5 6 7 8 5 3 2
Determinati un interval de încredere, cu încrederea de 90%, pentru proportia de elevi din scoalanu au luat nota de trecere (cel putin nota 5) la teza la Matematica.Exercitiu 4.8.18 Pentru femeile cu vârsta între 18 si 24 ani, presiunea sistolica (în mmHg) estedistribuita N (µ, 13.1).(a) Valoarea medie a presiunii sistolice pentru un grup de noua femei cu vârste între 18 si 24ani, alese aleator, este 120.5mmHg. Determinati un interval de încredere pentru µ (α = 0.1).(b) O femeie de 22 de ani are presiunea sistolica de 136mmHg si aceasta valoare reprezinta a90-a centila din populatie. Aflati valoarea lui µ .Exercitiu 4.8.19 O fabrica produce batoane de ciocolata cântarind 100g fiecare. Pentru a seestima abaterea masei de la aceasta valoare, s-a facut o selectie de 35 de batoane, obtinându-sevalorile:
100.12; 99.92; 100.1; 99.89; 100.07; 99.88; 100.11; 99.90; 99.97; 100.2;
99.89; 100.15; 99.9; 99.7; 100.2; 99.7; 100.2; 100.1; 100.04; 99.89;
99.76; 100.1; 99.24; 98.19; 100.15; 100.5; 99.79; 98.95; 100.23; 99.89;
100.12; 98.63; 99.03; 100.3; 98.68.
Gasiti un interval de încredere (cu α = 0.05) pentru deviatia standard a masei batoanelor produsede respectiva fabrica.Exercitiu 4.8.20 Urmatoarele valori reprezinta cinci observatii asupra unei variabile normale:3.14, 3.43, 3.21, 2.97, 3.05. Estimati prin intervale de încredere media si deviatia standard aacestei variabile (α = 0.1).Exercitiu 4.8.21 Gasiti un interval de încredere (cu α = 0.05) pentru deviatia standard a con-tinutului de nicotina a unui anumit tip de tigari, daca o selectie de 25 de bucati are deviatiastandard a continutului de nicotina de 1.6mg.
Exercitiu 4.8.22 Doua strunguri sunt potrivite sa produca piese identice pentru o comanda.Pentru a estima daca abaterile diametrelor pieselor produse de cele doua masini sunt sensibilegale, s-au luat la întamplare doua seturi de volume n1 = 7 si n2 = 10 de piese din cele doua

4.9 Exercitii propuse 113
loturi. Masuratorile au condus la urmatoarele rezultate:Lotul 1 25.06 24.95 25.01 25.05 24.98 24.97 25.02 − − −Lotul 2 25.01 25.09 25.02 24.95 24.97 25.03 24.99 24.97 25.03 24.98
Sa se determine un interval de încredere pentru raportul dispersiilor diametrelor pieselor produsede cele doua loturi (α = 0.1). Se va presupune ca diametrele pieselor urmeaza o repartitienormala.Exercitiu 4.8.23 Dintr-o selectie de 45 de baieti ai unei scoli, 21 au spus ca le place Matematica,iar dintr-o selectie de 65 de fete ale aceleiasi scoli, 37 au sustinut ca le place aceasta disciplina.Construiti un interval de încredere la nivelul de semnificatie α = 0.02 pentru diferenta proportii-lor de baieti si fete din respectiva scoala carora le place Matematica.
Exercitiu 4.8.24 O selectie aleatoare de volum n = 25 cu media se selectie x = 50 se ia dintr-opopulatie de volum N = 1000, ce are deviatia standard σ = 2.(a) Daca presupunem ca populatia este normala, gasiti un interval de încredere pentru mediapopulatiei, cu α = 0.05.(b) Gasiti un interval de încredere pentru media populatiei (α = 0.05) în cazul în care populatianu este normala.
4.9 Exercitii propuseExercitiu 4.9.1 Aratati ca n · (1−X) este o statistica suficienta pentru parametrul p din repartitiaB(n, p).Exercitiu 4.9.2 Calculati informatia Fisher relativa la parametrul λ pentru un esantion de volumn dintr-o variabila P(λ ).Exercitiu 4.9.3 Determinati o statistica suficienta pentru parametrul unei repartitii exponentialeexp(λ ).Exercitiu 4.9.4 Aratati ca statistica S2 este un estimator absolut corect pentru σ2 =Var(X), iarstatistica D2 este un estimator corect, dar nu absolut corect, pentru Var(X).Exercitiu 4.9.5 Aceleasi cerinte ca în Exercitiu 4.8.13, dar presupunem ca timpul de deservireeste o variabila aleatoare de tip exponential exp(θ).Exercitiu 4.9.6 Se considera o caracteristica X a carei lege de distributie depinde de parametrulθ ∈ R si poate fi scrisa sub forma exponentiala
f (x; θ) = ea(θ)T (x)+b(θ)+S(x),
unde a(θ) si b(θ) sunt niste functii de θ iar T (x) si S(x) sunt niste functii de date. Daca Xknk=1
sunt variabilele aleatoare de selectie repetata de volum n, aratati can
∑k=1
T (Xk) este o statistica
suficienta pentru parametrul θ . Particularizati pentru distributia Bernoulli.Exercitiu 4.9.7 Sa se arate ca X este un estimator eficient pentru parametrul µ al repartitieinormale N (µ, σ).Exercitiu 4.9.8 Estimati prin metoda verosimilitatii maxime parametrul p al unei caracteristiciX ∼B(n, p).Exercitiu 4.9.9 Determinati un estimator punctual (prin metoda momentelor si prin metodaverosimilitatii maxime) pentru parametrul α al caracteristicii X ce are densitatea de repartitief : R→ R+, data prin:
f (x; α) =
αe−αx , x > 0,0 , x≤ 0.

114 Capitolul 4. Notiuni din Teoria estimatiei
Verificati daca estimatorul gasit este deplasat.Exercitiu 4.9.10 Pentru esantionul
871 822 729 794 523 972 768 758 583 893 598 743 761 858 948
598 912 893 697 867 877 649 738 744 798 812 793 688 589 615 731
estimati absolut corect dispersia populatiei din care provine aceasta selectie.Exercitiu 4.9.11 Estimati prin metoda momentelor parametrii unei caracteristici X ∼B(n, p).Exercitiu 4.9.12 Determinati un estimator punctual (prin metoda momentelor si prin metodaverosimilitatii maxime) pentru parametrul θ > 0 al caracteristicii X ce are densitatea de repartitief : R→ R+, data prin:
f (x; θ) =
eθ−x , x > θ ,
0 , x≤ θ .
De asemenea, obtineti o statistica suficienta pentru θ .Exercitiu 4.9.13 Daca Xii=1,2, ...,n sunt variabile aleatoare de selectie repetata de volum nefectuate asupra unei caracteristici X , aratati ca informatia Fisher In(θ) definita prin
In(θ) = E
[(∂L (X , θ)
∂θ
)2]
este In(θ) = nI1(θ). (i.e., informatia Fisher continuta în selectia data este de n ori informatiacontinuta într-o singura variabila de selectie.)Exercitiu 4.9.14 Consideram o selectie de volum n dintr-o colectivitate repartizata Γ(n,λ ),n ∈ N. Gasiti un estimator pentru parametrul λ prin metoda verosimilitatii maxime si unul prinmetoda momentelor.Exercitiu 4.9.15 La un control de calitate se verifica masa tabletelor de ciocolata produse deo anumita masina. Pentru a se realiza acest control s-a efectuat o selectie de 50 tablete si s-aobtinut ca masa X al ciocolatelor are urmatoarele dimensiuni (în grame):
Masa 99.98 99.99 100.00 100.01 100.02Frecventa 9 10 13 11 7
Sa se determine:(a) o estimatie absolut corecta pentru masa medie a tabletelor produse;(b) o estimatie corecta si una absolut corecta pentru dispersia valorilor masei fata de medie.Exercitiu 4.9.16 Fie X o variabila aleatoare exponentiala de parametru λ . Daca r > 0, gasiti unestimator prin metoda verosimilitatii maxime pentru P(X ≤ r).Exercitiu 4.9.17 Fie U o variabila aleatoare uniform continua U (0, θ), unde θ > 0.(a) Determinati informatia Fisher continuta într-un esantion de volum n. Aratati ca valoareaminima posibila a unui estimator nedeplasat θ pentru θ este θ 2
n .(b) Aratati ca statistica θ ∗ = n+1
n U(n) este un estimator nedeplasat pentru θ .
(c) Aratati ca dispersia acestui estimator este σ2θ∗
= θ 2
n(n+2) , mai mica decât dispersia minimadata de inegalitatea Rao-Cramér. Cum explicati acest fapt?Exercitiu 4.9.18 Fie X1, X2, . . . , Xn o selectie repetata de volum n mare, luata dintr-o caracteris-tica ce are media µ necunoscuta si dispersia 4. Determinati volumul selectiei pentru care, cu oprobabilitate de 99% putem estima pe µ cu o eroare de o zecime.Exercitiu 4.9.19 Un angajat la Serviciu Fortelor de Munca doreste sa faca un sondaj prin caresa determine procentul de persoane dintr-o regiune a tarii ce lucreaza la negru. El doreste sa

4.9 Exercitii propuse 115
fie 98% sigur ca rezultatul gasit estimeaza procentul real cu o eroare de cel mult 2%. Dintr-unsondaj recent, la care au participat 1500 de persoane angajate, 273 au declarat ca nu li s-au facutcarte de munca.(a) Cât de mare ar trebui sa fie volumul selectiei pentru a realiza estimarea dorita?(b) Daca nu ar avea acces la acel sondajul recent, cât de mare ar trebui sa fie volumul selectieipentru a realiza estimarea dorita?Exercitiu 4.9.20 Un studiu recent arata ca dintre 120 de accidente rutiere ce s-au soldat cuvictime, 56 era datorate consumului de alcool. Gasiti un interval de încredere care sa estimezecu o probabilitate de risc α = 0.05 procentul real al accidentelor rutiere cauzate de consumul dealcool.Exercitiu 4.9.21 În urma aruncarii unei monede de 4050 de ori, s-a observat ca fata cu stema aaparut de 2052 ori. Determinati un interval de încredere pentru probabilitatea de aparitie a feteicu stema la aruncarea respectivei monede. Se va lua nivelul de semnificatie α = 0.05.Exercitiu 4.9.22 Într-un depozit sunt 500 de piese de acelasi tip. La un control de calitate,dintr-un lot de 150 de piese, 5 au fost gasite defecte. Determinati un interval de încredere cuα = 0.1 pentru numarul de piese defecte din depozit.Exercitiu 4.9.23 Notam cu X procentul de timp necesar unui student (ales la întâmplare) pentrua termina un anumit test într-un interval de timp fixat. Densitatea de repartitie a lui X estef : R→ R+,
f (x; θ) =
(θ +1)xθ , 0≤ x≤ 1, (θ ∈ R)0 , altfel.
(a) Pentru ce valori ale parametrului θ , functia f este o densitate de repartitie?Datele urmatoare reprezinta rezultatele a 7 studenti alesi la întâmplare:
x1 = 0.87, x2 = 0.75, x3 = 0.54, x4 = 0.95, x5 = 0.68, x6 = 0.72, x7 = 0.8.
(b) Folositi metoda momentelor pentru a determina un estimator pentru parametrul θ si calculativaloarea estimatorului pentru datele de mai sus.(c) Folositi metoda verosimilitatii maxime petru a determina un estimator pentru parametrul θ
si calculati valoarea estimatorului pentru datele de mai sus.Exercitiu 4.9.24 Cât de mare ar trebui sa fie volumul selectiei, pentru a estima proportia defumatori din tara cu o eroare de cel mult 2% si o încredere de 0.95?Exercitiu 4.9.25 Fie X o caracteristica binomiala B(n, p), cu n cunoscut. Folosind metoda inter-valelor de încredere pentru selectii mari, determinati un interval de încredere pentru parametrulp, la nivelul de semnificatie α .Exercitiu 4.9.26 Andrei si Maria primesc copii ale aceluiasi text pentru corectare. Ei corecteazatextul în mod independent. Andrei gaseste 20 de erori, iar Maria gaseste 15 erori, dintre care 10au fost gasite si de Andrei. Estimati numarul de erori din text care nu au fost detectate nici deniciunul dintre cei doi.


5. Testarea ipotezelor statistice
5.1 Intoducere
Testarea ipotezelor statistice este o metoda prin care se iau decizii statistice, utilizând dateleexperimentale culese. Testele prezentate mai jos au la baza notiuni din teoria probabilitatilor.Aceste teste ne permit ca, plecând de la un anumit set sau de la anumite seturi de date culeseexperimental, sa se putem valida anumite estimari de parametri ai unei repartitii sau chiar putemprezice forma legii de repartitie a caracteristicii considerate.Presupunem ca X este caracteristica studiata a unei populatii statistice si ca legea sa de probabili-tate este data de f (x, θ), unde θ ∈ Θ⊂ Rp. Dupa cum precizam în capitolul anterior, aceastafunctie poate fi specificata (adica îi cunoastem forma, dar nu si parametrul θ ), caz în care putemface anumite ipoteze asupra acestui parametru, sau f (x, θ) este necunoscuta, caz în care putemface ipoteze asupra formei sale.Sa presupunem ca x1, x2, . . . ,xn sunt datele observate relativ la caracteristica X .Definitie 5.1.1 (1) Numim ipoteza statistica o presupunere relativ la valorile parametrilorce apar în legea de probabilitate a caracteristicii studiate sau chiar referitoare la tipul legiicaracteristicii.(2) O ipoteza neparametrica este o presupunere relativ la forma functionala a lui f (x, θ). Deexemplu, o ipoteza de genul X ∼ Normala sau X are o repartitie Poisson.(3) Numim ipoteza parametrica o presupunere facuta asupra valorii parametrilor unei repartitii.Daca multimea la care se presupune ca apartine parametrul necunoscut este formata dintr-un singur element, avem de-a face cu o ipoteza parametrica simpla. Altfel, avem o ipotezaparametrica compusa.(4) O ipoteza nula este acea ipoteza pe care o intuim a fi cea mai apropiata de realitate si opresupunem a priori a fi adevarata. Cu alte cuvinte, ipoteza nula este ceea ce doresti sa crezi, încazul în care nu exista suficiente evidente care sa sugereze contrariul. Un exemplu de ipotezanula este urmatorul: "presupus nevinovat, pâna se gasesc dovezi care sa ateste o vina". O ipotezaalternativa este orice alta ipoteza admisibila cu care poate fi confruntata ipoteza nula.De exemplu, putem presupune ca ipoteza (parametrica) nula asupra gramajului unui anumit

118 Capitolul 5. Testarea ipotezelor statistice
produs alimentar este(H0) µ = 250g,
iar o ipoteza alternativa (bilaterala) poate fi
(H1) µ 6= 250g.
În general, pentru teste parametrice consideram
θ ∈Θ = Θ0⋃
Θ1, Θ0⋂
Θ1 =∅
si spunem ca(H0) θ ∈Θ0 este ipoteza nula,
iar(H1) θ ∈Θ1 este ipoteza alternativa.
(5) A testa o ipoteza statistica (en., statistical inference) înseamna a lua una dintre deciziile:− ipoteza nula se respinge− ipoteza nula se admite (sau, nu sunt motive pentru respingerea ei)
(6) În Statistica, un rezultat se numeste semnificativ din punct de vedere statistic daca este impro-babil ca el sa se fi realizat datorita sansei. Între doua valori exista o diferenta semnificativa dacaexista suficiente dovezi statistice pentru a dovedi diferenta, si nu datorita faptului ca diferenta arfi mare. Cu alte cuvinte, în Statistica marimea nu conteaza, conteaza doar existenta dovezilorcare sa ateste ca aceasta marime este semnificativ diferita de zero. Numim nivel de semnificatieprobabilitatea de a respinge ipoteza nula când, de fapt, aceasta este adevarata. În general, nivelulde semnificatie este ales ca fiind una dintre valorile: α = 0.01, 0.02, 0.05 etc.(7) Vom numi regiune critica multimea tuturor valorilor pentru datele de selectie care cauzeazarespingerea ipotezei nule. Reamintim faptul ca ipoteza nula este acea ipoteza pe care o conside-ram cât mai aproape de realitate, în lipsa unor dovezi care sa ateste contrariul.
Pentru a întelege mai bine aceasta regiune, sa presupunem ca avem de testat faptul ca masa mediea unui anumit produs este de 100g sau mai mare. Sa ne alegem nivelul de semnificatie α = 0.05si observam un esantion de volum n, x1, x2, . . . ,xn. Aceste esantion reprezinta gramajele a nproduse alese aleator din populatie. Matematic, vom scrie ca avem de verificat ipotezele
(H0) : µ = 100g vs. (H1) : µ > 100g.
Pe baza acestui esantion, am observat ca masa medie empirica (a esantionului) este x = 112.4g.Ne punem problema daca aceasta valoare este prea mare (prea departata de 100g), ca sa maiputem accepta ipoteza nula. Este de asteptat sa respingem ipoteza nula daca valoarea lui x estesuficient de mare. Dar, cât de mare este suficient de mare? Intuitiv, daca valoarea lui x depasesteun anumit prag c, atunci vom spune ca x este suficient de mare, ca sa putem respinge ipotezanula. Astfel, ipoteza alternativa va deveni cea mai aproape de adevar. În acest caz, regiuneacritica (care duce la respingerea ipotezei nule) este acea regiune din spatiul datelor pentru carevaloarea medie observata depaseste un anumit prag. În general, regiunea critica se definestesimilar, folosind diverse statistici S(x1, x2, . . . , xn) (aici, statistica este x). Daca putem scrieregiunea critica sub forma
U = (x1, x2, . . . , xn) ∈ Rn | S(x1, x2, . . . , xn)≥ c,

5.1 Intoducere 119
atunci valoarea c se numeste valoare critica iar S(x1, x2, . . . , xn) se numeste statistica test saucriteriu.Din punct de vedere matematic, o submultime U ⊂ R se numeste regiune critica cu un nivelde semnificatie α ∈ (0, 1) daca probabilitatea de a respinge o ipoteza adevarata este α . Scriemastfel:
P((x1, x2, . . . , xn) ∈U | H0 - adevarata) = α.
(8) Construirea unui test statistic revine la construirea unei astfel de multimi critice. Folosinddatele observate si U determinat ca mai sus, putem avea doua cazuri:
(i) (x1, x2, . . . , xn) 6∈ U , adica H0 este acceptata (pâna la o alta testare);
(ii) (x1, x2, . . . , xn) ∈ U , adica H0 este respinsa (adica H1 este acceptata);
(9) În urma unor astfel de decizii pot aparea doua tipuri de erori:• eroarea de speta (I) sau riscul furnizorului (en., false positive) − este eroarea care se poate
comite respingând o ipoteza (în realitate) adevarata. Se mai numeste si risc de genul (I).Probabilitatea acestei erori este nivelul de semnificatie, adica:
α = P((x1, x2, . . . , xn) ∈U | H0 - adevarata) = P(H0 este respinsa | H0 - adevarata).
• eroarea de speta a (II)-a sau riscul beneficiarului (en., false negative) − este eroarea carese poate comite acceptând o ipoteza (în realitate) falsa. Se mai numeste si risc de genul al(II)-lea. Probabilitatea acestei erori este
β = P((x1, x2, . . . , xn) 6∈U | H0 - falsa) = P(H0 este acceptata | H0 - falsa).
Gravitatea comiterii celor doua erori depinde de problema studiata. De exemplu, riscul degenul (I) este mai grav decât riscul de genul al (II)-lea daca verificam calitatea unui articol deîmbracaminte, iar riscul de genul al (II)-lea este mai grav decât riscul de genul (I) daca verificamconcentratia unui medicament.Definitie 5.1.2 Denumim valoare P sau P−valoare sau nivel de semnificatie observat (en., P-value) probabilitatea de a obtine un rezultat cel putin la fel de extrem ca cel observat, presupunândca ipoteza nula este adevarata. Valoarea P este cea mai mica valoare a nivelului de semnificatieα pentru care ipoteza (H0) ar fi respinsa, bazându-ne pe observatiile culese. Daca Pv ≤ α , atuncirespingem ipoteza nula la nivelul de semnificatie α , iar daca Pv > α , atunci admitem (H0). Cucât Pv este mai mica, cu atât mai mari sanse ca ipoteza nula sa fie respinsa. De exemplu, dacavaloarea P este Pv = 0.045 atunci, bazându-ne pe observatiile culese, vom respinge ipoteza(H0) la un nivel de semnificatie α = 0.05 sau α = 0.1, dar nu o putem respinge la un nivel desemnificatie α = 0.02.Daca ne raportam la P−valoare, decizia într-un test statistic poate fi facuta astfel: daca aceastavaloare este mai mica decât nivelul de semnificatie α , atunci ipoteza nula este respinsa, iar dacaP−value este mai mare decât α , atunci ipoteza nula nu poate fi respinsa.
Exemplu 5.1.1 Un exemplu simplu de test statistic este testul de sarcina. Acest test este, de fapt,o procedura statistica ce ne da dreptul sa decidem daca exista sau nu suficiente evidente ca saconcluzionam ca o sarcina este prezenta. Ipoteza nula ar fi lipsa sarcinii. Majoritatea oamenilorîn acest caz vor cadea de acord cum ca un false negative este mai grav decât un false positive.Totusi, probabil ca aici vor exista opinii separate între barbati si femei relativ la gravitatea erorilorde testare.

120 Capitolul 5. Testarea ipotezelor statistice
(10) Sa presupunem ca suntem într-o sala de judecata si ca judecatorul trebuie sa decida daca uninculpat este vinovat sau nu. El are de verificat urmatoarele ipoteze:
(H0) inculpatul este nevinovat vs. (H1) inculpatul este vinovat
Posibilele stari reale (asupra carora nu avem control) sunt:[1] inculpatul este nevinovat (H0 este adevarata si H1 este falsa);[2] inculpatul este vinovat (H0 este falsa si H1 este adevarata)
Deciziile posibile (asupra carora avem control; putem lua o decizie corecta sau una falsa):[i] H0 se respinge (dovezi suficiente pentru a încrimina inculpatul);
[ii] H0 nu se respinge (dovezi insuficiente pentru a încrimina inculpatul).
În realitate, avem urmatoarele posibilitati, sumarizate în Tabelul 5.1:
Situatie realaDecizii H0 - adevarata H0 - falsa
Respinge H0 [1]&[i] [2]&[i]Accepta H0 [1]&[ii] [2]&[ii]
Tabela 5.1: Posibilitati decizionale.
Interpretarile datelor din Tabelul 5.1 se gasesc în Tabelul 5.2.
Situatie realaDecizii H0 - adevarata H0 - falsa
Respinge H0 închide o persoana nevinovata închide o persoana vinovataAccepta H0 elibereaza o persoana nevinovata elibereaza o persoana vinovata
Tabela 5.2: Decizii posibile.
Erorile posibile ce pot aparea sunt cele din Tabelul 5.3.
Situatie realaDecizii H0 - adevarata H0 - falsa
Respinge H0 α judecata corectaAccepta H0 judecata corecta β
Tabela 5.3: Erori decizionale.
5.2 Tipuri de teste statisticeTipul unui test statistic este determinat de ipoteza alternativa (H1). Avem astfel:
• test unilateral stânga, atunci când ipoteza alternativa este θ < θ0 (Figura 5.1 (a));• test unilateral dreapta, atunci când ipoteza alternativa este θ > θ0 (Figura 5.1 (b));• test bilateral, atunci când ipoteza alternativa este θ 6= θ0 (Figura 5.2).
Asadar, pentru a construi un test statistic vom avea nevoie de o regiune critica. Pentru a construiaceasta regiune critica vom utiliza metoda intervalelor de încredere. Daca valoarea observata seafla în regiunea critica (adica în afara intervalului de încredere), atunci respingem ipoteza nula.
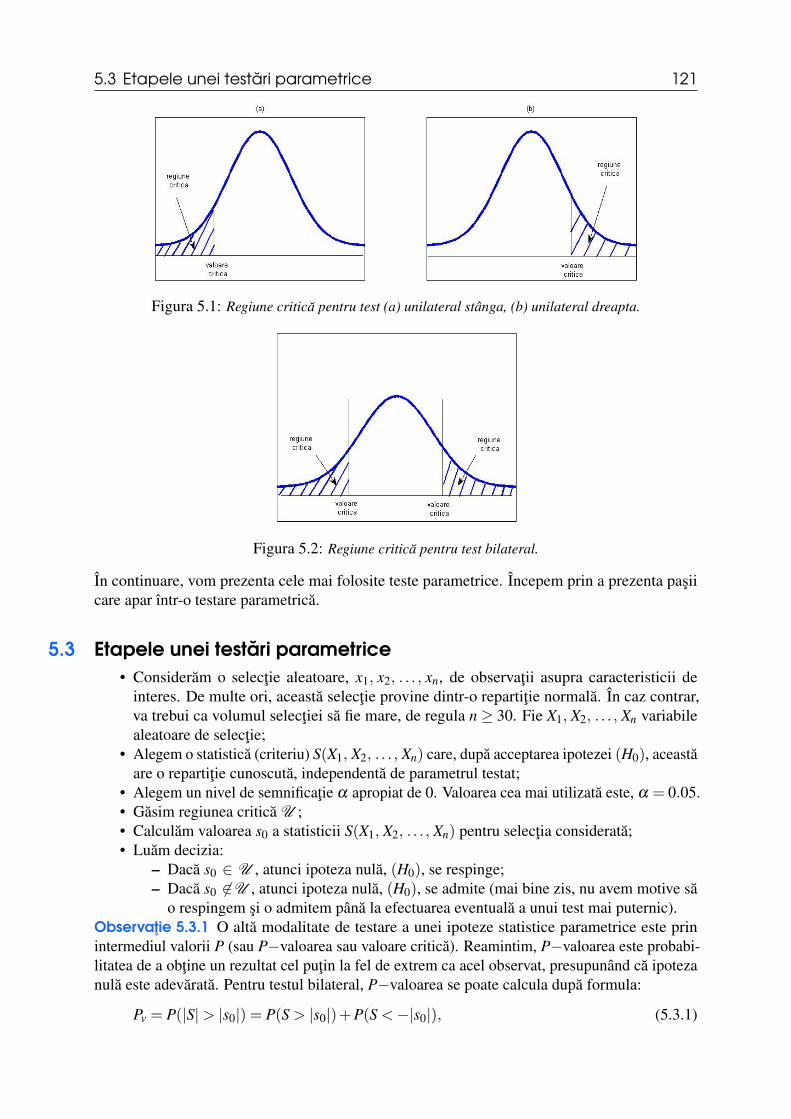
5.3 Etapele unei testari parametrice 121
Figura 5.1: Regiune critica pentru test (a) unilateral stânga, (b) unilateral dreapta.
Figura 5.2: Regiune critica pentru test bilateral.
În continuare, vom prezenta cele mai folosite teste parametrice. Începem prin a prezenta pasiicare apar într-o testare parametrica.
5.3 Etapele unei testari parametrice• Consideram o selectie aleatoare, x1, x2, . . . , xn, de observatii asupra caracteristicii de
interes. De multe ori, aceasta selectie provine dintr-o repartitie normala. În caz contrar,va trebui ca volumul selectiei sa fie mare, de regula n≥ 30. Fie X1, X2, . . . , Xn variabilealeatoare de selectie;
• Alegem o statistica (criteriu) S(X1, X2, . . . , Xn) care, dupa acceptarea ipotezei (H0), aceastaare o repartitie cunoscuta, independenta de parametrul testat;
• Alegem un nivel de semnificatie α apropiat de 0. Valoarea cea mai utilizata este, α = 0.05.• Gasim regiunea critica U ;• Calculam valoarea s0 a statisticii S(X1, X2, . . . , Xn) pentru selectia considerata;• Luam decizia:
– Daca s0 ∈ U , atunci ipoteza nula, (H0), se respinge;– Daca s0 6∈U , atunci ipoteza nula, (H0), se admite (mai bine zis, nu avem motive sa
o respingem si o admitem pâna la efectuarea eventuala a unui test mai puternic).Observatie 5.3.1 O alta modalitate de testare a unei ipoteze statistice parametrice este prinintermediul valorii P (sau P−valoarea sau valoare critica). Reamintim, P−valoarea este probabi-litatea de a obtine un rezultat cel putin la fel de extrem ca acel observat, presupunând ca ipotezanula este adevarata. Pentru testul bilateral, P−valoarea se poate calcula dupa formula:
Pv = P(|S|> |s0|) = P(S > |s0|)+P(S <−|s0|), (5.3.1)

122 Capitolul 5. Testarea ipotezelor statistice
unde S este statistica folosita în testare si s0 este valoarea acestei statistici pentru selectia data(respectiv, selectiile date, în cazul testarii cu doua selectii).Pentru testul unilateral stânga, P−valoarea se poate calcula dupa formula:
Pv = P(S < s0), (5.3.2)
iar pentru testul unilateral dreapta, P−valoarea este data de:
Pv = P(S > s0), (5.3.3)
Utilizând P−valoarea, testarea se face astfel:Ipoteza nula va fi respinsa daca Pv < α si va fi admisa daca Pv ≥ α . Asadar, cu cât Pv este maimic, cu atât mai multe dovezi de respingere a ipotezei nule.
5.4 Testul cel mai puternicSa presupunem ca X este caracteristica unei colectivitati statistice ce urmeaza o lege de probabi-litate f (x; θ), cu θ ∈Θ = θ0, θ1 ⊂ R, cu θ0 6= θ1. Presupunem ca avem de testat ipoteza
(H0) : θ = θ0 vs. (H1) : θ = θ1,
la nivelul de semnificatie α . De asemenea, consideram (x1, x2, . . . , xn) un esantion de volum n.Definitie 5.4.1 Vom numi puterea unui test probabilitatea respingerii unei ipoteze false (sau,probabilitatea de a nu comite eroarea de speta a II-a). Notam prin
π = P(H0 este respinsa | H0− falsa) = 1−P(H0 este admisa | H0− falsa) = 1−β .
Pentru un nivel de semnificatie α fixat, consideram Uα familia formata din toate regiunile criticeUα pentru care
P(x ∈Uα | H0− adevarata) = α.
Presupunem ca familia Uα este nenula. Se poate întâmpla ca în aceasta familie sa existe o ceamai buna regiune critica U ∗
α , în sensul ca aceasta are cea mai mare probabilitate de respingere aipotezei nule în cazul în care aceasta este, în realitate, falsa. Vom spune ca aceasta regiune criticaU ∗
α este cea mai buna pentru problema de testare pusa.Definitie 5.4.2 Spunem ca testul bazat pe regiunea critica U ∗
α ∈ Uα este cel mai puternic testîn raport cu toate testele bazate pe regiuni critice Uα din Uα , la nivelul de semnificatie α , dacasunt îndeplinite urmatoarele conditii:
(a) P(x ∈U ∗α | H0− adevarata) = α; (are nivelul de semnificatie α)
(b) πU ∗α≥ πUα
.
Cu alte cuvinte, dintre toate testele de nivel de semnificatie α fixat, cel mai puternic test este celpentru care puterea testului este maxima. Echivalent, pentru o eroare de speta întâi (α) fixata,eroarea de speta a doua (β ) este minima. Regiunea U ∗
α se numeste regiunea critica cea maibuna.Observatie 5.4.1 Nu întotdeauna exista un cel mai puternic test.În cazul în care ambele ipoteze (nula si alternativa) sunt simple, lema urmatoare ne conferaun cel mai bun test. În cazul unor ipoteze statistice compuse, nu se poate construi un astfel decriteriu.

5.4 Testul cel mai puternic 123
Lema 5.4.1 (Neyman1-Pearson2) Presupunem ca avem de testat
(H0) : θ = θ0 vs. (H1) : θ = θ1,
la nivelul de semnificatie α , pe baza informatiilor continute în esantionul x= (x1, x2, . . . , xn).
Notam cu L (x; θ) =n
∏i=1
f (xi; θ) functia de verosimilitate si fie statistica
S(x) =L (x; θ1)
L (x; θ0).
Atunci testul bazat pe regiunea critica U ∗α definita prin
U ∗α = x ∈ Rn; S(x)≥ c,
cu c astfel încât P(x ∈ U ∗α | H0− adevarata) = α , este cel mai puternic test la nivelul de
semnificatie α .Observatie 5.4.2 Ideea de baza este de a rescrie expresia raportului verosimilitatilor într-oforma ce contine o statistica test a carei repartitie este cunoscuta sau poate fi aflata. Folosindaceasta statistica test, putem obtine intervalul dorit, ce are nivelul de semnificatie dorit.Exemplu 5.4.1 Fie x1, x2, . . . , xn valori de selectie pentru o caracteristica X ∼N (µ0, σ), undeµ0 ∈ R este cunoscut. Dorim sa testam ipoteza nula:
(H0) : σ = σ0
versus ipoteza alternativa simpla
(H1) : σ = σ1 (σ1 > σ0).
R: Functia de verosimilitate asociata selectiei este:
L (x; σ) =1
σn(2π)n2
e− 1
2σ2
n
∑k=1
(xk−µ0)2
.
Calculând S(x), obtinem:
S(x) =L (x; σ1)
L (x; σ0)=
(σ0
σ1
)n
e− 1
2
(1
σ21− 1
σ20
) n
∑k=1
(xk−µ0)2
.
Utilizând lema Neyman-Pearson, regiunea critica cea mai buna este
U ∗α = x ∈ Rn; S(x)≥ c
= x ∈ Rn ;(
σ0
σ1
)n
e− 1
2
(1
σ21− 1
σ20
) n
∑k=1
(xk−µ0)2
≥ c
=
x ∈ Rn;
1σ2
0
n
∑k=1
(xk−µ0)2 ≥ 2
σ21
σ21 −σ2
0
(lnc+n ln
σ1
σ0
)
=
x ∈ Rn;
nσ2
0d2 ≥ 2
σ21
σ21 −σ2
0
(lnc+n ln
σ1
σ0
)=
x ∈ Rn;
nσ2
0d2 ≥ c∗
.
1Jerzy Spłlawa-Neyman (1894−1981), a fost un matematician si statistician polonez, nascut în Bender, Moldova2Egon Sharpe Pearson (1895−1980), a fost un statistician britanic, unul dintre cei trei copii ai lui Karl Pearson

124 Capitolul 5. Testarea ipotezelor statistice
Daca ipoteza (H0) este admisa, atunci statistica nσ2
0d2 ∼ χ2(n). Impunând conditia ca nivelul de
semnificatie al regiunii U ∗α sa fie α , gasim ca
α = P(x ∈U ∗α | H0− adevarata)
= P(
nσ2
0d2 ≥ c∗ |σ = σ0
),
de unde c∗ = χ21−α,n. Asadar, regiunea critica devine
U ∗α = x ∈ Rn;
1σ2
0
n
∑i=1
(xi−µ0)2 ≥ χ
21−α,n.
Astfel, vom respinge ipoteza (H0) daca setul de date verifica1
σ20
n
∑i=1
(xi−µ0)2 ≥ χ
21−α,n.
5.5 Teste parametrice5.5.1 Testul Z pentru medie (o selectie)
Testul Z bilateral
Testul Z pentru medie se foloseste pentru selectii normale sau pentru selectii de volum mare(n≥ 30) din orice tip de variabile aleatoare, atunci când dispersia populatiei este cunoscuta apriori.Fie caracteristica X ce urmeaza legea normala N (µ, σ) cu µ necunoscut si σ > 0 cunoscut.Presupunem ca avem deja culese datele de selectie (observatiile) asupra lui X :
x1, x2, . . . , xn.
Dorim sa verificam ipoteza nula(H0) : µ = µ0
vs. ipoteza alternativa(H1) : µ 6= µ0,
cu probabilitatea de risc α . Pentru a efectua acest test, consideram statistica
Z =X−µ
σ√n
. (5.5.4)
Daca ipoteza (H0) se admite, atunci Z =X−µ0
σ√n
∼N (0, 1), (conform Propozitiei 3.3.3). Ca-
utam un interval (z1, z2) astfel încât
P(z1 < Z < z2) = 1−α. (5.5.5)
Gasim ca acest interval este: (−z1−α
2, z1−α
2
),

5.5 Teste parametrice 125
unde zα este cuantila de ordin α pentru repartitia N (0, 1).Daca Z se afla în acest interval, atunci X este apropiat de valoarea testata µ0, deci nu avemmotive sa respingem ipoteza nula. În schimb, daca |Z | este mare, avem motive sa credem ca Xeste departe de valoarea testata, caz în care vom respinge ipoteza nula. Definim astfel regiuneacritica pentru ipoteza nula (relativ la valorile statisticii Z ) ca fiind acea regiune pentru careipoteza (H0) se respinge, daca media de selectie X apartine acelui interval. Stim ca un intervalde încredere pentru µ va contine valoarea reala µ0 cu o probabilitate destul de mare, 1−α . Estede asteptat ca regiunea critica sa fie complementara acestui interval, adica
U =
z ∈ R; z 6∈(−z1−α
2, z1−α
2
)= z; |z| ≥ z1−α
2. (5.5.6)
Prelucrând aceasta multime, gasim ca U este acea regiune în care:
X ≥ µ0 + z1−α
2
σ√n
si X ≤ µ0− z1−α
2
σ√n.
Notam cu z0 valoarea statisticii Z pentru observatia considerata.Decizia finala se face astfel:
• daca z0 ∈(−z1−α
2, z1−α
2
), (echivalent, z0 6∈U ), atunci admitem (H0) (pentru ca nu
sunt suficiente dovezi sa o respingem).• daca z0 6∈
(−z1−α
2, z1−α
2
), (echivalent, z0 ∈ U ), atunci respingem (H0) (exista sufi-
ciente dovezi sa o respingem).
Etapele testului Z bilateral
(1) Se dau: x1, x2, . . . , xn (date repartizate normal), µ0, σ , α;(2) Determinam valoarea z1− α
2astfel încât
Θ
(z1− α
2
)= 1− α
2.
(3) Calculam valoarea
z0 =x−µ0
σ√n
.
(4) Daca:(i) |z0|< z1− α
2, atunci (H0) este admisa (nu poate fi respinsa);
(ii) |z0| ≥ z1− α
2, atunci (H0) este respinsa (adica (H1) este admisa);
Testul Z unilateral
În conditiile din sectiunea anterioara, dorim sa verificam ipoteza nula
(H0) : µ = µ0
vs. ipoteza alternativa
(H1)s : µ < µ0, (unilateral stânga)
sau ipoteza alternativa
(H1)d : µ > µ0, (unilateral dreapta)

126 Capitolul 5. Testarea ipotezelor statistice
cu probabilitatea de risc α .Pentru a realiza testele, avem nevoie de definirea unor regiuni critice corespunzatoare. Acesteavor fi chiar intervalele de încredere pentru conditiile din ipotezele alternative. Cu alte cuvinte, oregiune critica pentru ipoteza nula (ceea ce semnifica o regiune în care, daca ne aflam, atuncirespingem ipoteza nula la pragul de semnificatie α) este o regiune în care realizarea ipotezeialternative este favorizata.Pentru ipoteza alternativa (H1)s, regiunea critica va fi regiunea acelor posibile valori ale statisticiiZ pentru care media observatiilor, x, este mult mai mica decât valoarea pentru care se testeaza,
µ0, ceea ce corespunde unei valori z0 =x−µ0
σ√n
situate sub un anumit prag negativ. Vom lua
aceasta regiune critica ca fiind:
U = (−∞, −z1−α). (5.5.7)
Aceasta este, în fapt, regiunea care corespunde erorii de speta întâi α . Într-adevar, se observa cuusurinta ca:
P((H0) respinsa | (H0) adevarata) = P(Z ∈U | µ = µ0)
= P(Z <−z1−α | µ = µ0)
= 1−Φ(z1−α) = 1− (1−α) = α.
În mod similar, daca avem ipoteza alternativa (H1)d , atunci alegem regiunea critica:
U = (z1−α , +∞). (5.5.8)
La fel ca mai sus, decizia se determina astfel (în ambele cazuri):
• daca z0 =x−µ0
σ√n6∈U , atunci admitem (H0).
• daca z0 =x−µ0
σ√n∈U , atunci respingem (H0).
Observatie 5.5.1 Testul Z (bilateral sau unilateral) poate fi aplicat cu succes si pentru populatiinon-normale, daca volumul selectiei observate este n≥ 30.
5.5.2 Testul Z pentru egalitatea mediilor a doua populatiiTestul Z pentru egalitatea mediilor se foloseste pentru selectii independente de volum mare(n≥ 30) din orice tip de variabile aleatoare, atunci când dispersiile populatiilor considerate suntcunoscute a priori.Fie X1 si X2 caracteristicile (independente) a doua populatii normale, N (µ1, σ1), respectiv,N (µ2, σ2), pentru care nu se cunosc mediile teoretice. Alegem din prima populatie o selectierepetata de volum n1, x1 = x11, x12, . . . , x1n1, ce urmeaza repartitia lui X1, iar din a douapopulatie alegem o selectie repetata de volum n2, x2 = x21, x22, . . . , x2n2, ce urmeaza repartitialui X2. Fie (X1i)i=1,n1
si (X2 j) j=1,n2variabilele aleatoare de selectie corespunzatoare fiecarei
selectii. Fixam pragul de semnificatie α . Dorim sa testam ipoteza nula ca mediile sunt egale
(H0) : µ1 = µ2
vs. ipoteza alternativa(H1) : µ1 6= µ2.

5.5 Teste parametrice 127
Pentru a testa aceasta ipoteza, alegem statistica
Z =(X1−X2)− (µ1−µ2)√
σ21
n1+
σ22
n2
. (5.5.9)
Daca (H0) este admisa (adica admitem ca µ1 = µ2), atunci (vezi (4.7.38)):
Z =(X1−X2)√
σ21
n1+
σ22
n2
∼ N (0, 1). (conform Propozitiei 3.3.6). (5.5.10)
Fie z0 =(x1− x2)√
σ21
n1+
σ22
n2
. Regiunea critica pentru ipoteza nula, exprimata în valori ale statisticii Z
este:
U =
z; z 6∈(−z1−α
2, z1−α
2
).
• Daca valoarea z0 nu se afla în U , atunci admitem (H0).• Daca valoarea z0 se afla în U , atunci respingem (H0).
Etapele testului Z pentru egalitatea mediilor
(1) Se dau datele normale x11, x12, . . . , x1n1, x21, x22, . . . , x2n2 si σ1, σ2, α;(2) Determinam valoarea z1− α
2astfel încât, functia lui Laplace,
Θ
(z1− α
2
)= 1− α
2.
(3) Calculam valoarea
z0 =x1− x2√
σ21
n1+
σ22
n2
.
(4) Daca:(i) |z0|< z1− α
2, atunci µ1 = µ2;
(ii) |z0| ≥ z1− α
2, atunci µ1 6= µ2.
Observatie 5.5.2 (1) În cazul în care σ1, σ2 sunt necunoscute, atunci utilizam testul t pentrudoua selectii, prezentat mai jos.(2) Regiunile critice pentru testele unilaterale sunt prezentate în Tabelul 5.5.(3) Testul Z pentru doua selectii, bilateral sau unilateral, poate fi aplicat cu succes si pentrupopulatii non-normale, daca volumele selectiilor observate sunt n1 ≥ 30, n2 ≥ 30.(4) Pentru testul Z , P−valoarea se poate calcula dupa urmatoarele formule:
Pv = P(|Z |> |z0|) = 1−Θ(|z0|)+Θ(−|z0|) (pentru testul Z bilateral);Pv = P(Z < z0) = Θ(z0) (pentru testul Z unilateral stânga);Pv = P(Z > z0) = 1−Θ(z0) (pentru testul Z unilateral dreapta).

128 Capitolul 5. Testarea ipotezelor statistice
5.5.3 Testul t pentru medie (o selectie)Testul t pentru medie se foloseste pentru selectii normale de volum mic, de regula n < 30, cânddispersia populatiei este necunoscuta a priori.Fie caracteristica X ce urmeaza legea normala N (µ, σ) cu µ necunoscut si σ > 0 necunoscut.Consideram datele de selectie (observatiile) asupra lui X :
x1, x2, . . . , xn.
Vrem sa verificam ipoteza nula(H0) : µ = µ0
vs. ipoteza alternativa(H1) : µ 6= µ0,
cu probabilitatea de risc α . Pentru a efectua acest test, consideram statistica
T =X−µ
S√n
. (5.5.11)
Daca (H0) se admite, atunci T =X−µ0
S√n
∼ t(n−1), (conform Propozitiei 3.3.13). Cautam un
interval (t1, t2) astfel incât
P(t1 < T < t2) = 1−α. (5.5.12)
Gasim ca acest interval este: (−t1−α
2 ; n−1, t1−α
2 ; n−1
),
unde tα; n reprezinta cuantila de ordin α pentru repartitia t(n).Regiunea critica este complementara intervalului de încredere. Decizia se ia astfel:
• daca t0 =x−µ0
S√n
∈(−t1−α
2 ; n−1, t1−α
2 ; n−1
)(echivalent, t0 6∈U ), admitem (H0).
• daca t0 =x−µ0
S√n
6∈(−t1−α
2 ; n−1, t1−α
2 ; n−1
)(echivalent, t0 ∈U ), respingem (H0).
Etapele testul t bilateral
(1) Se dau: x1, x2, . . . , xn (date normale), µ0, α;(2) Determinam valoarea t1− α
2 ; n−1 astfel încât functia de repartitie pentru t(n−1),
Fn−1
(t1− α
2 ; n−1
)= 1− α
2.
(3) Calculez valoarea
t0 =x−µ0
s√n
, unde, s =
√1
n−1
n
∑k=1
(xi− x)2.
(4) Daca: (i) |t0|< t1− α
2 ; n−1, atunci (H0) este admisa (nu poate fi respinsa);(ii) |t0| ≥ t1− α
2 ; n−1, atunci (H0) este respinsa ((H1) este admisa);

5.5 Teste parametrice 129
Testul t unilateral
În conditiile de mai sus, dorim sa verificam ipoteza nula
(H0) : µ = µ0
vs. ipoteza alternativa
(H1)s : µ < µ0, (unilateral stânga)
sau ipoteza alternativa
(H1)d : µ > µ0, (unilateral dreapta)
cu probabilitatea de risc α .Pentru a realiza testele, avem nevoie de regiuni critice corespunzatoare.Daca alegem ipoteza alternativa (H1)s, atunci regiunea critica pentru ipoteza nula va fi multimeavalorilor favorabile realizarii ipotezei alternative (H1)s, adica intervalul:
U = (−∞, −t1−α; n−1). (5.5.13)
Daca alegem ipoteza alternativa (H1)d , atunci regiunea critica pentru ipoteza nula va fi:
U = (t1−α; n−1, +∞). (5.5.14)
La fel ca mai sus, testarea este (în ambele cazuri):
• daca t0 =x−µ0
S√n
6∈U , atunci admitem (H0).
• daca t0 =x−µ0
S√n
∈U , atunci respingem (H0).
Observatie 5.5.3 Testul t (bilateral sau unilateral) poate fi aplicat cu succes si pentru populatiinon-normale, daca volumul selectiei observate este n≥ 30.
Alti parametri(H0) : µ = µ0 Tipul testului
(H1) Regiunea critica
σ µ 6= µ0
(−∞, −z1− α
2
]⋃[z1− α
2, +∞
)Testul Z bilateral
cunoscut µ < µ0 (−∞, −z1−α) Testul Z unilateral stângaµ > µ0 (z1−α , +∞) Testul Z unilateral dreapta
σ µ 6= µ0
(−∞, −t1− α
2 ; n−1
]⋃[t1− α
2 ; n−1, +∞
)Testul t bilateral
necunoscut µ < µ0 (−∞, −t1−α; n−1) Testul t unilateral stângaµ > µ0 (t1−α; n−1, +∞) Testul t unilateral dreapta
Tabela 5.4: Teste pentru valoarea medie a unei colectivitati.
5.5.4 Testul t pentru egalitatea mediilor a doua populatii
Testul t pentru egalitatea mediilor se foloseste pentru selectii normale independente de volummic (n < 30), atunci când dispersiile populatiilor considerate sunt necunoscute a priori.Fie X1 si X2 caracteristicile (independente) a doua populatii normale, N (µ1, σ1), respectiv,N (µ2, σ2), pentru care nu se cunosc mediile teoretice. Alegem din prima populatie o selectie

130 Capitolul 5. Testarea ipotezelor statistice
repetata de volum n1, x1 = x11, x12, . . . , x1n1, ce urmeaza repartitia lui X1, iar din a douapopulatie alegem o selectie repetata de volum n2, x2 = x21, x22, . . . , x2n2, ce urmeaza repartitialui X2. Fie (X1i)i=1,n1
si (X2 j) j=1,n2variabilele aleatoare de selectie corespunzatoare fiecarei
selectii. Fixam pragul de semnificatie α . Dorim sa testam ipoteza nula ca mediile sunt egale
(H0) : µ1 = µ2
vs. ipoteza alternativa(H1) : µ1 6= µ2.
Cazul I Presupunem ca σ1 6= σ2 sunt necunoscute. Pentru a testa aceasta ipoteza, alegemstatistica
T =(X1−X2)− (µ1−µ2)√
S21
n1+
S22
n2
. (5.5.15)
Aici, S21 si S2
2 sunt dispersiile de selectie. Daca (H0) este admisa (adica admitem ca µ1 = µ2),atunci (vezi relatia (4.7.38)):
T =X1−X2√S2
1n1
+S2
2n2
∼ t(N), (5.5.16)
cu N ca în relatia (4.7.39). Regiunea critica este complementara intervalului de încredere pentrudiferenta mediilor, adica:
U = R\(−t1−α
2 ; N , t1−α
2 ; N
).
Cazul II Presupunem ca σ1 = σ2 si sunt necunoscute. Pentru a testa aceasta ipoteza, alegemstatistica
T =(X1−X2)− (µ1−µ2)√(n1−1)S2
1 +(n2−1)S22
√n1 +n2−2
1n1+ 1
n2
. (5.5.17)
Daca (H0) este admisa (adica admitem ca µ1 = µ2), atunci (vezi relatia (4.7.37)):
T =X1−X2√
(n1−1)S21 +(n2−1)S2
2
√n1 +n2−2
1n1+ 1
n2
∼ t(n1 +n2−2). (5.5.18)
Regiunea critica este complementara intervalului de încredere pentru diferenta mediilor, adica:
U = R\(−t1−α
2 ; n1+n2−2, t1−α
2 ; n1+n2−2
).

5.5 Teste parametrice 131
Etapele testul t pentru egalitatea mediilor
(1) Se dau: x11, x12, . . . , x1n1, x21, x22, . . . , x2n2 (date normale), µ0, α (X1, X2independente).(2) Determinam valoarea t1− α
2 ; m (unde m = N sau m = n1 + n2− 2, dupa caz) astfel încâtfunctia de repartitie pentru repartitia Student t(m),
Fm
(t1− α
2 ; m
)= 1− α
2.
(3) Calculez valoarea t0 =
x1− x2√s2
1n1+
s22
n2
, daca σ1 6= σ2
x1− x2√(n1−1)s2
1 +(n2−1)s22
√n1 +n2−2
1n1+ 1
n2
, daca σ1 = σ2
(4) Daca: (i) |t0|< t1− α
2 ; m, atunci µ1 = µ2;(ii) |t0| ≥ t1− α
2 ; m, atunci µ1 6= µ2.
Observatie 5.5.4 (1) În practica, nu putem sti a priori daca dispersiile teoretice a celor douapopulatii ce urmeaza a fi testate sunt egale sau nu. De aceea, pentru a sti ce test sa folosim, vatrebui sa testam mai întâi ipoteza ca cele doua dispersii sunt egale, vs. ipoteza ca ele difera.Pentru aceasta, va trebui sa utilizam un test pentru raportul dispersiilor. Dupa ce acest prim testa fost realizat, putem decide daca în testarea egalitatii mediilor folosim statistica (5.5.15) saustatistica (5.5.17).(2) În cazul în care dispersiile sunt cunoscute, atunci se utilizeaza testul Z pentru diferentamediilor, care urmeaza pasii testului t pentru diferenta mediilor, cu diferenta ca statistica ce seconsidera este data de relatia (4.7.36) care, dupa acceptarea ipotezei nule, urmeaza repartitiaN (0, 1).(3) Testul t pentru doua selectii, bilateral sau unilateral, poate fi aplicat cu succes si pentrupopulatii non-normale, daca volumele selectiilor observate sunt n1 ≥ 30, n2 ≥ 30.(4) Pentru testul t, P−valoarea se poate calcula dupa urmatoarele formule:
Pv = P(|T |> |t0|) = 1−Fm(|t0|)+Fm(−|t0|) (pentru testul T bilateral);Pv = P(T < t0) = Fm(t0) (pentru testul T unilateral stânga);Pv = P(T > t0) = 1−Fm(t0) (pentru testul T unilateral dreapta).
unde m = N sau m = n1 +n2−2, dupa caz.
Alti parametri(H0) : µ1 = µ2 Tipul testului
(H1) Regiunea critica
σ1, σ2 µ1 6= µ2 |X1−X2| ≥ z1− α
2
√σ2
1n1
+σ2
2n2
Testul Z bilateral
cunoscute µ1 < µ2 X1−X2 <−z1−α
√σ2
1n1
+σ2
2n2
Testul Z unilateral stânga
µ1 > µ2 X1−X2 > z1−α
√σ2
1n1
+σ2
2n2
Testul Z unilateral dreapta
σ1 6= σ2 µ1 6= µ2 |X1−X2| ≥ t1− α
2 ;N
√S2
1n1+
S22
n2Testul t bilateral
necunoscute µ1 < µ2 X1−X2 <−t1−α;N
√S2
1n1+
S22
n2Testul t unilateral stânga
µ1 > µ2 X1−X2 > t1−α;N
√S2
1n1+
S22
n2Testul t unilateral dreapta
Tabela 5.5: Teste pentru egalitatea a doua medii.

132 Capitolul 5. Testarea ipotezelor statistice
5.5.5 Testul t pentru date perechiTestul poate fi aplicat pentru perechi de date pentru care diferentele intre valorile perechi suntnormale.In cursurile anterioare am vazut cum putem testa daca mediile a doua variabile independente Xsi Y sunt egale pe baza observatiilor facute asupra acestor variabile, xii=1,m si y j j=1,n, undem si n nu sunt neaparat egale. Exista insa situatii in care variabilele X si Y nu sunt independenteintre ele. Spre exemplu, observatiile facute asupra aceluiasi grup de indivizi inainte si dupa untratament. In astfel de situatii, testul t pentru diferenta mediilor studiat anterior nu se mai poateaplica.Presupunem ca X si Y sunt doua variabile (posibil corelate) si ca (x1, y1), (x2, y2), . . ., (xn, yn)sunt datele perechi observate. Notam mediile teoretice ale acestor variabile prin: µX = E(X) siµY = E(Y ). In multe aplicatii se doreste a se determina cum este X fata de Y . Pentru fiecare pere-che, consideram di = xi− yi. Presupunem ca variabilele corespunzatoare diferentelor, Dii=1,n,sunt normale, de media µD si deviatie standard σD. Evident, avem ca µD = µX −µY , insa σ2
Dnu mai este neaparat egal cu σ2
X +σ2Y , egalitatea avand loc doar in cazul independentei dintre
variabilele X si Y .
Poate fi utilizat doar daca diferentele di sunt aleatoare si repartitia din care au provenit di esteuna normala.Ipoteze statistice:
teste unilaterale:(H0) : µD = µ0
(H1)s : µD < µ0 [sau (H1)d : µD > µ0]
test bilateral:(H0) : µD = µ0
(H1) : µD 6= µ0.
Pentru setul de date dii=1,n, notam cu
d =1n
n
∑i=1
di si sD =
√1
n−1
n
∑i=1
[di−d]2.
Statistica test este
t =d−µ0
sD/√
n.
Regiunile care duc la respingerea ipotezei nule sunt, respectiv:
t ≤−t1−α;n−1 pentru testul unilateral stangat ≥ t1−α;n−1 pentru testul unilateral dreapta
|t| ≥ t1−α
2 ;n−1 pentru testul bilateral
De asemenea, testul poate fi efectuat pe baza unei valori Pv, care poate fi calculata in fiecare caz.
5.5.6 Testul χ2 pentru dispersieFie caracteristica X ce urmeaza legea normala N (µ, σ) cu µ si σ > 0 necunoscute. Consideramdatele de selectie (observatiile) asupra lui X , x1, x2, . . . , xn.Vrem sa verificam
(H0) : σ2 = σ
20 vs. (H1) : σ
2 6= σ20 ,

5.5 Teste parametrice 133
cu probabilitatea de risc α . Pentru a efectua acest test, consideram statistica
χ2 =n−1σ2 S2, (5.5.19)
care, dupa acceptarea ipotezei (H0) (adica σ2 ia valoarea σ20 ), devine χ2 ∼ χ2(n−1), (conform
relatiei (3.3.5). Intervalului de încredere pentru σ2 este(χ
2α
2 ;n−1, χ21−α
2 ;n−1
),
unde χ2α;n−1 este cuantila de ordin α pentru repartitia χ2(n).
Regiunea critica U va fi complementara acestui intervalul de încredere.
Sa notam prin χ20 =
n−1σ2
0s2 valoarea statisticii χ2 pentru selectia data. Atunci, regula de decizie
este urmatoarea:• daca χ
20 ∈
(χ
2α
2 ;n−1, χ21−α
2 ;n−1
), atunci admitem (H0) (i.e., σ2 = σ2
0 );
• daca χ20 6∈
(χ
2α
2 ;n−1, χ21−α
2 ;n−1
), atunci respingem (H0) (i.e., σ2 6= σ2
0 ).Observatie 5.5.5 Se pot considera, dupa caz, si ipotezele alternative unilaterale
(H1)s : σ2 < σ
20 si (H1)d : σ
2 > σ20 .
Regiunile critice (pe baza carora se pot face decizii) pentru acestea se gasesc în Tabelul 5.6.
(H0) : σ2 = σ20 Tipul testului
(H1) Regiunea critica
µ σ2 6= σ20
(0, χ2
α
2 ;n−1
]⋃[χ2
1− α
2 ;n−1, +∞
)Testul χ2 bilateral
necunoscut σ2 < σ20
(0, χ2
α;n−1)
Testul χ2 unilateral stângaσ2 > σ2
0(χ2
1−α;n−1, +∞)
Testul χ2 unilateral dreapta
Tabela 5.6: Teste pentru dispersie.
5.5.7 Testul F pentru egalitatea dispersiilor a doua populatiiFie X1 si X2 caracteristicile (independente) a doua populatii normale, N (µ1, σ1), respectiv,N (µ2, σ2), pentru care nu se cunosc mediile teoretice. Alegem din prima populatie o selectierepetata de volum n1, x1 = x11, x12, . . . , x1n1, ce urmeaza repartitia lui X1, iar din a douapopulatie alegem o selectie repetata de volum n2, x2 = x21, x22, . . . , x2n2, ce urmeaza repartitialui X2. Fie (X1i)i=1,n1
si (X2 j) j=1,n2variabilele aleatoare de selectie corespunzatoare fiecarei
selectii. Fixam pragul de semnificatie α . Dorim sa testam ipoteza nula ca dispersiile sunt egale
(H0) : σ21 = σ
22
vs. ipoteza alternativa(H1) : σ
21 6= σ
22 .
Pentru a testa aceasta ipoteza, alegem statistica
F =σ2
2σ2
1
S21
S22. (5.5.20)

134 Capitolul 5. Testarea ipotezelor statistice
Daca (H0) este admisa (adica σ21 = σ2
2 ), atunci:
F =S2
1S2
2∼ F (n1−1, n2−1) (repartitia Fisher). (5.5.21)
Intervalul de încredere pentru raportul dispersiilor este(f α
2 ; n1−1,n2−1, f1−α
2 ; n1−1,n2−1
)si se determina astfel încât
P(
f α
2 ; n1−1,n2−1 ≤ F ≤ f1−α
2 ; n1−1,n2−1
)= 1−α.
Extremitatile intervalului se determina din relatiile
Fn1−1;n2−1
(f α
2 ; n1−1,n2−1
)=
α
2si Fn1−1;n2−1
(f1−α
2 ; n1−1,n2−1
)= 1− α
2.
( fα; n1−1,n2−1 este cuantila de ordin α pentru repartitia Fisher F (n1−1, n2−1)).Regiunea critica U este complementara intervalului de încredere pentru raportul dispersiilor.Notam prin f0 valoarea lui F pentru observatiile date, x1 si x2. Avem:
f0 =s2
1s2
2.
Regula de decizie este:• daca f0 ∈
(f α
2 ; n1−1,n2−1, f1−α
2 ; n1−1,n2−1
), atunci admitem (H0) (i.e., σ1 = σ2);
• daca f0 6∈(
f α
2 ; n1−1,n2−1, f1−α
2 ; n1−1,n2−1
), atunci respingem (H0) (i.e., σ1 6= σ2).
Observatie 5.5.6 Se pot considera, dupa caz, si ipotezele alternative unilaterale
(H1)s : σ21 < σ
22 , si (H1)d : σ
21 > σ
22 .
Regiunile critice (pe baza carora se pot face decizii) pentru acestea se gasesc în Tabelul 5.7.
(H0) : σ21 = σ2
2 Tipul testului(H1) Regiunea critica
µ1, µ2 σ21 6= σ2
2
(0, f α
2 ; n1−1,n2−1
]⋃[f1− α
2 ; n1−1,n2−1, +∞
)Testul F bilateral
necunoscute σ21 < σ2
2 (0, fα; n1−1,n2−1) Testul F unilateral stângaσ2
1 > σ22 ( f1−α; n1−1,n2−1, +∞) Testul F unilateral dreapta
Tabela 5.7: Teste pentru raportul dispersiilor.
5.5.8 Teste pentru proportii într-o populatie binomiala
Test pentru proporttie (o singura selectie)
Fie X o caracteristica binomiala a unei colectivitati, cu probabilitatea de succes p. Pe baza unorselectii ale populatiei, dorim sa testam urmatoarea ipoteza asupra lui p:
(H0) : p = p0 vs. (H1) : p 6= p0.

5.5 Teste parametrice 135
De asemenea, putem considera si ipoteze alternative unilaterale:
(H1)s : p < p0 sau (H1)d : p > p0.
Pentru a putea testa acesta ipoteza, ne vom folosi de rezultatele din cursul precedent. Sapresupunem ca volumul populatiei (N) este mult mai mare posibil infinit) decât volumul n alselectiilor considerate. Fixam un nivel de semnificatie α . Vom construi testul pentru proportiapopulatiei pe baza intervalului de încredere (4.7.32).Testul poate fi folosit doar daca urmatoarele conditii sunt satisfacute:
n≥ 30, n2 ≥ 30, np≥ 5, n(1− p)≥ 5.
Etapele testului sunt:• Pe baza selectiei, calculam proportia de selectie p, care este o estimare a proportiei
populatiei, p;• Calculam valoarea
P0 =p − p0√
p0 (1− p0)
n
;
• Calculam cuantila z1−α
2;
• Daca|P0| ≤ z1−α
2,
atunci admitem ipoteza nula la acest nivel de semnificatie. Altfel, o respingem. Regiuneacritica este complementara intervalului de încredere,
U = R\(−z1−α
2, z1−α
2
).
Observatie 5.5.7 Pentru testul unilateral stânga regiunea critica pentru P0 este (−∞, −z1−α),iar pentru testul unilateral dreapta este (z1−α , ∞).
Testul pentru egalitatea proportiilor
Fie X1 si X2 doua caracteristici binomiale independente ale unei populatii, cu volumele siprobabilitatile de succes n1, p1 si, respectiv, n2, p2. Pe baza unor selectii, dorim sa testamipotezele:
(H0) : p1 = p2 vs. (H1) : p1 6= p2.
De asemenea, putem considera si ipoteze alternative unilaterale:
(H1)s : p1 < p2 sau (H1)d : p1 > p2.
Pentru a putea testa acesta ipoteza, ne vom folosi de rezultatele din cursul precedent. Sapresupunem ca volumul populatiei (N) este mult mai mare (posibil infinit) decât volumeleselectiilor considerate. Fixam un nivel de semnificatie α . Daca ipoteza nula este admisa, atuncip1 = p2 = p. Un estimator pentru p este frecventa relativa a numarului de succese cumulate încele doua selectii, i.e.,
p∗ =n1 p1 +n2 p2
n1 +n2.

136 Capitolul 5. Testarea ipotezelor statistice
Testul poate fi folosit doar daca urmatoarele conditii sunt satisfacute:
n1 ≥ 30, n2 ≥ 30, n1 p1 ≥ 5, n1(1− p1)≥ 5, n2 p2 ≥ 5, n2(1− p2)≥ 5.
Etapele testului sunt:• Calculam proportiile de selectie p1 si p2, care sunt estimari pentru p1, respectiv, p2;• Calculam valoarea
P0 =p1 − p2√
p∗(1− p∗)(
1n1+ 1
n2
) ;
• Calculam cuantila z1−α
2;
• Daca|P0| ≤ z1−α
2,
atunci admitem ipoteza nula la acest nivel de semnificatie. Altfel, o respingem. Regiuneacritica este complementara intervalului de încredere,
U = R\(−z1−α
2, z1−α
2
).
Observatie 5.5.8 Regiunea critica pentru testul unilateral stânga este U = (−∞,−z1−α), iarpentru testul unilateral dreapta este U = (z1−α , ∞).

5.6 Recapitulare (teste parametrice) 137
5.6 Recapitulare (teste parametrice)Test pentru media unei populatii ipoteza nula este (H0) : µ = µ0
Pentru a testa valoarea medie a unei anumite caracteristici X pe baza unui set de observatiix1, x2, . . . , xn asupra acesteia, atunci:
• Daca X are o repartitie normala iar deviatia standard σ este cunoscuta a priori, vom utilizatestul Z pentru medie. Testul poate fi facut pentru orice volum al esantionului (n ∈ N∗).
• În practica, exista putine cazuri în care σ este cunoscut a priori. Daca volumul n alesantionului este suficient de mare (e.g., n≥ 30), atunci putem aplica testul Z fara a maifi nevoie ca X sa aiba o repartitie normala.
• În cazul în care n este mare iar σ este necunoscut, înca mai putem folosi testul Z pentrumedie daca folosim statistica urmatoare (în care σ este înlocuit cu s):
Z =X−µ0
S√n
∼N (0, 1) pentru n 1.
• Daca esantionul considerat este de volum mic (n < 30), σ este necunoscut si caracteristicaX este normal repartizata, atunci folosim testul t pentru medie. Aici se utilizeaza statistica
t=X−µ0
s√n∼ t(n−1) pentru n≥ 2,
• Daca n este mic si X nu urmeaza repartitia normala, atunci vom folosi teste neparametrice(nu le studiem aici!) pentru a testa valoarea mediana a unei populatii.
Test pentru proportie (o singura populatie) ipoteza nula este (H0) : p = p0
Datele observate sunt de tip binomial B(n, p). Atunci:• Daca volumul esantionului este mare n≥ 30, se utilizeaza testul bazat pe statistica
Z =p− p0√p0(1−p0)√
n
∼N (0, 1) pentru n≥ 30.
• Daca volumul esantionului este mic n < 30, se utilizeaza testul bazat pe repartitia binomi-ala (nu îl studiem aici!).
Test pentru dispersia unei populatii ipoteza nula este (H0) : σ2 = σ20
Pentru a testa dispersia unei anumite caracteristici normale X pe baza unui set de observatiix1, x2, . . . , xn asupra acesteia, atunci:
• Daca X are o repartitie normala iar media µ nu este cunoscuta a priori, vom utiliza testulχ2 pentru dispersie, folosind statistica
χ2 =
1σ2
n
∑i=1
(xi− x)2 ∼ χ2(n−1) pentru n≥ 2.
• Daca X are o repartitie normala iar media µ este cunoscuta a priori, vom utiliza testul χ2
pentru dispersie, folosind statistica
χ2 =
1σ2
n
∑i=1
(xi−µ)2 ∼ χ2(n) pentru n ∈ N∗.

138 Capitolul 5. Testarea ipotezelor statistice
Test pentru egalitatea mediilor ipoteza nula este (H0) : µX = µY
(I) Populatii independente
Consideram doua seturi de date independente, ximi=1 si y jn
j=1.• Daca X si Y au repartitie normala iar deviatiile standard σX si σY sunt cunoscute a priori,
vom utiliza testul Z pentru diferenta mediilor. Testul poate fi efectuat pentru oricare m, n.• Daca volumul n al selectiei este suficient de mare (e.g., m ≥ 30, n ≥ 30), atunci putem
aplica testul Z fara a mai fi nevoie sa presupunem ca X si Y sunt normal repartizate.• În practica, exista putine cazuri în care deviatiile standard sunt cunoscute a priori. Daca
macar o selectie este de volum mic (m, n < 30) si caracteristicile X si Y sunt normalrepartizate, atunci folosim testul t pentru diferenta mediilor. Totusi, pentru acurateteatestului, va trebui sa efectuam mai întâi un test pentru egalitatea dispersiilor. În functie derezultatul testului din urma, alegem testul t potrivit (respectiv, statistica potrivita):
t =
X−Y√s2Xm +
s2Yn
, daca σX 6= σY
X−Y√(m−1)s2
X+(n−1)s2Y
√m+n−2
1m+ 1
n, daca σX = σY
• Daca volumele sunt mici si caracteristicile nu urmeaza repartitia normala, atunci se vorfolosi teste neparametrice (nu le studiem aici!).
(II) Populatii dependente
• Pentru a testa egalitatea mediilor a doua caracteristici X si Y unui set de observatii depen-dente (x1, y1), (x2, y2), . . . , (xn, yn) (n≥ 30), se va folosi testul t pentru date perechi.
Test pentru egalitatea dispersiilor ipoteza nula este (H0) : σ2X = σ2
Y
Consideram doua seturi de date independente, ximi=1 si y jn
j=1.• Daca X si Y urmeaza repartitii normale, vom utiliza testul F pentru dispersie, folosind
statistica potrivita:
F =
σ2
Yσ2
X
d2X
d2Y, daca µX si µY cunoscute a priori
σ2Y
σ2X
s2X
s2Y, daca µX si µY necunoscute a priori
• Daca datele nu sunt normale si volumul este mic, putem folosi teste neparametrice (nu lestudiem aici!).
Test pentru egalitatea proportiilor ipoteza nula este (H0) : pX = pY
Consideram doua seturi de date independente, ximi=1 si y jn
j=1.• Daca m, n≥ 30, iar m · pX , m ·(1− pX), n · pY , n ·(1− pY )≥ 5, atunci folosim testul bazat
pe statistica
Z =pX − pY√
p∗(1− p∗)( 1
m + 1n
) ∼N (0, 1), unde p∗ =n1 pX +n2 pY
m+n.
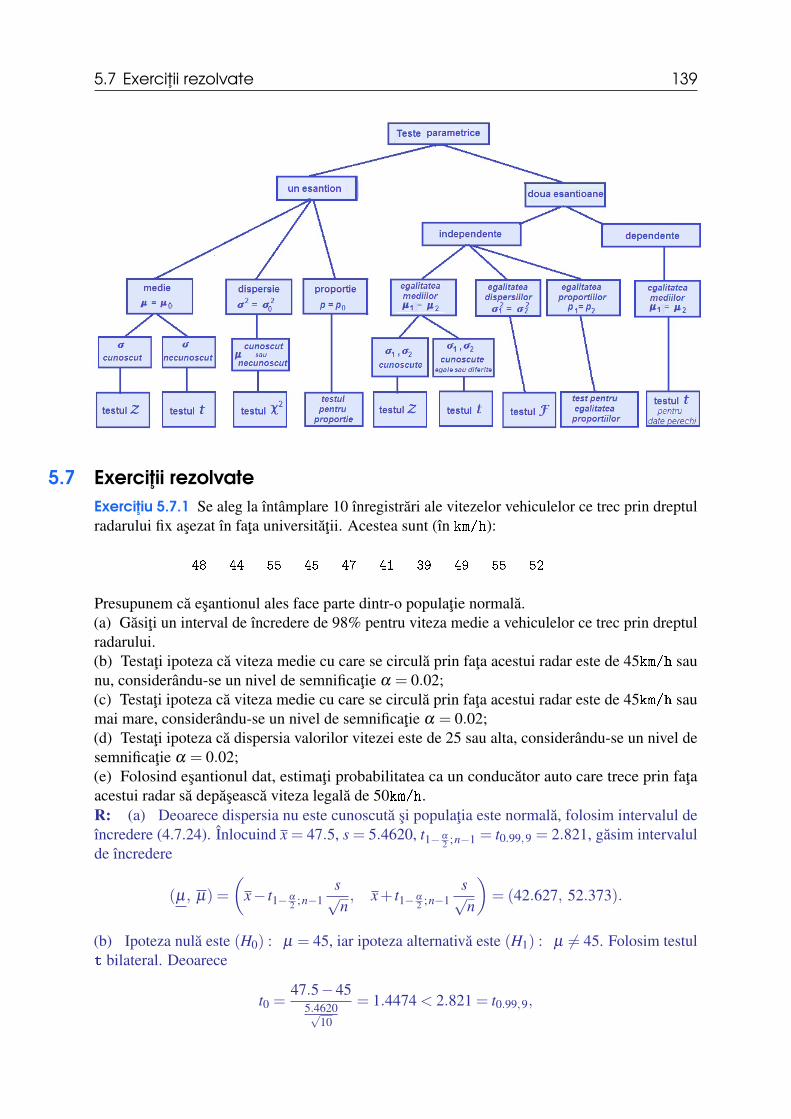
5.7 Exercitii rezolvate 139
5.7 Exercitii rezolvateExercitiu 5.7.1 Se aleg la întâmplare 10 înregistrari ale vitezelor vehiculelor ce trec prin dreptulradarului fix asezat în fata universitatii. Acestea sunt (în km/h):
48 44 55 45 47 41 39 49 55 52
Presupunem ca esantionul ales face parte dintr-o populatie normala.(a) Gasiti un interval de încredere de 98% pentru viteza medie a vehiculelor ce trec prin dreptulradarului.(b) Testati ipoteza ca viteza medie cu care se circula prin fata acestui radar este de 45km/h saunu, considerându-se un nivel de semnificatie α = 0.02;(c) Testati ipoteza ca viteza medie cu care se circula prin fata acestui radar este de 45km/h saumai mare, considerându-se un nivel de semnificatie α = 0.02;(d) Testati ipoteza ca dispersia valorilor vitezei este de 25 sau alta, considerându-se un nivel desemnificatie α = 0.02;(e) Folosind esantionul dat, estimati probabilitatea ca un conducator auto care trece prin fataacestui radar sa depaseasca viteza legala de 50km/h.R: (a) Deoarece dispersia nu este cunoscuta si populatia este normala, folosim intervalul deîncredere (4.7.24). Înlocuind x = 47.5, s = 5.4620, t1−α
2 ;n−1 = t0.99,9 = 2.821, gasim intervalulde încredere
(µ, µ) =
(x− t1−α
2 ;n−1s√n, x+ t1−α
2 ;n−1s√n
)= (42.627, 52.373).
(b) Ipoteza nula este (H0) : µ = 45, iar ipoteza alternativa este (H1) : µ 6= 45. Folosim testult bilateral. Deoarece
t0 =47.5−45
5.4620√10
= 1.4474 < 2.821 = t0.99,9,

140 Capitolul 5. Testarea ipotezelor statistice
acceptam ipoteza nula la nivelul de semnificatie α = 0.02.Altfel, deoarece valoarea testata pentru medie se afla în intervalul de încredere de mai sus,acceptam ipoteza nula (nu avem motive sa o respingem).(c) Ipoteza nula este (H0) : µ = 45, iar ipoteza alternativa este (H1)d : µ > 45. Folosim testult unilateral dreapta. Regiunea critica este U = (t0.98,9, ∞) = (2.398, ∞). Deoarece
t0 =47.5−45
5.4620√10
= 1.4474 6∈U ,
deducem ca ipoteza nula nu poate fi respinsa (o admitem).(d) Ipoteza nula este (H0) : σ2 = 25, iar ipoteza alternativa este (H1) : σ2 6= 25. Folosimtestul pentru dispersie bazat pe statistica (5.5.19). Regiunea critica este
U =(
0, χ2α
2 ;n−1
]⋃[χ
21−α
2 ;n−1, +∞
)=(0, χ
20.1;9
]⋃[χ
20.99;9, +∞
)=(0, 4.17]
⋃[21.67, +∞).
Cum valoarea statisticii test, χ20 = 9
25 ·5.46202 = 10.74, nu se afla în regiunea critica, deducemca ipoteza nula este admisa.(e) P(v > 50)≈ 3
10 = 0.3.Exercitiu 5.7.2 Într-un sondaj national de opinie, 5000 de persoane au fost rugate sa raspundala o întrebare legata de apartenenta religioasa. La întrebarea "Sunteti crestini?", raspunsul a fostafirmativ în 4893 dintre cazuri. Rezultatul acestui sondaj este utilizat în estimarea procentului decrestini din tara. Sa notam cu p acest procent. La nivelul de semnificatie α = 0.05, testati daca peste de 95% sau mai mare.
R: Avem de testat ipoteza
(H0) : p = 0.95 vs. (H1) : p > 0.95.
Procentul de selectie este p = 48935000 = 0.9786, cuantila este z1−α = 1.6449 si valoarea statisticii
este
P0 =0.9786 − 0.95√0.95(1−0.95)
5000
= 9.2791 ∈ [1.6449, ∞),
asadar ipoteza nula este respinsa la acest nivel de semnificatie. Admitem ca p > 0.95.Aceeasi concluzie poate fi dedusa si prin inspectia P−valorii. Aceasta este
Pv = P(Z > P0) = 1−P(Z ≤ P0) = 1−Θ(9.2791)≈ 0 < α = 0.05.
Asadar, ipoteza nula va fi respinsa la toate nivele de semnificatie practice.Exercitiu 5.7.3 Revenim la Exemplul 4.8.23. Sa se testeze, la nivelul de semnificatie α = 0.02daca exista diferente semnificative între proportiile de baieti si fete din respectiva scoala carorale place Matematica.
R: Avem: p1 =2345 , p2 =
3765 , p∗ = 23+37
45+65 = 611 si z0.99 ≈ 2.33. Valoarea statisticii este:
P0 =2345 − 37
65√6
11(1− 611)( 1
45 +1
65
) =−0.6019 ∈ [−2.3263, 2.3263],

5.7 Exercitii rezolvate 141
deci ipoteza nula nu poate fi respinsa la acest nivel de semnificatie.Aceeasi concluzie o putem lua daca verificam P−valoarea. Aceasta este:
Pv = P(|Z |> |P0|) = 1−P(Z < |P0|)+P(Z <−|P0|) = 0.5472 > 0.02 = α.
Exercitiu 5.7.4 La un examen national, se contabilizeaza nota x obtinuta de fiecare examinatîn parte. Pentru o analiza statistica, se aleg la întâmplare 200 de candidati. S-a gasit ca suma
notelor alese este200
∑i=1
xi = 1345.37 si suma patratelor acestor note este200
∑i=1
x2i = 10128.65. Se cer:
(a) Gasiti un interval de încredere pentru media µ a tuturor notelor participantilor la examen, lanivelul de semnificatie α = 0.05.(b) Testati ipoteza nula (H0) : µ = 6.75, vs. ipoteza alternativa (H1) : µ 6= 6.75, la nivelulα = 0.05. Argumentati statistica folosita în testare.
R: Din datele problemei, gasim ca x = 1200
200
∑i=1
xi = 6.7268, iar
s2 =1
n−1
200
∑i=1
x2i − x2 =
10128.65199
−6.72682 = 5.6479.
Astfel, s = 2.3765. Deoarece dispersia nu este cunoscuta a priori si esantionul este suficient demare, folosim intervalul de încredere (4.7.24). Folosind t1−α
2 ;n−1 = t0.975,199 ≈ z0.975 = 1.96,gasim intervalul de încredere
(µ, µ) =
(x− t1−α
2 ;n−1s√n, x+ t1−α
2 ;n−1s√n
)= (6.3974, 7.0562).
(b) Folosim testul t bilateral (dispersia nu este cunoscuta priori, iar n = 200 este suficient demare). Deoarece
t0 =6.7268−6.75
2.3765√200
=−0.1381 si |t0|= 0.1381 < 1.96,
acceptam ipoteza nula la nivelul de semnificatie α = 0.05.Altfel, deoarece valoarea testata pentru medie se afla în intervalul de încredere de mai sus,acceptam ipoteza nula (nu avem motive sa o respingem).Exercitiu 5.7.5 Informatiile din tabelul de mai jos reprezinta doua esantioane independente ceau fost extrase din doua populatii statistice.
Selectia Volumul selectiei media de selectie deviatia standard de selectie1 50 9.75 1.52 75 9.5 0.95
Se cer:(a) Estimati punctual si printr-un interval de încredere (α = 0.01) valoarea µ1−µ2. Presupunemca σ1 6= σ2.(b) Testati ipoteza ca mediile teoretice ale celor doua populatii sunt egale, cu alternativa ca eledifera (α = 0.01).(c) Calculati valoarea Pv si luati decizia testului pe baza acestei valori.

142 Capitolul 5. Testarea ipotezelor statistice
R: (a) Un estimator punctual pentru µ1− µ2 este x1− x2 = 9.75− 9.5 = 0.25. Folosindfaptul ca n1 = 50 > 30, n2 = 75 > 30, z0.995 = 2.5758, un interval de încredere 99% pentruµ1−µ2 estex1− x2− z1−α
2
√s2
1n1
+s2
2n2
, x1− x2 + z1−α
2
√s2
1n1
+s2
2n2
= (−0.3651, 0.8651).
(b) Avem de testat ipoteza
(H0) : µ1 = µ2 vs. (H1) : µ1 6= µ2
Deoarece 0 se afla în intervalul de încredere de mai sus, nu putem respinge ipoteza nula la acestnivel de semnificatie (o admitem).Altfel, valoarea statisticii test este
z0 =x1− x2√
s21
n1+
s22
n2
= 1.0468,
iar |z0|= 1.0468 < 2.5758 = z0.995, de unde deducem faptul ca ipoteza nula este admisa.(c) Valoarea Pv este data de
Pv = P(|Z |> |z0|) = 1−P(Z < 1.0468)+P(Z <−1.0468)= 1−Θ(1.0468)+Θ(−1.0468) = 0.2952.
Deoarece Pv = 0.2952 > 0.01 = α , admitem ipoteza nula.Exercitiu 5.7.6 În industria farmaceutica, variabilitatea masei medicamentelor este critica. Esan-tionul de mai jos reprezinta masa (în grame) a 15 tablete de acelasi tip.
5.6; 5.52; 5.45; 5.41; 5.47; 5.55; 5.41; 5.58; 5.6; 5.4; 5.54; 5.47; 5.5; 5.53; 5.59
(a) Determinati un interval de încredere pentru dispersie (α = 0.05).(b) Presupunem ca acest esantion provine dintr-o populatie normala. Testati ipoteza ca dispersiamasei pentru acest tip de medicament, pentru întreaga populatie, depaseste 0.004g2.R: (a) Pentru acest esantion, s2 = 0.005. Un interval de încredere pentru σ2 este(
n−1χ2
1−α
2 ,n−1
s2,n−1
χ2α
2 ,n−1
s2
)=
(14
26.12·0.005,
145.63
·0.005)= (0.0027, 0.0124).
(b) Ipotezele testate sunt:
(H0) : σ2 = 0.004 vs. (H1)d : σ
2 > 0.004.
Valoarea statisticii test pentru esantion este χ20 = 14
0.004 · 0.005 = 17.5. Regiunea critica este
U =(
χ21−α,n−1, ∞
)= (23.68, +∞). Cum χ2
0 6= U , acceptam ipoteza nula.Exercitiu 5.7.7 Consideram un esantion de volum 100, x1, x2, . . . , x100, dintr-o populatieN (µ, 2), cu µ necunoscut. Construiti testul cel mai puternic la nivelul de semnificatie α = 0.05pentru ipotezele
(H0) : µ = 1 vs. (H1) : µ = 2.

5.8 Exercitii propuse 143
R: Functia de verosimilitate asociata selectiei este:
L (x; µ) =1
2100(2π)50 e− 1
8
100
∑k=1
(xk−µ)2
.
Calculând S(x), obtinem:
S(x) =L (x; µ1)
L (x; µ0)= e− 1
8
(100
∑i=1
(xi−2)2−100
∑i=1
(xi−1)2
)= e−
18 (3n−2nx)
Asadar, regiunea critica va fi
U ∗α = x ∈ R100; S(x)≥ c= x ∈ R100; e−
18 (300−200x) ≥ c
= x ∈ R100; x≥ 32+
125
lnc
= x ∈ R100; x≥ c∗.
Pentru ca testul sa aiba nivelul de semnificatie α = 0.05, trebuie sa avem
P(x ∈U ∗α | H0− adevarata) = 0.05,
de unde (folosim faptul ca, daca (H0) este adevarata, atunci X ∼N (1, 2))
0.05 = P(x ∈ R100; x≥ c∗
)= P
(x ∈ R100;
x−12√100
≥ c∗−12√100
),
de undec∗−1
0.2= z0.95 = 1.6449, deci c∗ = 1.32898.
Asadar, testul cel mai puternic la nivelul de semnificatie 0.05 este bazat pe regiunea criticaU ∗
α = x ∈ R100; x≥ 1.32898. În consecinta, vom respinge ipoteza (H0) daca media empiricaobservata satisface x > 1.32898, altfel o acceptam.
5.8 Exercitii propuseExercitiu 5.8.1 Se arunca o moneda de 250 de ori, obtinându-se 140 de aparitii ale stemei. Laun nivel de semnificatie α = 0.05, sa se decida daca avem suficiente dovezi de a afirma ca acestamoneda este falsa.Exercitiu 5.8.2 Caracteristica X reprezinta cheltuielile lunare pentru convorbirile telefonice aleunei familii. În urma unui sondaj la care au participat 100 de familii, am obtinut datele (repartitiade frecvente):(
[50, 75) [75, 100) [100, 125) [125, 150) [150, 175) [175, 200) [200, 250) [250, 300)6 11 13 18 20 14 11 7
)(a) Sa se verifice, cu nivelul de semnificatie α = 0.02, ipoteza ca media acestor cheltuieli lunarepentru o singura familie este de 140RON, stiind ca abaterea standard este 35RON.(b) Sa se verifice aceeasi ipoteza, în cazul în care abaterea standard nu este cunoscuta a priori.

144 Capitolul 5. Testarea ipotezelor statistice
Exercitiu 5.8.3 O selectie de volum n = 50 este folosita pentru a verifica urmatoarea ipoteza
(H0) : µ = 15 vs. (H1) : µ 6= 15,
la nivelul de semnificatie α = 0.05. Determinati: valoarea critica, regiunea critica, valoareastatisticii pentru selectia data si concluzia testarii, pentru(a) x = 17.5 si s = 4.5 (σ este necunoscut);(b) x = 17.5 si σ = 4.Exercitiu 5.8.4 Pentru o selectie data, de volum n = 196, am obtinut x = 0.25 si s = 4. Nucunoastem nici valoarea medie si nici dispersia variabilei aleatoare ce caracterizeaza populatia.Verificati la nivelul de semnificatie α = 0.05 ipoteza µ = 0, cu alternativa µ 6= 0.Exercitiu 5.8.5 Un patron sustine ca firma sa nu face discriminare sexuala la angajare (i.e., atâtbarbatii, cât si femeile au aceeasi sansa de a se angaja în respectiva firma). Se aleg aleator 500de angajati si se observa ca 271 sunt barbati. Testati la nivelul de semnificatie 0.05 daca patronulfirmei spune adevarul sau nu.Exercitiu 5.8.6 O selectie de volum n = 50 este folosita pentru a verifica urmatoarea ipoteza
(H0) : µ = 15 vs. (H1) : µ 6= 15,
la nivelul de semnificatie α = 0.05. Determinati: valoarea critica, regiunea critica, valoareastatisticii pentru selectia data si concluzia testarii, pentru(a) x = 17.5 si s = 4.5 (σ este necunoscut);(b) x = 17.5 si σ = 4.Exercitiu 5.8.7 Urmarim pretul X al aceluiasi articol în 20 de magazine, alese la întâmplare.Acestea sunt:
9.6 9.9 10.3 10.0 10.5 9.7 9.9 10.2 10.0 10.4
9.9 9.8 10.1 10.4 9.9 10.2 10.3 10.1 10.0 9.7
Consideram ca pretul acestui articol urmeaza o repartitie gaussiana.(i) Se poate admite ipoteza E(X) = 10.0, la nivelul de semnificatie α = 0.05?(ii) Se poate admite ipoteza Var(X) = 0.2, la nivelul de semnificatie α = 0.05?Exercitiu 5.8.8 Unui grup format din 12 copii de 5 ani li s-a cerut sa faca fiecare câte un puzzlesimplu. Dupa ce l-au terminat, au fost rugati sa-l refaca, urmarindu-se daca timpii de lucru s-auîmbunatatit semnificativ. Timpii de lucru (în secunde) pentru ambele încercari sunt notati întabelul de mai jos:
Copil C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 C12
prima încercare 321 339 180 123 289 285 259 124 283 180 254 184a doua încercare 204 184 85 91 175 305 148 116 194 195 221 184
Presupunem ca timpii de lucru sunt caracteristici normale. Formulati un test statistic potrivit, înurma caruia sa decideti daca timpii de lucru pentru a doua încercare s-au îmbunatatit semnificativ.Exercitiu 5.8.9Tabelul alaturat contine repartitia pe grupe de vârsta a unei selectiialeatoare de 385 de someri dintr-o anumita regiune a tarii.(a) Calculati vârsta medie si deviatia standard pentru selectia data.(b) Estimati printr-un interval de încredere vârsta medie a somerilordin acea regiune (α = 0.1).(c) Testati ipoteza ca vârsta medie a somerilor este 42 de ani(α = 0.1).
vârsta frecventa[18,25) 34[25,35) 76[35,45) 124[45,55) 87[55,65) 64

5.8 Exercitii propuse 145
Exercitiu 5.8.10 Într-o scoala sunt 200 de elevi de clasa a XII-a care au sustinut teza la Mate-matica. Tabelul urmator contine o selectie aleatoare de 36 de note la aceasta teza:
note 4 5 6 7 8 9 10frecventa 5 6 7 8 5 3 2
(a) Estimati printr-un interval de încredere procentul notelor de trecere obtinute de elevii declasa a XII-a din acea scoala (α = 0.06).(b) Testati ipoteza ca 15% dintre elevii din scoala nu au luat nota de trecere (α = 0.06).Exercitiu 5.8.11 O selectie de 700 de salarii pe ora din România arata ca media salariului pe oraeste x = 13.72RON si s = 9.3. Putem decide, pe baza acestui sondaj, ca media salariului pe oraeste, de fapt, µ > 12.43RON, valoare stabilita de guvernul român? Se va folosi α = 0.05.Exercitiu 5.8.12 Pentru un esantion de volum n, valoarea medie observata este 205.13. Dispersiateoretica a populatiei din care a fost extras esantionul este 4.2, iar caracteristica studiata estenormala. Se doreste a se testa ipotezele
(H0) µ = 200 vs. (H1) µ 6= 200.
Care este valoarea minima a lui n pentru care ipoteza nula va fi respinsa? (α = 0.05).Exercitiu 5.8.13 Presupunem ca timpul de functionare continua a unui anumit componentelectric este o variabila aleatoare de tip exponential de medie θ . În conditii normale de productie,o anumita fabrica produce aceste componente, ce au o durata de functionare continua de 40000h.Totusi, în anumite conditii restrictive, durata de functionare continua scade la 30000h. Unesantion aleator de 40 de astfel de componente este folosit pentru a verifica ipotezele
(H0) : θ = 40000 vs. (H1) : θ = 30000.
Folositi lema Neyman-Pearson pentru a construi cel mai puternic test la nivelul de semnificatie0.05.


6. Teste de concordanta
. [You should take Poisson only on rare occasions]
În general, testele de concordanta (en., goodness-of-fit tests) realizeaza concordanta întrerepartitia empirica (repartitia datelor observate) si o repartitie teoretica sau testeaza daca douaseturi de date observate provin dintr-o aceeasi repartitie. Dintre cele mai des utilizate teste deconcordanta, amintim:
• testul χ2 de concordanta, criteriul Cramér–von Mises, testul Anderson–Darling. Toateaceste trei teste pot fi folosite pentru a testa concordanta între repartitia datelor obsevate sio repartitie teoretica data.
• testul Kolmogorov-Smirnov (pentru a testa a testa concordanta între repartitia datelorobsevate si o repartitie teoretica data (one-sample test) sau pentru a testa daca doua seturide date observate provin dintr-o aceeasi repartitie (two-sample test).
• testul Shapiro-Wilk, folosit pentru a testa normalitatea datelor.În cele ce urmeaza vom discuta doar testul χ2 de concordanta.
6.1 Testul χ2 de concordantaAcest test de concordanta poate fi utilizat ca un criteriu de verificare a ipotezei potrivit careiaun ansamblu de observatii urmeaza o repartitie data. Se aplica la verificarea normalitatii, aexponentialitatii, a caracterului Poisson, a caracterului Weibull etc. Testul mai este numit sitestul χ2 al lui Pearson sau testul χ2 al celei mai bune potriviri (en., goodness of fit test).Testul poate fi utilizat daca:
• setul de date este obtinut în urma unei selectii aleatoare simple;• variabila studiata este numerica sau categoriala;• avem un numar suficient de date (n≥ 30);• în fiecare clasa a variabilei considerate ne asteptam sa gasim macar 5 valori.

148 Capitolul 6. Teste de concordanta
6.1.1 Cazul neparametricSa consideram o caracteristica X a unei populatii statistice Ω. Repartitia variabilei aleatoare Xeste necunoscuta a priori, însa intuim (sau avem anumite informatii) cum ca aceasta ar fi data delegea de probabilitate complet specificata f (x, θ) (e.g., f (x) = e−2 2x
x! , x ∈ N (X ∼P(2)) sau
f (x) = 13√
2πe(x−5)2
18 (X ∼N (5, 3) )).Deoarece legea de probabilitate ipotetica este complet specificata, θ este cunoscut si vom omitesa mai punem în evidenta dependenta lui f de acesta în decursul aceste sectiuni.Pentru a verifica ipoteza facuta asupra repartitiei lui X , consideram un set de observatii asupra luiX si testam concordanta dintre repartitia empirica a datelor observate cu legea teoretica data def (x). Fie x1, x2, . . . , xn setul de date observate. Sa notam cu F(x) functia de repartitie teoretica.În cele ce urmeaza, urmarim sa aplicam testul χ2 de concordanta, ale carui etape sunt:
• Descompunem în clase multimea observatiilor facute asupra lui X , astfel încât fiecareelement al multimii apartine unei singure clase. Scriem asadar,
x1, x2, . . . , xn=k⋃
i=1
Oi, Oi⋂
O j =∅, ∀i 6= j.
Determinam frecventele empirice absolute, i.e., numerele ni de observatii ce apartin fiecarei
clase Oi. În mod evident, va trebui sa avem cak
∑i=1
ni = n.
• Pentru fiecare i ∈ 1, 2, . . . , k, determinam probabilitatea teoretica pi ca un element alpopulatiei sa se afle în clasa Oi. Aceasta probabilitate este obtinuta cu ajutorul functieif (x). Astfel, frecventele teoretice absolute sunt n pi, i ∈ 1, 2, . . . , k. Altfel spus, n pieste numarul estimat de valori ale repartitiei cercetate ce ar cadea în clasa Oi. Pentru untest relevant, ar fi de dorit ca npi ≥ 5 pentru orice i. În cazul în care numarul estimat deaparitii într-o anumita clasa nu depaseste valoarea 5, atunci se vor cumula doua sau maimulte clase, astfel încât în noua clasa sa fie respectata conditia. Desi, daca avem cel putin5 clase, uneori sunt suficiente cel putin 3 valori în fiecare clasa.În consecinta, trebuie tinut cont de modificarea numarului de clase, iar numarul k trebuiemodificat corespunzator (îl înlocuim cu noul numar, notat aici tot cu k).
• Formulam ipoteza nula,
(H0) : Functia de repartitie a lui X este F(x).
Aceasta este echivalenta cu
(H0) : probabilitatea unei observatii de a apartine clasei Oi este pi (i = 1, 2, . . . , k).
• Ipoteza alternativa este negatia ipotezei nule.• Deviatia între cele doua situatii (empirica si teoretica) este masurata de statistica
χ2 =k
∑i=1
(ni−n pi)2
n pi. (6.1.1)
(Fiecare dintre termenii(ni−n pi)
2
n pipoate fi privit ca fiind o eroare relativa de aproximare
a valorilor asteptate ale repartitiei cu valorile observate.)Statistica χ2 urmeaza repartitia χ2(k−1). Uneori, statistica χ=
√χ2 se numeste discre-
panta.

6.1 Testul χ2 de concordanta 149
• Alegem nivelul de semnificatie α , de regula, foarte apropiat de zero.• Alegem regiunea critica, ca fiind regiunea pentru care valoarea χ2
0 a acestei statistici pentruobservatiile date satisface
χ20 > χ
21−α; k−1,
unde χ21−α; k−1 este cuantila de ordin 1−α pentru repartitia χ2(k−1).
• Daca ne aflam în regiunea critica, atunci datele observate sunt semnificativ diferite dedatele asteptate (calculate teoretic). În consecinta, ipoteza nula (H0) se respinge la nivelulde semnificatie α . Altfel, nu sunt dovezi statistice suficiente sa se respinga.
Observatie 6.1.1 Daca ipoteza nula este respinsa, atunci motivul poate fi acela ca unele valoriobservate au deviat prea mult de la valorile asteptate. În acest caz, este interesant de observatcare valori sunt extreme, cauzând respingerea ipotezei nule. Putem defini astfel reziduurilestandardizate:
ri =Oi−n pi√n pi (1− pi)
=Oi−Ei√Ei (1− pi)
,
unde prin Oi am notat valorile observate si prin Ei valorile asteptate. Daca ipoteza nula ar fiadevarata, atunci ri ∼N (0, 1). În general, reziduuri standardizate mai mari ca 2 sunt semnaleca datele contin valori observate extreme.
6.1.2 Cazul parametricCând probabilitatile teoretice pi nu sunt a priori cunoscute, atunci ele vor trebui estimate.Acest caz apare atunci când legea de probabilitate f (x, θ) nu este complet specificata, ci doarspecificata (stim forma lui f , dar nu stim unul sau, eventual, mai multi parametri ai sai). Folosinddatele observate, va trebui sa estimam parametrii necunoscuti ai repartitiei ipotetice. Fiecareestimare ne va costa un grad de libertate. Cu alte cuvinte, daca avem de estimat un singurparametru, atunci pierdem un grad de libertate, pentru doi parametri, pierdem doua grade etc.Sa presupunem ca legea de probabilitate a lui X de mai sus este f (x, θ), unde θ = (θ1, θ2,. . . , θp) ∈ Θ ⊂ Rp sunt parametri necunoscuti. Pentru a aproxima acesti parametri, folosimobservatiile culese asupra lui X . O metoda la îndemâna pentru estimari parametrice este metodaverosimilitatii maxime, dar cea mai potrivita metoda de estimare a parametrilor pentru a putea fiutilizati in testul lui Pearson este metoda minimului lui χ2.Dupa ce am estimat parametrii repartitiei teoretice ipotetice, determinam probabilitatile estimate.Stabilim apoi ipoteza nula:
(H0) : pi = pi, (i = 1, 2, . . . , k),
unde pi este probabilitatea unei observatii de a apartine clasei i si pi sunt valorile estimate.Din acest moment, etapele testului χ2− cazul parametric sunt asemanatoare cu cele din cazulneparametric, cu deosebirea ca statistica χ2 data prin (6.1.1) urmeaza repartitia χ2 cu (k− p−1)grade de libertate. Aceasta este urmare a faptului ca se pierd p grade de libertate din cauzafolosirii observatiilor date pentru estimarea celor p parametri necunoscuti.
Etapele aplicarii testului χ2 de concordanta (neparametric sau parametric)
• Se dau: α, x1, x2, . . . , xn. Intuim F(x; θ1, θ2, . . . , θp);• Formulam ipotezele statistice:(H0) functia de repartitie teoretica a variabilei aleatoare X este F(x; θ1, θ2, . . . , θp)(H1) ipoteza nula nu este adevarata.

150 Capitolul 6. Teste de concordanta
• Daca θ1, θ2, . . . , θk (k≤ p) nu sunt parametri cunoscuti, atunci determinam estimarile θ1, θ2, . . . , θkpentru acestia (doar în cazul parametric; altfel sarim peste acest pas);
• Scriem distributia empirica de selectie (tabloul de frecvente),(clasa Oi
ni
)i=1,k
,k
∑i=1
ni = n;
• Se calculeaza probabilitatea pi, ca un element luat la întâmplare sa se afle în clasa Oi. DacaOi = (ai−1, ai], atunci
pi = F(ai; θ)−F(ai−1; θ), în cazul neparametric;pi = F(ai; θ)−F(ai−1; θ), în cazul parametric.
Se verifica daca n pi ≥ 5, ∀i. Daca nu, se reorganizeaza clasele.
• Se calculeaza χ20 =
k
∑i=1
(ni−n pi)2
n pi;
• Determinam valoarea pragului teoretic χ∗, care este
χ∗ =
χ2
1−α; k−1 , în cazul neparametric,χ2
1−α; k−p−1 , în cazul parametric,
unde χ2α; n este cuantila de ordin α pentru repartitia χ2(n);
• Daca χ20 < χ
∗, atunci acceptam (H0), altfel o respingem.
6.2 Exercitii rezolvate
Exercitiu 6.2.1Se arunca un zar de 60 de ori si se obtin rezultatele dinTabelul 6.1. Pe baza acestor observatii, decideti dacazarul este corect sau fals (α = 0.05).
Fata (clasa Oi) Frecv. absoluta (ni)1 152 73 44 115 66 17
Tabela 6.1: Tabel cu numarul depuncte obtinute la aruncarea zarului.
R: (aplicam testul χ2 de concordanta, cazul neparametric)Zarul este corect doar daca fiecare fata a sa are aceeasi sansa de a aparea, adica probabilitatile cafiecare fata în parte sa apara sunt:
(H0) : pi =16, (i = 1, 2, . . . , 6).
Altfel, notam cu X variabila aleatoare ce are valori numarul punctelor ce apar la aruncarea zarului.Un zar corect ar însemna ca X urmeaza repartitia uniforma discreta U (6).Toate cele 60 de rezultate obtinute în urma aruncarii zarului pot fi împartite în sase clase. Acesteclase sunt: Oi = 1, 2, . . . , 6. Ipoteza nula este (H0) sau, echivalent,
(H0) : Functia de repartitie a lui X este U (6).
Ipoteza alternativa este "(H0) nu are loc", adica:
(H1) : Exista un j, cu p j 6=16, ( j ∈ 1, 2, . . . , 6).

6.2 Exercitii rezolvate 151
Calculez valoarea statisticii χ2 pentru observatiile date:
χ20 =
(15−10)2
10+
(7−10)2
10+
(4−10)2
10+
(11−10)2
10+
(6−10)2
10+
(17−10)2
10= 13.6.
Repartitia statisticii χ2 este χ2 cu k−1 = 5 grade de libertate. Regiunea critica este:
U = (χ20.95; 5; +∞) = (11.0705, +∞).
Deoarece χ20 se afla în regiunea critica, ipoteza nula se respinge la nivelul α = 0.05, asadar zarul
este masluit.Exercitiu 6.2.2 În urma unui recensamânt, s-a determinat ca proportiile indivizilor din RO ceapartin uneia dintre cele patru grupe sangvine sunt: O : 34%, A : 41%, B : 19%, AB : 6%. Pentruun esantion de 450 de persoane din România, s-a obtinut urmatoarele rezultate:
Grupa sanguina O A B ABFrecventa 136 201 82 31
Verificati, la nivelul de semnificatie α = 0.05, compatibilitatea datelor cu rezultatul teoretic.R: Ipotezele statistice sunt:
(H0) : Rezultatul observat este compatibil cu cel teoretic,
(H1) : Exista diferente semnificative între rezultatul teoretic si observatii.
Daca ipoteza nula ar fi adevarata, atunci valorile asteptate pentru cele patru grupe sangvine (din450 de persoane) ar fi: O : 153, A : 184.5, B : 85.5, AB : 27.Calculez valoarea statisticii χ2 pentru observatiile date:
χ20 =
(136−153.5)2
153.5+
(201−184.5)2
184.5+
(82−85)2
85+
(31−27)2
27= 4.1004.
Repartitia statisticii test este χ2(3). Astfel, regiunea critica este:
U = (χ20.95; 3; +∞) = (7.8147, +∞).
Deoarece χ20 nu se afla în regiunea critica, ipoteza nula nu poate fi respinsa la acest nivel de
semnificatie.Exercitiu 6.2.3 La campionatul mondial de fotbal din 2006 au fost jucate în total 64 de meciuri,iar repartitia numarului de goluri înscrise într-un meci are tabelul de distributie ca în Tabelul 6.2.Determinati (la nivelul de semnificatie α = 0.05) daca numarul de goluri pe meci urmeaza odistributie Poisson.
Nr. de goluri pe meci Nr. de meciuri0 81 132 183 114 105 26 2
Tabela 6.2: Tabel cu numarul de goluri pe meci la FIFA WC 2006.

152 Capitolul 6. Teste de concordanta
R: (aplicam testul de concordanta χ2 parametric) Fie X variabila aleatoare ce reprezintanumarul de goluri înscrise într-un meci. Teoretic, X poate lua orice valoare din multimea N.Multimea observatiilor facute asupra lui X este 0, 1, 2, 3, 4, 5, 6, cu frecventele respective dintabel. În total, au fost inscrise 144 de goluri. Estimam numarul de goluri pe meci prin medialor, adica λ = x = 144
64 = 2.25. Pe baza datelor observate, dorim sa testam daca X urmeaza orepartitie Poisson. Avem astfel de testat ipoteza nula:
(H0) : X urmeaza o lege Poisson P(λ ).
vs. ipoteza alternativa
(H1) : X nu urmeaza o lege Poisson P(λ ).
Clasa ni pi n pi(ni−n pi)
2
n pi0 8 0.1054 6.7456 0.23331 13 0.2371 15.1775 0.31242 18 0.2668 17.0747 0.05013 11 0.2001 12.8060 0.25474 10 0.1126 7.2034 1.08575 2 0.0506 3.2415 −≥ 6 2 0.0274 1.7514 −≥ 5 4 0.0780 4.9926 0.1973
Tabela 6.3: Tablou de distributie pentru P(2.25).
Daca admitem ipoteza (H0) (adica X ∼P(2.25), atunci pi = pi(λ ) si distributia valorilorvariabilei este data de Tabelul 6.3. Valoarea pi este P(X = i), adica probabilitatea ca variabilaaleatoare X ∼P(2.25) sa ia valoarea i (i = 0, 1, 2, 3, 4). Am putea forma 7 clase. Deoarecepentru ultimele doua clase din Tabelul 6.3, si anume X = 5 si X ≥ 6, valorile asteptate înaceste clase, npi nu depasesc valoarea 3, le stergem din tabel si le unim într-o singura clasa, încare X ≥ 5, cu npi ≈ 5. Vom nota prin p≥5 probabilitatea
p≥5 = P(X ≥ 5) = 1−P(X < 5) = 1−P(X ≤ 4) = 1−4
∑i=0
P(X = i).
Ramânem asadar cu 6 clase. Ipoteza nula (H0) se poate rescrie astfel:
(H0) : p0 = 0.1054, p1 = 0.2371, p2 = 0.2668, p3 = 0.2001, p4 = 0.1126, p≥5 = 0.0780.
Ipoteza alternativa este
(H1) : ipoteza (H0) nu este adevarata.
Calculam acum valoarea statisticii χ2 pentru observatiile date:
χ20 =
(8−6.7456)2
6.7456+
(13−15.1775)2
15.1775+
(18−17.0747)2
17.0747+
(11−12.8060)2
12.8060+ . . .
+(10−7.2034)2
7.2034+
(4−4.9926)2
4.9926= 2.1337.
Deoarece avem 6 clase si am estimat parametrul λ , deducem ca numarul gradelor de libertateeste 6−1−1 = 4. Cuantila de referinta (valoarea critica) este χ2
0.95; 4 = 9.4877. Regiunea critica

6.2 Exercitii rezolvate 153
pentru χ2 este intervalul (χ20.95; 4, +∞). Deoarece χ2
0 < χ20.95; 4, urmeaza ca ipoteza nula (H0)
nu poate fi respinsa la nivelul de semnificatie α . Asadar, este rezonabil sa afirmam ca numarulde goluri marcate urmeaza o repartitie Poisson.Exercitiu 6.2.4 Într-o anumita zi de lucru, sunt urmariti timpii de asteptare într-o statie detramvai, pâna la încheierea zilei de lucru (adica, pâna trece ultimul tramvai). Notam cu T carac-teristica ce reprezinta numarul de minute asteptate în statie, pâna soseste tramvaiul. Rezultateleobservatiilor sunt sumarizate în Tabelul 6.4. Se cere sa se cerceteze (α = 0.05) daca timpii deasteptare sunt repartizati exponential.
Durata 0−5 5−10 10−15 15−20 20−25ni 39 35 14 7 5
Tabela 6.4: Timpi de asteptare în statia de tramvai.
R: (folosim testul χ2 de concordanta, parametric) Avem de testat ipoteza nula
(H0) F(x)∼= F0(x) = 1− e−λ x, x > 0
vs. ipoteza alternativa(H1) ipoteza (H0) este falsa.
Deoarece parametrul λ este necunoscut, va trebui estimat pe baza selectiei date. Pentru aceasta,folosim metoda verosimilitatii maxime. Functia de verosimilitate pentru exp(λ ) este
L (t1, t2, . . . , tn; λ ) =n
∏k=1
λe−λ ti = λne−λ nt .
Mai sus, am notat prin t1, t2, . . . , tn valorile de selectie pentru variabila aleatoare T .Punctele critice pentru L (λ ) sunt date de ecuatia
∂ lnL
∂λ= 0 =⇒ ∂
∂λ(n lnλ −λ nt) =⇒ λ =
1t.
Se observa cu usurinta ca∂ 2 lnL
∂λ 2 |λ=λ=−nt2 < 0,
de unde concluzionam ca λ este punct de maxim pentru functia de verosimilitate.Tabelul de distributie pentru caracteristica T este:(
2.5 7.5 12.5 17.5 22.539 35 14 7 5
).
Calculam media de selectie, t = 1100(2.5 · 39+ 7.5 · 35+ 12.5 · 14+ 17.5 · 7+ 22.5 · 5) = 7.7,
adica λ ≈ 0.1299.Daca variabila T ar urma repartitia exponentiala exp(λ ), atunci probabilitatile ca T sa ia valoriîn fiecare dintre cele cinci clase sunt, în mod corespunzator:
pi = P(X ∈ [ai, ai+1) | F = F0) = F0(ai+1; λ )−F0(ai; λ )
= e−ai λ − e−ai+1 λ , i = 1, 2, 3, 4, 5.
unde a6 =+∞.În Tabelul 6.5 am înregistrat urmatoarele date:

154 Capitolul 6. Teste de concordanta
• clasele (de notat ca ultima clasa este [20,+∞), deoarece se doreste o concordanta adatelor observate cu date repartizate exponential, iar multimea valorilor pentru repartitiaexponentiala este R+),
• extremitatile din stânga ale claselor (ai),• frecventele absolute ni (sau valorile observate în fiecare clasa),• probabilitatile pi, valorile asteptate în fiecare clasa (n pi),• erorile relative de aproximare ale datelor asteptate cu cele observate.
Numarul gradelor de libertate este k− p−1 = 3. Calculam valoarea critica χ20.95; 3 = 7.8147 si,
de asemenea, valoarea
χ20 =
k
∑i=1
(ni−n pi)2
n pi= 6.5360.
Deoarece χ20 < χ2
0.95; 3, ipoteza (H0) nu poate fi respinsa la acest nivel de semnificatie.
Clasa ai ni pi n pi(ni−n pi)
2
n pi[0, 5) 0 39 0.4777 47.77 1.6101[5, 10) 5 35 0.2495 24.95 4.0482[10, 15) 10 14 0.1303 13.03 0.0722[15, 20) 15 7 0.0681 6.81 0.0053[20,+∞) 20 5 0.0744 7.44 0.8002[0,+∞) − 100 1 100 6.5360
Tabela 6.5: Tabel de distributie pentru timpii de asteptare
6.3 Exercitii propuse
Exercitiu 6.3.1 Se prezice ca repartitia literelor care apar cel mai des în limba engleza ar fiurmatoarea:
Litera O R N T EFrecventa 16 17 17 21 29
Aceasta semnifica urmatoarea: de fiecare data când cele 5 litere apar într-un text, în 16% dintrecazuri apare litera O, în 21% dintre cazuri apare litera T etc. Sa presupunem ca un criptologistanalizeaza un text si numara aparitiile celor 5 litere. Acesta a gasit urmatoarea distributie:
Litera O R N T EFrecventa 18 14 18 19 31
Folosind testul χ2 de concordanta, sa se verifice daca aceste aparitii sunt în nota discordanta cupredictia initiala.
Exercitiu 6.3.2 Tabelul urmator contine numarul de nasteri pe zi ce au avut loc într-o anumitamaternitate, observate în decursul a 100 de zile alese la întâmplare.
nasteri pe zi 0 1 2 3 4 5 6frecventa 21 27 33 10 7 1 1

6.3 Exercitii propuse 155
(a) Estimati numarul mediu de nasteri pe zi ce au loc în mod regulat în acea maternitate.(b) Testati ipoteza ca numarul de nasteri pe zi este o variabila aleatoare repartizata Poisson.(c) Folosind rezultatul de la punctul (b), estimati probabilitatea ca, într-o zi aleasa la întâmplare,sa aiba loc cel putin 2 nasteri în acea maternitate.
Exercitiu 6.3.3 Se doreste determinarea sanselor de avea un baiat sau o fata pentru mamele cupatru copii. Avem la îndemâna o selectie de 564 de mame a câte 4 copii. Rezultatele sunt celedin tabelul de mai jos.
Numar de copii Frecventa4 fete 38
3 fete si un baiat 1382 fete si 2 baieti 213o fata si 3 baieti 141
4 baieti 34
(i) Reprezentati grafic datele pe un pe disc (pie chart).(ii) La nivelul de semnificatie α = 0.05, testati ipoteza ca, pentru mamele cu patru copii,probabilitatea de avea un baiat este egala cu probabilitatea de avea o fata.Indicatie: Se testeaza concordanta cu repartitia B(4,0.5).
Exercitiu 6.3.4 Se arunca o moneda de 250 de ori, obtinându-se 138 de aparitii ale stemei. Laun nivel de semnificatie α = 0.05, sa se decida daca avem suficiente dovezi de a afirma ca acestamoneda este falsa.
Exercitiu 6.3.5 Datele din tabelul de mai jos reprezinta repartizarea pe vârste pentru un esantionde 385 de someri dintr-o anumita regiune a tarii.
Vârsta [18, 25) [25, 35) [35, 45) [45, 55) [55, 65)Frecventa 34 76 124 87 64
(a) Reprezentati datele prin bare.(b) Folosind testul χ2, testati daca datele din tabel sunt observatii facute asupra unei caracteristicinormale (se va alege α = 0.05).
Exercitiu 6.3.6 Se considera caracteristica X ce reprezinta înaltimea barbatilor (în centimetri)dintr-o anumita regiune a unei tari. S-a facut o selectie de volum n = 200, iar datele de selectieau fost grupate în tabelul urmator:
Clasa ≤ 165 (165, 170] (170, 175] (175, 180] (180, 185] (185, 190] (190, 195] ≥ 195ni 12 25 34 47 36 27 17 2
(a) Reprezentati datele printr-o histograma.(b) Precizati estimatori nedeplasati pentru media si dispersia înaltimii barbatilor din acea regiune.Folosind datele din tabel, determinati valorile acestor estimatori.(c) Testati daca datele din tabel sunt observatii facute asupra unei caracteristici normale(α = 0.05).(d) Care este probabilitatea ca un barbat ales la întâmplare din acest tinut sa fie mai înalt de182cm?
Exercitiu 6.3.7 Testati normalitatea datelor din Tabelul 2.5 la nivelul de semnificatie α = 0.1.


7. Corelatie si regresie
7.1 Introducere
În acest capitol vom discuta masuri si tehnici de determinare a legaturii între doua sau mai multevariabile aleatoare. Pentru lecturi suplimentare, se pot consulta materialele [18], [19], [22].Primele metode utilizate în studiul relatiilor dintre doua sau mai multe variabile au aparut dela începutul secolului al XIX-lea, în lucrarile lui Legendre1 si Gauss2, în ce priveste metodacelor mai mici patrate pentru aproximarea orbitelor astrelor în jurul Soarelui. Un alt mare omde stiinta al timpului, Francis Galton3, a studiat gradul de asemanare între copii si parinti, atâtla oameni, cât si la plante, observând ca înaltimea medie a descendentilor este legata liniar deînaltimea ascendentilor. Este primul care a utilizat conceptele de corelatie si regresie ( (lat.)regressio - întoarcere). Astfel, a descoperit ca din parinti a caror înaltime este mai mica decâtmedia colectivitatii provin (în general) copii cu o înaltime superioara lor si, vice-versa, dinparinti cu înaltimi peste media colectivitatii provin (în general) copii cu o înaltime inferioaralor. Astfel, a concluzionat ca înaltimea copiilor ce provin din parinti înalti tinde sa "regreseze"spre înaltimea medie a populatiei. Din lucrarile lui Galton s-a inspirat un student de-al sau, KarlPearson, care a continuat ideile lui Galton si a introdus coeficientul (empiric) de corelatie ce îipoarta numele. Acest coeficient a fost prima masura importanta introdusa care cuantifica tarialegaturii dintre doua variabile ale unei populatii statistice.
Un ingredient fundamental în studiul acestor doua concepte este diagrama prin puncte, numitadiagrama scatter plot. În probleme de regresie în care apare o singura variabila raspuns (variabilacare este prezisa) si o singura variabila predictor (variabila pe baza careia facem predictia),diagrama scatter plot (raspuns vs. predictor) este punctul de plecare pentru studiul regresiei.
1Adrien-Marie Legendre (1752−1833), matematician francez2Johann Carl Friedrich Gauss (1777−1855), matematician si fizician german3Sir Francis Galton (1822−1911), om de stiinta britanic

158 Capitolul 7. Corelatie si regresie
O diagrama scatter plot ar trebui reprezentata pentru oriceproblema de analiza regresionala, deoarece aceasta ne vada o prima idee despre ce tip de regresie vom folosi. Unexemplu de astfel de diagrama este reprezentat în Figura7.1, în care am reprezentat coeficientul de inteligenta (IQ)a 200 de perechi sot-sotie. Fiecare cruciulita din diagramareprezinta IQ-ul pentru o pereche sot-sotie.
Figura 7.1: Scatter plot pentru IQîn familie.
7.2 Corelatie si coeficient de corelatieCorelatia sau covarianta sunt termene statistice folosite pentru a defini interdependenta saulegatura între doua sau mai multe variabile aleatoare. Totodata, corelatia este si o metodastatistica de descriere si analiza a legaturilor de tip statistic între doua sau mai multe variabile.Daca X , Y sunt doua variabile aleatoare ce admit medie, atunci corelatia sau covarianta(teoretica) dintre X si Y se defineste prin:
cov(X , Y ) = E [(X−E(X)) · (Y −E(Y ))] = E(X ·Y )−E(X) ·E(Y ).Observatie 7.2.1 (i) Din punct de vedere teoretic, daca X si Y sunt variabile aleatoare inde-pendente, atunci cov(X , Y ) = 0.Reciproca nu este, în general, adevarata. De exemplu, daca X ∼U (−1, 1) si Y = X2, atunci
cov(X , Y ) = E(X ·Y )−E(X) ·E(Y ) = E(X3)−E(X) ·E(X2)
=∫ 1
−1x3 dx−
(∫ 1
−1xdx)(∫ 1
−1x2 dx
)= 0,
însa X si Y = X2 sunt dependente.(ii) În cazul în care X si Y sunt, în plus, variabile aleatoare normal repartizate, atunci independentavariabilelor aleatoare X si Y este echivalenta cu necorelarea lor (i.e., cov(X , Y ) = 0).O relatie liniara între doua variabile este acea relatie ce poate fi reprezentata cel mai bine printr-olinie. Corelatia detecteaza doar dependente liniare între doua variabile aleatoare. Putem avea ocorelatie pozitiva, însemnând ca X si Y cresc sau descresc împreuna, sau o corelatie negativa,însemnând ca X si Y se modifica în directii opuse.
7.2.1 Coeficient teoretic de corelatieO masura standardizata a corelatiei dintre doua variabile este coeficientul de corelatie. Acestaeste foarte utilizat în stiinte ca fiind o masura a dependentei liniare între doua variabile. Dinpunct de vedere teoretic, definim coeficientul de corelatie a doua variabile aleatoare X si Y prin:
ρX,Y =cov(X , Y )
σX ·σY= cov(X , Y ),
unde X si Y sunt variabilele aleatoare standardizate iar
σX =√E[(X−X)2
]si σY =
√E[(Y −Y )2
]sunt deviatiile standard teoretice corespunzatoare variabilelor X , respectiv Y .

7.2 Corelatie si coeficient de corelatie 159
Propozitie 7.2.1 (proprietati ale coeficientului teoretic de corelatie):(a) Coeficientul de corelatie este simetric, i.e., ρX,Y = ρY,X.(b) Daca X si Y sunt independente, atunci
ρX,Y = 0.
(c) −1≤ ρX,Y ≤ 1, pentru orice variabile X si Y .(d) Daca Y = aX +b (a, b ∈ R, a 6= 0), atunci
ρX,Y =
+1, daca a > 0;−1, daca a < 0.
(e) Daca a, b, c, d ∈ R, a, c > 0, atunci ρaX+b,cY+d = ρX,Y.
Magnitudinea (valoarea absoluta) coeficientului de corelatie ρX,Y determina taria relatiei liniaredintre variabilele aleatoare X si Y . Daca ρX,Y = 1, atunci X si Y sunt perfect pozitiv corelate,iar daca ρX,Y =−1, variabilele X si Y vor fi perfect negativ corelate. Daca reprezentam graficperechile ordonate (x, y), ele se vor afla pe o dreapta de panta pozitiva, daca ρX,Y = 1, si de pantanegativa pentru ρX,Y =−1.Corelarea nu implica o cauzalitate. Cu alte cuvinte, doar faptul ca variabilele X si Y sunt corelatenu implica faptul ca X ar cauza pe Y sau invers. Cu alte cuvinte, daca doua variabile X si Y suntcorelate pozitiv (spre exemplu), atunci nu este obligatoriu ca oricarei valori xk mai mari decâtmedia E(X) sa îi corespunda o valoare yk mai mare decât media E(Y ).
7.2.2 Coeficient empiric de corelatieÎn practica, pentru a stabili daca exista sau nu vreo legatura între doua variabile aleatoare, se facobservatii asupra acestora, urmând apoi a cuantifica relatia dintre observatii.Fie (xk, yk), k ∈ 1, 2, . . . , n un set de date bidimensionale, ce reprezinta observatii asupravectorului aleator (X , Y ). O masura a legaturii dintre xkk si ykk este coeficientul de corelatieempiric introdus de K. Pearson (în literatura de specialitate mai este cunoscut si sub denumireade coeficientul r):
r =
n
∑k=1
(xk− x)(yk− y)√n
∑k=1
(xk− x)2
√n
∑k=1
(yk− y)2
(7.2.1)
=1
n−1
n
∑k=1
(xk− x
sx
)(yk− y
sy
)=
cove(x, y)sx · sy
, (7.2.2)
unde
cove(x, y) =1
n−1
n
∑k=1
(xk− x)(yk− y), sx =
√1
n−1
n
∑k=1
(xk− x)2, sy =
√1
n−1
n
∑k=1
(yk− y)2
sunt covarianta (corelatia) empirica si deviatiile standard empirice pentru X si Y .Daca r > 0, vom spune ca perechile de date sunt pozitiv corelate, iar daca r < 0, vom spune caperechile de date sunt negativ corelate.

160 Capitolul 7. Corelatie si regresie
Propozitie 7.2.2 (proprietati ale coeficientului empiric de corelatie (al lui Pearson)):(a) Coeficientul lui Pearson este simetric, i.e., rX,Y = rY,X.(b) −1≤ r ≤ 1.(c) Daca yk = axk +b (a, b ∈ R, a 6= 0), k = 1, 2, . . . , n, atunci
rX,Y =
+1, daca a > 0;−1, daca a < 0.
(d) Daca r este coeficientul de corelatie Pearson pentru (xk, yk)nk=1, atunci r este coeficientul
de corelatie Pearson pentru (axk +b, cyk +d)ni=1, unde a, b, c, d ∈ R, a, c > 0.
Demonstratie. (b) Plecam de la
n
∑k=1
[xk− x
sx− yk− y
sy
]2
≥ 0,
de unden
∑k=1
(xk− x
sx
)2
+n
∑k=1
(yk− y
sy
)2
−2n
∑k=1
(xk− x
sx· yk− y
sy
)≥ 0,
(n−1)+(n−1)−2(n−1)r ≥ 0 ⇐⇒ r ≤ 1.
Similar, plecând de lan
∑k=1
[xk− x
sx+
yk− ysy
]2
≥ 0,
gasim ca r ≥−1.
Observatie 7.2.2 [1] Daca X si Y sunt independente, atunci ρX,Y= 0. Totusi, daca (xk, yk)nk=1
este un set observatii asupra vectorului aleator (X , Y ), atunci rX,Y nu este neaparat egal cu 0.[2] La fel ca si coeficientului de corelatie teoretic, ρX,Y, coeficientul r al lui Pearson ia valoridoar în intervalul [−1, 1]. Cazurile limita pentru r sunt r = 1 sau r =−1, cazuri în care putemtrage concluzia ca variabilele X si Y sunt pozitiv, respectiv, negativ) perfect corelate (vezi Figura7.2). Pentru valori ale lui r între −1 si 1, nu putem vorbi de gradul de corelare între X si Y fara aefectua un test statistic asupra valorii coeficientulul teoretic de corelatie, ρ . De multe ori însa,putem afirma ca avem o corelatie pozitiva daca r este apropiat de valoarea 1 (e.g., r = 0.85, cazîn care norul de date are panta ascendenta) si avem o corelatie negativa daca r este apropiat devaloarea −1 (e.g., r =−0.98, caz în care norul de date are panta descendenta).Spre exemplu, pentru esantioanele
x = [0.49 -0.45 0.39 0.05 -0.49 0.24 0.72 0.15 0.13 -1.01];
y = [1.31 1.20 -2.58 -2.09 0.39 -0.86 -1.23 2.64 -0.90 -1.22];
coeficientul r al lui Pearson ester =−0.0905,
care indica o corelatie negativa dintre xk si yk foarte slaba. Acest rezultat ar putea sugera faptulca cele doua selectii sunt observatii obtinute din doua variabile aleatoare necorelate (i.e., ρ = 0),fapt ce va trebui confirmat folosind un test statistic în care testam ipoteza nula ρ = 0, cu ipotezaalternativa ρ 6= 0.
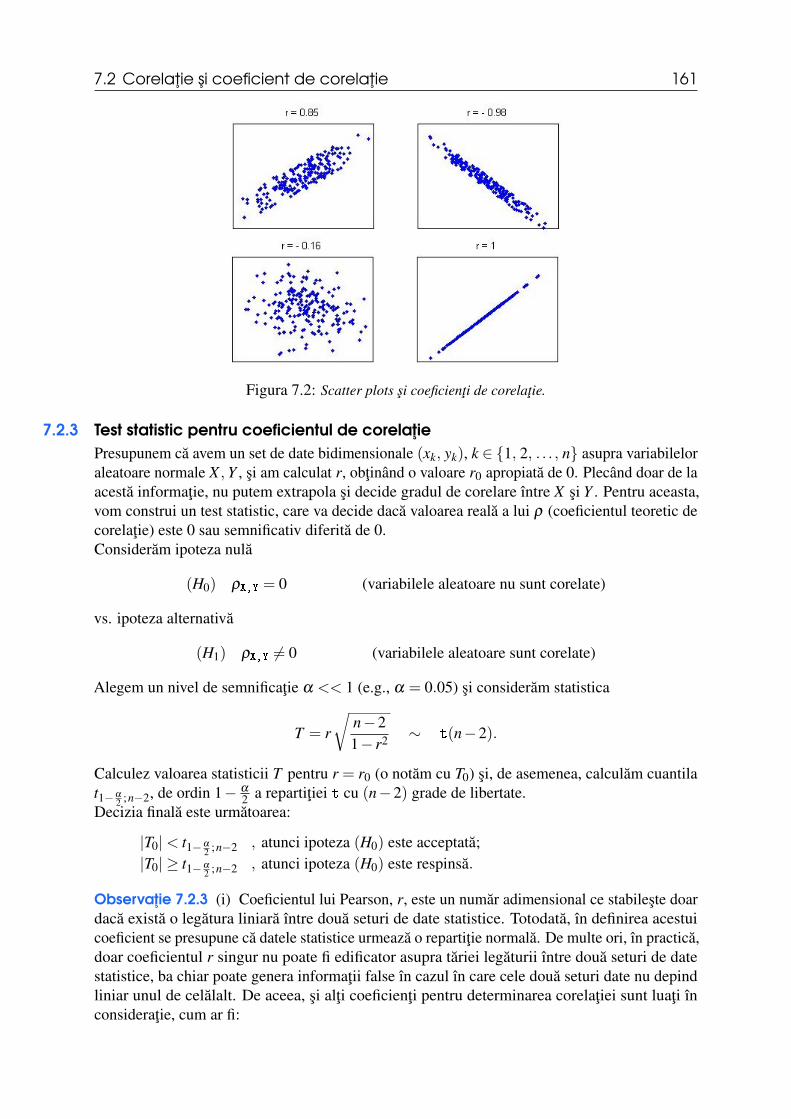
7.2 Corelatie si coeficient de corelatie 161
Figura 7.2: Scatter plots si coeficienti de corelatie.
7.2.3 Test statistic pentru coeficientul de corelatiePresupunem ca avem un set de date bidimensionale (xk, yk), k ∈ 1, 2, . . . , n asupra variabileloraleatoare normale X , Y , si am calculat r, obtinând o valoare r0 apropiata de 0. Plecând doar de laacesta informatie, nu putem extrapola si decide gradul de corelare între X si Y . Pentru aceasta,vom construi un test statistic, care va decide daca valoarea reala a lui ρ (coeficientul teoretic decorelatie) este 0 sau semnificativ diferita de 0.Consideram ipoteza nula
(H0) ρX,Y = 0 (variabilele aleatoare nu sunt corelate)
vs. ipoteza alternativa
(H1) ρX,Y 6= 0 (variabilele aleatoare sunt corelate)
Alegem un nivel de semnificatie α << 1 (e.g., α = 0.05) si consideram statistica
T = r
√n−21− r2 ∼ t(n−2).
Calculez valoarea statisticii T pentru r = r0 (o notam cu T0) si, de asemenea, calculam cuantilat1−α
2 ;n−2, de ordin 1− α
2 a repartitiei t cu (n−2) grade de libertate.Decizia finala este urmatoarea:
|T0|< t1−α
2 ;n−2 , atunci ipoteza (H0) este acceptata;|T0| ≥ t1−α
2 ;n−2 , atunci ipoteza (H0) este respinsa.
Observatie 7.2.3 (i) Coeficientul lui Pearson, r, este un numar adimensional ce stabileste doardaca exista o legatura liniara între doua seturi de date statistice. Totodata, în definirea acestuicoeficient se presupune ca datele statistice urmeaza o repartitie normala. De multe ori, în practica,doar coeficientul r singur nu poate fi edificator asupra tariei legaturii între doua seturi de datestatistice, ba chiar poate genera informatii false în cazul în care cele doua seturi date nu depindliniar unul de celalalt. De aceea, si alti coeficienti pentru determinarea corelatiei sunt luati înconsideratie, cum ar fi:

162 Capitolul 7. Corelatie si regresie
• r2, coeficientul de determinare (notat în Statistica prin R2), care stabileste care esteprocentul din variatia uneia dintre datele statistice ce determina (sau explica) pe celelaltedate. De exemplu, un coeficient de determinare R2 = 0.42 semnifica faptul ca variabilaindependenta explica doar 42% din variatia variabilei dependente. În Statistica, acestcoeficient este definit în mai multe moduri, unele nu tocmai într-un mod echivalent;
• coeficientul lui Spearman4, coeficientul lui Kendall5 etc. (acestea nu presupun ca datelestatistice sunt normale)
(ii) Se poate testa, de asemenea, ipoteza nula
(H0) : ρX,Y = ρ0, cu ρ0 6= 0,
însa aceasta nu este foarte des întâlnita în practica.În acest sens, se poate utiliza statistica
Z =12
ln(
1+ r1− r
)= arctanh(r) ∼ N
(12
ln(
1+ρ0
1−ρ0
),
1√n−3
).
(iii) Corelatia a doua variabile aleatoare nu implica o cauzalitate. Cu alte cuvinte, exista ocorelatie între vârsta si înaltime la copii, însa niciuna dintre aceastea nu o cauzeaza pe cealalta.Corelatia poate fi luata în evidenta pentru o posibila relatie cauzala, însa nu este determinanta sinu poate preciza relatia cauzala, daca aceasta exista.(iv) Volumul selectiei este un factor foarte important în testarea ipotezei ca doua variabilealeatoare sunt necorelate. Spre exemplu, o relatie poate fi puternica (având un r nu foarte aproapede 0), însa nu semnificativa, daca valoarea lui n nu este suficient de mare. Invers, o relatie poatefi slaba (un r aproape de 0), dar semnificativa. Exemplul (7.2.1) poate fi edificator.
Exemplu 7.2.1 Sa presupunem ca dorim sa stabilim daca exista vreo legatura între vârsta uneipersoane si coeficientul sau de inteligenta. Pe baza a doua seturi de datele asupra acestorcaracteristici, de volum n = 10, gasim un coeficient de corelatie empiric r = 0.62. Se cere:(a) Este aceasta legatura puternica?(b) Este aceasta legatura semnificativa?R: (a) Calculam coeficientul de determinare si gasim ca R2 = 0.3844. Asta semnifica faptul cadoar 38.44% din variatia coeficientului de inteligenta este explicata de vârsta.(b) Aplicam testul pentru coeficientul de corelatie la un nivel de semnificatie α = 0.05. Ipotezanula este
(H0) Nu exista o corelatie semnificativa între vârsta si IQ
Ipoteza alternativa este
(H1) Exista o corelatie semnificativa între vârsta si IQ
Statistica considerata va avea 8 grade de libertate, T0 = 0.62√
81−0.3844 = 2.2351 < 2.3060 =
t0.975;8, de unde concluzionam ca ipoteza nula ρ = 0 este admisa (i.e., nu sunt dovezi suficientepentru ca ipoteza sa poate fi respinsa la acest nivel de semnificatie).
(v) Se poate testa si ipoteza ca doi coeficienti de corelatie ce corespund fiecare la câte douaselectii difera semnificativ unul de celalalt. Presupunem ca avem de testat ipoteza
(H0) : ρ1 = ρ2,
4Charles Edward Spearman (1863−1945), psiholog britanic5Sir Maurice George Kendall (1907−1983), statistician britanic

7.3 Coeficientul de corelatie Spearman 163
vs. ipoteza alternativa(H1) : ρ1 6= ρ2.
Presupunem ca volumele selectiilor folosite în testare sunt n1 si n2 si ca r1, r2 sunt coeficientiide corelatie empirici calculati. Pentru a testa ipoteza de mai sus, se foloseste faptul ca variabilele
Zi =12
ln(
1+ ri
1− ri
), i = 1, 2.
au o distributie asimptotica normala N(
12 ln(
1+ρi1−ρi
), 1√
n−3
). Atunci, distributia asimptotica a
statisticii Z = Z1−Z2 este
Z ∼ N
(µZ1−µZ2,
√1
n1−3+
1n2−3
),
cu µZi =12 ln(
1+ρi1−ρi
), i = 1, 2. Statistica test va fi
Z =Z1−Z2− (µZ1−µZ2)√
1n1−3 +
1n2−3
∼ N (0, 1) ,
Daca |z| ≤ z1−α
2, acceptam ipoteza (H0), altfel o respingem.
7.3 Coeficientul de corelatie SpearmanÎn cazul datelor calitative, unde nu se pot asocia valori numerice pentru caracteristica de interes,coeficientul de corelatie Pearson nu mai poate fi calculat. De asemenea, daca datele nu satisfacipoteza de normalitate, folosirea coeficientului Pearson in testarea corelatiei dintre valori poate fipusa sub semnul întrebarii. O alternativa neparametrica a coeficientului Pearson este coeficientulde corelatie Spearman, sau coeficientul de corelatie a rangurilor. Acest coeficient poate ficalculat atât pentru date calitative, cât si pentru date cantitative. Pentru a calcula acest coeficient,fiecarui atribut sau fiecarei valori a caracteristicii i se desemneaza un rang. Coeficientul decorelatie Spearman este coeficientul de corelatie Pearson pentru aceste ranguri. Coeficientul luiSpearman este utilizat în depistarea (daca este cazul) a unei relatii monotone între doua variabile(fie ea liniara sau nu). Acest coeficient este mai putin senzitiv la valorile extreme (outliers)ale seturilor de date, în sensul ca valori foarte mari sau foarte mici comparativ cu altele nuinfluenteaza valoarea coeficientului Spearman.În general, daca (xi, yi)n
i=1 este un set de date bidimensionale, ale caror ranguri corespunzatoaresunt (x∗i , y∗i )
ni=1, atunci coeficientul de corelatie Spearman (notat aici cu rS) este
rS =
n
∑k=1
(x∗k− x∗)(y∗k− y∗)√n
∑k=1
(x∗k− x∗)2
√n
∑k=1
(y∗k− y∗)2
. (7.3.3)
La fel ca si coeficientul lui Pearson, coeficientul Spearman ia valori reale în intervalul [−1, 1];valoarea 1 însemnând corelatie pozitiva perfecta a rangurilor, iar valoarea−1 însemnând corelatienegativa perfecta a rangurilor.
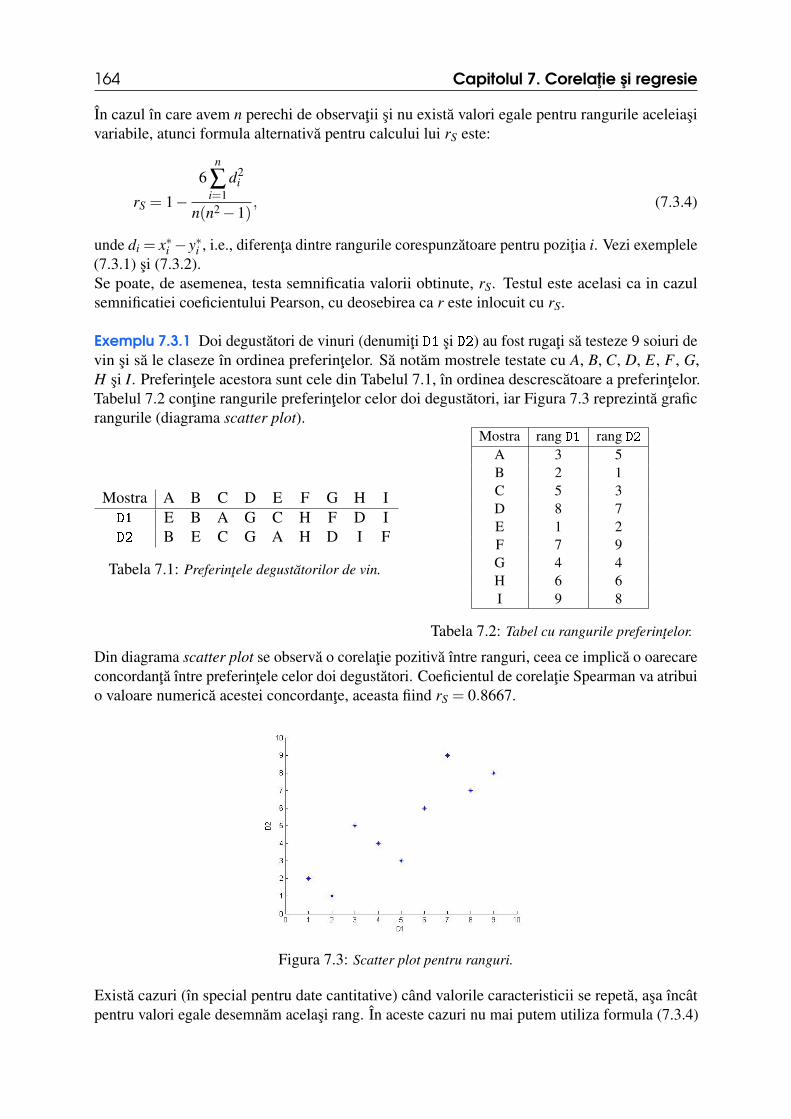
164 Capitolul 7. Corelatie si regresie
În cazul în care avem n perechi de observatii si nu exista valori egale pentru rangurile aceleiasivariabile, atunci formula alternativa pentru calcului lui rS este:
rS = 1−6
n
∑i=1
d2i
n(n2−1), (7.3.4)
unde di = x∗i −y∗i , i.e., diferenta dintre rangurile corespunzatoare pentru pozitia i. Vezi exemplele(7.3.1) si (7.3.2).Se poate, de asemenea, testa semnificatia valorii obtinute, rS. Testul este acelasi ca in cazulsemnificatiei coeficientului Pearson, cu deosebirea ca r este inlocuit cu rS.
Exemplu 7.3.1 Doi degustatori de vinuri (denumiti D1 si D2) au fost rugati sa testeze 9 soiuri devin si sa le claseze în ordinea preferintelor. Sa notam mostrele testate cu A, B, C, D, E, F , G,H si I. Preferintele acestora sunt cele din Tabelul 7.1, în ordinea descrescatoare a preferintelor.Tabelul 7.2 contine rangurile preferintelor celor doi degustatori, iar Figura 7.3 reprezinta graficrangurile (diagrama scatter plot).
Mostra A B C D E F G H ID1 E B A G C H F D ID2 B E C G A H D I F
Tabela 7.1: Preferintele degustatorilor de vin.
Mostra rang D1 rang D2
A 3 5B 2 1C 5 3D 8 7E 1 2F 7 9G 4 4H 6 6I 9 8
Tabela 7.2: Tabel cu rangurile preferintelor.
Din diagrama scatter plot se observa o corelatie pozitiva între ranguri, ceea ce implica o oarecareconcordanta între preferintele celor doi degustatori. Coeficientul de corelatie Spearman va atribuio valoare numerica acestei concordante, aceasta fiind rS = 0.8667.
Figura 7.3: Scatter plot pentru ranguri.
Exista cazuri (în special pentru date cantitative) când valorile caracteristicii se repeta, asa încâtpentru valori egale desemnam acelasi rang. În aceste cazuri nu mai putem utiliza formula (7.3.4)

7.4 Regresia 165
pentru calculul coeficientului Spearman, ci va trebui sa utilizam formula (7.3.3) (vezi exemplulurmator).
Exemplu 7.3.2 Datele din Tabelul 7.3 reprezinta numarul de accidente rutiere (A) si numarul dedecese (D) înregistrate într-un anumit oras, în primele 6 luni ale anului. Rangurile corespunzatoarevalorilor sunt prezentate în Tabelul 7.4. Datele au fost introduse în tabel în ordinea inversa anumarului de accidente. De notat ca, deoarece numarul de decese înregistrate în luna Mai esteegal cu numarul de decese din Aprilie, rangul pentru fiecare dintre cele doua luni este mediacelor doua pozitii în care s-ar afla. Folosind formula (7.3.3), calculam coeficientul de corelatieSpearman. Acesta este rS = 0.8117.
Luna Ian. Feb. Mar. Apr. Mai Iun.A 27 24 15 11 17 12D 8 6 5 3 3 2
Tabela 7.3: Evenimente rutiere în primele 6 luni.
Luna A rang A D rang D
Ian. 27 6 8 6Feb. 24 5 6 5Mai 17 4 3 2+3
2 = 2.5Mar. 15 3 5 4Iun. 12 2 2 1Apr. 11 1 3 2+3
2 = 2.5
Tabela 7.4: Tabel cu rangurile pentruaccidente.
7.4 RegresiaRegresia este o metoda statistica utilizata pentru descrierea naturii relatiei între variabile. Defapt, regresia stabileste modul prin care o variabila depinde de alta variabila, sau de alte variabile.Analiza regresionala cuprinde tehnici de modelare si analiza a relatiei dintre o variabila depen-denta (variabila raspuns) si una sau mai multe variabile independente. De asemenea, raspunde laîntrebari legate de predictia valorilor viitoare ale variabilei raspuns pornind de la o variabila datasau mai multe. În unele cazuri se poate preciza care dintre variabilele de plecare sunt importanteîn prezicerea variabilei raspuns. Se numeste variabila independenta o variabila ce poate fimanipulata (numita si variabila predictor, stimul sau comandata), iar o variabila dependenta(sau variabila prezisa) este variabila pe care dorim sa o prezicem, adica o variabila al careirezultat depinde de observatiile facute asupra variabilelor independente. Sa luam exemplul uneicutii negre (black box) (vezi Figura 7.4). În aceasta cutie intra (sunt înregistrate) informatiilex1, x2, . . . , xm, care sunt prelucrate (în timpul prelucrarii apar anumiti parametri, β1, β2, . . . , βk),iar rezultatul final este înregistrat într-o singura variabila raspuns, y.Spre exemplu, dorim sa stabilim o relatie între valoarea pensiei (y) în functie de numarul deani lucrati (x1) si salariul avut de-alungul carierei (x2). Variabilele independente sunt masurateexact, fara erori. În timpul prelucrarii datelor sau dupa aceasta pot apara distorsiuni în sistem,de care putem tine cont daca introducem un parametru ce sa cuantifice eroarea ce poate apareala observarea variabilei y. Se stabileste astfel o legatura între o variabila dependenta, y, si unasau mai multe variabile independente, x1, x2, . . . , xm, care, în cele mai multe cazuri, are formamatematica generala
y = f (x1, x2, . . . , xm; β1, β2, . . . , βk)+ ε, (7.4.5)
unde β1, β2, . . . , βk sunt parametri reali necunoscuti a priori (denumiti parametri de regresie) siε este o perturbatie aleatoare. În cele mai multe aplicatii, ε este o eroare de masurare, considerataa fi modelata printr-o variabila aleatoare normala de medie zero. Functia f se numeste functie

166 Capitolul 7. Corelatie si regresie
de regresie. În cazul în care aceasta nu este cunoscuta a priori, poate fi greu de determinat, iarutilizatorul analizei regresionale va trebui sa o intuiasca sau sa o aproximeze utilizând metode detip trial and error (prin încercari). Daca avem doar o variabila independenta (un singur x), atuncispunem ca avem o regresie simpla. Regresia multipla face referire la situatia în care avem multevariabile independente.
Figura 7.4: Black box.
Daca observarea variabilei dependente s-ar face fara vreo eroare, atunci relatia (7.4.5) ar deveni(cazul ideal):
y = f (x1, x2, . . . .., xm; β1, β2, . . . , βk). (7.4.6)
Forma vectoriala a dependentei (7.4.5) este:
y = f (x; β)+ ε. (7.4.7)
Pentru a o analiza completa a regresiei (7.4.5), va trebui sa intuim forma functiei f si apoi sadeterminam (aproximam) valorile parametrilor de regresie. În acest scop, un experimentalistva face un numar suficient de observatii (experimente statistice), în urma carora va aproximaaceste valori. Daca notam cu n numarul de experimente efectuate, atunci le putem contabiliza peacestea în urmatorul sistem de ecuatii stochastice:
yi = f (x, β)+ εi, i = 1, 2, . . . , n. (7.4.8)
În ipoteze uzuale, erorile εi sunt variabile aleatoare identic repartizate N (0, σ), independentestochastic doua câte doua (σ > 0). Astfel, sistemul (7.4.8) cu n ecuatii stochastice algebrice arenecunoscutele β j j si σ .În cazul în care numarul de experimente este mai mic decât numarul parametrilor ce trebuieaproximati (n < k+1), atunci nu avem suficiente informatii pentru a determina aproximarile.Asadar, pentru a putea determina parametrii de regresie, va fi nevoie de minimum k+ 1 date.Daca n= k+1, atunci problema se reduce la a rezolva n ecuatii cu n necunoscute. Daca n> k+1,atunci avem un sistem cu valori nedeterminate. Deoarece avem o nedeterminare, în general, nuexista un set de parametri care sa potriveasca perfect setul de date. Diferenta n− k−1 apare înanaliza regresionala ca fiind numarul gradelor de libertate a modelului liniar simplu.În functie de forma functiei de regresie f , putem avea:
• regresie liniara simpla, în cazul în care avem doar o variabila independenta si
f (x; β) = β0 +β1x.
• regresie liniara multipla, daca
f (x; β) = β0 +β1x1 +β2x2 + · · ·+βmxm.

7.5 Regresie liniara simpla 167
• regresie patratica multipla (cu doua variabile), daca
f (x; β) = β0 +β1x1 +β2x2 +β11x21 +β12x1x2 +β22x2
2.
• regresie polinomiala, daca
f (x; β) = β0 +β1x+β2x2 +β3x3 + · · ·+βkxk.
Vom avea regresie patratica pentru k = 2, regresie cubica pentru k = 3 etc.• regresie exponentiala, când
f (x; β) = β0 eβ1 x.
• regresie logaritmica, daca
f (x; β) = β0 · logβ1x.
• si altele.
De remarcat faptul ca primele patru modele sunt liniare în parametri, pe când ultimele doua nusunt liniare în parametri. Modelele determinate de aceste functii se vor numi modele de regresie(curbe, suprafete etc).
În cadrul analizei regresionale, se cunosc datele de intrare, xii, si cautam sa estimam parametriide regresie β j j si deviatia standard a erorilor, σ . Daca functia de regresie f este cunoscuta(intuita), atunci metode statistice folosite pentru estimarea necunoscutelor sunt: metoda verosi-militatii maxime, metoda celor mai mici patrate si metoda lui Bayes. Daca f este necunoscuta,metode ce duc la estimarea necunoscutelor sunt: metoda celor mai mici patrate sau metodaminimax.
7.5 Regresie liniara simpla
Este cel mai simplu tip de regresie, în care avem o singura variabila independenta, x, si variabiladependenta y. Sa presupunem ca ni se da familia de date bidimensionale (xi, yi)i=1,n. Repre-zentam grafic aceste date într-un sistem x0y (de exemplu, vezi Figura 7.5 (a)) si observam odependenta aproape liniara a lui y de x. Daca valoarea coeficientului de corelatie liniara, r, esteaproape de 1 sau −1 (indicând o corelatie liniara strânsa), atunci se pune problema stabilirii uneirelatii numerice exacte între x si y de forma
y = β0 +β1x. (7.5.9)
O astfel de dreapta o vom numi dreapta de regresie a lui y în raport cu x. Pentru un set de datebidimensionale ca mai sus, putem reprezenta aceasta dreapta ca în Figura 7.5 (b).
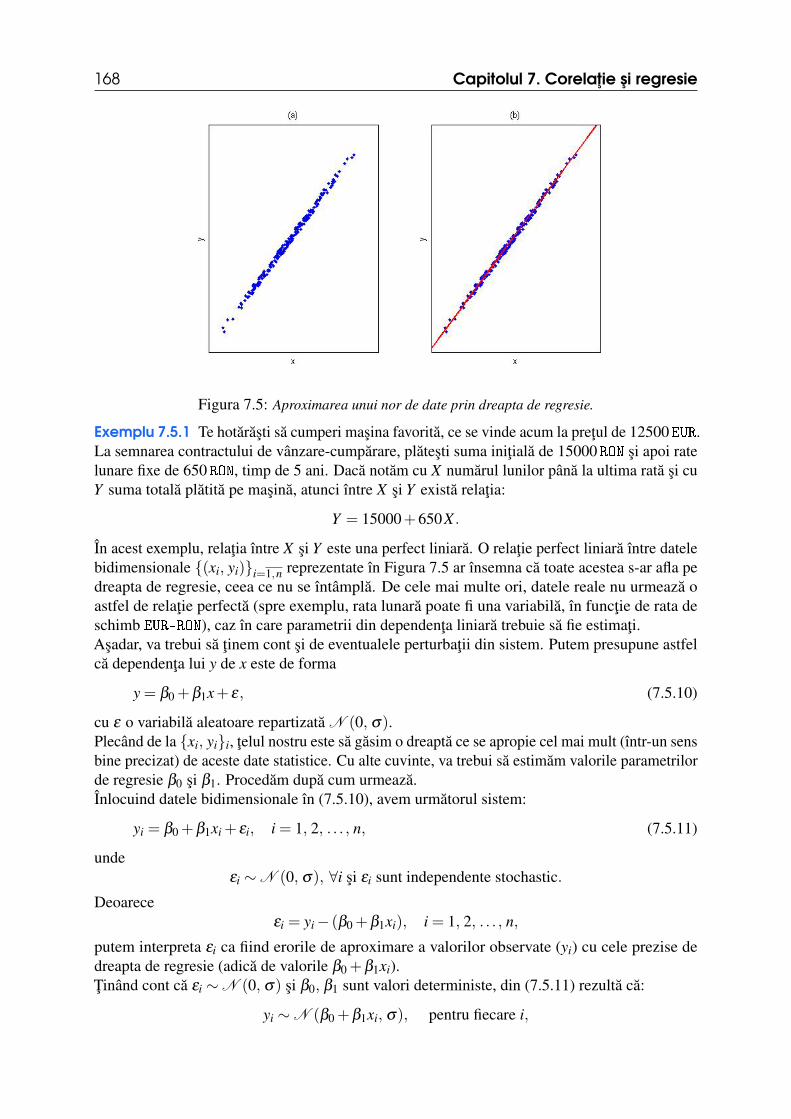
168 Capitolul 7. Corelatie si regresie
Figura 7.5: Aproximarea unui nor de date prin dreapta de regresie.
Exemplu 7.5.1 Te hotarasti sa cumperi masina favorita, ce se vinde acum la pretul de 12500 EUR.La semnarea contractului de vânzare-cumparare, platesti suma initiala de 15000 RON si apoi ratelunare fixe de 650 RON, timp de 5 ani. Daca notam cu X numarul lunilor pâna la ultima rata si cuY suma totala platita pe masina, atunci între X si Y exista relatia:
Y = 15000+650X .
În acest exemplu, relatia între X si Y este una perfect liniara. O relatie perfect liniara între datelebidimensionale (xi, yi)i=1,n reprezentate în Figura 7.5 ar însemna ca toate acestea s-ar afla pedreapta de regresie, ceea ce nu se întâmpla. De cele mai multe ori, datele reale nu urmeaza oastfel de relatie perfecta (spre exemplu, rata lunara poate fi una variabila, în functie de rata deschimb EUR-RON), caz în care parametrii din dependenta liniara trebuie sa fie estimati.Asadar, va trebui sa tinem cont si de eventualele perturbatii din sistem. Putem presupune astfelca dependenta lui y de x este de forma
y = β0 +β1x+ ε, (7.5.10)
cu ε o variabila aleatoare repartizata N (0, σ).Plecând de la xi, yii, telul nostru este sa gasim o dreapta ce se apropie cel mai mult (într-un sensbine precizat) de aceste date statistice. Cu alte cuvinte, va trebui sa estimam valorile parametrilorde regresie β0 si β1. Procedam dupa cum urmeaza.Înlocuind datele bidimensionale în (7.5.10), avem urmatorul sistem:
yi = β0 +β1xi + εi, i = 1, 2, . . . , n, (7.5.11)
undeεi ∼N (0, σ), ∀i si εi sunt independente stochastic.
Deoareceεi = yi− (β0 +β1xi), i = 1, 2, . . . , n,
putem interpreta εi ca fiind erorile de aproximare a valorilor observate (yi) cu cele prezise dedreapta de regresie (adica de valorile β0 +β1xi).Tinând cont ca εi ∼N (0, σ) si β0, β1 sunt valori deterministe, din (7.5.11) rezulta ca:
yi ∼N (β0 +β1xi, σ), pentru fiecare i,

7.5 Regresie liniara simpla 169
de unde, probabilitatea ca într-o singura masuratoare a xi sa obtinem raspunsul yi este
Pi =1
σ√
2πexp(−(yi−β0−β1xi)
2
2σ2
).
Deoarece εii sunt independente stochastic, probabilitatea ca, plecând de la observatiile inde-pendente x1, x2, , . . . , xn, sa obtinem valorile corespunzatoare y1, y2, , . . . , yn este:
L (β0, β1, σ) =n
∏i=1
Pi =1
σn(2π)n/2 exp
(−
n
∑i=1
(yi−β0−β1xi)2
2σ2
).
L (β0, β1, σ) este verosimilitatea de a observa (y1, y2, , . . . , yn) plecând de la (x1, x2, , . . . , xn).Avem de estimat urmatoarele cantitati: β0, β1 si σ . Pentru aceasta, vom folosi metoda verosimi-litatii maxime. Urmarim sa gasim acele valori ale parametrilor β0, β1 si σ care maximizeazafunctia de verosimilitate. Înlocuind pe L cu lnL , problema de maximizare este urmatoarea:
maxβ0,β1,σ
lnL (β0, β1, σ).
Conditiile de extrem (impuse pentru lnL) sunt:
∂ lnL
∂β0=
1σ2
n
∑i=1
(yi−β0−β1xi) = 0;
∂ lnL
∂β1=
1σ2
n
∑i=1
xi(yi−β0−β1xi) = 0;
∂ lnL
∂σ= − n
σ+
1σ2
n
∑i=1
(yi−β0−β1xi)2 = 0.
Rezolvând primele doua ecuatii în raport cu β0 si β1, obtinem estimatiile:
β1 =sxy
s2x
si β0 = y− β1 x, (7.5.12)
unde,
x=1n
n
∑i=1
xi, y=1n
n
∑i=1
yi, s2x =
1n−1
n
∑i=1
(xi−x)2, sxy = cove(x, y)=1
n−1
n
∑i=1
(xi−x)(yi−y).
Se arata apoi ca matricea Hessiana luata în aceste puncte critice este negativ definita, deci valorileobtinute în (7.5.12) pentru β0 si β1 sunt valori de maxim pentru lnL .
Astfel, gasim ca aproximarea dreptei de regresiea lui y în raport cu x este:
y = y− β1 x+sxy
s2x
x, (7.5.13)
sau, altfel scrisa,
y = y+sxy
s2x(x− x). (7.5.14)
Figura 7.6: Aproximarea dreptei de regresie

170 Capitolul 7. Corelatie si regresie
Din ultima conditie de extrem, gasim ca o estimatie pentru dispersia σ2 a erorilor este:
σ2 =1n
n
∑i=1
(yi− β0− β1xi)2. (7.5.15)
Însa, estimatia pentru σ2 data prin formula (7.5.15) este una deplasata. În practica, în loculacestei estimatii se utilizeaza urmatoarea estimatie nedeplasata:
σ2 =1
n−2
n
∑i=1
(yi− β0− β1xi)2. (7.5.16)
Observatie 7.5.1 (1) Terminologie:• dreapta de regresie, y = β0 +β1 x, este dreapta ce determina dependenta liniara a lui y de
valorile lui x, pentru întreaga populatie de date (daca aceasta exista);• aproximarea dreptei de regresie (en., fitting line), y = β0+ β1 x, este dreapta care se apropie
cel mai mult (în sensul metodei celor mai mici patrate) de datele experimentale (de selectie)(xi, yi)i. Aceasta dreapta este o aproximare a dreptei de regresie;
• Valorile yi se numesc valori observate, iar valorile yi = β0 + β1 xi, i = 1, 2, . . . , n, senumesc valori prezise (i = 1, 2, . . . , n);
• valorile εi = yi− yi se numesc reziduuri. Un reziduu masoara deviatia unui punct observatde la valoarea prezisa de aproximarea dreptei de regresie (fitting line);
• suma patratelor erorilor,n
∑i=1
ε2i , se noteaza de obicei prin SSE (sum of squared errors);
• eroarea medie patratica sau reziduala esteSSE
n−2, notata MSE (mean squared error);
• radacina patrata a MSE se numeste eroarea standard a regresiei;• se poate demonstra ca
SSE
σ2 = (n−2)σ2
σ2 ∼ χ2(n−2).
cu autorul acestei relatii se pot gasi intervale de încredere pentru valoarea reala a lui σ2.În formula (7.5.16), (n−2) reprezinta numarul gradelor de libertate ale variabilei SSE.
(2) Valoarea σ2 este o masura a gradului de împrastiere a punctelor (x, y) în jurul dreptei deregresie. Mai subliniem faptul ca valorile din formulele (7.5.12) si (7.5.16) sunt doar estimatiiale parametrilor necunoscuti si nu valorile lor exacte. Formula pentru β1 mai poate fi scrisa subforma:
β1 = rxysy
sx.
(3) Daca deviatia standard σ ar fi cunoscuta a priori, atunci putem estima parametrii β0 si β1în urmatorul mod. Estimam acesti doi parametri prin acele valori ce realizeaza minimumulsumei patratelor erorilor SSE. Vom avea astfel problema de minimizare (metoda celor mai micipatrate):
minβ0,β1
n
∑i=1
(yi−β0−β1xi)2.

7.5 Regresie liniara simpla 171
Notând cu F(β0, β1) =n
∑i=1
(yi−β0−β1xi)2, conditiile de extrem sunt:
∂F∂β0
= −2n
∑i=1
(yi−β0−β1xi) = 0;
∂F∂β1
= −2n
∑i=1
xi(yi−β0−β1xi) = 0.
Rezolvând acest sistem de ecuatii algebrice în raport cu β0 si β1, gasim solutiile β0 si, respectiv,β1 de mai sus. Aceasta dovedeste ca, în cazul în care erorile sunt identic normal repartizate siindependente stochastic, metoda verosimilitatii maxime este, în fapt, totuna cu metoda celor maimici patrate.
7.5.1 Caracteristici ale parametrilor de regresie
Estimatiile pentru parametrii de regresie β0 si β1 depind de observatiile folosite. Pentru adecide daca valorile calculate pe baza datelor experimentale (xi, yi)i pot fi considerate valorilepotrivite pentru întreaga populatie, se vor utiliza testari statistice. Mai jos, vom construi testestatistice cu privire la testarea valorilor ambilor parametri, β0 si β1, însa cel mai uzual test estetestul pentru verificarea valorii pantei dreptei de regresie, β1.Mai întâi, vom calcula media si dispersia pentru fiecare dintre β1 si β0.Avem succesiv,
E(β1) = E(
sxy
s2x
)= E
n
∑i=1
(xi− x)(yi− y)
n
∑i=1
(xi− x)2
.
Aici, xi sunt valori deterministe, iar yi variabile aleatoare. Deoarece
y = β0 +β1x+1n
n
∑i=1
εi,
obtinem ca E(y) = β0 +β1x. Însa,
E(yi− y) = β0 +β1xi− (β0 +β1x) = β1(x1− x), ∀i.
Asadar,
E(β1) =
n
∑i=1
(xi− x)E[yi− y]
n
∑i=1
(xi− x)2=
β1
n
∑i=1
(xi− x)2
n
∑i=1
(xi− x)2= β1.
Pentru β0 avem:
E(β0) = E(y)− xE(β1) = β0 +β1x− xβ1 = β0.
Prin urmare, atât β0, cât si β1, sunt estimatori nedeplasati pentru β0 si, respectiv, β1.

172 Capitolul 7. Corelatie si regresie
Calculam acum dispersiile Var(
β1
)si Var
(β0
). Deoarece
n
∑i=1
(xi− x)y = 0, avem:
Var(
β1
)=Var
n
∑i=1
(xi− x)yi
n
∑i=1
(xi− x)2
=
n
∑i=1
(xi− x)2Var(yi)(n
∑i=1
(xi− x)2
)2 =σ2s2
xs4
x=
σ2
s2x. (7.5.17)
Utilizând urmatoarea proprietate,
Var(X +Y ) =Var(X)+2cov(X , Y )+Var(Y ),
putem scrie:
Var(
β0
)=Var(y− β1x) =Var(y)−2xcov(y, β1)+ x2Var
(β1
). (7.5.18)
Dar,
Var(y) =Var
(1n
n
∑i=1
εi
)=
1n2 nσ
2 =σ2
n
si
cov(
y, β1
)= cov
1n
n
∑i=1
εi,
n
∑i=1
(xi− x)(β0 +β1xi + εi)
b
∑i=1
(xi− x)2
= cov
1n
n
∑i=1
εi,
n
∑i=1
(xi− x)εi
n
∑i=1
(xi− x)2
=1
nn
∑i=1
(xi− x)2cov
(n
∑i=1
εi,n
∑i=1
(xi− x)εi
)
=
n
∑i=1
(xi− x)σ2
nn
∑i=1
(xi− x)2= 0.
Înlocuind în (7.5.18), gasim ca
Var(
β0
)= x2 σ2
s2x+
σ2
n= σ
2(
1n+
x2
s2x
). (7.5.19)

7.5 Regresie liniara simpla 173
Tinând cont ca estimatorii β0 si β1 sunt nedeplasati, de relatiile (7.5.19) si (7.5.17), si deestimatorul σ2 pentru σ2, se poate demonstra ca:
β0−β0
σ
√1n +
x2
s2x
∼ t(n−2) (7.5.20)
si
β1−β1σ
sx
∼ t(n−2). (7.5.21)
Aici, am notat prin σ cantitatea
σ =
√1
n−2
n
∑i=1
(yi− β0− β1xi
)2.
Putem folosi aceste statistici pentru a determina intervale de încredere pentru β0 si β1. Uninterval de încredere pentru β0 la nivelul de semnificatie α esteβ0− t1−α
2 ;n−2 σ
√1n+
x2
s2x, β0 + t1−α
2 ;n−2 σ
√1n+
x2
s2x
. (7.5.22)
Un interval de încredere pentru β1 la nivelul de semnificatie α este[β1− t1−α
2 ;n−2σ
sx, β1 + t1−α
2 ;n−2σ
sx
]. (7.5.23)
Observatie 7.5.2 (1) În general, dispersia σ2 a erorilor de regresie nu este cunoscuta a priori.În cazul în care aceasta este cunoscuta, atunci în loc de (7.5.20) si (7.5.21) am avea:
β0−β0
σ
√1n +
x2
s2x
∼N (0, 1) siβ1−β1
σ
sx
∼N (0, 1). (7.5.24)
În acest caz, intervalele de încredere pentru β0 si β1 vor fi similare cu cele din relatiile (7.5.22) si(7.5.23), cu diferenta ca t1−α
2 ;n−2 este înlocuit prin z1−α
2. Oricum, pentru n suficient de mare,
valorile t1−α
2 ;n−2 si z1−α
2sunt foarte apropiate.
(2) Coeficientul de determinare R2 (= r2) se poate calcula si folosind urmatoarea formula:
R2 = 1− SSE
SST, (7.5.25)
unde
SSE=n
∑i=1
(yi− β0− β1xi)2, SST=
n
∑i=1
(yi− y)2.
În analiza regresionala, coeficientul R2 este folosit pentru a determina cât de bine poate ficonstruita o valoare prezisa pe baza valorilor independente.

174 Capitolul 7. Corelatie si regresie
7.5.2 Validarea parametrilor
Test statistic pentru β1
Mai jos prezentam testul ce verifica daca β1 ia o valoare data β10 sau nu, la un nivel de semnificatieα . Dispersia erorilor de regresie este necunoscuta.Testam
(H0) : β1 = β10 versus (H1) : β1 6= β10.
Consideram statistica
T =β1−β1
σ
sx
,
care urmeaza repartitia t(n−2). Etapele testului sunt urmatoarele:• Calculam valoarea critica
T0 =β1−β10
σ
sx
.
• Calculam cuantila de ordin 1− α
2 pentru repartitia t cu (n−2) grade de libertate, t1−α
2 ;n−2;• Daca
|T0|< t1−α
2 ;n−2, atunci acceptam ipoteza (H0);
Daca|T0| ≥ t1−α
2 ;n−2, atunci acceptam ipoteza (H1);
Observatie 7.5.3 (1) O ipoteza alternativa poate fi considerata si una dintre urmatoarele:
(H1)s : β1 < β10, (H1)d : β1 > β10.
(2) Testul(H0) : β1 = 0 versus (H1) : β1 6= 0
este testul pentru semnificatia pantei de regresie observata β1. Daca se admite ipoteza nula,atunci modelul de regresie nu este liniar. Daca ipoteza alternativa β1 6= 0 este admisa, atunciîntre x si y exista o dependenta liniara.
Test statistic pentru β0
Mai jos prezentam testul ce verifica daca β0 ia o valoare data β ∗0 sau nu, la un nivel de semnificatieα . Dispersia erorilor de regresie este necunoscuta.Testam
(H0) : β0 = β∗0 versus (H1) : β0 6= β
∗0 .
Consideram statistica
T =β0−β0
σ
√1n +
x2
s2x
∼ t(n−2),
care urmeaza repartitia t(n−2). Etapele testului sunt urmatoarele:• Calculam valoarea critica
T0 =β0−β ∗0
σ
√1n +
x2
s2x
∼ t(n−2).

7.6 Validitatea modelului de regresie liniara simpla 175
• Calculam cuantila de ordin 1− α
2 pentru repartitia t cu (n−2) grade de libertate, t1−α
2 ;n−2;• Daca
|T0|< t1−α
2 ;n−2, atunci acceptam ipoteza (H0);
Daca|T0| ≥ t1−α
2 ;n−2, atunci acceptam ipoteza (H1);
Observatie 7.5.4 Pot fi considerate si teste unilaterale în cazul testarii valorii lui β0.În cazul în care σ2 este cunoscut a priori atunci, gratie relatiilor (7.5.24), putem utiliza testul Zpentru testarea ipotezelor de mai sus, atât pentru β0, cât si pentru β1.
7.6 Validitatea modelului de regresie liniara simplaPresupunem ca X si Y sunt doua variabile de interes, pentru care se doreste a determina o relatieliniara de forma
Y = β0 +β1X + ε.
Pentru a determina oportunitatea unei astfel de legaturi, se culeg date relativ la aceste variabile.Consideram ca aceste observatii sunt (xi, yi)i=1,2, ...,n. Pe baza acestor date se poate aproximadreapta de regresie liniara (daca exista) astfel:
Y = β0 + β1X , unde: β1 =sxy
sxxsi β0 = y− β1x,
x =1n
n
∑i=1
xi, y =1n
n
∑i=1
yi, sxx =n
∑i=1
(xi− x)2, sxy =n
∑i=1
(xi− x)(yi− y).
Pentru a verifica daca modelul de regresie liniara este unul valid, se pot folosi mai multe metode,dintre care amintim cele mai uzuale:
• coeficientul de determinare R2. Acest coeficient se calculeaza astfel:
R2 = 1− SSE
SST, (7.6.26)
unde
SSE=n
∑i=1
(yi− y)2 =n
∑i=1
(yi− β0− β1xi)2, SST=
n
∑i=1
(yi− y)2.
Aici, SST reprezinta suma totala a patratelor the total sum of squares. În analiza regre-sionala, coeficientul R2 este o statistica folosita în a determina cât de bine pot fi estimatevalorile lui y pe baza modelului de regresie. Valorile lui R2 sunt între 0 si 1 si, pentrua avea un model destul de bun, ar fi necesar un coeficient de determinare aproape de 1.Totusi, este posibil ca R2 sa aiba valori mai mari ca 1 în cazul în care modelul de regresienu este unul liniar. În cazul regresiei liniare simple, R2 = r2, adica patratul coeficientuluide corelatie Pearson.
• grafice:– yi vs. xi: Din aceasta figura (scatter plot) ne putem da seama de oportunitatea
modelarii datelor observate folosind un model de regresie liniara simpla. Aceastafigura ar trebui facuta înainte de aproximarea dreptei de regresie. Pentru a puteautiliza un model de regresie liniara simpla, valorile reprezentate ar trebui sa fieapropiate de o anumita dreapta.
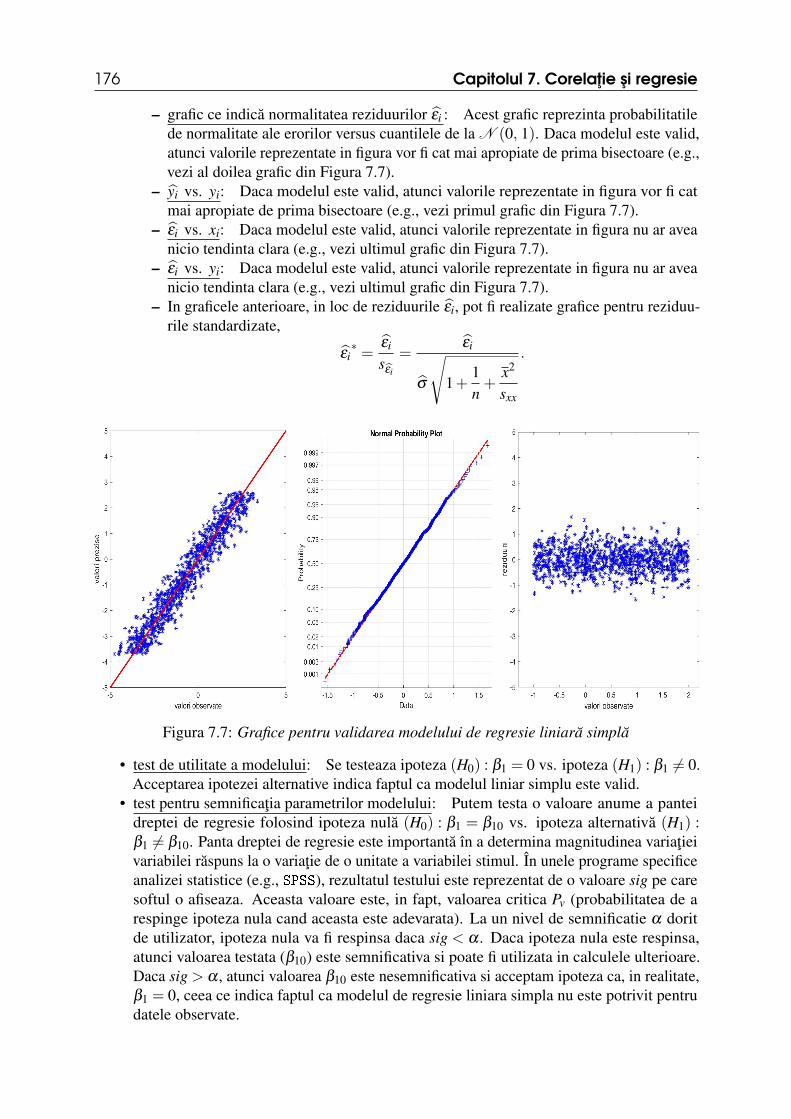
176 Capitolul 7. Corelatie si regresie
– grafic ce indica normalitatea reziduurilor εi : Acest grafic reprezinta probabilitatilede normalitate ale erorilor versus cuantilele de la N (0, 1). Daca modelul este valid,atunci valorile reprezentate in figura vor fi cat mai apropiate de prima bisectoare (e.g.,vezi al doilea grafic din Figura 7.7).
– yi vs. yi: Daca modelul este valid, atunci valorile reprezentate in figura vor fi catmai apropiate de prima bisectoare (e.g., vezi primul grafic din Figura 7.7).
– εi vs. xi: Daca modelul este valid, atunci valorile reprezentate in figura nu ar aveanicio tendinta clara (e.g., vezi ultimul grafic din Figura 7.7).
– εi vs. yi: Daca modelul este valid, atunci valorile reprezentate in figura nu ar aveanicio tendinta clara (e.g., vezi ultimul grafic din Figura 7.7).
– In graficele anterioare, in loc de reziduurile εi, pot fi realizate grafice pentru reziduu-rile standardizate,
εi∗=
εi
sεi
=εi
σ
√1+
1n+
x2
sxx
.
Figura 7.7: Grafice pentru validarea modelului de regresie liniara simpla
• test de utilitate a modelului: Se testeaza ipoteza (H0) : β1 = 0 vs. ipoteza (H1) : β1 6= 0.Acceptarea ipotezei alternative indica faptul ca modelul liniar simplu este valid.
• test pentru semnificatia parametrilor modelului: Putem testa o valoare anume a panteidreptei de regresie folosind ipoteza nula (H0) : β1 = β10 vs. ipoteza alternativa (H1) :β1 6= β10. Panta dreptei de regresie este importanta în a determina magnitudinea variatieivariabilei raspuns la o variatie de o unitate a variabilei stimul. În unele programe specificeanalizei statistice (e.g., SPSS), rezultatul testului este reprezentat de o valoare sig pe caresoftul o afiseaza. Aceasta valoare este, in fapt, valoarea critica Pv (probabilitatea de arespinge ipoteza nula cand aceasta este adevarata). La un nivel de semnificatie α doritde utilizator, ipoteza nula va fi respinsa daca sig < α . Daca ipoteza nula este respinsa,atunci valoarea testata (β10) este semnificativa si poate fi utilizata in calculele ulterioare.Daca sig > α , atunci valoarea β10 este nesemnificativa si acceptam ipoteza ca, in realitate,β1 = 0, ceea ce indica faptul ca modelul de regresie liniara simpla nu este potrivit pentrudatele observate.

7.7 Predictie prin regresie 177
Ce este de facut daca modelul de regresie liniara simpla nu este unul valid?
• Este posibil ca Y sa nu depinda liniar de X . Acest fapt poate fi observat de la inceput,din diagrama scatter plot ce reprezinta yi vs. xi. Pentru modele neliniare, se poateincerca o transformare a variabilelor X si Y astfel incat modelul liniar pentru variabileletransformate sa fie unul aplicabil (nu merge intotdeauna). Spre exemplu, vezi Exercitiul7.8.6, in care am determinat o regresie liniara intre variabilele ln(Y ) si X .
• Se poate intampla ca reziduurie εi sa prezinte o dependinta clara de xi (fapt ce poate fi obser-vat dintr-o reprezentare εi vs. xi), asadar aplicabilitatea modelului de regresie liniara esteinoportuna. Faptul ca εi nu au toate o aceeasi dispersie σ2 se numeste heteroscedasticitate(proprietate opusa homoscedasticitatii).
• Daca reziduurile nu sunt normale (se observa din grafic sau, eventual, se poate apela la untest de normalitate), modelul liniar de regresie nu este oportun.
• Exista posibilitatea ca datele observate (xi, yi)i=1,2, ...,n sa contina valori aberante (outli-ers). Este important de a intelege aceste valori si, in caz ca nu sunt semnificative, pot fisterse din setul de date care este supus analizei de regresie.
• In multe cazuri, o singura variabila predictor (X) nu poate explica de una singura variabilaY , cazuri in care se apeleaza la o regresie multipla (se iau in considerare si alte variabilepredictor).
7.7 Predictie prin regresie[Pe scurt, predictia prin regresie este precum ai conduce masina legat la ochi, ghidat de un copilot carepriveste doar în luneta]
În anumite cazuri, putem folosi regresia în predictia unor valori ale variabilei dependente. Deexemplu, putem prezice temperatura într-un anumit oras plecând de la observatiile temperaturilordin orasele învecinate. Regresia poate fi utilizata pentru predictie dupa cum urmeaza. Sapresupunem ca datele pe care le detinem, (xi, yi)n
i=1, pot fi modelate de o dreapta de regresiede forma (7.5.9). Data fiind o valoarea xp ce nu se afla printre valorile xi, dar este o valoarecuprinsa între valorile extreme ale variabilei independente, xmin si xmax, dorim sa prezicem valoarearaspuns,
yp = β0 +β1 xp + εp.
Daca β0 si β1 sunt estimatiile pentru parametrii de regresie β0, respectiv, β1, atunci valoareaprezisa pentru yp pentru un xp observat va fi o valoare yp de pe dreapta de regresie, data deformula:
yp = β0 + β1 xp. (7.7.27)
Un interval de încredere pentru y pentru un xp dat, la nivelul de semnificatie α (aici, xp ∈[xmin, xmax]) este:[
yp− t1−α
2 ;n−2 σ
√1+
1n+
(xp− x)2
s2x
, yp + t1−α
2 ;n−2 σ
√1+
1n+
(xp− x)2
s2x
]. (7.7.28)
Observatie 7.7.1 (1) De notat faptul ca este foarte important ca xp sa fie o valoare cuprinsaîntre xmin si xmax. Daca se foloseste formula (7.7.27) si pentru valori ale lui x în afara range-ului
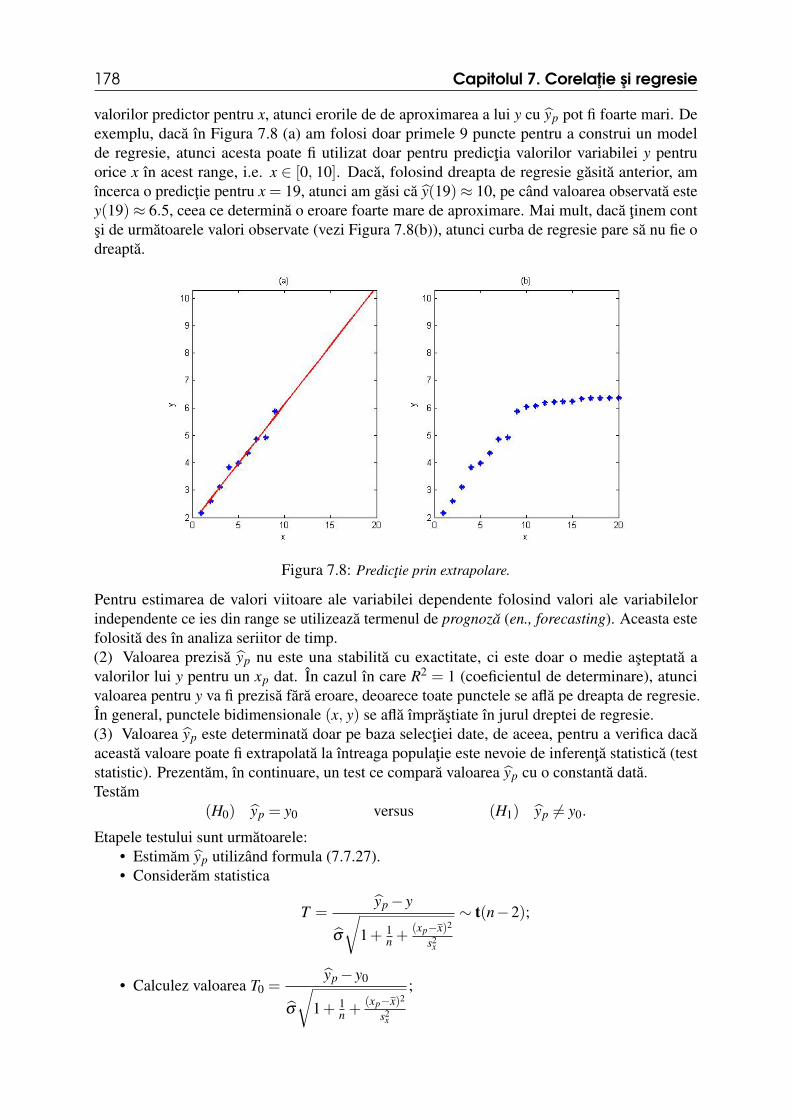
178 Capitolul 7. Corelatie si regresie
valorilor predictor pentru x, atunci erorile de de aproximarea a lui y cu yp pot fi foarte mari. Deexemplu, daca în Figura 7.8 (a) am folosi doar primele 9 puncte pentru a construi un modelde regresie, atunci acesta poate fi utilizat doar pentru predictia valorilor variabilei y pentruorice x în acest range, i.e. x ∈ [0, 10]. Daca, folosind dreapta de regresie gasita anterior, amîncerca o predictie pentru x = 19, atunci am gasi ca y(19)≈ 10, pe când valoarea observata estey(19)≈ 6.5, ceea ce determina o eroare foarte mare de aproximare. Mai mult, daca tinem contsi de urmatoarele valori observate (vezi Figura 7.8(b)), atunci curba de regresie pare sa nu fie odreapta.
Figura 7.8: Predictie prin extrapolare.
Pentru estimarea de valori viitoare ale variabilei dependente folosind valori ale variabilelorindependente ce ies din range se utilizeaza termenul de prognoza (en., forecasting). Aceasta estefolosita des în analiza seriitor de timp.(2) Valoarea prezisa yp nu este una stabilita cu exactitate, ci este doar o medie asteptata avalorilor lui y pentru un xp dat. În cazul în care R2 = 1 (coeficientul de determinare), atuncivaloarea pentru y va fi prezisa fara eroare, deoarece toate punctele se afla pe dreapta de regresie.În general, punctele bidimensionale (x, y) se afla împrastiate în jurul dreptei de regresie.(3) Valoarea yp este determinata doar pe baza selectiei date, de aceea, pentru a verifica dacaaceasta valoare poate fi extrapolata la întreaga populatie este nevoie de inferenta statistica (teststatistic). Prezentam, în continuare, un test ce compara valoarea yp cu o constanta data.Testam
(H0) yp = y0 versus (H1) yp 6= y0.
Etapele testului sunt urmatoarele:• Estimam yp utilizând formula (7.7.27).• Consideram statistica
T =yp− y
σ
√1+ 1
n +(xp−x)2
s2x
∼ t(n−2);
• Calculez valoarea T0 =yp− y0
σ
√1+ 1
n +(xp−x)2
s2x
;

7.8 Exercitii rezolvate 179
• Daca|T0|< t1−α
2 ;n−2, atunci acceptam ipoteza (H0);
Daca|T0| ≥ t1−α
2 ;n−2, atunci acceptam ipoteza (H1);
(4) În concluzie, regresia este o unealta dibace pentru predictie. Economistii care o utilizeaza
pot prezice cu succes chiar 10 dintre ultimele 2 recesiuni!Observatie 7.7.2 Pâna acum am vazut cum putem estima valoarea lui y folosind pe x. În unelecazuri, putem inversa rolurile lui x si y, si putem vorbi astfel de regresie a lui x în raport cu y.De exemplu, în Exercitiul 7.8.5 am putea estima notele la Probabilitati în functie de notele laStatistica. Formulele obtinute pentru dreapta de regresie a lui x în raport cu y sunt cele gasiteanterior pentru dreapta de regresie a lui y în raport cu x, în care rolurile lui x si y sunt inversate.
7.8 Exercitii rezolvateExercitiu 7.8.1 Datele din tabelul urmator reprezinta o selectie de observatii asupra variabilei X .
X 0 −1 3 1 2 −2Y 2 0
(a) Daca pentru variabilele X si Y coeficientul de corelatie Spearman este −1, completati întabel (daca este posibil) un set de valori pentru Y .(b) Aceeasi cerinta în cazul în care coeficientul de corelatie Pearson este −1.
R: (a) Coeficientul Spearman este −1 daca cele doua seturi de date sunt de monotonii inverse.Putem alege, spre exemplu, Y = [
√3, 2,−2.5, 1.5, 0, 10]. Alegerea nu este unica.
(b) Coeficientul Pearson este −1 daca toate datele se afla pe o aceeasi dreapta. Dreapta ce treceprin punctele (−1, 2) si (2, 0) este
y =23(2− x).
Astfel, valorile lui Y sunt unic determinate: Y = [4/3, 2,−2/3, 2/3, 0, 8/3].
Exercitiu 7.8.2 (a) Determinati coeficientul de corelatie Pearsonpentru setul alaturat de date, reprezentate prin punctele albastre (farapunctul P).(b) Determinati coeficientul de corelatie Pearson pentru datele dinfigura, incluzând punctul P(103,103). Cum explicati fenomenul ob-servat?(c) Aceleasi cerinte ca la (a) si (b), dar pentru coeficientul Spearman.R: (a) Cele 9 date sunt:
(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)
Coeficientul de corelatie Pearson pentru cele 9 puncte este 0.(b) Coeficientul de corelatie Pearson pentru cele 10 puncte este ≈ 1.(c) Rangurile asociate celor 9 date sunt:
rx = [2, 2, 2, 5, 5, 5, 8, 8, 8]; ry = [2, 5, 8, 2, 5, 8, 2, 5, 8];

180 Capitolul 7. Corelatie si regresie
Coeficientul de corelatie Spearman pentru cele 9 puncte este 0, iar pentru cele 10 puncte este0.2941. Rangurile asociate celor 10 date sunt:
rx = [2, 2, 2, 5, 5, 5, 8, 8, 8, 10]; ry = [2, 5, 8, 2, 5, 8, 2, 5, 8, 10];
Coeficientul de corelatie Pearson este foarte senzitiv la valorile extreme din date, pe cândcoeficientul de corelatie Spearman este mai putin senzitiv la valori extreme.
Exercitiu 7.8.3 Urmatoarele date sunt observatii ale unor caracteristici normale X si Y .
x −1 0 1 2 3y −2 −1 0 7 26
(a) Testati daca ρ = 0 (coeficientul de corelatie teoretic) pentru α = 0.05.(b) Este faptul ca x si y sunt legate prin relatia y = x3− 1 în contradictie cu rezultatul de lapunctul (a)?(c) Calculati coeficientul de corelatie Spearman observat pentru setul de date.R: (a) Calculam coeficientul de corelatie Pearson si gasim ca r0 = 0.8630. Folosim testulpentru semnificatia lui r0. Valoarea observata a statisticii test este
T0 = r0
√n−21− r2
0= 2.9584 < 3.1824 = t0.975,3,
deci valoarea observata este nesemnificativa statistic la nivelul α = 0.05. Astfel, variabilele suntnecorelate liniar.
Valoarea Pv asociata acestui test este
Pv = P(|T | ≥ |T0|) = P(T ≤−|T0|)+1−P(T < |T0|) = 0.0596 > 0.05.
(b) Nu. Coeficientul ρ determina doar corelatia liniara între variabile.(c) Rangurile asociate sunt rx = [1, 2, 3, 4, 5] si ry = [1, 2, 3, 4, 5]. Coeficientul de corelatieSpearman observat este rS = 1. Astfel, datele sunt perfect pozitiv corelate în sens Spearman.
Exercitiu 7.8.4 Tabelul de mai jos contine calificativele obtinute de un elev de clasa I la oselectie de 9 teste din clasa I, care au fost reluate la inceputul clasei a doua a-II-a.
Discipline A B C D E F G H Iclasa I S FB FB B B FB S B FB
clasa a II-a B I B FB FB B B S B
(a) Reprezentati grafic datele;(b) Calculati coeficientul de corelatie Spearman si semnificatia lui pentru calificativele obtinuteîn clasa I si cele din clasa a II-a (α = 0.1).R: (a) Asociem valori numerice datelor pentru a le putea reprezenta grafic.I→ 1, S→ 2, B→ 3, FB→ 4.
7.8 Exercitii rezolvate 181
(b) Rangurile asociate sunt
r1 = [1.5, 7.5, 7.5, 4, 4, 7.5, 1.5, 4, 7.5] si r2 = [5, 1, 5, 8.5, 8.5, 5, 5, 2, 5].
Coeficientul de corelatie Spearman este rS =−0.2746. Folosim testul pentru semnificatia lui rS.Valoarea observata a statisticii test este
T0 = rS
√n−21− r2
S=−0.7557.
Cum t0.95,7 = 1.8946, valoarea observata este nesemnificativa statistic la nivelul α = 0.1.
Exercitiu 7.8.5 Dorim sa determinam daca exista vreo corelatie între punctajele la examenul deProbabilitati si cele de la Statistica obtinute de studentii unui an de studiu. În acest sens, au fostobservate notele obtinute de 10 studenti la aceste doua discipline si au fost trecute în Tabelul 7.5de mai jos. Se cere:(a) Stabiliti daca exista o legatura puternica între aceste note (r si R2);(b) Determinati dreapta de regresie a notelor de la Statistica în raport cu notele la Probabilitati sidesenati-o în acelasi sistem de axe ca si notele obtinute (scatter plot).(c) Testati daca exista sau nu vreo corelatie între notele de la Statistica si Probabilitati (α = 0.05).
Student A B C D E F G H I JProbabilitati 82 36 72 58 70 48 44 94 60 40
Statistica 84 42 50 64 68 54 46 80 60 32
Tabela 7.5: Notele la Statistica si Probabilitati.
R: (a) Calculam r cu formula lui Pearson. Obtinem:
r =cove(x, y)
sx · sy= 0.8677.
Coeficientul de determinare este R2 = r2 = 0.7528, deci o tarie a legaturii nu foarte buna.(b) Folosind formulele pentru coeficientii de regresie, gasim ca
β0 = 10.3816 si β1 = 0.7553.
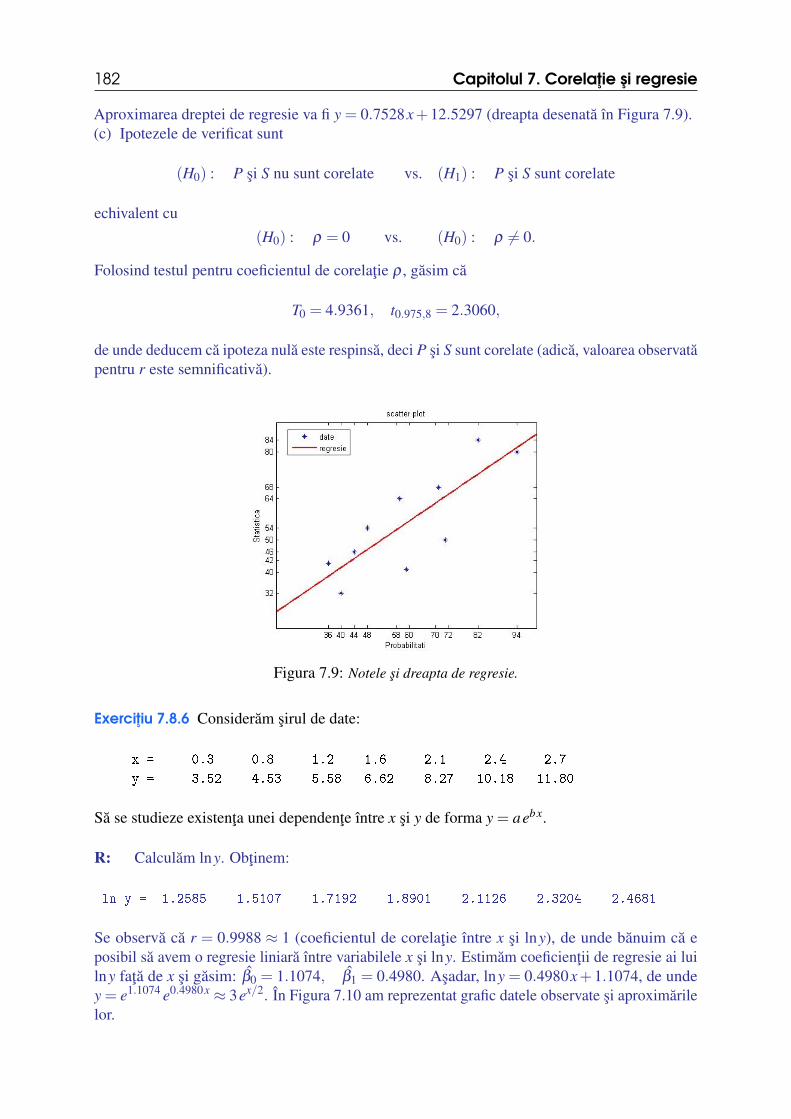
182 Capitolul 7. Corelatie si regresie
Aproximarea dreptei de regresie va fi y = 0.7528x+12.5297 (dreapta desenata în Figura 7.9).(c) Ipotezele de verificat sunt
(H0) : P si S nu sunt corelate vs. (H1) : P si S sunt corelate
echivalent cu(H0) : ρ = 0 vs. (H0) : ρ 6= 0.
Folosind testul pentru coeficientul de corelatie ρ , gasim ca
T0 = 4.9361, t0.975,8 = 2.3060,
de unde deducem ca ipoteza nula este respinsa, deci P si S sunt corelate (adica, valoarea observatapentru r este semnificativa).
Figura 7.9: Notele si dreapta de regresie.
Exercitiu 7.8.6 Consideram sirul de date:
x = 0.3 0.8 1.2 1.6 2.1 2.4 2.7
y = 3.52 4.53 5.58 6.62 8.27 10.18 11.80
Sa se studieze existenta unei dependente între x si y de forma y = aebx.
R: Calculam lny. Obtinem:
ln y = 1.2585 1.5107 1.7192 1.8901 2.1126 2.3204 2.4681
Se observa ca r = 0.9988 ≈ 1 (coeficientul de corelatie între x si lny), de unde banuim ca eposibil sa avem o regresie liniara între variabilele x si lny. Estimam coeficientii de regresie ai luilny fata de x si gasim: β0 = 1.1074, β1 = 0.4980. Asadar, lny = 0.4980x+1.1074, de undey = e1.1074 e0.4980x ≈ 3ex/2. În Figura 7.10 am reprezentat grafic datele observate si aproximarilelor.
7.8 Exercitii rezolvate 183
Figura 7.10: Aproximarea datelor din Exercitiul 7.8.6
Exercitiu 7.8.7 Tabelul de mai jos contine calificativele obtinute de doi elevi de clasa I la cele 9discipline scolare.
Discipline A B C D E F G H Ielev I B FB FB B B FB S I FBelev II S I B FB FB B B S B
(FB = "foarte bine", B = "bine", S = "suficient", I = "insuficient".)Dorim sa stabilim o posibila legatura între cele doua seturi de calificative. Calculati un coeficientde corelatie potrivit la nivelul de semnificatie α = 0.05. Comentati rezultatul obtinut.R: Variabilele pentru care avem valorile din tabel sunt de tip calitativ. Pentru a calcula uncoeficient de corelatie între cele doua seturi, avem doua variante: ori (I) calculam coeficientulde corelatie Pearson pentru valorile numerice atribuite datelor, sau (II) calculam coeficientulde corelatie Spearman.(I) Atribuim valori numerice datelor, astfel: I = 1, S = 2, B = 3, FB = 4. Datele devin
Discipline A B C D E F G H Ielev I 3 4 4 3 3 4 2 1 4elev II 2 1 3 4 4 3 3 2 3
Coeficientul de corelatie Pearson pentru aceste seturi de date este rP = 0.0271. Pentru a testasemnificatia sa, folosim testul pentru coeficientul de corelatie Pearson. Ipotezele de verificat sunt
(H0) : rP nu este semnificativ vs. (H1) : rP este semnificativ
echivalent cu(H0) : ρ = 0 vs. (H0) : ρ 6= 0.
Folosind testul pentru coeficientul de corelatie ρ , gasim ca
T0 = 0.0718, t0.975,7 = 2.3646,
de unde deducem ca ipoteza nula este admisa, deci valoarea observata pentru rP nu este semnifi-cativa statistic.(II) Pentru a determina coeficientul de corelatie Spearman, determinam mai întâi rangurileobservatiilor în fiecare set. Acestea sunt (ordonam crescator începând cu I si terminând cu FB.Pentru valori egale, rangul atribuit este media rangurilor valorilor egale):

184 Capitolul 7. Corelatie si regresie
Discipline A B C D E F G H Ielev I 4 7.5 7.5 4 4 7.5 2 1 7.5elev II 2.5 1 5.5 8.5 8.5 5.5 5.5 2.5 5.5
Calculam coeficientul de corelatie Pearson pentru valorile numerice si obtinem rS =−0.0421.Acesta este coeficientul de corelatie Spearman. Pentru a testa semnificatia sa, folosim testulpentru coeficientul de corelatie Pearson. Ipotezele de verificat sunt
(H0) : rS nu este semnificativ vs. (H1) : rS este semnificativ
echivalent cu(H0) : ρS = 0 vs. (H0) : ρS 6= 0.
Folosind testul pentru coeficientul de corelatie ρ , gasim ca
T0 =−0.1114, t0.975,7 = 2.3646,
de unde deducem ca ipoteza nula este admisa, deci valoarea observata pentru r nu este semnifica-tiva statistic.În concluzie, calificativele obtinute de cei doi elevi nu sunt corelate.
7.9 Exercitii propuseExercitiu 7.9.1 Pentru setul de date:
u = 1.0 1.5 2.0 2.5 3.0 3.5 4.0
v = 1.5 4.5 7.5 12.5 17.5 24.5 32.5
sa se studieze existenta unei dependente între u si v de forma v = au2 +b.Exercitiu 7.9.2 În tabelul urmator, se dau câte 5 valori pentru doua variabile x si y, unde yeste variabila independenta. Determinati o aproximare pentru o dreapta de regresie potrivita cuajutorul careia se poate calcula(i) valoarea lui x când y = 2.5;(ii) valoarea lui y când x = 50;(iii) Putem prezice valoarea lui y pentru x = 75?
x 46 55 41 58 53y 1.7 2.1 1.5 2.9 1.9
Exercitiu 7.9.3 Un student ia cu împrumut o carte de la biblioteca si observa ca pagina deinteres este rupta pe alocuri. Totusi, poate citi textul din Figura 7.11. Ajutati-l sa reconstruiascapasajul de text (i.e., determinati y si dreapta de regresie a lui x fata de y). De asemenea, calculaticoeficientul empiric de corelatie r si comentati asupra aproximarii datelor de selectie prin dreptelementionate în text.
Figura 7.11: Fragment incomplet dintr-un text

7.9 Exercitii propuse 185
Exercitiu 7.9.4 Tabelul 7.6 contine calificativele obtinute de un elev de clasa I la cele 9 discipline,în fiecare dintre cele doua semestre. Sa se gaseasca o masura a legaturii dintre cele doua seturide calificative (e.g., coeficientul de corelatie Spearman).
Discipline A B C D E F G H ISem. I FB FB B FB B B B S FBSem. II B B B FB FB S B S FB
Tabela 7.6: Calificative din anul I de studiu
Exercitiu 7.9.5 Suntem interesati în determinarea unei legaturi între înaltime si marimea lapantof. Datele din tabelul de mai jos reprezinta observatii asupra înaltimilor (H) si a marimilorla pantof (M) pentru 10 barbati, alesi la întâmplare.
H 1.75 1.70 1.80 1.65 1.83 1.73 1.86 1.65 1.68 1.82M 43 41.5 44 40.5 44.5 41 44.5 39.5 40 43.5
(a) Calculati coeficientul de corelatie Pearson dintre înaltime si marimea la pantof. Ce procentdin valorile lui M sunt determinate de valorile lui H(b) Determinati o aproximare pentru dreapta de regresie a lui M fata de H.(c) Obtineti o predictie a marimii la pantof pentru un barbat cu înaltimea 1.78.
(d) La nivelul de semnificatie α = 0.05, testati ipoteza ca panta dreptei de regresie este34
.Exercitiu 7.9.6 Se masoara viteza unei masini, v, în primele 10 secunde dupa aceasta a începutsa accelereze. Aceste date sunt înregistrate în Tabelul 7.12.
t 0 1 2 3 4 5 6 7 8 9 10v 0 3.1 6.9 9.9 12.7 16.1 19.8 21.2 22.8 24.3 25.9
Figura 7.12: Viteza unei masini în primele 10 secunde dupa plecarea de pe loc
Se cere:(a) Desenati diagrama scatter plot;(b) Determinati dreapta de regresie a lui v fata de t;(c) Calculati coeficientul de corelatie empirica si comentati asupra validitatii aproximarii datelorcu dreapta de regresie.Exercitiu 7.9.7 Aproximarea dreptei de regresie a variabilei y fata de variabila x este y = 2x−6.Determinati conditiile în care aproximarea dreptei de regresie a lui x fata de y este x = 0.5y+3.Exercitiu 7.9.8 Tabelul 7.7 contine numarul de absente (A) la Statistica si notele corespunzatoare(N) a 15 studenti.
A 3 1 4 12 11 3 5 2 9 6 4 6 7 6 14N 9.00 9.50 8.75 4.75 5.50 8.50 6.75 8.25 5.50 6.75 8.00 7.75 6.00 7.00 3.50
Tabela 7.7: Tabel cu absente si note la Statistica.
(a) Calculati coeficientul de corelatie Pearson. Care este semnificatia acestei valori referitor larelatia dintre absente si note?(b) Determinati dreapta de regresie a lui N fata de A si desenati-o în acelasi sistem de axe cudatele din tabel.(c) Testati, la un nivel de semnificatie α = 0.05, daca exista dovezi suficiente pentru a afirma caîntre numarul de absente si notele obtinute exista o corelatie.

186 Capitolul 7. Corelatie si regresie
Exercitiu 7.9.9 În Tabelul 7.8 datele reprezinta înaltimile (H) si masele corporale (M) a 10 fetedintr-o clasa a unui liceu.
H 179.6 166.8 163.1 180.0 158.4 166.5 165.8 168.1 175.9 160.7M 61.2 48.2 46 64.4 46.3 54.7 51.4 55.3 65.3 47.9
Tabela 7.8: Înaltimea si masa corporala a 10 eleve dintr-o clasa.
Suntem interesati în prezicerea masei corporale, stiind înaltimea unei eleve.(a) Desenati diagrama scatter plot a lui H versus M. Bazându-va pe aceasta diagrama, consideratica metoda regresiei liniare este potrivita în acest caz?(b) Calculati estimatii ale parametrilor (β0 si β1) de regresie liniara si reprezentati grafic dreaptade regresie liniara.(c) Obtineti o estimare nedeplasata pentru σ2.(d) Testati ipoteza nula (H0) : β1 = 0.9.Exercitiu 7.9.10 S-a realizat un studiu pentru a afla daca exista vreo relatie între masa corporala(M) si presiunea sangvina (P) la oameni. Urmatorul set de date a fost obtinut dintr-un studiuclinic, alegând 10 persoane la întâmplare.
M 78 86 72 82 80 86 84 89 68 71P 140 160 134 144 180 176 174 178 128 132
(a) Calculati indicele de corelatie Pearson si determinati semnificatia acestuia (α = 0.05).(b) Scrieti o ecuatie liniara ce poate fi utilizata în a prezice presiunea sangvina a unei persoanepe baza masei sale corporale.(c) Calculati indicele de corelatie Spearman dintre M si P.Exercitiu 7.9.11 Tabelul de mai jos contine mediile obtinute de un elev de clasa a V-a la toatedisciplinele scolare, pentru fiecare dintre cele doua semestre.
Discipline A B C D E F G H I Jsemestrul I 6 9 7 8 8 9 9 9 7 10
semestrul al II-a 7 9 8 9 8 9 8 10 8 10
(a) Calculati coeficientul de corelatie Pearson si testati semnificatia valorii obtinute. (α = 0.04)(b) Calculati coeficientul de corelatie Spearman.
Exercitiu 7.9.12 Un numar de studenti ce au frecven-tat un anumit curs au fost solicitati sa îsi exprime pare-rea în legatura cu dificultatea si atractivitatea notiunilorprezentate. Pentru fiecare variabila, ei au avut de alesnumere întregi dintr-o scara de la 1 la 5, unde 1 re-prezinta clasa cea mai de jos de dificultate (respectivatractivitate) iar 5 nivelul maxim. Datele sunt prezen-tate în tabelul de frecvente alaturat.
Di f icultatea−→Utilitatea ↓ 1 2 3 4 5
1 0 0 3 4 62 0 0 4 4 73 0 4 5 6 54 3 5 4 1 05 5 3 1 1 0
Sunt cele doua opinii corelate? Calculati coeficientul de corelatie Pearson. Este semnificativ?(α = 0.05)
Exercitiu 7.9.13 Pentru datele de mai jos
X 0 1 2 3 4 5 6 7 8 9 10Y −0.2 1.2 4.21 9.15 15.6 24.3 35.9 48.31 62.95 80 95
determinati coeficientii de corelatie Pearson si Spearman. Care dintre ei este semnificativ lanivelul α = 0.04?
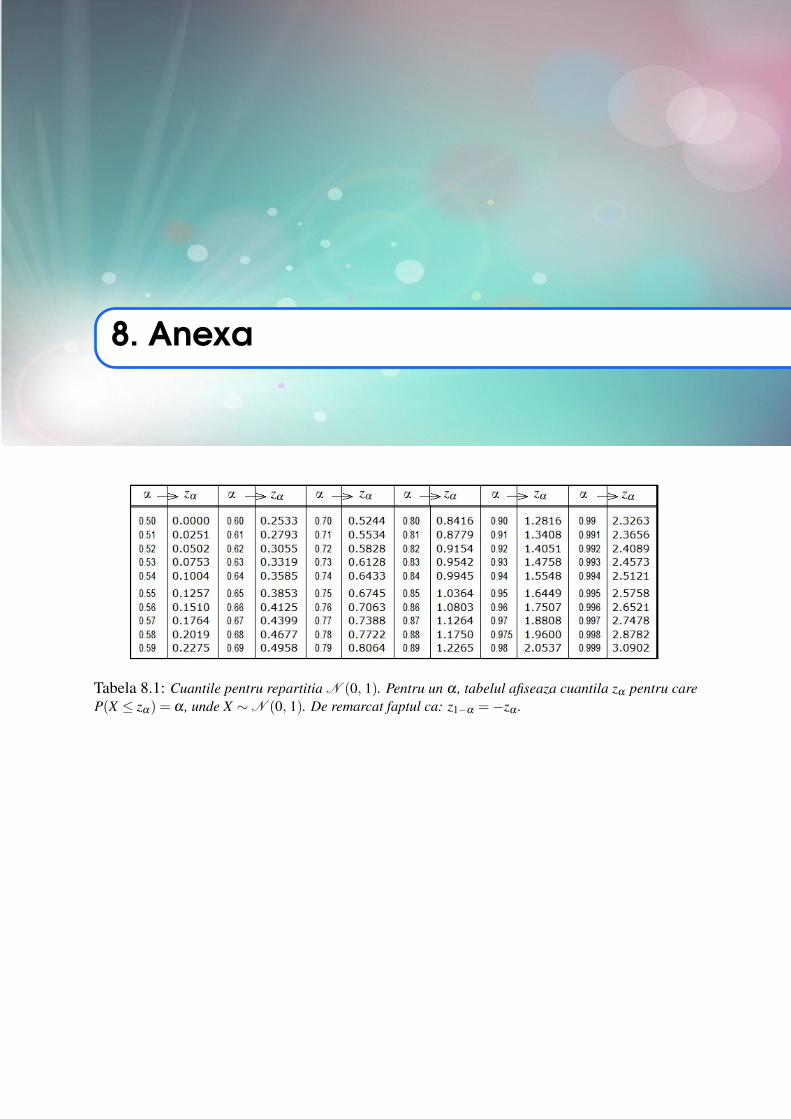
8. Anexa
Tabela 8.1: Cuantile pentru repartitia N (0, 1). Pentru un α , tabelul afiseaza cuantila zα pentru careP(X ≤ zα) = α , unde X ∼N (0, 1). De remarcat faptul ca: z1−α =−zα .
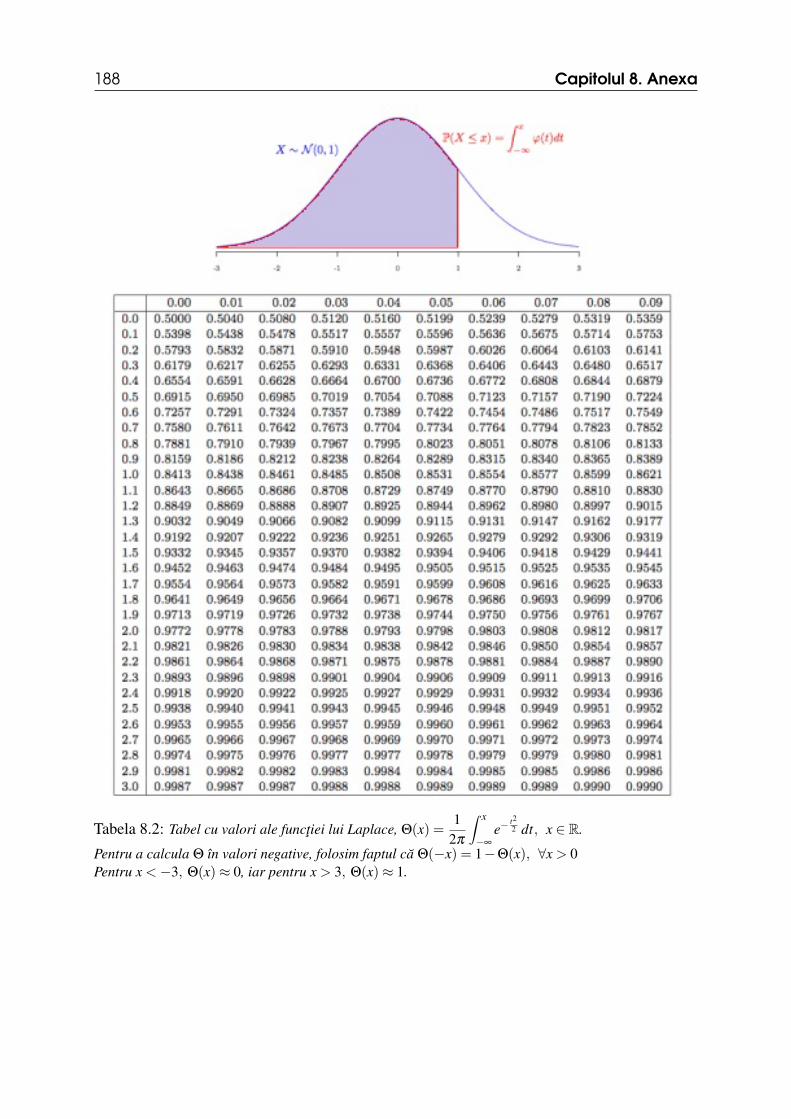
188 Capitolul 8. Anexa
Tabela 8.2: Tabel cu valori ale functiei lui Laplace, Θ(x) =1
2π
∫ x
−∞
e−t22 dt, x ∈ R.
Pentru a calcula Θ în valori negative, folosim faptul ca Θ(−x) = 1−Θ(x), ∀x > 0Pentru x <−3, Θ(x)≈ 0, iar pentru x > 3, Θ(x)≈ 1.
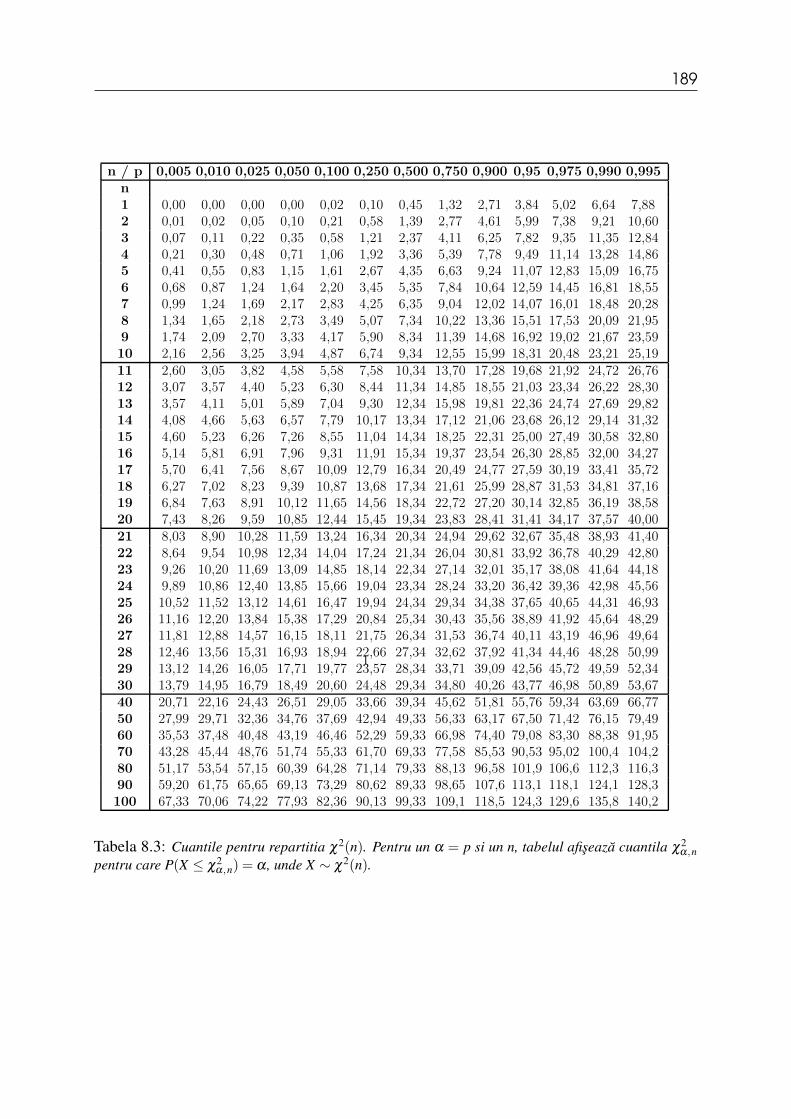
189
1 Table des quantiles de la v.a. Chi-Carre
Fournit les quantiles xp tels queP(X≤xp)= ppour X ∼ χ2
n
n / p 0,005 0,010 0,025 0,050 0,100 0,250 0,500 0,750 0,900 0,95 0,975 0,990 0,995n1 0,00 0,00 0,00 0,00 0,02 0,10 0,45 1,32 2,71 3,84 5,02 6,64 7,882 0,01 0,02 0,05 0,10 0,21 0,58 1,39 2,77 4,61 5,99 7,38 9,21 10,603 0,07 0,11 0,22 0,35 0,58 1,21 2,37 4,11 6,25 7,82 9,35 11,35 12,844 0,21 0,30 0,48 0,71 1,06 1,92 3,36 5,39 7,78 9,49 11,14 13,28 14,865 0,41 0,55 0,83 1,15 1,61 2,67 4,35 6,63 9,24 11,07 12,83 15,09 16,756 0,68 0,87 1,24 1,64 2,20 3,45 5,35 7,84 10,64 12,59 14,45 16,81 18,557 0,99 1,24 1,69 2,17 2,83 4,25 6,35 9,04 12,02 14,07 16,01 18,48 20,288 1,34 1,65 2,18 2,73 3,49 5,07 7,34 10,22 13,36 15,51 17,53 20,09 21,959 1,74 2,09 2,70 3,33 4,17 5,90 8,34 11,39 14,68 16,92 19,02 21,67 23,5910 2,16 2,56 3,25 3,94 4,87 6,74 9,34 12,55 15,99 18,31 20,48 23,21 25,1911 2,60 3,05 3,82 4,58 5,58 7,58 10,34 13,70 17,28 19,68 21,92 24,72 26,7612 3,07 3,57 4,40 5,23 6,30 8,44 11,34 14,85 18,55 21,03 23,34 26,22 28,3013 3,57 4,11 5,01 5,89 7,04 9,30 12,34 15,98 19,81 22,36 24,74 27,69 29,8214 4,08 4,66 5,63 6,57 7,79 10,17 13,34 17,12 21,06 23,68 26,12 29,14 31,3215 4,60 5,23 6,26 7,26 8,55 11,04 14,34 18,25 22,31 25,00 27,49 30,58 32,8016 5,14 5,81 6,91 7,96 9,31 11,91 15,34 19,37 23,54 26,30 28,85 32,00 34,2717 5,70 6,41 7,56 8,67 10,09 12,79 16,34 20,49 24,77 27,59 30,19 33,41 35,7218 6,27 7,02 8,23 9,39 10,87 13,68 17,34 21,61 25,99 28,87 31,53 34,81 37,1619 6,84 7,63 8,91 10,12 11,65 14,56 18,34 22,72 27,20 30,14 32,85 36,19 38,5820 7,43 8,26 9,59 10,85 12,44 15,45 19,34 23,83 28,41 31,41 34,17 37,57 40,0021 8,03 8,90 10,28 11,59 13,24 16,34 20,34 24,94 29,62 32,67 35,48 38,93 41,4022 8,64 9,54 10,98 12,34 14,04 17,24 21,34 26,04 30,81 33,92 36,78 40,29 42,8023 9,26 10,20 11,69 13,09 14,85 18,14 22,34 27,14 32,01 35,17 38,08 41,64 44,1824 9,89 10,86 12,40 13,85 15,66 19,04 23,34 28,24 33,20 36,42 39,36 42,98 45,5625 10,52 11,52 13,12 14,61 16,47 19,94 24,34 29,34 34,38 37,65 40,65 44,31 46,9326 11,16 12,20 13,84 15,38 17,29 20,84 25,34 30,43 35,56 38,89 41,92 45,64 48,2927 11,81 12,88 14,57 16,15 18,11 21,75 26,34 31,53 36,74 40,11 43,19 46,96 49,6428 12,46 13,56 15,31 16,93 18,94 22,66 27,34 32,62 37,92 41,34 44,46 48,28 50,9929 13,12 14,26 16,05 17,71 19,77 23,57 28,34 33,71 39,09 42,56 45,72 49,59 52,3430 13,79 14,95 16,79 18,49 20,60 24,48 29,34 34,80 40,26 43,77 46,98 50,89 53,6740 20,71 22,16 24,43 26,51 29,05 33,66 39,34 45,62 51,81 55,76 59,34 63,69 66,7750 27,99 29,71 32,36 34,76 37,69 42,94 49,33 56,33 63,17 67,50 71,42 76,15 79,4960 35,53 37,48 40,48 43,19 46,46 52,29 59,33 66,98 74,40 79,08 83,30 88,38 91,9570 43,28 45,44 48,76 51,74 55,33 61,70 69,33 77,58 85,53 90,53 95,02 100,4 104,280 51,17 53,54 57,15 60,39 64,28 71,14 79,33 88,13 96,58 101,9 106,6 112,3 116,390 59,20 61,75 65,65 69,13 73,29 80,62 89,33 98,65 107,6 113,1 118,1 124,1 128,3100 67,33 70,06 74,22 77,93 82,36 90,13 99,33 109,1 118,5 124,3 129,6 135,8 140,2
1
Tabela 8.3: Cuantile pentru repartitia χ2(n). Pentru un α = p si un n, tabelul afiseaza cuantila χ2α,n
pentru care P(X ≤ χ2α,n) = α , unde X ∼ χ2(n).
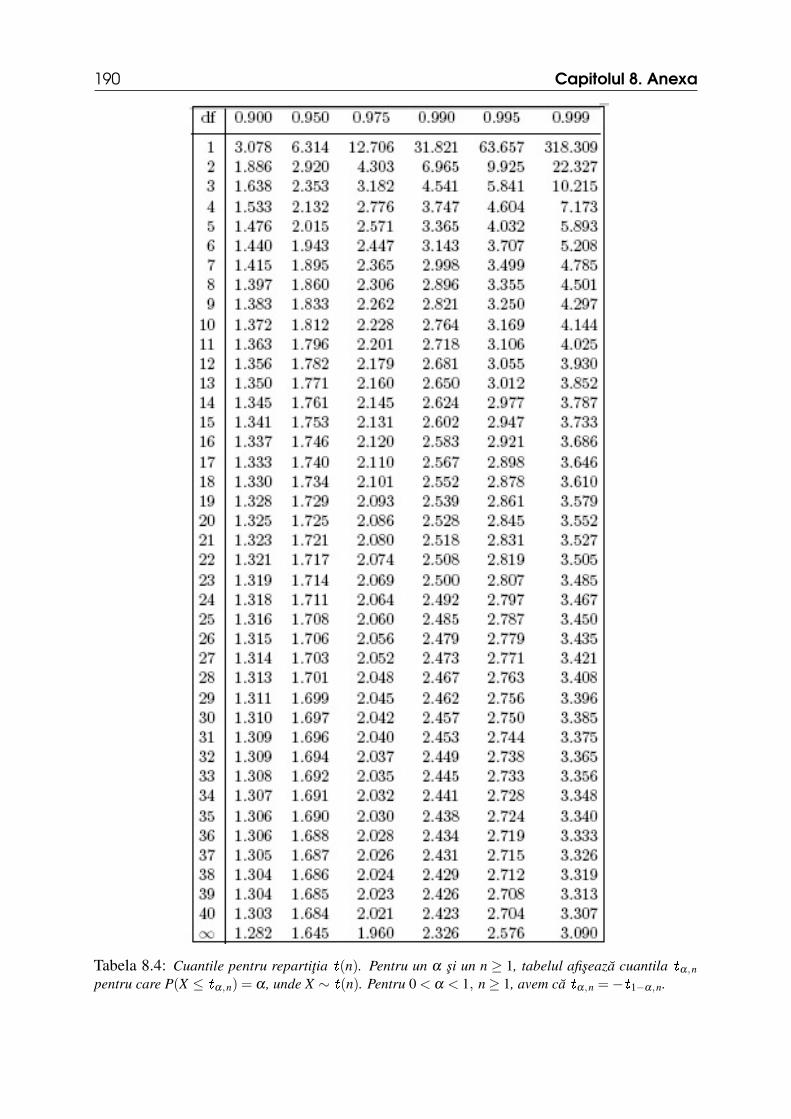
190 Capitolul 8. Anexa
Tabela 8.4: Cuantile pentru repartitia t(n). Pentru un α si un n ≥ 1, tabelul afiseaza cuantila tα,n
pentru care P(X ≤ tα,n) = α , unde X ∼ t(n). Pentru 0 < α < 1, n≥ 1, avem ca tα,n =−t1−α,n.
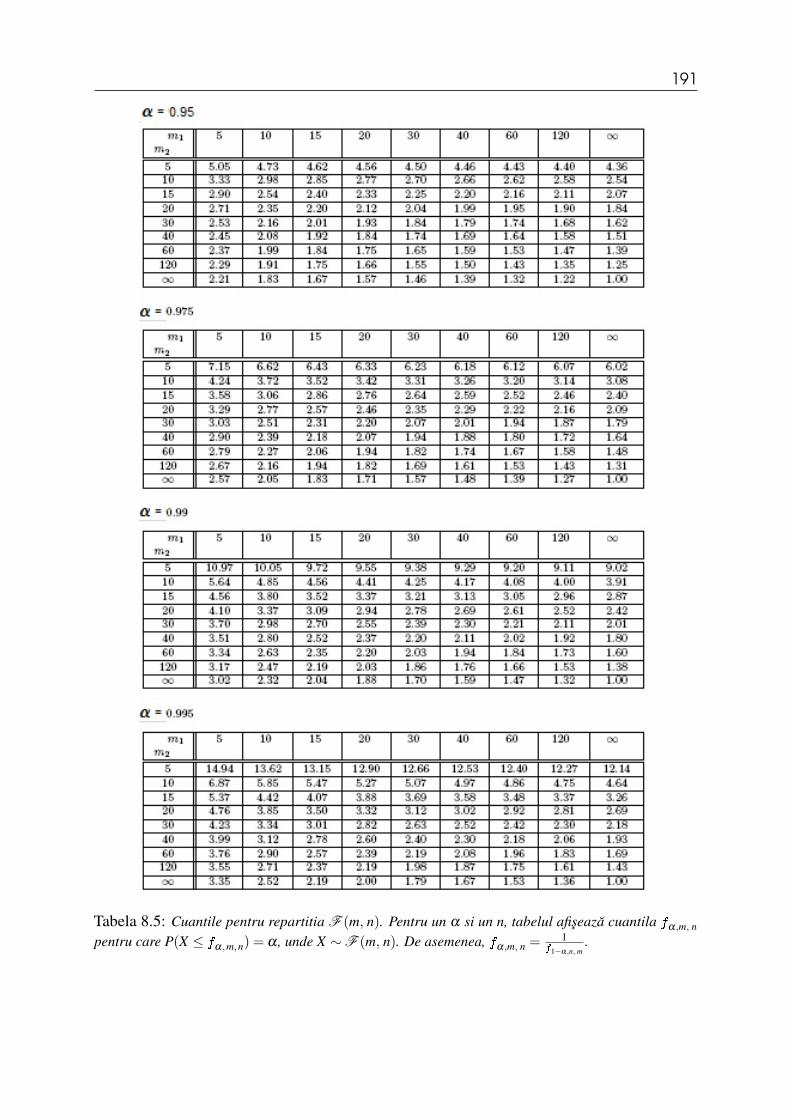
191
Tabela 8.5: Cuantile pentru repartitia F (m, n). Pentru un α si un n, tabelul afiseaza cuantila fα,m, n
pentru care P(X ≤ fα,m,n) = α , unde X ∼F (m, n). De asemenea, fα,m, n =1
f1−α,n, m.

192 Capitolul 8. Anexa
Motive serioase pentru care merita sa devii statistician(top 10)
(10) Pentru statisticieni, deviatiile sunt considerate a fi normale.(9) Statisticienii lucreaza discret si continuu.(8) Statisticienii pot concluziona orice, la un nivel de semnificatie potrivit.(7) Nu trebuie sa spunem niciodata ca suntem siguri; e suficient doar 95%.(6) Normalitatea nu este o conditie sine qua non.(5) Statisticienii sunt semnificativ diferiti.(4) Statisticienii pot testa, fara probleme si dupa o lege bine stabilita, distributia posterioara a
oricui.(3) Statistica este arta de a nu fi nevoit sa spui vreodata ca ai gresit.(2) Folosind un numar suficient de parametri, un statistician poate potrivi orice set de date.
"With four parameters I can fit an elephant, and with five I can make him wiggle his trunk."[John von Neumann]
(1) Aproape nimeni nu doreste jobul important al unui statistician, deci nu vei avea emotii cavei ramâne somer.

Bibliografie
[1] Petru Blaga, Statistica. . . prin Matlab, Presa universitara clujeana, Cluj-Napoca, 2002.
[2] David Brink, Statistics compendium, David Brink & Ventus Publishing ApS, 2008.
[3] David Brink, Statistics exercises, David Brink & Ventus Publishing ApS, 2008.
[4] Gheorghe Ciucu, Virgil Craiu, Teoria estimatiei si verificarea ipotezelor statistice, EdituraDidactica si Pedagogica, Bucuresti, 1968.
[5] Virgil Craiu, Teoria probabilitatilor cu exemple si probleme, Editura Fundatiei "Romaniade Mâine", Bucuresti, 1997.
[6] G. Ciucu, V. Craiu, I. Sacuiu, Probleme de teoria probabilitatilor, Editia a II-a, EdituraTehnica, Bucuresti, 1974.
[7] Steve Dobbs, Jane Miller, Statistics 1, Cambridge University Press, Cambridge 2000.
[8] Jay L. DeVore, Kenneth N. Berk, Modern Mathematical Statistics with Applications (withCD-ROM), second edition, Springer, 2012.
[9] I. Florescu, C.Tudor, Handbook of Probability, Wiley Handbooks in Applied Statistics,Wiley, 2013.
[10] Robert V. Hogg, Allen Craig, Joseph W. McKean, Introduction to Mathematical Statistics,Prentice Hall, 6th edition, 2004.
[11] Marius Iosifescu, Costache Moineagu, Vladimir Trebici, Emiliana Ursianu, Mica enciclo-pedie de statistica, Editura stiintifica si enciclopedica, Bucuresti, 1985.
[12] http://www.mathworks.com

194 BIBLIOGRAFIE
[13] Gheorghe Mihoc, N. Micu, Teoria probabilitatilor si statistica matematica, Bucuresti,1980.
[14] Elena Nenciu, Lectii de statistica matematica, Universitatea A. I. Cuza, Iasi, 1976.
[15] Octavian Petrus, Probabilitati si Statistica matematica - Computer Applications, Iasi, 2000.
[16] Sheldon M. Ross, A First Course in Probability, Eighth Edition, Pearson, 2010.
[17] M.R. Spiegel, L.J. Stephens, Schaum’s Outline of Statistics, McGraw-Hill, 2007.
[18] Larry J. Stephens, Theory and problems of Beginning Statistics, Schaum’s Outline Series,2nd ed., The McGraw-Hill Companies, Inc., 1998.
[19] Dominick Salvatore, Derrick Reagle, Theory and problems of Statistics and Econometrics,Schaum’s Outline Series, 2nd ed., The McGraw-Hill Companies, Inc., 2002.
[20] Iulian Stoleriu, Statistica prin MATLAB. MatrixRom, Bucuresti, 2010.
[21] Gábor Székely, Paradoxes in Probability Theory and Mathematical Statistics, (Mathematicsand its Applications), Springer Verlag, 1987.
[22] Sanford Weisberg, Applied Linear Regression, Wiley series in Probability and Statistics,3rd ed., 2005.
[23] David Williams, Weighing the Odds: A Course in Probability and Statistics, CambridgeUniversity Press, 2001.

Glosar
amplitudinea, 36, 55
box-and-whisker plot, 39
caracteristica, 9cauzalitate, 159, 162cel mai puternic test, 122clasa mediana, 40coeficient de aplatizare, 14, 37coeficient de asimetrie, 14, 37coeficient de corelatie, 15coeficient de corelatie, 36coeficient de corelatie empirica, 159coeficient de corelatie teoretic, 15, 158coeficientul de corelatie Spearman, 163coeficientul de corelatie empiric, 34coeficientul de determinare, 162coeficientul de variatie , 36colectivitate normala, 57colectivitate statistica, 9corelatia, 15, 36, 158corelatia empirica, 159corelatia teoretica, 15, 158corelatie, 157covarianta, 15, 158cuantile, 14
date continue, 10, 26date discrete, 10, 25densitati de frecventa, 31
deviatie standard de selectie, 53deviatie standard empirica, 53deviatia standard, 36diagrama cuantila-cuantila, 34diagrama probabilitate-probabilitate, 34dispersia, 36dispersia de selectie, 52dispersia empirica, 52dispersia teoretica, 51dispersia teoretica, 14dispersie de selectie modificata, 52distributie empirica de selectie, 26
esantion, 49eficienta, 81eroare în medie patratica, 75eroarea standard, 52estimatie, 74estimator, 74estimator absolut corect, 76estimator consistent, 75estimator de verosimilitate maxima, 83estimator eficient, 81estimator prin metoda momentelor, 85extrapolare, 178
frecventa cumulata, 28frecventa absoluta, 27frecventa cumulata, 27frecventa relativa cumulata, 27

196 GLOSAR
frecventa relativa, 27frontierele unei clase, 33functie de repartitie, 51functie de repartitie de selectie, 53functie de repartitie empirica, 36
histograma, 31
informatie Fisher, 79informatie Fisher, 79interval de încredere, 89ipoteza statistica, 117, 118
kurtosis, 14, 37
media, 35media de selectie, 51media empirica, 51media teoretica, 51metoda celor mai mici patrate, 86metoda minimului lui χ2, 87modul, 15momente, 35momente centrate ale unei v.a., 14
nivel de semnificatie, 89, 118
ogiva, 34
P-valoare, 119, 121populatie statistica, 9predictie, 177probabilitate de risc, 89prognoza, 178puterea unui test, 122
recensamânt, 11regiune critica, 118, 119regresie, 157, 165regresie liniara simpla, 167repartitia mediei de selectie, 58riscul beneficiarului, 119riscul furnizorului, 119
scatter plot, 157scor, 78selectie, 10skewness, 14, 37Statistica, 8statistica, 50, 51
statistica suficienta, 82statistica test, 119statistica, 50statistici de ordine, 55stem-and-leaf, 29
tabel de frecvente, 26test bilateral, 120test de concordanta, 147test statistic, 119, 120test unilateral dreapta, 120test unilateral stânga, 120testul χ2, 147testul t pentru date perechi, 132
UMVUE, 75
valoare critica, 119valori de selectie, 50variabila predictor , 157variabila raspuns, 157variabila aleatoare, 13variabile aleatoare de selectie, 50verosimilitate, 78

















