

1
Curs 1 Econometrie
1.1. Ce este econometria? 1.2. Metodologia econometriei 1.3. Recapitularea unor noţiuni de statistică descriptivă şi inferenţială 1.1. Ce este econometria? Simplu spus, econometria înseamnă măsurătoare economică.
Ragnar Anton Kittil Frisch
primul câştigător al premiului Nobel în economie 1969
Goldberg1 defineşte econometria ca fiind ştiinţa în care uneltele teoriilor economice, matematice şi statistice sunt aplicate pentru analizarea unor fenomene economice. Samuelson, Koopmans şi Stone2 spun că econometria constă în aplicarea statisticii în datele economice pentru a adapta modelele empirice la modele construite cu ajutorul economiilor matematice cu scopul de a obţine rezultate numerice.
Paul Anthony Samuelson Tjalling C.Koopmans John Richard Nicholas Stone premiul Nobel în economie în 1970 premiul Nobel în economie în 1975 premiul Nobel în economie în 1984
În fapt, econometria, se bazează pe dezvoltarea metodelor statistice pentru estimarea legăturilor între variabilele economice, pentru testarea teoriilor economice şi pentru evaluarea şi implementarea politicilor economice. Una dintre cele mai importante aplicaţii ale econometriei constă în previzionarea unor indicatori macroeconomici cum ar fi rata dobânzii, rata inflaţiei, PIB. 1 Goldberg, A.S., Econometric Theory, Wiley, New-York, 1964, p. 1. 2 Samuelson, P.A., Koopmans, T.C., Stone, J.R.N., Report of the Evaluative Committee for Econometrica, Econometrica, 22(2), 1954, pg. 141-146.

2
1.2. Metodologia econometriei
1. Formularea ipotezelor; 2. Colectarea datelor; 3. Specificarea modelului matematic; 4. Specificarea modelului statistic sau econometric; 5. Estimarea parametrilor modelului ales; 6. Găsirea celui mai bun model; 7. Testarea ipotezelor ce derivă din model; 8. Estimări şi previziuni pe baza modelului.
În fapt econometria a apărut ca instrument de testare a unor ipoteze formulate pornind de la anumite situaţii întâlnite în practica economică.
Spre exemplu pornim cu următoarea întrebare: ? Influenţează condiţiile economice dorinţa oamenilor de a munci?
Pentru a răspunde la această întrebare considerăm două variabile şi anume rata şomajului (RS) şi rata forţei de muncă (RFM). 1.2.1. Formularea ipotezelor În teoriile economice asupra pieţei muncii există două ipoteze asupra efectului condiţiilor economice asupra dorinţei oamenilor de a muncii şi anume:
1. ipoteza „discouraged-worker” care spune că atunci când condiţiile economice se înrăutăţesc mulţi şomerii renunţă la speranţa de a-şi mai găsi un loc de muncă;
2. ipoteza „added-worker” care spune că în condiţii economice înrautăţite mulţi dintre cei apţi de muncă, dar care nu activează pe piaţa muncii (mame cu copii), decid să intre pe piaţa muncii în condiţiile în care celălalt membru al familiei îşi pierde slujba. Chiar dacă slujba este slab remunerată, câştigurile vor acoperi o parte din pierderile suferite prin concedierea celulilalt membru al familiei.
Este evident că dacă efectul „added-worker” este dominant, RFM va creşte chiar în condiţiile unei RS ridicate. Invers, dacă efectul „discouraged-worker” este dominant atunci RFM va scădea. Se pune întrebarea cum aflăm acest lucru? Care evident este o întrebare empirică.
3
1.2.2. Colectarea datelor Avem nevoie de informaţii cantitative despre cele două variabile.
Anul RFM (%) RS (%) COM* ($) 1980 63.8 7.1 7.78 1981 63.9 7.6 7.69 1982 64.0 9.7 7.68 1983 64.0 9.6 7.79 1984 64.4 7.5 7.80 1985 64.8 7.2 7.77 1986 65.3 7.0 7.81 1987 65.6 6.2 7.73 1988 65.9 5.5 7.69 1989 66.5 5.3 7.64 1990 66.5 5.6 7.52 1991 66.2 6.8 7.45 1992 66.4 7.5 7.41 1993 66.3 6.9 7.39 1994 66.6 6.1 7.40 1995 66.6 5.6 7.40 1996 66.8 5.4 7.43
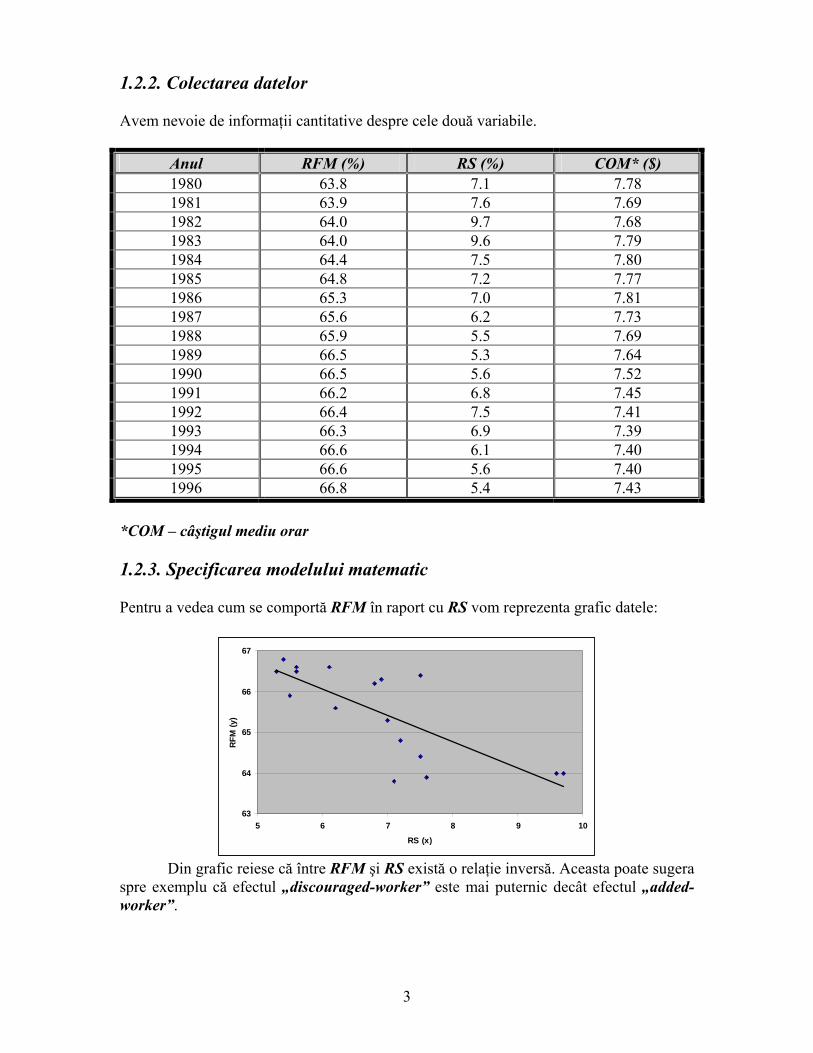
*COM – câştigul mediu orar 1.2.3. Specificarea modelului matematic Pentru a vedea cum se comportă RFM în raport cu RS vom reprezenta grafic datele:
63
64
65
66
67
5 6 7 8 9 10
RS (x)
RFM
(y)
Din grafic reiese că între RFM şi RS există o relaţie inversă. Aceasta poate sugera
spre exemplu că efectul „discouraged-worker” este mai puternic decât efectul „added-worker”.

4
Ca o primă aproximare putem scrie relaţia dintre RFM şi RS astfel: RFM=B0 + B1*RS (1) B0, B1 se numesc parametrii modelului matematic. B1 ne arată cu cât se modifică RFM atunci când RS se modifică cu o unitate. B1 poate fi pozitiv caz în care în exemplul nostru efectul „added-worker” domină efectul „discouraged-worker” sau poate fi negativ caz în care efectul „discouraged-worker” este mai puternic decât efectul „added-worker”. Gaficul sugerează, în cazul exemplului nostru, că B1<0. 1.2.4. Specificarea modelului statistic sau econometric Modelul liniar de mai sus nu este foarte „iubit” de statisticieni pentru că acest model sugerează că unei valori a lui RS îi corespunde o unică valoare a lui RFM. În practică aceste cazuri sunt rareori întâlnite de cele mai multe ori relaţiile între diferite variabile economice sunt inexacte sau statistice adică sunt adevărate cu o anumită probabilitate. Reiese clar din reprezentarea grafică că nu toate punctele se află pe aceeaşi dreaptă. De ce se întâmplă aşa? Pentru că între valorile observate (cele din tabel) şi cele calculate (cele de pe dreapta definită de ecuaţia (1)) există anumite diferenţe, diferenţe cunoscute sub numele de erori aleatoare. Din punct de vedere practic aceste erori aleatoare reprezintă alţi factori(aleatori) care pot influenţa RFM. În aceste condiţii modelul econometric va fi:
RFM=B0 + B1*RS + u (2) Modelul (2) este cunoscut sub numele de model regresional liniar care în forma sa generală arată astfel:
Y=B0 + B1*X + u (3) unde: Y – variabila dependentă (explicată, output); X – variabila independentă (explicativă, input). Se observă că relaţia (2) derivă din relaţia (1) ceea ce demonstrează complementaritatea matematicilor economice şi a econometriei. Observaţie În ecuaţia (2) am stabilit că RFM este variabila dependentă, iar RS este variabila independentă. Se pune întrebarea: sunt cele două variabile relaţionate cauzal? Este RS cauza şi RFM efectul? Cu alte cuvinte implică regresia cauzalitate?

5
Kendall şi Stuart3 notează că o relaţie statistică, oricât de puternică şi sugestivă nu poate stabili o relaţie cauzală. Ideea de cauzalitate trebuie să vină din afara statisticii. Conform acestei teorii, în cazul exemplului nostru, teoria economică trebuie să stabilească relaţia de tip cauză-efect, dacă există, între cele două variabile. Dacă cauzalitatea nu poate fi stabilită, atunci ecuaţia (2) o vom numi relaţie predictivă, adică ştiind RS putem previziona RFM. 1.2.5. Estimarea parametrilor modelului econometric Metoda care stă la baza estimării parametrilor modelului regresional se numeşte metoda celor mai mici pătrate pe baza căreia obţinem că: RFM = 69.9355 – 0.6458*RS (4) Observaţie: RFM ne reaminteşte că (4) este o estimare a ecuaţiei (2). Această relaţie ne arată că dacă RS creşte cu o unitate, RFM scade în medie cu 0.64 puncte procentuale. 1.2.6. Alegerea celui mai bun model Cât de bun, cât de adecvat, este modelul definit de ecuaţia (4)? Este adevărat că o persoană va decide să intre pe piaţa muncii luând în considerare condiţiile de pe această piaţă măsurate prin rata şomajului? Este evident că există şi alţi factori care vor influenţa decizia cum ar fi spre exemplu câştigul mediu orar (COM). Dacă vom lua în considerare şi această variabilă atunci vom ajunge la următorul model: RFM= B0 + B1*RS + B2*COM + u (5) Ecuaţia (5) este un exemplu de model regresional multiplu în care intervin două variabile explicative. Parametrii modelului, aşa cum vom vedea mai târziu, se determină prin metoda celor mai mici pătrate. În acest caz vom avea: RFM= 97.9 – 0.446*RS – 3.86*COM (6) Această relaţie ne arată următoarele:
• dacă COM este constatat atunci RFM se modifică cu 0.446 puncte procentuale la modificări cu o unitate ale RS;
3 Kendall, M.G., Stuart, A., The Advanced Theory of Statistics, Charles Griffin Publishers, New-York, 1961.

6
• dacă RS este constatat atunci RFM se modifică cu 3.86 puncte procentuale la modificări cu o unitate ale COM.
Care model trebuie ales? 1.2.7. Testarea ipotezelor ce derivă din model Având acum un model determinat vrem să aflăm dacă acesta are sens din punct de vedere economic. De exemplu ipoteza „discouraged-worker” postulează o relaţie inversă între RFM şi RS. Reiese această ipoteză din rezultatele obţinute de noi? Rezultatele obţinute de noi sunt în conformitate cu această ipoteză deoarece coeficientul estimat corespunzător lui RS este negativ. Ce este de reţinut aici este faptul că în cazul analizei regresionale s-ar putea să fim interesaţi nu numai de estimarea parametrilor modelului ci şi de testarea unor ipoteze sugerate de teoria economică. 1.2.8. Estimări şi predicţii Se pune natural următoarea întrebare: O dată trecuţi prin toate etapele de mai sus şi având la dispoziţie cel mai bun model regresional, ce putem face cu acesta? Răspunsul este cât se poate de evident. Îl vom folosi pentru a estima sau previziona RFM corespunzătoare unor valori ale RS şi COM înregistrate spre exemplu în anul 1997. Comparând valorile obţinute cu cele reale, publicate de guvern, se vor observa diferenţa numite şi erori de predicţie. Evident că scopul nostru va fi ca aceste erori să fie cât mai mici. Dacă acest lucru este întotdeauna posibil vom vedea ceva mai târziu. 1.3. Recapitularea unor noţiuni de statistică descriptivă şi inferenţială Ne propunem în această secţiune să facem un repertoar al celor mai importante noţiuni de statistică descriptivă şi inferenţială, noţiuni ce vor fi folosite de-a lungul cursului de econometrie. Pentru detalii sunteţi rugaţi să consultaţi:
Server/Profiles/Chifu/Statistica_aplicata
1.3.1. Elemente de statistică descriptivă
Date, elemente, populaţie, eşantion, variabile, serii statistice
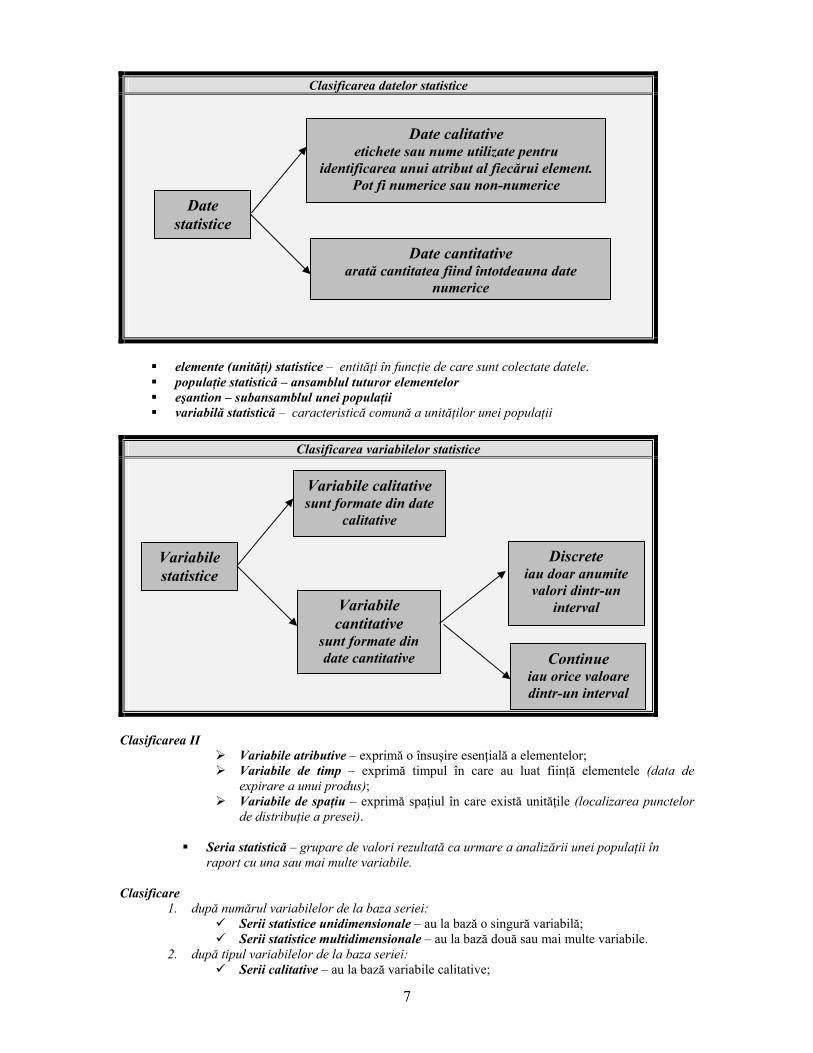
Statistica – ştiinţa colectării, analizării, prezentării şi interpretării datelor. date statistice
7
Clasificarea datelor statistice
elemente (unităţi) statistice – entităţi în funcţie de care sunt colectate datele. populaţie statistică – ansamblul tuturor elementelor eşantion – subansamblul unei populaţii variabilă statistică – caracteristică comună a unităţilor unei populaţii
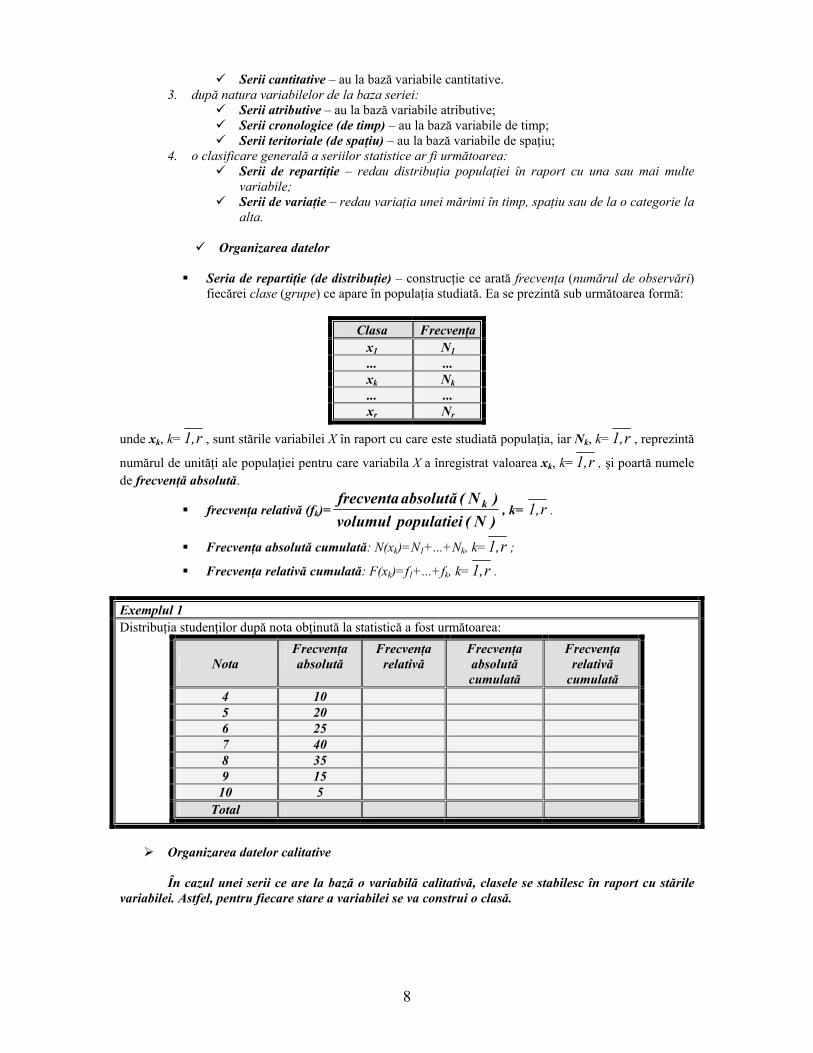
Clasificarea variabilelor statistice
Clasificarea II
Variabile atributive – exprimă o însuşire esenţială a elementelor; Variabile de timp – exprimă timpul în care au luat fiinţă elementele (data de
expirare a unui produs); Variabile de spaţiu – exprimă spaţiul în care există unităţile (localizarea punctelor
de distribuţie a presei).
Seria statistică – grupare de valori rezultată ca urmare a analizării unei populaţii în raport cu una sau mai multe variabile.
Clasificare
1. după numărul variabilelor de la baza seriei: Serii statistice unidimensionale – au la bază o singură variabilă; Serii statistice multidimensionale – au la bază două sau mai multe variabile.
2. după tipul variabilelor de la baza seriei: Serii calitative – au la bază variabile calitative;
Variabile statistice
Variabile calitative sunt formate din date
calitative
Variabile cantitative
sunt formate din date cantitative
Discrete iau doar anumite
valori dintr-un interval
Continue iau orice valoare dintr-un interval
Date statistice
Date calitative etichete sau nume utilizate pentru
identificarea unui atribut al fiecărui element. Pot fi numerice sau non-numerice
Date cantitative arată cantitatea fiind întotdeauna date
numerice
8
Serii cantitative – au la bază variabile cantitative. 3. după natura variabilelor de la baza seriei:
Serii atributive – au la bază variabile atributive; Serii cronologice (de timp) – au la bază variabile de timp; Serii teritoriale (de spaţiu) – au la bază variabile de spaţiu;
4. o clasificare generală a seriilor statistice ar fi următoarea: Serii de repartiţie – redau distribuţia populaţiei în raport cu una sau mai multe
variabile; Serii de variaţie – redau variaţia unei mărimi în timp, spaţiu sau de la o categorie la
alta.
Organizarea datelor
Seria de repartiţie (de distribuţie) – construcţie ce arată frecvenţa (numărul de observări) fiecărei clase (grupe) ce apare în populaţia studiată. Ea se prezintă sub următoarea formă:
Clasa Frecvenţa
x1 N1 ... ... xk Nk ... ... xr Nr
unde xk, k= r,1 , sunt stările variabilei X în raport cu care este studiată populaţia, iar Nk, k= r,1 , reprezintă
numărul de unităţi ale populaţiei pentru care variabila X a înregistrat valoarea xk, k= r,1 , şi poartă numele de frecvenţă absolută.
frecvenţa relativă (fk)= )N(populatieivolumul)N(absolutăfrecventa k , k= r,1 .
Frecvenţa absolută cumulată: N(xk)=N1+...+Nk, k= r,1 ;
Frecvenţa relativă cumulată: F(xk)=f1+...+fk, k= r,1 . Exemplul 1 Distribuţia studenţilor după nota obţinută la statistică a fost următoarea:
Nota Frecvenţa absolută
Frecvenţa relativă
Frecvenţa absolută cumulată
Frecvenţa relativă
cumulată 4 10 5 20 6 25 7 40 8 35 9 15
10 5 Total
Organizarea datelor calitative
În cazul unei serii ce are la bază o variabilă calitativă, clasele se stabilesc în raport cu stările variabilei. Astfel, pentru fiecare stare a variabilei se va construi o clasă.
9
Exemplul 2 Un producător de pâine realizează cinci sortimente de pâine pe care le pune în vânzare printr-un magazin propriu. Cele cinci sortimente de pâine sunt: franzelă (F), baghetă (B), pâine albă (PA), pâine neagră (PN), pâine integrală (PI). Producătorul iniţiază un studiu în vederea obţinerii de informaţii cu privire la sortimentul care se bucură de cel mai mare succes printre consumatori. Pentru aceasta producătorul urmăreşte un lot de n=30 clienţi pentru a vedea sortimentul pe care aceştia îl preferă. Rezultatele studiului sunt redate în tabelul următor:
PA PI B PA PI PA PN PI PA PA F PA PN F PA B F PN B F
PA F PA F F PI B PI PN B
1. Populaţia studiată este formată din_________________________ 2. Volumul eşantionului este n=_______ 3. Variabila în raport cu care este studiat eşantionul este__________, de tip_______, avînd
stările_______________ 4. Repartiţia clienţilor în raport cu sortimentul ales este:
Sortiment (S) Frecvenţa absolută
Frecvenţa relativă
Frecvenţa absolută
cumulataă
Frecvenţa relativă
cumulataă F B
PA PN PI
Total
Organizarea datelor cantitative
În cazul în care seria are la bază o variabilă cantitativă discretă dar cu un număr relativ mic de stări, clasele se stabilesc ca şi în cazul seriilor care au la bază variabile cu caracter calitativ adică fiecărei stări a variabilei i se asociază o clasă. Exemplul 3 Managerii unei firme (F) având 20 de angajaţi doresc să cunoască date referitoare la aceştia în vederea realizării unor promovări. Referitor la vechimea angajaţilor în firmă, datele culese au fost următoarele:
Vechimea angajaţilor (V) 2 4 2 4 2 2 5 3 3 3 4 2 3 3 3 3 5 5 2 5
1. Populaţia studiată este formată din_________________________ 2. Volumul eşantionului este n=_______ 3. Variabila în raport cu care este studiat eşantionul este__________, de tip_______, avînd
stările_______________ 4. Repartiţia angajaţilor în raport cu vechimea ales este:
Vechime (V) Frecvenţa absolută1
Frecvenţa relativă (%)2
Frecvenţa absolută
cumulată3
Frecvenţa relativă
cumulată (%)4
2 3 4
10
5 Total
Ce se întâmplă dacă la baza unei serii statistice stă o variabilă cantitativă continuă sau discretă dar cu un număr mare de stări?⇒ intervalele de variaţie.
Clasa Frecvenţaxo – x1 N1
... ... xk-1 – xk Nk
... ... xr-1 – xr Nr
unde: xo=xmin este cea mai mică valoare înregistrată de variabilă; xr=xmax este (în general) cea mai mare valoare înregistrată de variabilă;
xk-1 - xk – clasa, intervalul de variaţie; xk=xk-1+l, unde l este lungimea intervalului de variaţie, k= r,1 .
Lungimea intervalului (l)=clasenumarxx minmax −
.
Exemplul 4 Relativ la veniturile lunare ale angajaţilor firmei F, datele culese (sute RON) sunt următoarele:
Veniturile angajaţilor (Vn) 12 14 21 22 17 15 14 18 32 23 20 15 19 16 28 22 27 18 18 13
1. Populaţia studiată este formată din_________________________ 2. Volumul eşantionului este n=_______ 3. Variabila în raport cu care este studiat eşantionul este__________, de tip_______, avînd
stările_______________ 4. Repartiţia angajaţilor în raport cu venitul ales este (se vor folosi 5 calse):
Venit (Vn)
Frecvenţa absolută1
Frecvenţa relativă (%)2
Frecvenţa absolută
cumulată3
Frecvenţa relativă
cumulată (%)4
Total
Distribuţii bidimensionale X Y
x1 x2 ... xj ... xJ Total
y1 N11 N12 ... N1j ... N1J 1N ′
y2 N21 N22 ... N2j ... N2J 2N ′
... yi Ni1 Ni2 ... Nij ... NiJ
iN ′
... yI NI1 NI2 ... NIj ... NIJ
IN ′
Total N1 N2 ... Nj ... NJ N

11
În acest tabel notaţiile ce apar reprezintă:
• Nij – numărul de unităţi pentru care variabila X a înregistrat starea xj, iar variabila Y a înregistrat starea yi;
• iN ′ - numărul de unităţi pentru care variabila Y a înregistrat starea yi indiferent de nivelul înregistrat de variabila X;
• Nj - numărul de unităţi pentru care variabila X a înregistrat starea xj indiferent de nivelul înregistrat de variabila Y;
• N – volumul populaţiei studiate. Exemplul 5 Relativ la angajaţii firmei F, repartiţia bidimensională în raport cu vechimea şi veniturile salariale lunare va arăta astfel:
Venituri salariale (Vn)
12 – 16 16 – 20 20 – 24 24 – 28 28 – 32 Total 2 3 4 5
Vec
him
e (V
)
Total Parametrii tendinţei centrale şi de structură Cazul discret Valoarea medie (μ, x )
populaţie ∑∑ == kkkk fx
NNx
μ ,
eşantion ∑∑ == kkkk fx
nnx
x
Valoarea mediană (Me) Modalitatea de calcul a valorii mediane în cazul discret implică următoarele etape:
Determinarea rangului valorii mediane: 2NrMe = ;
Dacă Mer ∉ Ζ atunci Me = [ ] 1rMex + , unde [rMe] reprezintă partea întreagă a
rangului medianei;
Dacă Mer ∈ Ζ atunci Me = 2xx 1rr MeMe ++
.
Valoarea modală este acea valoare a unei variabile pentru care s-a înregistrat cea mai mare frecvenţă Quartilele Aşa cum am văzut împart populaţia în 4 părţi egale ceea ce implică faptul că vom avea de calculat p=3 valori. Modalitatea de calcul nu diferă foarte mult de cea din cazul medianei. Astfel vom avea următoarele etape:

12
Determinarea rangului quartilei: N4p
rpQ ⋅= ;
Dacă pQr ∉ Ζ atunci Qp = [ ] 1r pq
x + , unde [rQp] reprezintă partea întreagă a
rangului quartilei;
Dacă pQr ∈ Ζ atunci Qp =
2
xx 1rr pqpq ++.
Cazul datelor grupate pe intervale de variaţie
Clasa Frecvenţa absolută Frecvenţa relativă[xo , x1] N1 f1 (x1 , x2] N2 f2
... ... ... (xk-1, xk] Nk fk
... ... ... (xr-1, xr] Nr fr
Valoarea medie (μ, x ) În cazul datelor grupate pe intervale de variaţie modalitatea de calcul a valorii medii este următoarea:
În cazul populaţiei: ∑∑ ′=′
= kkkk fx
NNx
μ , unde 2
xxx k1k
k+
=′ − , este centrul clasei k
(mijlocul intervalului de variaţie).
În cazul eşantionului ∑∑ ′=′
= kkkk fx
nnx
x , unde 2
xxx k1k
k+
=′ − este centrul clasei k
(mijlocul intervalului de variaţie)
Valoarea mediană (Me)
Determinarea rangului valorii mediane: 2NrMe = ;
Determinarea intervalului valorii mediane – se calculează frecvenţele cumulate până la acea frecvenţă care adăugată conduce la depăşirea rangului valorii mediane, cu alte cuvinte dacă N1+...+Nk ≥ rMe, atunci Me∈(xk-1 , xk] interval căruia îi corespunde frecvenţa Nk;
Calcularea expresiei Δx = ( ) ( )1kk
k
1kMe xxN
xNr−
− −⋅−
, unde ( )1kxN − este frecvenţa
cumulată până la intervalul median; Calcularea valorii mediane: Me = xk-1 + Δx.
Valoarea modală (Mo)
Determinarea intervalului valorii modale - acel interval pentru care s-au înregistrat cele mai multe unităţi statistice;
Mo = xk-1 + ( )1kk21
1 xx −−⋅+ ΔΔΔ
, unde Δ1 este diferenţa dintre frecvenţa intervalului modal
şi frecvenţa intervalul precedent, iar Δ2 este diferenţa dintre frecvenţa intervalului modal şi frecvenţa intervalul următor.

13
Quartilele
Determinarea rangului quartilei: Nmpr
pq = , p= 1m,1 − ;
Determinarea intervalului quartilei – se calculează frecvenţele cumulate până la acea frecvenţă care adăugată conduce la depăşirea rangului quartilei, cu alte cuvinte dacă N1+...+Nk ≥ pqr ,
atunci qp ∈(xk-1 , xk];
Calcularea expresiei Δx = ( )
( )1kkk
1kqxx
N
xNrp
−−
−⋅−
, unde ( )1kxN − este frecvenţa
cumulată până la intervalul quartilei, iar lk este lungimea intervalului quartilei; Calcularea valorii quartile: qp = xk-1 + Δx, p= 1m,1 − .
Parametrii variaţiei
Dispersia (σ2, s2). Abaterea medie pătratică (σ, s). Dispersia
Populaţie Caz discret
date negrupate 2xσ =
( )N
x 2k∑ −μ
;
date grupate 2xσ =
( )N
Nx k2
k∑ −μ.
Caz continuu (date grupate pe intervale de variaţie):
2xσ =
( )N
Nx k2
k∑ −′ μ,
unde 2
xxx k1k
k+
=′ − este centrul clasei k (mijlocul intervalului de variaţie).
Eşantion Caz discret
date negrupate 2xs =
( )1n
xx2
k
−−∑
;
date grupate 2xs =
( )1n
nxx k2
k
−−∑
.
Caz continuu (date grupate pe intervale de variaţie):
2xs =
( )1n
nxx k2
k
−−′∑
,
unde 2
xxx k1k
k+
=′ − este centrul clasei k (mijlocul intervalului de variaţie), iar nk
este frecvenţa clasei în eşantion. Abaterea medie pătratică – măsoară gradul de reprezentativitate al valorii medii, dând măsura gradului de împrăştiere a valorilor variabilei în jurul valorii medii.
Populaţie: σx =2xσ ;
14
Eşantion: sx =2xs .
Coeficientul de variaţie al lui Pearson
Populaţie: Vx = 100x ×μσ
;
Eşantion: Vx = 100xsx × .
Exemplul 6 Reluăm exemplul relativ la vechimea angajaţilor firmei F. Seria statistică obţinută în acest caz a fost:
Vechime (V) Frecvenţa absolută 2 6 3 7 4 3 5 4
Total 20 Să se determine vechimea medie, mediană, modală, quartilele şi parametrii variaţiei.
Exemplul 7 În cazul veniturilor angajaţilor firmei F avem:
Clasa de venit Centrul Frecvenţa absolută[12,16] 14 7 (16,20] 18 6 (20,24] 22 4 (24,28] 26 2 (28,32] 30 1
Să se determine vechimea medie, mediană, modală, quartilele şi parametrii variaţiei.
Coeficientul de corelaţie liniară
rxy =( ) ( )2
i2i
2i
2i
iiii
yynxxn
yxyxn
∑∑∑∑∑∑∑
−−
−
Valorile coeficientului de corelaţie sunt cuprinse între -1 şi 1. Astfel: • dacă r∈[0;0,3] ⇒ legătură liniară pozitivă (directă) slabă; • dacă r∈(0,3;0,7] ⇒ legătură liniară pozitivă (directă) de intensitate medie; • dacă r∈ (0,7;1] ⇒ legătură liniară pozitivă (directă)
puternică; • dacă r∈[-0,3;0] ⇒ legătură liniară negativă (inversă)
slabă; • dacă r∈[-0,7; -0,3) ⇒ legătură liniară negativă (inversă) de intensitate medie; • dacă r∈ [-1; -0,7) ⇒ legătură liniară negativă (inversă)
puternică.

15
Exemplul 8 Un eşantion de 20 de angajaţi ai unei firme a furnizat următoarele date în ceea ce priveşte vechimea şi venitul lunar:
Vechimea (ani) Venitul (mil. ROL)2 15 2 16 4 20 3 17 3 16 4 19 5 22 5 21 1 12 2 14 5 22 5 21 5 21 3 16 3 18 2 14 4 19 5 21 1 10 3 17
Se cere să se studieze intensitatea legăturii dintre vechime şi venit.
1.3.2. Elemente de statistică inferenţială
Estimarea parametrilor Estimarea punctuală a parametrilor
Estimatorul punctual al valorii medii μ a populaţiei este media de eşantion
nx
x i∑= .
Estimatorul punctual al dispersiei populaţiei 2xσ este dispersia de eşantion
( )
1nxx
s2
i2x −
−= ∑ .
Estimatorul punctual al abaterii medii pătratice a populaţiei σx este abaterea medie pătratică de eşantion
sx=2xs .
Estimatorul punctual al erorii standard a mediei xσ este xs unde:
nss x
x = în cazul populaţiei infinite;
Estimatorul punctual al proporţiei populaţiei p este proporţia la nivel de eşantion p .

16
Exemplul 9 Datele următoare corespund unui eşantion de 8 angajaţi ai unei companii studiaţi în raport cu salariul lunar exprimat în mii RON. 6, 8, 10, 7, 10, 12, 14, 5. Pe de altă parte se ştie că 2 din cei 8 angajaţi au urmat un curs de calificare. Să se estimeze punctual:
1. media populaţiei; 2. abaterea medie pătratică a populaţiei; 3. eroarea standard a mediei; 4. proporţia populaţiei.
Estimarea parametrilor prin intervale de încredere
Intervalul (λ1,λ2) se numeşte interval de încredere pentru parametrul necunoscut λ dacă P(λ1< λ < λ2)= 1–α, unde (1–α) se numeşte coeficient (nivel) de încredere iar α se numeşte coeficient (nivel) de semnificaţie.
Dacă λ̂ este un estimator punctual al parametrului necunoscut λ atunci intervalul de încredere pentru parametrul λ va avea forma:
λ̂ ± (eroarea de eşantion)
Interval de încredere pentru valoarea medie
x ± (eroarea de eşantion)
Cazul eşantioanelor de volum mare (n≥30)
Dacă se cunoaşte dispersia populaţiei atunci:
( )x2zx σμ α±∈
nx
σσ =
Dacă nu se cunoaşte dispersia populaţiei atunci:
( )x2 szx αμ ±∈
ns
s xx =

17
Nivel de semnificaţieα
Nivel de încredere1–α
P(0< z < 2zα ) 2zα
0,1 0,90 0,45 1,65 0,05 0,95 0,475 1,96 0,01 0,99 0,495 2,58
Exemplul 10 Pentru a estima costul mediu al cazării/noapte într-o anumită staţiune este studiat un eşantion de 64 de turişti. Datele obţinute au arătat un cost mediu de 32 euro.
1. Presupunând că abaterea medie pătratică la nivel de populaţie este σ=2,4 euro determinaţi un interval de încredere pentru valoarea medie cu un coeficient de încredere de 0,95.
2. Presupunând că nu se cunoaşte dispersia populaţiei dar că eşantionul a furnizat o dispersie 2xs =4, determinaţi un interval de încredere pentru valoarea medie cu un coeficient de
încredere de 0,95.
Cazul eşantioanelor de volum mic (n< 30)
( )( )xgl1n;2 stx −±∈ αμ , n
ss x
x =
Exemplul 11 Să se determine un interval de încredere pentru salarul mediu al angajaţilor companiei de la Exemplul 9 cu un nivel de încredere de 0,95. Interval de încredere pentru estimarea diferenţei a două valori medii
Cazul eşantioanelor independente
o Eşantioane independente de volum mare (n1≥ 30, n2≥ 30)

18
( )21 xx22121 zxx
−±−∈− σμμ α ,
2
22
1
21
xx nn21
σσσ +=− .
Dacă nu se cunosc dispersiile populaţiilor atunci acestea se înlocuiesc cu estimatorii lor punctuali şi anume dispersiile de eşantion 2
221 s,s , iar
21 xx −σ se înlocuieşte cu estimatorul său punctual
2
22
1
21
xx ns
ns
s21
+=−
. Astfel în acest caz intervalul va avea următoarea formă:
( )21 xx22121 szxx
−±−∈− αμμ .
Exemplul 12 Se consideră două populaţii originare studiate în raport cu aceeaşi variabilă. Din prima populaţie se extrage
un eşantion de volum n1=50 ce a furnizat o valoare medie 1x =15 cu o abatere medie s1=4. Din cea de a
doua populaţia s-a extras un eşantion de volum n2=75 ce a furnizat o medie 2x =12 cu o abatere medie s2=3. Cu un nivel de încredere de 95% să se determine un interval de încredere pentru diferenţa valorilor medii ale celor două populaţii.
o Cazul eşantioanelor de volum mic (n1< 30, n2< 30)
( )21 xxgl;22121 stxx
−±−∈− αμμ ,
21
xx n1
n1ss
21+=
−,
( ) ( )( )2nn
s1ns1ns
21
222
2112
−+−+−
= .
Exemplul 13 Din două populaţii originare având dispersii egale s-au extras următoarele două eşantioane: 2, 5, 5, 3, 4, 7, 4, 2, 5, 3; 2, 4, 5, 3, 1, 2, 3, 4. Cu un nivel de încredere de 95% să se determine un interval de încredere pentru diferenţa mediilor celor două populaţii.

19
Cazul eşantioanelor perechi
( )d2d szd αμ ±∈ , d=x1 – x2,
Valoarea medie:nd
d i∑= , i2
i1i xxd −=
Dispersia:( )
1ndd
s2
i2d −
−= ∑ ;
Abaterea medie pătratică 2dd ss = ;
Eroarea standard n
ss d
d = .
Exemplul 14 Datele de mai jos reprezintă timpii realizaţi de o echipă ce asamblează manual anumite produse de artizanat înainte şi după parcurgerea unui stagiu de pregătire:
Muncitor Înainte de stagiu După stagiu1 10 8 2 10 7 3 8 7 4 9 9 5 7 6 6 8 7 7 9 8 8 6 5 9 8 5
10 9 6 Să se estimeze diferenţa dintre performanţele muncitorilor înainte şi după parcurgerea stagiului de pregătire, cu un nivel de încredere de 95%.
Verificarea ipotezelor statistice
Teste de semnificaţie
Fie λ un parametru necunoscut al unei populaţii. O ipoteză formulată asupra acestui parametru se
va numi ipoteză nulă Ho.
20
Ho: λ=λo O altă ipoteză ce se formulează este ipoteza alternativă H1 ce poate avea următoarea formă: H1: λ≠λo – test bilateral; H1: λ>λo – test unilateral la dreapta; H1: λ<λo – test unilateral la stânga.
Etapele derulării unui test de semnificaţie
1. Formularea ipotezei nule şi a ipotezei alternative
Test bilateral Teste unilaterale Ho: λ=λo Ho: λ=λo Ho: λ=λo H1: λ≠λo H1: λ>λo H1: λ< λo
2. Determinarea nivelului de semnificaţie α - probabilitatea comiterii unei erori prin
respingerea ipotezei nule datorită erorii de eşantionare, în cazul în care aceasta este de fapt adevărată;
3. Colectarea datelor la nivel de eşantion, alegerea şi calcularea statisticii test ce va fi folosită pentru a decide acceptarea sau respingerea ipotezei nule;
4. Determinarea valorilor critice ale statisticii; 5. Luarea deciziei.
Figura 12.2.1. Zonele de respingere şi de acceptare ale ipotezei nule
Test bilateral
Test unilateral la dreapta
Zonă de acceptare
valoarea critică
Zonă de respingere
Zonă de acceptare
valoarea critică valoarea critică
Zonă de respingere
Zonă de respingere
21
Test unilateral la stânga
Verificarea ipotezelor asupra valorii medii μ Test bilateral Test unilateral
Formularea ipotezelor Ho: μ=μo; H1: μ≠μo
Formularea ipotezelor Ho: μ=μo; H1: μ>μo Ho: μ=μo; H1: μ<μo
Determinarea nivelului de semnificaţie α Determinarea nivelului de semnificaţie α Colectarea datelor la nivel de eşantion, alegerea şi calcularea statisticii:
a. z=x
oxσμ−
sau z=x
o
sx μ−
b. t=x
o
sx μ−
Colectarea datelor la nivel de eşantion, alegerea şi calcularea statisticii:
a. z=x
oxσμ−
sau z=x
o
sx μ−
b. t=x
o
sx μ−
Determinarea valorilor critice Determinarea valorilor critice a. 2zα±
b. ( )gl1n;2t −± α
a. αz
b. ( )gl1n;t −α
a. - αz
b. - ( )gl1n;t −α
Luarea deciziei Luarea deciziei Dacă valorile calculate ale statisticilor se află între valorile critice atunci ipoteza nulă nu poate fi respinsă în caz contrar aceasta se respinge
Dacă valorile calculate sunt mai mici decât cele critice ipoteza nulă nu poate fi respinsă.
Dacă valorile calculate sunt mai mari decât cele critice ipoteza nulă nu poate fi respinsă.
Exemplul 15 Un producător de baterii oferă o garanţie de 20 de zile. Un eşantion de 100 de baterii a furnizat o medie de 19,5 zile cu o abatere medie de două zile. Cu un nivel de semnificaţie α=0,05 verificaţi dacă garanţia oferită este corectă.
Zonă de acceptare
valoarea critică
Zonă de respingere

22
Exemplul 16 Se studiază timpul de aşteptare între două autobuze. Un eşantion de volum n=10 a oferit următorii timpi exprimaţi în minute:
2, 5, 5, 3, 4, 7, 4, 2, 5, 3; Să se verifice ipoteza că timpul mediu de aşteptare este de 3 minute cu α=0,05.
Verificarea ipotezelor asupra diferenţei valorilor medii μ1-μ2 Eşantioane independente
Test bilateral Test unilateral Formularea ipotezelor
Ho: μ1-μ2=0; H1: μ1-μ2≠0 Formularea ipotezelor
Ho: μ1-μ2=0; H1: μ1-μ2 >0 Ho: μ1-μ2=0; H1: μ1-μ2<0
Determinarea nivelului de semnificaţie α Determinarea nivelului de semnificaţie α Colectarea datelor la nivel de eşantion, alegerea şi calcularea statisticii
Colectarea datelor la nivel de eşantion, alegerea şi calcularea statisticii
n1≥30, n2≥30 n1≥30, n2≥30
z=( ) ( )
21 xx
2121
sxx
−
−−− μμ,
2
22
1
21
xx ns
ns
s21
+=−
z=( ) ( )
21 xx
2121
sxx
−
−−− μμ,
2
22
1
21
xx ns
ns
s21
+=−
n1<30, n2<30 ( 222
21 σσσ == ) n1<30, n2<30 ( 22
221 σσσ == )
t=( ) ( )
21 xx
2121
sxx
−
−−− μμ
21xx n
1n1ss
21+=−
,
( ) ( )( )2nn
s1ns1ns21
222
2112
−+−+−
=
t=( ) ( )
21 xx
2121
sxx
−
−−− μμ
21xx n
1n1ss
21+=−
,
( ) ( )( )2nn
s1ns1ns21
222
2112
−+−+−
=
Determinarea valorilor critice Determinarea valorilor critice

23
n1≥30, n2≥30 ⇒ 2zα± n1≥30, n2≥30 ⇒ zα sau - zα
n1<30, n2<30 ⇒ gl)2nn(;2 21t −+± α n1<30, n2<30 ⇒ gl)2nn(; 21
t −+α sau
gl)2nn(; 21t −+− α
Luarea deciziei Luarea deciziei Dacă valorile calculate ale statisticilor se află între valorile critice atunci ipoteza nulă se acceptă în caz contrar aceasta se respinge
Dacă valorile calculate sunt mai mici decât cele critice ipoteza nulă se acceptă.
Dacă valorile calculate sunt mai mari decât cele critice ipoteza nulă se acceptă.
Eşantioane perechi Test bilateral Test unilateral
Formularea ipotezelor Ho: μd=0; H1: μd ≠0
Formularea ipotezelor Ho: μd=0; H1: μd>0 Ho: μd=0; H1: μd<0
Determinarea nivelului de semnificaţie α Determinarea nivelului de semnificaţie α Colectarea datelor la nivel de eşantion, alegerea şi calcularea statisticii
Colectarea datelor la nivel de eşantion, alegerea şi calcularea statisticii
n≥30 n≥30
z=d
d
sd μ−
, n
ss dd = z=
d
d
sd μ−
, n
ss dd =
n<30 n<30
t=d
d
sd μ−
, n
ss dd = t=
d
d
sd μ−
, n
ss dd =
Determinarea valorilor critice Determinarea valorilor critice n≥30 ⇒ 2zα± n≥30 ⇒ zα sau - zα
n<30 ⇒ gl)1n(;2t −± α n<30 ⇒ gl)1n(;t −α sau gl)1n(;t −− α Luarea deciziei Luarea deciziei
Dacă valorile calculate ale statisticilor se află între valorile critice atunci ipoteza nulă se acceptă în caz contrar aceasta se respinge
Dacă valorile calculate sunt mai mici decât cele critice ipoteza nulă se acceptă.
Dacă valorile calculate sunt mai mari decât cele critice ipoteza nulă se acceptă.
Exemplul 17 Se iniţiază un studiu în scopul de a estima diferenţa de vârstă dintre angajaţii a două compartimente ale unei companii. În primul compartiment s-a extras un eşantion de volum n1=36 care a furnizat o vârstă
medie 1x =40 ani cu o abatere medie de s1=9 ani. Din cel de al doilea compartiment se extrage un
eşantion de volum n2=49 care a furnizat o vârstă medie 2x =35 ani cu o abatere medie s2=10 ani. Cu un nivel de semnificaţie α=0,05 verificaţi dacă:
1. vârstele medii în cele două compartimente diferă semnificativ; 2. este mai mare media de vârstă din primul compartiment.

24
Exemplul 18 Se consideră următoarele două eşantioane extrase din două populaţii ce au aceeaşi dispersie:
Eşantion 1 Eşantion 2n1=15 n2=10
1x =8 2x =6 s1=2 s2=1
Cu un nivel de semnificaţie α=0,05 verificaţi dacă: 1. mediile celor două populaţii diferă semnificativ; 2. este mai mare media primei populaţii.
Exemplul 19 O companie deţine cinci magazine de desfacere a produselor proprii. Compania a lansat pe piaţă un nou produs şi a urmărit vânzările în prima săptămână de după lansare. Valorile înregistrate în cele cinci magazine au fost: 25, 28, 20, 23, 29. Companie recurge la o campanie promoţională. După lansarea campaniei situaţia vânzărilor în cele cinci magazine a fost: 28, 30, 25, 25, 32. Cu α=0,05 verificaţi dacă a avut efect asupra vânzărilor campania promoţională.

25
Analiza varianţei (ANOVA)
Etapele unei analize de tip ANOVA
1. Formularea ipotezelor; Ho: μ1=μ2=...=μk;
H1: nu toate mediile sunt egale. 2. Stabilirea nivelului de semnificaţie α; 3. Calculul elementelor necesare determinării valorii statisticii test
3.1. Calculul mediei şi dispersiei fiecărui eşantion k,1i,s,x 2ii = ;
3.2. Calculul valorii medii totale x ;
3.3. Calcul varianţei între grupuri
( )1k
xxns
k
1i
2
ii2b −
−=∑= ;
3.4. Calculul varianţei în grupuri 2ws =
( )
( ) kn...n
s1n
k1
k
1i
2ii
−++
−∑= =
( )
kn
s1nk
1i
2ii
−
−∑=
Tabelul ANOVA Tabelul ANOVA este un tabel în care se trec toate elementele calculate la punctul acesta având următoarea structură: Sursa Suma pătratelor Grade de libertate Media sumelor pătratelor
Între grupuri SSB k – 1 ( )1kSSBs 2b −=
În grupuri SSW n – k ( )knSSWs2w −=
Total SST=SSB+SSW n – 1 4. Calcularea statisticii test F;

26
F =( )
( )knSSW
1kSSB
−
−= 2
w
2b
ss
.
5. Determinarea valorilor critice Fα; (k-1, n-k)gl; 6. Luarea deciziei: dacă F> Fα; (k-1, n-k)gl ipoteza nulă se respinge în caz contrar aceasta acceptându-
se. Exemplul 20
Se iniţiază un studiu pentru a compara venitul mediu al populaţiilor din două zone diferite ale unei ţări. Pentru aceasta din fiecare zonă este extras câte un eşantion de volum n=5, datele obţinute fiind următoarele:
Venitul Zona 1 Zona 2 Zona 3
7,2 6 5 8 7,5 4,2
6,3 6,4 5,3 5,4 7 6 7 8,6 4,8
27
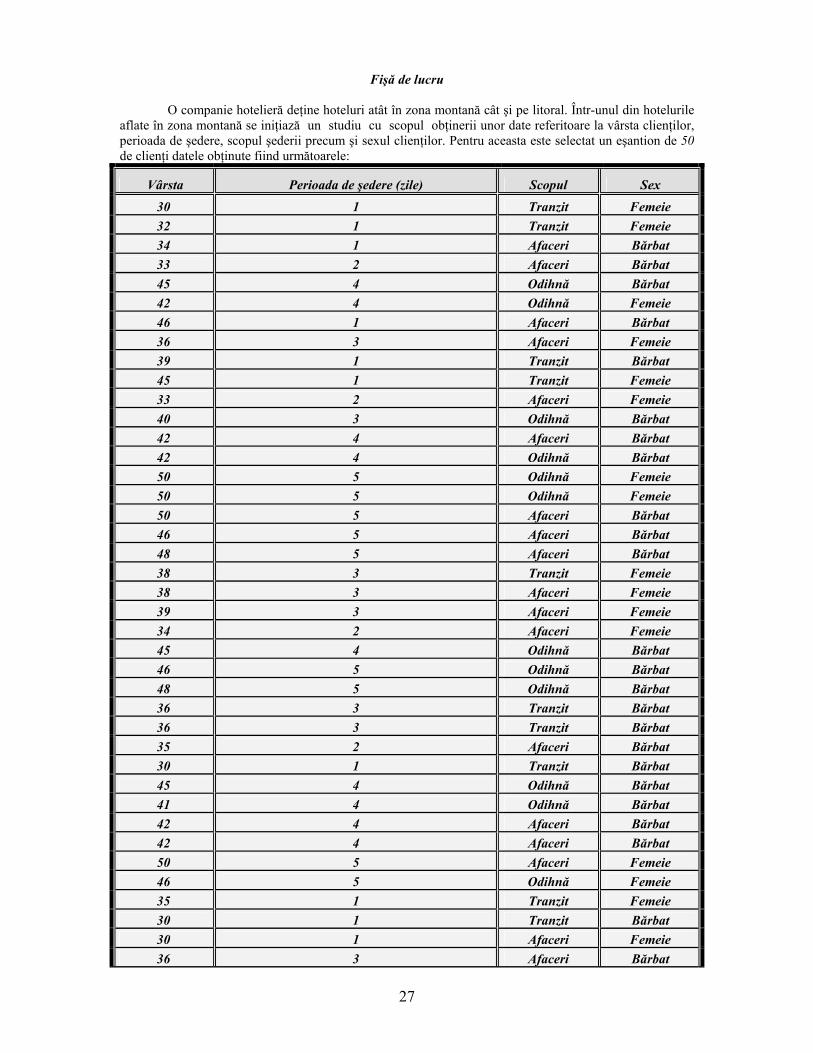
Fişă de lucru
O companie hotelieră deţine hoteluri atât în zona montană cât şi pe litoral. Într-unul din hotelurile aflate în zona montană se iniţiază un studiu cu scopul obţinerii unor date referitoare la vârsta clienţilor, perioada de şedere, scopul şederii precum şi sexul clienţilor. Pentru aceasta este selectat un eşantion de 50 de clienţi datele obţinute fiind următoarele:
Vârsta Perioada de şedere (zile) Scopul Sex
30 1 Tranzit Femeie 32 1 Tranzit Femeie 34 1 Afaceri Bărbat 33 2 Afaceri Bărbat 45 4 Odihnă Bărbat 42 4 Odihnă Femeie 46 1 Afaceri Bărbat 36 3 Afaceri Femeie 39 1 Tranzit Bărbat 45 1 Tranzit Femeie 33 2 Afaceri Femeie 40 3 Odihnă Bărbat 42 4 Afaceri Bărbat 42 4 Odihnă Bărbat 50 5 Odihnă Femeie 50 5 Odihnă Femeie 50 5 Afaceri Bărbat 46 5 Afaceri Bărbat 48 5 Afaceri Bărbat 38 3 Tranzit Femeie 38 3 Afaceri Femeie 39 3 Afaceri Femeie 34 2 Afaceri Femeie 45 4 Odihnă Bărbat 46 5 Odihnă Bărbat 48 5 Odihnă Bărbat 36 3 Tranzit Bărbat 36 3 Tranzit Bărbat 35 2 Afaceri Bărbat 30 1 Tranzit Bărbat 45 4 Odihnă Bărbat 41 4 Odihnă Bărbat 42 4 Afaceri Bărbat 42 4 Afaceri Bărbat 50 5 Afaceri Femeie 46 5 Odihnă Femeie 35 1 Tranzit Femeie 30 1 Tranzit Bărbat 30 1 Afaceri Femeie 36 3 Afaceri Bărbat
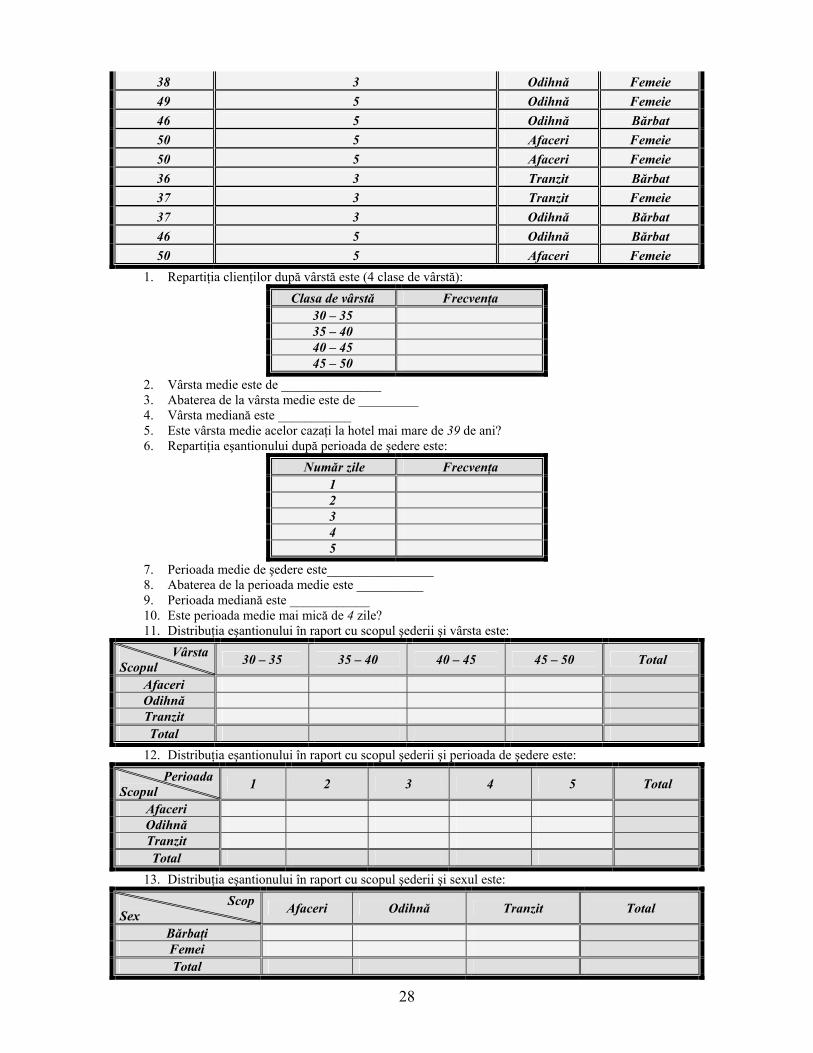
28
38 3 Odihnă Femeie 49 5 Odihnă Femeie 46 5 Odihnă Bărbat 50 5 Afaceri Femeie 50 5 Afaceri Femeie 36 3 Tranzit Bărbat 37 3 Tranzit Femeie 37 3 Odihnă Bărbat 46 5 Odihnă Bărbat 50 5 Afaceri Femeie
1. Repartiţia clienţilor după vârstă este (4 clase de vârstă): Clasa de vârstă Frecvenţa
30 – 35 35 – 40 40 – 45 45 – 50
2. Vârsta medie este de _______________ 3. Abaterea de la vârsta medie este de _________ 4. Vârsta mediană este ___________ 5. Este vârsta medie acelor cazaţi la hotel mai mare de 39 de ani? 6. Repartiţia eşantionului după perioada de şedere este:
Număr zile Frecvenţa 1 2 3 4 5
7. Perioada medie de şedere este________________ 8. Abaterea de la perioada medie este __________ 9. Perioada mediană este ____________ 10. Este perioada medie mai mică de 4 zile? 11. Distribuţia eşantionului în raport cu scopul şederii şi vârsta este:
Vârsta Scopul 30 – 35 35 – 40 40 – 45 45 – 50 Total
Afaceri Odihnă Tranzit Total
12. Distribuţia eşantionului în raport cu scopul şederii şi perioada de şedere este: Perioada
Scopul 1 2 3 4 5 Total
Afaceri Odihnă Tranzit Total
13. Distribuţia eşantionului în raport cu scopul şederii şi sexul este: Scop
Sex Afaceri Odihnă Tranzit Total
Bărbaţi Femei Total
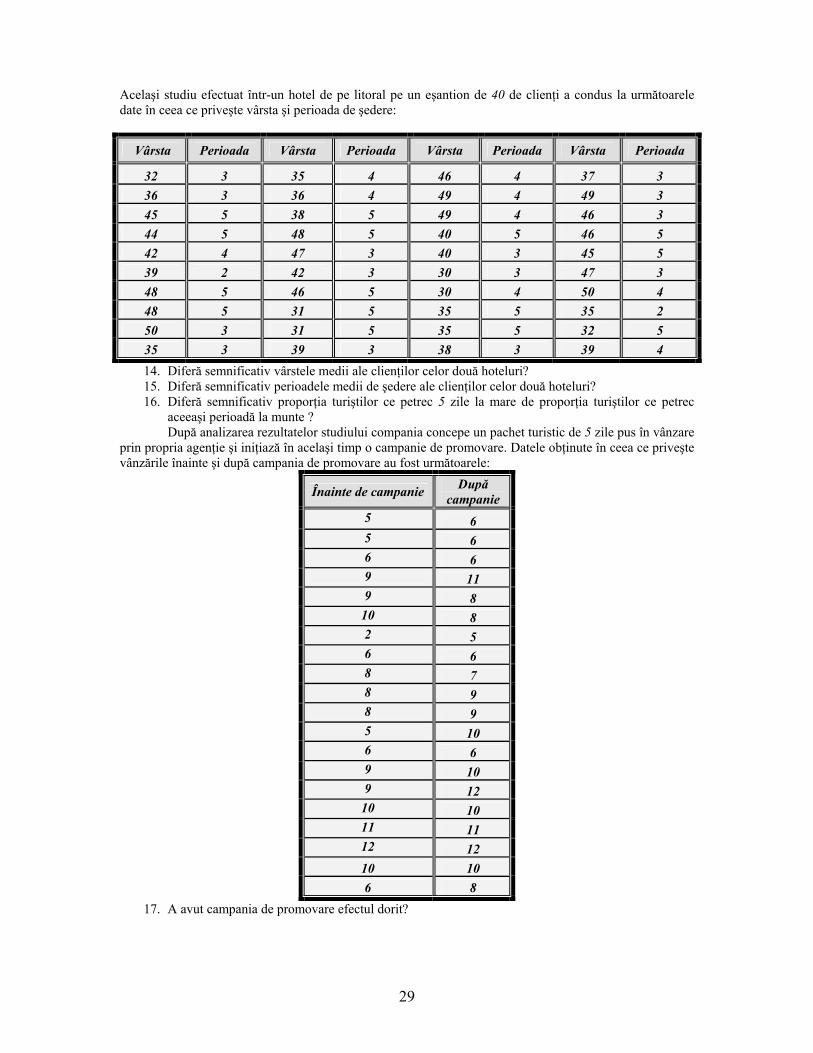
29
Acelaşi studiu efectuat într-un hotel de pe litoral pe un eşantion de 40 de clienţi a condus la următoarele date în ceea ce priveşte vârsta şi perioada de şedere:
Vârsta Perioada Vârsta Perioada Vârsta Perioada Vârsta Perioada
32 3 35 4 46 4 37 3 36 3 36 4 49 4 49 3 45 5 38 5 49 4 46 3 44 5 48 5 40 5 46 5 42 4 47 3 40 3 45 5 39 2 42 3 30 3 47 3 48 5 46 5 30 4 50 4 48 5 31 5 35 5 35 2 50 3 31 5 35 5 32 5 35 3 39 3 38 3 39 4 14. Diferă semnificativ vârstele medii ale clienţilor celor două hoteluri? 15. Diferă semnificativ perioadele medii de şedere ale clienţilor celor două hoteluri? 16. Diferă semnificativ proporţia turiştilor ce petrec 5 zile la mare de proporţia turiştilor ce petrec
aceeaşi perioadă la munte ? După analizarea rezultatelor studiului compania concepe un pachet turistic de 5 zile pus în vânzare
prin propria agenţie şi iniţiază în acelaşi timp o campanie de promovare. Datele obţinute în ceea ce priveşte vânzările înainte şi după campania de promovare au fost următoarele:
Înainte de campanie După campanie
5 6 5 6 6 6 9 11 9 8
10 8 2 5 6 6 8 7 8 9 8 9 5 10 6 6 9 10 9 12
10 10 11 11 12 12 10 10 6 8
17. A avut campania de promovare efectul dorit?
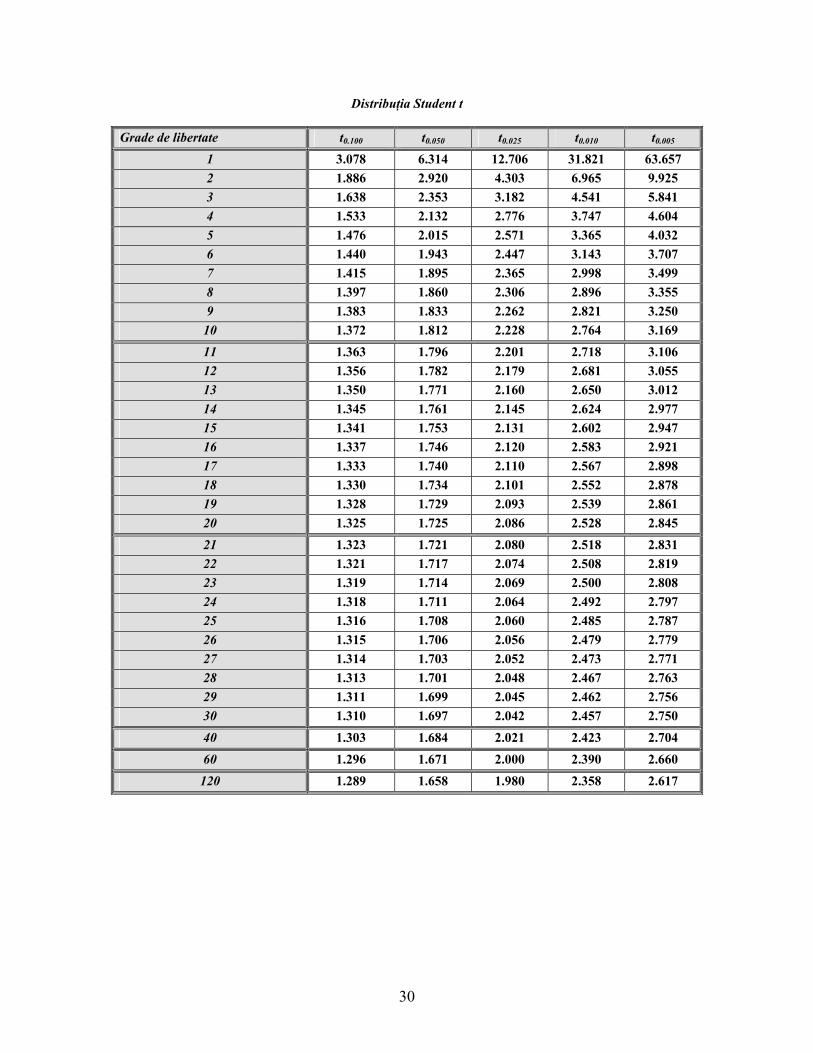
30
Distribuţia Student t Grade de libertate t0.100 t0.050 t0.025 t0.010 t0.005
1 3.078 6.314 12.706 31.821 63.657 2 1.886 2.920 4.303 6.965 9.925 3 1.638 2.353 3.182 4.541 5.841 4 1.533 2.132 2.776 3.747 4.604 5 1.476 2.015 2.571 3.365 4.032 6 1.440 1.943 2.447 3.143 3.707 7 1.415 1.895 2.365 2.998 3.499 8 1.397 1.860 2.306 2.896 3.355 9 1.383 1.833 2.262 2.821 3.250
10 1.372 1.812 2.228 2.764 3.169 11 1.363 1.796 2.201 2.718 3.106 12 1.356 1.782 2.179 2.681 3.055 13 1.350 1.771 2.160 2.650 3.012 14 1.345 1.761 2.145 2.624 2.977 15 1.341 1.753 2.131 2.602 2.947 16 1.337 1.746 2.120 2.583 2.921 17 1.333 1.740 2.110 2.567 2.898 18 1.330 1.734 2.101 2.552 2.878 19 1.328 1.729 2.093 2.539 2.861 20 1.325 1.725 2.086 2.528 2.845 21 1.323 1.721 2.080 2.518 2.831 22 1.321 1.717 2.074 2.508 2.819 23 1.319 1.714 2.069 2.500 2.808 24 1.318 1.711 2.064 2.492 2.797 25 1.316 1.708 2.060 2.485 2.787 26 1.315 1.706 2.056 2.479 2.779 27 1.314 1.703 2.052 2.473 2.771 28 1.313 1.701 2.048 2.467 2.763 29 1.311 1.699 2.045 2.462 2.756 30 1.310 1.697 2.042 2.457 2.750 40 1.303 1.684 2.021 2.423 2.704 60 1.296 1.671 2.000 2.390 2.660 120 1.289 1.658 1.980 2.358 2.617
31
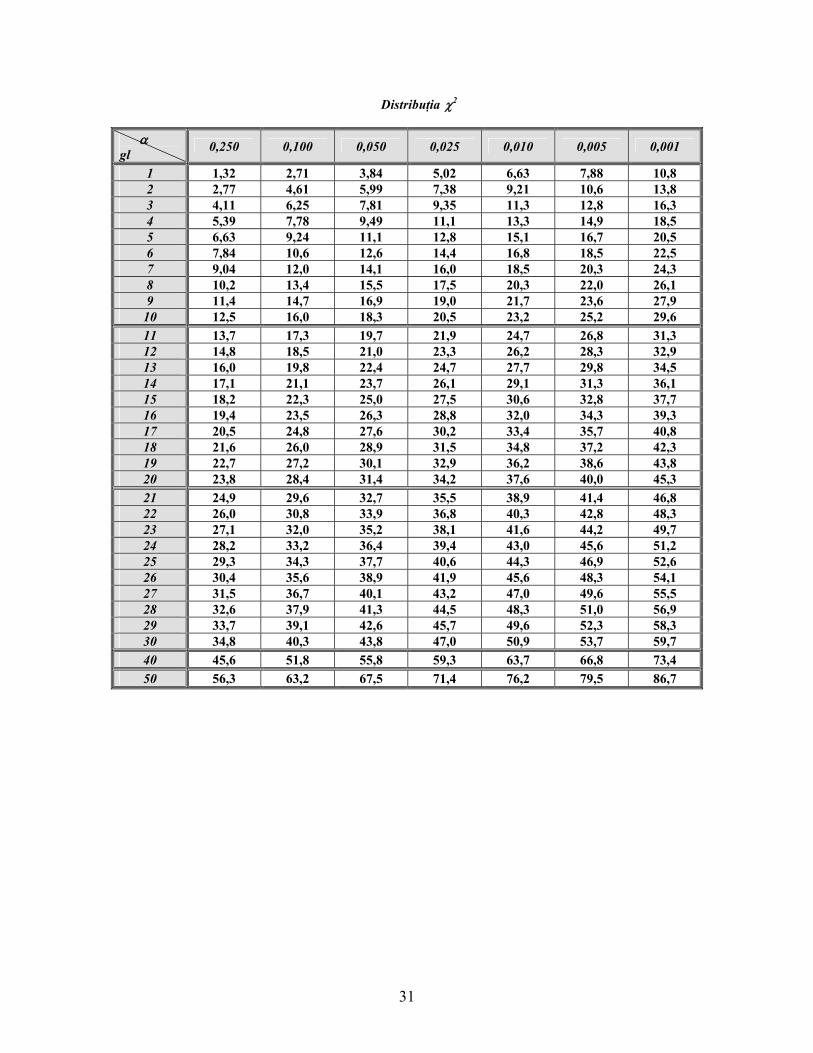
Distribuţia χ2
α gl 0,250 0,100 0,050 0,025 0,010 0,005 0,001
1 1,32 2,71 3,84 5,02 6,63 7,88 10,8 2 2,77 4,61 5,99 7,38 9,21 10,6 13,8 3 4,11 6,25 7,81 9,35 11,3 12,8 16,3 4 5,39 7,78 9,49 11,1 13,3 14,9 18,5 5 6,63 9,24 11,1 12,8 15,1 16,7 20,5 6 7,84 10,6 12,6 14,4 16,8 18,5 22,5 7 9,04 12,0 14,1 16,0 18,5 20,3 24,3 8 10,2 13,4 15,5 17,5 20,3 22,0 26,1 9 11,4 14,7 16,9 19,0 21,7 23,6 27,9
10 12,5 16,0 18,3 20,5 23,2 25,2 29,6 11 13,7 17,3 19,7 21,9 24,7 26,8 31,3 12 14,8 18,5 21,0 23,3 26,2 28,3 32,9 13 16,0 19,8 22,4 24,7 27,7 29,8 34,5 14 17,1 21,1 23,7 26,1 29,1 31,3 36,1 15 18,2 22,3 25,0 27,5 30,6 32,8 37,7 16 19,4 23,5 26,3 28,8 32,0 34,3 39,3 17 20,5 24,8 27,6 30,2 33,4 35,7 40,8 18 21,6 26,0 28,9 31,5 34,8 37,2 42,3 19 22,7 27,2 30,1 32,9 36,2 38,6 43,8 20 23,8 28,4 31,4 34,2 37,6 40,0 45,3 21 24,9 29,6 32,7 35,5 38,9 41,4 46,8 22 26,0 30,8 33,9 36,8 40,3 42,8 48,3 23 27,1 32,0 35,2 38,1 41,6 44,2 49,7 24 28,2 33,2 36,4 39,4 43,0 45,6 51,2 25 29,3 34,3 37,7 40,6 44,3 46,9 52,6 26 30,4 35,6 38,9 41,9 45,6 48,3 54,1 27 31,5 36,7 40,1 43,2 47,0 49,6 55,5 28 32,6 37,9 41,3 44,5 48,3 51,0 56,9 29 33,7 39,1 42,6 45,7 49,6 52,3 58,3 30 34,8 40,3 43,8 47,0 50,9 53,7 59,7 40 45,6 51,8 55,8 59,3 63,7 66,8 73,4 50 56,3 63,2 67,5 71,4 76,2 79,5 86,7
32
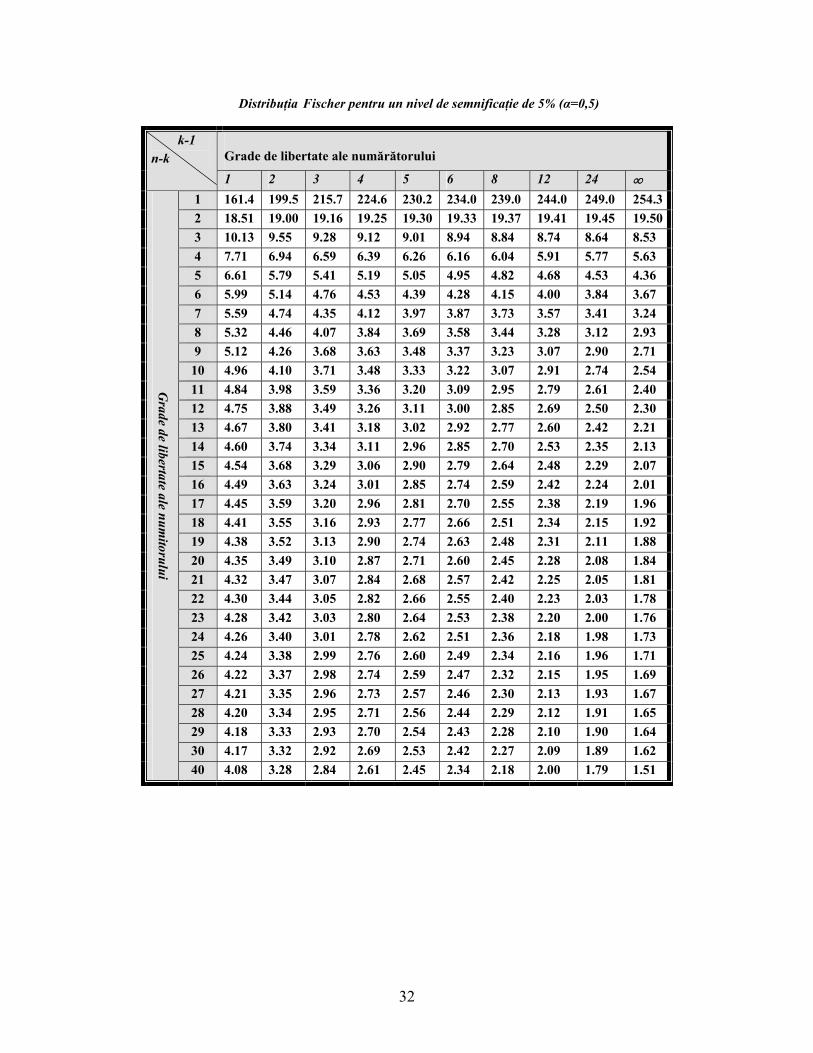
Distribuţia Fischer pentru un nivel de semnificaţie de 5% (α=0,5)
Grade de libertate ale numărătorului k-1
n-k 1 2 3 4 5 6 8 12 24 ∞
1 161.4 199.5 215.7 224.6 230.2 234.0 239.0 244.0 249.0 254.32 18.51 19.00 19.16 19.25 19.30 19.33 19.37 19.41 19.45 19.503 10.13 9.55 9.28 9.12 9.01 8.94 8.84 8.74 8.64 8.53 4 7.71 6.94 6.59 6.39 6.26 6.16 6.04 5.91 5.77 5.63 5 6.61 5.79 5.41 5.19 5.05 4.95 4.82 4.68 4.53 4.36 6 5.99 5.14 4.76 4.53 4.39 4.28 4.15 4.00 3.84 3.67 7 5.59 4.74 4.35 4.12 3.97 3.87 3.73 3.57 3.41 3.24 8 5.32 4.46 4.07 3.84 3.69 3.58 3.44 3.28 3.12 2.93 9 5.12 4.26 3.68 3.63 3.48 3.37 3.23 3.07 2.90 2.71
10 4.96 4.10 3.71 3.48 3.33 3.22 3.07 2.91 2.74 2.54 11 4.84 3.98 3.59 3.36 3.20 3.09 2.95 2.79 2.61 2.40 12 4.75 3.88 3.49 3.26 3.11 3.00 2.85 2.69 2.50 2.30 13 4.67 3.80 3.41 3.18 3.02 2.92 2.77 2.60 2.42 2.21 14 4.60 3.74 3.34 3.11 2.96 2.85 2.70 2.53 2.35 2.13 15 4.54 3.68 3.29 3.06 2.90 2.79 2.64 2.48 2.29 2.07 16 4.49 3.63 3.24 3.01 2.85 2.74 2.59 2.42 2.24 2.01 17 4.45 3.59 3.20 2.96 2.81 2.70 2.55 2.38 2.19 1.96 18 4.41 3.55 3.16 2.93 2.77 2.66 2.51 2.34 2.15 1.92 19 4.38 3.52 3.13 2.90 2.74 2.63 2.48 2.31 2.11 1.88 20 4.35 3.49 3.10 2.87 2.71 2.60 2.45 2.28 2.08 1.84 21 4.32 3.47 3.07 2.84 2.68 2.57 2.42 2.25 2.05 1.81 22 4.30 3.44 3.05 2.82 2.66 2.55 2.40 2.23 2.03 1.78 23 4.28 3.42 3.03 2.80 2.64 2.53 2.38 2.20 2.00 1.76 24 4.26 3.40 3.01 2.78 2.62 2.51 2.36 2.18 1.98 1.73 25 4.24 3.38 2.99 2.76 2.60 2.49 2.34 2.16 1.96 1.71 26 4.22 3.37 2.98 2.74 2.59 2.47 2.32 2.15 1.95 1.69 27 4.21 3.35 2.96 2.73 2.57 2.46 2.30 2.13 1.93 1.67 28 4.20 3.34 2.95 2.71 2.56 2.44 2.29 2.12 1.91 1.65 29 4.18 3.33 2.93 2.70 2.54 2.43 2.28 2.10 1.90 1.64 30 4.17 3.32 2.92 2.69 2.53 2.42 2.27 2.09 1.89 1.62
Grade de libertate ale num
itorului
40 4.08 3.28 2.84 2.61 2.45 2.34 2.18 2.00 1.79 1.51







