84
m n lege lege 100 × 10 N (5, 0.2) 200 × 50 P (0.01) 10000 μ =2 σ =0.5 L
| Date post: | 26-Nov-2015 |
| Category: |
Documents |
| Upload: | cipriana-paduraru |
| View: | 49 times |
| Download: | 3 times |

1 Statistic Aplicat (L1 & S1)
Experimente aleatoare în Matlab
Generarea de numere (pseudo-)aleatoare
Vorbim de numere pseudo-aleatoare deoarece numerele generate de Matlab sunt rezultatul compil riiunui program deja existent în Matlab, ³i de aceea ele nu pot � aleatoare în sensul strict al cuvântului.Îns , putem face abstracµie de modul programat de generare ale acestor numere ³i s consider m c aces-tea sunt numere aleatoare.
Generarea de numere aleatoare de o repartiµie dat
Comenzile Matlab pentru generarea de numere aleatoare ce urmeaz repartiµia notat generic lege sunt:
legernd(<param>, m, n)
sau, alternativ,
random('lege', <param>, m, n).
Oricare dintre cele dou comenzi genereaz o matrice aleatoare, cu m linii ³i n coloane, având componentenumere aleatoare ce urmeaz repartiµia lege. În loc de lege putem scrie oricare dintre expresiile din tabeluldin Tabelul 1.1. De exemplu,
normrnd (5, 0.2, 100, 10);
genereaz o matrice aleatoare cu 100× 10 componente repartizate N (5, 0.2).
random ('poiss',0.01, 200, 50);
genereaz o matrice aleatoare cu 200× 50 componente repartizate P(0.01).
Utilizând comanda
randtool
putem reprezenta interactiv selecµii aleatoare pentru diverse repartiµii. Comanda deschide o interfaµ gra�c ce reprezint prin histograme selecµiile dorite, pentru parametrii doriµi (vezi Figura 1.1). Datelegenerate deMatlab pot � exportate în �³ierul Workspace cu numele dorit. De exemplu, folosind dateledin Figura 1.1, am generat o selecµie aleatoare de 10000 de numere ce urmeaz repartiµia lognormal deparametri µ = 2 ³i σ = 0.5 ³i am salvat-o (folosind butonul Export) într-un vector L.
1

Figura 1.1: Interfaµ pentru generarea de numere aleatoare de o repartiµie dat .
repartiµii probabilistice discrete repartiµii probabilistice continue
norm: repartiµia normal N (µ, σ)bino: repartiµia binomial B(n, p) unif: repartiµia uniform continu U(a, b)nbin: repartiµia binomial negativ BN(n, p) exp: repartiµia exponenµial exp(λ)poiss: repartiµia Poisson P(λ) gam: repartiµia Gamma Γ(a, λ)unid: repartiµia uniform discret U(n) beta: repartiµia Beta β(m,n)geo: repartiµia geometric Geo(p) logn: repartiµia lognormal logN (µ, σ)hyge: repartiµia hipergeometric H(n, a, b) chi2: repartiµia χ2(n)
t: repartiµia student t(n)f: repartiµia Fisher F(m, n)
wbl: repartiµia Weibull Wbl(k, λ)
Tabela 1.1: Repartiµii uzuale în Matlab
Repartiµiile uniform continu ³i normal mai pot � simulate în Matlab folosind ³i alte seturi de funcµii,mai simplu de utilizat. Aceasta se datoreaz faptului c ele sunt cele mai des utilizate în simularea de datealeatoare. Dup cum vom vedea mai târziu, putem genera valori aleatoare de o repartiµie dat plecândde la repartiµia uniform continu .
2

Generarea de numere uniform repartizate într-un interval, U(a, b)
Funcµia rand
• Funcµia rand genereaz un num r aleator repartizat uniform în [0, 1].De exemplu, comanda
X = (rand < 0.5)
simuleaz aruncarea unei monede ideale. Mai putem spune ca num rul X astfel generat este unnum r aleator repartizat B(1, 0.5).
• De asemenea, num rul
Y = sum(rand(10,1) < 0.5)
urmeaz repartiµia B(10, 0.5) (simularea a 10 arunc ri ale unei monede ideale).
• rand(m, n) genereaz o matrice aleatoare cu m× n componente repartizate U(0, 1).
• Comanda a+ (b− a) ∗ rand genereaz un num r pseudo-aleator repartizat uniform în [a, b].
• Folosind comanda s = rand('state'), i se atribuie variabilei s un vector de 35 de elemente, repre-zentând starea actual a generatorului de numere aleatoare uniform (distribuite). Pentru a schimbastarea curent a generatorului sau iniµializarea lui, putem folosi comanda
rand(method, s)
unde method este metoda prin care numerele aleatoare sunt generate (aceasta poate � 'state','seed' sau 'twister'), iar s este un num r natural între 0 ³i 232 − 1, reprezentând starea iniµiali-zatorului. De exemplu,
rand('state', 125)
�xeaz generatorul la starea 125.
Observaµia 1.1 Printr-o generare de numere aleatoare uniform distribuite în intervalul (a, b) înµelegemnumere aleatoare care au aceea³i ³ans de a � oriunde în (a, b), ³i nu numere la intervale egale.
Figura 1.2 reprezint cu histograme date uniform distribuite în intervalul [−2, 3], produse de comandaMatlab:
hist(5*rand(1e4,1)-2,100)
3

Figura 1.2: Reprezentarea cu histograme a datelor uniforme.
Generarea de numere repartizate normal, N (µ, σ)
Funcµia randn
• Funcµia randn genereaz un num r aleator repartizat normal N (0, 1).
• randn(m, n) genereaz o matrice aleatoare cu m× n componente repartizate N (0, 1).
• Pentru a schimba metoda prin care sunt generate numerele aleatoare normale sau starea generato-rului, folosim comanda:
randn(method, s)
unde unde method este metoda prin care numerele aleatoare sunt generate (aceasta poate � 'state'
sau 'seed'), iar s este un num r natural între 0 ³i 232 − 1, reprezentând starea iniµializatorului.
• Comanda m+σ∗randn genereaz un num r aleator repartizat normal N (m, σ). De exemplu, codulurm tor produce Figura 1.3:
x = 0:0.05:10;
y = 5 + 1.1*randn(1e5,1); % date distribuite N (5, 1.1)
hist(y,x)
Simularea arunc rii unei monede
• Comanda
X = (rand < 0.5);
4

0 2 4 6 8 100
50
100
150
200
250
Figura 1.3: Reprezentarea cu histograme a datelor normale.
simuleaz aruncarea unei monede ideale. Vom mai spunem c num rul X astfel generat este unnum r aleator repartizat B(1, 0.5) (similar cu schema bilei revenite, în cazul în care o urn are bilealbe ³i negre în num r egal ³i extragem o bil la întâmplare)
• Num rul
Y = sum (rand(30,1)<0.5)
urmeaz repartiµia B(30, 0.5) (simularea a 30 arunc ri ale unei monede ideale).
• Acela³i experiment poate � modelat ³i prin comanda
round(rand(30,1))
Pentru a num ra câte feµe de un anumit tip au ap rut, folosim
sum(round(rand(30,1)))
Simularea în Matlab a unei v.a. de tip discret
S consider m o variabil aleatoare ce poate avea doar 3 rezultate posibile, a, b ³i c, cu probabilit µile derealizare 0.5, 0.2 ³i, respectiv, 0.3. Tabloul de repartiµie asociat este:
X :
(a b c
0.5 0.2 0.3
),
Pentru a modela aceast variabil aleatoare în Matlab, proced m astfel: alegem uniform la întâmplareun num r x din intervalul [0, 1]. Dac x < 0.5, atunci convenim c rezultatul a s-a realizat, dac 0.5 < x < 0.7, atunci rezultatul b s-a realizat. Altfel, rezultatul v.a. X este c. Dac acest experiment serepet de multe ori, atunci rezultatele pot � folosite în estimarea probabilit µilor de realizare a variabileialeatoare. Cu cât vom face mai multe experimente, cu atât vom aproxima mai bine valorile teoretice aleprobabilit µilor, deci putem spune c am aproximat variabila aleatoare X.În Matlab, scriem:
syms a b c % declaram a, b si c ca variabile simbolice
r = rand;
X = a*(r<0.5) + b*(0.5<r & r<0.7) + c*(r>0.7)
5

Folosind aceast metod , putem simula aruncarea unui zar ideal. Avem 6 rezultate posibile, ³i anume,apariµia unei feµe cu 1, 2, 3, 4, 5 sau 6 puncte. Pentru a simula acest experiment, modi�c m în modconvenabil problema. Vom considera c punctele din intervalul [0, 1] formeaz mulµimea tuturor cazurilorposibile ³i împ rµim intervalul [0, 1] în 6 subintervale de lungimi egale:{
(0,1
6), (
1
6,
2
6), (
2
6,
3
6), (
3
6,
4
6), (
4
6,
5
6), (
5
6, 1)
}.
corespunz toare, respectiv, celor ³ase feµe, s zicem în ordinea cresc toare a punctelor de pe ele. Vomvedea mai târziu (vezi metoda Monte Carlo) ca alegerea acestor intervale cu capete închise, deschisesau mixte nu are efect practic asupra calculului probabilit µii dorite. Acum, dac dorim s simul m înMatlab apariµia feµei cu 3 puncte la aruncarea unui zar ideal, vom alege (comanda rand) un num r "laîntâmplare" din intervalul [0, 1] ³i veri�c m dac acesta se a� în intervalul (26 ,
36). A³adar, comanda
Matlab
u = rand; (u < 3/6 & u > 2/6)
simuleaz aruncarea unui zar ideal. Ca o observaµie, deoarece cele 6 feµe sunt identice, putem simpli�caaceast comanda ³i scrie
(rand < 1/6).
Repartiµii probabilistice în Matlab
Funcµia de probabilitate (pentru v.a. discrete) ³i densitatea de repartiµie (pentru v.a. continue) (ambelenotate anterior prin f(x)) se introduc în Matlab cu ajutorul comenzii pdf, astfel:
pdf('LEGE', x, <param>) sau LEGEpdf(x, <param>).
Funcµia de repartiµie F (x) a unei variabile aleatoare se poate introduce în Matlab cu ajutorul comenziicdf, astfel:
cdf('LEGE', x, <param>) sau LEGEcdf(x, <param>).
Inversa funcµiei de repartiµie pentru repartiµii continue, F−1(y), se introduce cu comanda icdf, astfel:
icdf('LEGE', y, <param>) sau LEGEinv(y, <param>).
În comenzile de mai sus, LEGE poate � oricare dintre legile de repartiµie din Tabelul 1.1, x este un scalar sauvector pentru care se calculeaz f(x) sau F (x), y este un scalar sau vector pentru care se calculeaz F−1(y),iar <param> este un scalar sau un vector ce reprezint parametrul (parametrii) repartiµiei considerate.
Observaµia 1.2 Fie X o variabil aleatoare ³i F (x, θ) funcµia sa de repartiµie, θ �ind parametrul repar-tiµiei. Pentru un x ∈ R, relaµia matematic
P (X ≤ x) = F (x)
o putem scrie astfel în Matlab:
cdf('numele repartiµiei lui X',x,θ). (1.1)
6

Problema poate aparea la evaluarea în Matlab a probabilit µii P (X < x). Dac repartiµia considerat este una continu , atunci corespondentul în Matlab este tot (1.1), deoarece în acest caz
P (X ≤ x) = P (X < x) + P (X = x) = P (X < x).
De exemplu, dac X ∼ N (5, 2), atunci
P (X < 4) = cdf('norm', 4, 5, 2).
Dac X este de tip discret, atunci
P (X < x) =
{P (X ≤ [x]) , x nu e întreg
P (X ≤ m− 1) , x = m ∈ Z,
unde [x] este partea întreag a lui x.De exemplu, dac X ∼ B(10, 0.3), atunci
P (X < 5) = P (X ≤ 4)
= cdf('bino', 4, 10, 0.3) = 0.8497.
Exerciµii rezolvate
Exerciµiu 1.1 O moned ideal este aruncat de 100 de ori, iar X este variabila aleatoare ce reprezint num rul de feµe cu stema ap rute.(a) Care este probabilitatea de a obµine exact 52 de steme?(b) S se calculeze P (45 ≤ X ≤ 55).
Soluµie: (a) Avem de calculat P1 = P (X = 52). Îns X este o variabil aleatoare distribuit B(100, 0.5), a³adar rezultatul exact este:
P1 = C52100 · (0.5)52 · (0.5)48 = 0.0735.
(b) Not m cu FX funcµia de repartiµie pentru variabila aleatoare binomial X. Atunci,
P2 = P (45 ≤ X ≤ 55) = P (X ≤ 55)− P (X < 45)
= FX(55)− FX(44)
=55∑
k=45
Ck100 · (0.5)k · (0.5)100−k = 0.7287.
Înl Matlab, putem calcula probabilit µile astfel:
(a) P1 = binopdf(52,100,0.5)
sau P1 = nchoosek(100,52)*(0.5)^52*(0.5)^48
(b) P2 = binocdf(55,100,0.5) - binocdf(44,100,0.5) . √
Exerciµiu 1.2 Cineva a înregistrat zilnic timpul între dou sosiri succesive ale tramvaiului într-o anumit staµie ³i a g sit c , în medie, acesta este de 20 de minute. Se ³tie c acest timp este distribuit exponenµial.
7

Dac o persoan a ajuns în staµie exact când tramvaiul pleca, a�aµi care sunt ³ansele ca ea s a³tepte celpuµin 15 minute pân vine urm torul tramvai.
Soluµie: Not m cu T timpul de a³teptare în staµie între dou sosiri succesive ale tramvaiului ³i cu FTfuncµia sa de repartiµie. �tim c T ∼ exp(λ), unde λ = 20. A³adar, avem de calculat P (T ≥ 15), careeste:
P (T ≥ 15) = 1− P (T < 15) = 1− FT (15),
³i aceasta este
1 - cdf('exp',15, 20) = 0.4724 (sau 1-expcdf(15, 20) = 0.4724),
ceea ce implic 47.24% ³anse. √
Exerciµiu 1.3 Dintre spectatorii prezenµi pe un anumit stadion la un meci de fotbal, un procent de 20%sunt femei.La o tombola organizat pentru spectatori, un computer alege la întâmplare numerele a 7 bilete de intrare³i se premiaz posesorii.(i) Care este probabilitatea ca m car 3 dintre spectatorii premiaµi s �e femei?(ii) Care este probabilitatea ca nicio femeie s nu câ³tige la tombol ?(iii) Dac selecµia biletelor câ³tig toare ar � fost realizat prin alegerea a 7 spectatori ce erau a³ezaµiîn ³ir, pe un acela³i rând ales la întâmplare, argumentaµi dac probabilit µile g site la (i) si (ii) r mânacelea³i.
Soluµie: Fie X variabila aleatoare ce reprezint num rul de femei ce apar la alegerea la întâmplare a 7spectatori. Atunci X ∼ B(7, 0.2). Fie p = 0.2.(i) P (X ≥ 3) = 1− P (X < 3) = 1− P (X ≤ 2) = 1− FX(2) = 0.1480.În Matlab,
P1 = 1-binocdf(2,7,0.2).
(ii) P (X = 0) = C07 p
0 (1− p)7 = 0.2097 (=binopdf(0,7,0.2)).În Matlab,
P2 = binopdf(0,7,0.2).
(iii) În acest caz, X nu ar mai � o v.a. binomial , deoarece alegerea spectatorilor nu mai este aleatorie(spectatorii a³ezaµi al turi pot � cuno³tinte, prieteni etc.). √
Exerciµiu 1.4 (i) În faµa unui oponent de acela³i calibru la tenis de mas , care eveniment este maiprobabil: s câ³tigi 3 partide din 4, sau s câ³tigi 5 partide din 8? Justi�caµi r spunsul.(ii) Se menµine rezultatul anterior dac , în loc de tenis de mas , cei doi s-ar întrece la ³ah? Presupunemc adversarii sunt de aceea³i valoare. Justi�caµi r spunsul.
- (i) Deoarece cei doi oponenµi sunt de acela³i calibru, probabilitatea unuia de a câ³tiga împotrivaceluilalt este p = 0.5. S not m cu X num rul de jocuri câ³tigate de juc torul J1 împotriva lui J2. Atunci,X este o variabil aleatoare binomial ; în cazul în care se joac doar 4 partide, X ∼ B(4, 0.5), iar în cazulîn care se joac 8 partide, X ∼ B(8, 0.5).Probabilitatea ca J1 s câ³tige 3 din 4 este P1 = C3
40.54 = 0.25,iar probabilitatea ca J1 s câ³tige 5 din 8 este P2 = C5
80.58 = 0.2187.(ii) În acest caz, rezultatul se schimb . Nu mai putem folosi repartiµia binomial , deoarece la ³ah exist ³i posibilitatea unei remize (pentru o singur partid , exist 3 rezultate posibile). √
8

Exerciµiu 1.5 Un sondaj preliminar a determinat c 42% dintre persoanele cu drept de vot dintr-oanumit µar ar vota candidatul C pentru pre³edinµie. Alegem la întâmplare 200 de votanµi. Care esteprobabilitatea ca un procent dintre ace³tia, situat între 40% ³i 50%, îl vor vota pe C la pre³edinµie?
- S not m cu p = 0.42 ³i cu X variabila aleatoare ce reprezint num rul de votanµi ce au alescandidatul C, din selecµia aleatoare de volum n = 200 considerat . Este clar c X ∼ B(n, p). Se cereprobabilitatea P (80 ≤ X ≤ 100) (deoarece 40% din 200 înseamn 80 etc). Deoarece X este o variabil aleatoare discret , avem c :
P = P (80 ≤ X ≤ 100) = P (X ≤ 100)− P (X < 80) = FX(100)− FX(79),
unde FX este funcµia de repartiµie a lui X.În Matlab:
P = binocdf(100, 200, 0.42) - binocdf(79, 200, 0.42) = 0.7303. √
Exerciµiu 1.6 Care este probabilitatea de apariµie pentru prima oar a feµei cu 6 puncte la aruncareaunui zar ideal în cel mult 3 arunc ri? Dar în exact 3 arunc ri?
- Not m cu X v.a. variabil aleatoare ale c rei valori reprezint num rul de e³ecuri avute pân la primul succes. Aceasta urmeaz repartiµia geometric Geo(1/6). În consecinµ , num rul de arunc ri
necesare obµinerii feµei pentru prima dat este Y = X + 1. Probabilitatea de a obµine pentru primaoar aceast faµ din cel mult 3 arunc ri este totuna cu probabilitatea de a avea cel mult 2 e³ecuri pân la apariµia acestei feµe. A³adar, avem:
P1 = P (Y ≤ 3) = P (X ≤ 2) = 0.4213.
Probabilitatea de a obµine pentru prima oar faµa din exact 3 arunc ri este:
P2 = P (Y = 3) = P (X = 2) = 0.1157.
În Matlab scriem:
P1 = geocdf(2,1/6);
P2 = geopdf(2,1/6); √
Exerciµiu 1.7 Demonstraµi c dac X ∼ P(λ) ³i Y ∼ P(µ) sunt dou variabile aleatoare independente,atunci X + Y ∼ P(λ + µ). Generalizaµi rezultatul pentru n variabile aleatoare independente repartizatePoisson.
Soluµie: Demonstr m un rezultat mai general:Dac variabilele aleatoare X1 ∼ P(λ1), X1 ∼ P(λ1), . . . , X1 ∼ P(λn) sunt independente, atunci sumalor, Y = X1 +X2 + · · ·+Xn, urmeaz repartiµia Y ∼ P(λ1 + λ2 + · · ·+ λn).Funcµia generatoare de momente pentru X1 este
MX1(t) = E(etX1) =∑k∈N
etke−λ1λk1k!
= e−λ1∑k∈N
(λ1et)k
k!= e−λ1eλ1e
t= eλ1(e
t−1).
Folosind independenta variabilelor aleatoare date, putem scrie:
MY (t) = MX1+X2+···+Xn(t) = E(et(X1+X2+···+Xn)) = E(etX1) · E(etX2) · · · · · E(etXn)
= eλ1(et−1) · eλ2(et−1) · · · · · eλn(et−1) = e(λ1+λ2+···+λn)(e
t−1).
9

Obµinem c MY (t) este funcµia generatoare de momente pentru o variabil aleatoare Poisson cu parametrulλ1 + λ2 + · · ·+ λn. Folosind unicitatea funcµiei generatoare de momente, deducem c
Y ∼ P(λ1 + λ2 + · · ·+ λn). √
Exerciµiu 1.8 (a) În magazinul de la colµul str zii intr în medie 20 de clienµi pe or . �tiind c num rulclienµilor pe or este o variabil aleatoare repartizat Poisson, s se determine care este probabilitatea caîntr-o anumit or s intre în magazin cel puµin 15 clienµi?(b) Care este probabilitatea ca, într-o anumit zi de lucru (de 10 ore), în magazin s intre cel puµin 200de clienµi?
Soluµie: (a) Probabilitatea este
P1 = P (X ≥ 15) = 1− P (X < 15) = 1− P (X ≤ 14) = 1− FX(14) = 0.8951.
(b) P2 = P (
10∑k=1
Xk ≥ 200) = 1 − P (
10∑k=1
Xk < 200) = 1 − P (
10∑k=1
Xk ≤ 199) = 1 − F∑Xk(199) = 0.5094.
Am folosit faptul c 10∑k=1
Xk ∼ P(200), deoarece avem o sum de v.a. independente, identic repartizate
Poisson (vezi Exerciµiu 1.7).În Matlab, probabilit µile cerute se calculeaz astfel:
P1 = 1 - poisscdf(14,20);
P2 = 1 - poisscdf(199,200);
Exerciµiu 1.9 În drumul Mariei de acas pân la serviciu se a� dou semafoare. Not m cu X1 v.a. cereprezint num rul de semafoare pe care Maria le prinde pe ro³u, ³i presupunem c repartiµia lui X1 esteurm toarea:
x 0 1 2
p(x) 0.2 0.5 0.3
De asemenea, �e X2 num rul de semafoare pe care Maria le prinde pe ro³u pe drumul de întoarcere sprecas . Presupunem c X1 ³i X2 sunt independente ³i identic repartizate.(a) Determinaµi repartiµia, media ³i dispersia variabilei aleatoare X = X1 +X2.(b) Care e probabilitatea ca Maria s prind cel puµin 2 semafoare pe ro³u de acas la serviciu ³i retur?
Soluµie: (a) Repartiµia lui X este:
x 0 1 2 3 4
p(x) 0.04 0.2 0.37 0.3 0.09
E(X) = E(X1) + E(X2) = 2(0× 0.2 + 1× 0.5 + 2.3) = 2.2. ³i, folosind independenµa lui X1 ³i X2,
D2(X) = D2(X1) +D2(X2) = 2[(0− 1.1)2 × 0.2 + (1− 1.1)2 × 0.5 + (2− 1.1)2 × 0.3] = 0.98.
(b) P = 0.37 + 0.3 + 0.09 = 0.76. √
10

Exerciµii suplimentare
Exerciµiu 1.10 Consider m funcµia f : R −→ R, dat prin
f(x) =
2
λx e−
x2
λ , x > 0;
0 , x ≤ 0.
(a) Pentru ce valori ale parametrului λ, funcµia f este o densitate de repartiµie?(S not m cu X variabila aleatoare ce are aceast densitate de repartiµie)
(b) Calculaµi EX ³i D2(X).(c) Dac λ = 2, calculaµi P (X ≥ 2).
Exerciµiu 1.11 Consider m o v.a. X de tip continuu, având funcµia de repartiµie
F (x) =
0 , x ≤ 0;x
4
[1 + ln
(4
x
)], x ∈ [(0, 4];
1 , x > 4.
Calculaµi:(a) P (X ≤ 1), P (X = 1);(b) E(X);(c) P (1 ≤ X < 3).
Exerciµiu 1.12 Un anumit comerciant vinde trei tipuri de congelatoare: de 160 litri, de 190 litri ³i de230 litri. Fie X variabila aleatoare care reprezint alegerea unui client ales la întâmplare, ce are tabelulde repartiµie:
x 160 190 230
p(x) 0.2 0.5 0.3
(a) Calculaµi E(X), D2(X).(b) Dac preµul unui frigider se calculeaz dup formula P = 7X − 9.5, calculaµi valoarea a³teptat apreµului pl tit de urm torul client care cump r un congelator.(c) Calculaµi D2(P ).(d) Presupunem c , de³i capacitatea a�³at este X, capacitatea real a unui congelator este h(X) =X − 0.01X2. Care este valoarea medie a capacit µii reale pentru un congelator cump rat de urm torulclint?
Exerciµiu 1.13 Dou zaruri ideale sunt aruncate în mod independent unul de cel lalt. Not m cu Mmaximum dintre valorile ap rute.(a) Determinaµi tipul v.a. M ³i tabloul s u de repartiµie.(b) Determinaµi funcµia de repartiµie ³i desenaµi-o gra�c.
Exerciµiu 1.14 Temperatura T (0C) dintr-un anumit proces chimic are repartiµia U(−5, 5).Calculaµi P (T < 0); P (−2.5 < T < 2.5); P (−2 ≤ T ≤ 3).
11

Exerciµiu 1.15 Temperatura de topire a unui anumit material este o v.a. cu media de 120 oC ³i deviµiastandard de 2 oC. Determinaµi temperatura medie ³i deviaµia standard în oF , ³tiind c oF = 1.8 oC + 32.
Exerciµiu 1.16 Dac Z ∼ N (0, 1), calculaµi:P (Z ≤ 1.35); P (0 ≤ Z ≤ 1); P (1 ≤ Z); P (|Z| > 1.5).
Exerciµiu 1.17 Not m cu Sn suma numerelor ce apar în n arunc ri independente ale unui zar ideal.(a) Calculaµi probabilitatea P = P (S2 ≥ 6).(b) Calculaµi probabilitatea obµinerii unui num r par.
Exerciµiu 1.18 O companie de asigur ri ofer angajaµilor s i diverse poliµe de asigurare. Pentru unasigurat ales aleator, not m cu X num rul de luni scurs între dou pl µi succesive. Funcµia de repartiµiea lui X este:
F (x) =
0 , x < 1;
0.3 , 1 ≤ x < 3;
0.4 , 3 ≤ x < 4;
0.45 , 4 ≤ x < 6;
0.65 , 6 ≤ x < 12;
1 , 12 ≤ x.
(a) Determinaµi funcµia de probabilitate a lui X.(b) Calculaµi P (3 ≤ X ≤ 6) ³i P (4 ≤ X).
Exerciµiu 1.19 Pentru evaluarea rezultatelor obtinute la teza de Matematica de catre elevii unei anumitescoli, se face un sondaj de volum 35 printre elevii scolii, iar notele lor sunt sumarizate in Tabelul 1.2.
note 4 5 6 7 8 9 10
frecventa 3 6 7 8 5 4 2
Tabela 1.2: Medii generale si frecvente
(i) Sa se scrie si sa se reprezinte gra�c functia de repartitie pentru aceasta selectie;(ii) Notam cu X variabila aleatoare care guverneaza populatia. Utilizand selectia de mai sus, sa seaproximeze probabilitatea P (6 ≤ X ≤ 8).
Exerciµiu 1.20 O pereche de zaruri ideale este aruncat de 200 de ori. Care este probabilitatea s obµinem o sum de 7 în cel puµin 20% dintre cazuri?
Exerciµiu 1.21 Simulaµi în Matlab variabila aleatoare discret X ce are tabloul de distribuµie:
X :
(−2 0 214
12
14
).
G siµi ³i reprezentaµi gra�c funcµia de repartiµie F (x) a variabilei aleatoare X. Calculaµi F (12).
12

Exerciµiu 1.22 (i) Determinaµi funcµia generatoare de momente pentru o repartiµie exponenµial , exp(λ).(ii) Folosind funcµia generatoare de momente, ar taµi c dac {Xi}ni=1 sunt variabile aleatoare indepen-
dente, repartizate exp(λi) (respectiv), atunci vaiabila alatoare Y =
n∑i=1
Xi urmeaz repartiµia Γ(n, λ), cu
λ =n∑i=1
λi.
Exerciµiu 1.23 (i) Determinaµi funcµia generatoare de momente pentru o repartiµie binomial , B(n, p).(ii) Demonstraµi c dac X ∼ B(m, p) ³i Y ∼ B(n, p) sunt dou variabile aleatoare independente, atunciX + Y ∼ B(m + n, p). Generalizaµi rezultatul pentru n variabile aleatoare independente repartizatebinomial.
13

2 Statistic Aplicat (L2 & S2)
Exerciµiu 2.1 Dac X ∼ N (0, 1), determinaµi densitatea de repartiµie a variabilei aleatoare X2.(repartiµia obµinut este χ2(1)).
- Funcµia densitate de repartiµie pentru X este dat de
fX(x) =1√2πe−
x2
2 , x ∈ R. (2.1)
Not m cu FX2(y) funcµia de repartiµie pentru X2 ³i cu fX2(y) densitatea sa de repartiµie. Nu putem folosiformula de la curs deoarece funcµia g(x) = x2, x ∈ R, nu este bijectiv . Pentru a calcula densitatea luiX2, putem proceda astfel:
FX2(y) = P (X2 ≤ y) =
{0 , y ≤ 0;
P (−√y ≤ X ≤ √y) , y > 0,
de unde
fX2(y) = F ′X2(y) =
0 , y ≤ 0;1
2√y
[fX(√y) + fX(−√y)] , y > 0,
=
0 , y ≤ 0;1√yfX(√y) , y > 0.
=
0 , y ≤ 0;1√2πy
e−y2 dy , y > 0. √
Exerciµiu 2.2 Ar taµi c dac X1, X2, . . . , Xn sunt variabile aleatoare independente, identic repartizate
N (µ, σ), atunci variabila aleatoare H =1
σ2
n∑i=1
(Xi − µ)2 urmeaz repartiµia χ2(n).
- Dac Xi ∼ N (µ, σ), atunci Yi =Xi − µσ
∼ N (0, 1). Deoarece {Xi}ni=1 sunt independente,
atunci ³i {Y 2i }ni=1 sunt independente. Dac X ∼ N (0, 1), atunci X2 are densitatea de repartiµie
fX2(x) =
1√2πx
e−x2 dx , x > 0.
0 , x ≤ 0.
Funcµia generatoare de momente pentru X2 este
MX2(t) = E(etX2) =
∫ ∞0
etx2 1√
2πxe−
x2 dx = (1− 2t)−1/2, t < 1/2.
Folosind independenµa variabilelor {Y 2i }ni=1, obµinem c funcµia generatoare de momente a lui H este
MH(t) =n∏i=1
(1− 2t)−1/2 = (1− 2t)−n/2, t < 1/2,
care este densitatea de repartiµie pentru o variabil aleatoare χ2(n). √
14

Exerciµiu 2.3 Fie variabila aleatoare X ∼ exp(λ). Folosind metoda Hincin-Smirnov, generaµi o selec-µie de numere aleatoare ce urmeaz repartiµia lui X.
- Funcµia de repartiµie a lui X este F : R −→ [0, 1], F (x) = 1 − e−x/λ, x > 0, iar F−1 (carese de�ne³te doar pentru valori în (0, 1)) este:
F−1(u) = −λ ln(1− u), u ∈ (0, 1).
Atunci, dac {u1, u2, . . . , un} sunt numere aleatoare uniform repartizate în [0, 1], avem c {F−1(u1),F−1(u2), . . . , F−1(un)} formeaz o selecµie întâmpl toare de numere repartizate exp(λ).În Figura 2.1, am reprezentat gra�c o dou selecµii de volum 150 de numere aleatoare repartizate exp(5);una generat prin metoda funcµiei de repartiµie inverse, cealalt generat de funcµia Matlab prede�nit exprnd. Selecµiile generate au fost ordonate descresc tor. Funcµia Matlab care genereaz �gura esteprezentat mai jos.Apelarea funcµiei se face prin tastarea în fereastra de lucru în Matlab a comezii expsel(5). √
function expsel(lambda) % functia expsel.m
% generez 150 de numere cu metoda Hincin-Smirnov si le ordonez descrescator
Y = sort(-lambda*log(1-rand(150,1)), 'descend');
plot(Y, 'bo'); hold on % desenez selectia si retin figura
% generez 150 de numere cu exprnd si le ordonez descrescator
Z = sort(exprnd(lambda, 150,1), 'descend');
plot(Z, 'r*') % desenez Z cu rosu
legend('metoda functiei inverse','generare cu exprnd')
Figura 2.1: Generare de numere aleatoare prin metoda funcµiei inverse.
Exerciµiu 2.4 Dac U este o variabil aleatoare repartizat U(0, 1), determinaµi repartiµia variabileialeatoare Y = −λ ln(U), λ > 0.
15

Soluµie: Densitatea de repartiµie a lui U este
fU (x) =
{1, dac x > 0,
0, dac x ≤ 0.
Funcµia de repartiµie a lui Y este
FY (y) = P (Y ≤ y) = P (−λ ln(U) ≤ y) =
=
{P(ln(U) ≥ − y
λ
), dac y > 0,
0, dac y ≤ 0.=
{1− P
(U < e−
yλ
), dac y > 0,
0, dac y ≤ 0.=
{1− FU
(e−
yλ
), dac y > 0,
0, dac y ≤ 0.
Atunci, densitatea de repartiµie a lui Y este
fY (y) = F ′Y (y) =
fU(e−
yλ
) 1
λe−
yλ , dac y > 0,
0, dac y ≤ 0.
=
1
λe−
yλ , dac y > 0,
0, dac y ≤ 0.
Se observ c Y ∼ exp(λ). √
Exerciµiu 2.5 S presupunem c X este o v.a. continu ce reprezint în lµimea (în cm) b rbaµilor dintr-o µar . Se ³tie c P (X ≤ 170) = 0.1. �tiind c X este normal distribuit , cu media m = 175, s sedetermine dispersia lui X.
Soluµie: Consider variabila aleatoare standardizat Z = X−175σ ∼ N (0, 1). Atunci,
0.1 = P (X ≤ 170) = P
(X − 175
σ≤ 170− 175
σ
)= P
(Z ≤ − 5
σ
),
de unde − 5
σeste cuantila de ordin 0.1 pentru Z ∼ N (0, 1). Aceasta este z0.1 = −1.28 (norminv(0.1)),
de unde σ = 3.9. √
Exerciµiu 2.6 Trei întreprinderi trimit acela³i tip de piese într-un depozit central, în proporµie de 5, 3, 2.Cele trei întreprinderi au rebuturi în proporµie de, respectiv, 1%, 3%, 2%. Valoarea pieselor ce s-au dovedita � rebuturi este de 3600 RON. Cum ar trebui împ rµit aceast sum între cele 3 întreprinderi?
Soluµie: Not m cu:A−evenimentul ca o pies aleas la întâmplare din depozitul central s �e rebut.Ai−evenimentul ca, alegând la întâmplare o pies din depozitul central, aceasta s aparµin �rmei i.Pentru a determina cum împ rµim cei 3600 între cele 3 �rme, va trebui s determin probabilit µilecondiµionate P (A1|A), P (A2|A), P (A2|A), care reprezint ponderile de rebuturi produse de �ecare�rm , condiµionate de apariµia unui rebut la o alegere la întâmplare din depozit.Dar, P (A1) = 0.5, P (A2) = 0.3, P (A3) = 0.2 ³i P (A|A1) = 0.01, P (A|A2) = 0.03, P (A|A3) = 0.02.Avem c
P (A) = P (A1)P (A|A1) +P (A2)P (A|A2) +P (A3)P (A|A3) = 0.5× 0.01 + 0.3× 0.03 + 0.2× 0.02 = 0.018.
³i (formula lui Bayes)
P (A1|A) =P (A1)P (A|A1)
P (A)=
5
18, P (A2|A) =
P (A2)P (A|A2)
P (A)=
1
2, P (A3|A) =
P (A3)P (A|A3)
P (A)=
2
9.
16

În consecinµ , pierderile vor trebui s �e împ rµite astfel:
5
18× 3600 = 1000 (�rma 1);
1
2× 3600 = 1800 (�rma 2);
2
9× 3600 = 800 (�rma 3).
√
Exerciµiu 2.7 Un anumit restaurant popular serve³te la cin doar trei tipuri de meniuri cu preµuri �xe,³i anume: 25, 30 ³i 45 (incluzând b uturile). Pentru un cuplu ales la întâmplare dintre cele ce iau cinaîn acest restaurant, not m cu X costul meniului ales de femeie ³i cu Y costul meniului ales de partenerulei. Repartiµia comun a costurilor este dat în tabelul urm tor:
Yp(x, y) 25 30 4525 0.05 0.05 .10
X 30 0.05 0.10 .3545 0 0.20 .10
(1) Calculaµi repartiµiile marginale pentru X ³i Y ;(2) Care este probabilitatea ca preµul cinei pentru ambii parteneri s �e cel mult 30 de �ecare?(3) Determinaµi dac X ³i Y sunt v.a. independente;(4) Care este valoarea a³teptat a costului total al cinei pentru un cuplu ales la întâmplare?(5) La �nalul cinei, �ecare cuplu prime³te din partea casei pr jituri cu r va³. Dac un cuplu g se³te înr va³ mesajul �Drept curtoazie din partea casei, din preµul total al cinei vei primi înapoi diferenµa dintre
cel mai scump ³i cel mai ieftin dintre meniurile comandate de amândoi�, cât se a³teapt restaurantul s returneze pentru un singur cuplu?(6) Determinaµi coe�cientul de corelaµie dintre X ³i Y .(7) Determinaµi repartiµia lui Y condiµionat de evenimentul (X = 30).(8) Calculaµi E(Y |X = 30) ³i D2(Y |X = 30).
Soluµie: (1) pX(x) =∑
y p(x, y). Pentru x = 25, atunci pX(25) = 0.05 + 0.05 + 0.1 = 0.2. Obµinem c repartiµia marginal a lui X este:
x 25 30 45
pX(x) 0.2 0.5 0.3
Similar, pY (y) =∑
x p(x, y). Pentru y = 45, atunci pY (45) = 0.1 + 0.35 + 0.1 = 0.55. Obµinem c repartiµia marginal a lui Y este:
y 25 30 45
pY (y) 0.1 0.35 0.55
(2) Probabilitatea cerut este P (X ≤ 30, Y ≤ 30) = 0.05 + 0.05 + 0.05 + 0.1 = 0.25.
(3) Variabilele X ³i Y nu sunt independende, deoarece p(x, y) 6= pX(x) · pY (y) m car pentru o pereche(x, y). De exemplu, p(25, 25) = 0.05 6= 0.2 · 0.1 = pX(25) · pY (25).
(4) h(X, Y ) = X + Y ³i E(h(X, Y )) =∑x
∑y
h(x, y)p(x, y) =∑x
∑y
(x+ y)p(x, y) = 71.25.
(5) Determin m repartiµia variabilei aleatoare Z = |X − Y |. Aceasta este:
17

z 0 5 15 20
pZ(z) 0.1 0.25 0.55 0.1
Media lui Z este E(Z) = 11.5.
(6) Prin de�niµie,
ρX,Y =cov(X, Y )
σX · σY=
E(X · Y )− µX · µYσX · σY
.
Dar,
µX =∑x
xpx = 25×0.2+30×0.5+45.3 = 33.5; µY =∑y
ypy = 25×0.1+30×0.35+45×0.55 = 37.75.
σ2X =∑x
(x− µx)2px = 60.25; σ2Y =∑y
(y − µy)2py = 66.188.
E(X · Y ) =∑x
∑y
xy p(x, y) = 1253.8.
Obµinem c ρX,Y = −0.1722.
(7) Variabila aleatoare Y |X = 30 are funcµia de probabilitate fY |X(y| 30) =p(30, y)
pX(30), ce are tabelul de
repartiµie urm tor:
y 25 30 45
pY |X(y| 30) 0.1 0.2 0.7
(8) µY |X=30 = E(Y |X = 30) =∑
y y pY |X(y| 30) = 25× 0.1 + 30× 0.2 + 45× 0.7 = 40 ³i
D2(Y |X = 30) = E(Y 2|X = 30)− µ2Y |X=30 = 60. √
Exerciµiu 2.8 O numit companie de ambalat fructe uscate, amestec în acela³i pachet trei tipuri defructe, mango, ananas ³i papaya, astfel încât masa net a pachetului este de 500 de grame, de³i cantit µileindividuale din �ecare fruct uscat pot varia de la un pachet la altul. Deoarece suma ponderilor maselor�ec rui fruct la produsul �nal este egal cu 1, putem determina masa net de ananas din �ecare pachetdac am avea informaµii despre repartiµia comun a celorlale dou cantit µi de fruct din pachet.S not m cu X ponderea masei de mango din masa net a unui anumit pachet ³i cu Y ponderea maseide ananas din masa net a aceluia³i pachet, ales la întâmplare. Presupunem c repartiµia comun a celordou cantit µi este
f(x, y) =
{24xy, pentru 0 ≤ x ≤ 1, 0 ≤ y ≤ 1, x+ y ≤ 1,
0, altfel.
(a) Veri�caµi dac f(x, y) este o densitate de repartiµie legitim ³i calculaµi probabilitatea ca masa net de papaya s �e mai mare de un sfert de pachet.(b) Determinaµi densit µile de repartiµie marginale.(c) Veri�caµi dac X ³i Y sunt independente.(d) Determinaµi coe�cientul de corelaµie dintre X ³i Y .
18

(e) Determinaµi densitatea de repartiµie a lui Y condiµionat de X = x.(f) G siµi probabilitatea ca Y s �e cel mult un sfert de pachet, ³tiind c X este jum tate din masa net a pachetului. (i.e., calculaµi P (Y ≤ 0.25|X = 0.5)).(g) Calculaµi media condiµionat a lui Y ³tiind c X = 0.5. (i.e., E(Y |X = 0.5))(h) Calculaµi D2(Y |X = 0.5).
Soluµie: (a) Se vede c f(x, y) ≥ 0, ∀x, y. În plus,∫ ∞−∞
∫ ∞−∞
f(x, y) dxdy =
∫ 1
0
(∫ 1−x
024xy dy
)dx =
∫ 1
024x
(y2
2
∣∣∣y=1−xy=0
)dx =
∫ 1
012x(1− x)2 dx = 1.
Not cu D = {(x, y); 0 ≤ x ≤ 1, 0 ≤ y ≤ 1 ³i x+ y ≤ 0.75}. Atunci, probabilitatea cerut este:
P ((X,Y ) ∈ D) =x
D
f(x, y) dxdy =
∫ 0.75
0
(∫ 0.75−x
024xy dy
)dx = 0.3164.
(b) Repartiµia marginal a lui X este:
fX(x) =
∫ ∞−∞
f(x, y) dy =
{12x(1− x)2, dac 0 ≤ x ≤ 1;
0, altfel.
Repartiµia marginal a lui Y este:
fY (y) =
∫ ∞−∞
f(x, y) dx =
{12y(1− y)2, dac 0 ≤ y ≤ 1;
0, altfel.
(c) Deoarece f(x, y) 6= fX(x) · fY (y), ∀x, y, cele dou variabile nu sunt independente.
(d) Prin de�niµie,
ρX,Y =cov(X, Y )
σX · σY=
E(X · Y )− µX · µYσX · σY
.
Dar,
µX =
∫ ∞−∞
xfX(x) dx =
∫ 1
012x2(1− x)2 dx = 0.4; µY =
∫ ∞−∞
yfY (y) dy =
∫ 1
012y2(1− y)2 dy = 0.4.
σ2X = E(X2)−µ2X =
∫ 1
012x3(1−x)2 dx−0.16 = 0.04; σ2Y = E(Y 2)−µ2Y =
∫ 1
012y3(1−y)2 dy−0.16 = 0.04.
E(X · Y ) =
∫ ∞−∞
∫ ∞−∞
xyf(x, y) dxdy =
∫ 1
0
∫ 1−x
024x2y2 dxdy =
2
15.
Obµinem c ρX,Y = −2
3.
(e)
fY |X=x(y|x) =f(x, y)
fX(x)=
2y
(1− x)2, 0 ≤ y ≤ 1− x.
(f) Probabilitatea cerut este:
P (Y ≤ 0.25|X = 0.5) =
∫ 0.25
∞fY |X(y|x) dy =
∫ 0.25
0
2y
(1− x)2dy =
1
4.
19

(g)
µY |X=x = E(Y |X = x) =
∫ ∞−∞
yfY |X(y|x) dy =
∫ 1−x
0
2y2
(1− x)2dy =
2
3(1− x), 0 ≤ x ≤ 1.
În particular, pentru X = 0.5, obµinem c E(Y |X = 0.5) = 13 .
(h)
D2(Y |X = x) = E(Y 2|X = x)− µ2Y |X=x =
∫ 1−x
0
2y3
(1− x)2dy − 4
9(1− x)2 =
1
18(1− x)2, 0 ≤ x ≤ 1.
În particular, pentru X = 0.5, obµinem c σ2Y |X=0.5 = D2(Y |X = 0.5) = 0.0139. √
Exerciµiu 2.9 Dac X ³i Y sunt v.a. independente ³i identic repartizate N (0, 1), determinaµi repartiµiavariabilei aleatoare Z = X/Y .
Soluµie: Densit µile de repartiµie pentru X ³i Y sunt
fX(x) =1√2πe−x
2/2, x ∈ R, fY (y) =1√2πe−y
2/2, y ∈ R.
Deoarece sunt independente, densitatea de repartiµie a vectorului (X, Y ) este:
fX,Y (x) =1
2πe−(x
2+y2)/2, (x, y) ∈ R× R.
Pentru a determina repartiµia cerut , folosim transformarea u = x/y, v = y, care transform (X, Y ) în(U, V ) = (X/Y, Y ). Transformarea invers x = uv, y = v. Jacobianul transform rii inverse este J = v.Folosind formula de schimbare de variabile, obµinem:
fU, V (u, v) = fX,Y (uv, v)|v| = 1
2πe−v
2(u2+1)/2|v|, (u, v) ∈ R× R.
Densitatea de repartiµie marginal a primei componente se obµine integrând în raport cu a doua variabil .Obµinem:
fX/Y (u) = fU (u) =
∫ ∞−∞
fU, V (u, v)dv =
∫ ∞−∞
1
2πe−v
2(u2+1)/2|v|dv =1
π(u2 + 1), u ∈ R.
Se observ c fX/Y este densitatea de repartiµie pentru o repartiµie Cauchy C(0, 1). √
Exerciµii suplimentare
Exerciµiu 2.10 Folosind metoda Hincin-Smirnov, generaµi o familie de 100 de numere aleatoare ce ur-meaz densitatea de repartiµie f(x) = 5x4, 0 ≤ x ≤ 1.
Exerciµiu 2.11 Fie X o variabil aleatoare repartizat U(−π2,π
2).
(i) Determinaµi repartiµia variabilei aleatoare Y = tan(X) (Y se nume³te variabil aleatoare Cauchy).(ii) Folosind metoda Hincin-Smirnov, generaµi o familie de 1000 de numere aleatoare repartizate CauchyC(0, 1).(iii) Calculaµi P (| tanX| >
√3).
20

Exerciµiu 2.12 Dac X este o variabil aleatoare repartizat U(0, 1), determinaµi repartiµia variabileialeatoare Y = eX .
Exerciµiu 2.13 Fie X o variabil aleatoare repartizat B(n, p). Determinaµi repartiµia variabilei alea-toare Y = n−X.
Exerciµiu 2.14 Erorile a 10 m sur tori sunt variabile aleatoare εi ∼ N (0, 1), i = 1, 2, . . . , n.
(1) Ar taµi (folosind funcµia generatoare de momente) c variabila aleatoare H =
10∑i=1
ε2i urmeaz repar-
tiµia χ2, i.e. H ∼ χ2(10).(2) Determinaµi probabilit µile urm toare:
P (H ≤ 7); P (9.25 ≤ H ≤ 10.75); P (H > 12).
Exerciµiu 2.15 Latura unui pâtrat este o variabil aleatoare ce are densitatea de repartiµie f(x) =x8 , x ∈ (0, 4). Determinaµi densitatea de repartiµie a ariei p tratului.
Exerciµiu 2.16 Dac X ∼ N (0, 1), determinaµi densitatea de repartiµie a lui |X|.
Exerciµiu 2.17 (lipsa de memorie a variabilei aleatoare exponenµiale)
Ar taµi c dac X ∼ exp(λ), atunci are loc relaµia:
P (X > y + x|X > y) = P (X > x), (x ≥ 0, y ≥ 0).
Exerciµiu 2.18 Fie X ³i Y dou variabile aleatoare independente, identic repartizate N (0, 1). Determi-naµi raza cercului (r) cu centrul în origine astfel încât P ((X, Y ) ∈ D(0, r)) = 0.95. (D(0, r) = {(x, y) ∈R, x2 + y2 ≤ r2})
Exerciµiu 2.19 Distanµa X la care sunt aruncate mingile aruncate de o ma³in automat de servit mingide tenis este o variabil aleatoare repartizat normal. Media distanµei este necunoscut , dar deviaµiastandard este 1.2m.(a) �tiind c P (X ≤ 20) = 0.95, s se g seasc valoarea a³teptat a distanµei (adic , E(X)).
(b) Stabiliµi repartiµia variabilei aleatoare Z =X − E(X)
1.2³i calculaµi probabilitatea P (Z2 ≤ 2).
Exerciµiu 2.20 Fie U ³i V dou variabile aleatoare independente ³i identic repartizate U(0, 1).(1) Determinaµi repartiµia vectorului aleator (U, V ).(2) Determinaµi repartiµiile variabilelor aleatoare X =
√−2 lnU cos(2πV ) ³i Y =
√−2 lnU sin(2πV ).
(3) Bazându-v pe rezultatul de la (2), construiµi un algoritm care s permit simularea de variabilealeatoare N (0, 1) independente plecând de la variabile aleatoare U(0, 1) independente.
Exerciµiu 2.21 Determinaµi repartiµia sumei a dou variabile aleatoare independente ³i identic reparti-zate U(0, 1).
Exerciµiu 2.22 Determinaµi repartiµia raportului a dou variabile aleatoare independente ³i identic re-partizate N (0, 1).
21

Exerciµiu 2.23 P cal îl ademene³te pe Tândal la un joc de barbut. P cal a confecµionat urm toareletrei zaruri, pentru care num rul de puncte de pe �ecare faµ sunt modi�cate:
zarul 1: 5 7 8 9 10 18
zarul 2: 2 3 4 15 16 17
zarul 3: 1 6 11 12 13 14
Pentru �ecare zar, toate feµele au aceea³i ³ans de apariµie. Fiecare juc tor alege un zar ³i îl p streaz pentru restul competiµiei. Un joc const în aruncarea zarului ales, iar cel care obµine un num r mai marede puncte va câ³tiga jocul. Un astfel de joc poate � repetat de mai multe ori, în condiµii identice ³iindependente.(a) P cal , politicos �ind, îl invit pe Tândal s �e primul care î³i alege zarul. Ar taµi c , orice zar aralege Tândal , P cal are posibilitatea de a alege un zar mai bun dintre cele r mase.(b) La �ecare joc, cel care obµine un num r mai mare de puncte prime³te de la cel lalt juc tor 1 RON.Determinaµi câ³tigul mediu pe care îl poate avea P cal dup 60 de jocuri (arunc ri).(c) Calculaµi probabilitatea ca, dup 60 de jocuri, P cal s aib cel puµin 10 RON.
Exerciµiu 2.24 Repartiµia comun a vectorului aleator bidimensional (X, Y ) este reprezentat de tabelulurm tor:
Yp(x, y) 10 20 3020 a 0.1 a
X 40 0.1 0.3 3a
(a) Determinaµi parametrul real a pentru care tabelul reprezint o repartiµie legitim ;(b) Calculaµi P (X ≥ 20 ³i Y ≥ 30) ³i P (X ≤ 20 ³i Y ≥ 30).(c) Calculaµi F (20, 30), F (30, 40) ³i F (30, 25).(d) Pentru Z = X + Y , calculaµi probabilitatea P (|Z − 45| > 5).(e) Pentru W = 2X − 0.5Y + 10, determinaµi E(W ) ³i D2(W ).(f) Determinaµi cov(X, Y ) ³i ρX,Y .
Exerciµiu 2.25 La o benzin rie exist dou tipuri de staµii: cu servire asistat sau cu auto-servire.Fiecare serviciu are câte dou pompe independente. S not m cu X num rul de pompe de la staµia cuservire asistat care sunt folosite într-un anumit moment ³i cu Y num rul de pompe de la auto-servirefolosite în acela³i moment. Repartiµia comun pentru (X, Y ) este
Yp(x, y) 0 1 2
0 0.1 0.04 .02X 1 0.08 0.20 .06
2 0.06 0.14 .3
(a) Calculaµi P (X = 1 ³i Y = 1) ³i P (X ≤ 1 ³i Y ≤ 1).(b) Descrieµi în cuvinte evenimentul (X 6= 0 ³i Y 6= 0) ³i calculaµi probabilitatea acestuia.(c) Determinaµi probabilit µile marginale pentru X ³i Y .(d) Veri�caµi dac X ³i Y sunt independente.(e) Determinaµi coe�cientul de corelaµie ρX,Y .(f) Calculaµi E(Y |X = 0). Explicaµi în cuvinte ce reprezint aceast medie.
22

Exerciµiu 2.26 O anumit �rm prime³te comenzi la oricare dintre cele dou linii telefonice disponibile.Pentru �ecare linie, timpul de a³teptare dintre dou apeluri este repartizat exponenµial. Not m prin X³i Y cei doi timpi de a³teptare. Presupunem c ace³ti timpi sunt independenµi unul de cel lalt. Dac Xeste timpul de a³teptare mai mic dintre dou , atunci se poate ar ta c repartiµia comun pentru X ³i Yeste
f(x, y) =
{2e−(x+y), pentru 0 < x < y <∞.0, altfel.
(a) Determinaµi densitatea de repartiµie marginal a lui X.(b) Determinaµi densitatea de repartiµie a lui Y condiµionat de X = x.(c) G siµi probabilitatea ca Y s �e mai mare decât 2 minute, ³tiind c X ≤ 1 (i.e., P (Y > 2|X ≤ 1)).(d) Veri�caµi dac X ³i Y sunt independente.(e) Determinaµi media condiµionat a lui Y ³tiind c X = 1. (i.e., calculaµi E(Y |X = 1)).(f) Determinaµi probabilit µile P (X + Y ≤ 1) ³i P (X ≤ 1, Y ≤ 1).
Exerciµiu 2.27 Repartiµia comun pentru variabilele aleatoare X ³i Y este
f(x, y) =
{e−(x+y), pentru 0 < x, y <∞.0, altfel.
Determinaµi densit µile de repartiµie pentru variabilele aleatoare U = X + Y ³i V = XX+Y .
Exerciµiu 2.28 Presupunem c timpii de funcµionare continu a dou baterii, T1 ³i T2, sunt independenµiunul de cel lalt. De asemenea, presupunem c T1 ∼ exp(1000h) ³i T2 ∼ exp(1200h).(1) Determinaµi densitatea de repartiµie comun celor dou variabile aleatoare.(2) Calculaµi probabilitatea ca ambele baterii s funcµioneze continuu mai mult de 1500h.(3) �tiind c prima baterie a funcµionat exact 1200h, care este probabilitatea ca a dou baterie s maifunµioneze dup acest timp?
Exerciµiu 2.29∗ Un b µ de lungime 1m este rupt în dou , alegând la întâmplare ³i uniform punctul derupere. S not m cu X distanµa de la stânga b µului pân la punctul de rupere. Rupem din nou parteadin stânga (de lungime X), alegând la întâmplare ³i uniform un nou punct de rupere. S not m cu Ydistanµa de la stânga b µului rupt pân la noul punct de rupere.(a) Determinaµi E(Y |X = x).(b) Folosind fX(x) ³i fY |X(y|x), determinaµi f(x, y).(c) G siµi fY (y).
Exerciµiu 2.30 Vectorul aleator (X, Y ) are densitatea de repartiµie
f(x, y) =
{ke−y pentru 0 < x < y < 1.
0, altfel.
(a) Determinaµi valoarea lui k pentru care f(x, y) este o densitate de repartiµie.(b) Calculaµi coe�cientul de corelaµie ρX,Y .
Exerciµiu 2.31 Vectorul aleator (X, Y ) are densitatea de repartiµie
f(x, y) =
{ke−y pentru x > 0, y > x.
0, altfel.
23

(a) Determinaµi valoarea lui k pentru care f(x, y) este o densitate de repartiµie.(b) Determinaµi densitat µile de repartiµie marginale.(c) Calculaµi P (X > 1|Y < 3).
Exerciµiu 2.32 Fie variabilele aleatoare discrete X ³i Y , reprezentând sumele ce pot � câ³tigate la dou jocuri de noroc independente. Aceste variabile au tabelele de repartiµie urm toare:
X = x 5 10 20
p(x) 0.5 0.4 0.1
Y = y 1 10 15 30
p(y) 0.6 0.25 0.1 0.05
(i) S se determine repartiµiile variabilelor aleatoare m = min{X, Y } ³i M = max{X, Y }.(ii) Determinaµi valoarea a³teptat a câ³tigului cumulat din cele dou jocuri.
Exerciµiu 2.33 Vectorul aleator (X, Y ) are densitatea de repartiµie
f(x, y) =
{e−x−y pentru x ≥ 0, y ≥ 0.
0, altfel.
(a) Calculaµi probabilit µile P (X ≤ 1, Y ≤ 1), P (X + Y ≤ 1), P (X + Y > 2).(b) Calculaµi probabilit µile P (Y ≤ 1|X ≤ 1), P (X > 1|Y > 1), P (X ≥ 2Y ).(c) Calculaµi E(Y |X = 1), E(X|X = 1).
Exerciµiu 2.34 ∗ Se arunc o moned ideal în mod repetat, independent de alte arunc ri. Not m cuXk câ³tigul obµinut de un juc tor la aruncarea de rang k (k ∈ N). Acesta poate � 2 (câ³tig), dac aparestema, sau −2 (pierdere) dac apare cealalt faµ . Not m cu Sn câ³tigul cumulat din primele n arunc ri.Cunoscând valorile S1, S2, . . . , Sn (i.e., istoria câ³tigurilor pân la rangul n), s se determine valoareaa³teptat a câ³tigului la aruncarea n+ 1, i.e., E[Sn+1|Sn, Sn−1, . . . , S0].
24

3 Statistic Aplicat (L3 & S3)
Aplicaµii la TLC
Justi�care gra�c a teoremei limit central
Exerciµiu 3.1 În Figura 3.1 am reprezentat gra�c (cu bare) funcµiile de probabilitate pentru repartiµiilebinomial ³i Poisson, atunci când num rul de extrageri în schema binomial este un num r mare. Obser-v m c pentru un num r n su�cient de mare, cele dou gra�ce se suprapun. Aceasta este o "demonstraµie"gra�c a urm toarei convergenµe:
limn→∞p→0
λ=np
Ckn pk qn−k =
e−λλk
k!. (3.1)
0 5 10 15 20 25 300
0.02
0.04
0.06
0.08
0.1
0.12
Figura 3.1: B(n, p) ³i P(np) pentru n = 100, p = 0.15
În practic , proprietatea (3.1) este satisf cut pentru
n ≥ 30, p ≤ 0.1, λ = n p ≤ 0.1.
Din �gura 3.1, observ m c gra�cul are forma clopotului lui Gauss, justi�când gra�c faptul c funcµiilede probabilitate pentru binomial (albastru) ³i Poisson (ro³u) tind la densitatea de repartiµie pentrurepartiµia normal .
n = input('n='); p = input('p=');
lambda = n*p;
a=fix(lambda-3*sqrt(lambda)); b=fix(lambda+3*sqrt(lambda));
% a si b sunt valorile din problema celor 3σ
x=a:b; fB=binopdf(x,n,p); fP=poisspdf(x,lambda);
bar(x',[fB',fP'])
25

Exerciµiu 3.2 O pereche de zaruri ideale sunt aruncate de 100 de ori, în mod independent. Not m cuX variabila aleatoare ce reprezint num rul de duble ap rute.(a) Care este probabilitatea de a obµine exact 20 de duble?(b) S se calculeze P (14 ≤ X ≤ 17).(c) Aproximaµi probabilit µile de la (a) ³i (b) folosind teorema limit central .
Soluµie: (a) Avem de calculat P1 = P (X = 20). Îns X este o variabil aleatoare repartizat B(100, 1/6), a³adar rezultatul exact este:
P1 = C20100
(1
6
)20(5
6
)80
≈ 0.0679.
(b) Not m cu FX funcµia de repartiµie pentru variabila aleatoare binomial X. Atunci,
P2 = P (14 ≤ X ≤ 17) = P (X ≤ 17)− P (X < 14)
= FX(17)− FX(13)
=17∑
k=14
Ck100
(1
6
)k (5
6
)100−k≈ 0.3994.
(c) Dac aproxim m P1 folosind formula
P (X = k) ≈ 1√npq
Φ
(k − np√npq
), (k = 20, p =
1
6, q =
5
6)
obµinem:
P1 ≈1√
100 · 16 ·56
Φ
20− 100/6√100 · 16 ·
56
≈ 0.0717.
Dac aproxim m P2 folosind formula
P (X ≤ k) ≈ Θ
(k + 1
2 − np√npq
),
obµinem:
P2 = P (14 ≤ X ≤ 17) = P (X ≤ 17)− P (X ≤ 13) ≈ Θ
17 + 12 −
1006√
100 · 16 ·56
−Θ
13 + 12 −
1006√
100 · 16 ·56
≈ 0.3907.
Codul Matlab urm tor calculeaz probabilit µile cerute.
P1 = binopdf(10,100,1/6) % valoarea exacta P1
P2 = binocdf(17,100,01/6) - binocdf(13,100,1/6) % valoarea exacta P2
P1 = 6/sqrt(500)*normpdf((20-100/6)*6/sqrt(500)) % valoarea aproximativa P1
P2 = normcdf((17+0.5-100/6)*6/sqrt(500))-normcdf((13+0.5-100/6)*6/sqrt(500)) % aprox P2
Exerciµiu 3.3 Timpul de deservire la un anumit ghi³eu dintr-o banc este o variabil aleatoare repartizat exponenµial, cu media de 2 minute. �tiind c în faµ mai sunt înc 36 persoane ce a³teapt s �e servite(prima persoan la rând abia a fost chemat ) ³i c timpii de servire sunt independenµi, s se calculezeprobabilitatea de a a³tepta mai mult de o or la rând.
26

Soluµie: Not m cu Ti timpul de deservire pentru persoana din rând de pe poziµia i (i = 1, 36).
Atunci Ti sunt variabile aleatoare independente ³i identic repartizate exp(2). Not m cu S36 =
36∑i=1
Ti.
Probabilitatea c utat este
P (S36 > 60) = 1− P (S36 ≤ 60) = 1− FS36(60).
Pentru o variabil aleatoare exponenµial exp(2), media este µ = 2 ³i deviaµia standard este σ = 2.Deoarece n = 36 > 30, aplicând teorema limit central , putem concluziona c Sn ∼ N (nµ, σ
√n).
A³adar, S36 ∼ N (72, 12). Atunci, probabilitatea c utat este aproximativ
1 - normcdf(60, 72, 12) = 0.8413.
Altfel, putem scrie probabilitatea sub forma
P (S36 > 60) = 1−P (S36 ≤ 60) = 1−P(S36 − 72
12≤ 60− 72
12
)= 1−Θ(−1) = 1−normcdf(-1) = 0.8413.
√
Observaµia 3.1 Putem chiar determina ³i repartiµia exact a variabilei aleatoare S36. Folosind rezultatuldin Exerciµiul 1.22, obµinem c S36 ∼ Γ(36, 2). A³adar, probabilitatea c utat este (exact)
1 - gamcdf(60, 36, 2) = 0.8426.
Exerciµiu 3.4 Un cet µean turmentat pleac de la bar spre cas . S presupunem c punctul de plecareeste punctul O de pe axa orizontal ³i se mi³c doar pe aceast ax astfel: în �ecare unitate de timp, acestaori face un pas în faµ , cu probabilitatea 0.5, ori face un pas în spate, cu probabilitatea 0.5, independentde pa³ii anteriori. Folosind Teorema limit central , estimaµi probabilitatea ca, dup 100 de pa³i, acestanu a ajuns la mai mult de doi pa³i de punctul de plecare.
Soluµie: Fie Xi variabila aleatoare ce reprezint pasul pe care cet µeanul îl face la momentul i (i ∈ N).S atribuim X = −1, dac face un pas la stânga, ³i X = 1, dac face un pas la dreapta. A³adar, X esteo variabil aleatoare discret ce poate lua doar dou valori, −1 ³i 1, ambele cu probabilitatea 0.5. Secalculeaz cu u³urinµ , E(X) = 0 ³i D2(X) = 1. Suntem interesaµi s a� m ce se întâmpl dup 100 de
pa³i. Consider m mai întâi Sn =
n∑i=1
Xi. Atunci,
E(Sn) =n∑i=1
E(Xi) = 0 ³i D2(Sn) =n∑i=1
D2(Xi) = n,
deoarece {Xi}i=1, n sunt independente. Pentru n ≥ 30, Teorema limit central spune c
Sn − E(Sn)
D(Sn)=
Sn√n∼ N (0, 1),
echivalent cu Sn ∼ N (0,√n). Pentru n = 100, S100 ∼ N (0, 10). Probabilitatea cerut este:
P (|S100| ≤ 2) = P (−2 ≤ S100 ≤ 2) = FSn(2)− FSn(−2) ≈ 0.1585.
27

În Matlab, calcul m astfel: normcdf(2,0,10)-normcdf(-2,0,10).Folosind urm torul cod, putem simula în Matlab mi³carea aleatoare 1dim (vezi Figura 3.2):
N = input('N = '); % numar de pasi
X = 2*(rand(N,1)<0.5)-1; % simuleaza pasii la fiecare moment
S = cumsum(X); % simuleaza unde a ajuns dupa fiecare pas
plot(1:N, S, '-') % reprezinta miscarea
Z=length(find(S == 0)) % numarul de reintoarceri la bar √
Figura 3.2: Mi³care aleatoare (random walk) 1D.
Exerciµiu 3.5 Not m cu Sn suma numerelor ce apar în n arunc ri independente ale unui zar ideal.(a) Calculaµi probabilitatea P = P (S2 ≥ 6).(b) Folosiµi teorema limit central pentru a aproxima probabilit µile urm toare:
(i) P1 = P (S50 > 180);(ii) P2 = P (340 ≤ S100 ≤ 360).
Soluµie: (a) Tabloul de repartiµie pentru S2 este:
S2 :
(2 3 4 5 6 7 8 9 10 11 12136
236
336
436
536
636
536
436
336
236
136
),
de unde:P = 1− P (S2 < 6) = 1− P (S2 ≤ 5) = 1− 10
36=
13
18.
(b) Not m cu Xi num rul ap rut la aruncarea de rang i (i = 1, n).Observ m c : Xi = S1 ∼ U(6), µ = E(Xi) = 3.5, σ2 = D2(Xi) = 35
12 (i = 1, n).
Sn =n∑k=1
Xi, E(Sn) =n∑k=1
E(Xi) = n · E(Xi) = 3.5n, D2(Sn) =n∑k=1
D2(Xi) =35
12n.
Obµinem c : S50 ∼ N (175,√
8756 ), S100 ∼ N (350,
√8753 ). Pentru aproximare, scriem
P (Sn ≤ x) ≈ Θ
(x+ 0.5− E(Sn)
D(Sn)
).
28

Vom avea:
P1 = P (S50 > 180) = 1− P (S50 ≤ 180) ≈ 1−Θ
(5.5
√6
875
)≈ 0.3244.
În Matlab,1-normcdf(5.5*sqrt(6/875))
P2 = P (340 ≤ S100 ≤ 360) = P (S100 ≤ 360)− P (S100 ≤ 339)
≈ Θ
(10.5
√3
875
)−Θ
(−10.5
√3
875
)≈ 0.4613.
În Matlab,normcdf(10.5*sqrt(3/875)) - normcdf(-10.5*sqrt(3/875)) √
Exerciµiu 3.6 Arunc m o moned ideal în condiµii identice ³i not m cu νn frecvenµa absolut de apariµiea feµei cu stema din cele n repetiµii ale experimentului. Care este num rul minim de arunc ri ce trebuieefectuate pentru ca
P(∣∣∣νnn− 0.5
∣∣∣ ≤ 0.1)≥ 0.98.
Determinaµi n prin dou metode:(i) Folosind inegalitatea lui Cebâ³ev;(ii) Folosind Teorema limit central .
Soluµie: (i) Observ m c variabila aleatoare νn ∼ B(n, 0.5), de unde E(νn) = n2 ³i D2(νn) = n
4 .A³adar,
E(νnn
) = 0.5, D2(νnn
) =1
4n.
Folosim inegalitatea lui Cebâ³ev pentru X = νnn , a = 0.1. G sim c :
P(∣∣∣νnn− 0.5
∣∣∣ ≤ 0.1)≥ 1−
D2(νnn
)0.01
= 1− 25
n.
Impunem condiµia
1− 25
n≥ 0.98,
de unde obµinem c n ≥ 1250 .
(ii) C ut m n astfel încât
P(−0.1 ≤ νn
n− 0.5 ≤ 0.1
)= 0.98. (3.2)
Ne a³tept m ca valoarea lui n s �e mare, deci putem aplica Teorema limit central . Aplicând TLC,scriem c variabila aleatoare standardizat
νn − E(νn)
D(νn)=νn − 0.5n
0.5√n∼ N (0, 1).
29

Folosind aceasta, rescriem egalitatea (3.2) astfel:
0.98 = P(−0.1 ≤ νn
n− 0.5 ≤ 0.1
)= P
(−0.1
√n
0.5≤ νn − 0.5n
0.5√n≤ 0.1
√n
0.5
)= Θ
(√n
5
)−Θ
(−√n
5
)= Θ
(√n
5
)−[1−Θ
(√n
5
)]= 2Θ
(√n
5
)− 1
de unde Θ(√
n5
)= 0.99 ³i
√n5 = Θ(0.99) = z0.99 ≈ 2.33 (cuantila de ordin 0.99 pentru repartiµia normal
standard). Din ultima egalitate g sim c n ≈ 135.2974. În Matlab, calcul m astfel:
n = (5*norminv(0.99,0,1))^2
A³adar, pentru ca relaµia din enunµ s aib loc, va trebui ca n ≥ 136 .Observ m c aceast valoare este mult mai mic decât cea g sit anterior. Metoda a doua (TLC) ne d un rezultat mai bun decât cel obµinut cu ajutorul inegalit µii lui Cebâ³ev. Aici, �mai bun� se traduce prinfaptul c , folosind num r mai mic de simul ri ale experimentului, obµinem acela³i rezultat. √
Exerciµiu 3.2 O companie independent de evalu ri statistice a estimat ca un anumit candidat are 25%³anse s câ³tige alegerile locale. Dorim s efectu m un alt sondaj de opinie care s veri�ce rezultatulcompaniei. Determinaµi care ar trebui s �e volumul minim de selecµie pentru ca, cu o probabilitate de celpuµin 0.97, procentul de aleg tori ce intenµioneaz s -l voteze pe respectivul candidat se încadreaz întrevalorile 20% ³i 30%. Determinaµi volumul minim folosind cele dou metode menµionate în Exerciµiul 3.6.
Soluµie: S not m cu νn num rul de votanµi (din n ale³i aleator) care voteaz cu respectivul candidat.Se cere cel mai mic n ∈ N pentru care
P(
0.2 ≤ νnn≤ 0.3
)≥ 0.97,
echivalent cuP(∣∣∣νnn− 0.25
∣∣∣ ≤ 0.05)≥ 0.97.
(i) Observ m c variabila aleatoare νn ∼ B(n, 0.25), de unde E(νn) = n4 ³i D2(νn) = 3n
16 . A³adar,
E(νnn
) = 0.25, D2(νnn
) =3
16n.
Folosim inegalitatea lui Cebâ³ev pentru X = νnn , a = 0.05. G sim c :
P(∣∣∣νnn− 0.25
∣∣∣ ≤ 0.05)≥ 1−
D2(νnn
)0.052
= 1− 75
n.
Impunem condiµia
1− 75
n≥ 0.97,
de unde obµinem c n ≥ 2500 .
(ii) C ut m n astfel încât
P(−0.05 ≤ νn
n− 0.25 ≤ 0.05
)= 0.97. (3.3)
30

Ne a³tept m ca valoarea lui n s �e mare, deci putem aplica Teorema limit central . Aplicând TLC,scriem c variabila aleatoare standardizat
νn − E(νn)
D(νn)= 4
νn − 0.25n√3n
∼ N (0, 1).
Folosind aceasta, rescriem egalitatea (3.3) astfel:
0.97 = P(−0.05 ≤ νn
n− 0.25 ≤ 0.05
)= P
(−0.05× 4
√n
3≤ 4
νn − 0.25n√3n
≤ 0.05× 4
√n
3
)= Θ
(0.2
√n
3
)−Θ
(−0.2
√n
3
)= Θ
(0.2
√n
3
)−[1−Θ
(0.2
√n
3
)]= 2Θ
(0.2
√n
3
)− 1
de unde Θ(0.2√
n3
)= 0.985 ³i 0.2
√n3 = z0.985 ≈ 2.17 (cuantila de ordin 0.985 pentru repartiµia normal
standard). Din ultima egalitate g sim c n ≈ 353.1969. În Matlab, calcul m astfel:
n = 3*(norminv(0.985,0,1)/0.2)^2
A³adar, pentru ca relaµia din enunµ s aib loc, va trebui ca n ≥ 354 .Observ m, din nou, c aceast valoare este mult mai mic decât cea g sit anterior. √
Exerciµiu 3.7 Urm torul set de date reprezint preµurile (în mii de euro) a 20 de case, vândute într-oanumit regiune a unui ora³:
113 60.5 340.5 130 79 475.5 90 100 175.5 100
111.5 525 50 122.5 125.5 75 150 89 100 70
Determinaµi amplitudinea, media, mediana, modul, cuartilele ³i distanµa intercuartilic pentru acestedate. Care valoare este cea mai reprezentativ ?
Soluµie: Rearanj m datele în ordine cresc toare:
50 60.5 70 75 79 89 90 100 100 100 111.5
113.5 122.5 125.5 130 150 175.5 340.5 475.5 525
Amplitudinea este 525 − 50 = 475, media lor este 154.15, mediana este 105.75, modul este 100, cuartilainferioar este Q1 = 84, cuartila superioar este Q3 = 140, Q2 = Me ³i distanµa intercuartilic ested = Q3 −Q1 = 56.Mediana este valoarea cea mai reprezentativ în acest caz, deoarece cele mai mari trei preµuri, anume340.5, 475.5, 525, m resc media ³i o fac mai puµin reprezentativ pentru celelalte date. În cazul în caresetul de date nu este simetric, valoarea median este cea mai reprezentativ valoare a datelor. ÎnMatlab,
31

X = [113; 60.5; 340.5; 130; 79; 475.5; 90; 100; 175.5; 100; ...
111.5; 525; 50; 122.5; 125.5; 75; 150; 89; 100; 70
a = range(X); m = mean(X); Me = median(X); Mo = mode(X);
Q1 = quantile(X,0.25); Q2 = quantile(X,0.5); Q3 = quantile(X,0.75); d = Q3 - Q1;√
În lµimea (în cm) frecvenµa[0, 5) 5[5, 10) 13[10, 15) 23[15, 20) 17[20, 25) 10[25, 30) 2
Tabela 3.1:
Exerciµiu 3.8 Consider m datele din Tabelul 3.1. Determinaµi amplitudinea, media, mediana, modul,dispersia ³i prima cuartil pentru aceste date.
Soluµie: Amplitudinea este a = 30. Media este
x =
∑(x · f)
n=
1
70(2.5× 5 + 7.5× 13 + 12.5× 23 + 17.5× 17 + 22.5× 10 + 27.5× 2) = 13.9286.
Dispersia este:
s2 =1
n− 1(∑
(x2 · f)− n · x2)
=1
69(2.52 × 5 + 7.52 × 13 + 12.52 × 23 + 17.52 × 17 + 22.52 × 10 + 27.52 × 2 − 70 · 13.92862)
= 37.06.
Clasa median este clasa [10, 15). Deoarece în clasele anterioare ([0, 5) ³i [5, 10)) se a� deja 5 + 13 = 18date mai mici decât mediana, pentru a a�a în lµimea median a plantelor (i.e., acea valoare care estemai mare decât în lµimea a 35 de plante ³i mai mic decât în lµimea a alte 35 de plante), va trebuis determin m acea valoare din clasa median ce este mai mare decât alte 17 valori din aceast clas .A³adar, avem nevoie de a determina o fracµie 17
23 dintre valorile clasei mediane. În concluzie, valoareamedian este
Me = 10 +17
23× 5 = 13.6957.
Clasa modal este [10, 15), iar modul este valoarea central a clasei, 12.5.Calcul m acum prima cuartil . Împ rµim setul de date în patru. Prima cuartil este acea valoare dintrecele 70 care este mai mare decât alte 18 valori, adic Q1 = 10. Implementarea în Matlab:
x = [2.5; 7.5; 12.5; 17.5; 22.5; 27.5]; % centrele claselor
f = [5; 13; 23; 17; 10; 2]; % frecventele
n = 70; m = sum(x.*f)/n; s2 = (sum(x.^2.*f) - n*m^2)/(n-1); √
32

Exerciµiu 3.9 O companie de asigur ri a înregistrat num rul de accidente pe s pt mân ce au avut locîntr-un anumit sat, în decurs de un an (52 de s pt mâni). Acestea sunt, în ordine:
1, 0, 2, 3, 4, 1, 4, 0, 4, 2, 3, 0, 3, 3, 1, 2, 3, 0, 1, 2, 3, 1, 3, 2, 3, 2,
4, 3, 4, 2, 3, 4, 4, 3, 2, 4, 1, 2, 0, 1, 3, 2, 0, 4, 1, 0, 2, 2, 4, 1, 2, 2
(a) Construiµi un tabel de frecvenµe care s conµin num rul de accidente, frecvenµele absolute ³i relative.(b) G siµi media empiric , mediana ³i deviaµia standard empiric .(c) Reprezentaµi prin bare rezultatele din tabelul de frecvenµe.(d) G siµi ³i reprezentaµi gra�c (cdfplot) funcµia de repartiµie empiric a num rului de accidente.(e) Aproximaµi probabilitatea ca într-o s pt mân aleas la întâmplare s � avut cel puµin dou accidente.
Soluµie: (a) Tabelul de frecvenµe este Tabelul 3.2.
num rul 0 1 2 3 4
frecv. abs. 7 9 14 12 10
frecv. rel. 0.1346 0.1731 0.2692 0.2308 0.1923
Tabela 3.2: Tabel de frecvenµe pentru Exerciµiu 3.9
(b) Avem:
x =
52∑i=1
xi = 2.1731, s =
√√√√ 1
51
52∑i=1
(xi − x)2 = 1.3094, Me = 2.
(c) Reprezentarea prin bare a num rului de accidente ³i gra�cul lui F ∗n(x) sunt reprezentate în Figura3.3.(d) Funcµia de repartiµie empiric este:
F ∗n(x) = P (X ≤ x) =
0, dac x < 0;752 , dac x ∈ [0, 1);1652 , dac x ∈ [1, 2);3052 , dac x ∈ [2, 3);4252 , dac x ∈ [3, 4);
1, dac x ≥ 4.
Probabilitatea cerut la (e) este:
P (X ≥ 2) = 1− P (X < 2) = 1− P (X ≤ 1) ≈ 1− F ∗n(1) = 1− 16
52= 0.6923.
Codul Matlab pentru calcule ³i gra�ce este:
Y = [zeros(7,1);ones(9,1);2*ones(14,1);3*ones(12,1);4*ones(10,1)];
m = mean(Y); s = std(Y); Me = median(Y);
subplot(1,2,1); bar(0:4,[7,9,14,12,10]) % graficul cu bare
subplot(1,2,2); cdfplot(Y) % graficul functiei de repartitie empirice √
33
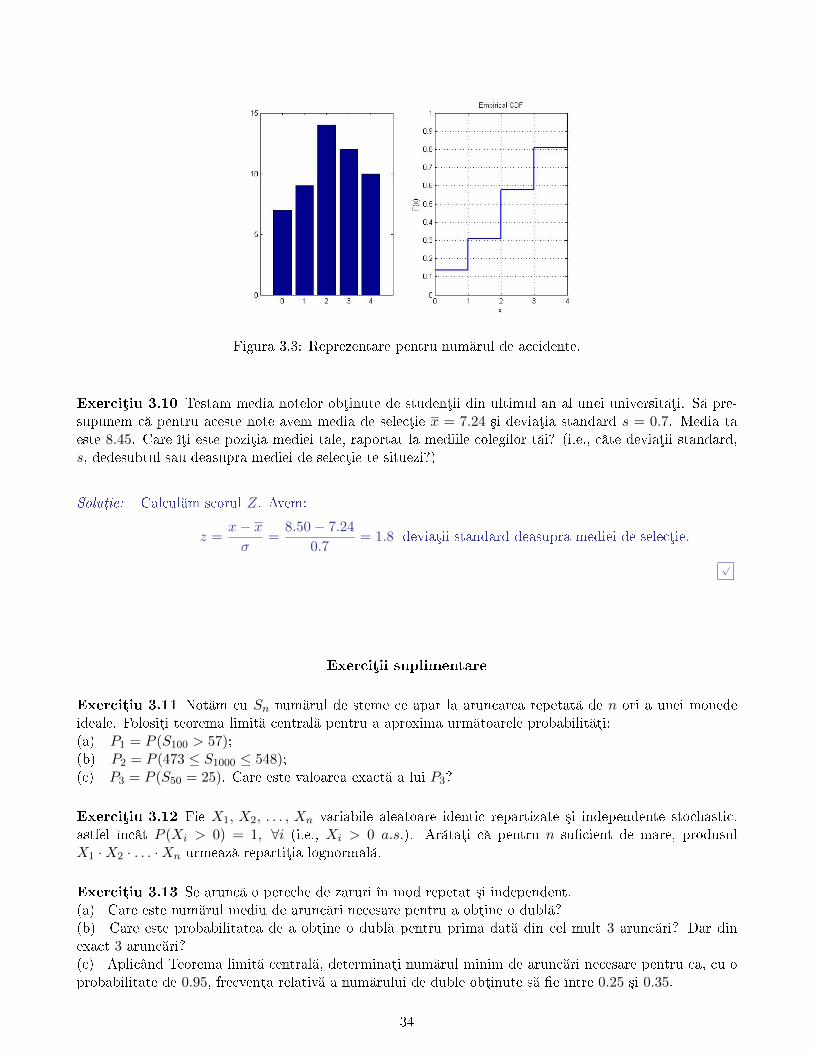
Figura 3.3: Reprezentare pentru num rul de accidente.
Exerciµiu 3.10 Test m media notelor obµinute de studenµii din ultimul an al unei universit µi. S pre-supunem c pentru aceste note avem media de selecµie x = 7.24 ³i deviaµia standard s = 0.7. Media taeste 8.45. Care îµi este poziµia mediei tale, raportat la mediile colegilor t i? (i.e., câte deviaµii standard,s, dedesubtul sau deasupra mediei de selecµie te situezi?)
Soluµie: Calcul m scorul Z. Avem:
z =x− xσ
=8.50− 7.24
0.7= 1.8 deviaµii standard deasupra mediei de selecµie.
√
Exerciµii suplimentare
Exerciµiu 3.11 Not m cu Sn num rul de steme ce apar la aruncarea repetat de n ori a unei monedeideale. Folosiµi teorema limit central pentru a aproxima urm toarele probabilit µi:(a) P1 = P (S100 > 57);(b) P2 = P (473 ≤ S1000 ≤ 548);(c) P3 = P (S50 = 25). Care este valoarea exact a lui P3?
Exerciµiu 3.12 Fie X1, X2, . . . , Xn variabile aleatoare identic repartizate ³i independente stochastic,astfel încât P (Xi > 0) = 1, ∀i (i.e., Xi > 0 a.s.). Ar taµi c pentru n su�cient de mare, produsulX1 ·X2 · . . . ·Xn urmeaz repartiµia lognormal .
Exerciµiu 3.13 Se arunc o pereche de zaruri în mod repetat ³i independent.(a) Care este num rul mediu de arunc ri necesare pentru a obµine o dubl ?(b) Care este probabilitatea de a obµine o dubl pentru prima dat din cel mult 3 arunc ri? Dar dinexact 3 arunc ri?(c) Aplicând Teorema limit central , determinaµi num rul minim de arunc ri necesare pentru ca, cu oprobabilitate de 0.95, frecvenµa relativ a num rului de duble obµinute s �e între 0.25 ³i 0.35.
34

Exerciµiu 3.14 Un zar ideal este aruncat de 48 de ori. Utilizaµi Teorema limit central pentru aaproxima:(a) probabilitatea ca suma punctelor obµinute s �e mai mare decât 165.(b) probabilitatea ca suma punctelor obµinute s �e între 160 ³i 175.
Exerciµiu 3.15 Dac X ∼ P(1), determinaµi cel mai mic num r natural n pentru care P (X < n) ≥ 0.99.
Exerciµiu 3.16 Fie X o variabil aleatoare cu µ = E(X) = 1 ³i σ =√D2(X) = 0.2. Determinaµi
marginile inferioare pentru urm toarele probabilit µi:
P (0.5 ≤ X ≤ 1.5), P (|X − 1| < 2).
Exerciµiu 3.17 Consider m ³irul de variabile aleatoare independente {Xn}n∈N∗ care pot lua urm toarelevalori: −
√n, 0,
√n, cu probabilit µile:
P (X1 = 0) = 1, P (Xk = −√k) = P (Xk =
√k) =
1
k³i P (Xk = 0) = 1− 2
k, k = 2, 3, 4, . . . .
Ar taµi c acest ³ir satisface legea slab a numerelor mari.
Exerciµiu 3.18 Teorema limit central a�rm c suma unui ³ir de v.a. independente ³i identic reparti-zate are o form normal , indiferent ce tip de repartiµie au variabilele din ³ir. Dorim s dovedim aceastagra�c, prin simul ri în Matlab, alegând o funcµie de repartiµie oarecare. S alegem 40 de numere dinintervalul [0, 1] ce au una dintre densit µile de repartiµie de mai jos. Calcul m suma lor, notat S40.Repet m acest eperiment de 1000 de ori ³i realiz m un gra�c cu bare (20 de bare) a rezultatelor obµinute.În acela³i sistem de coordonate, desen m densitatea de repartiµie N (µ, σ), unde µ = µ(S40) ³i σ = σ(S40).Urm riµi cât de bine se potrivesc cele dou gra�ce.
(a) f(x) = 2x; (b) f(x) = 3x2; (c) f(x) = 2− 4|x− 0.5|.
Exerciµiu 3.19 Cât de mare ar trebui s �e n, astfel încât suma Sn din exerciµiul precedent s �eaproximativ normal ? R spundeµi al aceast întrebare alegând, pe rând, câte n = 1, 5, 15, 20 numerealeatoare în [0, 1], pentru �ecare dintre densit µile de repartiµie de la (a) − (c), calculaµi de �ecare dat Sn ³i repetaµi experimentul de 1000 de ori. Determinaµi, de �ecare dat , pe acel n pentru care obµineµicea mai bun potrivire între gra�cul cu bare ³i gra�cul densit µii de repartiµie.
35

4 Statistic Aplicat (L4 & S4)
Utilizând funcµiilelegernd(< param >, m, n) (4.1)
³irandom(′lege′, < param >,m, n) (4.2)
introduse anterior, putem genera variabile aleatoare de selecµie de un volum dat, n. Pentru aceasta, vatrebui ca m = n în (4.1) ³i (4.2). Astfel, comanda
random('norm',100,6, 50,50)
genereaz o matrice p tratic , de dimensiune 50. Putem privi aceast matrice aleatoare astfel: �ecarecoloan a sa corespunde unei variabile aleatoare de selecµie de volum 50, c reia îi preciz m cele 50 devalori ale sale obµinute la o observaµie. În total, avem 50 de coloane, corespunzând celor 50 de variabilealeatoare de selecµie. A³adar, am generat 50 de variabile aleatoare de selecµie de volum 50, ce urmeaz repartiµia N (100, 6).
Exerciµiu 4.1 Presupunem c masa medie a unor batoane de ciocolat produse de o ma³in este ocaracteristic X ∼ N (100, 0.65). În vederea veri�c rii parametrilor ma³inii, dintre batoanele primiteîntr-un depozit s-au ales la întâmplare 1000 de buc µi.(i) Calculaµi media ³i deviaµia standard ale mediei de selecµie, X.(ii) Calculaµi P (98 < X < 102).(iii) Un baton este declarat rebut dac masa sa este sub 98 de grame sau peste 102 de grame. Calculaµiprocentul de rebuturi avute.
Soluµie: (i) �tim c media de selecµie X urmeaz repartiµia N (100, 0.65/√
1000). A³adar,
µX = 100, σX ≈ 0.02.
(ii) Probabilitatea P1 = P (98 < X < 102) este
P1 = P (X < 102)− P (X ≥ 98) = FX(102)− FX(98) ≈ 1.
(iii) Probabilitatea de a avea un rebut este:
P2 = P({X < 98}
⋃{X > 102}
)= P (X < 98) + P (X > 102)
= FX(98) + 1− FX(102),
de unde, procentul de rebuturi este
r = P2 · 100% ≈ 0.2091%,
adic aproximativ 2 rebuturi la 1000 de batoane.
36

În Matlab, acestea pot � calculate astfel:
mu = 100; sigma = 0.65; n=1000; % n = volumul selectiei
X = normrnd(mu, sigma, n,n); % am generat selectia de volum n
Xbar = mean(X); S = sigma/sqrt(n); % Xbar = media de selectie
m = mean(Xbar); s = std(Xbar); % media si deviatia standard
P1 = normcdf(102, mu, S) - normdf(98, mu, S);
P2 = normcdf(98,mu,sigma) + 1 - normcdf(102,mu,sigma);
rebut = P2*100; √
Exerciµiu 4.2 �amponul marca Fairhair se vinde acum în supermarket în trei m rimi (volume): 250ml,500ml ³i 1 litru. Treizeci la sut dintre cump r torii acestui produs cump r �aconul de 250ml, 50% pecel de 500ml, iar restul pe cel de 1 litru. Not m cu X volumul unui �acon de Fairhair. Fie X1 ³i X2
volumele �acoanelor cump rate de doi dintre clienµi, ale³i la întâmplare.(a) Determinaµi repartiµia mediei de selecµie X. Calculaµi media E(X) ³i comparaµi-o cu µ = E(X).(b) Calculaµi D2(X) ³i comparaµi-o cu σ2 = D2(X).(c) Calculaµi probabilitatea P (X ≥ 500).(d) Care ar trebui s �e volumul minim de cump r tori pentru ca media de selecµie s satisfac relaµiaP (X ≥ 500) > 0.75?
Soluµie: Fie v.a. X ce reprezint volumul ales de un cump r tor. Atunci distribuµia lui X este:
x 250 500 1000
p(x) 0.3 0.5 0.2.
Deoarece X1 ³i X2 sunt variabile aleatoare de selecµie, ele sunt independente ac si au aceea³i repartiµie caX. Avem c µ = E(X) = 525 ³i σ = D(X) = 25
√109.
(a) Media de selecµie este X = (X1 +X2)/2. Repartiµia sa este:
x 250 375 500 625 750 1000
p(x) 0.09 0.3 0.25 0.12 0.2 0.04.
Media este µX = E(X) = E(X) = µ = 525.
(b) σX =σ√2
= 25
√109
2< σ.
(c) P (X ≥ 500) = 0.25 + 0.12 + 0.2 + 0.04 = 0.61.
(d) În general, X ∼ N(µ,
σ√n
), de unde g sim c
X − µσ√n
∼ N (0, 1) A³adar,
0.75 < P (X ≥ 500) = 1−P (X ≤ 500) = 1−P
(X − µ
σ√n
≤ 500− µσ√n
)= 1−Θ
(500− µ
σ√n
)= 1−Θ
(−√
n
109
),
de unde
Θ
(−√
n
109
)< 0.25 ³i −
√n
109< Θ−1(0.25) = z0.25 = −0.6745, de unde n > 109 · z20.25 ≈ 50. √
37

Exerciµiu 4.3 În vederea studierii unei caracteristici X ce are densitatea de repartiµie
f(x) =
{2x, x ∈ (0, 1);
0, x 6∈(0, 1).
s-a efectuat o selecµie repetat de volum n = 100. Se cere s se determine probabilitatea P (X < 0.65),unde X este media de selecµie.
Soluµie: Se observ cu u³urinµ c f(x) îndepline³te condiµiile unei funcµii de repartiµie, adic estem surabil , nenegativ ³i ∫
Rf(x) dx =
∫ 1
02x dx = 1.
Pentru a calcula probabilitatea cerut , avem nevoie de E(X) ³i D2(X). Avem:
E(X) =
∫Rx f(x) dx =
∫ 1
02x2 dx =
2
3,
D2(X) = E(X2)− (E(X))2 =
∫Rx2 f(x) dx− 4
9=
1
18.
A³adar, repartiµia mediei de selecµie X este
X ∼ N(
2
3,
1√18 ·√
100
).
Putem acum calcula probabilitatea cerut . Ea este:
P (X < 0.65) = FX(0.65) = normcdf(0.65, 2/3, 1/(30*sqrt(2))) = 0.2398.
√
Exerciµiu 4.4 Not m cu P1, P2, . . . , P9 preµurile oferite de 9 ofertanµi la o licitaµie public pentru vinde-rea unui anumit tablou. Presupunem c acestea sunt variabile aleatoare repartizate uniform U(1000, 2000).Obiectul se va vinde celui care vine cu oferta cea mai mare. Determinaµi valoarea a³teptat a preµuluiobµinut pentru acest tablou.
- Deoarece P ∼ U(1000, 2000), atunci
f(x) =
{1
1000 , dac 1000 < x < 2000
0, dac x 6∈ (1000, 2000)
³iF (x) =
0, dac x ≤ 1000x−10001000 , dac 1000 < x < 2000
1, dac x ≥ 2000
Funcµia de repartiµie a statisticii de ordine M = P(9) = max{P1, P2, . . . , P9} este
FT(9)(x) = [F (x)]9, x ∈ R.
Densitatea de repartiµie a statisticii de ordine M este
fT(9)(x) = F ′T(9)(x) = 9[F (x)]8f(x), x ∈ R.
38

Preµul de vânzare a³teptat este media variabilei aleatoare M ,
E(Y ) =
∞∫∞
xfY (x)dx =9
1000
2000∫1000
x
(x− 1000
1000
)8
dx = 1900.
√
Exerciµiu 4.5 Becurile produse de un manufacturier A au timpul mediu de funcµionare de 1400 ore,cu deviaµia standard de 200 ore, în timp ce timpul mediu de funcµionare ale becurilor produse de unmanufacturier B au timpul mediu de funcµionare de 1200 ore, cu deviaµia standard de 100 ore. Se faceo selecµie de 125 becuri din �ecare tip ³i se testeaz becurile alese. Pentru selecµiile date, care esteprobabilitatea ca becurile produse de A au un timp mediu de viaµ mai mare cu(a) 160 de ore;(b) 250 de ore;mai mare decât timpul mediu de funcµionare ale becurilor produse de B?(c) Care este probabilitatea ca timpul mediu de funcµionare al becurilor selectate din tipul A s �ecuprins între 1375 de ore ³i 1425 de ore?(d) Presupunem c timpul mediu de funcµionare ale becurilor produse de A este o v.a. normal . Alegemla întâmplare un bec de tipul A. Care este probabilitatea ca timpul s mediu de funcµionare s �e cuprinsîntre 1375 de ore ³i 1425 de ore?
Soluµie: Not m cu T1 ³i T2 cele dou timpuri de funcµionare. Avem c
µT1 = 1400, σT1 = 200 ³i µT2 = 1200, σT2 = 100.
Pentru o selecµie de volum n = 125 (vom considera c selecµia este repetat , deoarece volumul selecµieieste mult mai mic decât num rul becurilor produse de �ecare manufacturir), avem c :
T1 ∼ N (1400,200
5√
5) ³i T2 ∼ N (1200,
100
5√
5).
Diferenµa mediilor de selecµie este o v.a. repartizat astfel:
T1 − T2 ∼ N (200, 20).
(a) Probabilitatea cerut este:
P (T1 − T2 > 160) = 1− FT1−T2(160)
= 1 - normcdf(160,200,20) = 0.9772.
(b) Probabilitatea cerut este:
P (T1 − T2 > 250) = 1− FT1−T2(250)
= 1 - normcdf(250,200,20) = 0.0062.
(c) Probabilitatea cerut este:
P (1375 ≤ T1 ≤ 1425) = FT1(1425)− FT1(1375)
= normcdf(1425,1400,8*sqrt(5)) - normcdf(1375,1400,8*sqrt(5))
= 0.8377.
39

(c) Probabilitatea cerut este:
P (1375 ≤ T1 ≤ 1425) = FT1(1425)− FT1(1375)
= normcdf(1425,1400,200) - normcdf(1375,1400,200)
= 0.0995.
√
Exerciµiu 4.6 Dou avioane zboar în aceea³i direcµie pe dou coridoare paralele. La momentul t = 0,primul avion are un avans de 6km în faµa celui de-al doilea. Presupunem c viteza primului avion (m surat în km/h) este o v.a. repartizat normal, cu media 510 ³i deviaµia standard 10, iar viteza celui de-al doileaavion este normal repartizat , cu media 500 ³i deviaµia standard 10.(a) Care este probabilitatea ca, dup 4 ore de zbor, al doilea avion s nu îl � ajuns pe primul?(b) Determinaµi probabilitatea ca, dup 4 ore de zbor, distanµa dintre cele dou avioane s �e de celmult 5km.
Soluµie: Not m cu v1 ³i v2 cele dou viteze. Avem c
v1 ∼ N (510, 10) ³i v2 ∼ N (500, 10).
Dup 4 ore de zbor (adic avem câte o selecµie de volum 4 pentru �ecare v.a., anume {v1i}i, {v2i}i, i =1, 4), mediile de selecµie for satisface:
v1 ∼ N (510, 5) ³i v2 ∼ N (500, 5).
Diferenµa mediilor de selecµie este o v.a. repartizat astfel:
v1 − v2 ∼ N (10, 5√
2).
(a) Evenimentul ca, dup 4 ore de zbor, al doilea avion s nu îl � ajuns pe primul este
{4∑i=1
v1i + 6−4∑i=1
v2i > 0} = {4v1 − 4v2 + 6 > 0}.
Probabilitatea acestui eveniment este:
P ({4v1 − 4v2 + 6 > 0}) = P ({v1 − v2 > −3
2}) = 1− P ({v1 − v2 ≤ −
3
2}) = 1− Fv1−v2(−3
2)
= 1 - normcdf(-3/2,10,5*sqrt(2)) = 0.9481.
(b) Evenimentul ca, dup 4 ore de zbor, distanµa dintre cele dou avioane s �e de cel mult 5km este{|4v1 − 4v2 + 6| ≤ 5}. Probabilitatea acestui eveniment este:
P ({|4v1 − 4v2 + 6| ≤ 5}) = P
(−11
4≤ v1 − v2 ≤ −
1
4
)= Fv1−v2
(−1
4
)− Fv1−v2
(−11
4
)= normcdf(-1/4,10,5*sqrt(2)) - normcdf(-11/4,10,5*sqrt(2))
= 0.0379.
√
40

Exerciµiu 4.7 S se arate c dispersia de selecµie ³i dispersia de selecµie modi�cat au urm toarelepropriet µi:
E[d2∗(X)] = D2(X), E[d2(X)] =n− 1
nD2(X), ∀n ∈ N∗.
- Not m cu µ = E(X). Avem c :
E(d2(X)) = E
(1
n
n∑i=1
(Xi −X)2
)=
1
nE
(n∑i=1
(Xi − µ+ µ−X)2
)
=1
nE
(n∑i=1
(Xi − µ)2 − 2(X − µ)
n∑i=1
(Xi − µ) +
n∑i=1
(X − µ)2
)
=1
n
[n∑i=1
E[(Xi − µ)2
]− 2nE
((X − µ)2
)+ nE
[(X − µ)2
]]
=1
n
[nE[(X − µ)2
]− nE
((X − µ)2
)]=
1
n
[nD2(X)− nD2(X)
]= D2(X)− D2(X)
n=n− 1
nD2(X).
Totodat , se observ c E[d2∗(X)] = D2(X). √
Exerciµii suplimentare
Exerciµiu 4.8 Un anumit component electric, care este strict necesar pe un satelit ce orbiteaz P mântul,are durata medie de funcµionare continu de 10 zile.(a) Care este probabilitatea ca durata de funcµionare continu a unui astfel de component s dep ³easc 10 zile? (se consider c timpul de funcµionare este o v.a. exponenµial ).(b) De îndat ce se defecteaz , acest component va trebui înlocuit imediat cu unul nou, identic. Care estenum rul minim de componente de acest tip ce trebuie luate la plecarea într-o misiune de un an, pentruca probabilitatea ca satelitul s devin inoperativ din cauza epuiz rii tuturor rezervelor funcµionabile s �e mai mic de 0.02?
Exerciµiu 4.9 Consider m funcµia f : R −→ R, dat prin
f(x) =
{a e−x , x > 0;
0 , x ≤ 0.
(i) G siµi valoarea parametrului a pentru care f(x) este o densitate de repartiµie;(ii) Fie X v.a. ce are densitatea de repartitie gasit . Calculaµi probabilitatea P (X > 1);(ii) Fie {X1, X2, . . . , X100} variabilele aleatoare de selecµie repetat asupra lui X si �e X media deselecµie. Calculaµi P
(X > 1
)³i P
(X = a
).
Exerciµiu 4.10 Determinaµi dispersia statisticii dispersie de selecµie d2∗(X).
Exerciµiu 4.11 Presupunem c timpul necesar pescuirii unui pe³te dintr-un anumit iaz este o variabil aleatoare repartizat exp(10min). La un concurs, ³apte pescari se întrec în a prinde câte un pe³te,câ³tigând cel care l-a prins primul.(i) Care este probabilitatea ca primul pe³te s �e prins în mai puµin de 7 minute?(ii) Care este probabilitatea ca toµi cei 7 pescari s � prins câte un pe³te în mai puµin de 15 minute?
41

Exerciµiu 4.12 (a) Ar taµi c dac U ∼ U(0, 1), atunci
X = µ+ λ tan
[π
(U − 1
2
)]∼ C(λ, µ).
(b) Generaµi înMatlab o selecµie de 500 de variabile aleatoare ce urmeaz repartiµia Cauchy C(100, 10).
Exerciµiu 4.13 Cantitatea de ap consumat de Ana în �ecare zi se presupune a � o v.a. normal cumedia 2 l ³i deviaµia standard 300ml, independent de zi. Ana a cump rat azi un bax de 6 sticle a câte2.5 litri de ap �ecare. Presupunând c Ana bea doar din apa cump rat azi, care este probabilitatea caea s mai aib ap din acest stoc ³i dup o s pt mân (7 zile, inclusiv cea de azi)?
Exerciµiu 4.14 Masa medie a unui bagaj ce trece pe la serviciul de check-in al aeroportului din Ia³i pentrucursa de Viena este o v.a. cu media 21 kg ³i deviaµia standard 3.5 kg pentru pasagerii de la clasa economic³i o v.a. cu media 12 kg ³i deviaµia standard 4.5 kg pentru pasagerii de la clasa business. Presupunem c aceste valori sunt ale unor variabile aleatoare independente de la un pasager la altul, indiferent de clas .(a) Dac într-o anumit curs se a� 16 pasageri la clasa business ³i 81 pasageri la clasa economic, careeste valoarea a³teptat ³i deviaµia standard a masei totale de bagaje ale pasagerilor din acel avion?(b) Care este probabilitatea ca masa total de bagaje ale celor 97 de pasageri pentru aceast curs s nu dep ³easc 2000 kg?(c) Se aleg la întâmplare bagajele a 6 pasageri de la clasa economic ³i a 10 pasageri de la clasa business³i se cânt resc. Care este probabilitatea ca diferenµa maselor bagajelor dintre cele dou clase s �e maimic de 20 kg?
Exerciµiu 4.15 Batoanele de ciocolat produse de o anumit �rm cânt resc �ecare 50 g, cu deviaµiastandard 0.02 g. Se aleg la întâmplare dou loturi de batoane de ciocolat , �ecare având 100 de buc µi.Care este probabilitatea ca masele totale ale celor dou loturi s nu difere prin mai mult de 5 g?
Exerciµiu 4.16 Presupunem c timpul de a³teptare a autobuzului în staµie este o v.a. repartizat U(0, 10) pentru orele dimineµii, iar timpul de a³teptare a autobuzului în staµie la orele serii este o v.a.repartizat U(0, 8). Toµi timpii sunt independenµi între ei.(a) Dac într-o anumit s pt mân luaµi autobuzul în �ecare zi (5 zile lucr toare), care este timpul totalmediu pe care v a³teptaµi s -l petreceµi în staµia de autobuz în întreaga s pt mân ?(b) Care este abaterea standard a timpului total petrecut în staµia de autobuz în întreaga s pt mân ?(c) Determinaµi valoarea medie ³i abaterea standard a diferenµei dintre timpul total petrecut dimineaµa³i timpul total petrecut seara în staµia de autobuz în întreaga s pt mân ?
Exerciµiu 4.17 Fie X1, X2, . . . , X10 o selecµie repetat de volum 10 de v.a. repartizate U(0, 1). G siµimedia ³i deviaµia standard pentru primele dou statistici de ordine, X(1) ³i X(2).
Exerciµiu 4.18 Tudor ³i Maria au hot rât s se întâlneasc între orele 1:00p.m. ³i 2:00p.m. în faµa unuirestaurant local, pentru a lua prânzul. Not m cu X timpul sosirii Mariei ³i cu Y timpul sosirii lui Tudor.Presupunem c X ³i Y sunt independente, �ecare �ind uniform repartizate U(1, 2).(a) Care este repartiµia comun a vectorului (X, Y )?(b) Care este probabilitatea ca amândoi s ajung între 1:15 ³i 1:30?(c) Dac primul care ajunge a³teapt 15 minute, iar dac cel talt nu sose³te în acest timp pleac , careeste probabilitatea ca ei s se întâlneasc în faµa acelui restaurant?(d) Dac Tudor a ajuns la 1:15 p.m., care este probabilitatea ca Maria s � ajuns pân la 1:30p.m.?(e) Determinaµi probabilitatea ca primul sosit s ajung pân la ora 1:15p.m.(f) Determinaµi probabilitatea ca amândoi s soseasc pân la ora 1:15p.m.
42

5 Statistic Aplicat (L5 & S5)
Estimaµii prin Matlab
Estimaµii punctuale
Estimarea parametrilor prin metoda verosimilit µii maxime poate � realizat în Matlab folosind funcµiamle. Formatul general al funcµiei este:
[p, pCI] = mle(X,'distribution','lege','nume_1','val_1','nume_2','val_2',...)
unde:
• p este parametrul (sau parametrii) (sau vectorul de parametri) ce urmeaz a � estimat punctual;
• pCI este variabila de memorie pentru intervalul (intervalele) de încredere ce va � estimat;
• X este un vector ce conµine datele ce urmeaz a � analizate;
• distribution este parte din formatul comenzii iar lege poate � oricare dintre legile din Tabelul1.1;
• nume_i/val_i sunt perechi opµionale de argumente/valori, dintre care amintim:
� alpha reprezint nivelul de con�denµ pentru intervalul de încredere. Valoarea implicit înMatlab este α = 0.005;
� ntrials (utilizat doar pentru repartiµia binomial , reprezint num rul de repetiµii ale expe-rimentului.
Dac urm rim s estim m parametrii unei caracteristici gaussiene, atunci putem folosi comanda simpli�-cat :
[p, pCI] = mle(X)
f r a mai preciza legea de distribuµie.
vârsta frecvenµa frecvenµa relativ frecvenµa cumulat vârsta medie[18, 25) 34 8.83% 8.83% 21.5[25, 35) 76 19.74% 28.57% 30[35, 45) 124 32.21% 60.78% 40[45, 55) 87 22.60% 83.38% 50[55, 65) 64 16.62% 100.00% 60Total 385 100% - -
Tabela 5.1: Tabel cu frecvenµe pentru rata somajului.
De exemplu, s lu m drept obiect de lucru datele din Tabelul 5.1. O estimare a parametrilor µ ³i σ prinmetoda verosimilit µii maxime este
43

X=[7*rand(34,1)+18;10*rand(76,1)+25;10*rand(124,1)+35;10*rand(87,1)+45;10*rand(64,1)+55]
[p, pCI] = mle(X)
³i obµinem estim rile:
p =
41.9716 12.0228 % estimari punctuale pentru µ si σ
pCI =
40.7653 11.2439 % intervale de incredere
43.1779 12.9547
unde prima coloan reprezint estimarea punctual ³i un interval de încredere pentru µ, iar a doua coloan estimarea punctual ³i un interval de încredere pentru σ.
Estim ri punctuale ³i cu intervale de încredere mai putem obµine ³i utilizând funcµia
LEGEfit(X,alpha)
unde, în locul cuvântului LEGE punem o lege de probabilitate ca în Tabelul 1.1, X reprezint observaµiile³i alpha este nivelul de con�denµ . (Exemple: normfit, binofit, poissfit, expfit etc).
Exerciµiu 5.1 S se arate c media de selecµie X constituie un estimator absolut corect ³i e�cient alparametrului λ din repartiµia Poisson P(λ).
Soluµie: Deoarece X ∼ P(λ), urmeaz c E(X) = D2(X) = λ. Atunci,
E(X) =1
nE
(n∑i=1
Xi
)=
1
n
(n∑i=1
E(Xi)
)=
1
n(n∑i=1
λ) = λ,
D2(X) =1
n2D2
(n∑i=1
Xi
)=
1
n2
(n∑i=1
D2(Xi)
)=
1
n2(n∑i=1
λ) =λ
n−→ 0, când n→∞.
A³adar, conform de�niµiei, media de selecµie este un estimator absolut corect pentru parametrul λ. Funcµiade probabilitate este
f(x, λ) = e−λλx
x!, x ∈ N,
de unde∂ ln f(x, λ)
∂λ= −1 +
x
λ.
Calcul m e�cienµa estimatorului. Avem
In(λ) = n · E
([∂ ln f(X, λ)
∂λ
]2)
= nE(
1− 2X
λ+X2
λ2
)= n
(1− 2
λ
λ+
1
λ2(λ2 + λ)
)=n
λ.
Se observ c D2(X) · In(λ) = 1, deci estimatorul X pentru λ este e�cient. √
44

Exerciµiu 5.2 Fie Xi ∼ B(1, p), i = 1, n ³i
θ = nX =n∑i=1
Xi, num rul de succese în n incerc ri.
S se arate c θ este un estimator su�cient pentru p.
Soluµie: Pentru veri�carea su�cienµei, utiliz m de�niµia. Avem succesiv:
L(x1, x2, . . . , xn; p) =
n∏i=1
pxi(1− p)1−xi
= p
n∑i=1
xi
(1− p)n−
n∑i=1
xi
= g(x) · h(θ(x), p),
unde g(x) ≡ 1 ³i h(θ(x), p) = pθ(x)(1− p)n−θ(x). √
Exerciµiu 5.3 Arunc m o moned despre care nu ³tim dac este sau nu corect (adic , probabilitateade apariµie a feµei cu stema nu este neap rat 0.5). Fie X variabila aleatoare ce reprezint num rul deapariµii ale feµei cu stema la aruncarea repetat a unei monede. Not m cu p probabilitatea evenimentuluica la o singur aruncare a monedei apare stema. Realiz m 80 de arunc ri ale acelei monede ³i obµinemvalorile (1 înseamn c faµa cu stema a ap rut iar 0 dac nu a ap rut):
0 1 0 0 1 0 1 1 0 1 0 0 1 0 1 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 1 1 0 1 0 1 1 0
1 0 1 0 1 0 0 0 1 1 0 0 1 0 1 1 0 1 1 0 0 0 1 1 0 1 0 1 1 0 1 1 1 0 0 0 1 0 1 0
(1) S se g seasca un estimator absolut corect pentru p ³i a se studieze e�cienµa acestuia.(2) S se g seasc estimaµii punctuale ³i intervale încredere pentru p, folosind funcµiile mle ³i binofitdin Matlab.
Soluµie: (1) Repartiµia lui X este Bernoulli, B(1, p). Astfel,
E(X) = p, D2(X) = p(1− p).
Consider m variabilele de selecµie repetat de volum, (Xk)k=1n.Un estimator absolut corect pentru medie este X, deoarece
E(X) = E(X) ³i D2(X) =p(1− p)n2
−−−−→n→∞
0.
A³adar, pentru selecµia dat , valoarea x =
n∑k=1
xk = 0.5125.
(2) Utilizând funcµiile Matlab astfel:
[p,pCI] = mle(Y,'distribution','bino','ntrials',1,'alpha',0.05)
45

cu rezultatul:
p = pCI =
0.5125 0.3981
0.6259
sau, folosind comanda binofit,
[p,pCI] = binofit(sum(Y),length(Y),0.05)
cu rezultatul:
p = pCI =
0.5125 0.3981
0.6259 √
Exerciµiu 5.4 Consider m un vector ale c rui componente sunt:
X = 2*rand(1e6,1) - 1;
Dac presupunem c aceste observaµii au fost obµinute urm rind valorile unei v.a. normale N (µ, σ),atunci estim m parametrii s i astfel:
[mu, sigma] = normfit(X)
G sim estim rile
mu = 0.0006425
sigma =0.5771
Dac presupunem c aceste observaµii au fost obµinute urm rind valorile unei v.a. uniforme continuuU(a, b), atunci estim m parametrii s i astfel:
[a, b] = unifit(X)
a = -1.0000
b = 1.0000
Exerciµiu 5.5 Consider m urm torul joc de noroc: Se arunc o moned pentru care probabilitatea deapariµie a feµei cu banul este θ. Dac la o aruncare a monedei apare faµa cu banul, atunci juc torul pierde1RON ³i jocul se încheie. Altfel, pentru �ecare apariµie consecutiv a feµei cu stema câ³tig 1RON ³i areposibilitatea s arunce din nou moneda. Jocul continu pân la apariµia feµei cu banul, când jocul seopre³te.
46

Not m cu X suma (câ³tigat sau pierdut ) la acest joc de noroc ³i presupunem c funcµia sa probabilitateeste:
f(x; θ) =
{θ , x = −1;
(1− θ)2θx , x = 0, 1, 2, . . .
(a) Veri�caµi dac f(x; θ) este o funcµie de probabilitate legitim . Calculaµi E(X) (valoarea a³teptat acâ³tigului).(b) Determinaµi un estimator pentru parametrul θ.(c) Un num r de 10 persoane au participat la acest joc, urm toarele �ind sumele rezultate în �ecare caz:{1, −1, 0, 1, 2, 3, −1, 1, 2, 0}. Folosiµi aceste observaµii pentru a determina o estimare pentru probabili-tatea de a pierde la acest joc.
Soluµie: (a) Mai întâi, observ m c θ ∈ (0, 1). Ar t m c suma probabilit µilor este 1. Avem:
θ +
∞∑x=0
(1− θ)2θx = θ + (1− θ)2∞∑x=0
θx = θ + (1− θ)2 1
1− θ= 1.
Media variabilei aleatoare X este:
E(X) = −θ +∞∑x=0
(1− θ)2xθx = −θ + (1− θ)2∞∑x=0
xθx = −θ + (1− θ)2 θ
(1− θ)2= 0.
Observ m c nu putem utiliza metoda momentelor pentru a determina un estimator pentru θ, deoareceE(X) nu depinde de θ (nu conµine nicio informaµie despre θ).
(b) Not m cu Y variabila aleatoare ce reprezint num rul de insuccese (i.e., num rul variabilelor aleatoarede selecµie pentru care Xi = −1). Atunci, funcµia de verosimilitate este:
L(θ) =n∏i=1
f(xi; θ) = θYn−Y∏i=1
(1− θ)2θXi = θ
Y+
n−Y∑i=1
Xi
(1− θ)2(n−Y ).
Logaritmând, obµinem:
lnL(θ) = (Y +n−Y∑i=1
Xi) ln θ + 2(n− Y ) ln(1− θ)
Punctele critice pentru aceast funcµie veri�c ecuaµia:
lnL(θ)
∂θ= 0,
de unde g sim c
θ =
Y +n−Y∑i=1
Xi
2n− Y +n−Y∑i=1
Xi
.
Se veri�c faptul c derivata a doua a acestei funcµii în raport cu θ este negativ , deci punctul obµinuteste de maxim.
47

Pentru urm toarele observaµiile date, g sim c Y = 2 ³i valoarea estimatorului este θ = 2+1020−2+10 = 3
7 , ceeace înseamn c probabilitatea de a pierde la acest joc este 3
7 .
Mai mult, observ m c estimaµia lui θ bazat pe un ³ir de n observaµii toate egale cu −1 este θ = 1
(deoarece, în acest caz, Y = n,
n−Y∑i=1
Xi = 0), adic estimarea ³ansei de a pierde bazat pe cele n observaµii
pierdante este 1.
Exerciµiu 5.6 Timpii de deservire la un anumit ghi³eu pentru 7 clienµi sunt (în minute.fracµiuni de mi-nut): 3.14, 4.63, 2.71, 4.85, 4.37, 5.12, 3.49 sunt valori ale unei caracteristici uniforme U(0, θ). Determinaµiestimatori pentru parametrul θ prin metoda momentelor ³i prin metoda verosimilit µii maxime. Calculaµivalorile estimatorilor pentru selecµia dat .
Soluµie: Densitatea de repartiµie pentru o variabil aleatoare U(0, θ) este
f(x; θ) =
1
θ, x ∈ (0, θ);
0 , în rest
Metoda momentelor: Egalând momentul teoretic de oridinul întâi (α1(X) = E(X)) cu momentul deselecµie de ordinul întâi (α1(X) = X), obµinem:
θ
2= E(X) = X,
de unde estimatorul obµinut prin metoda momentelor este θ1 = 2X. Pentru selecµia dat , valoarea acestuiaeste θ1 = 8.0886.
Metoda verosimilit µii maxime: Funcµia de verosimilitate este
L(X; θ) =
1
θn, Xi ∈ (0, θ), i = 1, n;
0 , în rest
Observ m c aceast funcµie admite un maxim doar în cazul în care toate variabilele aleatoare de selecµieiau valori în (0, θ), caz în care max
i=1, nXi ≤ θ. Dar, funcµia de verosimilitate este o funcµie descresc toare
în θ, a³adar maximumul lui L(θ) se obµine pentru θ2 = maxi=1, n
Xi.
Pentru observaµiile date, estimaµia de verosimilitate maxim este θ2 = 5.12.
Observaµia 5.1 De³i valorile celor doi estimatori sunt diferite, totu³i, dac num rul de observaµii estefoarte mare (n → ∞), atunci estimaµiile date de θ1 ³i θ2 vor � sensibil egale. Pentru un num r mic deobservaµii, aceste valori nu sunt neap rat uniform distribuite într-un interval, deci nu ne putem a³teptala valori egale pentru θ1 ³i θ2.
48

Estimaµii prin intervale de încredere în Matlab
Exemplu 5.2 O ma³in de îngheµat umple cupe cu îngheµat . Se dore³te ca îngheµat din cupe s aib masa de µ = 250g. Desigur, este practic imposibil s umplem �ecare cup cu exact 250g de îngheµat .Presupunem c masa conµinutului din cup este o variabil aleatoare repartizat normal, cu masa ne-cunoscut ³i dispersia cunoscut , σ = 3g. Pentru a veri�ca dac ma³ina este ajustat bine, se aleg laîntâmplare 30 de înghetate ³i se cânt re³te conµinutul �ec reia. Obµinem astfel o selecµie repetat , x1, x2,. . . , x30 dup cum urmeaz :
257 249 251 251 252 251 251 249 248 248 251 253 248 245 251
248 256 247 250 247 251 247 252 248 253 251 247 253 244 253
Se ³tie c un estimator absolut corect pentru masa medie este media de selecµie, X = 250.0667.Se cere s se g seasc un interval de încredere pentru µ, cu nivelul de con�denµ 0.99.
Soluµie: Dup cum am v zut mai sus, un interval de încredere pentru µ este:
(µ, µ) =
(x− z1−α
2
σ√n, x+ z1−α
2
σ√n
).
Urm torul cod Matlab furnizeaz un interval de încredere bazat pe datele de selecµie observate.
n=30; sigma=3; alpha = 0.01;
x=[257 249 251 251 252 251 251 249 248 248 251 253 248 245 251 ...
248 256 247 250 247 251 247 252 248 253 251 247 253 244 253];
z = icdf('norm',1-alpha/2,0,1); % cuantila de ordin 1-alpha/2 pentru normala
m1 = mean(x)-z*sigma/sqrt(n); m2 = mean(x)+z*sigma/sqrt(n); % capetele intervalului
fprintf('(m1,m2)=(%6.3f,%6.3f)\n',m1,m2); % afiseaza intervalul dupa modul dorit
Rulând codul, obµinem intervalul de încredere pentru µ când σ este cunoscut:
(µ, µ) = (248.659, 251.478). √
Observaµia 5.3 Exist funcµii prede�nite în Matlab ce furnizeaz estimatori punctuali ³i intervale deîncredere. A se compara rezultatul din acest exerciµiu cu cel din Exemplul 5.4 (estimare a intervalului deîncredere când σ nu este cunoscut) sau Exerciµiul 5.6 (intervale furnizate de funcµii Matlab prede�nite).
Exemplu 5.4 S se g seasc un interval de încredere pentru masa medie din Exerciµiul 5.2, în cazul încare abaterea standard σ nu mai este cunoscut .
Soluµie: Dup cum am v zut mai sus, un interval de încredere pentru µ este:
(µ, µ) =
(x− t1−α
2;n−1
d∗(X)√n
, x+ t1−α2;n−1
d∗(X)√n
).
49

Figura 5.1: Intervalul de încredere pentru Exerciµiu 5.2.
Urm torul cod Matlab furnizeaz un interval de încredere bazat pe datele de selecµie observate.
n=30; alpha = 0.01;
x=[257 249 251 251 252 251 251 249 248 248 251 253 248 245 251 ...
248 256 247 250 247 251 247 252 248 253 251 247 253 244 253];
dev = std(X); % deviatia standard de selectie
t = icdf('t',1-alpha/2,n-1); % cuantila de ordin 1-alpha/2 pentru t(n-1)
m1 = mean(x)-t*dev/sqrt(n); m2 = mean(x)+t*dev/sqrt(n); % capetele intervalului
fprintf('(m1,m2)=(%6.3f,%6.3f)\n',m1,m2); % afiseaza intervalul dupa modul dorit
Rulând codul, obµinem intervalul de încredere pentru µ când σ este cunoscut:
(µ, µ) = (248.572, 251.561). √
Observaµia 5.5 A se compara rezultatul din acest exemplu cu cel din Exemplul 5.2 (estimare a in-tervalului de încredere când σ este cunoscut) sau Exerciµiul 5.6 (intervale furnizate de funcµii Matlab
prede�nite).
Exemplu 5.6 Suntem, din nou, în cadrul Exerciµiului 5.2, cu menµiunea c dispersia nu este cunoscut a priori (vezi Exerciµiu 5.4). Dorim s obµinem o estimaµie printr-un interval de încredere pentru µ cândσ nu este cunoscut . Folosind funcµia normfit obµinem chiar mai mult decât ne propunem, ³i anume:estimaµii punctuale pentru µ ³i σ ³i câte un interval de încredere pentru ambele. Rulând funcµia, adic
[m,s,mCI,sCI] = normfit(X,0.01)
50

Observ m c valorile furnizate pentru intervalul de încredere pentru µ, (mCI), sunt exact acelea³i ca celeobµinute în Exerciµiu 5.4.
m = s = mCI = sCI =
250.0667 2.9704 248.572 2.2111
251.561 4.4159
Observaµia 5.7 S presupunem c facem 50 de selecµii repetate de volum 30 (adic alegem în 50 de zilediferite câte o selecµie de 30 de îngheµate) ³i a� m intervalele de încredere (toate cu nivelul de con�denµ α = 0.01) pentru masa medie a conµinutului. Figura 5.2 reprezint gra�c cele 50 de intervale.
Dup cum se observ din �gur , se poate întâmpla ca un interval de încredere generat s nu conµin valoarea pe care acesta ar trebui s o estimeze. Aceasta nu contrazice teoria, deoarece probabilitatea cucare valoarea estimat este acoperit de intervalul de încredere este
P(µ < µ < µ
)= 1− α = 0.99,
deci exist ³anse de a gre³i în estimare, în cazul de faµ de 1%.
Figura 5.2: 50 de realiz ri ale intervalului de încredere pentru µ
Exemplu 5.8 Într-un institut politehnic, s-a determinat c dintr-o selecµie aleatoare de 100 de studenµiînscri³i, doar 67 au terminat studiile, obµinând o diplom . G siµi un interval de încredere care, cu ocon�denµ de 90%, s determine procentul de studenµi absolvenµi dintre toµi studenµii ce au fost înscri³i.
Soluµie: Mai întâi, observ m c α = 0.1, n > 30, p = 67100 = 0.67, np = 67 > 5 ³i n(1 − p) = 33 > 5.
Deoarece nu ni se d vreo informaµie despre N (num rul total de studenµi înscri³i), putem presupune c n < 0.05N . G sim c intervalul de încredere c utat este:(
0.67− z0.975
√0.67 (1− 0.67)
100, 0.67 + z0.975
√0.67 (1− 0.67)
100
)= (59.27%, 74.73%). √
51

Exemplu 5.9 Dintr-o selecµie de 200 de elevi ai unei ³coli cu 1276 de elevi, 65% a�rm c deµin cel puµinun telefon mobil. S se g seasc un interval de încredere pentru procentul de copii din respectiva ³coal ce deµin cel puµin un telefon mobil, la nivelul de semni�caµie α = 0.05.
Soluµie: Avem: n = 200, N = 1276, p = 0.65. Deoarece n ≥ 0.05N , g sim c un interval de încrederela nivelul de semni�caµie 0.05 este(
0.65− 1.96
√0.65 (1− 0.65)
200
√1276− 200
1276− 1, 0.65 + 1.96
√0.65 (1− 0.65)
200
√1276− 200
1276− 1
)= (58.93%, 71.07%). √
Observaµia 5.10 Dac se dore³te estimarea volumului selecµiei pentru care se obµine estimarea proporµieip printr-un interval de încredere cu o eroare maxim E , atunci folosim formula
E = z1−α2
√p (1− p)
n(5.1)
Dac am putea ghici proporµia populaµiei, p, atunci g sim urm toarea estimare a volumului selecµiei:
n =
[p(1− p)
(z1−α
2
E
)2], (5.2)
unde [ · ] este partea întreag . Dac p nu poate � ghicit, atunci folosim faptul c p(1 − p) este maximpentru p = 0.5 ³i estim m pe n prin
n =
[1
4
(z1−α
2
E
)2].
Exemplu 5.11 Un studiu susµine c între 35% ³i 40% dintre elevii de liceu din µar fumeaz . Cât demare ar trebui s �e volumul unei selecµii dintre elevii de liceu pentru a estima procentul real de elevi cefumeaz , cu o eroare de estimare maxim de 0.5%. Se va alege nivelul de semni�caµie α = 0.1.
Soluµie: Folosim formula (5.2), pentru p = 0.4 (se alege valoarea 40%, cea mai apropiat de 50%).Cuantila este z0.95 = 1.28. G sim c o estimaµie pentru n este:
n =
[0.4(1− 0.4)
(1.64
0.005
)2]
= 25820. √
Exemplu 5.12 O fabric produce batoane de ciocolat cânt rind 100g �ecare. Pentru a se estima aba-terea masei de la aceast valoare, s-a f cut o selecµie de 35 de batoane, obµinându-se valorile:
100.12; 99.92; 100.1; 99.89; 100.07; 99.88; 100.11; 99.90; 99.97; 100.2;
99.89; 100.15; 99.9; 99.7; 100.2; 99.7; 100.2; 100.1; 100.04; 99.89;
99.76; 100.1; 99.24; 98.19; 100.15; 100.5; 99.79; 98.95; 100.23; 99.89;
52

100.12; 98.63; 99.03; 100.3; 98.68.
G siµi un interval de încredere (cu α = 0.05) pentru deviaµia standard masei batoanelor produse de res-pectiva fabric .
Soluµie: Mai întâi, calcul m d2(x). Avem:
d2(x) =1
35
35∑i=1
[Xi − 100]2 = 0.3.
Din tabele, sau utilizând Matlab, g sim cuantilele:
χ20.975; 35 = 53.2033; χ2
0.025; 35 = 20.5694.
În Matlab, cuantilele se calculeaz astfel:
icdf('chi2',0.975, 35); icdf('chi2',0.025, 35)
Intervalul de încredere pentru dispersie este:
(σ2, σ2) = (0.20, 0.51).
Pentru variaµia standard, intervalul de încredere este:
(σ, σ) = (√
0.2,√
0.51) = (0.44, 0.71). √
Exemplu 5.13 G siµi un interval de încredere (cu α = 0.05) pentru deviaµia standard a conµinutului denicotin a unui anumit tip de µig ri, dac o selecµie de 25 de buc µi are deviaµia standard a conµinutuluide nicotin de 1.6mg.
Soluµie: Mai întâi, s = d∗(x) = 1.6. Din tabele, sau utilizând Matlab, g sim:
χ20.975; 24 = 39.3641; χ2
0.025; 24 = 12.4012.
Intervalul de încredere pentru dispersie este:
(σ2, σ2) = (1.56, 4.95).
Pentru variaµia standard, intervalul de încredere este:
(√
1.5608,√
4.9544) = (1.25, 2.22). √
Exemplu 5.14 Dou strunguri sunt potrivite s produc piese identice pentru o comand . Pentru aestima dac abaterile diametrelor pieselor produse de cele dou ma³ini sunt sensibil egale, s-au luat laîntamplare dou seturi de volume n1 = 7 ³i n2 = 10 de piese din cele dou loturi. M sur torile au condusla urm toarele rezultate:
53

Lotul 1 25.06 24.95 25.01 25.05 24.98 24.97 25.02 − − −Lotul 2 25.01 25.09 25.02 24.95 24.97 25.03 24.99 24.97 25.03 24.98
S se determine un interval de încredere pentru raportul dispersiilor diametrelor pieselor produse de celedou loturi (α = 0.1). Se va presupune c diametrele pieselor urmeaz o repartiµie normal .
Soluµie: Determin m mai întâi dispersiile empirice. Acestea sunt:
d2∗1 =1
6
7∑i=1
(L1i − L1i)2 = 0.0412 ³i d2∗2 =
1
9
10∑j=1
(L2j − L2j)2 = 0.0409.
Cuantilele sunt:f0.05, 6, 9 = 0.2440 ³i f0.95, 6, 9 = 3.3738.
Folosind Matlab, putem calcula cuantilele astfel:
f1 = finv(0.05, 6, 9); f2 = finv(0.95, 6, 9);
G sim intervalul de încredere:
(f1, f2) ≈ (0.25, 3.4). √
Exemplu 5.15 Dintr-o selecµie de 45 de baieµi ai unei ³coli, 21 au spus c le place Matematica, iar dintr-oselecµie de 65 de fete ale aceleia³i ³coli, 37 au susµinut c le place aceast disciplin . Construiµi un intervalde încredere la nivelul de semni�caµie α = 0.02 pentru diferenµa proporµiilor de baieµi ³i fete din respectiva³coal c rora le place Matematica.
Soluµie: Mai întâi, p1 = 2345 , p2 = 37
65 ³i z0.99 ≈ 2.33. Intervalul c utat este:21
45− 37
65− 2.33
√2145 ·
2445
45+
3765 ·
2865
65,
21
45− 37
65+ 2.33
√2145 ·
2445
45+
3765 ·
2865
65
= (−0.1990, −0.0061).
√
Exerciµiu 5.16 O selecµie aleatoare de volum n = 25 cu media se selecµie x = 50 se ia dintr-o populaµiede volum N = 1000, ce are deviaµia standard σ = 2.(a) Dac presupunem c populaµia este normal , g siµi un interval de încredere pentru media populaµiei,cu α = 0.05.(b) G siµi un interval de încredere pentru media populaµiei (α = 0.05) în cazul în care populaµia nu estenormal .
Soluµie: (a) G sim intervalul de încredere
(µ, µ) =
(50− z0.975
2√25, 50 + z0.975
2√25
)= (48.4, 51.6).
54

(b) Deoarece populaµia nu este normal distribuit ³i nici volumul populaµiei nu este mare (n < 30), vomestima intervalul de încredere bazându-ne pe inegalitatea lui Cebî³ev. Avem c probabilitatea ca valorilelui X s �e aproximate prin µX = µ cu o eroare de cel mult k deviaµii standard este:
P ({|X − µX | < kσX}) ≥ 1− 1
k2.
Luând 1− 1
k2= 0.95, g sim k =
√20. Astfel, un interval de încredere pentru media populaµiei va �
(µ, µ) =
(x− k σ√
n, x+ k
σ√n
)=
(50−
√20
2√25, 50 +
√20
2√25
)= (46.42, 53.58).
Am folosit faptul c σ2X
= D2(X) =σ2
n. Observ m c acest interval este mai mare decât cel g sit ante-
rior, de aceea inegalitatea lui Cebî³ev este rar folosit pentru a determina intervale de încredere. Totu³i,în acest caz nu aveam o alt alternativ de calcul. Dac se dore³te o precizie mai bun , ar � indicat cavolumul selecµiei s �e de cel puµin 30, caz în care putem folosi aproximarea cu repartiµia normal . √
Exerciµii propuse
Exerciµiu 5.7 Ar taµi c n·(1−X) este un estimator su�cient pentru parametrul p din repartiµia B(n, p).
Exerciµiu 5.8 Ar taµi c informaµia Fisher In(µ) pentru o caracteristic N (µ, σ) este
In(µ) = nI1(µ) =n
σ2.
(deci, cantitatea de informaµie cre³te cu descre³terea lui σ.)
Exerciµiu 5.9 Ar taµi c statistica d2∗(X) este un estimator absolut corect pentru σ2 = D2(X), iarstatistica d2(X) este un estimator corect, dar nu absolut corect, pentru D2(X).
Exerciµiu 5.10 Estimaµi prin metoda verosimilit µii maxime parametrul p al unei caracteristici X ∼B(n, p).
Exerciµiu 5.11 Determinaµi un estimator punctual (prin metoda momentelor ³i prin metoda verosimili-t µii maxime) pentru parametrul α al caracteristicii X ce are densitatea de repartiµie f : R → R+, dat prin:
f(x; θ) =
{αe−αx , x > 0,
0 , x ≤ 0.
Veri�caµi dac estimatorul g sit este deplasat.
Exerciµiu 5.12 Fie selecµia
871 822 729 794 523 972 768 758 583 893 598 743 761 858 948
598 912 893 697 867 877 649 738 744 798 812 793 688 589 615 731
S se estimeze absolut corect dispersia populaµiei din care provine aceast selecµie.
55

Exerciµiu 5.13 Estimaµi prin metoda momentelor parametrii unei caracteristici X ∼ N (µ, σ).
Exerciµiu 5.14 Dac {Xi}i=1, n sunt variabile aleatoare de selecµie repetat de volum n efectuate asupraunei caracteristici X, ar taµi c informaµia Fisher In(θ) de�nit prin
In(θ) = E
[(∂L(X, θ)
∂θ
)2]
este In(θ) = nI1(θ). (i.e., informaµia Fisher conµinut în selecµia dat este de n ori informaµia conµinut într-o singur variabil de selecµie.)
Exerciµiu 5.15 S se arate c X este un estimator e�cient pentru parametrul µ al repartiµiei normaleN (µ, σ).
Exerciµiu 5.16 Consider m o selecµie de volum n dintr-o colectivitate repartizat Γ(n, λ), n ∈ N. G siµiun estimator pentru parametrul λ prin metoda verosimilit µii maxime ³i unul prin metoda momentelor.
Exerciµiu 5.17 Consider m funcµia f : R −→ R, dat prin
f(x) =
2
ax e−
x2
a , x > 0;
0 , x ≤ 0.
(a) Pentru ce valori ale parametrului a, funcµia f(x) este o densitate de repartiµie?(S not m cu X variabila aleatoare ce are aceast densitate de repartiµie);(b) G siµi un estimator pentru parametrul a (folosind, la alegere, metoda momentelor sau metoda vero-similit µii maxime);(c) Calculaµi E(a), D2(a), P (X > 0).
Exerciµiu 5.18 La un control de calitate se veri�c masa tabletelor de ciocolat produse de o anumit ma³in . Pentru a se realiza acest control s-a efectuat o selecµie de 50 tablete ³i s-a obµinut c masa X alciocolatelor are urm toarele dimensiuni (în grame):
Masa 99.98 99.99 100.00 100.01 100.02
Frecvenµa 9 10 13 11 7
S se determine:(a) o estimaµie absolut corect pentru masa medie a tabletelor produse;(b) o estimaµie corect ³i una absolut corect pentru dispersia valorilor masei faµ de medie.
Exerciµiu 5.19 Fie X o variabil aleatoare exponenµial de parametru λ. Dac r > 0, g siµi un estimatorprin metoda verosimilit µii maxime pentru P (X ≤ r).
Exerciµiu 5.20 Fie X1, X2, . . . , Xn o selecµie repetat de volum n mare, luat dintr-o caracteristic ceare media µ necunoscut ³i dispersia 4. Determinaµi volumul selecµiei pentru care, cu o probabilitate de99% putem estima pe µ cu o eroare de o zecime.
56

Exerciµiu 5.21 La un control de calitate, dintr-un lot de 150 de piese, 5 s-au g sit defecte. Determinaµiun interval de încredere cu α = 0.01 pentru probabilitatea ca o pies luat la întâmplare s �e defect .
Exerciµiu 5.22 Un angajat la Serviciu Forµelor de Munc dore³te s fac un sondaj prin care s determineprocentul de persoane dintr-o regiune a µ rii ce lucreaz la negru. El dore³te s �e 98% sigur c rezultatulg sit estimeaz procentul real cu o eroare de cel mult 2%. Dintr-un sondaj recent, la care au participat1500 de persoane angajate, 273 au declarat c nu li s-au f cut carte de munc .(a) Cât de mare ar trebui s �e volumul selecµiei pentru a realiza estimarea dorit ?(b) Dac nu ar avea acces la acel sondajul recent, cât de mare ar trebui s �e volumul selecµiei pentru arealiza estimarea dorit ?
Exerciµiu 5.23 Un studiu recent arat c dintre 120 de accidente rutiere ce s-au soldat cu victime, 56era datorate consumului de alcool. G siµi un interval de încredere care s estimeze cu o probabilitate derisc α = 0.05 procentul real al accidentelor rutiere cauzate de consumul de alcool.
Exerciµiu 5.24 Not m cuX procentul de timp necesar unui student (ales la întâmplare) pentru a terminaun anumit test într-un interval de timp �xat. Densitatea de repartiµie a lui X este f : R→ R+,
f(x; θ) =
{(θ + 1)xθ , 0 ≤ x ≤ 1, (θ ∈ R)
0 , altfel.
(a) Pentru ce valori ale parametrului θ, funcµia f este o densitate de repartiµie?Datele urm toare reprezint rezultatele a 7 studenµi ale³i la întâmplare:
x1 = 0.87, x2 = 0.75, x3 = 0.54, x4 = 0.95, x5 = 0.68, x6 = 0.72, x7 = 0.8.
(b) Folosiµi metoda momentelor pentru a determina un estimator pentru parametrul θ ³i calculaµi valoareaestimatorului pentru datele de mai sus.(c) Folosiµi metoda verosimilit µii maxime petru a determina un estimator pentru parametrul θ ³i calculaµivaloarea estimatorului pentru datele de mai sus.
Exerciµiu 5.25 Cât de mare ar trebui s �e volumul selecµiei, pentru a estima proporµia de fum tori dinµar cu o eroare de cel mult 2%, ³i o probabilitate de încredere de 0.95?
Exerciµiu 5.26 Fie X o caracteristic binomial B(n, p), cu n cunoscut. Folosind metoda intervalelorde încredere pentru selecµii mari, determinaµi un interval de încredere pentru parametrul p, la nivelul desemni�caµie α.
Exerciµiu 5.27 În urma arunc rii unei monede de 4050 de ori, s-a observat c faµa cu stema a ap rutde 2052 ori. Determinaµi un interval de încredere pentru probabilitatea de apariµie a feµei cu stema laaruncarea respectivei monede. Se va lua nivelul de semni�caµie α = 0.05.
Exerciµiu 5.28 La un control de calitate, dintr-un lot de 150 de piese, 5 au fost g site defecte. Deter-minaµi un interval de încredere cu α = 0.01 pentru probabilitatea ca o pies luat la întâmplare s �edefect .
57

6 Statistic Aplicat (L6 & S6)
Testarea tipului de date experimentale
Pentru a putea efectua un test statistic în mod corect, este necesar s ³tim care este tipul (tipurile) dedate pe care le avem la dispoziµie. Pentru anumite teste statistice (e.g., testul Z sau testul t, dateletestate trebuie s �e normal distribuite ³i independente. De multe ori, chiar ³i ipoteza ca datele s �enormal repartizate trebuie veri�cat . De aceea, se pune problema realiz rii unei leg turi între funcµiade repartiµia empiric ³i cea teoretic (teste de concordanµ ). Vom discuta mai pe larg aceste teste deconcordanµ într-o secµiune urm toare.ÎnMatlab sunt deja implementate unele funcµii ce testeaz dac datele sunt normal repartizate. Funcµianormplot(X) reprezint gra�c datele din vectorul X versus o repartiµie normal . Scopul acestei funcµiieste de a determina gra�c dac datele din observate sunt normal distribuite. Dac aceste date sunt selec-tate dintr-o repartiµie normal , atunci acest gra�c va � liniar, dac nu, atunci va � un gra�c curbat. Deexemplu, s reprezent m cu normplot vectorii X ³i Y de mai jos. Gra�cele sunt cele din Figura 6.1.
X = normrnd(100,2,200,1);
subplot(1,2,1); normplot(X)
Y = exprnd(5,200,1);
subplot(1,2,2); normplot(Y)
Figura 6.1: Reprezentarea normal a datelor.
Observ m c primul gra�c este aproape liniar, pe când al doilea nu este. Putem astfel s concluzion mc datele date de X sunt normal repartizate (fapt con�rmat ³i de modul cum le-am generat), iar dateledin Y nu sunt normal repartizate.
Funcµia chi2gof determin , în urma unui test χ2, dac datele observate sunt normal repartizate, la unnivel de semni�caµie α = 0.05. Astfel, comanda
h = chi2gof(x)
58

ne va furniza rezultatul h = 1, dac datele nu sunt normal repartizate (i.e., ipoteza alternativ (H1) esteadmis ), sau h = 0, dac nu putem respinge ipoteza c datele observate sunt normal distribuite (i.e.,ipoteza nul (H0) este admis ). Aplicând testul pentru X ³i Y de mai sus, obµinem h = 0, respectiv,h = 1.
De asemenea, putem veri�ca dac datele statistice ar putea proveni ³i din alte repartiµii decât cea normal .De exemplu, funcµia
probplot(distribution,Y)
creaz un gra�c ce compar repartiµia datelor din vectorul Y cu repartiµia dat de distribution. Prin-tre repartiµiile ce pot � comparate folosind aceast comand menµion m: 'normal', 'exponential','weibull' ³i 'lognormal'. Trebuie avut grij ca valorile vectorului Y s �e pozitive pentru comparareacu oricare dintre ultimele trei repartiµii. Comanda simpli�cat este probplot(Y), care presupune în modimplicit c distribution = 'normal'. O alt comand util este
wblplot(Y)
care este echivalent cu comanda probplot(weibull,Y).În continuare, prezent m un exemplu de utilizare a acestor comenzi. Figura 6.2, veri�c m dac �ecaredintre cele dou selecµii generate, una exponenµial ³i cealalt normal , ar putea proveni dintr-o repartiµieexponenµial .
x = exprnd(0.5, 250,1); % selectie exponentiala
y = normrnd(3, 1, 250,1); % selectie normala
probplot('exponential',[x y])
legend('Selectie exponentiala','Selectie normala','Location','SE')
Figura 6.2: Reprezentarea exponenµial a datelor.
59
Urm toarea funcµie Matlab compar un set de date cu o repartiµie precizat . Funcµia
histfit(X, n, 'tip_repartitie')
reprezint datele din vectorulX printr-o histogram ce are num rul de bare egal cu n. Dac opµiunea 'tip_repartitie'apare (valabil doar pentru lucrul cu Statistics Toolbox!), atunci peste histogram se va desena densitatea de re-partiµie a repartiµiei precizate (e.g., exponential, gamma, lognormal etc). În caz în care opµiunea nu apare, seconsider implicit c repartiµia cu care se compar datele este cea normal . Exemplul de mai jos produce gra�culdin Figura 6.3.
X = binornd(1e3, 0.1, 1e4, 1); histfit(X, 100)
Figura 6.3: Compararea prin histograme.
Teste parametrice rezolvate în Matlab
Testul Z în Matlab
Testul Z pentru o selecµie poate � simulat în Matlab utilizând comanda
[h, p, ci, zval] = ztest(X,m0,sigma,alpha,tail)
unde:
• h este rezultatul testului. Dac h = 1, atunci ipoteza nul se respinge, dac h = 0, atunci ipoteza nul nupoate � respins pe baza observaµiilor facute (adic , se admite, pân la un test mai puternic);
• p este valoarea P (P− value);
• ci este un interval de încredere pentru µ, la nivelul de semni�caµie α;
60

nota frecvenµa frecvenµa relativ 2 2 2.22%3 4 4.44%4 8 8.89%5 15 16.67%6 18 20.00%7 17 18.89%8 15 16.67%9 7 7.78%10 4 4.44%
Total 90 100%
Tabela 6.1: Tabel cu frecvenµe pentru date discrete.
• zval este valoarea statisticii Z pentru observaµia considerat ;
• X este un vector sau o matrice, conµinând observaµiile culese. Dac X este matrice, atunci mai multe testeZ sunt efectuate, de-alungul �ec rei coloane a lui X;
• m0 = µ0, valoarea testat ;
• sigma este deviaµia standard teoretic a lui X, a priori cunoscut ;
• alpha este nivelul de semni�caµie;
• tail poate � unul dintre urm toarele ³iruri de caractere:
� 'both', pentru un test bilateral (poate s nu �e speci�cat , se subînµelege implicit);
� 'left', pentru un test unilateral stânga (µ < µ0);
� 'right', pentru un test unilateral dreapta (µ > µ0);
Exemplu 6.1 Spre exempli�care, s presupunem c datele discrete din Tabelul 6.1 sunt obµinute în urma unuisondaj care contabilizeaz notele la Matematic obµinute de elevii unei anumite ³coli. Dorim s test m, la nivelulde semni�caµie α = 0.05, dac media tuturor notelor la Matematic a elevilor ³colii este µ = 6.8 sau mai mare. Se³tie c deviaµia standard este σ = 2.5.
Soluµie: A³adar, avem de testat
(H0) µ = 6.8 vs. (H1) µ > 6.8.
Vectorul X de mai jos cuprinde toate notele obµinute în urma sondajului.
X = [2*ones(2,1); 3*ones(4,1); 4*ones(8,1); 5*ones(15,1); 6*ones(18,1); ...
7*ones(17,1); 8*ones(15,1); 9*ones(7,1); 10*ones(4,1)];
[h, p, ci, zval] = ztest(X, 6.8, 2.5, 0.05, 'right')
Acest cod a�³eaz
h = p = ci = stats =
0 0.9500 5.9332 -1.6444
Inf
Aceasta înseamn faptul c ipoteza nul este admis la acest nivel de semni�caµie. √
61

Observaµia 6.2 (1) Dac ipoteza alternativ este bilateral ((H1) : µ 6= 6.8), atunci comanda ar �:
[h, p, ci, zval] = ztest(X, 6.8, 2.5)
În acest caz, g sim c ipoteza nul este respins (i.e., rezultatul este h = 1).
(2) Decizia testului putea � luat ³i pe baza P−valorii. Aceasta este:
Pv = P (Z > z0) = 1− P (Z ≤ z0) = 1−Θ(z0) = 0.95 > 0.05 = α.
În Matlab, aceast valoare poate � calculat astfel:
m0 = 6.8; sigma = 2.5; n = 90; z0 = (mean(X) - m0)/(sigma/sqrt(n));
Pv = 1 - normcdf(z0, 0, 1)
(3) Pentru efectuarea testului, nu este neap rat necesar s a�³ m toate cele patru variabile din membrul stâng.Putem a�³a, dup preferinµ , doar trei, dou , sau numai o variabil , dar doar în ordinea precizat . De exemplu,comanda
h = ztest(X, m0, sigma, alpha, tail)
ne va furniza doar rezultatul testului (h = 0 sau h = 1), f r a a�³a alte variabile.(4) Nu exist o funcµie în Matlab care s simuleze testul Z pentru dou selecµii.
Testul t în Matlab
Testul t pentru o selecµie
Testul t poate � simulat în Matlab utilizând comanda general
[h, p, ci, stats] = ttest(X,m0,alpha,tail)
unde:
• h, p, ci, m0, alpha, tail sunt la fel ca în funcµia ztest;
• variabila stats înmagazineaz urm toarele date:
� tstat - este valoarea statisticii T pentru observaµia considerat ;
� df - num rul gradelor de libertate ale testului;
� sd - deviaµia standard de selecµie;
Exemplu 6.3 Dorim s test m dac o anumit moned este corect , adic ³ansele �ec rei feµe de a apare la oricearuncare sunt 50%− 50%. Arunc m moneda în caza de 100 de ori ³i obµinem faµa cu stema de exact 59 de ori. Pebaza acestei experienµe, c ut m s test m ipoteza nul
(H0) : moneda este corect
vs. ipoteza alternativ (H1) : moneda este m sluit ,
62

la un prag de semni�caµie α = 0.05.
Soluµie: Fie X variabila aleatoare ce reprezint faµa ce apare la o singur aruncare a monedei. S spunemc X = 1, dac apare faµa cu stema ³i X = 0, dac apare faµa cu banul. Teoretic, X ∼ B(1, 0.5), de undeE(X) = 0.5, D2(X) = 0.25.Prin ipotez , ni se d o selecµie de volum n = 100 ³i scriem observaµiile f cute într-un vector x ce conµine 59 de 1³i 41 de valori 0. Deoarece n = 100 > 30, putem utiliza testul t pentru o selecµie. Rescriem ipotezele (H0) ³i (H1)astfel:
(H0) : µ = 0.5
(H1) : µ 6= 0.5.
Dac {X1, X2, . . . , Xn} sunt variabilele aleatoare de selecµie, atunci alegem statistica
T =X − µd∗(X)√
n
.
Dac ipoteza (H0) se admite, atunci µ este �xat, µ = 0.5 ³i statistica T ∼ t(n − 1). Valoarea acestei statisticipentru selecµia dat este:
t0 =x− µd∗(X)√
n
= 1.8207.
Din t1−α2 ; n−1 = t0.975; 99 = 1.9842, rezult c |t0| < t1−α2 ; n−1, ³i decidem c ipoteza (H0) este admis (nu poate� respins la nivelul de semni�caµie α).P−valoarea este
Pv = 1− Fn−1(t0) + Fn−1(−t0) = 1− F99(1.8207) + F99(−1.8207) = 0.0717.
Codul Matlab pentru calculul analitic de mai sus este urm torul:
n=100; mu = 0.5; alpha = 0.05; x = [ones(59,1); zeros(41,1)];
t0 = (mean(x) - mu)/(std(x)/sqrt(n));
tc = tinv(1-alpha/2, n-1); % cuantila
if (abs(t0) < tc)
disp('moneda este corecta')
else disp('moneda este masluita')
end
Pv= 1 - tcdf(t0,n-1) + tcdf(-t0,n-1) % P-valoarea
Rulând codul, obµinem rezultatul:
moneda este corecta
În loc s folosim codul de mai sus, am putea folosi funcµia ttest din Matlab, dup cum urmeaz :
[h, p, ci, stats] = ttest(X,0.5,0.05,'both')
³i obµinem
h = p = ci = stats =
0 0.0717 0.4919 tstat: 1.8207
0.6881 df: 99
sd: 0.4943 √
63

Observaµia 6.4 (1) Deoarece P−valoarea este p = 0.0717, deducem c la un prag de semni�caµie α ≥ 0.08,ipoteza nul ar � fost respins .(2) Dac dintre cele 100 de observ ri aveam o apariµie în plus a stemei, atunci ipoteza nul ar � respins , adic moneda ar � fost catalogat a � m sluit .
Testul t pentru dou selecµii
Testul t pentru egalitatea a dou medii poate � simulat în Matlab utilizând comanda
[h, p, ci, stats] = ttest2(X, Y, alpha, tail, vartype)
unde:
• h, p, ci, alpha, stats ³i tail sunt la fel ca mai sus;
• X ³i Y sunt vectori sau o matrice, conµinând observaµiile culese. Dac ele sunt matrice, atunci mai multe testeZ sunt efectuate, de-alungul �ec rei coloane;
• vartype ia valoarea equal dac dispersiile teoretice sunt egale sau unequal pentru dispersii inegale.
Exemplu 6.5 Caracteristicile X1 ³i X2 reprezint notele obµinute de studenµii de la Master MF ′08, respectiv,MF ′09 la examenul de Statistic Aplicat . Conducerea universit µii recomand ca aceste note s urmeze repartiµianormal ³i examinatorul se conformeaz dorinµei de sus. Presupunem c X1 ∼ N (µ1, σ1) ³i X2 ∼ N (µ2, σ2), cuσ1 6= σ2, necunoscute a priori. Pentru a veri�ca modul cum s-au prezentat studenµii la acest examen în doi aniconsecutivi, select m aleator notele a 25 de studenµi din prima grup ³i 30 de note din a doua grup . distribuctiide frecvenµe ale notelor sunt cele din Tabelul 6.2.(i) Veri�caµi dac ambele seturi de date provin dintr-o repartiµie normal ;
(ii) G siµi un interval de încredere pentru diferenµa mediilor, la nivelul de semni�caµie α = 0.05;(ii) S se testeze (cu α = 0.01) ipoteza nul
(H0) : µ1 = µ2, (în medie, studenµii sunt la fel de buni)
versus ipoteza alternativ
(H1) : µ1 < µ2, (în medie, studenµii au note din ce în ce mai mari)
Nota obµinut Frecvenµa absolut
Grupa MF ′08 Grupa MF ′095 3 56 4 67 9 88 7 69 2 310 0 2
Tabela 6.2: Tabel cu note.
Soluµie: (i) h = chi2gof(u) % h = 0, deci u ∼ Nk = chi2gof(v) % k = 0, deci v ∼ N
(u ³i v sunt vectorii din codul Matlab de mai jos)
64

(ii) Un interval de încredere la acest nivel de semni�caµie se obµine apelând funcµia Matlab
[h, p, ci, stats] = ttest2(u, v, 0.05, 'both', 'unequal')
Acesta este:(-0.7294, 0.6760)
Altfel, se calculeaz intervalul de încredere:x1 − x2 − t1−α2 ; N
√d2∗1n1
+d2∗2n2
, x1 − x2 + t1−α2 ; N
√d2∗1n1
+d2∗2n2
Codul Matlab:
n1=25; n2=30; alpha = 0.05;
u = [5*ones(3,1);6*ones(4,1);7*ones(9,1);8*ones(7,1);9*ones(2,1)];
v = [5*ones(5,1);6*ones(6,1);7*ones(8,1);8*ones(6,1);9*ones(3,1);10*ones(2,1)];
d1 = var(u); d2 = var(v); N = (d1/n1+d2/n2)^2/((d1/n1)^2/(n1-1)+(d2/n2)^2/(n2-1))-2;
t = tinv(1-alpha/2,N);
m1 = mean(u)-mean(v)-t*sqrt(d1/n1+d2/n2); m2 = mean(u)-mean(v)+t*sqrt(d1/n1+d2/n2);
fprintf('(m1,m2)=(%6.3f,%6.3f)\n',m1,m2);
(iii) Comanda Matlab este:
[h,p,ci,stats] = ttest2(u, v, 0.01, 'left', 'unequal')
În urma rul rii comenzii, obµinem:
h = p = ci = stats =
0 0.4698 -Inf tstat: -0.0761
0.8137 df: 52.7774
sd: 2x1 double √
Observaµia 6.6 Valoarea P poate � calculat ³i cu formula:
Pv = P (T < t0) = FN−1(t0) = 0.4698.
În Matlab,
t0 = (mean(u)-mean(v))/sqrt(d1/n1+d2/n2); Pv = tcdf(t0, N-1)
Testul χ2 pentru dispersie în Matlab
Exemplu 6.7 Se cerceteaz caracteristica X, ce reprezint diametrul pieselor (în mm) produse de un strung. �timc X urmeaz legea normal N (µ, σ). Alegem o selecµie de volum n = 11 ³i obµinem distribuµia empiric :(
10.50 10.55 10.60 10.652 3 5 1
).
65

S se testeze (cu α = 0.1) ipoteza nul (H0) : σ2 = 0.003,
versus ipoteza alternativ (H1) : σ2 6= 0.003.
Soluµie: Intervalul de încredere pentru σ este (0.0012, 0.0055) iar valoarea critic este χ20 = 7.2727. Deoarece
aceasta aparµine intervalului de încredere, concluzion m c ipoteza nul nu poate � respins la acest nivel desemni�caµie.Aceea³i concluzie poate � luat în urma inspecµiei valorii P , care este mai mare decât nivelul α. Avem:
Pv = P (|χ2| > |χ20|) = P (χ2 > χ2
0) = 1− Fn−1(7.2727) = 0.6995. √
Testul χ2 poate � simulat în Matlab utilizând comanda
[h, p, ci, stats] = vartest(X,var,alpha,tail)
unde:
• h, p, ci, m0, alpha, stats, tail sunt la fel ca în funcµia ttest;
• var este valoarea testat a dispersiei;
Spre exempli�care, codul Matlab pentru exerciµiul anterior este:
X = [10.50*ones(2,1); 10.55*ones(3,1); 10.60*ones(5,1); 10.65];
[h, p, ci, stats] = vartest(X,0.003,0.1,'both')
Rularea acestuia ne d :
h = p = ci = stats =
0 0.6011 0.0012 chisqstat: 7.2727
0.0055 df: 10
adic ipoteza nul este acceptat la acest nivel de semni�caµie.Folosind Matlab, putem calcula P−valoarea astfel:
c0 = (n-1)/0.003*var(X); Pv = 1 - chi2cdf(c0,10)
Testul F în Matlab
Testul raportului dispersiilor poate � simulat în Matlab utilizând comanda
[h, p, ci, stats] = vartest2(X, Y, alpha, tail)
unde variabilele sunt la fel ca în funcµia ttest2.
66

Exemplu 6.8 Revenim la Exerciµiul 6.5 ³i veri�c m dac cele dou selecµii de note (Tabelul 6.2) provin dinpopulaµii cu dispersii egale. A³adar, avem de testat (la nivelul de semni�caµie α = 0.01)
(H0) σ21 = σ2
2 vs. (H1) σ21 6= σ2
2 .
Soluµie: Utilizând notaµiile din Exerciµiul 6.5, comanda Matlab care rezolv acest test este:
[h, p, CI, stats] = vartest2(u, v , 0.01 , 'both')
(pentru teste unilaterale, folosim 'left' sau 'right' în locul lui 'both'.)Rezultatul comenzii anterioare este:
h = p = CI = stats =
0 0.2119 0.2191 fstat: 0.6047
1.7426 df1: 24
df2: 29
Deoarece h = 0, decidem c dispersiile teoretice ale celor dou populaµii pot � considerate a � egale la nivelul desemni�caµie α = 0.01. √
Observaµia 6.9 Decizia testului poate � luat ³i pe baza inspecµiei valorii P , observând c aceasta este mai maredecât α. Aceasta este:
Pv = 1− Fn1−1, n2−1(|f0|) + Fn1−1, n2−1(−|f0|) = 1− Fn1−1, n2−1(|f0|).
În Matlab, calcul m astfel:
f0 = var(u)/var(v); Pv = 1 - fcdf(abs(f0),n1-1,n2-1)
Teste parametrice pentru proporµii
Exemplu 6.10 Într-un sondaj naµional de opinie, 5000 de persoane au fost rugate s r spund la o întrebarelegat de apartenenµa religioas . La întrebarea "Sunteµi cre³tini?", r spunsul a fost a�rmativ în 4893 dintre cazuri.Rezultatul acestui sondaj este utilizat în estimarea procentului de cre³tini din µar . S not m cu p acest procent.La nivelul de semni�caµie α = 0.05, testaµi dac p este de 95% sau mai mare.
Soluµie: Avem de testat ipoteza
(H0) : p = 0.95 vs. (H1) : p > 0.95.
Procentul de selecµie este p = 48935000 = 0.9786, cuantila este z1−α = 1.6449 ³i valoarea statisticii este
P0 =0.9786 − 0.95√0.95 (1− 0.95)
5000
= 9.2791 ∈ [1.6449, ∞),
a³adar ipoteza nul este respins la acest nivel de semni�caµie. Admitem c p > 0.95.Aceea³i concluzie poate � dedus ³i prin inspecµia P−valorii. Aceasta este
Pv = P (Z > P0) = 1− P (Z ≤ P0) = 1−Θ(9.2791) ≈ 0 < α = 0.05.
A³adar, ipoteza nul va � respins la toate nivele de semni�caµie practice. √
67

Exemplu 6.11 Revenim la Exemplul 5.15. S se testeze, la nivelul de semni�caµie α = 0.02 dac exist diferenµesemni�cative între proporµiile de baieµi ³i fete din respectiva ³coal c rora le place Matematica.
Soluµie: Avem: p1 = 2345 , p2 = 37
65 , p∗ = 23+37
45+65 = 611 ³i z0.99 ≈ 2.33. Valoarea statisticii este:
P0 =2345 −
3765√
611 (1− 6
11 )(
145 + 1
65
) = −0.6019 ∈ [−2.3263, 2.3263],
deci ipoteza nul nu poate � respins la acest nivel de semni�caµie.Aceea³i concluzie o putem lua dac veri�c m P−valoarea. Aceasta este:
Pv = P (|Z| > |P0|) = 1− P (Z < |P0|) + P (Z < −|P0|) = 0.5472 > 0.02 = α.
√
Exerciµii suplimentare
Exerciµiu 6.1 Se arunc o moned de 250 de ori, obµinându-se 138 de apariµii ale stemei. La un nivel de semni�-caµie α = 0.05, s se decid dac avem su�ciente dovezi de a a�rma c acest moned este fals .
Exerciµiu 6.2 Caracteristica X reprezint cheltuielile lunare pentru convorbirile telefonice ale unei familii. Înurma unui sondaj la care au participat 100 de familii, am obµinut datele (repartiµia de frecvenµe):(
[50, 75) [75, 100) [100, 125) [125, 150) [150, 175) [175, 200) [200, 250) [250, 300)6 11 13 18 20 14 11 7
).
(a) S se veri�ce, cu nivelul de semni�caµie α = 0.02, ipoteza c media acestor cheltuieli lunare pentru o singur familie este de 140RON , ³tiind c abaterea standard este 35RON .(b) S se veri�ce aceea³i ipotez , în cazul în care abaterea standard nu este cunoscut a priori.
Exerciµiu 6.3 La un examen naµional, se contabilizeaz nota x obµinut de �ecare examinat în parte. Pentru o
analiza statistic , se aleg la întâmplare 200 de candidaµi. S-a g sit c suma notelor alese este200∑i=1
xi = 1345.37 ³i
suma p tratelor acestor note este200∑i=1
x2i = 10128.65. Se cer:
(a) G siµi un interval de încredere pentru media µ a tuturor notelor participanµilor la examen, la nivelul desemni�caµie α = 0.05.(b) Testaµi ipoteza nul (H0) : µ = 6.75, vs. ipoteza alternativ (H1) : µ 6= 6.75, la nivelul α = 0.05. Argumentaµistatistica folosit în testare.
Exerciµiu 6.4 Pentru o selecµie dat , de volum n = 196, am obµinut x = 0.25 ³i s = 4. Nu cunoa³tem nici valoareamedie ³i nici dispersia variabilei aleatoare ce caracterizeaz populaµia. Veri�caµi la nivelul de semni�caµie α = 0.05ipoteza µ = 0, cu alternativa µ 6= 0.
Exerciµiu 6.5 Un patron susµine c �rma sa nu face discriminare sexual la angajare (i.e., atât b rbaµii, cât ³ifemeile au aceea³i ³ans de a se angaja în respectiva �rm ). Se aleg 500 de angajaµi ³i se g sesc 267 de b rbaµi.Testaµi la nivelul de semni�caµie 0.05 dac patronul �rmei spune adev rul sau nu.
Exerciµiu 6.6 Dintre toate înregistr rile vitezelor vehiculelor ce trec prin dreptul radarului �x a³ezat în faµa uni-versit µii, se aleg 10 date la întâmplare. Acestea sunt (în km/h):
68

48 44 55 45 47 41 39 49 55 52
Presupunem c selecµia face parte dintr-o populaµie normal .(a) G siµi un interval de încredere cu încrederea de 98% pentru viteza medie a vehiculelor ce trec prin dreptulradarului.(b) Testaµi dac viteza medie cu care se circul prin faµa acestui radar este de 45km/h sau nu, considerându-se unnivel de semni�caµie α = 0.02 ;(c) Estimaµi probabilitatea ca viteza legal de 50km/h s � fost dep ³it , folosind datele selecµiei considerate.
Exerciµiu 6.7 O selecµie de volum n = 50 este folosit pentru a veri�ca urm toarea ipotez
(H0) : µ = 15 vs. (H1) : µ 6= 15,
la nivelul de semni�caµie α = 0.05. Determinaµi: valoarea critic , regiunea critic , valoarea statisticii pentru selecµiadat ³i concluzia test rii, pentru(a) x = 17.5 ³i s = 4.5 (σ este necunoscut);(b) x = 17.5 ³i σ = 4.
Exerciµiu 6.8 O selecµie de volum n = 50 este folosit pentru a veri�ca urm toarea ipotez
(H0) : µ = 15 vs. (H1) : µ 6= 15,
la nivelul de semni�caµie α = 0.05. Determinaµi: valoarea critic , regiunea critic , valoarea statisticii pentru selecµiadat ³i concluzia test rii, pentru(a) x = 17.5 ³i s = 4.5 (σ este necunoscut);(b) x = 17.5 ³i σ = 4.
Exerciµiu 6.9 Într-un sondaj de opinie, 5 b rbaµi ³i 5 femei au fost întrebate dac urm resc meciuri de fotbal laTV în mod regulat. Toµi b rbaµii ³i doar dou femei au r spuns a�rmativ, ceilalµi spunând c nu. S se testeze lanivelul de semni�caµie α = 0.05 dac diferenµa este semni�cativ din punct de vedere statistic (i.e., dac femeile seuit la fotbal la TV cot la cot cu b rbaµii).
Exerciµiu 6.10 Urm rim preµul X al aceluia³i articol în 20 de magazine, alese la întâmplare. Acestea sunt:
9.6 9.9 10.3 10.0 10.5 9.7 9.9 10.2 10.0 10.4
9.9 9.8 10.1 10.4 9.9 10.2 10.3 10.1 10.0 9.7
Consider m c preµul acestui articol urmeaz o repartiµie gaussian .(i) Se poate admite ipoteza E(X) = 10.0, la nivelul de semni�caµie α = 0.05?(ii) Se poate admite ipoteza D2(X) = 0.2, la nivelul de semni�caµie α = 0.05?
Exerciµiu 6.11 Informaµiile din tabelul de mai jos sunt date despre dou selecµii independente ce au fost extrasedin dou populaµii statistice.
Selecµia Volumul selecµiei media de selecµie deviaµia standard de selecµie1 50 9.75 1.52 75 9.5 0.95
Se cer:(a) Estimaµi punctual ³i printr-un interval de încredere (α = 0.01) valoarea µ1 − µ2;(b) Testaµi (α = 0.01) ipoteza
(H0) : µ1 = µ2 vs. (H1) : µ1 6= µ2
69

Exerciµiu 6.12 O selecµie de 700 de salarii pe or din România arat c media salariului pe or este x = 11.42RON³i s = 9.3. Putem decide, pe baza acestui sondaj, c media salariului pe or este, de fapt, µ > 9.78RON, valoarestabilit de guvernul român? Se va folosi α = 0.05.
70

7 Statistic Aplicat (L7 & S7)
Teste de concordanµ (probleme)
Exemplu 7.1 Se arunc un zar de 60 de ori ³i se obµin rezultatele din Tabelul 7.1. S se decid , la nivelul desemni�caµie α = 0.02, dac zarul este corect sau fals.
Faµa (clasa Oi) Frecvenµa absolut (ni)1 152 73 44 115 66 17
Tabela 7.1: Tabel cu num rul de puncte obµinute la aruncarea zarului.
Soluµie: (aplic m testul χ2 de concordanµ , cazul neparametric)Zarul este corect doar dac �ecare faµ a sa are aceea³i ³ans de a aparea, adic probabilit µile ca �ecare faµ înparte s apar sunt:
(H0) : pi =1
6, (i = 1, 2, . . . , 6).
Altfel, not m cu X variabila aleatoare ce are valori num rul punctelor ce apar la aruncarea zarului. Un zar corectar însemna c X urmeaz repartiµia uniform discret U(6).Toate cele 60 de rezultate obµinute în urma arunc rii zarului pot � împ rµite în ³ase clase. Aceste clase sunt:Oi = {i}, i ∈ {1, 2, . . . , 6}. Ipoteza nul este (H0) sau, echivalent,
(H0) : Funcµia de repartiµie a lui X este U(6).
Ipoteza alternativ este "(H0) nu are loc", adic :
(H1) : Exist un j, cu pj 6=1
6, (j ∈ {1, 2, . . . , 6}).
Calculez valoarea statisticii χ2 pentru observaµiile date:
χ20 =
(15− 10)2
10+
(7− 10)2
10+
(4− 10)2
10+
(11− 10)2
10+
(6− 10)2
10+
(17− 10)2
10= 13.6.
Repartiµia statisticii χ2 este χ2 cu k − 1 = 5 grade de libertate. Regiunea critic este:
U = (χ20.98; 5; +∞) = (13.3882, +∞).
Deoarece χ20 se a� în regiunea critic , ipoteza nul se respinge la nivelul α = 0.02, a³adar zarul este m sluit.
Codul Matlab:
n = 60; k=6; alpha = 0.02; x = 1:6; f = [15,7,4,11,6,17]; p = 1/6*ones(1,6);
chi2 = sum((f-n*p).^2)./(n*p)); % valoarea χ20
val = chi2inv(1-alpha,k-1); % cuantila χ20.99; 5
H = (chi2 > val) % afiseaza 0 daca zarul e corect si 1 daca nu √
Observaµia 7.2 Dac nivelul de semni�caµie este ales α = 0.01, atunci χ20.99; 5 = 15.0863, ceea ce determin
acceptarea ipotezei nule (adic zarul este corect) la acest nivel.
71

Exemplu 7.3 În urma unui recens mânt, s-a determinat c proporµiile indivizilor din RO ce aparµin uneia dintrecele patru grupe sanguine sunt: O : 34%, A : 41%, B : 19%, AB : 6%. S-au testat aleator 450 de persoane dinRO, obµinându-se urm toarele rezultate:
Grupa sanguin O A B ABFrecvenµa 136 201 82 31
Veri�caµi, la nivelul de semni�caµie α = 0.05, compatibilitatea datelor cu rezultatul teoretic.
Soluµie: Ipotezele statistice sunt:
(H0) : Rezultatul observat este compatibil cu cel teoretic,
(H1) : Exist diferenµe semni�cative între rezultatul teoretic ³i observaµii.
Dac ipoteza nul ar � adev rat , atunci valorile a³teptate pentru cele patru grupe sanguine (din 450 de persoane)ar �: O : 153.5, A : 184.5, B : 85, AB : 27.
Calculez valoarea statisticii χ2 pentru observaµiile date:
χ20 =
(136− 153.5)2
153.5+
(201− 184.5)2
184.5+
(82− 85)2
85+
(31− 27)2
27= 4.1004.
Repartiµia statisticii este χ2(3). Astfel, regiunea critic este:
U = (χ20.95; 3; +∞) = (7.8147, +∞).
Deoarece χ20 nu se a� în regiunea critic , ipoteza nul nu poate � respins la acest nivel de semni�caµie. √
Teste de concordanµ în Matlab
Am v zut deja c funcµia chi2gof(x) testeaz (folosind testul χ2 al lui Pearson) dac vectorul x provine dintr-orepartiµie normal , cu media ³i dispersia estimate folosind x.
Pentru testul χ2, forma general a funcµiei Matlab este:
[h,p,stats] = chi2gof(X,name1,val1,name2,val2,...)
unde:− h, p sunt la fel ca în exemplele anterioare;− perechile namei/valuei sunt opµionale. Variabilele namei pot �: num rul de clase, 'nbins', un vector devalori centrale ale intervalelor ce de�nesc clasele, 'ctrs', sau un vector cu capetele claselor, 'edges'.Alte variabile ce pot � utilizate: 'cdf', 'expected', 'nparams', 'emin', 'frequency', 'alpha'.− variabila de memorie stats a�³eaz : chi2stat - statistica χ2, df - gradele de libertate, edges - un vectorcu capetele intervalelor claselor dup triere, O - num rul de valori observate în �ecare clas , E - num rul de valoria³teptate în �ecare clas .
Exemplu 7.4 Spre exempli�care, revenim la Exerciµiul 7.1, dar cu valoarea nivelului de încredere din Observaµia7.2. Codul Matlab ce folose³te funcµia de mai sus este:
x = 1:6; f = [15,7,4,11,6,17]; p = 1/6*ones(1,6); e = N*p; alpha = 0.01;
[h, p, stats] = chi2gof(x,'ctrs', x,'frequency', f,'expected',e, 'alpha',alpha)
72

Acest cod returneaz :
h = p = stats =
0 0.0184 chi2stat: 13.6000
df: 5
edges: [0.5000 1.5000 2.5000 3.5000 4.5000 5.5000 6.5000]
O: [15 7 4 11 6 17]
E: [10 10 10 10 10 10]
Acest rezultat con�rm c ipoteza nul (zarul este corect) este acceptat la nivelul α = 0.01. √
Exemplu 7.5 La campionatul mondial de fotbal din 2006 au fost jucate în total 64 de meciuri, iar repartiµianum rului de goluri înscrise într-un meci are tabelul de distribuµie ca în Tabelul 7.2. Determinaµi (la nivelul desemni�caµie α = 0.05) dac num rul de goluri pe meci urmeaz o distribuµie Poisson.
Nr. de goluri pe meci Nr. de meciuri0 81 132 183 114 105 26 2
Tabela 7.2: Tabel cu num rul de goluri pe meci la FIFA WC 2006.
Soluµie: (aplic m testul de concordanµ χ2 parametric) Fie X variabila aleatoare ce reprezint num rul degoluri înscrise într-un meci. Teoretic, X poate lua orice valoare din mulµimea N. Mulµimea observaµiilor f cuteasupra lui X este {1, 2, 3, 4, 5, 6}, cu frecvenµele respective din tabel. În total, au fost inscrise 144 de goluri.Estim m num rul de goluri pe meci prin media lor, adic λ = x = 144
64 = 2.25. Pe baza datelor observate, dorim s test m dac X urmeaz o repartiµie Poisson. Avem astfel de testat ipoteza nul :
(H0) : X urmeaz o lege Poisson P(λ).
vs. ipoteza alternativ (H1) : X nu urmeaz o lege Poisson P(λ).
Dac admitem ipoteza (H0) (adic X ∼ P(2.25), atunci pi = pi(λ) ³i distribuµia valorilor variabilei este dat de
Clasa ni pi n pi(ni − n pi)2
n pi0 8 0.1054 6.7456 0.23331 13 0.2371 15.1775 0.31242 18 0.2668 17.0747 0.05013 11 0.2001 12.8060 0.25474 10 0.1126 7.2034 1.08575 2 0.0506 3.2415 −≥ 6 2 0.0274 1.7514 −≥ 5 4 0.0780 4.9926 0.1973
Tabela 7.3: Tablou de distribuµie pentru P(2.25).
Tabelul 7.3. Valoarea pi este P (X = i), adic probabilitatea ca variabila aleatoare X ∼ P(2.25) s ia valoarea i
73

(i = 0, 1, 2, 3, 4). Am putea forma 7 clase. Deoarece pentru ultimele dou clase din Tabelul 7.3, anume {X = 5}³i {X ≥ 6}, numerele ni nu dep ³e³c valoarea 3, le ³tergem din tabel ³i le unim într-o singur clas , în care {X ≥ 5},cu ni = 4 > 3. Vom nota prin p≥5 probabilitatea
p≥5 = P (X ≥ 5) = 1− P (X < 5) = 1− P (X ≤ 4) = 1−4∑i=0
P (X = i).
R mânem a³adar cu 6 clase. Ipoteza nul (H0) se poate rescrie astfel:
(H0) : p0 = 0.1054, p1 = 0.2371, p2 = 0.2668, p3 = 0.2001, p4 = 0.1126, p≥5 = 0.0780.
Ipoteza alternativ este(H1) : ipoteza (H0) nu este adev rat .
Calcul m acum valoarea statisticii χ2 pentru observaµiile date:
χ20 =
(8− 6.7456)2
6.7456+
(13− 15.1775)2
15.1775+
(18− 17.0747)2
17.0747+
(11− 12.8060)2
12.8060+ . . .
+(10− 7.2034)2
7.2034+
(4− 4.9926)2
4.9926= 2.1337.
Deoarece avem 6 clase ³i am estimat parametrul λ, deducem c num rul gradelor de libertate este 6−1−1 = 4. Cu-antila de referinµ (valoarea critic ) este χ2
0.95; 4 = 9.4877. Regiunea critic pentru χ2 este intervalul (χ20.95; 4, +∞).
Deoarece χ20 < χ2
0.95; 4, urmeaz c ipoteza nul (H0) nu poate � respins la nivelul de semni�caµie α. A³adar,este rezonabil s a�rm m c num rul de goluri marcate urmeaz o repartiµie Poisson. Prezent m mai jos un codMatlab ce rezolv aceast problem .
X = [0*ones(8,1);1*ones(13,1);2*ones(18,1);3*ones(11,1);4*ones(10,1);...
5*ones(2,1);6*ones(2,1)];
f = [8 13 18 11 10 4]; % vectorul de frecvente absolute
n = 64; alpha = 0.05; lambda = mean(X);
for i=1:5 % probabilitatile P(X=i), i=0,1,2,3,4
p(i) = poisspdf(i-1,lambda);
end
p(6)= 1 - poisscdf(4,lambda); % probabilitatea P(X≥5)H2 = sum((f-n*p).^2./(n*p)); Hstar = chi2inv(1-alpha,4);
if (H2 < Hstar)
disp('X urmeaza repartitia Poisson');
else
disp('X nu urmeaza repartitia Poisson');
end √
Observaµia 7.6 Dac ipoteza nul este respins , atunci motivul poate � acela c unele valori observate au deviatprea mult de la valorile a³teptate. În acest caz, este interesant de observat care valori sunt extreme, cauzândrespingerea ipotezei nule. Putem de�ni astfel reziduurile standardizate:
ri =Oi − n pi√n pi (1− pi)
=Oi − Ei√Ei (1− pi)
,
unde prin Oi am notat valorile observate ³i prin Ei valorile a³teptate. Dac ipoteza nul ar � adev rat , atunciri ∼ N (0, 1). În general, reziduuri standardizate mai mari ca 2 sunt semne pentru numere observate extreme.
Exemplu 7.7 Într-o anumit zi de lucru, urm rim timpii de a³teptare într-o staµie de tramvai, pân la încheiereazilei de lucru (adic , pân trece ultimul tramvai). Fie T caracteristica ce reprezint num rul de minute a³teptateîn staµie, pân sose³te tramvaiul. Rezultatele observaµiilor sunt sumarizate în Tabelul 7.4. Se cere s se cerceteze(α = 0.05) dac timpii de a³teptare sunt repartizaµi exponenµial.
74

Durata 0− 5 5− 10 10− 15 15− 20 20− 25ni 39 35 14 7 5
Tabela 7.4: Timpi de a³teptare în staµia de tramvai.
Soluµie: (folosim testul χ2 de concordanµ , parametric) Avem de testat ipoteza nul
(H0) F (x) ∼= F0(x) = 1− e−λx, x > 0
vs. ipoteza alternativ (H1) ipoteza (H0) este fals .
Deoarece parametrul λ este necunoscut, va trebui estimat pe baza selecµiei date. Pentru aceasta, folosim metodaverosimilit µii maxime. Funcµia de verosimilitate pentru exp(λ) este
L(t1, t2, . . . , tn; λ) =
n∏k=1
λe−λ ti = λne−λn t.
Mai sus, am notat prin t1, t2, . . . , tn valorile de selecµie pentru variabila aleatoare T .Punctele critice pentru L(λ) sunt date de ecuaµia
∂ lnL
∂λ= 0 =⇒ ∂
∂λ
(n lnλ− λn t
)=⇒ λ =
1
t.
Se observ cu u³urinµ c ∂2 lnL
∂λ2|λ=λ = −n t2 < 0,
de unde concluzion m c λ este punct de maxim pentru funcµia de verosimilitate.Tabelul de distribuµie pentru caracteristica T este:(
2.5 7.5 12.5 17.5 22.539 35 14 7 5
).
Calcul m media de selecµie, t = 1100 (2.5 · 39 + 7.5 · 35 + 12.5 · 14 + 17.5 · 7 + 22.4 · 5) = 7.7, adic λ = 0.1299.
Dac variabila T ar urma repartiµia exponenµial exp(λ), atunci probabilit µile ca T s ia valori în �ecare clas sunt, în mod corespunz tor:
pi = pi(λ) = P (X ∈ (ai, ai+1] | F = F0) = F0(ai+1; λ)− F0(ai; λ), i = 1, 2, 3, 4, 5.
unde a6 = +∞.În Tabelul 7.5 am înregistrat urm toarele date:
• clasele (de notat c ultima clas este (20, +∞), deoarece se dore³te o concordanµ a datelor observate cudate repartizate exponenµial, iar mulµimea valorilor pentru repartiµia exponenµial este R+),
• extremit µile din stânga ale claselor (ai),
• frecvenµele absolute ni (sau valorile observate în �ecare clas ),
• probabilit µile pi, valorile a³teptate în �ecare clas (n pi),
• erorile relative de aproximare ale datelor a³teptate cu cele observate.
Num rul gradelor de libertate este k − p − 1 = 3. Calcul m valoarea critic χ20.95; 3 = 7.8147 ³i, de asemenea,
valoarea
H0 =
k∑i=1
(ni − n pi)2
n pi= 6.5365.
75

Deoarece χ20 < χ2
0.95; 3, ipoteza (H0) nu poate � respins la acest nivel de semni�caµie.
Codul Matlab este urm torul:
T = [2.5*ones(39,1);7.5*ones(35,1);12.5*ones(14,1);17.5*ones(7,1);22.5*ones(5,1)];
% sau
% T = [5*rand(39,1);5+5*rand(35,1);10+5*rand(14,1);15+5*ones(7,1);20+5*ones(5,1)];
n = 100; alpha = 0.05; m = mean(T); lambda = 1/m;
a = [0, 5, 10, 15, 20, Inf]; f = [39, 35, 14, 7, 5];
for i =1:5
p(i) = expcdf(a(i+1),m)-expcdf(a(i),m);
end
H2 = sum((f-n*p).^2./(n*p)); cuant = chi2inv(0.95,3);
if (H2 < cuant)
disp('Timpii de asteptare sunt exponential repartizati');
else
disp('ipoteza (H0) se respinge');
end √
Clasa ai ni pi n pi(ni − n pi)2
n pi(0, 5] 0 39 0.4776 47.7615 1.6072(5, 10] 5 35 0.2495 24.9499 4.0483(10, 15] 10 14 0.1303 13.0334 0.0717(15, 20] 15 7 0.0681 6.8085 0.0054
(20, +∞) 20 5 0.0745 7.4467 0.8039
(0, +∞) − 100 1 100 6.5365
Tabela 7.5: Tabel de distribuµie pentru timpii de a³teptare.
76

Corelaµie ³i Regresie
Fie X ³i Y doi vectori de acela³i tip. Urm toarele funcµii din Matlab sunt utile pentru analiza corelaµiei ³iregresiei:
• scatter(X,Y) reprezint gra�c valorile lui Y vs. valorile lui X;
• R = corrcoef(X,Y) calculeaz coe�cientul de corelaµie între X ³i Y. Rezultatul este a�³at sub forma:>> ans =
1.0000 ρρ 1.0000
unde 1.0000 este coe�cientul de corelaµie dintre X ³i X, respectiv Y ³i Y, iar ρ este coe�cientul c utat.
• cov(X,Y) pentru matricea de covarianµ empiric dintre X ³i Y;
• b = regress(Y,X) a�³eaz estimarea coe�cienµilor pentru care Y = bX. Aici, X este o matrice n × k ³i Yun vector coloana n× 1. Coloanele vectorului X corespund observaµiilor (i.e., variabilelor independente).Dac X este un vector coloan de aceea³i dimensiune cu Y, atunci b este doar un scalar.Dac X este matrice, atunci putem folosi aceast comand pentru a estima coe�cienµii de regresie liniar multipl . Spre exemplu, s presupunem c se dore³te estimarea coe�cienµilor de regresie liniar simpl , i.e.,β0 ³i β1 pentru care y = β0 + β1 x, unde pentru �ecare dintre x ³i y avem n observaµii. În acest caz, k = 2.Fie X, respectiv, Y vectorii ce conµin aceste observaµii. Comanda Matlab care estimeaz cei doi coe�cienµieste
B = regress(Y', [ones(n,1)'; X]')
Comanda furnizeaz aproxim ri pentru parametrii β0 ³i β1 ce fac urm toarea aproximare cât mai bun :y1y2...yn
≈ β0
11...1
+ β1
x1x2...xn
.
• p = polyfit(X,Y,n) g se³te coe�cienµii unui polinom p(x) de grad n ale c rui valori p(xi) se apropie celmai mult de datele observate yi, în sensul celor mai mici p trate. Matlab va a�³a în acest caz un vectorlinie de lungime n+1, conµinând coe�cienµii polinomiali în ordinea descresc toare a puterilor. Spre exemplu,dac
p(x) = β0 + β1x+ β2x2 + · · ·+ βnx
n,
atunci Matlab va a�³aβn, . . . , β1, β0.
• Y = polyval(p,X) a�³eaz valorile unui polinom p(x) pentru valorile din vectorul X. Polinomul p(x) estedat prin coe�cienµii s i, ordonaµi în ordine descresc toare a puterilor. De exemplu, dac p(x) = 3x2 + 2x+ 4³i dorim s evalu m acest polinom pentru trei valori, −3, 1 ³i 5, atunci scriem în Matlab:
p = [3 2 4]; polyval(p,[-3 1 5])
obµinând rezultatul:ans = 37 5 69
Exerciµiu 7.8 Dorim s determin m dac exist vreo corelaµie între notele la examenul de Probabilit µi ³i cele dela Statistic obµinute de studenµii unui an de studiu. În acest sens, au fost observate notele obµinute de 10 studenµi
77

la aceste dou discipline ³i au fost trecute în Tabelul 7.6 de mai jos. Se cere:(a) Stabiliµi dac exist o leg tur puternic între aceste note (r ³i r2);(b) Determinaµi dreapta de regresie a notelor de la Statistic în raport cu notele la Probabilit µi ³i desenaµi-o înacela³i sistem de axe ca ³i notele obµinute (scatter plot).(c) Testaµi dac exist sau nu vreo corelaµie între notele de la Statistic ³i Probabilit µi.
Student A B C D E F G H I JProbabilit µi 82 36 72 58 70 48 44 94 60 40Statistic 84 42 50 64 68 54 46 80 60 32
Tabela 7.6: Notele la Statistic ³i Probabilit µi.
Soluµie: (a) Calcul m r (cu formula lui Person). Funcµia Matlab pentru coe�cientul Pearson este corrcoef.În codul Matlab de mai jos l-am calculat pe r folosind aceast funcµie, dar ³i în dou alte modalit µi, folosindformula
r =cove(x, y)
sx · sy,
sau scriind desf ³urat expresia lui r.
(b) Coe�cienµii de regresie se pot obµine în 3 moduri, �e folosind funcµia Matlab polyfit, care realizeaz �tareadatelor cu un polinom, în cazul liniar �ind un polinom de forma S(P ) = β0 + β1 P . O alt variant de calcula coe�cienµilor β0 ³i β1 este simpla implementare în Matlab a formulelor pentru ace³tia. A treia variant estefolosirea funcµiei regress din Matlab.Reprezentarea gra�c a datelor poate � realizat folosind ori funcµia plot, ori funcµia "scatter", ambele funcµiiprede�nite din Matlab. Gra�cul este cel din Figura 7.1.
P = [82,36,72,58,70,48,44,94,60,40]; S = [84,42,50,64,68,54,46,80,40,32];
mp = mean(P); ms = mean(S);
%%%~~~~~~~~~~~~~~ Calculez coeficientul de corelatie empiric ~~~~~~~~~~~~~~~~~~~~~~~~~~
CC = corrcoef(P,S); r = CC(1,2)
%%%~~~~~~~~~~~~~~~~~~~~ Alte variante de calcul pentru r ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
% C = cov(P,S)/(std(P)*std(S)); r = C(1,2);
% r = sum((P-mp).*(S-ms))/sqrt(sum((P-mp).^2)*sum((S-ms).^2));
%%%~~~~~~~~~~~~~~~~~~~~~~~~ Calculez coeficientii de regresie ~~~~~~~~~~~~~~~~~~~~~~~
B = polyfit(P,S,1)
%%%~~~~~~~~~~~~~~~~~~~~ Alte variante de calcul pentru B ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
% b1 = sum((P-mp).*(S-ms))/sum((P-mp).^2); b0 = ms - b1*mp;
% B = regress(S',[P;ones(10,1)']');
%%%~~~~~~~~~~~~~~~~ Scatter plot si dreapta de regresie ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
x=0:100; plot(P,S,'*',x,B(2) + B(1)*x,'r-')
% scatter(P,S) % varianta pentru scatter plot
%%%~~~~~~~~~~~~~~~~~~~~~~~ Testul pentru ρ = 0 ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
alpha = 0.05; n = 10; T0 = r*sqrt((n-2)/(1-r^2)); quant = tinv(1-alpha/2,n-2);
if (abs(T0) < quant)
disp('P si S nu sunt corelate')
else
disp('P si S sunt corelate')
end
Rulând codul de mai sus, obµinem:
r = B = P si S sunt corelate
0.8247 0.7553 10.3816 √
78
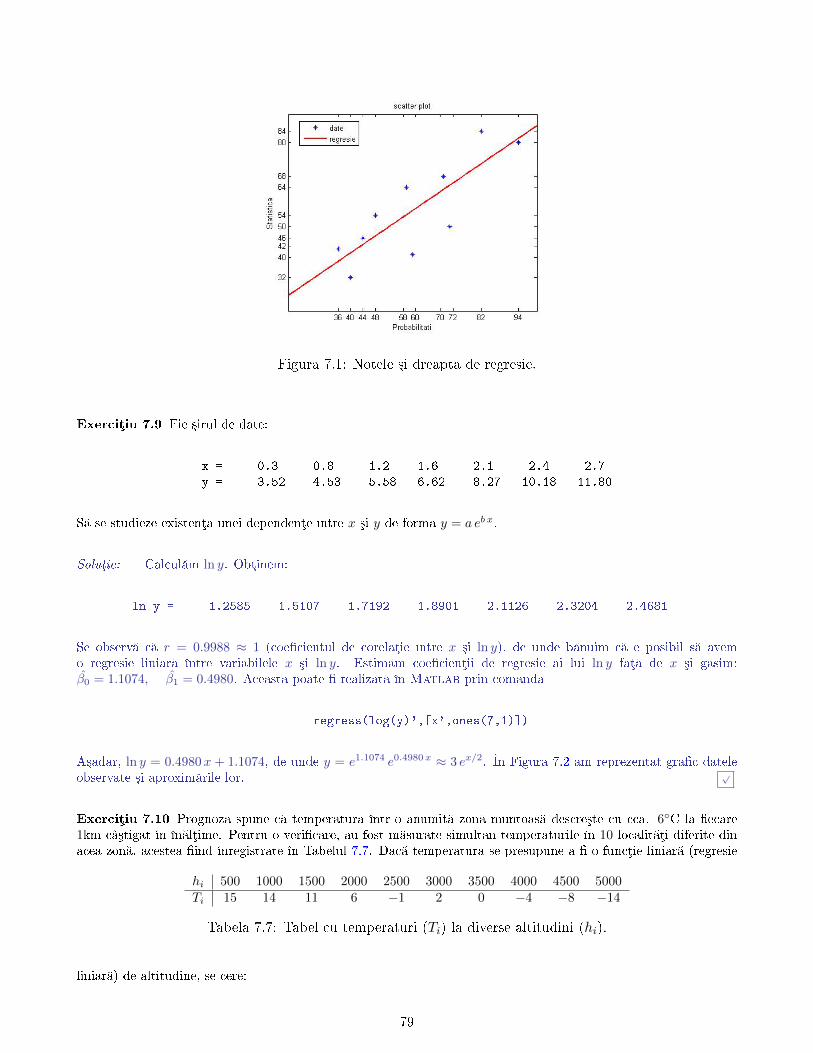
Figura 7.1: Notele ³i dreapta de regresie.
Exerciµiu 7.9 Fie ³irul de date:
x = 0.3 0.8 1.2 1.6 2.1 2.4 2.7
y = 3.52 4.53 5.58 6.62 8.27 10.18 11.80
S se studieze existenµa unei dependenµe între x ³i y de forma y = a eb x.
Soluµie: Calcul m ln y. Obµinem:
ln y = 1.2585 1.5107 1.7192 1.8901 2.1126 2.3204 2.4681
Se observ c r = 0.9988 ≈ 1 (coe�cientul de corelaµie între x ³i ln y), de unde b nuim c e posibil s avemo regresie liniar între variabilele x ³i ln y. Estim m coe�cienµii de regresie ai lui ln y faµ de x ³i g sim:β0 = 1.1074, β1 = 0.4980. Aceasta poate � realizat în Matlab prin comanda
regress(log(y)',[x',ones(7,1)])
A³adar, ln y = 0.4980x + 1.1074, de unde y = e1.1074 e0.4980 x ≈ 3 ex/2. În Figura 7.2 am reprezentat gra�c dateleobservate ³i aproxim rile lor. √
Exerciµiu 7.10 Prognoza spune c temperatura într-o anumit zon muntoas descre³te cu cca. 6◦C la �ecare1km câ³tigat în în lµime. Pentru o veri�care, au fost m surate simultan temperaturile în 10 localit µi diferite dinacea zon , acestea �ind înregistrate în Tabelul 7.7. Dac temperatura se presupune a � o funcµie liniar (regresie
hi 500 1000 1500 2000 2500 3000 3500 4000 4500 5000Ti 15 14 11 6 −1 2 0 −4 −8 −14
Tabela 7.7: Tabel cu temperaturi (Ti) la diverse altitudini (hi).
liniar ) de altitudine, se cere:
79

Figura 7.2: Aproximarea datelor din Exerciµiul 7.9
(i) S se estimeze parametrii β0 ³i β1;(ii) S se testeze (α = 0.05) dac prognoza din enunµ este adevarat (i.e., β1 = −0.006);(iii) S se g seasc un interval de încredere pentru panta dreptei de regresie, β1;(iv) Cât de bun este aproximarea temperaturii cu o funcµie liniar de altitudine?(v) Estimaµi temperatura la altitudinea h = 2544. G siµi, de asemenea, un interval de încredere pentru aceastatemperatur .
Soluµie: (i) Estim m parametrii necunoscuµi folosind formulele
β1 =sxys2x
³i β0 = y − β1 x, (7.1)
sau folosind funcµia Matlab polyfit (vezi codul de mai jos).(ii) Pentru testarea ipotezei nule (H0) : β1 = −0.006 utiliz m testul pentru coe�cientul β1.(iii) Un interval de încredere pentru β1 se poate calcula folosind formula[
β1 − t1−α2 ;n−2σ
sx, β1 + t1−α2 ;n−2
σ
sx
]. (7.2)
(iv) Pentru a decide cât de bun este aproximarea, calcul m coe�cientul de determinare, R2. Acesta este R2 =94.83, ceea ce înseamn c temperatura real este foarte aproape de cea prognozat .(v) Utiliz m formulele
yp = β0 + β1 xp. (7.3)
³i [yp − t1−α2 ;n−2 σ
√1 +
1
n+
(xp − x)2
s2x, yp + t1−α2 ;n−2 σ
√1 +
1
n+
(xp − x)2
s2x
]. (7.4)
pentru xp = 2544. (vezi rezultatele generate de codul de mai jos)Codul Matlab este urm torul:
h = [500 1000 1500 2000 2500 3000 3500 4000 4500 5000];
T = [15 14 11 6 -1 2 0 -4 -8 -14]; mh = mean(h); mT = mean(T);
%%%~~~~~~ Calculez coeficientul de corelatie empiric si coeficientul de determinare ~~~
CC = corrcoef(h,T); r = CC(1,2)
R2 = r^2
%%%~~~~~~~~~~~~~~~~~~~ Calculez coeficientii de regresie ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
80

B = polyfit(h,T,1)
%%%~~~~~~~~~~~~~~~~~~~~ Alte variante de calcul pentru B ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
% B = regress(T',[h;ones(10,1)']');
% b1 = sum((h-mh).*(T-mT))/sum((h-mh).^2); b0 = mT - b1*mh;
%%%~~~~~~~~~~~~~~~~~~~~ Scatter plot si dreapta de regresie ~~~~~~~~~~~~~~~~~~~~~~~~~
x=0:5600; plot(h,T,'*',x,B(2) + B(1)*x,'r-')
%%%~~~~~~ Testul pentru panta dreptei de regresie, (H0) : β1 = −0.006 ~~~~~~~~~~~~~~~~
alpha = 0.05; n = 10;
sigmahat = sqrt(sum((T-B(2) - B(1)*h).^2)/(n-2)); sigmax = std(h);
T0 = (B(1)+0.006)*sigmax/sigmahat; quant = tinv(1-alpha/2,n-2);
if (abs(T0) < quant)
disp('ipoteza (H0) se accepta')
else
disp('ipoteza (H0) se respinge')
end
%%%~~~~~~~~~~~~~~~ Interval de incredere pentru β1 ~~~~~~~~~~~~~~~~~~~~~~~
CI = [B(1) - quant*sigmahat/sigmax,\;B(1) + quant*sigmahat/sigmax]
hp = 2544; Tp = B(2) + B(1)*hp
CI_T = [Tp - quant*sigmahat*sqrt{1 + 1/n + (hp-mh)^2/sigmax^2}, ...
Tp + quant*sigmahat*sqrt{1 + 1/n + (hp-mh)^2/sigmax^2}]
Rulând codul de mai sus, obµinem:
r = R2 = B = CI =
-0.9738 94.83 [-0.0061, 18.9333] [-0.0096, -0.0026]
Tp = CI_T =
3.3610 [-2.2335, 8.9555]
ipoteza nula se accepta √
Figura 7.3: Diagrama de temperaturi în funcµie de altitudine, ³i dreapta de regresie.
81

Exerciµii suplimentare
Exerciµiu 7.1 Testaµi normalitatea datelor din Tabelul 3.1 la nivelul de semni�caµie α = 0.1.
Exerciµiu 7.2 Se prezice c repartiµia literelor care apar cel mai des în limba englez ar � urm toarea:
Litera O R N T EFrecvenµa 16 17 17 21 29
Aceasta semni�c urm toarea: de �ecare dat când cele 5 litere apar într-un text, în 16% dintre cazuri apare literaO, în 21% dintre cazuri apare litera T etc. S presupunem c un criptologist analizeaz un text ³i num r apariµiilecelor 5 litere. Acesta a g sit urm toarea distribuµie:
Litera O R N T EFrecvenµa 18 14 18 19 31
Folosind testul χ2 de concordanµ , s se veri�ce dac aceste apariµii sunt în not discordant cu predicµia iniµial .
Exerciµiu 7.3 Un student ia cu împrumut o carte de la bibliotec ³i observ c pagina de interes este rupt pealocuri. Totu³i, poate citi textul din Figura 7.4. Se cere s se reconstruiasc pasajul de text (i.e., determinaµi y ³idreapta de regresie a lui x faµ de y). De asemenea, calculaµi coe�cientul empiric de corelaµie r ³i comentaµi asupraaproxim rii datelor de seleµie prin dreptele de selecµie.
Figura 7.4: Fragment incomplet dintr-un text
Exerciµiu 7.4 Tabelul 7.8 conµine cali�cativele obµinute de un elev de clasa I la cele 9 discipline, în �ecare dintrecele dou semestre. S se g seasc o m sur a leg turii dintre cele dou seturi de cali�cative (e.g., coe�cientul decorelaµie Spearman).
Discipline A B C D E F G H ISem. I FB FB B FB B B B S FBSem. II B B B FB FB S B S FB
Tabela 7.8: Cali�cative din anul I de studiu
Exerciµiu 7.5 Se dau urm toarele date:
(a) Testaµi dac ρ = 0 (coe�cientul de corelaµie teoretic).(b) Este faptul c x ³i y sunt legate prin relaµia y = x2 în contradicµie cu rezultatul de la punctul (a) (datele suntperfect necorelate)?(c) Calculaµi coe�cientul de corelaµie Spearman.
82

x −3 −2 −1 0 1 2
y 9 4 1 0 1 4
Exerciµiu 7.6 Suntem interesaµi în determinarea unei leg turi între în lµime ³i m rimea la pantof. Datele dintabelul de mai jos reprezint observaµii asupra în lµimilor (H) ³i a m rimilor la pantof (M) pentru 10 b rbaµi, ale³ila întâmplare.
H 1.75 1.70 1.80 1.65 1.83 1.73 1.86 1.65 1.68 1.82M 43 41.5 44 40.5 44.5 41 44.5 39.5 40 43.5
(a) Calculaµi coe�cientul de corelaµie Pearson dintre în lµime ³i m rimea la pantof. Ce procent din valorile lui Msunt determinate de valorile lui H(b) Determinaµi o aproximare pentru dreapta de regresie a lui M faµ de H.(c) Obµineµi o predicµie a m rimii la pantof pentru un b rbat cu în lµimea 1.78.
(d) La nivelul de semni�caµie α = 0.05, testaµi ipoteza c panta dreptei de regresie este3
4.
Exerciµiu 7.7 Fie ³irul de date:
u = 1.0 1.5 2.0 2.5 3.0 3.5 4.0
v = 1.5 4.5 7.5 12.5 17.5 24.5 32.5
S se studieze existenµa unei dependenµe între u ³i v de forma v = a u2 + b.
Exerciµiu 7.8 În tabelul urm tor, se dau câte 5 valori pentru dou variabile x ³i y, unde y este variabila indepen-dent . Determinaµi o dreapta de regresie potrivit pentru a calcula(i) valoarea lui x când y = 2.5;(ii) valoarea lui y când x = 50;(iii) Putem prezice valoarea lui y pentru x = 75?
x 46 55 41 58 53
y 1.7 2.1 1.5 2.9 1.9
Exerciµiu 7.9 Se m soar viteza unei ma³ini, v, în primele 10 secunde dup aceasta a început s accelereze.Aceste date sunt înregistrate în Tabelul 7.9. Se cere:
t 0 1 2 3 4 5 6 7 8 9 10v 0 3.1 6.9 9.9 12.7 16.1 19.8 21.2 22.8 24.3 25.9
Tabela 7.9: Viteza unei ma³ini în primele 10 secunde dup plecarea de pe loc
(a) Desenaµi diagrama scatter plot;(b) Determinaµi dreapta de regresie a lui v faµ de t;(c) Calculaµi coe�cientul de corelaµie empiric ³i comentaµi asupra validit µii aproxim rii datelor cu dreapta deregresie.
83

Exerciµiu 7.10 Opinia general este c rata maxim (R) a b t ilor inimii unei persoane se poate determina dup formula R = β0 + β1 V , unde V este vârsta persoanei, calculat în ani. Cercet torii cardiologi a�rma c ace³ticoe�cienµi ar �: β0 = 220 ³i β1 = −1. Pentru o veri�care empiric a acestei a�rmaµii, sunt alese la întâmplare 15persoane de diverse vârste, care sunt supuse unui test pentru determinarea ratei maxime ale bat ilor inimii. Acesterezultate sunt contabilizate în Tabelul 7.10.(a) Calculaµi coe�cientul de corelaµie Pearson dintre vârst ³i rata maxim a bat ilor inimii. Care este semni�caµiaacestei valori?(b) Determinaµi dreapta de regresie a lui R faµ de V ³i desenaµi-o în acela³i sistem de axe cu datele din tabel.(c) Testaµi ipoteza (H0) : β1 = −1, vs. ipoteza alternativ (H1) : β1 6= −1, la nivelul de semni�caµie α = 0.05.
Vârsta 15 23 25 35 17 34 54 50 45 42 19 42 20 39 37Rata max 207 186 187 180 200 175 169 183 156 183 199 174 198 183 178
Tabela 7.10: Tabel cu rata maxim a bat ilor inimii în funcµie de vârst .
Exerciµiu 7.11 Dreapta de regresie a variabilei y faµ de variabila x este y = 2x − 6. Determinaµi condiµiile încare dreapta de regresie a lui x faµ de y este x = 0.5 y + 3.
A 3 1 4 12 11 3 5 2 9 6 4 6 7 6 14N 9.00 9.50 8.75 4.75 5.50 8.50 6.75 8.25 5.50 6.75 8.00 7.75 6.00 7.00 3.50
Tabela 7.11: Tabel cu absenµe ³i note la Statistic .
Exerciµiu 7.12 Tabelul 7.11 conµine num rul de absenµe (A) la Statistic ³i notele corespunz toare (N) a 15studenµi.(a) Calculaµi coe�cientul de corelaµie Pearson. Care este semni�caµia acestei valori referitor la relaµia dintre absenµe³i note?(b) Determinaµi dreapta de regresie a lui N faµ de A ³i desenaµi-o în acela³i sistem de axe cu datele din tabel.(c) Testaµi, la un nivel de semni�caµie α = 0.05, dac exist dovezi su�ciente pentru a a�rma c între num rul deabsenµe ³i notele obµinute exist o corelaµie.
Exerciµiu 7.13 În Tabelul 7.12 datele reprezint în lµimile (H) ³i masele corporale (M) a 10 fete dintr-o clas aunui liceu. Suntem interesaµi în prezicerea masei corporale, ³tiind înalµimea unei eleve.
H 179.6 166.8 163.1 180.0 158.4 166.5 165.8 168.1 175.9 160.7M 61.2 48.2 46 64.4 46.3 54.7 51.4 55.3 65.3 47.9
Tabela 7.12: Înalµimea ³i masa corporal a 10 eleve dintr-o clas .
(a) Desenaµi diagrama scatter plot a lui H versus M . Bazându-v pe aceast diagram , consideraµi c metodaregresiei liniare este potrivit în acest caz?(b) Calculaµi estimaµii ale parametrilor (β0 ³i β1) de regresie liniar ³i reprezentaµi gra�c dreapta de regresie liniar .(c) Obµineµi o estimare nedeplasat pentru σ2.(d) Testaµi ipoteza nul (H0) : β1 = 0.9.
84

















