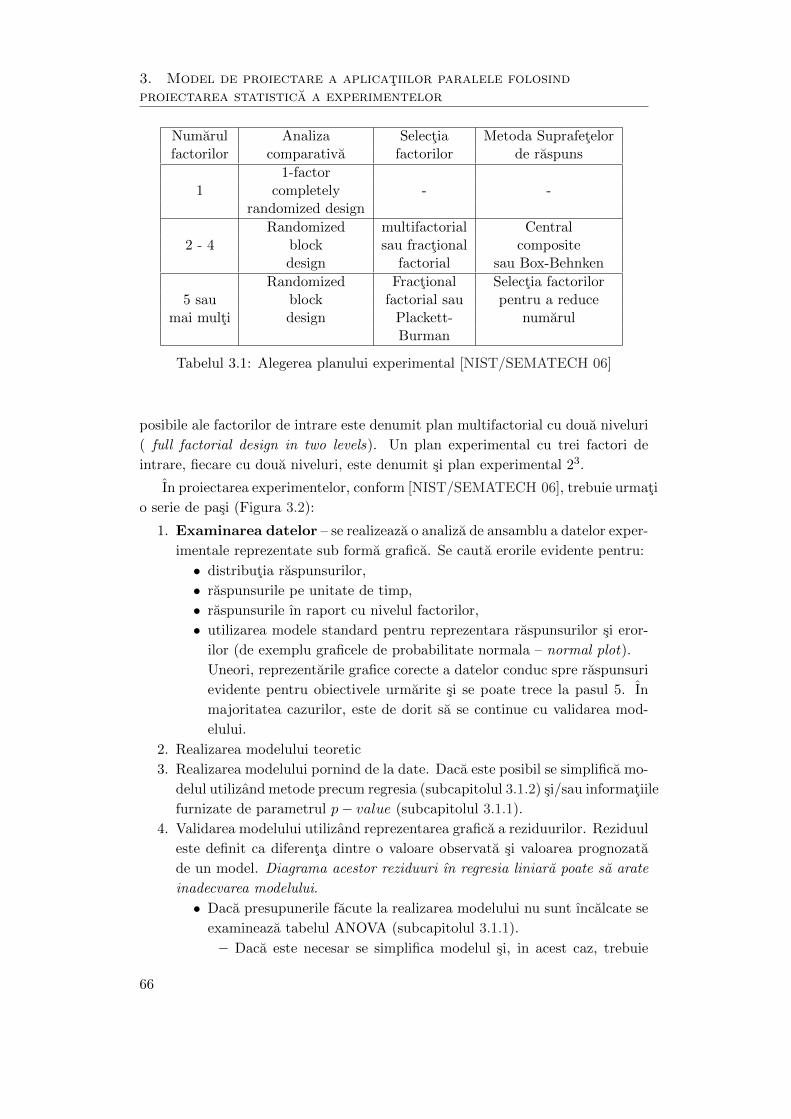
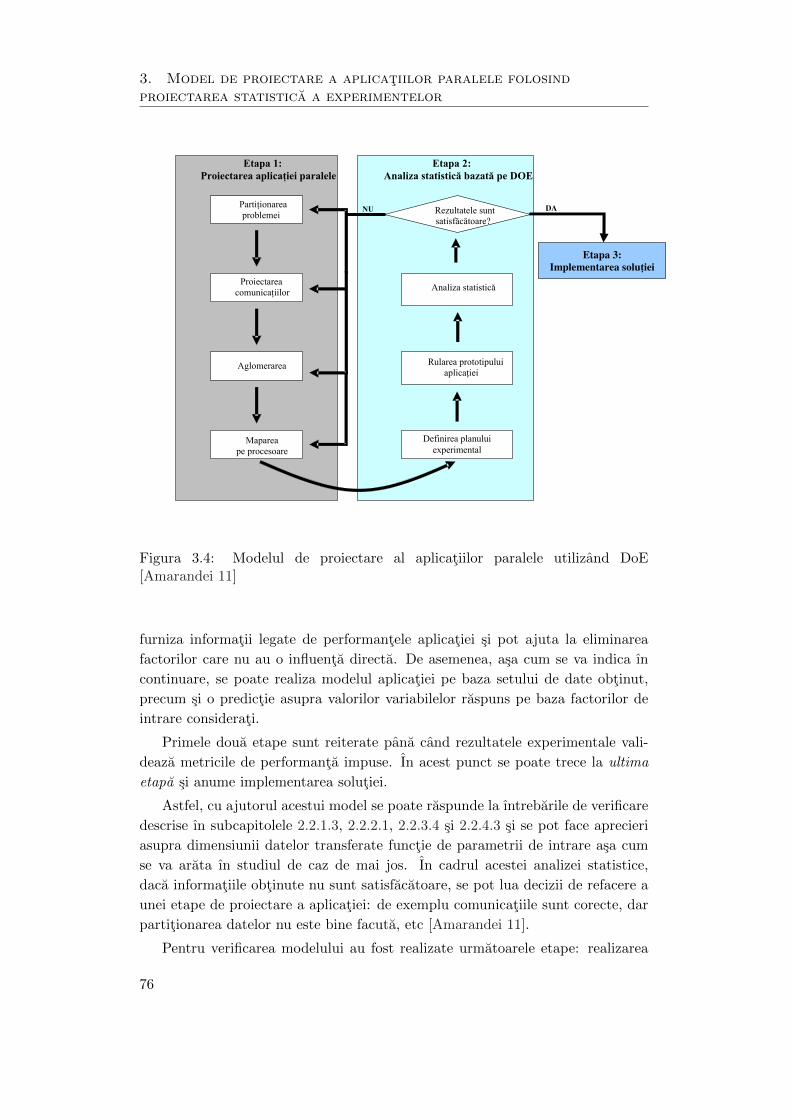
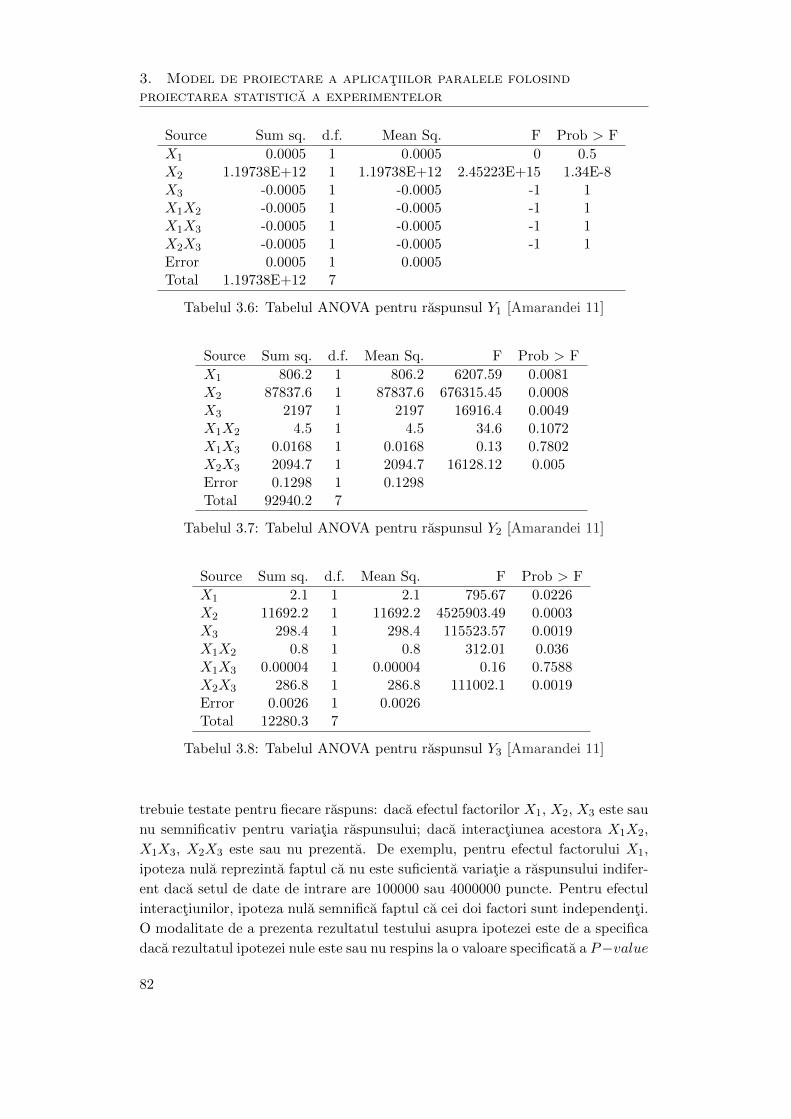
Universitatea Tehnică „Gheorghe Asachi” din Iaşi Facultatea de Automatică şi Calculatoare 2011 Contribuţii la proiectarea aplicaţiilor paralele pe clustere de calculatoare ing. Cristian Mihai Amarandei - TEZĂ DE DOCTORAT - Conducător ştiinţific: prof. dr. ing. Vasile-Ion Manta
Transcript
Universitatea Tehnică „Gheorghe Asachi” din Iaşi Facultatea de Automatică şi Calculatoare
2011
Contribuţii la proiectarea aplicaţiilor paralele pe clustere de calculatoare
ing. Cristian Mihai Amarandei
- TEZĂ DE DOCTORAT -
Conducător ştiinţific: prof. dr. ing. Vasile-Ion Manta
Teza de doctorat
Contributii la proiectarea
aplicatiilor paralele pe clustere de
calculatoare
ing. Cristian-Mihai AMARANDEI
Iasi, 2011
UNIVERSITATEA TEHNICA ,,GHEORGHE ASACHI” DIN IASI
Facultatea de Automatica si Calculatoare
Comisia pentru sustinerea tezei de doctorat:
1. Conf. dr. ing. Mihai Postolache Presedinte comisie
(Universitatea Tehnica ,,Gheorghe Asachi” din Iasi)
2. Prof. dr. ing. Vasile-Ion Manta Conducator stiintific
(Universitatea Tehnica ,,Gheorghe Asachi” din Iasi)
3. Prof. dr. ing. Stefan-Gheorghe Pentiuc Membru
(Universitatea ,,Stefan cel Mare” din Suceava)
4. Prof. dr. Gheorghe Grigoras Membru
(Universitatea ”A. I. Cuza” din Iasi)
5. Prof. dr. Mitica Craus Membru
(Universitatea Tehnica ,,Gheorghe Asachi” din Iasi)
Sotiei mele, Andreia
Mentiuni
Inainte de a va invita sa cititi aceasta lucrare, se cuvine sa multumesc celor ce
m-au sustinut ın obtinerea rezultatelor ce vor fi prezentate.
Doresc sa multumesc domnului profesor Vasile Manta pentru sfaturile dum-
nealui si pentru rabdarea de care a dat dovada ın coordonarea acestei lucrari.
As dori sa multumesc ın mod deosebit domnului profesor Mitica Craus. Dum-
nealui m-a sprijinit constant pe parcursul cercetarilor ın domeniul calculului pa-
ralel si cel al sistemelor Grid. Apreciez foarte mult ıncrederea dumnealui de a
ma include ın colectivele de cercetare ale contractelor coordonate. Multe dintre
rezultatele prezentate ın cadrul acestei lucrari au fost obtinute ın urma acestei
colaborari.
Doresc sa multumesc colegilor mei: Alex, Simona, Andrei, Adi, Daniel si
Marius. Le multumesc pentru sprijinul acordat si pentru mediul deosebit creat.
Nu ın ultimul rand, doresc sa multumesc familiei pentru sustinerea necondi-
tionata si pentru rabdarea de care a dat dovada pe parcursul studiilor doctorale.
Doresc, de asemenea, sa multumesc tuturor celor care m-au sprijinit si m-au
pele de aglomerare si mapare din proiectarea aplicatiilor, iar ın unele cazuri
sunt necesari algoritmi sofisticati pentru determinarea unei strategii de
aglomerare si mapare care creeaza task -uri de dimensiune aproximativ egala
si minimizeaza necesitatile comunicare prin crearea unui numar minim de
canale de comunicatii. Daca cerintele de comunicare sunt dinamice, acesti
algoritmi vor fi aplicati frecvent, iar costul rularii acestor algoritmi poate fi
prea mare ın comparatie cu beneficiile aduse [Grigoras 00].
• scheme de comunicatii statice sau dinamice: atunci cand identitatea par-
tenerului de comunicare nu se schimba pe durata executiei, schema de
comunicatii este statica; atunci cand identitatea partenerul de comunicare
este determinata dinamic, ın functie de datele calculate la un moment dat,
se obtin comunicatii dinamice (exemplu: quick sort pe hipercub) [Foster 95].
• metode de interactiune sincrone sau asincrone: atunci cand partenerii de
comunicatie se asteapta unul pe celalalt pentru a realiza operatia de comuni-
care, comunicatiile sunt sincrone; atunci cand partenerii de comunicatie pot
obtine datele fara cooperarea partenerului, se obtin comunicatii asincrone
(atunci cand se folosesc buffere). Alegerea formei de comunicare a datelor,
sincrona sau asincrona, este o problema dificila. Comunicatiile sincrone sunt
simple si usor de utilizat, pe cand cele asincrone pot duce la modificarea
ıntarzierilor cauzate de operatiile de comunicatii. De asemenea este posibil,
25
2. Metodologii de proiectare a aplicatiilor paralele
datorita specificului problemei, ca algoritmul ce rezolva o anumita problema
sa forteze alegerea unei anumite metode [Gergel 06].
In cazul comunicatiilor asincrone, task -urile care au nevoie de date le pot cere
explicit de la procesul care le detine, desi acesta din urma nu poate determina
momentul cererii ın discutie. Cea mai frecventa situatie este aceea ın care cal-
culele sunt structurate ca un set de task -uri care trebuie sa citeasca sau sa scrie
periodic elementele unei structuri de date partajate. Sa presupunem ca aceste
date sunt prea mari sau accesate frecvent pentru a putea fi ıncapsulate ıntr-un
singur task. In acest caz va fi necesar un mecanism care sa permita distribuirea
datelor, pastrand suportul de scriere si citire pentru operatiile asincrone asupra
acestor date. Un astfel de mecanism poate include urmatoarele:
• Structurile de date sa fie distribuite catre toate task -urile. Fiecare task
realizeaza calcule si genereaza cereri pentru datele detinute de alt task. De
asemenea, periodic, ısi va ıntrerupe activitatea si va rezolva cererile pentru
date.
• Structura de date distribuita este ıncapsulata ıntr-un alt set de task -uri
responsabile doar de citirea sau scrierea cererilor (Figura 2.3). Task -urile
care realizeaza calculele genereaza cereri de scriere/citire catre task -urile
care detin datele. Liniile continue reprezinta cererile iar cele ıntrerupte
raspunsul. Un task de calcule si unul de date pot fi atribuite unui singur
procesor (4 ın total) pentru a asigura o ıncarcare (cu date si calcule) egala
a procesoarelor [Foster 95].
• Pe sistemele care suporta modelul de programare bazat pe memorie comuna
(shared-memory), task -urile pot accesa datele partajate fara a se lua masuri
speciale. Totusi trebuie asigurat faptul ca operatiile de citire/scriere asupra
datelor au loc ıntr-o anumita ordine.
26
2.2. Modele de proiectare a aplicatiilor paralele
Calcule Calcule Calcule Calcule
citeste(k)kscrie(a) d citeste(d)
Date
l
k
j
Date
i
hg
Date
f
e
d
Date
c
b
Figura 2.3: Utilizarea task -urilor de date separat pentru a deservi cererile de
scriere/citire asupra unei structuri de date distribuite (adaptare dupa [Foster 95])
Fiecare strategie are avantajele si dezavantajele ei, performantele fiind diferite
de la un sistem de calcul la altul:
• comutarea de la un task la altul poate fi costisitoare ın unele cazuri;
• ın situatiile ın care datele nu sunt locale, sunt necesare comunicatii pentru
operatiile de citire/scriere;
• raspunsurile aferente cererilor ar trebui sa fie imediate, nu sa se astepte
tratarea lor dupa o anumita perioada de timp.
2.2.2.1 Reguli de proiectare/verificare a comunicatiilor
Pentru evaluarea rezultatelor obtinute ın aceasta etapa se recomanda parcurgerea
unui set de verificari [Quinn 04], dupa cum urmeaza:
• Toate task -urile realizeaza aproximativ acelasi numar de operatii de comuni-
care? Un dezechilibru al comunicatiilor sugereaza o constructie nescalabila.
In astfel de cazuri trebuie reproiectate comunicatiile pentru a fi distribuite
echitabil. De exemplu, daca structurile de date accesate frecvent sunt ıncap-
sulate ıntr-un singur task, ar trebui verificat daca se pot replica sau distribui
catre mai multe task -uri.
• Task -urile comunica numai cu un numar mic de procese vecine? Daca
fiecare task realizeaza comunicatii cu un numar mare de task -uri, trebuie
evaluata posibilitatea transformarii acestor comunicatii globale ın comunica-
tii locale.
27
2. Metodologii de proiectare a aplicatiilor paralele
• Comunicatiile pot fi realizate concurent? Daca nu, algoritmul nu este nici
eficient si nici scalabil. Trebuie abordate tehnici de tip divide-and-conquer
pentru a realiza concurenta.
• Este posibil ca diferite calcule asociate unor task -uri sa fie executate con-
curent? Daca nu, algoritmul fie nu este eficient, fie nu este scalabil. In acest
caz ar trebui revazute comunicatiile si calculele sau, ın anumite cazuri, chiar
specificatiile problemei.
Aceste verificari suplimentare au rolul de a detecta cazurile ın care implementarea
(desi realizata conform specificatiilor problemei) pentru un anumit tip de masina
paralela poate, fie sa introduca ıncarcari suplimentare, fie sa nu furnizeze para-
metrii de performanta doriti pentru aplicatia paralela.
2.2.3 Aglomerarea
Schemele de calcul paralel dezvoltate pentru rezolvarea problemelor trebuie sca-
late relativ la dimensiunile sistemelor tinta. In cazurile ın care numarul de ac-
tivitati de calcul este mult mai mare decat numarul de procesoare este necesara
scaderea numarului acestui tip de activitati. Acest lucru coincide cu recoman-
dararile de la finalul etapei de partitionare [Gergel 06]. Algoritmul rezultat dupa
parcurgerea primelor doua etape este abstract ın sensul ca nu este specializat
pentru executia eficienta pe un anumit sistem de calcul paralel. In realitate ex-
ista cazuri ın care sistemele de calcul paralel nu sunt destinate executiei eficiente
a task -urilor de mici dimensiuni. Etapa aglomerarii presupune trecerea de la
modelul abstract la cazul concret de implementare. Sunt reanalizate deciziile
legate de fazele de partitionare si comunicare pentru a obtine un algoritm care
se va executa eficient pe o anumita clasa de calculatoare paralele. In particu-
lar, poate fi utila combinarea sau aglomerarea task -urilor identificate ın etapa de
partitionare, astfel ıncat sa se obtina un numar redus de task -uri de dimensiune
corespunzatoare (Figura 2.4) [Quinn 04]:
• poate fi crescut volumul task -urilor prin reducerea numarului de dimensiuni
implicate ın descompunere ( Figura 2.4 a);
• task -urile adiacente pot fi grupate pentru a produce o descompunere de
granularitate mare ( Figura 2.4 b);
• ın cazul aplicatiilor de tip divide-and-conquer, unele structuri de tip sub-
arbore pot fi reunite pe baza criteriilor de omogenitate (Figura 2.4 c);
• o alta abordare posibila pentru situatiile similare cazului anterior poate fi
combinarea nodurilor omogene din arborele solutie (Figura 2.4 d).
In functie de specificul problemelor de rezolvat, replicarea datelor si/sau a cal-
culelor poate fi, de asemenea, luata ın considerare. Foster atrage atentia asupra
faptului ca desi numarul de task -uri create dupa faza de aglomerare este redus,
acesta poate fi mai mare decat numarul de procesoare [Foster 95].
28
2.2. Modele de proiectare a aplicatiilor paralele
a)
b)
c)
d)
Figura 2.4: Exemple de aglomerare (adaptare dupa [Foster 95])
In astfel de situatii este de dorit reducerea ın continuare a numarului de task -
uri, astfel ıncat sa se obtina o mapare de un singur task atribuit unui singur
procesor (daca, spre exemplu, calculatorul paralel tinta sau mediul de dezvoltare
impun un program de tip SPMD). Daca aceasta reducere este posibila se poate
afirma ca proiectarea aplicatiei este aproape completa deoarece a fost atinsa si
29
2. Metodologii de proiectare a aplicatiilor paralele
problema maparii.
Deciziile legate de aglomerare si replicare trebuie luate considerandu-se trei
obiective tinta [Foster 95]:
• reducerea costului comunicatiilor prin cresterea volumului de calcule si a
granularitatii comunicatiilor;
• pastrarea flexibilitatii pentru a nu influenta scalabilitatea si deciziile luate
ın faza de mapare;
• reducerea costurilor de proiectare a software-ului.
Pot fi ıntalnite cazuri in care atingerea unuia dintre obiective le defavorizeaza pe
celelalte.
2.2.3.1 Reducerea costului comunicatiilor
In faza de partitionare a procesului de proiectare, eforturile sunt concentrate pe
definirea unui numar de task -uri cat mai mare posibil. Acest lucru se poate dovedi
util deoarece forteaza considerarea unui numar crescut de posibilitati de executie.
De asemenea, definirea unui numar mare de task -uri cu granularitate fina nu im-
plica ın mod necesar faptul ca algoritmul paralel rezultat este eficient. Costul
comunicatiilor devine o problema critica si poate influenta decisiv performantele
aplicatiilor paralele: vehicularea mesajelor implica oprirea activitatilor de calcul.
Considerand etapele de calcul ca fiind prioritare, se poate creste performanta
aplicatiei paralele prin reducerea timpului pierdut cu efectuarea comunicatiilor.
Acest lucru poate fi obtinut prin doua metode: se ıncearca fie reducerea volu-
mului de date transmis, fie minimizarea numarului de comunicatii necesar pen-
tru transmiterea aceluiasi volum de date (aceasta ultima metoda se dovedeste
eficienta ıntrucat un numar redus de comunicatii implica si o scadere a timpi-
lor de initializare – communication startup cost). Aglomerarea este ıntotdeauna
benefica daca analiza necesarului de comunicatii indica faptul ca unele task -uri
nu se pot executa concurent [Foster 95].
2.2.3.2 Pastrarea flexibilitatii
Este foarte usor ca ın etapa de aglomerare sa fie luate decizii de proiectare care sa
limiteze scalabilitatea algoritmului. De exemplu, se poate alege descompunerea
unei structuri de date multidimensionale pe o singura dimensiune, daca acest
lucru furnizeaza un grad sporit de concurenta relativ la numarul de procesoare
disponibile. Aceasta strategie se poate dovedi a fi imprudenta si poate conduce
la implementari ineficiente daca, ın final, aplicatia va rula pe un sistem de calcul
paralel cu un numar mare de procesoare.
Capacitatea de a crea un numar variat de task -uri este critica ın cazurile ın
care programele dezvoltate vor trebui sa fie portabile si scalabile. In plus, al-
goritmii paraleli eficienti trebuie sa fie flexibili relativ la variatia numarului de
procesoare. Flexibilitatea poate fi utila si ın cazul ın care se urmareste ajustarea
30
2.2. Modele de proiectare a aplicatiilor paralele
codului pentru un anumit calculator paralel. Daca task -urile se blocheaza des
ın asteptarea unor date aflate la alte procese, poate fi avantajoasa maparea
mai multor task -uri pe un procesor. In acest caz blocarea unui task nu im-
plica faptul ca un procesor va fi ın stare idle (fara nimic de executat), deoarece
un task blocat este imediat ınlocuit de catre un alt task activ. In acest fel
comunicatiile unui task sunt suprapuse peste calculele altuia, tehnica fiind nu-
mita suprapunerea comunicatiilor si a calculelor (overlapping computation and
communication)[Foster 95].
Un alt avantaj al proiectarii aplicatiilor astfel ıncat numarul de task -uri decat
numarul de procesoare este acela al obtinerii unui grad crescut de libertate ın
faza maparii, cand se poate realiza o mai buna echilibrare a ıncarcarii. Ca si
regula generala, se poate cere ca numarul de task -uri sa fie cu cel putin un ordin
de marime mai mare decat numarul de procesoare. Numarul optim de task -uri se
poate determina printr-o combinatie de modele analitice si studii empirice. Flex-
ibilitatea nu este o cerinta expresa daca ın urma proiectarii se creeaza un numar
mare de task -uri. Granularitatea poate fi controlata prin parametri transmisi ın
fazele de compilare sau de rulare. Un aspect foarte important este ca ın faza de
proiectare sa nu se introduca limitari inutile ın privinta numarului de task -uri
care vor fi create [Gergel 06].
2.2.3.3 Reducerea costurilor de proiectare
Pana acum, s-a presupus ca strategia de aglomerare este determinata numai de
dorinta de a ımbunatati eficienta si flexibilitatea unui algoritm paralel. O preocu-
pare suplimentara, ce poate fi foarte importanta atunci cand se paralelizeaza un
cod secvential, este costul de dezvoltare asociat diferitelor strategii de partitionare.
Din aceasta perspectiva, cea mai interesanta strategie ar putea fi aceea ın care
se evita schimbarile masive ale codului pentru a putea reutiliza unele rutine deja
scrise. Frecvent, proiectarea unei aplicatii paralele se face avand grija ca algorit-
mul paralel rezultat sa poata fi executat ca o parte integranta a unui sistem mai
mare. In acest caz, apare o alta problema a proiectarii aplicatiilor paralele: dis-
tribuirea datelor utilizate de alte componente ale programului. De exemplu, cel
mai bun algoritm pentru un program poate cere ca o structura de date de intrare
sa fie descompusa ın trei dimensiuni, ın timp ce structura datelor rezultate dintr-o
faza anterioara sa fie bidimensionala. In acest caz, fie se schimba ambii algoritmi,
fie se restructureaza datele ıntr-o etapa intermediara. In functie de solutia aleasa,
se vor obtine ın final diferite caracteristici de performanta [Foster 95].
2.2.3.4 Reguli de aglomerare
Pentru evaluarea rezultatului proiectarii ın urma etapei de aglomerare, sunt utile
urmatoarele ıntrebari/verificari, care vor deveni din ce ın ce mai importante pe
masura ce se trece de la abstract la concret [Quinn 04]:
31
2. Metodologii de proiectare a aplicatiilor paralele
• Aglomerarea reduce costurile generate de comunicatii prin cresterea volu-
mului de task -uri locale? Daca nu, trebuie examinat algoritmul pentru a
determina daca acest lucru poate fi obtinut prin alte strategii de aglomerare.
• Daca aglomerarea a dus la replicarea calculelor, s-a verificat daca beneficiile
acestei replicari depasesc costurile, pentru un numar variat de dimensiuni
ale problemei si de procesoare?
• Daca aglomerarea duce la replicarea datelor, s-a verificat daca acest lucru
nu compromite scalabilitatea algoritmului prin restrictionarea la o anumita
dimensiune a problemei sau a numarului de procesoare pentru care poate
fi folosit?
• Aglomerarea produce task -uri ce au costuri de calcul si comunicatie simi-
lare? Cu cat este mai mare task -ul creat prin aglomerare, cu atat este mai
important sa avem costuri aproximativ egale. Daca a fost creat doar un
task pentru fiecare procesor, atunci aceste task -uri trebuie sa aiba costuri
aproape identice.
• Numarul de task -uri este scalabil ın raport cu dimensiunea problemei? Daca
nu, algoritmul nu este capabil sa rezolve probleme de mari dimensiuni pe
sisteme de calcul mai puternice si cu un numar mare de procesoare.
• Daca aglomerarea elimina oportunitatile de executie concurenta, s-a veri-
ficat daca exista suficiente calcule concurente pentru sistemul existent sau
pentru dezvoltari ulterioare? Un algoritm care nu ofera posibilitati de
executie concurenta poate fi totusi eficient, daca alti algoritmi au costuri
de comunicatie excesive si pot fi folosite modele de calcul a performantei
pentru cuantificarea acestor avantaje.
• Poate fi redus numarul de task -uri fara a introduce dezechilibre de ıncarcare
si fara a creste costurile de proiectare sau a reduce scalabilitatea? Daca da,
este posibil sa fie mai simplu de creat task -uri cu o granularitate mai mare
decat sa se genereze un numar mare de task -uri cu granularitatea mica?
• Daca este paralelizat un algoritm secvential, au fost considerate costurile
pentru modificarea necesara codului secvential? Daca aceste costuri sunt
prea ridicate, trebuie luate ın considerare strategii de aglomerare care cresc
posibilitatile de reutilizare a codului. Daca algoritmul rezultat este mai
putin eficient, trebuie utilizate tehnici de modelare care sa estimeze cos-
turile.
2.2.4 Maparea
Ultima etapa a procesului de proiectare a algoritmilor paraleli, maparea, are
rolul de a specifica unde va fi executat fiecare task. Problema maparii nu apare
pe un sistem multi-procesor sau pe sistemele cu memorie comuna care furnizeaza
tehnici de planificare a executiei task -ului. Pe aceste sisteme de calcul, cerintele
de comunicatii asociate task -urilor sunt ın mod uzual suficiente pentru definirea
32
2.2. Modele de proiectare a aplicatiilor paralele
specificatiilor unui algoritm paralel, si planificarea executiei task -urilor pe proce-
soare cade ın seama sistemului de operare sau a mecanismelor hardware. In cazul
sistemelor multiprocesor, daca numarul de task -uri coincide cu numarul de pro-
cesoare si daca topoplogia de comunicare este un graf complet (toate activitatile
sunt conectate direct ıntre ele) problema este mult simplificata [Gergel 06]. Totusi,
mecanisme generice de mapare automata sunt dificil de dezvoltat pentru sistemele
paralele scalabile. In general, maparea reprezinta o problema dificila care trebuie
abordata ın fazele de proiectare a unui algoritm paralel. Scopul principal ın dez-
voltarea algoritmilor de mapare este minimizarea timpului total de executie si
pentru aceasta pot fi utilizate doua strategii:
• se plaseaza task -urile ce se pot executa ın paralel pe procesoare diferite,
pentru a creste paralelismul;
• se plaseaza task -urile care comunica frecvent pe acelasi procesor, pentru a
mentine cat mai multe comunicatii locale.
Aceste doua strategii pot intra ın conflict si ın acest caz proiectantul sa re-
alizeze un un compromis ın alegerea unei solutii eficiente. In plus, limitarile
accesului la resursele de calcul poate restrictiona numarul de task -uri care pot
fi alocate unui singur procesor. Suplimentar, trebuie notata si cerinta de mini-
mizare a comunicatiilor dintre procesoare, cerinta ce poate contrazice conditia de
mapare uniforma.
Problema maparii este NP-completa, adica nu exista nici un algoritm de timp
polinomial care sa poata evalua costurile de calcul si de comunicatii pentru cazul
general. In timp, datorita cunostintelor acumulate ın privinta strategiilor eu-
ristice si a claselor de probleme pentru care acestea sunt eficiente, au aparut
solutii acceptabile pentru rezolvarea problemei maparii. De exemplu, ın cazul
problemelor care se rezolva utilizand o plasa (mesh) de procesoare, fiecare task
executa acelasi volum de calcule si comunicatii cu task -urile vecine (Figura 2.5).
Plasa si calculele asociate sunt distribuite ıntre procesoare astfel ıncat sa sa se
obtina acelasi volum de calcule si sa se minimizeze comunicatiile pentru fiecare
procesor ın parte.
Multi algoritmi paraleli au fost dezvoltati utilizand tehnica descompunerii
domeniului de date. In mod uzual, este generat un numar fix de task -uri de
dimensiuni egale si un numar fix de comunicatii globale si/sau locale, fapt ce
implica un proces de mapare simplu si eficient. Task -urile sunt mapate astfel
ıncat sa fie minimizate comunicatiile inter-procesor, fie prin aglomerarea mai
multor task-urilor pe un procesor, fie prin crearea unui numar de task -uri, cu
granularitate mare, egal cu numarul de procesoare din sistem.
In cazul algoritmilor mai complecsi de descompunere a domeniului, cu o canti-
tate de calcule variabila per task si/sau cu comunicatii nestructurate, aglomerarea
si strategia de mapare eficienta nu este evidenta, de cele mai multe ori, pentru
programator. Sunt astfel necesari algoritmi de echilibrare a ıncarcarii pentru a
33
2. Metodologii de proiectare a aplicatiilor paralele
Figura 2.5: Maparea ın problemele care se rezolva pe o plasa de procesoare(adaptare dupa [Foster 95])
gasi o solutie de aglomerare si o strategie de mapare eficienta, cautare ce se face,
de obicei, folosind tehnici euristice. Timpul necesar pentru rularea acestor al-
goritmi trebuie sa primeze beneficiilor aduse de reducerea timpului de executie
(altfel spus, determinarea solutiei de echilibrare si aplicarea acesteia trebuie sa
obtina o reducere cat mai semnificativa a timpului de executie pentru aplicatia
reechilibrata). Metodele probabilistice de echilibrare a ıncarcarii tind sa introduca
o ıncarcare suplimentara mai mica decat cele care exploateaza structura interna
a unei aplicatii. Cei mai complecsi algoritmi de echilibrare a ıncarcarii sunt aceia
ın care atat numarul de task -uri, cat si volumul de calcule si de comunicatii se
schimba dinamic ın timpul rularii programului.
In cazul problemelor care folosesc tehnica descompunerii domeniului se pot
utiliza strategii dinamice de echilibrare a ıncarcarii: algoritmul de echilibrare
este executat periodic pentru a se determina noi solutii de aglomerare si ma-
pare. Deoarece echilibrarea ıncarcarii trebuie facuta ın timpul rularii progra-
mului, sunt preferati algoritmii care nu cer informatii despre starea globala a
calculelor. Aceste strategii vor fi discutate pe larg ın sectiunea 2.5.2. Algoritmii
ce au la baza descompunerea functionala genereaza adeseori calcule prin crearea
de task -uri cu durata de viata redusa, task -uri ce se coordoneaza cu celelalte doar
la pornire si la oprire. Se pot folosi algoritmi de planificare ce aloca task -urile
catre procesoarele libere sau care sunt pe cale sa devina libere.
34
2.2. Modele de proiectare a aplicatiilor paralele
2.2.4.1 Algoritmi de echilibrare a ıncarcarii
Au fost propuse o varietate de tehnici de echilibrare a ıncarcarii specifice unui
tip de aplicatii pentru a fi utilizate ın dezvoltarea algoritmilor paraleli bazati
pe descompunerea domeniului: metoda bisectiei, algoritmi locali, metode proba-
bilistice sau mapari ciclice. Aceste tehnici au ca scop aglomerarea task -urilor cu
granularitate fina ıntr-o partitie initiala pentru a obtine un task cu granularitate
mare pe fiecare procesor. Alternativ, aceste tehnici pot fi privite ca o partitionare
a domeniului de calcule pentru a crea sub-domenii pentru fiecare procesor ın parte
si sunt referite ca algoritmi de partitionare [Foster 95].
Subcapitolul 2.5 trateaza ın detaliu problema echilibrarii ıncarcarii ın proiec-
tarea aplicatiilor paralele.
2.2.4.2 Algoritmi de planificare a task-urilor
Algoritmii de planificare a task -urilor pot fi utilizati atunci cand descompunerea
functionala genereaza foarte multe task -uri, fiecare cu cerinte de comunicatii lo-
cale reduse. Este mentinuta o multime de task -uri (task pool), centralizata sau
distribuita, ın care sunt introduse task -urile nou create si din care sunt preluate
cele ce vor fi alocate la procesoare. Efectiv, se rescrie algoritmul paralel astfel
ıncat ceea ce a fost conceput ca un task va deveni o structura de date ce reprezinta
”problemele”. Cele mai importante aspecte legate de algoritmii de planificare a
proceselor sunt strategiile utilizate pentru alocarea acestora catre procesoare.
In general, strategia aleasa reprezinta un compromis ıntre cerinte contradictorii:
realizarea independenta a calculelor (pentru a reduce costul comunicatiilor) si
obtinerea informatiilor despre starea generala a calculelor (pentru echilibrarea
ıncarcarii) [Foster 95].
2.2.4.3 Reguli de mapare
Etapa de mapare este ultima din faza de proiectare si specifica modul ın care
sunt repartizate (mapate) task -urile definite ın etapele anterioare pentru executia
pe procesoare. Deciziile de mapare ıncearca sa echilibreze contradictiile dintre
cerintele pentru echilibrarea ıncarcarii si costul comunicatiilor. Atunci cand este
posibil, schemele de mapare statica repartizeaza cate un singur task la fiecare pro-
cesor. In cazurile ın care numarul sau dimensiunea task -urilor sunt variabile sau
nu sunt cunoscute pana ın momentul rularii, sunt, ın mod uzual, abordate doua
strategii: fie sunt utilizati algoritmi dinamici de echilibrare a ıncarcarii, fie este re-
formulata problema astfel ıncat structurile de date pentru planificarea proceselor
sa poata fi folosite pentru planificarea calculelor. Pentru evaluarea rezultatelor
etapei de mapare sunt utile urmatoarele ıntrebari/verificari [Quinn 04]:
• Daca se ia ın considerare un model SPMD pentru probleme complexe, a fost
utilizat un algoritm bazat pe crearea si stergerea dinamica a task -urilor?
35
2. Metodologii de proiectare a aplicatiilor paralele
• Daca se ia ın considerare un model bazat pe crearea si stergerea dinamica
a task -urilor, a fost luat ın considerare un algoritm SPMD? Un astfel de
algoritm poate furniza un control mai bun asupra planificarii calculelor si
comunicatiilor, dar poate fi cu mult mai complex.
• Daca se foloseste o schema centralizata de echilibrare a ıncarcarii, s-a verifi-
cat daca procesorul manager nu devine o sursa de ıntarzieri (bottleneck)? Se
pot reduce ın continuare costurile comunicatiilor ın cadrul acestor scheme
prin transmiterea unor pointeri la task -uri (fata de cazul transmiterii task -
urilor ın sine)?
• Daca se foloseste o schema dinamica de echilibrare a ıncarcarii, au fost e-
valuate costurile altor strategii? Costurile de implementare ale acestora
trebuie, de asemenea, incluse ın analiza performantelor. Maparea prin
metode probabilistice sau ciclice este simpla si ar trebui luata ın considerare
ıntotdeauna pentru a ınlatura nevoia de repetare a operatiilor de echilibrare
a ıncarcarii.
• Daca se folosesc metodele probabilistice sau ciclice de mapare, exista un
numar suficient de task-uri pentru a asigura echilibrarea ıncarcarii proce-
soarelor? Sunt necesare de cel putin de zece ori mai multe task-uri decat
procesoare.
Desi sunt terminate toate fazele de proiectare ale algoritmului paralel, nu se
poate trece la scrierea codului. Mai trebuie efectuate analize privind performantele
pentru a putea alege ıntre algoritmi alternativi si pentru a determina daca sunt
ıntrunite criteriile de performanta. O alta problema o reprezinta costul de imple-
mentare si oportunitatile de reutilizare a codului existent. Mai trebuie evaluate,
de asemenea, si posibilitatile de integrare a algoritmului paralel ın contextul mai
larg al unui program complet [Foster 95].
2.3 Proiectarea modulara
O aplicatie paralela completa include mai multi algoritmi paraleli, fiecare operand
cu structuri de date, partitionari, comunicatii si strategii de mapare diferite.
Complexitatea care apare atunci cand sunt construite aplicatii mari poate fi con-
trolata prin tehnici de proiectare modulara. Ideea principala este de a ıncapsula
aspecte complexe sau variabile ın componente separate ale programului, sau mod-
ule, cu interfete bine definite care sa indice modul ın care interactioneaza cu
exteriorul. Proiectarea modulara creste fiabilitatea, reduce costurile prin dez-
voltarea mai usoara a programelor si reutilizarea componentelor. Ideea de baza
a proiectarii modulare este organizarea sistemelor complexe ca un set de compo-
nente distincte ce pot fi dezvoltate independent si apoi asamblate. Desi pare o
idee simpla, ın practica se dovedeste a fi destul de dificil de implementat si de-
pinde de modul ın care este ımpartit sistemul ın componente si de mecanismele
36
2.3. Proiectarea modulara
utilizate pentru conectarea lor. In continuare sunt prezentate cateva principii de
proiectare utile ın programarea paralela [Foster 95]:
• Furnizarea de interfete simple: Interfetele simple reduc numarul de interacti-
uni care trebuiesc luate ın considerare atunci cand se verifica daca sis-
temul are functionalitatea dorita, si le fac usor de utilizat ın circumstante
diferite. Reutilizarea codului este un factor major de reducere a costurilor
de dezvoltare atat prin eliminarea timpului consumat cu scrierea codului,
proiectarea si testarea aplicatiei, cat si prin amortizarea costului de dez-
voltare a mai multor proiecte.
• Ascunderea informatiilor despre functionarea interna: Modul ın care un
program este descompus are o influenta determinanta asupra modului de a
implementa sau de a modifica aplicatia ın discutie. In mod uzual, un modul
poate ıncapsula informatii care nu sunt necesare pentru restul programului.
Aceasta tehnica reduce costul de reproiectare a modulelor. De exemplu, un
modul poate ıncapsula:
– functii care au o implementare comuna sau care sunt utilizate ın mai
multe parti ale programului;
– functionalitati care este posibil sa nu se schimbe ın fazele de proiectare
sau de dezvoltare ale aplicatiilor;
– aspecte ale problemei care sunt mai complicate si/sau
– cod care poate fi refolosit ın alte programe.
Trebuie observat ca nu se precizeaza daca modulul trebuie sa contina functio-
nalitati care sunt logic ınrudite, deoarece acest tip de descompunere nu
faciliteaza ıntretinerea si nici nu promoveaza reutilizarea codului.
• Utilizarea unor instrumente potrivite de dezvoltare: Modulele proiectate pot
fi implementate ın aproape orice limbaj de programare, lucru cu atat mai
usor de realizat cu cat limbajul ofera suport mai bun pentru ıncapsularea
codului si a structurilor de date.
2.3.1 Reguli de proiectare modulara
Urmatoarele reguli, identificate de Foster ın [Foster 95], pot fi utilizate la proiec-
tarea modulelor unei aplicatii:
• Proiectarea modulelor trebuie realizata ın asa fel ıncat acestea sa fie capabile
sa lucreze cu mai multe tipuri de date, fapt ce le creste gradul de reutilizare;
• Trebuie ıncorporate informatiile legate de datele distribuite ın structuri de
date si nu ın interfetele modulului. Acest lucru duce la realizarea unor
interfete mai simple si maximizeaza oportunitatile de reutilizare a codului;
• Utilizarea descompunerii secventiale atunci cand sunt realizate aplicatii
pentru un sistem de programare SPMD, precum HPF (High Performance
Fortran) sau MPI;
37
2. Metodologii de proiectare a aplicatiilor paralele
• Considerarea compunerii secventiale atunci cand componentele unui pro-
gram nu se pot executa concurent sau au nevoie de o cantitate foarte mare
de date partajate;
• Considerarea compunerii concurente atunci cand componentele programu-
lui se pot executa concomitent, costul comunicatiilor este ridicat si se pot
suprapune etapele de comunicatie cu cele de calcul;
• Considerarea compunerii paralele daca memoria este un factor cheie sau cos-
tul comunicatiilor interne, din cadrul componentelor, este mai mare decat
cel dintre componentele ın sine.
Rezultatele proiectarii modulelor unei aplicatii paralele pot fi evaluate cu urma-
toarea lista de verificari/ıntrebari (o aplicatie bine proiectata ofera raspunsuri
afirmative) [Foster 95]:
• Modulele sunt identificate corect si clar ın faza de proiectare?
• Fiecare modul are un scop clar definit? Se poate formula acest scop ıntr-o
propozitie?
• Interfata fiecarui modul este suficient de abstracta pentru a nu fi necesara
studierea implementarii pentru a fi ınteleasa? Sunt ascunse detaliile de
implementare fata de celelalte module?
• Modulele sunt descompuse ıntr-un mod cat mai util posibil?
• Au fost verificate modulele astfel ıncat sa nu aiba functionalitati similare?
• Au fost izolate aspectele complexe ale problemei, cele specifice hardware-
ului sau cele cu o probabilitate redusa de modificare?
2.4 Analiza cantitativa si calitativa a algoritmilor paraleli
O aplicatie paralela este bine proiectata daca optimizeaza timpul de executie,
cerintele de memorie, costurile de implementare si de ıntretinere, etc. Aceste
ıncercari de optimizare implica, ın mod uzual, compromisuri ıntre simplitate,
performanta, portabilitate si alti factori. Deciziile referitoare la ce metoda de
rezolvare trebuie aleasa pentru o anumita problema trebuie luate considerand
diferitele costuri implicate de fiecare metoda ın parte. In acest context devine
utila dezvoltarea unor modele matematice pentru analiza performantelor. Aceste
modele pot fi folosite pentru a face o comparatie eficienta ıntre diversi algoritmi,
pentru evaluarea scalabilitatii si pentru identificarea diverselor deficiente (un ex-
emplu de acest fel este ”gatuirea” executiei – bottlenecks) ınainte de investi un
efort substantial ın implementare. Modelele de performanta pot ajuta eforturile
de implementare pentru a indica eventualele optimizari posibile [Foster 95].
38
2.4. Analiza cantitativa si calitativa a algoritmilor paraleli
2.4.1 Parametrii cantitativi
2.4.1.1 Accelerarea
Accelerarea, notata cu Sp, reprezinta raportul ıntre timpul de executie al celui
mai bun program secvential (t1) si timpul de executie al programului paralel
echivalent (tp) pe un sistem paralel cu p procesoare:
Sp =t1tp
(2.4.1)
Daca, fie nu se cunoaste timpul de executie al celui mai bun algoritm secvential,
fie varianta paralela difera foarte mult de cea secventiala, comparatia nu-si mai
are rostul. Din acest motiv se accepta mai multe variante de definitie pentru cei
doi timpi si vom avea cinci alternative la definitia accelerarii [Sahni 4]:
• relativa, atunci cand t1 este timpul de executie al variantei paralele pe un
singur procesor al sistemului paralel; depinde de problema de rezolvat si de
numarul de procesoare;
• reala, atunci cand se compara timpul de executie paralel cu timpul de
executie pentru varianta secventiala cea mai rapida, pe un procesor al sis-
temului paralel. Este posibil ca cel mai rapid algoritm ce rezolva problema
sa nu fie cunoscut, sau un singur algoritm nu este cel mai rapid pentru toate
dimensiunile posibile ale problemei, motiv pentru care se alege ca referinta
varianta secventiala cea mai rapida;
• absoluta, atunci cand se compara timpul de executie al algoritmului paralel
cu timpul de executie al celui mai rapid algoritm secvential, executat pe
procesorul serial cel mai rapid;
• asimptotica, atunci cand se compara timpul de executie al celui mai bun
algoritm secvential cu functia de complexitate asimptotica a algoritmului
paralel, ın ipoteza existentei numarului necesar de procesoare;
• relativ asimptotica, atunci cand se foloseste complexitatea asimptotica a
algoritmului paralel executat pe un procesor.
Daca p este numarul de procesoare ale sistemului paralel, atunci, ıntr-un caz
ideal, are loc urmatoarea relatie:
tp =t1p. (2.4.2)
Utilizand 2.4.2, conform ecuatiei 2.4.1, se obtine Sp = p. Intrucat apelurile
functiilor sistem determina o diminuare a accelerarii, ın cazurile reale se obtine:
1 ≤ Sp ≤ p (2.4.3)
In [Sun 91], Sun si Gustafson considera ca accelerarea este o unitate de masura
imprecisa, ce favorizeaza procesoarele lente si codul de calitate slaba. Autorii
creeaza o unitate de masura derivata, numita sizeup, definita ca fiind raportul
39
2. Metodologii de proiectare a aplicatiilor paralele
dintre dimensiunea problemei rezolvate de un calculator paralel si dimensiunea
problemei rezolvate de un sistem secvential ıntr-un anumit interval de timp. Fie,
spre exemplu, cazul a doua calculatoare paralele, M1 si M2, pentru care costul
fiecarei operatii este acelasi. Se considera ca M1 executa operatiile paralelizabile
mai rapid decat M2. Sun si Gustafson demonstreaza ca M1 obtine o accelerare
mai slaba (chiar daca sunt ignorate comunicatiile), dar conform sizeup M1 ar
trebui considerat ca fiind mai bun.
O alta unitate de masura a scalabilitatii introdusa de Sun si Rover ın [Sun 94],
numita izoviteza, reprezinta factorul cu care dimensiunea problemei poate fi
crescuta astfel ıncat viteza medie de calcul sa ramana constanta daca este crescut
si numarul de procesoare de la p la p′. Unitatea medie de viteza a calculatorului
paralel este definita ca fiind viteza de procesare obtinuta pentru un anumit volum
de date (W ) divizata cu numarul de procesoare din sistem. Atfel, daca numarul
de procesoare este crescut de la p la p′ se va obtine:
izoviteza(p, p′) =p′W
pW ′. (2.4.4)
Utilizand ecuatia 2.4.4, dimensiunea W ′ a problemei pentru p′ procesoare este
determinata astfel: considerand cazul ideal al unui algoritm perfect paralelizabil,
fara comunicatii, se poate arata usor ca izoviteza trebuie sa aiba valoarea 1; se
va obtine:
izoviteza(p, p′) = 12.4.4=⇒ W ′ =
p′W
p
Pentru un sistem paralel real, relatiile anterioare se modifica astfel [Kumar 91]:
izoviteza(p, p′) < 1
W ′ >p′W
p
2.4.1.2 Eficienta
Eficienta masoara modul ın care sunt utilizate procesoarele din sistem:
Ep =Spp. (2.4.5)
Acest parametru exprima penalitatea platita pentru nivelul de performanta atins.
In cazul ideal acest parametru are valoare 1, dar ın cazurile reale 0 < Ep < 1.
Daca se mareste numarul de procesoare al sistemului, eficienta poate fi mentinu-
ta la aceeasi valoare prin cresterea volumului de calcule, ca o consecinta a volu-
mului mai mare de date de prelucrat [Grigoras 00]. Timpul de executie paralela se
mai poate exprima si ın functie de gestiunea proceselor paralele (creare/distrugere,
planificare, sincronizare), comunicatiile dintre ele, echilibrarea ıncarcarii si re-
alizarea de calcule suplimentare. Aceste operatii consuma un timp numit timp
40
2.4. Analiza cantitativa si calitativa a algoritmilor paraleli
de overhead, care se aduna la timpul executiei paralele si depinde de volumul de
calcule si de numarul de procesoare [Kwiatkowski 02]:
toverhead(W,p) = tp −W
p. (2.4.6)
Din relatia 2.4.6 rezulta ca:
tp =W
p+ toverhead(W,p) , (2.4.7)
ceea ce implica, conform [Grama 03], modificarea relatiei 2.4.5 astfel:
Ep =Spp
=
WWp+toverhead(W,p)
p=
W
W + p · toverhead(W,p)=
1
1 + p · toverhead(W,p)W
(2.4.8)
Considerand relatiile anterioare, volumul de calcule W , conform [Grama 03],
devine:
W =Ep
1− Epp · toverhead(W,p) = K · p · toverhead(W,p) (2.4.9)
Acest ultim rezultat este cunoscut ın literatura de specialitate sub numele de
functie de izoeficienta [Grama 03]:
W = K · p · toverhead(W,p) . (2.4.10)
Relatia 2.4.10 indica modul ın care trebuie sa se modifice volumul de calcule
W , astfel ıncat sa se mentina aceeasi eficienta, atunci cand creste numarul de
procesoare din sistem.
2.4.1.3 Supraıncarcarea
Daca eficienta este privita ca o functie dependenta de dimensiunea problemei
(n) si de numarul de procesoare (p), notata E(n, p), atunci supraıncarcarea se
poate defini ca [Petcu 01]:
f(n, p) =1
E(n, p)− 1 (2.4.11)
Supraıncarcarea (overhead) include costurile implicate de startarea unui pro-
ces, de comunicare a datelor, de diversele sincronizari si eventuale calcule su-
plimentare. In general supraıncarcarea poate fi [Petcu 01]:
• software: calcule aditionale descompunerii datelor si atribuirii acestora
catre procesoare;
41
2. Metodologii de proiectare a aplicatiilor paralele
• datorata dezechilibrului ıncarcarii : fiecare proces ar trebui sa primeasca
acelasi volum de calcule;
• datorata comunicatiilor : ın cazurile ın care este imposibila suprapunerea
comunicatiilor si a calculelor, accesarea datelor aflate la distanta poate
introduce timpi suplimentari considerabili sau ın cazul ın care volumul de
calcule dintre comunicatii succesive este redus (granularitate redusa).
2.4.1.4 Costul
Costul unui program paralel (Cp) se defineste ca fiind produsul dintre timpul de
calcul (tp) si numarul de procesoare (p). Daca se presupune ca toate procesoarele
executa acelasi numar de instructiuni, atunci:
Cp = p · tp (2.4.12)
Deoarece o aplicatie paralela poate fi simulata pe un sistem secvential, caz ın care
procesorul executa de p ori instructiunile executate de un procesor al sistemului
paralel, atunci aplicatia paralela este optima din punct de vedere al costului daca
valoarea acestuia este egala cu timpul de executie al celei mai bune variante
secventiale.
2.4.1.5 Legile accelerarii
Legea lui Amdahl
”Accelerarea este marginita superior de o valoare independenta de numarul de
procesoare si de arhitectura masinii.”
Se considera urmatoarele notatii [Shi 96]:
• tsec: timpul de procesare pentru partea secventiala a unui program (uti-
lizand 1 procesor);
• tpar: timpul de procesare pentru partea paralela a unui program (utilizand
1 procesor);
Shi, pentru a demonstra legea lui Amdahl, considera ca timpul de executie
al programului paralel (tp) poate fi considerat ca o suma ıntre o componenta
ce corespunde secventelor de instructiuni din program care nu pot fi paraleliza-
te (partea secventiala a programului) si o componenta paralela executata de p
procesoare (tparp ) [Shi 96]:
tp = tsec +tparp
. (2.4.13)
In acelasi context timpul de executie a unui program paralel pe un singur procesor
(t1) se poate defini ca fiind [Shi 96]:
t1 = tsec + tpar . (2.4.14)
42
2.4. Analiza cantitativa si calitativa a algoritmilor paraleli
Conform relatiei 2.4.1 se obtine
Sp =tsec + tpar
tsec +tparp
≤ t1tsec
, (2.4.15)
ceea ce ınseamna ca oricare ar fi p (numarul de procesoare), accelerarea este
inferioara inversului proportiei de cod serial din totalul codului[Grigoras 00].
Legea lui Amdahl modeleaza foarte bine comportarea programelor cu para-
lelism de cod, dar nu si a celor cu paralelism de date. Lee considera ca odata
cu variatia parametrului i - numar de procesoare, cu valori ın domeniul [1, p], se
modifica si proportia din program, qi, care poate fi paralelizata (executata de i
procesoare) [Lee 80]. In acest context relatiile anterioare ce descriu timpul de
executie paralel (2.4.13), secvential (2.4.14) si accelerarea (2.4.15), se modifica
astfel [Lee 80]:
t1 =
p∑i=1
qiti , (2.4.16)
tp =
p∑i=1
qiiti , (2.4.17)
Sp =1
p∑i=1
qii
. (2.4.18)
Daca qi = 1/p,∀i ∈ [1, p], se obtine [Lee 80]:
Sp ≤p
log2 p. (2.4.19)
Acest rezultat arata faptul ca accelerarea nu mai depinde de natura aplicatiei ci
de numarul de procesoare din sistem [Lee 80].
Legea Gustafson-Barsis
Gustafson si Barsis, ın [Gustafson 88], pleca de la ipoteza ca timpul total
de executie pe un singur procesor este constant: s + p, unde s este timpul de
executie al codului secvential si p timpul de executie al codului paralel pe un
singur procesor. Pentru simplitatea caluclelor se considera ca s+p = 1. In aceste
conditii accelerarea devine [Wilkinson 99]:
S =s+ p
s+ p/n=
1
s+ (1− s)/n(2.4.20)
Plecand de la acest rezultat, Gustafson si Barsis au introdus un nou factor nu-
mit factor de scalare a accelerarii SS(n). Considerand ca timpul de executie
pe un calculator paralel este format dintr-o componenta secvetiala si o compo-
nenta paralela, s+ p, ca timpul de executie pe un singur calculator va fi s+ pn,
43
2. Metodologii de proiectare a aplicatiilor paralele
unde n reprezinta numarul de parti ce trebuie executate secvential, si din nou ca
s+ p = 1, acest factor se calculeaza astfel [Wilkinson 99]:
S =s+ np
s+ p= s+ np = n+ (1− n)/s (2.4.21)
Aceasta relatie, cunoscuta sub numele de legea Gustafson-Barsis, arata ca ac-
celerarea trebuie masurata prin scalarea dimensiunii problemei odata cu numarul
procesoarelor si nu prin pastrarea unei dimensiuni fixe.
Arhitecturile microprocesoarelor integreaza tot mai multe unitati de procesare
pe acelasi cip, pentru a depasi constrangerile arhitecturilor cu un singur nucleu si
consumul de energie din ce ın ce mai mare al acestora. Aceasta abordare ofera o
alternativa la regula lui Pollack care afirma urmatoarele: cresterea performantei
microprocesoarelor este aproximativ proportionala cu radacina patrata a cresterii
ın complexitate a procesorului [Pollack 99]. Conform acestei reguli, pentru o
crestere cu 40% a performantelor unui sistem cu un singur nucleu, trebuie dublat
numarul de porti logice. In acest context, sistemele cu mai multe nuclee ofera o
alternativa eficienta din punct de vedere al costului, furnizand mai multa putere
de calcul prin procesarea paralela, consumand mai putina energie si ocupand mai
putin spatiu [Sun 10].
Pentru aplicarea legii lui Amdahl la sistemele cu mai multe nuclee trebuie
elaborat un model de cost care sa ia ın considerare numarul si performantele
nucleelor suportate de procesor [Hill 08]. ın primul rand, autorii presupun ca
procesoarele multicore pot contine n BCE (Base Core Equivalents), unde BCE
reprezinta un singur nucleu. In al doilea rand, se mai presupune caproiectantul
procesorului poate utiliza resursele a mai multe BCE pentru a un nucleu cu
performante secventiale mai bune. Daca performanta unui BCE este 1, se pre-
spune ca se pot folosi resursele a r BCE pentru a crea un procesor mai puternic
cu performanta secventiala perf(r) ( 1<perf(r)<2) Plecan de la acest model
de cost, Hill si Marty identifica trei tipuri de procesoare multicore pentru care
trebuie reformulata legea lui Amdahl: simetrice, asimetrice si dinamice.
• Procesoare multicore simetrice: se presupune ca fiecare nucleu are acelasi
cost. In [Hill 08], autorii noteaza cu:
– f – portiunea de cod paralelizabila,
– n – numarul total de BCE,
– r – resursele implicate ın cresterea performantei unui singur nucleu si,
– perf(r) – perfomanta cu care aceste procesoare folosec un singur nu-
cleu pentru executia codului secvential,
– perf(r)× n/r – performanta cu care aceste procesoare executa codul
paralel.
44
2.4. Analiza cantitativa si calitativa a algoritmilor paraleli
,In aceste conditii accelerarea este o expresie de forma [Yao 09] :
Speedupsimetric(f, n, r) =1
1−fperf(r) + f ·r
perf(r)·n, (2.4.22)
• Procesoare multicore asimetrice: presupun ca unele nuclee sunt mai puter-
nice decat altele. Astfel, formula 2.4.22 devine [Yao 09]:
Speedupasimetric(f, n, r) =1
1−fperf(r) + f
perf(r)+n−r. (2.4.23)
• Procesoare multicore dinamice: presupun combinarea a r nuclee pentru
a creste performantele componentei secventiale. In acest caz accelerarea
devine [Yao 09]:
Speedupdinamic(f, n, r) =1
1−fperf(r) + f
n
. (2.4.24)
In contrast cu Hill si Marty, ce considerau incert viitorul procesoarelor multi-
core, Sun si Chen demonstreaza ca aceste arhitecturi sunt fundamental scalabile
si nu sunt afectate de legea lui Amdahl [Sun 10] .
2.4.2 Parametrii calitativi
2.4.2.1 Granularitatea
Granularitatea (grain size) indica volumul de calcule alocate procesoarelor ın val-
ori minime acceptabile.
Granularitatea aplicatiei - reprezinta dimensiunea minima a unei unitati sec-
ventiale dintr-un program, exprimata ın numar minim de instructiuni, ın care
nu se executa operatii de sincronizare sau de comunicare cu alte procese (G =
Tcalcule/Tcomunic) [Kwiatkowski 02] Deoarece un proces este compus din unitati
secventiale de granularitati diferite, atunci granularitatea unui proces este gran-
ularitatea unitatii secventiale celei mai mici [Grigoras 00].
Granularitatea sistemului - valoarea minima a granularitatii sub care performanta
unui sistem paralel dat scade semnificativ si este justificata de timpul de overhead
(comunicatii, sincronizari) care poate fi comparabil cu timpul de calcul paralel.
Granularitatea sistemului paralel este definita ca raportul dintre timpul consumat
pentru o operatie fundamentala de comunicatie si timpul consumat de o operatie
fundamentala de calcul.
Granularitatea este folosita ın [Kwiatkowski 02] pentru a calcula eficienta si
implicit accelerarea plecand de la formula urmatoare:
E =G
G+ 1(2.4.25)
Este de dorit ca un calculator paralel sa aiba o granularitate mica, astfel ıncat
sa poata executa eficient o gama larga de programe, iar aplicatiile sa aiba o
granularitate cat mai mare.
45
2. Metodologii de proiectare a aplicatiilor paralele
2.4.2.2 Scalabilitatea
Scalabilitatea reprezinta posibilitatea de a asigura cresterea accelerarii odata cu
cresterea numarului de procesoare pornind de la ipoteza ca programul executat
are o granularitate suficient de mare. Daca se obtine o crestere liniara a ac-
celerarii, avem un sistem scalabil liniar. La nivelul aplicatiei este necesar sa fie
asigurata flexibilitatea si adaptabilitatea la dinamica arhitecturii.
Factorii ce influenteaza scalabilitatea unei aplicatii sunt legati de echipa-
mentele hardware si/sau de bibliotecile si aplicatiile folosite: dimensiunea mem-
oriei, dezechilibrele arhitecturale, performantele sistemului de I/O, accesul con-
curent la resurse, comunicatii sau echilibrarea ıncarcarii. Scalabilitatea mai este
echivalenta cu asigurarea izoeficientei si poate fi mentinuta pana la atingerea
unui numar de procesoare egal cu un Pmax. Valoarea numarului maxim de proce-
soare poate fi marita prin cresterea granularitatii. Optimizarea performantelor si
ımbunatatirea calitatii unui sistem multiprocesor se bazeaza pe exploatarea par-
alelismului la nivelul proceselor care alcatuiesc aplicatiile si ınsusi a sistemului de
programe de baza.
In [Zirbas 89], este dezvoltat un framework care modeleaza scalabilitatea unui
sistem paralel. Un algoritm paralel format dintr-o componenta secventiala Wserial
si o componenta paralela Wparalel, atunci cand este rulat pe un singur procesor
are un timp de rulare de forma: tc(Wserial + Wparalel), unde tc este o constanta
pozitiva. Timpul de executie ideal pe un sistem cu p procesoare este de forma
[Zirbas 89]:
tc(Wserial +Wparalel
p) (2.4.26)
In practica, datorita overheadului introdus de paralelism, valoarea timpului de
executie este mai mare. Din acest motiv se introduce o functie de overhead
Φ(p). Un sistem cu p procesoare este scalabil daca timpul de executie TP pe p
procesoare satisface relatia [Zirbas 89]:
TP ≤ tc(Wserial +Wparalel
p)× Φ(p) (2.4.27)
Cea mai mica valoare a functiei Φ(p) ce satisface ecuatia 2.4.27 este denumita
functia de overhead a sistemului si este definita de relatia: TPtc(Wserial+Wparalel/p)
.
Un sistem paralel este considerat scalabil daca functia de overhead ramane con-
stanta atunci cand dimensiunea problemei se modifica suficient de rapid.
Pentru orice sistem paralel, daca dimensiunea problemei creste mai repede
ca functia de izoeficienta, atunci functia de overhead Φ(p) reprezinta o con-
stanta ce face sistemul ideal scalabil [Kumar 91]. Astfel, conform definitiilor din
[Zirbas 89], toate sistemele paralele pentru care exista functia de izoeficienta sunt
scalabile. Daca Φ(p) creste ca o functie de p, atunci rata de crestere a functiei
de overhead determina gradul ın care un sistem nu este scalabil. Cu cat este mai
rapida cresterea, cu atat sistemul este mai putin scalabil.
46
2.5. Problema echilibrarii ıncarcarii ın proiectarea aplicatiilor paralele
Astfel, functia de supraıncarcare (overhead), complementara functiei de izo-
eficienta, face distinctie ıntre sistemele care sunt scalabile si cele nescalabile fara
a furniza ınsa nici o informatie cu privire la gradul de scalabilitate a unui sistem.
Pe de alta parte, functia de izoeficienta nu furnizeaza nici o informatie ın legatura
cu gradul de scalabilitate a unui sistem de calcul. O limitare a acestui rezultat
este faptul ca functia de overhead Φ(p) surprinde numai overheadul introdus de
comunicatii si nu pe cel introdus de codul secvential. Daca un algoritm par-
alel este slab scalabil datorita dimensiunilor mari ale componentelor secventiale,
Φ(p) poate avea valori mici datorita faptului ca supraıncarcarea introdusa de
comunicatii este redusa. De exemplu, daca Wserial = WS si Wparalel = 0, atunci:
Φ(p) = TPtc(Wserial+Wparalel/p)
= 1tc
= Φ(1), adica sistemul este perfect scalabil
[Kumar 91].
2.5 Problema echilibrarii ıncarcarii ın proiectarea aplicatiilor
paralele
2.5.1 Echilibrarea ıncarcarii ın aplicatiile paralele
Un rol important ın proiectarea aplicatiilor paralele cu efect imediat asupra
performan-telor ıl are echilibrarea ıncarcarii. Scopul echilibrarii ıncarcarii poate
fi formulat ın felul urmator: avand o colectie de task -uri care realizeaza un calcul
si un set de computere pe care aceste task -uri pot rula, sa se gaseasca o mapare de
task -uri la computere astfel ıncat fiecare computer sa aiba o cantitate aproxima-
tiv egala de sarcini. O mapare care echilibreaza ıncarcarea procesoarelor va mari
eficienta pe ansamblu a calculului. Marirea eficientei pe ansamblu va reduce tim-
pul de executie al calculului, care este de fapt un scop al calculului paralel. Dar
uneori o tratare simplista a echilibrarii ıncarcarii nu conduce ın mod necesar la un
calcul mai rapid. Daca aplicatia este statica (adica timpul asociat unui anumit
task poate fi determinat apriori), problema echilibrarii ıncarcarii se reduce la ma-
parea grafului aplicatiei pe reteaua de procesoare. Daca aplicatia este dinamica
(adica ıncarcarea unui procesor poate varia ın decursul unui calcul si nu poate fi
estimata ınainte), exista un numar de strategii (SID, DASUD, difuzie) care pot
fi folosite pentru a varia ıncarcarea unui procesor. Majoritatea strategiilor de
echilibrare a ıncarcarii au cel putin unul din urmatoarele neajunsuri:
• Nu se poate face o estimare dinamica a ıncarcarii. Majoritatea tehnicilor
dezvoltate pana ın prezent se bazeaza pe cunoasterea globala a volumului
de lucru.
• Eficienta lor nu poate fi analizata teoretic. Desi intuitiv, multe tehnici pot
avea un potential destul de mare, implementate practic pot genera multe
dezechilibre ın distributia sarcinilor.
47
2. Metodologii de proiectare a aplicatiilor paralele
• Sunt specifice aplicatiilor. Multe dintre aceste tehnici au fost proiectate si
implementate numai pentru anumite aplicatii
• Aplicabilitatea lor a fost studiata la o scara redusa. O parte din aceste
tehnici au fost studiate pe masini cu un numar mic de procesare sau pe
task -uri generice.
• Sunt prea complicatii pentru implementari optimale. Modalitatea relativ
complexa ın care sunt prezentati acesti algoritmi ın lucrarile de specialitate
duce la aparitia erorilor ın implementarea acestora.
• Ingreuneaza foarte mult comunicatiile ıntre procese si nu se reuseste esti-
marea costului acestor comunicatii.
• Sunt sincroni. Multe dintre aceste tehnici sunt concepute astfel ıncat toate
unitatile de procesare sa execute ın acelasi timp faza de echilibrare a ıncarca-
rii.
O solutie practica pentru problema echilibrarii ıncarcarii dinamice implica cinci
faze distincte:
• Evaluarea ıncarcarii: o estimare a ıncarcarii procesorului trebuie realizata
pentru a determina daca exista un eventual dezechilibru.
• Determinarea profitabilitatii: odata ce ıncarcarea procesoarelor a fost e-
valuata, prezenta dezechilibrului poate fi detectat? Daca costul dezechili-
brului depaseste costul echilibrarii ıncarcarii, atunci echilibrarea ıncarcarii
poate fi initiata.
• Calcularea vectorului de transfer al ıncarcarii: pe baza masuratorilor facute
ın prima faza, se calculeaza vectorul de transfer al ıncarcarii pentru a echili-
bra procesoarele.
• Selectia task -urilor: Task -urile sunt selectate pentru transfer ın acord cu
vectorul de transfer calculat ın faza anterioara.
• Migrarea task -urilor: Odata selectat, task -urile sunt transferate de la un
computer la altul.
2.5.2 Echilibrarea dinamica a ıncarcarii
In cazul echilibrarii dinamice a ıncarcarii, task -urile sunt alocate procesoarelor
ın timpul executiei programului. Echilibrarea poate fi centralizata sau descen-
tralizata. In primul caz, task -urile sunt remise dintr-o locatie centrala. Exista
o structura clara master-slave, ın care procesul master controleaza direct fiecare
proces slave. In al doilea caz, task -urile sunt pasate ıntre procese arbitrare. O
colectie de procese de lucru opereaza asupra problemei si interactioneaza, ra-
portand ın final unui singur proces. Un proces poate primi task -uri de la alte
procese si poate trimite la randul sau task -uri altor procese.
48
2.5. Problema echilibrarii ıncarcarii ın proiectarea aplicatiilor paralele
2.5.2.1 Echilibrarea centralizata
In echilibrarea centralizata, procesul master poseda colectia de task -uri care
urmeaza a fi executate. Task -urile sunt trimise proceselor slave. Cand un proces
slave termina un task, el cere un altul de la procesul master. Acest mecanism
este trasatura esentiala a abordarii denumite work-pool. Aceasta tehnica poate
fi usor aplicata problemelor simple de tip divide-and-conquer. Poate fi de aseme-
nea aplicata problemelor ın care task -urile sunt sensibil diferite si cu dimensiuni
inegale. In general, este bine sa fie trimise mai ıntai task -urile cele mai mari si
mai complexe. Daca un task mai mare este trimis mai tarziu, task -urile mai mici
pot fi terminate de catre procesele slave, care vor sta apoi inactive ın asteptarea
terminarii task -ului mai mare. Tehnica mai poate fi aplicata cand numarul de
task
task
Cerere task
Trimitere task
task
task
Procese
slavetask
Task-uri
Proces
Master
Figura 2.6: Work-pool centralizat (adaptare dupa [Wilkinson 99])
task -uri se modifica ın timpul executiei. In unele aplicatii, mai ales algoritmi
de cautare, executia unui task poate genera noi task -uri, desi ın final numarul
task -urilor trebuie sa se reduca la 0, semnalizand terminarea procesului de calcul.
Pentru memorarea task -urilor ın asteptare poate fi folosita o coada, Figura 2.6.
Daca toate task -urile sunt de dimensiune si importanta egale, poate fi acceptata
o coada simpla FIFO. Daca unele task -uri sunt mai importante decat altele (de
exemplu, pot conduce mai repede catre o solutie), acestea vor fi pasate primelor
procese slave. Procesul master poate detine si alte informatii, cum ar fi solutia
optima curenta [Wilkinson 99].
Oprirea procesului de calcul ın momentul gasirii solutiei se numeste terminare.
Un avantaj specific echilibrarii centralizate este existenta unui singur master, care
49
2. Metodologii de proiectare a aplicatiilor paralele
recunoaste foarte usor momentul terminarii. Atunci cand task -urile sunt preluate
dintr-o coada, procesul de calcul se termina cand coada este vida sau atunci
cand fiecare proces a facut o cerere pentru un nou task fara sa mai primeasca
vreunul. In unele aplicatii, un proces slave poate detecta conditia de terminare a
programului prin unele conditii locale (de exemplu, gasirea unui element cautat).
In acest caz, el va trimite un mesaj de terminare catre master, care va opri toate
celelalte procese slave. In alte aplicatii, fiecare proces slave trebuie sa atinga
o conditie locala de terminare specifica, precum convergenta unei solutii locale.
In acest caz, master -ul trebuie sa primeasca mesaje de terminare de la toate
procesele slave [Wilkinson 99].
2.5.2.2 Echilibrarea descentralizata
Desi utilizata pe scara larga, echilibrarea centralizata are un dezavantaj semni-
ficativ: procesul master poate trimite un singur task la un anumit moment, iar
dupa ce task -urile initiale au fost trimise, el poate raspunde la o singura cerere
de noi task -uri la un moment dat. De aici rezulta potentialul unui blocaj, atunci
cand exista multe procese slave care pot face simultan cereri. Echilibrarea cen-
tralizata este satisfacatoare daca exista putine procese slave si task -urile sunt
intensiv computationale. Pentru task -uri cu granularitate mai fina si procese
slave mai numeroase, este mai potrivita distribuirea volumului de lucru ın mai
multe locatii (Figura 2.7). Procesul master divizeaza volumul de lucru initial ın
task
task
task
task
task
Task-
uri
Proces M0
Proce
se
slav
e
task
task
task
task
task
Task-
uri
Proce
se
slav
e
Proces Mn-1
task Task-
uri iniţia
le
Proces Master
Trimitere task
Cerere task
Figura 2.7: Work-pool distribuit (adaptare dupa [Wilkinson 99])
mai multe paarti si trimite fiecare parte unei multimi de procese ”mini-master”
50
2.5. Problema echilibrarii ıncarcarii ın proiectarea aplicatiilor paralele
(M0 . . .Mn−1). Fiecare mini-master controleaza un grup de procese slave. Pen-
tru o problema de optimizare, procesele mini-master pot gasi un optim local pe
care sa-l trimita ınapoi la master si acesta va selecta cea mai buna solutie. Este
clar ca aceasta abordare poate fi dezvoltata astfel ıncat sa cuprinda mai multe
nivele de descompunere; poate fi format un arbore cu procesele slave ın calitate
de frunze iar nodurile interne sa divida volumul de lucru. Acesta este metoda
de baza pentru descompunerea unui task ın sub-task -uri egale. La fiecare nivel
din arbore, procesul paseaza jumatate din task -uri unui sub-arbore si cealalta
jumatate celuilalt sub-arbore, daca avem ın vedere un arbore binar.
O alta abordare distribuita ar fi ca procesele slave sa detina o portiune a
volumului de lucru si sa rezolve problema pentru aceasta [Wilkinson 99]. Odata ce
sarcinile sunt distribuite proceselor, exista posibilitatea ca acestea sa interschimbe
task -uri (Figura 2.8). Task -urile pot fi transferate prin:
proces
proces
proces
proces
proces
Cereri taskuri
Figura 2.8: Work-pool descentralizat (adaptare dupa [Wilkinson 99])
• metoda initializarii de catre receptor (receiver-initiated): un proces solicita
task -uri de la alte procese pe care le selecteaza. In general, un proces solicita
task -uri de la alte procese atunci cand are putine sarcini de ındeplinit (sau
nici una). S-a demonstrat ca metoda functioneaza bine la ıncarcari mari
ale sistemului.
• metoda initializarii de catre transmitator (sender-initiated): un proces
trimite task -uri altor procese pe care le selecteaza. Un proces cu o ıncarcare
mare paseaza unele task -uri altor procese care sunt dispuse sa le accepte.
S-a demonstrat ca aceasta metoda este potrivita sistemelor cu ıncarcari reduse.
51
2. Metodologii de proiectare a aplicatiilor paralele
O alta optiune este combinarea celor doua metode. Din pacate, determinarea
ıncarcarilor proceselor poate fi costisitoare. In sisteme cu ıncarcari foarte mari,
echilibrarea ıncarcarii poate fi de asemenea dificila datorita lipsei proceselor
disponibile. Echilibrarea ıncarcarii ın contextul metodei initializarii de catre re-
ceptor poate fi adaptata si pentru metoda initializarii de catre transmitator. Sunt
posibile mai multe strategii. Procesele pot fi organizate ca un inel, ın care task -
urile sunt cerute de la vecinii cei mai apropiati. O organizare de tip inel va fi
potrivita pentru un sistem multiprocesor care foloseste o retea de interconectare
inelara. In mod similar, ıntr-un hipercub, procesele pot solicita task -uri de la
vecinii cu care au legaturi, cate unul pentru fiecare dimensiune. Desigur, in-
diferent de strategie, trebuie sa ne asiguram ca un task primit nu este trimis
mai departe [Wilkinson 99]. Fara constrangerile (si avantajele) unui anumit tip
de retea, toate procesele sunt candidati egali, care pot selecta orice alt proces.
Pentru operatiile distribuite, fiecare proces trebuie sa aiba propriul algoritm de
selectie ca ın Figura 2.9 Cand este implementat local, acest algoritm poate fi
Listă taskuri
Alg
oritm
de
se
lecţie
loca
lă
Alg
oritm
de s
ele
cţie
locală
Listă taskuri
cereri
cereri
Proces Pi
Proces Pj
Figura 2.9: Algoritm de selectie descentralizat (adaptare dupa [Wilkinson 99])
aplicat tuturor proceselor care lucreaza la problema sau la diferite submultimi
ale sale. Unul din algoritmii pentru selectarea unui proces este roundrobin, ın
care procesul Pi solicita task -uri procesului Px, unde x este dat de un contor,
incrementat dupa fiecare cerere, modulo numarul de procese. De exemplu, daca
exista n = 8 procese, x ia valorile 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7 etc. Proce-
sul nu se auto-selecteaza, deci contorul va fi incrementat ınca o data cand este
ındeplinita conditia x = i. In algoritmul votarii aleatorii (random polling), proce-
52
2.5. Problema echilibrarii ıncarcarii ın proiectarea aplicatiilor paralele
sul Pi solicita task -uri de la procesul Px, unde x este un numar selectat aleatoriu
din intervalul 0−n−1, excluzand i. Cand un proces primeste o cerere de task -uri,
trimite un fragment din task -urile pe care le mai are de ındeplinit catre procesul
solicitant. De exemplu, sa presupunem ca avem de rezolvat problema traversarii
ın adancime a unui arbore de cautare. Nodurile vor fi vizitate ıntr-o maniera
descendenta, ıncepand cu radacina. Va fi mentinuta o lista cu nodurile neviz-
itate, iar procesul va selecta din lista o multime potrivita de noduri nevizitate,
pe care o va trimite procesului solicitant. Pot fi folosite diverse strategii pentru
a determina cate noduri si care vor fi returnate [Wilkinson 99].
2.5.3 Echilibrarea dinamica a ıncarcarii ın sistemele de agenti mobili
si sisteme message passing
Vom considera o clasa de calculatoare paralele echipate cu o multime finita de
procesoare omogene interconectate printr-o retea de interconectare directa. Pro-
cesoarele comunica prin transmiterea de mesaje. Canalele de comunicatie se
considera full-duplex, astfel ıncat o pereche de procesoare conectate direct pot
primi si trimite simultan mesaje unul altuia. In continuare este prezentat studiul
asupra algoritmilor SID (Sender Initiated Diffusion) si DASUD (Diffusion Al-
gorithm Searching Unbalanced Domains) de echilibrare dinamica a ıincarcarii
implementati pe o platforma de agenti mobili PASIBC (Platforma Agent pen-
tru dezvoltarea Sistemelor Informatice Bazate pe Cunostinte) [Sova 06] si pe un
mediu message passing (MPI) [Sova si Amarandei 04].
Algoritmul SID, propus ın [Willebeek-LeMair 93], porneste de la premisa ca
task -urile sunt infinit divizibile si ıncarcarea unui procesor este reprezentata de
un numar real. Presupunerea este valida ın programele paralele care folosesc
paralelismul ın task -urile cu granularitate mica. Pentru taskurile cu granular-
itate medie sau mare algoritmul trebuie sa poata lucra cu taskuri indivizibile.
Algoritmul DASUD descris de [Cortes 98] se bazeaza pe algoritmul SID, care a
fost ımbunatatit pentru a ıncorpora caracteristici noi, care detecteaza daca un
domeniu (toti vecinii imediati ai unui procesor) este echilibrat sau nu. Daca
domeniul nu este echilibrat, excesul de ıncarcare este distribuit vecinilor dupa
diferite criterii, depinzand de distributia ıncarcarii lor.
In mediile distribuite traditionale programele sunt proiectate astfel ıncat sa
accepte cat mai multi clienti posibili. Procesele client ruleaza de obicei pe cal-
culatoare aflate la distanta si comunica cu procesele server pentru a-si putea
ındeplini sarcinile. Aceasta abordare poate genera un nivel ridicat de trafic ın
retea si, ın functie de aceasta, pot sa apara ıntarzieri semnificative. Tehnologia
agenttilor mobili, prin procesul de migrare a codului executabil, aduce clientul
mai aproape de sursa si astfel se obtine o reducere majora a traficului necesar.
Totusi, ınlocuirea sistemelor client-server cu agentii mobili nu este ıntotdeauna o
idee foarte buna. De exemplu, agentii mobili trebuie sa transporte cu ei datele,
53
2. Metodologii de proiectare a aplicatiilor paralele
ın timp ce sistemele client-server trimit datele imediat ınapoi catre client. Astfel,
ın cazul sistemelelor client-server, se poate reduce traficul ın retea. Platforma de
agenti mobili descrisa ın [Sova 06] pe care au fost implementati si testati algo-
ritmii de echilibrare a ıncarcarii este PASIBC implementata folosind tehnologii
.NET. Platformele de agenti mobili au fost interconectate pentru a forma topolo-
gia de tip hipercub, dar sistemul poate fi utilizat ssi ın cazul altor topologii cum
ar fi, de exemplu, topologii inel, stea, mesh sau combinatii ale acestora.
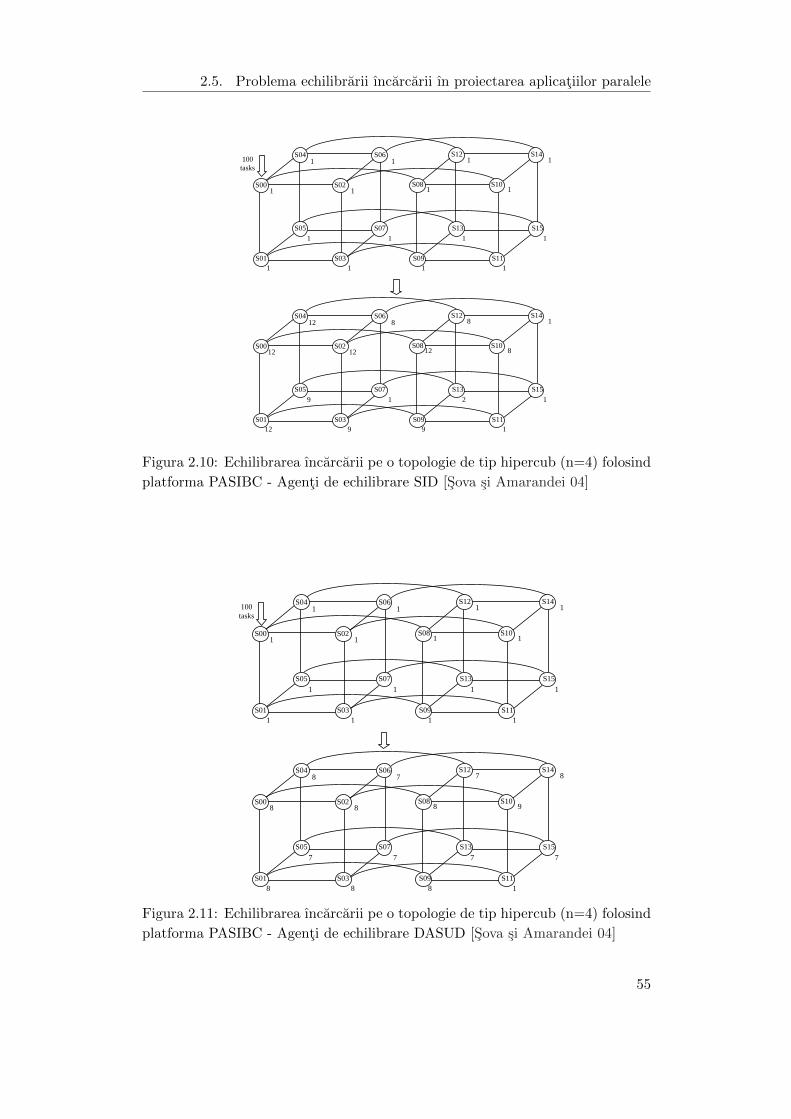
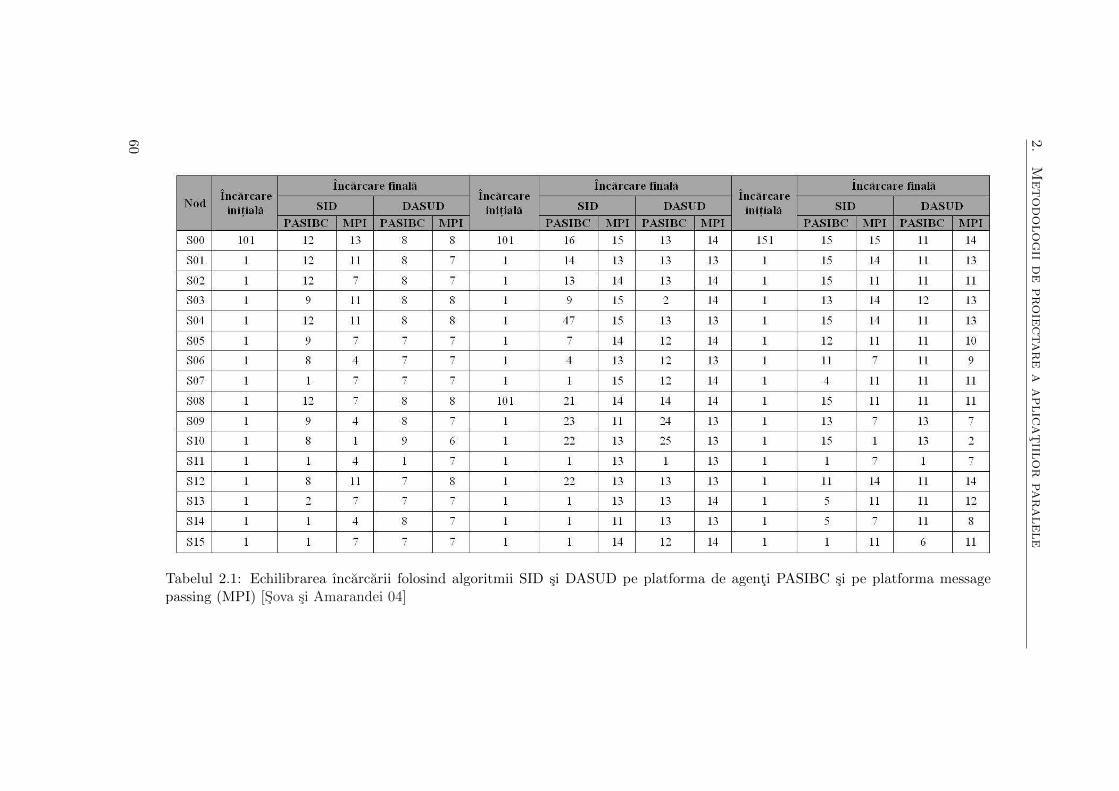
In cadrul simularii pe topologia de tip hipercub cu 4 dimensiuni au fost injec-
tate 100 de unitati de ıncarcare ın nodul S00. O unitate de ıncarcare este de fapt
un agent mobil ce poate migra ıntre diferite platforme, iar injectarea unitatilor
de ıncarcare consta ın crearea agentilor task. Injectarea task -urilor poate fi fa-
cuta ın orice moment, ın orice nod al sistemului si ın oricate noduri. Pentru
topologia hipercub am ales nodul S00, deoarece alegerea oricarui alt nod nu ar fi
influentat complexitatea situatiei. Migrarea unui astfel de agent este initiata de
catre platforma agent pe care rezida acesta. Fiecare platforma PASIBC dispune
de un agent de echilibrare a ıncarcarii astfel ıncat, la nivelul nodului S00, avem
101 agenti ce trebuie distribuiti ın cadrul sistemului ca ın figurile 2.10 si 2.11.
Suplimentar am ales cazul, defavorabil, ın care este supraıncarcat nodul S00 cu
100 si respectiv 150 task -uri.
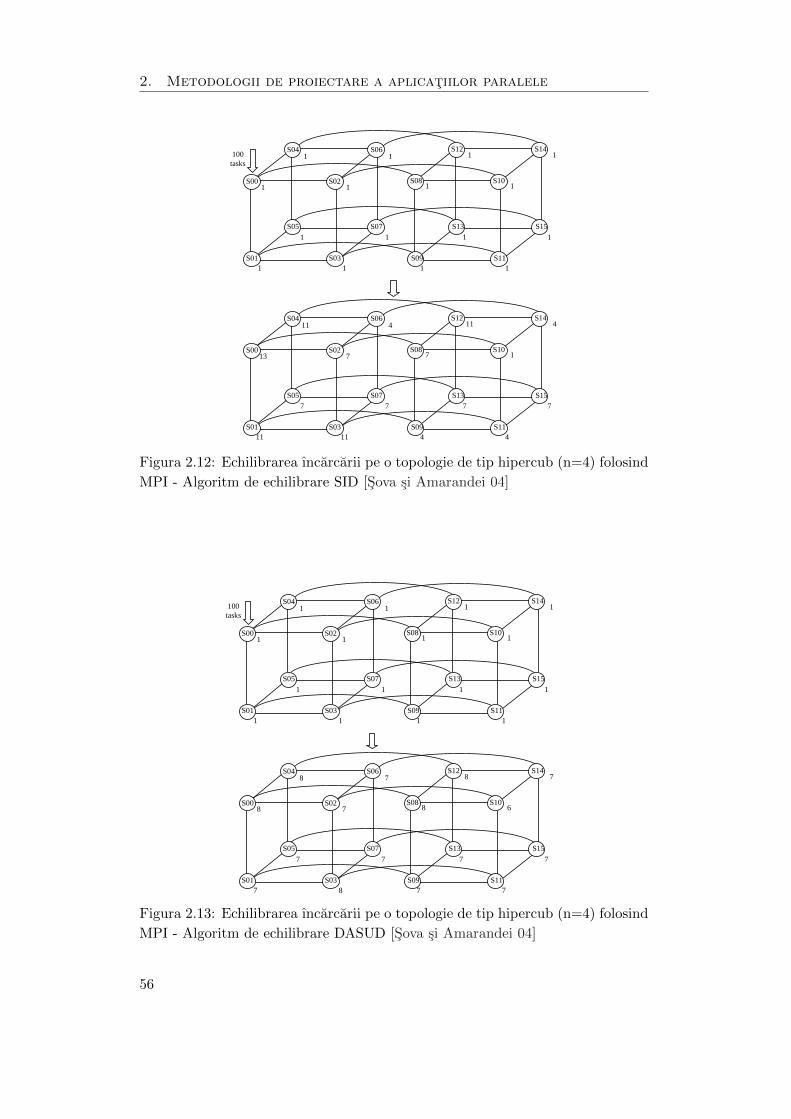
Pentru testarea implementarii algoritmilor de echilibrare a ıncarcarii SID si
DASUD folosind MPI s-a folosit acelasi set de date initiale (ıncarcarea initiala)
ca cel de la platforma PASIBC, rezultatele fiind prezentate ın figurile 2.12 si 2.13.
54
2.5. Problema echilibrarii ıncarcarii ın proiectarea aplicatiilor paralele
1 1
1 1
1 1
1 1
S01
S05 S07
S03
S00
S04 S06
S02
S09
S13 S15
S11
S08
S12 S14
S10
1 1
1 1
1 1
1 1 100 tasks
12 9
9 1
12 12
12 8
S01
S05 S07
S03
S00
S04 S06
S02
S09
S13 S15
S11
S08
S12 S14
S10
9 1
2 1
12 8
8 1
Figura 2.10: Echilibrarea ıncarcarii pe o topologie de tip hipercub (n=4) folosind
platforma PASIBC - Agenti de echilibrare SID [Sova si Amarandei 04]
1 1
1 1
1 1
1 1
S01
S05 S07
S03
S00
S04 S06
S02
S09
S13 S15
S11
S08
S12 S14
S10
1 1
1 1
1 1
1 1 100 tasks
8 8
7 7
8 8
8 7
S01
S05 S07
S03
S00
S04 S06
S02
S09
S13 S15
S11
S08
S12 S14
S10
8 1
7 7
8 9
7 8
Figura 2.11: Echilibrarea ıncarcarii pe o topologie de tip hipercub (n=4) folosind
platforma PASIBC - Agenti de echilibrare DASUD [Sova si Amarandei 04]
55
2. Metodologii de proiectare a aplicatiilor paralele
1 1
1 1
1 1
1 1
S01
S05 S07
S03
S00
S04 S06
S02
S09
S13 S15
S11
S08
S12 S14
S10
1 1
1 1
1 1
1 1 100 tasks
11 11
7 7
13 7
11 4
S01
S05 S07
S03
S00
S04 S06
S02
S09
S13 S15
S11
S08
S12 S14
S10
4 4
7 7
7 1
11 4
Figura 2.12: Echilibrarea ıncarcarii pe o topologie de tip hipercub (n=4) folosind
MPI - Algoritm de echilibrare SID [Sova si Amarandei 04]
1 1
1 1
1 1
1 1
S01
S05 S07
S03
S00
S04 S06
S02
S09
S13 S15
S11
S08
S12 S14
S10
1 1
1 1
1 1
1 1 100 tasks
7 8
7 7
8 7
8 7
S01
S05 S07
S03
S00
S04 S06
S02
S09
S13 S15
S11
S08
S12 S14
S10
7 7
7 7
8 6
8 7
Figura 2.13: Echilibrarea ıncarcarii pe o topologie de tip hipercub (n=4) folosind
MPI - Algoritm de echilibrare DASUD [Sova si Amarandei 04]
56
2.5. Problema echilibrarii ıncarcarii ın proiectarea aplicatiilor paralele
2.5.4 Rezultate
Din rezultatele obtinute ın cazul echilibrarii ıncarcarii pe platforma de agenti mo-
bili si pe sistemul de tip message-passing se observa ca ın cazul algoritmului SID
se obtine doar o echilibrare locala iar sistemul pe ansamblu este dezechilibrat. O
ımbunatatire substantiala se observa ın cazul utilizarii algoritmului DASUD - o
echilibrare locala si globala. Totusi, ın ambele cazuri apar probleme (dezechili-
bre) din cauza configuratiei hardware si software pe care au fost facute testele -
incompatibilitati cu software-ul instalat. Testele efectuate cu platforma PASIBC
a fost rulate pe o retea alcatuita din statii cu WindowsXP, iar testele folosind
MPI au fost rulate pe un cluster Linux. Implementarea algoritmilor fiind aprox-
imativ aceeasi, diferenta apare datorita modului ın care sunt implementate cele
2 sisteme de test. Mai exact, varianta de MPI ce ruleaza pe Linux beneficiaza
de modul de lucru cu procese al acestui sistem de operare; ın timp ce platforma
PASIBC fiind implementata folosind platforma .NET, nu a fost posibila folosirea
acelorasi mecanisme de comunicatii [Sova si Amarandei 04].
Pe de alta parte, utilizarea platformelor de agenti mobili ofera urmatoarele
avantaje [Teodoru si Amarandei 07]:
• reducerea traficului pe retea – numai codul agentului si datele finale sunt
mutate de pe un nod pe altul, nu si datele intermediare.
• adaptabilitate – agentii mobili au abilitatea de a-si schimba comportamen-
tul functie de mediul ın care ruleaza.
• robustete si toleranta la defecte – platformele de agenti mobili sunt mult
mai robute decat alte modele de sisteme distribuite. Daca o platforma se
defecteaza, alta poate prelua agentii cu task-urile aferente.
• arhitectura distribuita si flexibila – sistemele de agenti mobili sunt foarte
flexibile datorita posibilitatii de migrare a codului.
Performantele sistemelor distribuite ce utilizeaza agenti mobili pot fi crescute prin
utilizarea algoritmilor de echilibrare a ıncarcarii, datorita faptului ca agentii pot
utiliza mai bine puterea de procesare a sistemului [Teodoru si Amarandei 07].
57
2. Metodologii de proiectare a aplicatiilor paralele
Figura 2.14: Rezultatele algoritmilor SID si DASUD cu primul set de date
[Sova si Amarandei 04]
Figura 2.15: Rezultatele algoritmilor SID si DASUD cu al doilea set de date
[Sova si Amarandei 04]
58
2.5. Problema echilibrarii ıncarcarii ın proiectarea aplicatiilor paralele
Figura 2.16: Rezultatele algoritmilor SID si DASUD cu al treilea set de date
[Sova si Amarandei 04]
59
2.
Metodolog
iide
proie
ctare
aaplic
atiil
or
paralele
Tabelul 2.1: Echilibrarea ıncarcarii folosind algoritmii SID si DASUD pe platforma de agenti PASIBC si pe platforma messagepassing (MPI) [Sova si Amarandei 04]
60
Capitolul 3
Model de proiectare a aplicatiilor
paralele folosind proiectarea
statistica a experimentelor
Rezumat
Performantele aplicatiilor paralele sunt influentate de numerosi factori
dependenti de mediul de rulare, precum performanta retelei, ıncarcarea pro-
cesoarelor, memoria disponibila etc. Datele produse de o aplicatie parale-
la pot fi analizate folosind tehnici de investigatie, cum ar fi, de exemplu,
proiectarea statistica a experimentelor (DOE – Design of experiments) pen-
tru investigarea erorilor de proiectare. Pentru utilizarea acestei tehnici este
dezvoltat un model de proiectare al aplicatiilor paralele, model care per-
mite descrierea comportamentului acelei aplicatii ın functie de factorii care
o influenteaza.
Suportul disponibil pentru rularea aplicatiilor paralele (sistemele multicore,
hyperthreading, GPU etc.) precum si arhitecturile ın care sunt integrate (sis-
teme paralele, distribuite etc.) sunt din ce ın ce mai complexe. Acest lucru
face deosebit de dificila construirea de modele analitice care sa permita studiul
performantelor unei aplicatii sau predictia acestora. Prin urmare se ridica prob-
lema validarii aplicatiilor paralele propuse ca solutii pentru rezolvarea prob-
lemelor din diverse domenii. Precum ın cazul altor domenii stiintifice, raspunsul ıl
constitue validarea prin experimente. Cu toate acestea, experimentele ın dome-
niul stiintei calculatoarelor este un subiect ce ridica mai multe probleme deca
rezolva: Ce poate valida un experiment? Ce reprezinta un ”experiment bine
realizat”? Cum se poate construi un mediu experimental ce permite realizarea
unui ”experiment bun”? Cum se poate realiza acest lucru ın cazul calculului de
61
3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
mare performanta? [Gustedt 09]. Realizarea unei aplicatii paralele presupune si
analiza parametrilor cantitativi si calitativi ce o descriu: timpi de raspuns, scala-
bilitate etc. Acest lucru se transpune ın realizarea unor teste de performanta pe
baza carora se pot trage concluzii privind modul ın care a fost proiectata si imple-
mentata aplicatia ın cauza. Proiectarea aplicatiilor paralele conform [Foster 95] si
[Quinn 04] presupune patru etape: partitionarea datelor, definirea comunicatiilor,
aglomerarea si maparea. Chiar daca acest model (vezi Figura 2.2) este urmarit cu
atentie ın faza de proiectare, aplicatia rezultata nu functioneaza la parametrii de
performanta asteptati. Acest lucru este posibil nu numai datorita unor verificari
superficiale ale cerintelor suplimentare propuse de Foster, cat datorita conditiilor
ın care ruleaza aplicatia. Pentru a depasi aceste neajunsuri este definit un model
analitic de investigare a performantei, model bazat pe metoda de proiectare de-
scrisa ın capitolul anterior.
Abordarile eficiente din punct de vedere al costurilor se obtin rareori avand
baze exclusiv teoretice. Acest lucru se datoreaza nevoii de flexibilitate si de
usurinta ın mentenanta software-ului pe de o parte si datorita complexitatii sis-
temelor de calcul paralel, pe de alta parte. Datorita numarului mare de strategii
de proiectare si a posibililor factori ce le influenteaza, studiile experimentale tre-
buie realizate tinand cont de urmatoarele [Amarandei 11]:
• factorii ce influenteaza anumite metrici de performanta;
• existenta interactiunilor dintre acesti factori;
• cuantificarea efectului fiecarui factor si a interatiunilor dintre acestia;
• valorile pentru care factorii furnizeaza raspunsul optim;
• limitarile impuse de conditiile de rulare asupra aplicatiei.
Un factor important, care adesea nu este luat ın considerare, este faptul ca
pe un anumit cluster nu ruleaza, ın mod uzual, o singura aplicatie paralela.
Astfel, ın functie de datele transferate ıntre noduri la un moment dat, gradul
de ocupare al retelei interne a clusterului este diferit. De asemenea, utilizarea
clusterului poate fi rezervata pentru mai multe scopuri (de exemplu academice, de
cercetare sau comerciale). O aplicatie proiectata fara a tine cont de acesti factori
poate avea variatii drastice de performanta. In timpul proiectarii nu se poate
cunoaste cu exactitate pentru ce dimensiuni ale problemei va fi rulata aplicatia
de catre beneficiar. Astfel, ın cazurile ın care proiectarea aplicatiilor paralele
se realizeaza folosind descompunerea domeniului, datele sunt separate ın blocuri
distincte ce pot fi procesate separat. Dupa stabilirea modului de partitionare
a domeniului de date este necesara definirea comunicatiilor, sarcina ce poate
reprezenta o adevarata provocare.
Pentru a veni ın sprijinul proiectantului se poate dezvolta un model statistic al
aplicatiei. Utilizand acest model, dupa implementarea unui prototip al aplicatiei,
proiectantul trebuie sa poata urmari evolutia parametrilor de calitate ai aplicatiei
si sa poata identifica mai usor eventualele erori.
62
3.1. Introducere ın tehnica proiectarii statistice a experimentelor
3.1 Introducere ın tehnica proiectarii statistice a experi-
mentelor
In realizarea testelor, ın mod deliberat sunt schimbate una sau mai multe vari-
abile (factori) pentru a observa efectul pe care aceste schimbari ıl au asupra
raspunsului. Tehnica proiectarii statistice a experimentelor (Design of ex-
periments – DOE) reprezinta o metoda eficienta de planificare a testelor astfel
ıncat rezultatele obtinute pot fi analizate pentru a trage concluzii valide si obiec-
tive [NIST/SEMATECH 06].
Metodologia DOE poate fi aplicata cu succes ın cazurile de tip blackbox, atunci
cand se cauta optimizarea unei caracteristici de calitate (raspuns al sistemului)
prin reglarea factorilor de intrare. Datele de intrare sunt cunoscute ın literatura
de specialitate cu numele de factori/variabile care pot fi cunoscuti sau controlati.
Pot exista ınsa si factori care influenteaza sistemul, dar care nu pot fi gestionati,
fiind o sursa de incertitudine – se numesc ın mod uzual factori necunoscuti sau
necontrolati. Datele de iesire ale sistemului se numesc raspunsuri sau variabile
de iesire care sunt de fapt caracteristici de calitate ce urmeaza a fi studiate si
optimizate.
Un plan experimental este o schema de realizare a experimentelor prin care
[Isaic-Maniu 06]:
• sunt organizate, desfasurate si executate experimentele;
• sunt culese si ınregistrate datele de observatie si felul ın care sunt rapor-
tate acestea, astfel ıncat sa se poata investiga influenta factorilor controlati
asupra variabilei de interes, estimand cantitativ si calitativ magnitudinea
acestei influente si stabilind care dintre factorii controlati au o importanta
deosebita;
• sunt decantate sursele de variabilitate prezente ın datele stranse – cele da-
torate factorilor controlati si cele atribuite variatiilor aleatoare provenite
din actiunea factorilor necontrolati.
Realizarea planului experimental ıncepe cu determinarea obiectivelor unui expe-
riment si selectarea factorilor ce vor fi studiati.
Un plan experimental bine ales maximizeaza cuantumul de informatii care
poate fi obtinut pentru un anumit efort depus ın realizarea experimentului. Tre-
buie precizat ca se evita folosirea termenului de ”planificare” a experimentului,
deoarece nu se planifica nimic ın sensul de a obtine ceva dinainte scontat. ”Plani-
ficarea” nu se refera decat la conditiile ın care se desfasoara experimentul, pentru
a asigura obiectivitatea acestuia [Isaic-Maniu 06].
Teoria ce sta la baza DOE are ca punct de start definirea conceptului de
model al procesului. Pasii ce urmeaza fi parcursi pentru realizarea acestui model
sunt [NIST/SEMATECH 06]:
• selectarea modelului (model selection);
63
3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
• ajustarea modelului (model fitting);
• validarea modelului (model validation).
Acesti trei pasi sunt urmati iterativ (vezi Figura 3.1) pana cand se gaseste un
model ce descrie cat mai bine procesul.
Start
Selectarea modelului pe baza datelor curente sau pe baza
rezultatelor unui model anterior
Validarea modelului
Sunt necesare date noi
pentru aproximarea modelului?
Proiectează unnou experiment.
Aproximează modelul folosind metoda estimării parametrilor
bazată pe informaţii şi date ale procesului
Achiziţie date noi.
Performanţelemodelului sunt satisfăcătoare?
Stop
Nu
Da
Nu
Da
Figura 3.1: Alegerea modelului DOE (adaptare dupa [NIST/SEMATECH 06])
Exista patru arii de probleme de proiectare ın care se poate aplica tehnica
DOE [NIST/SEMATECH 06]:
• Testari comparative (Comparative): – se urmareste sa se determine ın ce
masura schimbarile efectuate asupra unui singur factor au ca rezultat mod-
ificarea/ımbunatatirea procesului ca ıntreg.
• Selectare (Screening/Characterizing): – reprezinta ıntelegerea procesului ca
64
3.1. Introducere ın tehnica proiectarii statistice a experimentelor
ıntreg ın sensul ca se doreste obtinerea unei liste cu factorii, de la cei mai
importanti la cei mai putin importanti, ce au influenta asupra procesului.
• Modelare (Modeling): – dezvoltarea unui model al modului de functiona-
re a unui proces, cu raspunsurile descrise de o functie matematica si spre
obtinerea unei estimari cat mai precise a coeficientilor acestei functii.
• Optimizare (Optimizing): – identificarea valorii optime a factorilor ce in-
fluenteaza procesul, si determinarea factorilor, sau ce nivel al acelor factori,
optimizeaza raspunsul procesului.
Alegerea unui plan experimental depinde de obiectivele experimentului si de
numarul de factori ce urmeaza a fi investigati [NIST/SEMATECH 06]:
• Analiza comparativa a factorilor (Comparative objective): Daca exista unul
sau mai multi factori ce trebuie investigati, iar scopul analizei este aflarea
unor informatii despre un anumit factor (ın pofida prezentei si/sau absentei
altor factori) si determinarea importantei acestuia, atunci trebuie realizat
un plan de analiza comparativa.
• Selectia factorilor (Screening objective): Scopul urmarit este gasirea si ex-
tragerea doar a acelor factori ce au influenta asupra raspunsului. Acest tip
de analiza este numita si plan de tip ”efecte principale”.
• Metoda suprafetelor de raspuns (Response Surface (method) objective: ın
acest caz, este utilizata ipoteza ca experimentul este proiectat astfel ıncat sa
permita estimarea interactiunilor si sa ofere informatii despre forma (locala)
a suprafetei de raspuns investigate. In general, aceste metode sunt utilizate
pentru:
– gasirea unor parametri mai buni sau chiar a celor optimi pentru un
proces;
– depanarea si descoperirea punctelor slabe;
– realizarea unui produs sau proces imbunatatit si mai robust la influenta
factorilor ce nu pot fi controlti.
• Optimizarea raspunsului: obiectivul acestui model este determinarea influ-
entei diferitelor combinari de factori asupra variabilei raspuns. Se urmareste
practic identificarea acelor combinari care, ın diferite proportii, maximizeaza
(sau minimizeaza) valoarea raspunsului primit.
• Obiective de tip adaptarea optima a modelelor de regresie: scopul urmarit
este identificarea acelui tip de regresie care aproximeaza cel mai bine pro-
cesul supus analizei.
Alegerea planului experimental se poate face conform Tabelului 3.1, descrirea
detaliata a acestuia fiind disponibila la [NIST/SEMATECH 06].
Planul experimental folosit in sectiunea 3.3.2 este cel multifactorial (full fac-
torial) cu doua niveluri pentru fiecare factor, plan care este cel mai des ıntalnit,
conform [NIST/SEMATECH 06]. Nivelul fiecarui factor poate fi ”minim” (”low”
sau ”+1”) sau ”maxim” (”high” sau ”−1”). Un plan ce contine toate combinatiile
65
3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
Numarul Analiza Selectia Metoda Suprafetelorfactorilor comparativa factorilor de raspuns
1-factor1 completely - -
randomized design
Randomized multifactorial Central2 - 4 block sau fractional composite
design factorial sau Box-Behnken
Randomized Fractional Selectia factorilor5 sau block factorial sau pentru a reduce
Reziduurile sunt aleatoare şi au o distribuţie normală
în jurul valorii 0?
Existăerori de aproximare
mari?
Examinare tabel ANOVA
Se încearcăprocesarea datelor
experimentale
Utilizarea reprezentării graficepentru a identifica sursa erorilor
de aproximare. Daca este fezabil, se modifică
modelul. Dacă nu, se reproiectează.
Este utilă simplificarea
modelului?
Utilizarea rezultatelor obţinute pentru a răspunde la întrebările generate de
obiectivele analizei.
Nu
Da
Da
Nu
Da
Da
Nu
Nu
Figura 3.2: Etapele ce trebuie urmate ın analiza folosind DOE (adaptare dupa
[NIST/SEMATECH 06])
3.1.1 Analiza dispersionala
Procedeul de analiza a variantei factorilor sau analiza dispersionala (analysis of
variance – ANOVA) reprezinta acea metoda ce analizeaza variatia unei variabile
ın raport cu factorii de influenta [Jaba 98]. Prin acest procedeu se pot testa
ipoteze cu privire la parametrii unui model, se pot estima componentele dispersiei
unei variabile si semnificatia factorilor de influenta asupra dispersiei.
67
3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
Procedeul consta ın descompunerea variatiei totale a unui ansamblu de date
ınregistrate pentru o variabila X ın componente definite dupa sursa variatiei
(cauzele acesteia) si compararea acestora pentru a stabili daca factorii considerati
cauza au influenta semnificativa asupra varaibilei X [Jaba 98].
Metoda analizei dispersionale (ANOVA), este utilizata pentru a verifica gradul
ın care valorile reale, empirice ale unei caracteristici se abat de la valorile teoretice,
determinate ın general cu ajutorul mediilor sau al ecuatiilor de regresie. Metoda
studiaza efectul variabilei/variabilelor independente asupra celei dependente, al-
tfel spus, masura ın care variatia caracteristicii rezultative este dependenta sau
nu de factorul (factorii) de grupare. ANOVA are la baza metoda gruparii, prin
ea separandu-se influenta factorilor esentiali (determinanti) de influenta facto-
rilor considerati ıntamplatori (aleatori) asupra caracteristicii efect. In functie de
numarul factorilor ınregistrati ce-si exercita influenta asupra caracteristicii rezul-
tative (unul, doi sau mai multi), analiza dispersionala se poate efectua dupa un
model unifactorial, bifactorial sau multifactorial.
Pentru fiecare varianta/interval de variatie a caracteristicii cauzale X, se ınre-
gistreaza o distributie de valori ale variabilei efect Y , distributie pe care o putem
caracteriza, de regula, prin nivelul mediu. Daca aceste medii ale variabilei Y , pe
grupe dupa X sunt egale sau foarte putin diferite, atunci se concluzioneaza ca
variabila independenta X nu influenteaza variatia variabilei dependente Y . Cu
cat mediile lui Y pe grupe dupa X difera mai mult unele de altele, cu atat X
influenteaza mai mult pe Y .
Tabelul ANOVA pentru o variabila raspuns este utilizat la identificarea fac-
torilor si a interactiunii dintre factori ce sunt semnificative din punct de vedere
statistic (vezi Tabelele 3.6, 3.7, 3.8). Acest tabel are urmatoarele componente
[Montgomery 07]:
• prima coloana indica sursa de variatie;
• coloana a doua reprezinta suma patratelor abaterilor (Sum of squares –
SS);
• coloana a treia reprezinta numarul de grade de libertate ( d.f.)
• coloana a patra reprezinta media patratelor (Mean Squares - MS);
• ın coloana a cincea se gaseste testul statistic F (Fisher);
• gradul de influenta – P −value: reprezinta probabilitatea de aparitie a unei
erori observate din ıntamplare.
Semnificatia statistica a P−value este urmatoarea: o valoare foarte apropiata
de zero indica o importanta crescuta a factorului ın discutie asupra raspunsului
urmarit. Presupunem o familie de teste ale unei ipoteze nule (notata cu H0),
definite de valori ale nivelului de semnificatie p. Prin P − value asociata ipotezei
nule, pentru setul de date considerat, se ıntelege cel mai mic nivel de semnificatie
p pentru care ipoteza nula se respinge ın toate testele. Astfel, ıntr-un test uni-
lateral, daca X este statistica testului si notam cu xp valoarea critica astfel ıncat
68
3.1. Introducere ın tehnica proiectarii statistice a experimentelor
respingem H0 pentru X < xp, notam cu x valoarea observata a lui X, atunci
P − value pentru ipoteza nula si observatiile disponibile este cea mai mica val-
oare p ıncat x < xp. Majoritatea programelor dedicate calculelor statistice ofera,
la procedurile de testare a ipotezelor, valoarea de probabilitate. Daca P − valueeste mai mica sau egala cu nivelul de semnificatie p, atunci se respinge ipoteza
nula.
O situatie des ıntalnita ın practica este aceea ın care asupra unei caracteristici
ce trebuie studiate, actioneaza doi factori A si B, factori ce se pot influenta
reciproc. In acest caz trebuie luata ın considerare si interactiunea acestora. Este
posibil ca efectul interactiunii factorilor asupra variabilei investigate sa fie nul, dar
acest lucru nu se poate determina cu certitudine ınaintea derularii experimentului.
Acest model este numit modelul bifactorial cu interactiuni. Pentru fiecare factori
avem mai multe niveluri. Notam cu a numarul de niveluri ale factorului A, cu
b numarul de niveluri ale factorului B si cu n numarul de experimente. Pentru
acest caz, tabelul ANOVA este de forma:
Sursa de variatieSuma de
patrate
Gradele de
libertateMedia patratelor
Statistica
F
Tratamentul (A) SSA a− 1 MSA = SSAa−1
MSAMSE
Tratamentul (B) SSB b− 1 MSB = SSBb−1
MSBMSE
Interactiunea
(AB)SSAB (a− 1)(b− 1) MSAB = SSAB
(a−1)(b−1)MSABMSE
Eroarea SSE ab(n− 1) MSE = SSEab(n−1) –
Total SST abn− 1 – –
Tabelul 3.2: Tabelul ANOVA pentru un plan bifactorial cu interactiuni (adaptare
dupa [Isaic-Maniu 06] si [Montgomery 07])
Formulele cu ajutorul carora se calculeaza sumele de patrate din tabelul
ANOVA sunt urmatoarele [Montgomery 07]:
a∑i=1
b∑j=1
n∑k=1
(yijk − y···)2 = bna∑
i=1
(yi·· − y···)2
+ anb∑
j=1
(y·j· − y···)2
+ n
a∑i=1
b∑j=1
(yij· − yi·· − y·j· + y···)2
+a∑
i=1
b∑j=1
n∑k=1
(yijk − yij·)2
69
3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
sau simbolic:
SST = SSA + SSB + SSAB + SSE ,
unde: y··· – reprezinta media tuturor celor abn observatii; yi·· – reprezinta media
observatiilor pentru nivelul i al factorului A; y·j· – reprezinta media observatiilor
pentru nivelul j al factorului B iar yij· – reprezinta media observatiilor pentru
nivelurile i si j ale celor 2 factori [Isaic-Maniu 06].
Daca pentru o statistica F din tabelul ANOVA, probabilitatea P −value este
mai mica sau egala cu nivelul de semnificatie ales (de obicei 0.05 sau 0.01), atunci
se respinge ipoteza nula, asa cum se va arata ın subcapitolul 3.3.2.
3.1.2 Analiza de regresie
Intelegerea comportamentului unui sistem impune studierea legaturilor dintre
variabilele ce ıl definesc prin utilizarea metodei de regresie si corelatie. Situatiile
care se ıntalnesc ın studiul legaturilor dintre variabile [Jaba 98]:
• legatura nula: cand nu exista nici o influenta ıntre variabilele considerate;
• legatura functionala: cand modificarea unei variabile antreneaza variatia
altei variabile ıntr-o masura ce ramane constanta;
• legatura statistica: cand modificarea unei variabile este rezultatul conjugat
al influentei mai multor variabile.
Studiul comportamentului a doua sau mai multe variabile poate evidentia o
relatie de dependenta functionala sau o dependenta statistica (definirea unei legi
care sa explice relatia dintre variabile). Astfel de probleme se pot rezolva cu
ajutorul analizei de regresie si corelatie.
Conceptul de regresie exprima o legatura de tip statistic cu privire la com-
portamentul unor variabile. Analiza modelelor de regresie reprezinta o metoda
statistica care permite studierea si masurarea relatiei care exista ıntre doua sau
mai multe variabile, precum si descoperirea legii relative la forma legaturilor
dintre variabile. Prin aceasta metoda se ıncearca, pe baza unui esantion, sa
se estimeze relatia matematica dintre doua sau mai multe variabile, adica sa
se estimeze valorile unei variabile ın functie de valorile altei variabile [Jaba 98].
Modelele matematice obtinute prin aplicarea analizei de regresie sunt denumite
ecuatii de regresie. Expresia generala a unui ecuatii de regresie va fi descrisa ın
paragraful urmator.
Pentru alegerea tipului de regresie se poate utiliza aceiasi metoda ca aceea
descrisa ın Figura 3.1 la alegerea modelului DOE.
3.1.3 Modelul unui proces
In mod uzual, modelarea unui proces ıncepe cu modelul de cutie neagra, ımpreuna
cu factorii de intrare discreti sau continui ce pot fi controlati si modificati de
cercetator, si una sau mai multe variabile de tip raspuns ce pot fi determinate.
70
3.1. Introducere ın tehnica proiectarii statistice a experimentelor
Variabilele raspuns se presupun a fi continue. Datele experimentare sunt utilizate
pentru a realiza un model empiric care leaga factorii de intrare de raspunsuri. De-
seori, experimentele trebuie sa determine numarul de factori ce nu pot fi controlati
(Figura 3.3).
Informatii suplimentare legate de proiectarea statistica a experimentelor si
de construirea modelelor empirice bazate pe analiza statistica pot fi gasite ın
Modelul generic al unei ecuatii de regresie este de forma [Montgomery 06]:
Y = f (X1, X2, . . . , Xk) + ε . (3.1.1)
Intrări
necunoscute/necontrolate -ε
Intr
ări
contr
ola
te
(Fac
tori
) X
Ieşi
ri
(Răs
punsu
ri)
Y
Figura 3.3: Modelul de tip cutie neagra (adaptare dupa [NIST/SEMATECH 06])
Pentru un model liniar cu doi facori X1 si X2, ecuatia de regresie poate fi
scrisa [Montgomery 06]:
Y = β0 + β1X1 + β2X2 + β12X1X2 + ε , (3.1.2)
unde Y reprezinta raspunsul pentru un anumita valoare a factorilor X1 si X2,
ε este eroarea experimentala iar termenul X1X2 simbolizeaza un posibil efect al
interactiunii dintre X1 si X2. Constanta β0 reprezinta raspunsul Y al sistemului
atunci cand cei doi factori sunt nuli.
Pentru modele mai complicate, un model liniar cu trei factori X1, X2, X3 si
un raspuns Y poate fi descris prin ecuatia urmatoare [Montgomery 06]:
Y = β0 + β1X1 + β2X2 + β3X3 + β12X1X2
+β13X1X3 + β23X2X3 + β123X1X2X3 + ε , (3.1.3)
71
3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
sau ın cazul general:
Y = β0 +
k∑i=1
βixi +
k∑i=1
βiix2i +
k∑i<j
k∑j=1
βij ·xi ·xj +
p∑i<j<k
βijk ·xi ·xj ·xk + . . .+ ε .
(3.1.4)
Termenii ce contin un singur factor X reprezinta efectul direct al acestora
asupra raspunsului. In cazul general, modelul expus de ecuatia 3.1.4 va lua ın
considerare toate interactiunile combinate ıntre toti cei k factori de intrare. Alt-
fel spus trebuie considerati toti factorii de forma Cik, pentru 1 < i ≤ k. Astfel,
pentru cazul a trei factori de intrare exista C23 = 3 interactiuni bilaterale ıntre
factori si C33 = 1 interactiuni trilaterale (ecuatia 3.1.3). Pentru simplitate aceasta
ultima interactiune ıntre factori este adesea ignorata. Cand sunt analizate datele
experimentale, toti parametrii necunoscuti β sunt estimati, iar coeficientii terme-
nilor X sunt testati pentru a determina care sunt valorile semnificativ diferite de
zero, conform ANOVA.
Coeficientii β mai sunt numiti si coeficienti de regresie. Acesti coeficienti
sunt estimati cu scopul de a minimiza eroarea, proces denumit si regresie. Ecuatia
raspunsului Y se poate scrie sub forma matriciala astfel [Montgomery 06] :
y = X · β + ε . (3.1.5)
unde
y =
y1y2...
yn
X =
1 x11 x12 · · · x1k1 x21 x22 · · · x2k...
......
...
1 xn1 xn2 · · · xnk
β =
β1β2...
βn
ε =
ε1ε2...
εn
In cazul general, y este vectorul raspunsurilor (n × 1), X este o matrice n × p,unde p = k + 1, ce contine nivelurile factorilor si a interactiunii dintre acestia –
matricea modelului, β este un vector de dimensiune p×1 ce reprezinta coeficientii
de regresie si ε este un vector de dimensiune (n× 1) cu erorile experimentale.
In ecuatia anterioara, deoarece se urmareste minimizarea erorii ε, coeficientii
β ai modelului predictiv sunt estimati utilizand formula urmatoare:
β =(XT ·X
)−1 ·XT · y . (3.1.6)
3.1.4 Utilizare ın domeniu
Analiza statistica folosind planul experimental ofera o cale de a determina ce con-
figuratie specifica trebuie simulata pentru ca informatiile dorite sa fie obtinute
dupa un numar redus de simulari [Law 99]. Suplimentar, planul experimental
realizat si analizat corespunzator: (1) faciliteaza identificarea efectului factorilor
72
3.1. Introducere ın tehnica proiectarii statistice a experimentelor
(variabilelor) care pot determina modifiari ale performantei; si (2) ajuta ın a de-
termina daca un anumit factor are efect semnificativ sau daca diferentele obser-
vate sunt rezultatul unor erori aleatorii rezultate din masuratori si din paramatri
ce nu pot fi controlati [Jain 91].
Ruthruff, ın [Ruthruff 06], arata ca utilizarea tehnicii planului experimental
poate ajuta cercetatorii si dezvoltatorii de software sa identifice limitarile tehni-
cilor de analiza, sa ımbunatateasca tehnicile de analiza experimentala existente
si sa creeze noi tehnici de analiza a programelor. Aceste tehnici pot fi capabile
sa creioneze concluzii despre proprietatile sistemelor software ın cazul ın care
utilizarea metodelor traditionale nu are succes [Ruthruff 06].
De exemplu, ın [Rao 08], tehnica planului experimental este utilizata pen-
tru testarea performantelor masinii virtuale Java pe sisteme embedded. Au-
torii construiesc un model de regresie care utilizeaza relatii ıntre parametrii de
performanta ai masinii virtuale Java cu diverse metrici corespunzatoare arhitec-
turilor embedded. Modelul dezvoltat este usor de interpretat si precizia este
apropiata de erorile de masurare. Prin aceasta metoda, proiectantul aplicatiilor
este sfatuit sa modifice parametrii masinii virtuale Java pentru a obtine performan-
tele optime.
Utilizarea metodei de proiectare statistica a experimentelor ın proiectarea a-
plicatiilor secventiale reprezinta o buna politica de selectare a componentelor unei
aplicatii, ce ofera cele mai bune rezultate pentru o anumita problema. O astfel
de abordare este descrisa ın [Stewardson 02] pentru selectarea unui numar redus
de combinatii de algoritmi genetici pentru rezolvarea problemelor de planificare.
Deoarece selectia trebuie sa acopere ın egala masura fiecare tip de parametru
si combinatiile acestora, autorii utilizeaza metoda planului experimental pe post
de metoda de reducere a incertitudinii si complexitatii. Tehnica planului exper-
imental este utilizata si ın [Ridge 07], unde este construit un model predictiv
al performantelor ce combina tehnicile euristice de optimizare asupra unui set
de parametri si caracteristicile problemei studiate. Alte abordari statistice de
analiza a performantelor aplicatiilor paralele au fost propuse recent de [Zheng 10],
[Barnes 08] si [Whiting 04].
Totusi, nici una din solutiile mentionate nu se adreseaza tehnicilor de cons-
truire a unui eventual model generic de proiectare a aplicatiilor paralele. De
exemplu, [Zheng 10] utilizeaza modele statistice pentru predictia performantelor
unei aplicatii paralele, utilizand performantele blocurilor secventiale. Acest lu-
cru este realizat prin simulari ale unui model de dimensiuni reduse al problemei
pentru a afla caracteristicile aplicatiei. Prin intermediul tehnicilor de ınvatare
(machine learning techniques) precum retelele neuronale, cunostintele acumulate
sunt transformate ıntr-un model statistic pentru fiecare bloc executat secvential.
Aceste cunostinte sunt apoi utilizate ın prezicerea performantelor la rularea ın
cazul real pe un simulator.
73
3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
In [Barnes 08], regresia multi-variabila este utilizata pentru a prezice per-
formantele unei configuratii cu un numar mare de procesoare utilizand datele
obtinute prin rularea pe un numar mic de procesoare. Chiar daca aceasta metoda
poate fi utilizata pentru prezicerea scalabilitatii unui program paralel, tehnica nu
ofera informatii legate de factorii ce determina performantele aplicatiei parale-
le studiate. Tehnica planului experimental este utiliata de [Whiting 04] pen-
tru a evalua performantele unei aplicatii paralele ce implementeaza o problema
computationala complexa din domeniul filogeneticii. Autorii prezinta cateva
metode de realizare a planului experimental precum: multifactorial (full facto-
rial), fractional factorial (vezi Tabelul 3.1) si D-optimal (definit ın [Dykstra 71]).
Evaluarea parametrilor este realizata prin metoda planului D-optimal. Autorii
prezinta un set de concluzii cu privire la influenta spatiului de cautare, a algorit-
mului ales si a numarului de procesoare asupra performantelor aplicatiei.
Analiza comportamentului unui program prin intermediul paradigmelor de de-
sign experimental poate ajuta cercetatorii si dezvoltatorii de aplicatii sa identifice
limitarile tehnicilor de analiza, sa ımbunatateasca modelul si sa creeze noi tehnici
de analiza.Aceste tehnici sunt capabile sa creeze o imagine asupra proprietatilor
sistemului ın cazurile ın care tehnicile traditionale esueaza [Ruthruff 06].
O strategie bazata pe DOE a fost utilizata pentru analiza performantelor mo-
delului retelelor mobile ad-hoc si a protocoalelor utilizate. Rezultatele obtinute
au condus la determinarea unor concluzii obiective asupra unor arii largite de
retele si medii de comunicatii [Totaro 05].
Spre deosebire de aceste solutii, abordarea prezentata ın sectiunile urmatoare
are la baza un model predictiv al performantelor, scopul acestuia fiind deter-
minarea factorilor ce influenteaza performantele aplicatiei paralele, precum si
prezicerea performantelor aplicatiei ın diferite conditii de rulare ınca din faza de
proiectare.
Un numar semnificativ de factori si strategii de proiectare conduc la nu-
meroase ıntrebari: Care factori influenteaza o anumita metrica de performanta?
Exista interactiuni ıntre factori? Este posibila cuantificarea efectului fiecarui fac-
tor si a interactiunilor dintre acestia? Daca da, modificarea carui factor furnizeaza
performante maxime si care este comportamentul acestora? Aceste modificari
impun limitari pentru programe?
O alternativa la DOE ar fi utilizarea de tehnici euristice, dar ın acest caz
comportamentul aplicatiei nu poate fi cuantificat. Tehnicile euristice presupun
rularea repetata a aplicatiei pentru a obtine comportamente diferite. Dezavanta-
jul acestor tehnici este ca ofera rezultate aproximative, ce trebuie reevaluate ın
permanenta pentru a fi ımbunatatite [Ridge 07].
Prin contrast, avantajele utilizarii tehnicilor statistice bazate pe DOE sunt
semnificative. Un plan experimental bine construit permite proiectantilor de
aplicatii sa obtina maximum de informatii cu un numar minim de experimente
74
3.2. Modelul propus pentru ımbunatatirea proiectarii aplicatiilor paralele
[Totaro 05]. Planul experimental ofera o metoda de indentificare a configuratiilor
specifice de simulare ınaintea rularii efective. Astfel, informatiile dorite sunt
obtinute cu un numar minim de simulari [Jain 91].
Tehnici detaliate de folosire a DOE si de construire a modelelor empirice se pot
gasi ın detaliu ın [Box 78], [Jain 91], [Montgomery 06] si [Kleijnen 04]. Cateva
idei si metodologii de investigare empirica ce pot fi utilizate ın ingineria software
sunt prezentate ın [Kitchenham 02] si in [Ivan 04].
3.2 Modelul propus pentru ımbunatatirea proiectarii apli-
catiilor paralele
In continuare este prezentat un model de analiza si verificare a unei aplicatii
paralele. Modelul ia ın considerare factorii ce pot influenta comportamentul
aplicatiei, furnizand indicii asupra erorilor ce pot apare ın etapele de proiectare.
Este prezentata modalitatea ın care strategiile statistice bazate pe DOE pot fi
folosite pentru analiza performantelor unei aplicatii paralele ın scopul de a trage
concluzii obiective privind erorile de proiectare. De asemenea, se pot obtine
informatii legate de conditiile de rulare pe baza parametrilor de performanta
luati ın considerare.
Modelul propus ın [Amarandei 11] pentru proiectarea aplicatiilor paralele pre-
supune parcurgerea a trei etape (Figura 3.4).
Astfel prima etapa reprezinta pasii clasici de proiectare a unei aplicatii par-
alele, pasi descrisi ın [Foster 95]. Conform acestui model, la sfarsitul fiecarei
etape, proiectantul unei aplicatii paralele trebuie sa analizeze rezultatul obtinut
printr-o serie de verificari descrise ın cadrul subcapitolelor 2.2.1.3, 2.2.2.1, 2.2.3.4
si 2.2.4.3. Rezultatul acestei etape ıl reprezinta prototipul aplicatiei paralele sau a
algoritmului paralel. Cu acest prototip se fac masuratori legate de functionalitatea
si performantele aplicatiei: timpii de procesare, timpii de comunicatie, cantitatea
de date transferata ıntre procese, etc.
Dupa proiectarea aplicatiei paralele, un rol important ıl au modelele de perfor-
manta descrise ın [Foster 95] si mai pe larg ın sectiunea 2.4. Informatii importante
pot fi obtinute prin compararea datelor masurate si a celor prezise. Aceste valori
sunt rareori identice datorita gradului de idealizare utilizat ın timpul proiectarii.
Daca sunt discrepante majore, acestea apar fie datorita modelului incorect, fie
datorita implementarii defectuoase. In cazul unui model incorect, rezultatele
empirice pot fi utilizate pentru a determina deficientele modelului si a reevalua
compromisurile facute pentru a justifica deciziile de proiectare. In al doilea caz,
putem utiliza modelul pentru a identifica unde anume poate fi ımbunatatita im-
plementarea.
Etapa a doua presupune realizarea unui plan experimental cu efectuarea expe-
rimentelor, analiza statistica si interpretarea rezultatelor. Analiza statistica poate
75
3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
Etapa 2:
Analiza statistică bazată pe DOE
Etapa 1:
Proiectarea aplicaţiei paralele
Partiţionarea
problemei
Proiectarea
comunicaţiilor
Aglomerarea
Maparea
pe procesoare
Definirea planului
experimental
Rularea prototipului
aplicaţiei
Analiza statistică
NU Rezultatele sunt satisfăcătoare?
Etapa 3:
Implementarea soluţiei
DA
Figura 3.4: Modelul de proiectare al aplicatiilor paralele utilizand DoE[Amarandei 11]
furniza informatii legate de performantele aplicatiei si pot ajuta la eliminarea
factorilor care nu au o influenta directa. De asemenea, asa cum se va indica ın
continuare, se poate realiza modelul aplicatiei pe baza setului de date obtinut,
precum si o predictie asupra valorilor variabilelor raspuns pe baza factorilor de
intrare considerati.
Primele doua etape sunt reiterate pana cand rezultatele experimentale vali-
deaza metricile de performanta impuse. In acest punct se poate trece la ultima
etapa si anume implementarea solutiei.
Astfel, cu ajutorul acestui model se poate raspunde la ıntrebarile de verificare
descrise ın subcapitolele 2.2.1.3, 2.2.2.1, 2.2.3.4 si 2.2.4.3 si se pot face aprecieri
asupra dimensiunii datelor transferate functie de parametrii de intrare asa cum
se va arata ın studiul de caz de mai jos. In cadrul acestei analizei statistice,
daca informatiile obtinute nu sunt satisfacatoare, se pot lua decizii de refacere a
unei etape de proiectare a aplicatiei: de exemplu comunicatiile sunt corecte, dar
partitionarea datelor nu este bine facuta, etc [Amarandei 11].
Pentru verificarea modelului au fost realizate urmatoarele etape: realizarea
76
3.2. Modelul propus pentru ımbunatatirea proiectarii aplicatiilor paralele
unei aplicatii paralele ce utilizeaza tehnica descompunerii domeniului de date
(domain decomposition), realizarea unui plan experimental de tip multifactorial
(conform Tabelului 3.1) pentru analiza performantelor aplicatiei, interpretarea
rezultatelor din ANOVA si din analiza de regresie pentru identificarea unor even-
tuale erori de proiectare.
3.2.1 Analiza unei aplicatii paralele folosind modelul propus
Utilizand analiza statistica a datelor obtinute ın urma simularilor, prin inter-
mediul ANOVA, cercetatorii pot identifica efectele produse de factorii de intrare
precum si interactiunea dintre acestia pentru a explica metricile de performanta
[Totaro 05]. Pasii care trebuie urmati pentru realizarea experimentului sunt
urmatorii [Amarandei 11]:
1. Definirea obiectivelor: Scopul acestui model este demonstrarea eficientei
strategiei bazate pe DOE ın evaluarea performantelor unei aplicatii par-
alele si identificarea erorilor de proiectare. Pentru atingerea acestui scop,
obiectivele specifice sunt cuantificarea efectelor unor potentiali factori ce
influenteaza performantele unei aplicatii paralele. Utilizand aceste efecte, se
dezvolta un model empiric, ce poate fi folosit pentru a prezice performantele
aplicatiei paralele ın momentul rularii cu date de intrare diferite de cele ex-
aminate.
2. Selectarea factorilor de intrare: Pasul urmator ın realizarea planului
experimental este selectia factorilor de intrare potentiali ce pot influenta
performantele aplicatiei paralele.
3. Selectarea variabilelor raspuns: Dupa alegerea factorilor de intrare,
functie de obiectivele urmarite sunt selectate variabilele raspuns – ca de
exemplu timpul de procesare sau timpul de comunicatie.
4. Selectarea metodei de analiza: Exista libertate deplina ın a alege o
metoa de analiza ın functie de numarul factorilor si de obiectivele urmarite
(Tabelul 3.3 si Figura 3.1), motivarea alegerii si metodele disponibile nu fac
obiectul acestei teze, fiind prezentate pe larg ın [NIST/SEMATECH 06].
Pentru simplitatea calculelor, este utilizata o codare a factorilor folosind,
de obicei, valori +/- sau 0/1.
5. Rularea aplicatiei si colectarea datelor: In acest pas se efectueaza
testarea aplicatiei. In functie de numarul factorilor de intrare, aplicatia
trebuie rulata de n ori (la fiecare rulare pentru factorii de intrare trebuie
utilizate valorile din planul experimental si adunate rezultatele.
6. Analiza statistica: In acest pas, se analizeaza efectele principale si cele
de interactiune. Efectele principale sunt modificarile asupra unei variabile
raspuns la variatia unui factor de intrare. Efectele de interactiune sunt
efectele combinate ale factorilor de intrare asupra unei variabile raspuns.
Dupa rularea aplicatiei, pentru setul de date de intrare ales, se analizeaza
77
3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
influenta acestora asupra raspunsului urmarit.
7. Construirea modelului empiric pentru raspunsurile considerate:
Dupa rularea aplicatiei utilizand factorii de intrare selectati, se analizeaza
influenta acestora asupra variabilelor raspuns. Se construieste un model
empiric pe baza datelor obtinute utilizand metoda planului experimental.
Pasii ce trebuie urmati sunt urmatorii: selectia modelului, ajustarea si vali-
darea acestuia. Acesti trei pasi sunt utilizati iterativ pana cand se obtine un
model cat mai apropiat de rezultatele obtinute. In etapa de selectie a mod-
elului, efectele factorilor si a interactiunilor dintre acestia sunt determinate
din tabelul ANOVA pentru a afla modul ın care modelul poate fi adaptat
la date. Dupa acest pas, folosind modelul selectat si datele disponibile, se
verifica daca acest model descrie cat mai bine posibil parametrii necunoscuti
ai modelului. Dupa estimarea parametrilor, modelul este evaluat pentru a
afla daca nu cumva presupunerile facute pe parcursul analizei sunt plauz-
ibile. Daca se dovedeste ca presupunerile sunt corecte, modelul poate fi
folosit pentru a raspunde ıntrebarilor care au dus la realizarea lui. Daca pe
parcursul validarii modelului sunt descoperite probleme, se repeta etapele
parcurse folosind informatiile deja obtinute pentru a selecta si/sau adapta
un model ımbunatatit.
8. Interpretarea rezultatelor: In aceasta ultima etapa se coreleaza efectele
factorilor de intrarea considerati cu analiza variabilelor raspuns ale aplicatiei
paralele pentru a valida sau invalida modelul aplicatiei rezultat din analiza
statistica ın functie de restrictiile impuse asupra parametrilor de performanta.
Dupa analiza statistica asupra factorilor ce influenteaza variabilele raspuns se
construieste un model empiric pe baza datelor colectate utilizand diverse modele
de tip regresie descrise pe larg ın [NIST/SEMATECH 06]. Acest model defineste
relatia functionala ıntre factorii de intrare si metricile de performanta urmarite.
Pe baza acestui model se pot face optimizari asupra modelului, se pot calcula si
estima performantele aplicatiei.
3.3 Analiza cu DOE a unei aplicatii paralele ce utilizeaza
metoda descompunerii domeniului de date: sort last
parallel rendering
Pentru a demonstra utilitatea modelului propus vom analiza o aplicatie de ran-
dare paralela. Operasiunea de realizarea unei imagini 3D se doua etape: proce-
sarea geometriei (transformari, decupari, iluminare etc.) si rasterizarea (transfor-
marea de rastru - umbrire, determinarea vizibilitatii). Paralelizarea geometriei
este de obicei realizata prin atribuirea unei submultimi din primitivele grafice
din scena la fiecare procesor. Paralelizarea operatiei de rasterizare se face prin
78
3.3. Analiza cu DOE a unei aplicatii paralele ce utilizeaza metodadescompunerii domeniului de date: sort last parallel rendering
distribuirea unei portiuni din calculele pixelilor la procesoarele din sistemul de
calcul paralel.
Operatia de randare are ca punct central calcularea efectului fiecarei primitive
asupra fiecarui pixel. Deoarece o primitiva se poate afla oriunde ın spatiul ecran
sau ın afara lui, randarea poate fi privita ca o problema de sortare. Pentru
sisteme complet paralele, operatia de sortare implica redistribuirea datelor ıntre
procesoare. Responsabilitatea pentru fiecare primitiva grafica si pentru fiecare
pixel este distribuita la procesoarele sistemului paralel [Molnar 08].
Proces masterDistribuţie task-uri (NP/n)
Date de intrare (NP)
IM2 IM3 IMnIM1
WP1 WP2 WP3 WPn
Procesare
date
Procesare
date
Procesare
date
Procesare
date
Proces masterAdună rezultatele şi
compune imaginea finală Imaginea finală
Legendă:
WPi – procese worker
NP – dimesciunea datelor de intrare
IMi – imaginea procesată de workerul i
Figura 3.5: Aplicatia paralela de randare a unei imagini [Amarandei 11]
Structura sistemului de randare paralela este data de locul unde are loc
operatia de sortare. Din acest motiv, principala provocare ın proiectarea unui
sistem de randare paralela o reprezinta varietatea de structuri posibile ce se pot
realiza cu resursele de calcul. Sortarea poate avea loc oriunde ın procesul de
randare: ın timpul procesarii geometriei (sortare-ınainte sau ”sort-first” - sunt
distribuite primitivele neprelucrate ınainte de li se cunoaste coordonatele ecran),
ıntre procesarea geometriei si rasterizare (sortare-ıntre sau ”sort-middle” - se re-
alizeaza redistribuirea primitivelor din spatiul ecran) sau ın timpul rasterizarii
(sortare-dupa sau ”sort-last” - sunt redistribuiti pixelii).
In randarea paralela de tip sortare-dupa, cunoscuta si sub numele de randare
paralela ın spatiul obiect, fiecare nod de procesare este responsabil cu randarea
unui bloc de date, indiferent daca acestea sunt sau nu vizibile la momentul re-
79
3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
spectiv (Figura 3.5).
Aplicatia paralela analizata implementeaza modelul de randare paralela sortare-
dupa utilizand modelul de programare message passing. Implementarea aplicatiei
paralele urmareste modelul descris ın Figura 2.2. De aici, utilitatea modelului
propus ın subcapitolul anterior este imediata. Aplicatia poate suferi dezechilibre
ale sarcinilor de randare, si din acest motiv se preteaza analizei utilizand modelul
propus. Scopul acestei analize este extragerea de informatii despre performantele
aplicatiei si identificarea eventualelor erori de proiectare si/sau de implementare.
3.3.1 Planul experimental
Deoarece obiectivul nostru este ilustrarea eficientei metodei de analiza statistica
bazata pe DOE, sunt selectati doar trei factori: dimensiunea datelor de intrare
(X1), dimensiunea imaginii finale (X2) si numarul de procesoare (X3). Valorile
pe care le pot lua acesti factori sunt date ın tabelul 3.3 [Amarandei 11]:
Denumire Codificare Valoare minima Valoare maxima
Nr. puncte X1 100000 4000000
Rezolutia imaginii X2 480000 50000000
Nr. procesoare X3 6 8
Tabelul 3.3: Factorii de intrare [Amarandei 11]
Consideram urmatoarele variabile raspuns pentru aplicatie: dimensiunea da-
telor schimbate ıntre procese (Y1), timpul de procesare (Y2) si timpul de comu-
nicatii (Y3).
Pentru analiza vom utiliza un plan multifactorial (full factorial) pe doua
niveluri. Pentru simplitatea calculelor, este utilizata o codare a factorilor folosind