123
UNIVERSITATEA „DANUBIUS“ DIN GALAŢI DEPARTAMENTUL DE ÎNVĂŢĂMÂNT LA DISTANŢĂ FACULTATEA DE ŞTIINŢE ECONOMICE Conf. univ. dr. CĂTĂLIN ANGELO IOAN STATISTICĂ ECONOMICĂ Anul I, Semestrul I

UNIVERSITATEA „DANUBIUS“ DIN GALAŢI
DEPARTAMENTUL DE ÎNVĂŢĂMÂNT LA DISTANŢĂ
FACULTATEA DE ŞTIINŢE ECONOMICE
Conf. univ. dr. CĂTĂLIN ANGELO IOAN
STATISTICĂ ECONOMICĂ Anul I, Semestrul I

Cătălin Angelo Ioan Statistică economică
2

CUPRINS
Introducere........................................................................................... 5 1. NOȚIUNI DE BAZĂ ALE STATISTICII...................................... 7
2. INDICATORII STATISTICI. OPERAȚII CU VARIABILE ALEATOARE.................................................................................
25
3. INDICATORII TENDINȚEI CENTRALE.................................... 38
4. INDICATORII VARIAȚIEI…………………………................... 62 5. SONDAJUL STATISTIC............................................................... 91 6. SERII CRONOLOGICE................................................................. 101 7. REGRESII....................................................................................... 109

Cătălin Angelo Ioan Statistică economică
4

Cătălin Angelo Ioan Statistică economică
5
INTRODUCERE Modulul intitulat “Statistică economică” se studiază în anul I în semestrul I și vizează dobândirea de competențe în domeniul cunoașterii teoriilor economice. După ce se va învăța modulul, vor fi dobândite următoarele competențe generale:
• Realizarea prestațiilor în contabilitate și informatică de gestiune;
• Explicarea si interpretarea de date si informații din punct de vedere cantitativ si calitativ, pentru formularea de argumente si decizii concrete;
• Culegerea si prelucrarea de date din surse documentare alternative si din activitatea curenta, pentru evaluarea factorilor care influențează realizarea prestațiilor în organizații;
• Fundamentarea de studii si analize, organizatorice si de eficiență a activității firmelor în vederea acordării de consiliere si asistență;
• Elaborarea de calcule pentru diferite situații alternative (variante decizionale) în alocarea de resurselor;
• Realizarea de studii secvenţiale de implementare a calităţii pentru cazuri practice bine definite în condiţii de asistenţă calificată;
• Însuşirea și cunoașterea modului în care ideile și paradigmele au influențat economia în ansamblul ei.
Obiectivele cadru pe care le propun sunt următoarele: • Însuşirea și cunoașterea modului de acțiune statistic; • Aprofundarea și înțelegerea indicatorilor statistici;
• Formarea deprinderilor de a utiliza statistica în economie.
Conținutul este structurat în următoarele unităţi de învăţare:
• NOȚIUNI DE BAZĂ ALE STATISTICII
• INDICATORII STATISTICI
• INDICATORII TENDINȚEI CENTRALE
• INDICATORII VARIAȚIEI
• SONDAJUL STATISTIC
• SERII CRONOLOGICE
• REGRESII
În unitățile de învăţare se vor regăsi operaționalizarea următoarelor competenţe specifice:
• Definirea adecvată a conceptelor şi principiilor specifice teoriei economice;

Cătălin Angelo Ioan Statistică economică
6
• Explicarea şi interpretarea de date si informaţii din punct de vedere cantitativ şi calitativ, pentru formularea de argumente şi decizii concrete asociate;
• Explicarea corectă a noilor concepte;
• Dezvoltarea capacităţii studentului de a percepe rolul şi importanţa doctrinelor economice
după ce se va studia conținutul cursului şi se va parcurge bibliografia recomandată. Pentru aprofundare şi autoevaluare se propun teste adecvate care vor permite să se aprofundeze noțiunile prezentate.
Pentru o învăţare eficientă este nevoie de următorii pași obligatorii:
• Să se citească modulul cu maximă atenție;
• Să se evidențieze informațiile esențiale cu culoare, să fie notate pe hârtie, sau adnotate în spațiul alb rezervat;
• Să se răspundă la întrebări şi să se rezolve exercițiile propuse;
• Să se simuleze evaluarea finală, autopropunându-vă o temă şi rezolvând-o fără să apelați la suportul scris;
• Să se compare rezultatul cu suportul de curs şi să vă explicaţi de ce ați eliminat (eventual) anumite secvențe;
• În caz de rezultat nesatisfăcător să se reia întreg demersul de învăţare.
Se vor primi, după fiecare capitol parcurs, lucrări de verificare, cu cerinţe clare, care vor trebui rezolvate, imediat ce veți fi anunțați prin intermediul platformei de învățământ în termen de o săptămână; în acest fel vor fi îndeplinite obiectivele pe care le-am formulat. Se va răspunde în scris la aceste cerințe, folosindu-vă de suportul de curs şi de următoarele resurse suplimentare (autori, titluri, pagini). Veți fi evaluat după gradul în care ați reușit să operaționalizați competenţele. Se va ţine cont de acuratețea rezolvării, de modul de prezentare şi de promptitudinea răspunsului. Pentru neclarităţi şi informații suplimentare veți apela la tutorele indicat. 30% din notă va proveni din evaluarea continuă (cele două lucrări de verificare) şi 70% din evaluarea finală.

Cătălin Angelo Ioan Statistică economică
7
1. NOȚIUNI DE BAZĂ ALE STATISTICII
NOȚIUNI DE BAZĂ ALE STATISTICII 7
Rezumat 23
Test de autoevaluare 23
Răspunsuri şi comentarii la întrebările din testele de autoevaluare
24
Bibliografie minimală 24
Obiective în termeni de competențe specifice:
La sfârşitul modulului, se va şti: să se definească în mod adecvat conceptele şi principiile specifice teoriei economice;
să se explice şi interpreteze datele și informaţiile din punct de vedere cantitativ şi calitativ pentru formularea de argumente şi decizii concrete;
să se poată explica corect noile concepte;
să se folosească în mod practic instrumentarul economic.
Timp mediu estimat pentru studiu individual: 4 ore
Pentru înțelegerea fenomenelor specifice de natură
statistică, vom opera cu o serie de concepte ce trebuie ca să fie lămurite apriori.
Orice studiu statistic se bazează pe o populație statistică ce reprezintă o mulțime de elemente ce prezintă regularități sub
aspectul naturii lor. Populația statistică trebuie delimitată și evidențiată după conținutul ei (la ce se referă în mod concret) și după situarea ei spațială și temporală (același conținut poate varia de la o zonă la alta sau la diferite perioade de timp). Ca exemplificare, avem conform Anuarului Statistic al României – 20141: “Populația după domiciliu pe vârste, sexe și medii, la 1 iulie
1 Institutul Național de Statistică, Anuarul Statistic al României - 2014, INS, 2015

Cătălin Angelo Ioan Statistică economică
8
2014”, “Veniturile totale ale gospodăriilor din România, în perioada 2010-2013” etc.
Populația statistică poate avea caracter static sau dinamic. Astfel, în primul exemplu de mai sus, colectarea datelor statistice s-a realizat relativ la un moment fixat de timp (1 iulie 2014), pe când, în cel de-al doilea caz, veniturile gospodăriilor au fost înregistrate pe un interval temporal de patru ani. Dacă în cazul static, statistica este descriptivă, în cel de-al doilea caz ea permite elaborarea de prognoze și, implicit, teoriile ce beneficiază de rezultatele ei pot avansa măsuri pentru eventuala îmbunătățire a situației existente.
În cadrul unei populații statistice, se întâlnesc unitățile statistice. Acestea pot fi persoane sau produse ce au aceleași caracteristici și pot fi prelucrate la nivel de agregare.
Cardinalul unei populaţii statistice se numeşte volumul populaţiei. În general, atunci când se efectuează o analiză statistică aceasta
studiază anumite caracteristici comune ale unităţilor statistice, caracteristici care pentru a fi analizate prin intermediul statisticii matematice trebuie cuantificate. Exemplu
Fie populaţia statistică compusă din mulţimea firmelor de comerţ dintr-o regiune. Firma X este o unitate statistică. O caracteristică poate fi de exemplu mărimea capitalului social, o alta rata profitului etc.
În general, informaţiile privind valorile unei caracteristici nu se preiau de la întreaga populaţie (care poate avea un volum foarte mare) în care caz problema s-ar reduce la o simplă numărare, ci se efectuează un sondaj. Acesta constă în alegerea unui eşantion sau a unei selecţii din populaţie al (a) cărui (cărei) volum se numeşte volumul eşantionului (selecţiei).
Variabilele statistice reprezintă criteriile de caracterizare a unităților statistice, ele înregistrând numărul absolut (frecvențe absolute) sau relativ (caz în care se numesc frecvențe relative sau uneori, simplu frecvențe) de unități statistice care satisfac criteriile stabilite. Din punct de vedere al numărului de valori acestea pot fi simple în cazul finit, discrete în cazul infinit, dar numărabil (adică se pot organiza ca șir infinit de valori) și continue în cazul infinit și nenumărabil.
Rezultatele prelucrărilor informațiilor cuprinse în variabile statistice se numesc date statistice al căror suport concret este dat de indicatorii statistici. Aceștia sunt indicatori numerici care permit emiterea de judecăți de valoare asupra fenomenelor, precum și emiterea de prognoze (pe baza modelelor).
În procesul de culegere a datelor, precum și în urma aplicării diferitelor modele apar o serie de erori provenite din cauze diverse (inexactități în activitatea de culegere a datelor, răspunsuri incorecte în cadrul anchetelor sau sondajelor, dar și limitări și simpificări ale modelelor) ce pot conduce la distorsionări ale concluziilor. Erorile generate de aplicarea diverselor modele statistice se numesc erori statistice. De regulă, orice analiză serioasă permite o eroare absolută maximă de 5%.

Cătălin Angelo Ioan Statistică economică
9
1. Modalitatea de desfășurare a observării statistice Orice activitate de natură statistică trebuie, în mod obligatoriu,
precedată de un proces de culegere a datelor. În mod natural, o culegere eronată sau neefectuată pe baze riguros științifice va conduce la concluzii eronate și modele ce nu vor putea fi aplicate cu succes în practică.
Primul lucru, înainte de începerea efectivă a activității de colectare a datelor este acela de a avea definite în mod clar caracteristicile după care se efectuează operațiunea.
De asemenea, în procesul de colectare trebuie avută în vedere autenticitatea informațiilor cu scopul de a diminua, pe cât posibil, erorile de culegere.
Cum, de regulă, colectivitățile sunt de dimensiuni mari, colectarea se face pe eșantioane care trebuie ca să satisfacă condițiile de volum (ce reprezintă numărul unităților statistice care formează populația statistică). Un volum mic al datelor va conduce rareori la concluzii corecte (gândiți-vă de exemplu la un sondaj cu privire la numărul de cărți citite în această lună. Un sondaj efectuat pe cei câțiva cititori ai acestei lucrări va conduce la un procent de 100% a oamenlor ce au citit cel puțin o carte, ceea ce, să recunoaștem, este cam exagerat...). Un volum prea mare al datelor va necesita costuri mari ale campaniei de colectare a acestora, iar efectul va consta, în cel mai bun caz, într-o scădere a marjei de eroare cu unul sau două procente (aici ar trebui făcută o precizare. Orice model, oricât de elaborat ar fi el, nu poate să furnizeze niciodată o prognoză perfectă deoarece există un număr enorm de factori care concură la influențarea lui. Prin urmare, toate concluziile obținute sunt, în limita marjei de eroare, orientative).
Un alt aspect, de asemenea de neneglijat, este cel al completitudinii datelor culese.
În cadrul oricărei activități de observare statistică există mai multe etape ce trebuie parcurse în mod obligatoriu.
Prima dintre acestea se referă la stabilirea scopului observării statistice. Fără un scop bine stabilit și determinat nu se vor putea niciodată selecta acele caracteristici necesare analizei statistice.
O altă etapă constă în stabilirea obiectului observării statistice ce constă în delimitarea colectivității asupra căreia se vor culege datele. Aceasta trebuie să aibă un caracter unitar (în cazul analizelor mari, aceasta se poate eventual subdivide în colectivități mai mici, dar omogene) și să fie în concordanță cu tipul de analiză statistică pe care dorim ca să o efectuăm.
Programul observării statistice conține un set de întrebări ce sunt prezentate adresanților pe formulare statistice și care trebuie să acopere integralitatea caracteristicilor. Întotdeauna, trebuie evitate întrebările ce nu au legătură sau relevanță pentru sondajul statistic sau cele la care răspunsul se poate deduce din celelalte prezente.
În cadrul activității de culegere a datelor de o mare importanță sunt unitățile de observare. Acestea pot fi simple (muncitori, studenți, elevi,

Cătălin Angelo Ioan Statistică economică
10
pensionari etc.) sau complexe (echipe de lucru, secții ale unor întreprinderi, facultăți, școli etc.). În mod natural, stabilirea tipului de unități trebuie făcută în concordanță cu caracteristicile studiate și, de asemenea, cu natura statică sau dinamică a colectivității.
Pe lângă unitățile de observare există, de asemenea, și unitățile raportoare ce reprezintă entități (instituții, firme etc.) ce sunt obligate ca, la anumite perioade determinate de timp, să transmită informații de natură statistică organelor județene sau naționale pentru determinarea stării de fapt a economiei naționale în ansamblul ei.
Un alt aspect ce trebuie avut în vedere este acela al determinării timpului de observare. Acesta se referă la momentul de referință pentru care se culeg datele. Astfel, de exemplu, dacă în Anuarul statistic al României, la data de 1 iulie 2013 exista un număr de 19.983.471 de locuitori, acest fapt înseamnă că la ora 0 a acelei zile toți acești locuitori erau în viață. Dacă un recenzor a ajuns la o anumită adresă la data de 5 iulie 2013, iar pe data de 3 iulie 2013 un membru al familiei respective a decedat el este trecut ca fiind în viață (la ora 0 de pe 1 iulie 2013). De asemenea, dacă un copil s-a născut pe data de 1 iulie la ora 5 el nu va fi întregistrat, deoarece la ora 0 nu se născuse încă. Trebuie deci remarcat că timpul de observare nu are nicio legătură cu timpul la care se efectuează înregistrarea (singura condiție, evidentă, fiind aceea că trebuie să fie anterior înregistrării). În situația datelor dinamice se determină intervalul de timp la care se referă observarea statistică.
De asemenea, trebuie precizat faptul că timpul observării trebuie ca să țină seama de o serie de aspecte privind deplasarea populației, sezonalitatea etc. Astfel, un recensământ al populației efectuat într-o lună de vară nu va putea oferi niciodată informații exacte, foarte mulți locuitori fiind plecați în concedii, deci neputând furniza informații. În mod analog, analiza vânzărilor unei firme comerciale nu va fi niciodată edificatoare dacă ea va fi efectuată în perioada premergătoare sărbătorilor de iarnă.
După stabilirea timpului observării trebuie determinat și locul acesteia. De regulă, locul observării trebuie ca să fie în același loc cu cel al unităților de observare și al producerii fenomenelor investigate. De asemenea, în cadrul analizelor ample, la nivel național, el trebuie ca să aibă în vedere o distribuție uniformă a subiecților supuși chestionarelor. O analiză a dotării populației cu smartphone-uri efectuată în centrul capitalei, chiar dacă ea se va încadra în limitele de volum, nu va oferi niciodată informații relevante la nivel național. De asemenea, o analiză a nivelului de pasiune pentru obiectul “Statistică” nu va da răspunsuri concludente dacă ea se va desfășura în afara celor ce citesc acum această lucrare...
După stabilirea tuturor acestor condiții se trece la întocmirea formularelor statistice și a instrucțiunilor de completare a acestora. De regulă, formularele statistice sunt fie de tip fișă (în care există mai multe întrebări adresate unei singure unități de observare – cum este, de exemplu, cazul

Cătălin Angelo Ioan Statistică economică
11
recensămintelor), fie de tip listă atunci când acestea se adresează unor colectivități numeroase și conțin un număr mai redus de întrebări.
Un alt aspect al observării statistice este acela al determinării metodei concrete de observare. Astfel, după gradul de cuprindere2 există observarea
totală (recensăminte sau rapoarte statistice) ce presupune analiza tuturor elementelor colectivității și observarea parțială care colectează date numai dintr-o parte reprezentativă (în mod necesar) a acesteia.
Dintr-un alt punct de vedere, observarea poate fi statistică atunci când ea se referă la un moment fixat de timp și dinamică atunci când are ca obiect o perioadă determinată de timp.
Relativ la periodicitatea observării aceasta poate fi curentă (în situația în care permanent se colectează informații), periodică (atunci când informația este preluată la intervale bine specificate de timp) și unică (atunci când sondajul se efectuează în situații speciale, răspunzând unor nevoi de moment).
Ca și metode de observare statistică putem enunța, mai întâi, ancheta
statistică ce nu satisface, de obicei, normele de reprezentativitate. În general, această metodă de observare se organizează pentru a obține răspunsuri punctuale cum ar fi: opinia unor consumatori privind o anumită firmă (produse, ambient, modalitate de servire etc.), chestionarea opiniei publice relativ la o anumită manifestare etc.
O altă metodă importantă este cea a recensământului. Acesta are caracterul unei observări periodice având drept scop determinarea mutațiilor populației relativ la o serie de indicatori.
Rapoartele statistice se prezintă ca informații culese de la agenți economici, având o periodicitate de culegere stabilită prin lege și sunt destinate fie informării guvernamentale (pentru adaptarea politicilor macroeconomice la realitatea zilnică), fie informării populației.
Sondajul statistic are caracter de observare parțială și se referă la analize generale în care nu este rentabilă consultarea tutror membrilor colectivității, rezultatele având incluse o marjă de eroare acceptată (de regulă 3-5%).
2. Teoria erorilor în cadrul observării statistice În cadrul observării și al prelucrării statistice își fac prezența o serie de
erori. Înainte de a prezenta tipurile de erori specifice observării statistice,
vom trece în revistă câteva noțiuni generale3. Fie deci x valoarea reală a unei mărimi și x - valoarea aproximativă
(obținută prin măsurare).
2Biji E.M., Lilea E., Roșca E., Vătui M., Statistică pentru economiști, Editura Economică, București, 2010
3 Dorn W.S., McCracken D.D., Metode numerice cu programe în Fortran IV, Ed. tehnică, București, 1976

Cătălin Angelo Ioan Statistică economică
12
Definiție
Se numește eroare absolută diferența dintre valoarea reală și cea aproximativă:
ex=x- x Definiție
Se numește eroare relativă raportul dintre eroarea absolută și valoarea reală:
εx=x
ex =x
xx −=
x
x1−
Cum însă valoarea reală a unei mărimi nu este cunoscută (altfel nu ar avea prea mare sens ca să vorbim despre erori, exceptând situația în care se vorbește despre determinarea preciziei de măsurare a unui instrument) vom prefera următoarea: Definiție
Se numește eroare relativă raportul dintre eroarea absolută și valoarea aproximativă:
εx=x
ex =x
xx −= 1
x
x−
Uneori, se mai folosește și eroarea procentuală, care nu este însă altceva decât eroarea relativă exprimată în procente, adică:
xx 100% ε=ε
Exemplu Să considerăm o cameră cu lungimea x=5,15 m. Dacă o vom măsura cu
ajutorul unei bare de lemn, negradată, de lungime 1 m, vom obține lungimea
aproximativă x =5 m. Prin urmare: ex=5,15-5=0,15 m, iar εx=5
15,0=0,03.
Eroarea procentuală este %xε =3.
Observație Dacă eroarea absolută are aceeași unitate de măsură ca și fenomenul studiat, cea relativă este adimensională. În aplicațiile practice, se stabilește apriori un nivel maxim pozitiv admis al erorii absolute (sau al erorii relative). Astfel, dacă emax este nivelul
maxim acceptat pentru eroarea absolută va trebui ca xe ≤emax de unde:
maxexx ≤− sau altfel:
maxmax exxex +≤≤−
În cazul erorii relative, dacă εmax este maximul acesteia, avem:
xε ≤εmax deci: max1x
xε≤− . În final:
( ) ( )x1xx1 maxmax ε+≤≤ε−
Relativ la propagarea erorilor la operațiile aritmetice, avem pentru două valori x și y ale căror aproximații sunt x și y :
Propagarea erorilor la adunarea numerelor

Cătălin Angelo Ioan Statistică economică
13
( ) yxyx eeyxeyexyx +++=+++=+
de unde:
( ) yxyx eeyxyxe +=+−+=+
În situația în care pragul admis este emax avem:
maxmaxmaxyxyxyx e2eeeeeee =+≤+≤+=+ . Ca urmare a acestui lucru,
pentru obținerea unui rezultat în limitele erorii maxime admise, cei doi termeni ai adunării trebuie ca să aibă o eroare maximă mai mică sau egală cu jumătate din cea a rezultatului. În cazul erorii relative, avem:
yxyxyxyx
yx yx
y
yx
x
yx
yx
yx
ee
yx
eε
++ε
+=
+
ε+ε=
+
+=
+=ε
+
+
Propagarea erorilor la scăderea numerelor
( ) yxyx eeyxeyexyx −+−=−−+=−
de unde:
( ) yxyx eeyxyxe −=−−−=−
În situația în care pragul admis este emax avem:
maxmaxmaxyxyxyx e2eeeeeee =+≤+≤−=− . Ca urmare a acestui lucru,
pentru obținerea unui rezultat în limitele erorii maxime admise, cei doi termeni ai scăderii trebuie ca să aibă (ca și în cazul adunării) o eroare maximă mai mică sau egală cu jumătate din cea a rezultatului.
În cazul erorii relative, avem:
yxyxyxyx
yx yx
y
yx
x
yx
yx
yx
ee
yx
eε
−−ε
−=
−
ε−ε=
−
−=
−=ε
−
−
Propagarea erorilor la înmulțirea numerelor
( )( ) yxxyyx eeeyexyxeyexxy +++=++=
Dacă vom neglija produsul erorilor ex și ey (în situația în care sunt mult mai mici decât valorile aproximative ale lui x, respectiv y) obținem:
xyxy eyexyxxye +=−=
În situația în care pragul admis este emax avem:
=+≤+=+≤+= maxmaxxyxyxyxy eyexeyexeyexeyexe
( ) maxeyx + .
În cazul erorii relative, avem:
yxxyxyxy
xy yx
xyyx
yx
eyex
yx
eε+ε=
ε+ε=
+==ε
Propagarea erorilor la împărțirea numerelor
y
e1
1
y
ex
ey
y
y
ex
ey
ex
y
x
y
x
y
x
y
x
+
+=
+
+=
+
+=

Cătălin Angelo Ioan Statistică economică
14
Considerând funcția ( )t1
1tf
+= avem: ( )
( )2t1
1t'f
+−= ,
( )( )3t1
2t"f
+= , ( )
( )4t1
6t'"f
+−= etc. de unde: ( ) 10f = , ( ) 10'f −= , ( ) 20"f = ,
( ) 60'"f −= etc. Dezvoltarea în serie MacLaurin
( ) ( ) ( ) ( ) ( )
++++= ...t
!3
0'"ft
!2
0"ft
!1
0'f0ftf 32 a lui f este deci:
...ttt1t1
1 32 +−+−=+
(convergentă pentru t∈(-1,1)). Revenind, pentru
t=y
ey avem: ...y
e
y
e
y
e1
y
e1
13
3y
2
2yy
y
+−+−=
+
Eliminând termenii ce conțin puteri
ale lui ey superioare lui 1, obținem: y
ey
y
e1
y
e1
1 yy
y
−=−=
+
. Revenind, avem:
2
yxxyyx
y
eeeyexyx
y
ey
y
ex
y
x −+−=
−+=
Eliminând din nou produsul erorilor absolute exey obținem:
xy22
xy ey
1e
y
x
y
x
y
eyexyx
y
x+−=
+−=
de unde:
y2x
y
x ey
xe
y
1e −=
În situația în care pragul admis este emax avem:
≤+=+≤−= y2xy2xy2x
y
x ey
xe
y
1e
y
xe
y
1e
y
xe
y
1e
max2max2max ey
yxe
y
xe
y
1 +=+ .
În cazul erorii relative, avem:
yx
yxy2xy
x
y
x
y
x
yy
x
y
x
y
x
ey
xe
y
1
y
x
e
ε−ε=
ε−ε
=
−
==ε
Revenind, eroarea de observare se referă la abaterea dintre datele înregistrate și cele reale. Acestea pot apare din diverse cauze: răspunsuri nesincere la sondaje, erori de înregistrare din necunoașterea exactă a modalității de completare a chestionarelor statistice etc.
Erorile de reprezentativitate apar în cadrul observațiilor parțiale atunci când fie eșantionul ales nu satisface întocmai condițiile respective

Cătălin Angelo Ioan Statistică economică
15
În fine, erorile de modelare statistică apar în cadrul prelucrării statistice fie din cauza erorilor mașinilor de calcul, fie din cauza adoptării unor modele insuficient elaborate.
3. Metode de prezentare și prelucrare primară a datelor
Cercetările efectuate în cadrul observațiilor statistice se concretizează
într-un număr, de regulă, foarte mare de date, aparent haotice, ce nu permit, în general, evidențierea aspectelor specifice fenomenelor și nu facilitează obținerea de informații utile ulterioare analizei statistice.
Înainte de a obține informații relevante despre procesul studiat sau a concepe modele ce vor permite efectuarea de predicții, datele vor trebui sistematizate în mod științific.
Primul pas în cadrul abordării statistice a unui fenomen este deci cel de sistematizare a datelor observate. Aceasta presupune o operație de centralizare a datelor, precum și obținerea unor agregări ale acestora. Ca și forme de prezentare a datelor sau rezultatelor statistice se folosesc fie tabele statistice, fie reprezentări grafice sugestive ale acestora.
Sarcina de lucru 1
Fie x și y două mărimi ale căror valori reale sunt: x=2,47 și y=3,79, cele măsurate fiind x =2,46, respectiv y =3,81. Să se determine erorile
absolute și cele relative pentru: a) x+y; b) x-y; c) xy;
d) y
x
Cătălin Angelo Ioan Statistică economică
16
De regulă, în acțiunea de tabelare sau de prelucrare a datelor, acestea trebuie în prealabil codificate pentru a nu încărca inutil procesele specifice.
Să considerăm, astfel, un număr de n variabile ce vor descrie fenomenul studiat: V1,...,Vn și N unități de observare. Un tabel de centralizare a datelor statistice poate avea următorul aspect:
Nr.crt. Variabile
V1 ...
Vn
1 v11 v1n
... ... ...
...
k vk1 ...
vkn
... ... ...
...
N vN1 ...
vNn
TOTAL ∑=
N
1kkv
... ∑
=
N
1kknv
În tabel, pe coloane sunt trecute variabilele ce compun datele primare, iar pe linii numărul curent al unității de observare. Elementul vij reprezintă valoarea variabilei j corespunzătoare unității de observare i. Exemplu
Să considerăm situația vânzărilor unui anumit produs în bucăți, respectiv în valoare bănească pe zile pentru o anumită firmă. Notând cu V1 – bucățile de produs, cu V2 – valoarea acestora, iar la numărul curent – numărul zilei de observație, avem (date imaginare):
Nr.crt. Variabile
V1 V2
1 20 400
2 32 640
3 18 360
4 27 540
5 35 700
TOTAL 132 2640 De asemenea, în tabelele centralizatoare pot apărea și o serie de variabile derivate ce pot contribui la obținerea de informații relevante pentru studiul efectuat. În scopul de a omogeniza datele statistice, dar și de a elimina uneori informații ce nu sunt neapărat relevante pentru studiul respectiv, se folosește metoda grupării datelor statistice. Noțiunea de grupare reprezintă o separare a datelor pe grupuri ce sunt caracterizate prin omogenitate, la nivelul fie a variațiilor minime de la un

Cătălin Angelo Ioan Statistică economică
17
indicator numeric, fie la nivelul abaterilor minime de la o caracteristică dominantă.
Există astfel, mai multe tipuri de grupări4. Grupările cronologice presupun drept caracteristică timpul. Un exemplu edificator ar fi situația vânzărilor unei firme pe luni (ce ar elimina, măcar parțial, influențele cauzate de anumite zile nelucrătoare).
Grupările teritoriale au drept caracteristică situarea geografică a caracteristicii studiate.
Grupările după valorile unei variabile numerice se realizează încadrând valorile variabilei în anumite intervale ce presupun o determinare apriori a unei amplitudini rezonabile. Conform formulei lui Sturges5, numărul optim al intervalelor de date este
mint=
+
−
Nlog1
vv
2
minmax =
+
−
Nlg3219,31
vv minmax =
+
−
Nln4427,11
vv minmax unde [a] reprezintă
partea întreagă a lui a∈R.
Dacă vom nota StN=Nln4427,11
1
+, avem: mint= ( )[ ]minmaxN vvSt − .
Valorile lui StN corespunzătoare lui 2≤N≤249 sunt date în anexa nr.1.
Intervalele de date sunt fie de forma [x1,x2)∪[x2,x3)∪...∪ [xk,xk+1] în care limita inferioară a fiecăruia (exceptându-l pe primul) este egală cu limita superioară a predecesorului lui, fie de forma intervalelor diferențiate cu o
unitate: [x1,x2]∪[x2+1,x3]∪...∪ [xk+1,xk+1].
Dacă intervalele au lungimi egale, atunci xp=vmin+(p-1)⋅ int
minmax
m
vv −,
p= 1k,1 + .
Exemplu
Să considerăm situația vânzărilor unui anumit produs în bucăți (date imaginare):
Nr.crt. Vânzare
(lei) 1 20
2 32
3 18
4 27
5 35
6 24
4 Biji E.M., Lilea E., Roșca E., Vătui M., Statistică pentru economiști, Editura Economică,
București, 2010 5 Scott D.W., Sturge’s Rule, Wiley Interdisciplinary Reviews: Computational Statistics, 2009, pp.303-306
Cătălin Angelo Ioan Statistică economică
18
7 18
8 17
9 34
10 28
TOTAL 132 Cum vmax=35, vmin=17, iar N=10, din anexa nr.1 avem:
mint= ( )[ ]17350,231378 −⋅ =[4,1648]=4 intervale. Deoarece vmax-vmin=18, avem
int
minmax
m
vv −=
4
18=4,5, de unde: x1=17, x2=17+4,5=21,5, x3=17+2⋅4,5=26,
x4=17+3⋅4,5=30,5, x5=17+4⋅4,5=35. Tabelul grupărilor de date devine:
Grupa de vânzări
Număr absolut
[17;21,5) 4 [21,5;26) 1 [26;30,5) 2 [30,5;35] 3
Trebuie remarcat aici că metoda grupării se aplică diferențiat în funcție de specificul datelor numerice. Astfel, dacă amplitudinea datelor este mică (vmax-vmin) gruparea se realizează direct pe variantele respective, intervalele devenind nesemnificative. Exemplu
Numărul mediu de persoane pe o cameră, după mărimea gospodăriei în anul 2005
Mărimea gospodăriei Număr persoane
1 persoană 0,44 2 persoane 0,77 3 persoane 1,09 4 persoane 1,37 5 persoane 1,53
6 persoane și peste 1,95
TOTAL 1,07 Sursa: http://statistici.insse.ro/
În situația în care amplitudinea datelor este medie, gruparea se realizează pe intervale de lungimi egale. Dacă amplitudinea datelor este mare, gruparea se realizează pe intervale de lungimi inegale. Astfel, inițial se procedează la o împărțire în intervale egale, după care acestea se reunesc în funcție de alte caracteristici pentru a oferi o omogenitate mai mare a rezultatelor. Un alt tip de grupare a datelor este cea combinată. O astfel de grupare se practică în momentul în care există mai multe caracteristici. Gruparea se realizează, mai întâi, după caracteristica dominantă, cauzală, după care datele

Cătălin Angelo Ioan Statistică economică
19
se subdivid după cea de a doua caracteristică etc. Datele obținute se prezintă sub forma unui tabel de contingență. În exemplele de mai sus, am văzut deja câteva modalități de prezentare a datelor statistice. Cea mai frecventă metodă este cea a tabelelor statistice. Acestea au o structură matriceală ce trebuie să satisfacă unor condiții absolut obligatorii. Astfel, mai întâi trebuie specificat subiectul tabelului ce se referă la colectivitatea la care fac referință datele prezentate (de exemplu, în tabelul nr.9 – “Născuţii - vii după grupa de vârstă a părinţilor în anul 2013”). Sistemul de caracteristici prezente în analiza statistică constituie predicatul
tabelului (de exemplu, în tabelul nr.9 – “Grupa de vârstă a mamei (ani)” și “Grupa de vârstă a tatălui (ani)”). Macheta tabelului este reprezentată de structura acestuia pe linii și coloane, precum și titlurile interioare ale acestuia (de exemplu, în tabelul nr.9 liniile și coloanele – “TOTAL”, “Sub 15”, “15-19” etc.).
În situația în care este nevoie de acest lucru, tabelele pot fi însoțite de note explicative cum ar fi anumite aspecte ale datelor (de exemplu, atunci când unele date se referă la alte perioade de timp – cazul situațiilor privind populația unei anumite țări atunci când recensământul este de dată mai veche) sau sursele de informații (de exemplu, sub tabelul nr.9 – “Institutul Național de Statistică, Anuarul Statistic al României - 2014, INS, 2015”).
O altă metodă de prezentare a datelor este cea a seriilor statistice. O astfel de serie reprezintă o relație funcțională dintre două serii de date. Ele se pot prezenta fie tabelat, fie sub formă matriceală.
Dacă natura caracteristicii este cantitativă, seriile se numesc de
distribuție. Cele mai frecvente serii de date sunt cele cronologice. Acestea prezintă
variația unei anumite caracteristici în funcție de timp. Ca și în cazul tabelelor, seriile cronologice se pot raporta la momente fixe de timp sau la intervale temporale. Seriile teritoriale au ca obiect variația teritorială a caracteristicii respective. Pentru a fi edificatoare și a putea fi corelate cu alte statistici, unitățile teritoriale folosite trebuie să se ralieze la cadrul general administrativ al țării, continentului, întregii planete. Vă dați seama, ce haos s-ar crea dacă într-o situație internațională, unele țări ar raporta date la nivel național, iar altele la nivel de regiuni, județe etc.! Seriile descriptive prezintă datele în funcție de categoriile unei anumite caracteristici.

Cătălin Angelo Ioan Statistică economică
20
4. Reprezentarea grafică a datelor statistice “O imagine valorează cât o mie de cuvinte” afirmă un binecunoscut
proverb chinezesc. De multe ori, anterior prelucrării datelor statistice este utilă vizualizarea datelor într-un mod cât mai edificator, dar și atractiv. De asemenea, în cadrul demersului de popularizare a rezultatelor cercetărilor statistice adresate publicului larg, dar nu numai, este utilă o prezentare grafică
Sarcina de lucru 2
Să considerăm situația vânzărilor unui anumit produs în bucăți:
Nr.crt. Vânzare
(lei) 1 24
2 74
3 100
4 92
5 73
6 83
7 96
8 61
9 81
10 34
TOTAL 718 Să se întocmească tabelul corespunzător Grupărilor după valorile vânzărilor produsului.

Cătălin Angelo Ioan Statistică economică
21
a datelor și a rezultatelor ce are ca scop eliberarea informației transmise de aspecte tehnice ce pot avea drept rezultat încâlcirea scopului final.
Reprezentarea grafică a datelor trebuie să se facă în mod precis și cât mai edificator. Ea are la bază un sistem precis de regului atât referitoare la forma de reprezentare, cât și la conținutul propriu-zis al graficelor.
Primul aspect al unui grafic este alegerea unui titlu edificator pentru conținutul acestuia și care să ofere informații cât mai precise despre conținutul propriu-zis al acestuia.
Stabilirea axelor de coordonate este esențială. Pe axa orizontală (axa Ox) se trasează fie valorile, fie intervalele de variație ale variabilei independente. Pe axa verticală (axa Oy) se punctează valorile caracteristicii avute în vedere (valori absolute, frecvențe etc.). Pentru o înțelegere corectă a unui grafic este recomandată etichetarea axelor de coordonate în sensul explicitării conținutului acestora. Astfel, dacă variabila independentă este, de exemplu, “anul” vom scrie acest lucru în dreptul axei orizontale, nescriind “axa Ox” sau, mai rău, neprecizând nimic. Acest lucru se va realiza și în legătură cu axa Oy. Originea axelor de coordonate se stabilește, de regulă, în funcție de natura (pozitivă sau negativă) datelor. Astfel, dacă datele toate sunt pozitive (de exemplu, un grafic ce reprezintă numărul de salariați al unei întreprinderi pe ani calendaristici) vom reprezenta numai cadranul I, cu originea în stânga-jos.
Rețeaua graficului reprezintă, de regulă, liniile de coordonate, menite ca să faciliteze citirea rezultatelor. În anumite tipuri de grafice (de exemplu, în cazul celor polare) se pot întâlni rețele de tip circular. Un aspect deosebit de important este cel al scării graficului. Astfel, unitățile de măsură pe axe pot fi diferite în funcție de amplitudinea și ordinul de mărime al acestora. În mod evident dacă vom reprezenta evoluția PIB-ului României pe o perioadă de timp, nu vom putea alege aceeași unitate de măsură pentru ani și pentru valoarea acestuia în lei. De asemenea, atunci când valorile sunt foarte mari sau foarte mici este indicată o scalare a acestora în sensul împărțirii sau înmulțirii cu un factor rezonabil astfel încât reprezentarea grafică să fie cât mai îngrijită.
Legenda graficului reprezintă un aspect esențial atunci când sunt reprezentate mai multe seturi de date pe același grafic. Este recomandat ca în cazul graficelor cu multe seturi de date, culorile alese pentru diverse seturi să fie cât mai variate pentru a nu crea confuzie.
Notele explicative ale unui grafic se trec în partea de jos a acestuia dacă este cazul.
Un ultim aspect, dar deloc neesențial, este acela al precizării sursei datelor atunci când ele nu au caracter de originalitate (din privința autorului). Este adevărat, în mod evident, că dacă sursa datelor este prevăzută în textul ce însoțește graficul atunci nu mai este necesar ca să se specifice încă odată acest lucru.

Cătălin Angelo Ioan Statistică economică
22
În cele ce urmează, vom prezenta principalele tipuri de grafice. Graficele liniare se reprezintă prin trasarea unei curbe frânte ce unește seturile consecutive de date. Ele se folosesc, de regulă, la reprezentarea fenomenelor temporale pentru a urmări evoluția fenomenului de la un moment la altul.
În cazul mai multor seturi de date, acestea se pot reprezenta pe același grafic având culori diferite. Dacă intervalele de variație corespunzătoare mai multor seturi de date sunt foarte decalate, se pot folosi două axe ordonate plasate una în stânga, iar cealaltă în dreapta.
Graficele prin benzi sau coloane se reprezintă sub forma unor dreptunghiuri orizontale sau verticale. Ca și în cazul graficelor liniare ele se folosesc, de regulă, în urmărirea evoluției fenomenelor temporale. Chiar dacă sunt mai atractive și mai ușor de vizualizat, apreciem că evoluția fenomenului este mai bine pusă în evidență în cazul graficelor liniare. Uneori, pentru o lizibilitate mai bună a graficelor, se recomandă trecerea valorii variabilei în partea de sus a coloanelor sau în partea laterală a barelor. În cazul mai multor seturi de date se pot folosi graficele cu coloane sau benzi grupate. Acestea se pot grupa fie, de exemplu, după anul calendaristic, fie după caracteristica studiată. Un alt mod de reprezentare grafică a datelor este cel prin figuri
geometrice (pătrate, cercuri, dreptunghiuri etc.) În acest caz, suprafața figurilor geometrice este proporțională cu mărimea absolută a caracteristicii studiate. Astfel, în cazul pătratelor se va
determina latura pătratului prin formula valoare , iar în cazul cercurilor, raza
va fi: π
valoare.
Graficele de tip plăcintă (pie - engl.) se folosesc în situația în care se dorește evidențierea părților componente ale unui întreg (și numai atunci!). Graficul are aspectul unui disc (interiorul unui cerc) descompus în sectoare ale căror suprafață este proporțională cu ponderea fenomenului în total. Graficele de tip radar se utilizează, de regulă, în analiza variației periodice (zilnice, lunare, trimestriale etc.) a unei caracteristici. Se trasează o serie de linii de nivel de formă pătrată, după care, pe o serie de axe, egal distanțate unghiular se marchează valorile caracteristicii unite ulterior prin segmente de dreaptă. Histogramele reprezintă graficele unei distribuții de frecvențe. Considerând un set de date și distribuția acestora (obținută prin numărarea valorilor corespunzătoare unui indicator) de forma:
V=
k321
k321
n...nnn
v...vvv, histograma reprezintă graficul cu bare
corespunzător perechilor de puncte (vi,ni), i= k,1 .
În situația în care numărul de valori absolute este foarte mare se procedează la descompunerea intervalului de variație [vmin,vmax] în n intervale

Cătălin Angelo Ioan Statistică economică
23
de lungimi egale (se recomandă ca acesta să fie proporțional cu log2N= lnN1,44 ⋅ unde N este numărul de date).
Intervalele se determină prin calcularea mai întâi a lungimii acestora
h=n
vv minmax − și apoi, pentru intervalul “i” limitele acestuia vor fi: [vmin+(i-
1)⋅h,vmin+i⋅h), i= 1n,1 − . Valorile absolute ale caracteristicii corespunzătoare se
obțin prin însumarea acelora care “cad” în intervalul [vmin+(i-1)⋅h,vmin+i⋅h) (cu excepția ultimului interval care este închis la dreapta).
Poligonul frecvențelor se obține cu aceleași considerații de mai sus, dar are forma unui grafic liniar obținut prin unirea coordonatelor respective. În situația în care seria este cu intervale egale, pentru trasarea poligonului frecvențelor se alege centrul fiecărui interval. Dacă intervalele nu sunt egale, atunci se vor pondera datele în raport cu mărimea intervalelor. Astfel, dacă intervalul cel mai mic are lungimea lmin, pentru un interval de lungime “lung”, datele se vor înmulți cu coeficientul:
lung
lmic după care se va trasa poligonul frecvențelor cu noile valori.
Considerând frecvențele cumulate se obține, în mod analog, poligonul
frecvenţelor cumulate (ogiva). Graficele de tip împrăștiere (scatter - engl.) sunt utile la investigarea
posibilelor dependențe dintre două seturi de date statistice. Ele se realizează prin reprezentarea perechilor de valori într-un sistem cartezian de axe.
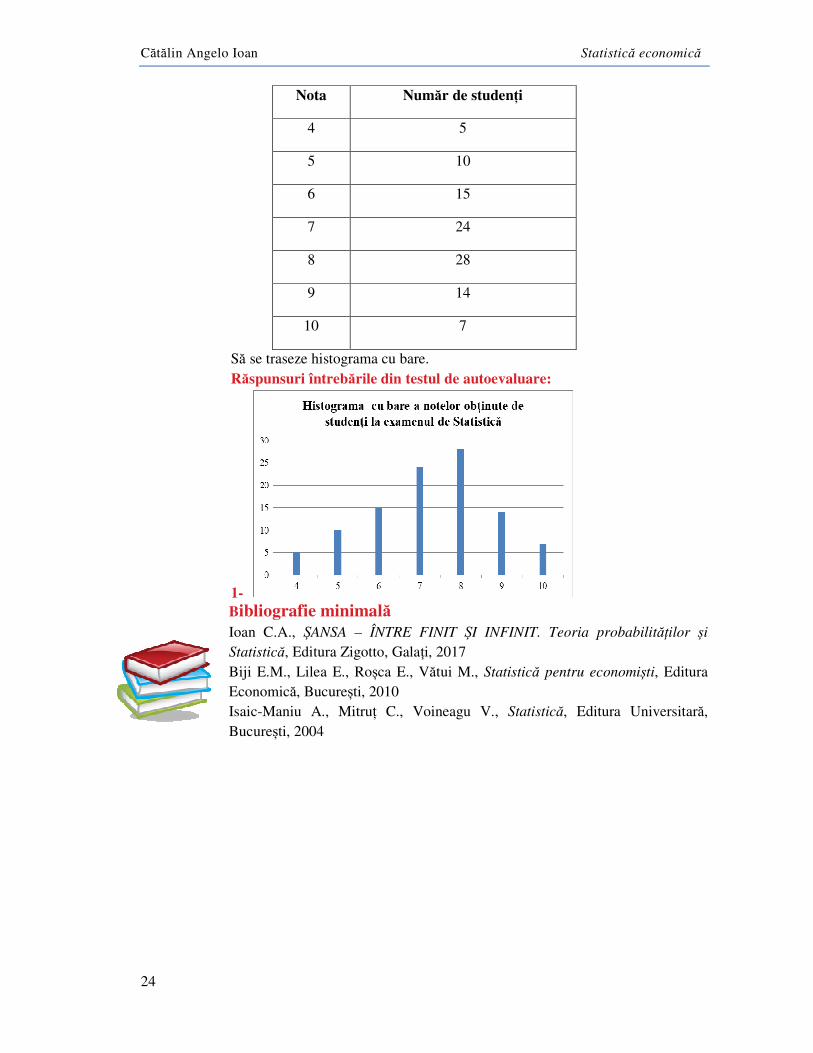
Test de autoevaluare I. Se consideră Situația notelor obținute de studenți la examenul de Statistică (pur ipotetic):
Rezumat Variabilele statistice reprezintă criteriile de caracterizare a unităților
statistice, ele înregistrând numărul absolut (frecvențe absolute) sau relativ (caz în care se numesc frecvențe relative sau uneori, simplu frecvențe) de unități statistice care satisfac criteriile stabilite. Din punct de vedere al numărului de valori acestea pot fi simple în cazul finit, discrete în cazul infinit, dar numărabil (adică se pot organiza ca șir infinit de valori) și continue în cazul infinit și nenumărabil.
Rezultatele prelucrărilor informațiilor cuprinse în variabile statistice se numesc date statistice al căror suport concret este dat de indicatorii statistici. Aceștia sunt indicatori numerici care permit emiterea de judecăți de valoare asupra fenomenelor, precum și emiterea de prognoze (pe baza modelelor).
Cătălin Angelo Ioan Statistică economică
24
Nota Număr de studenți
4 5
5 10
6 15
7 24
8 28
9 14
10 7
Să se traseze histograma cu bare. Răspunsuri întrebările din testul de autoevaluare:
1- Bibliografie minimală Ioan C.A., ȘANSA – ÎNTRE FINIT ȘI INFINIT. Teoria probabilităților și Statistică, Editura Zigotto, Galați, 2017 Biji E.M., Lilea E., Roșca E., Vătui M., Statistică pentru economiști, Editura Economică, București, 2010 Isaic-Maniu A., Mitruț C., Voineagu V., Statistică, Editura Universitară, București, 2004

Cătălin Angelo Ioan Statistică economică
25
2. INDICATORII STATISTICI. OPERAȚII CU VARIABILE STATISTICE
Indicatorii statistici. Operații cu variabile statistice 25 Rezumat 33
Test de autoevaluare 34
Răspunsuri şi comentarii la întrebările din testele de autoevaluare
35
Bibliografie minimală 37
Obiective în termeni de competențe specifice:
La sfârşitul modulului, se va şti: Modul de calcul al indicatorilor derivați
Modul de calcul al indicatorilor relativi
Timp mediu estimat pentru studiu individual: 2 ore
Indicatorii statistici reprezintă expresii numerice obținute
în urma unui proces de cercetare.
Pentru a-și realiza menirea, indicatorii statistici trebuie ca să îndeplinească, în mod cumulativ, o serie de funcții.
Astfel, prima funcție esențială este cea de măsurare a fenomenului studiat. Statistica, fiind, prin excelență, o disciplină numerică, nu poate opera decât cu mărimi cuantificabile. Astfel, în cadrul analizei statistice primul lucru care trebuie făcut este acela de a alege acele caracteristici ce pot fi măsurate în mod concret.
Compararea datelor este esențială atunci când se dorește efectuarea de predicții asupra fenomenelor. Astfel, datele pot fi comparate la nivel absolut, dar numai dacă sunt exprimate în aceeași unitate de măsură (ca exemplu imediat având veniturile și cheltuielile unei unități productive) sau la nivel relativ atunci când se determină raportul dintre valorile unui același indicator la două momente de timp.

Cătălin Angelo Ioan Statistică economică
26
Funcția de analiză a datelor are drept scop fie eliminarea valorilor aberante (cazul, de exemplu, al analizei vânzărilor unei firme comerciale în primele zile după deschiderea ei), fie corelarea părților cu întregul atunci când agregarea unor părți ale unui indicator totalizator (preluat din diferite surse) generează diferențe semnificative.
Sinteza datelor statistice are drept scop obținerea de indicatori relevanți pentru colectivitate atât la nivel orizontal, cât și vertical (agregări sau mărimi medii).
Cea mai importantă funcție este însă ea de estimare. O statistică pur descriptivă, neînsoțită de predicții asupra fenomenului, este, de multe ori, pur contemplativă. Estimarea valorilor viitoare ale unui fenomen permite adaptarea politicilor sau strategiilor economice orientate spre realizarea dezideratului. Estimările se pot face fie la nivel individual (pentru fiecare caracteristică în parte), fie la nivel colectiv, atunci când se construiesc funcții complexe pe baza caracteristicilor studiate.
O ultimă funcție, ulterioară celei de estimare este cea de verificare a
ipotezelor statistice și de testare a semnificației rezultatelor. În elaborarea de predicții statistice intră o serie de fenomene măsurabile. Nu întotdeauna însă aceste caracteristici sunt esențiale pentru fenomenul analizat sau, uneori, conțin date concludente pentru acesta. Pentru acest lucru, în statistică (ca și în teoria probabilităților) există o serie de indicatori numerici ce oferă informații despre influența fiecărei caracteristici în parte la descrierea cu acuratețe a fenomenului în sine. De asemenea, orice estimare statistică este valabilă în limitele unei probabilități, izvorâtă din cauze variate (acuratețea datelor culese, limitele modelului etc.), deci rezultatele obținute nu vor oferi cu precizie informații despre comportarea viitoare a unui fenomen, ci intervale în care se vor găsi valorile acestuia (mai mici sau mai mari în funcție de precizia dorită a estimării).
În funcție de momentul în care apar, indicatorii statistici e împart în două categorii: primari și derivați.
Indicatorii primari, după cum le arată și denumirea, se obțin în faza inițială a prelucrărilor statistice. Chiar dacă uneori pot fi considerați drept indicatori primari și cei obținuți direct în urma procesului de culegere sau observare (de exemplu, numărul studenților pentru fiecare specializare din cadrul unei facultăți), de cele mai multe ori ei prezintă valori agregate (obținute din însumarea valorilor comparabile, caracteristice unui anumit fenomen). Astfel, numărul studenților unei anumite facultăți se obține prin însumarea tuturor ce formează diversele specializări. De asemenea, Produsul Intern Brut (prin metoda cheltuielilor) se obține prin însumarea componentelor sale (PIB= Consumul final efectiv+ Formarea brută de capital fix+ Variaţia stocurilor+ Exportul net – vezi tabelul nr.21).
Cătălin Angelo Ioan Statistică economică
27
Indicatorii derivați se obțin, în marea majoritate a cazurilor, prin aplicarea unor modele estimative sau de prognoză. Acești indicatori se pot exprima fie prin relații de natură cantitativă între caracteristicile constitutive ale fenomenului analizat, fie prin variabile ce exprimă gradul de interdependență a variabilelor. Ca și exprimare valorică, indicatorii derivați se pot prezenta fie sub formă absolută (diferență dintre două valori), fie relativă (raport a două valori), fie de tip medie, de tip indici etc.
Indicatorii relativi se prezintă sub forma unui raport între doi indicatori absoluți. Dacă numărătorul raportului poartă numele de indicator raportat, numitorul acestuia se numește bază de raportare. În mod evident, în construcția unui indicator relativ, cei doi termeni ai raportului trebuie să fie coerenți unul în raport cu celălalt, adică să existe o legătură logică de condiționalitate între ei, fiecare fiind semnificativ pentru fenomenul studiat. Astfel, de exemplu, productivitatea muncii este reprezentată de raportul dintre numărul de piese (bucăți etc.) produse și intervalul de timp alocat. Nu va fi un indicator relativ, de exemplu, raportul dintre numărul de piese și numărul pesonalului neproductiv dintr-o întreprindere!
Indicatorii relativi de structură sunt utilizați în analiza structurii diferitelor colectivități statistice6. Considerând un tabel statistic de forma:
Grupa Variabile
V1 ... Vp
1 n11 n1p
... ... ... ...
k nk1 ... nkp
... ... ... ...
N nN1 ... nNp
TOTAL ∑=
N
1k
1kn ...
∑=
N
1kkpn
un prim indicator ce se calculează este frecvența relativă a aparițiilor absolute ale unei grupe în totalul acestora pentru fiecare variabilă în parte. Avem deci:
∑=
=N
1kks
kss,k
n
nf , k= N,1 , s= p,1
6 Isaic-Maniu A., Mitruț C., Voineagu V., Statistică, Editura Universitară, București, 2004

Cătălin Angelo Ioan Statistică economică
28
unde s,kf - frecvența relativă a grupei k corespunzător variabilei s, nks –
numărul de unități absolute (frecvența absolută) din grupa k corespunzător variabilei s, iar suma de la numitor - suma valorilor de pe coloana s corespunzătoare variabilei respective. Dacă valorile absolute din tabel reprezintă agregări provenite dintr-un tabel de observații atunci nks se înlocuiește cu suma valorilor corespunzătoare.
Frecvența relativă procentuală se obține prin înmulțirea cu 100 a frecvenței relative. Avem deci:
s,ks,k f100%f ⋅=
Din cele de mai sus, rezultă: 1
n
nf
N
1kks
N
1kksN
1ks,k ==
∑
∑∑
=
=
=
, 100%fN
1ks,k =∑
=
.
Reprezentarea grafică a frecvențelor relative se poate realiza cu ajutorul graficelor de structură în care un indicator se reprezintă cu ajutorul unor dreptunghiuri adiacente, fiecare având lățimea proporțională cu frecvența relativă a sa.
Considerând acum x o caracteristică ce se cere a fi studiată dintr-o
selecţie de volum N, dacă S={x1,...,xn} sunt valorile lui x, acestea pot fi gândite ca valori ale unei variabile aleatoare. După obţinerea acestor valori se procedează de regulă la o grupare a lor obţinându-se în final o fişă de observaţie de forma:
Valoarea caracteristicii Număr de apariţii
x1 n1
... ...
xk nk
unde x1,...,xk sunt distincte. Dacă volumul unei selecţii este mare se recomandă gruparea valorilor după interval astfel: se determină mai întâi un interval (a,b) suficient de mare ca să cuprindă toate valorile caracteristicii studiate. Se împarte apoi acest interval într-un număr de p părţi
(a,b)=(a0,a1)∪[a1,a2)∪...∪[ap-1,ap) (a=a0,b=ap) de preferinţă de lungimi egale. Se obţine în final un tabel de forma celui de mai sus având în locul valorilor xi intervalele considerate.
Să notăm acum: I1=(a0,a1) şi Is=[as-1,as), s=2,...,p. Fie ns=card(S∩Is) numărul de valori xi din intervalul Is. Vom nota ns-frecvenţa absolută a

Cătălin Angelo Ioan Statistică economică
29
intervalului Is. Raportul fs=N
n s este frecvenţa relativă (sau simplu frecvenţa) a
intervalului Is. Numărul νs=∑=
s
1iif se numeşte frecvenţa cumulată
corespunzătoare intervalului Is. Avem evident relaţiile:
∑=
p
1iin =N, ∑
=
p
1iif =1, f1=ν1≤ν2≤...≤νp-1≤νp=1
Toate aceste mărimi se înregistrează într-un tablou de forma:
Intervalul Frecvenţa absolută Frecvenţa
relativă
Frecvenţa cumulată
I1 n1 f1 νννν1
... ... ... ...
Ip np fp ννννp
În cazul tabelelor de contingență (tabele ce grupează datele a două caracteristici) se calculează pe lângă frecvențele relative asociate distribuției bidimensionale și frecvențele relative marginale asociate distribuțiilor unidimensionale și cele condiționate.
Astfel, considerând tabelul de contingență:
frecvențele relative asociate distribuției bidimensionale sunt:
∑∑= =
==u
1i
v
1jij
pspsps
n
n
N
nf , p= u,1 , s= v,1
frecvențele relative marginale asociate distribuției unidimensionale X sunt:
∑∑
∑
= =
===
u
1i
v
1jij
v
1jpj
pp
n
n
N
Nf , p= u,1
frecvențele relative marginale asociate distribuției unidimensionale Y sunt:

Cătălin Angelo Ioan Statistică economică
30
∑∑
∑
= =
===u
1i
v
1jij
u
1iis
ss
n
n
N
nf , s= v,1
frecvențele relative condiționate de distribuția unidimensională X sunt:
∑=
==v
1jpj
ps
p
psps,X
n
n
N
nf , p= u,1 , s= v,1
frecvențele relative condiționate de distribuția unidimensională Y sunt:
∑=
==u
1iis
ps
s
psps,Y
n
n
n
nf , p= u,1 , s= v,1
Din definițiile de mai sus, rezultă relațiile:
p
psps,X f
ff = ,
s
psps,Y f
ff = ,
ps,X
ps,Y
s
p
f
f
f
f=
Productivitatea muncii, pe persoană ocupată se determină prin împărțirea producției valorice pe fiecare activitate la populația ocupată. Importanța acestor calcule este aceea că pune în evidență aportul valoric al fiecărei activități în raport cu forța de muncă. Exprimând datele primei coloane în monedă convertibilă (euro, dolar etc.), indicatorul calculat poate furniza concluzii interesante relativ la situarea forței de muncă în raport cu cea existentă în alte țări.
Indicatorii relativi de dinamică se determină pentru analiza evoluției temporale a unui anumit fenomen. De regulă, acești indicatori se prezintă ca indici cu bază fixă sau indici cu bază mobilă.
Considerând un tabel statistic de forma:
Nr.crt./Anul/Trim./Luna Variabila V
0 n0
1 n1
... ...
k nk

Cătălin Angelo Ioan Statistică economică
31
... ...
N nN
indicele cu bază fixă al variabilei V corespunzător perioadei k se definește prin formula:
0
k0/k n
nI = , k= N,0
iar indicele cu bază mobilă al variabilei V corespunzător perioadei k se definește prin formula:
1k
k1k/k n
nI
−
− = , k= N,1
Procentual avem, în mod evident:
100n
n%I
0
k0/k ⋅= , 100
n
n%I
1k
k1k/k ⋅=
−
− , k= N,1
La modul general, baza de comparație în cazul indicelui cu bază fixă, poate fi orice termen al seriei de date, dar, se recomandă, ca în cazul seriilor mici, aceasta să fie primul termen al seriei. Oricum, indiferent de poziția acesteia în cadrul setului de date, odată fixată ea trebuie ca să fie unică. În cadrul seriilor mari (peste 10 termeni) este recomandată divizarea acestora în grupe omogene și considerarea bazei de comparație (exceptând în mod evident prima grupă unde baza va fi primul termen) ca fiind ultimul termen al grupei anterioare.
Indicii cu bază mobilă oferă informații relevante referitoare la regularitatea dinamicității fenomenului studiat.
Între indicii cu bază fixă și cei cu bază mobilă există determinări
reciproce. Astfel: 0/1k1k/k0
1k
1k
k
0
k0/k II
n
n
n
n
n
nI −−
−
−
===
de unde:
0/1k
0/k1k/k I
II
−
− = , k= N,1
Reciproc, din relația de recurență 0/1k1k/k0/k III −−= rezultă succesiv:
0/1k1k/k0/k III −−= = 0/2k2k/1k1k/k III −−−− =...=

Cătălin Angelo Ioan Statistică economică
32
0/00/12k/1k1k/k II...II −−− . Cum însă: 1n
nI
0
00/0 == rezultă, în final:
=0/kI 0/12k/1k1k/k I...II −−− , , k= N,1
Dacă schimbăm acum baza de comparație cu cea de-a “p” dată, se obține:
0/p
0/k
p
0
0
k
p
kp/k I
I
n
n
n
n
n
nI === , k,p= N,0
respectiv:
0/pp/k0/k III =
Tot în categoria indicatorilor relativi de dinamică se încadrează ratele
de variație a acestora.
Astfel, rata de variație cu bază fixă se definește prin:
1I1n
n
n
nnR 0/k
0
k
0
0k0/k −=−=
−= , k= N,0
iar rata de variație cu bază mobilă prin:
1I1n
n
n
nnR 1k/k
1k
k
1k
1kk1k/k −=−=
−= −
−−
−− , k= N,1
Relativ la un moment de referință “p” avem:
1I1n
n
n
nnR p/k
p
k
p
pkp/k −=−=
−=
de unde, cum 1R
1R
I
II
0/p
0/k
0/p
0/kp/k
+
+== rezultă:
1R
RR1
1R
1RR
0/p
0/p0/k
0/p
0/kp/k
+
−=−
+
+=
În mod analog cu situația indicilor se determină ratele procentuale:
100%I100R%R 0/k0/k0/k −=⋅= ,
100%I100R%R 1k/k1k/k1k/k −=⋅= −−−
Cu ajutorul acestor indici sau rate se pot reobține valorile absolute (în limita erorilor de rotunjire sau trunchiere) și anume:

Cătălin Angelo Ioan Statistică economică
33
00/kk nIn = , ( ) 00/kk nR1n += , k= N,0
1k1k/kk nIn −−= , ( ) 1k1k/kk nR1n −−+= , k= N,1
pp/kk nIn = , p0/p
0/kk n
1R
1Rn
+
+= , k,p= N,0
Sarcina de lucru 3
Să considerăm tabelul de contingență pentru două caracteristici X și Y:
X/Y 2 5 7 9
1 159 177 175 102
2 184 105 193 108
4 182 155 185 139
6 101 131 183 155
Să se calculeze:
a) frecvențele relative asociate distribuției bidimensionale;
b) frecvențele relative marginale asociate distribuției unidimensionale X;
c) frecvențele relative marginale asociate distribuției unidimensionale Y;
d) frecvențele relative condiționate de distribuția unidimensională X;
e) frecvențele relative condiționate de distribuția unidimensională Y

Cătălin Angelo Ioan Statistică economică
34
Test de autoevaluare 1. Să considerăm evoluția Consumului final al României în perioada 2000-2016:
Anul Consum final
( mil.lei 2000)
2000 69459
2001 73187
2002 74874
2003 80140
2004 87178
2005 92442
2006 98167
2007 102086
2008 106727
Rezumat Indicatorii statistici reprezintă expresii numerice obținute în urma
unui proces de cercetare. Astfel, prima funcție esențială este cea de măsurare a fenomenului
studiat. Compararea datelor este esențială atunci când se dorește efectuarea
de predicții asupra fenomenelor. Indicatorii primari, după cum le arată și denumirea, se obțin în faza
inițială a prelucrărilor statistice. Chiar dacă uneori pot fi considerați drept indicatori primari și cei obținuți direct în urma procesului de culegere sau observare.
Indicatorii derivați se obțin, în marea majoritate a cazurilor, prin aplicarea unor modele estimative sau de prognoză. Acești indicatori se pot exprima fie prin relații de natură cantitativă între caracteristicile constitutive ale fenomenului analizat, fie prin variabile ce exprimă gradul de interdependență a variabilelor. Ca și exprimare valorică, indicatorii derivați se pot prezenta fie sub formă absolută (diferență dintre două valori), fie relativă (raport a două valori), fie de tip medie, de tip indici etc.
Indicatorii relativi se prezintă sub forma unui raport între doi indicatori absoluți. Dacă numărătorul raportului poartă numele de indicator
raportat, numitorul acestuia se numește bază de raportare

Cătălin Angelo Ioan Statistică economică
35
2009 99177
2010 98227
2011 97487
2012 98613
2013 98287
2014 101729
2015 104366
2016 109834
a) Să se determine indicii consumului final, cu bază fixă relativ la anul 2000;
b) Să se determine indicii consumului final, cu bază mobilă;
c) Pe baza indicilor cu bază mobilă, să se traseze graficul de variație a consumului final și să se interpreteze acesta.
Răspunsuri întrebările din testul de autoevaluare:
1- a) Determinăm indicii cu bază fixă pe baza formulei 0
k0/k n
nI = , împărțind
elementele fiecărei linii la valoarea consumului final din anul 2000 (deflatată) din ultima coloană:
Anul Indici cu bază fixă (2000)
2001 73187/69459=1,054
2002 74874/69459=1,078
2003 80140/69459=1,154
2004 87178/69459=1,255
2005 92442/69459=1,331
2006 98167/69459=1,413
2007 102086/69459=1,47
2008 106727/69459=1,537
2009 99177/69459=1,428
2010 98227/69459=1,414
Cătălin Angelo Ioan Statistică economică
36
2011 97487/69459=1,404
2012 98613/69459=1,42
2013 98287/69459=1,415
2014 101729/69459=1,465
2015 104366/69459=1,503
2016 109834/69459=1,581
b) Determinăm indicii cu bază mobilă pe baza formulei 1k
k1k/k n
nI
−
− = ,
împărțind elementele fiecărei linii la valoarea existentă în linia anterioară (deflatată) din ultima coloană:
Anul Indici cu bază mobilă
2001 73187/69459=1,054
2002 74874/73187=1,023
2003 80140/74874=1,07
2004 87178/80140=1,088
2005 92442/87178=1,06
2006 98167/92442=1,062
2007 102086/98167=1,04
2008 106727/102086=1,045
2009 99177/106727=0,929
2010 98227/99177=0,99
2011 97487/98227=0,992
2012 98613/97487=1,012
2013 98287/98613=0,997
2014 101729/98287=1,035
2015 104366/101729=1,026
2016 109834/104366=1,052
c) Graficul este:
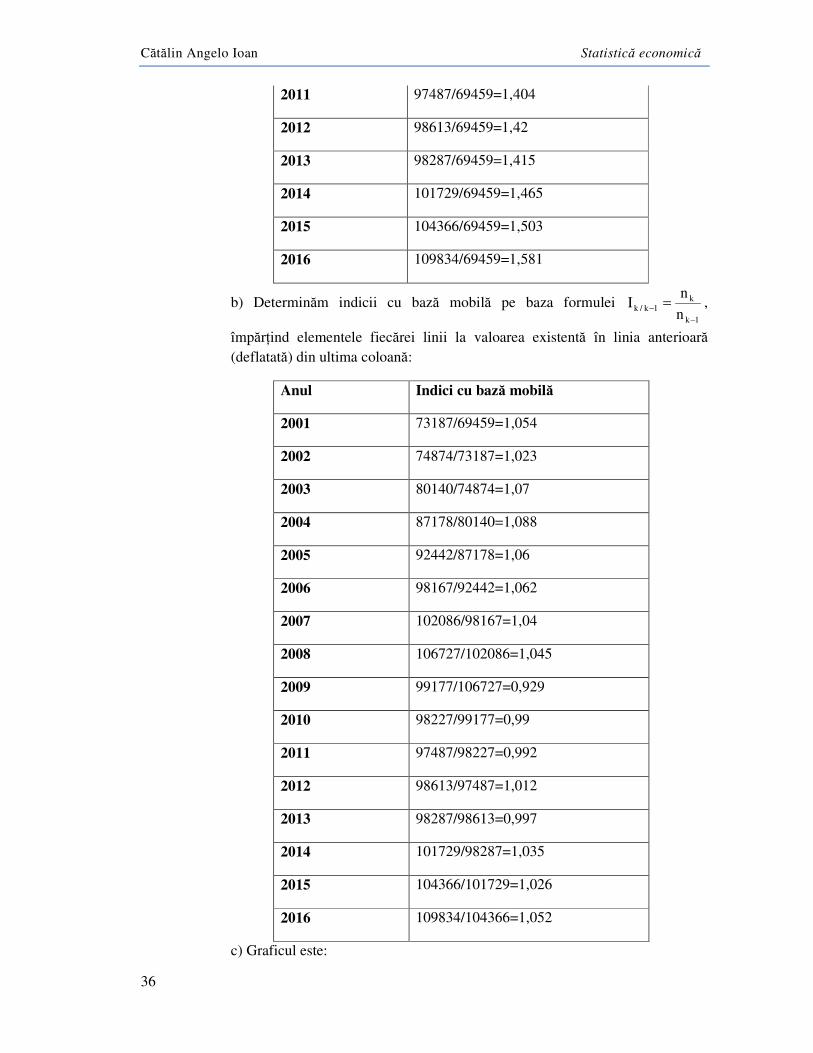
Cătălin Angelo Ioan Statistică economică
37
Din grafic, se observă cum Consumul final a cunoscut o evoluție oscilantă, înregistrând o scădere în perioada 2009-2011 pe fondul crizei economice globale.
Bibliografie minimală Ioan C.A., ȘANSA – ÎNTRE FINIT ȘI INFINIT. Teoria probabilităților și Statistică, Editura Zigotto, Galați, 2017
Biji E.M., Lilea E., Roșca E., Vătui M., Statistică pentru economiști, Editura Economică, București, 2010
Isaic-Maniu A., Mitruț C., Voineagu V., Statistică, Editura Universitară, București, 2004

Cătălin Angelo Ioan Statistică economică
38
3. INDICATORII TENDINȚEI CENTRALE
INDICATORII TENDINȚEI CENTRALE 38
Rezumat 60
Teste de autoevaluare 60
Răspunsuri şi comentarii la întrebările din testele de autoevaluare
61
Bibliografie minimală 61
Obiective în termeni de competențe specifice:
La sfârşitul modulului, se va şti: Să se poată calcula media unei variabile statistice;
Să se poată calcula mediana unei variabile statistice;
Să se poată calcula mediala unei variabile statistice.
Timp mediu estimat pentru studiu individual: 6 ore
În general, după colectarea datelor statistice, se constată o mare diversitate de valori provenită fie din caracterul aleator, fie din acțiunea unor factori mai mult sau mai puțin importanți sau pur și simplu din variabilitatea intrinsecă a fenomenului studiat.
Pentru emiterea însă de predicții sau uneori chiar și pentru analiza în sine a fenomenului este imperios necesar ca să avem la dispoziție un set de indicatori numerici care să poată da informații rapide și accesibile. Pentru a înțelege în mod concret acest lucru, gândiți-vă ce s-ar întâmpla dacă la un examen de admitere în facultate numai pe baza rezultatelor din liceu, un elev ar veni cu totalitatea notelor sale la toate materiile din cele patru clase! Probabil că s-ar crea un haos de nedescris!
Un set de indicatori ce caracterizează un fenomen trebuie ca să satisfacă (cel puțin la nivel teoretic) o serie de condiții. Astfel, conform lui George Udny Yule (1871-1951) indicatorul trebuie ca să:
• fie independent de voința celui ce analizează fenomenul;

Cătălin Angelo Ioan Statistică economică
39
• se bazeze pe toate observațiile făcute; • aibă proprietăți simple și evidente, fără un caracter matematic abstract; • se calculeze rapid (relativ la complexitatea sa); • fie foarte puțin afectat de fluctuațiile datelor observate; • se preteze la calcule matematice ulterioare.
Indicatorii tendinței centrale sunt de două feluri: indicatori medii și indicatori de localizare.
1. Indicatori medii
1.1. Media aritmetică și media ponderată
Definiție
Considerând o variabilă statistică “x” ale cărei valori observate sunt
x1,...,xn, n≥1, definim media aritmetică a acestora ca fiind:
n
x...xx n1 ++
= =n
xn
1kk∑
=
Din definiție, se observă că deoarece n,1k
kin,1k
k xmaxxxmin==
≤≤ , i= n,1
avem:
n,1kk
n,1kk
n,1kk
n,1kk
n1 xminn
xminn
n
xmin...xmin
n
x...xx
=
====
⋅
=
++
≥++
=
n,1kk
n,1kk
n,1kk
n,1kk
n1 xmaxn
xmaxn
n
xmax...xmax
n
x...xx
=
====
⋅
=
++
≤++
=
deci:
n,1kk
n,1kk xmaxxxmin
==
≤≤
Media aritmetică este deci cuprinsă între minimul și maximul datelor statistice.
Definiţie
Variabila u=x- x se numeşte abaterea variabilei statistice x.
Abaterea variabilei statistice x va avea valorile xk- x , k= n,1 .
Media aritmetică a lui u este deci: =un
xx...xx n1 −++−=
n
xnx...x n1 −++= x
n
x...x n1 −++
= xx − =0.

Cătălin Angelo Ioan Statistică economică
40
Prin urmare, media aritmetică a valorilor abaterii unei variabile statistice este nulă.
Observație
În cazul mediei aritmetice, se observă că toate valorile au aceleași ponderi, variabila statistică având distribuția:
x=
n
1...
n
1...
n
1x...x...x nk1
Definiție
Considerând o variabilă statistică “x” a cărei distribuție de frecvențe
relative este: x=
pk1
pk1
f...f...f
x...x...x, p≥1, definim media ponderată a lui
“x” ca fiind:
pp11 fx...fxx ++= =∑=
p
1kkk fx
unde este evident faptul că ∑=
p
1kkf =1.
În cazul în care variabila este dată prin intermediul frecvențelor
absolute: x=
pk1
pk1
n...n...n
x...x...x, p≥1, din faptul că fk=
∑=
p
1ii
k
n
n, k= p,1
definim media ponderată a lui “x” ca fiind:
p1
pp11
n...n
nx...nxx
++
++= =
∑
∑
=
=
p
1kk
p
1kkk
n
nx
Notația identică pentru media aritmetică și pentru cea ponderată nu dă naștere la ambiguități din următoarele motive:
• dacă f1=...=fp=p
1 atunci media ponderată devine medie aritmetică;
• dacă variabila statistică are frecvențele absolute: x=
pk1
pk1
n...n...n
x...x...x
atunci ea poate fi scrisă și sub forma:

Cătălin Angelo Ioan Statistică economică
41
x=
∑∑∑∑∑∑====== 44344 2144 3442144 344 21
321321321
ori n
p
1ii
p
1ii
ori n
p
1ii
p
1ii
ori n
p
1ii
p
1ii
ori n
pp
ori n
kk
ori n
11
pk1
pk1
n
1...
n
1...
n
1...
n
1...
n
1...
n
1
x...x...x...x...x...x
de unde media
aritmetică devine:
∑=
++=
p
1ii
pp11
n
xn...xnx identică mediei ponderate.
1.2. Media armonică
Definiție
Considerând o variabilă statistică “x” ale cărei valori observate sunt
x1,...,xn, n≥1, definim media armonică a acestora ca fiind:
n1
h
x
1...
x
1n
x++
= =
∑=
n
1k kx
1
n
Din definiția mediei armonice rezultă că:
n
x
1
x
1
n
1k k
h
∑=
=
deci inversa acesteia este tocmai media aritmetică a inverselor valorilor variabilei statistice.
Dacă valorile xi, i= n,1 sunt strict pozitive, atunci deoarece
n,1kki
n,1kk xmaxxxmin
==
≤≤ , i= n,1 avem:
n,1kki
n,1kk xmax
1
x
1
xmin
1
==
≥≥ de unde:
n,1kk
n
1i in,1k
k xmax
n
x
1
xmin
n
=
=
=
≥≥∑ , iar în final:
n,1kkn
1i i
n,1kk xmax
x
1
nxmin
=
=
=
≤≤
∑. Prin urmare:
n,1kkh
n,1kk xmaxxxmin
==
≤≤
Media armonică a unor valori pozitive este deci cuprinsă între minimul și maximul datelor statistice.

Cătălin Angelo Ioan Statistică economică
42
Tot pentru valori pozitive avem inegalitatea binecunoscută (consecință a celebrei inegalități Cauchy-Schwarz-Bunyakovsky):
xn
x...x
x
1...
x
1n
x n1
n1
h =++
≤
++
=
deci media armonică este mai mică sau egală decât media aritmetică. Egalitatea are loc dacă și numai dacă toate valorile sunt egale: x1=...=xn.
Dacă variabila statistică are frecvențele absolute:
x=
pk1
pk1
n...n...n
x...x...x atunci ea poate fi scrisă și sub forma:
x=
∑∑∑∑∑∑====== 44344 2144 344 2144 344 21
321321321
ori n
p
1ii
p
1ii
ori n
p
1ii
p
1ii
ori n
p
1ii
p
1ii
ori n
pp
ori n
kk
ori n
11
pk1
pk1
n
1...
n
1...
n
1...
n
1...
n
1...
n
1
x...x...x...x...x...x
de unde media armonică devine:
p
p
1
1
p1h
x
n...
x
n
n...nx
++
++= =
∑
∑
=
=
p
1i i
i
p
1ii
x
n
n.
În termeni de frecvențe relative, fi=
∑=
p
1ii
i
n
n avem (după împărțirea la
∑=
p
1iin ):
∑=
=
++
=p
1i i
i
p
p
1
1h
x
f
1
x
f...
x
f
1x
1.3. Media pătratică
Definiție
Considerând o variabilă statistică “x” ale cărei valori observate sunt
x1,...,xn, n≥1, definim media pătratică a acestora ca fiind:

Cătălin Angelo Ioan Statistică economică
43
n
x...xx
2n
21
2
++= =
n
xn
1k
2k∑
=
Deoarece n,1k
kin,1k
k xmaxxxmin==
≤≤ , i= n,1 avem:
2
n,1kk
2i
2
n,1kk xmaxxxmin
≤≤
==
de unde:
2
n,1kk
n
1i
2i
2
n,1kk xmaxnxxminn
≤≤
===
∑ , iar în final:
n,1kk
n
1i
2i
n,1kk xmax
n
xxmin
=
=
=
≤≤∑
Prin urmare:
n,1kk2
n,1kk xmaxxxmin
==
≤≤
Media pătratică este deci cuprinsă între minimul și maximul valorilor absolute ale datelor statistice.
Considerând funcția de gradul al doilea f:R→R, f(x)=x2 deoarece
f”(x)=2>0 rezultă că aceasta este convexă pe R. Din inegalitatea lui Jensen pentru funcții convexe:
( ) ( ) ( )nn11nn11 xf...xfx...xf λ++λ≤λ++λ
∀λ1,...,λn∈[0,1], λ1+...+λn=1
rezultă pentru λ1=...=λn=n
1:
n
x...x
n
x...x 2n
21
2
n1 ++≤
++ de unde:
2
2n
21n1n1 x
n
x...x
n
x...x
n
x...xx =
++≤
++≤
++=
Prin urmare, media pătratică este mai mare sau egală decât media aritmetică. Egalitatea are loc dacă și numai dacă valorile sunt egale: x1=...=xn.

Cătălin Angelo Ioan Statistică economică
44
Dacă variabila statistică are frecvențele absolute:
x=
pk1
pk1
n...n...n
x...x...x atunci ea poate fi scrisă și sub forma:
x=
∑∑∑∑∑∑====== 44344 2144 344 2144 344 21
321321321
ori n
p
1ii
p
1ii
ori n
p
1ii
p
1ii
ori n
p
1ii
p
1ii
ori n
pp
ori n
kk
ori n
11
pk1
pk1
n
1...
n
1...
n
1...
n
1...
n
1...
n
1
x...x...x...x...x...x
de unde media pătratică devine:
∑
∑
=
==p
1ii
p
1i
2ii
2
n
xnx . În termeni de frecvențe
relative, fi=
∑=
p
1ii
i
n
n avem (după împărțirea la ∑
=
p
1iin ):
∑=
=p
1i
2ii2 xfx
1.4. Media de ordin “p”
Definiție
Considerând o variabilă statistică “x” ale cărei valori observate sunt
x1,...,xn, n≥1, definim media de ordin “p”, p∈N, p≥2 a acestora ca fiind:
ppn
p1
p n
x...xx
++= =
p
n
1k
pk
n
x∑=
Dacă p=impar atunci cum n,1k
kin,1k
k xmaxxxmin==
≤≤ , i= n,1 avem:
p
n,1kk
pi
p
n,1kk xmaxxxmin
≤≤
==
de unde:
p
n,1kk
n
1i
pi
p
n,1kk xmaxnxxminn
≤≤
===∑ , iar în final:

Cătălin Angelo Ioan Statistică economică
45
n,1kk
p
n
1k
pk
n,1kk xmax
n
xxmin
=
=
=
≤≤∑
.
Prin urmare:
n,1kkp
n,1kk xmaxxxmin
==
≤≤ , p=impar.
Dacă p=par, deoarece n,1k
kin,1k
k xmaxxxmin==
≤≤ , i= n,1 avem:
p
n,1kk
pi
p
n,1kk xmaxxxmin
≤≤
==
de unde:
p
n,1kk
n
1i
pi
p
n,1kk xmaxnxxminn
≤≤
===
∑ , iar în final:
n,1kk
p
n
1k
pk
n,1kk xmax
n
xxmin
=
=
=
≤≤∑
.
Prin urmare:
n,1kkp
n,1kk xmaxxxmin
==
≤≤
Media pătratică este deci cuprinsă între minimul și maximul valorilor (absolute dacă p=par) ale datelor statistice.
Considerând funcția putere de gradul “p”, f:R→R, f(x)=xp, p≥2,
deoarece f”(x)=p(p-1)xp-2>0 rezultă că aceasta este convexă pe R. Din
inegalitatea lui Jensen pentru funcții convexe rezultă pentru λ1=...=λn=n
1:
n
x...x
n
x...x pn
p1
p
n1 ++≤
++ de unde:
pp
pn
p1n1n1 x
n
x...x
n
x...x
n
x...xx =
++≤
++≤
++=
Prin urmare, media de ordin “p” este mai mare sau egală decât media aritmetică. Egalitatea are loc dacă și numai dacă valorile sunt egale: x1=...=xn.
Mai mult, se arată că:

Cătălin Angelo Ioan Statistică economică
46
n,1kkp32
n,1kk xmax...x...xxxxmin
==
≤≤≤≤≤≤≤
Prin urmare, media de ordin “p” crește odată cu valoarea acestuia.
Dacă variabila statistică are frecvențele absolute:
x=
mk1
mk1
n...n...n
x...x...x atunci ea poate fi scrisă și sub forma:
x=
∑∑∑∑∑∑====== 44344 2144 344 2144 344 21
43421321321
ori n
m
1ii
m
1ii
ori n
m
1ii
m
1ii
ori n
m
1ii
m
1ii
ori n
mm
ori n
kk
ori n
11
mk1
mk1
n
1...
n
1...
n
1...
n
1...
n
1...
n
1
x...x...x...x...x...x
de unde media de ordin “p” devine: p m
1ii
m
1i
pii
p
n
xnx
∑
∑
=
== . În termeni de frecvențe
relative, fi=
∑=
m
1ii
i
n
n avem (după împărțirea la ∑
=
m
1iin ):
pm
1i
piip xfx ∑
=
=
1.5. Media geometrică
Definiție
Considerând o variabilă statistică “x” ale cărei valori pozitive observate
sunt x1,...,xn, n≥1, definim media geometrică a acestora ca fiind:
nn1g x...xx = = n
n
1kkx∏
=
Deoarece n,1k
kin,1k
k xmaxxxmin==
≤≤ , i= n,1 avem:
n
n,1kkn1
n
n,1kk xmaxx...xxmin
≤≤
==
de unde:
n,1kk
nn1
n,1kk xmaxx...xxmin
==
≤≤ , deci:

Cătălin Angelo Ioan Statistică economică
47
n,1kkg
n,1kk xmaxxxmin
==
≤≤
Considerând funcția ln:(0,∞)→R, f(x)=ln x, deoarece f”(x)=
-2x
1<0 rezultă că aceasta este concavă pe R. Din inegalitatea lui Jensen pentru
funcții concave, rezultă pentru λ1=...=λn=n
1:
n
xln...xln
n
x...xln n1n1 ++
≥
++⇔ ( )n1
n1 x...xlnn
1
n
x...xln ≥
++⇔
( )n
1
n1n1 x...xln
n
x...xln ≥
++⇔ n
n1n1 x...x
n
x...x≥
++ (deoarece funcția ln
este strict crescătoare).
Prin urmare, media aritmetică este mai mare sau egală decât media geometrică. Egalitatea are loc dacă și numai dacă valorile sunt egale: x1=...=xn.
Mai mult, dacă în această inegalitate facem substituția: xi→ix
1, i= n,1
obținem: n
n1
n1
x
1...
x
1
n
x
1...
x
1
≥
++
⇔
nn1
n1
x...x
x
1...
x
1n
≤
++
adică faptul că media armonică este mai mică sau
egală decât cea geometrică, egalitatea având loc dacă și numai dacă valorile variabilelor sunt egale.
În final, avem deci:
n,1kkp32gh
n,1kk xmax...x...xxxxxxmin
==
≤≤≤≤≤≤≤≤≤
Considerând variabila statistică ln x ale cărei valori sunt: ln x1, ...,ln xn, media aritmetică a acesteia este:
gn
n
1kk
n
1n
1kk
n
1kk
n
1kk
n
1kk
xlnxlnxlnxlnn
1
n
xln
n
xlnxln ==
==== ∏∏∏
∏∑
===
==
de unde:
gx = xlne

Cătălin Angelo Ioan Statistică economică
48
Prin urmare, media geometrică este exponențiala mediei aritmetice a logaritmilor naturali ai termenilor seriei.
Reciproc, considerând variabila statistică ex ale cărei valori sunt 1xe ,..., nxe , media ei geometrică este:
xn
x
n x
n
n
1i
xg
x eeeee
n
1iin
1ii
i =
∑
=∑
===
=∏=
de unde:
gxelnx =
Prin urmare, media aritmetică este logaritmul natural al mediei geometrice a exponențialelor termenilor seriei.
Dacă variabila statistică are frecvențele absolute:
x=
mk1
mk1
n...n...n
x...x...x atunci media geometrică devine:
∑= =
m
1ii
m1
nnm
n1g x...xx =
∑= ∏
=
m
1ii
in m
1i
nix
În termeni de frecvențe relative, fi=
∑=
m
1ii
i
n
n avem, după logaritmare:
=
∑=
∑=
∑=∑
=
=
=
=
=
=
=
=
∑∑∏∏ = m
1ii
m
1iii
m
1ii
m
1i
nim
1i
nim
1ii
n
1m
1i
nig
n
xlnn
n
xlnxln
n
1xlnxln
i
i
m
1iii
∏∑∑∑====
=
===
∑
m
1i
fi
m
1i
fi
m
1iii
m
1iim
1jj
i ii xlnxlnxlnfxlnn
n de unde:
=gx ∏=
m
1i
fi
ix
Prin urmare media geometrică a unei variabile statistice exprimată prin frecvențe relative este egală cu produsul valorilor variabilei la puterile frecvențelor relative corespunzătoare.

Cătălin Angelo Ioan Statistică economică
49
Observație
De regulă, media geometrică se utilizează pentru calculul indicilor medii. Astfel, considerând indicii cu bază mobilă pentru o variabilă V
corespunzători perioadelor k= N,1 : 1k
k1k/k n
nI
−
− = unde nk sunt frecvențele
absolute corespunzătoare, indicele mediu se va defini ca:
N1N/N1/20/1 I...III −=
Observăm, din definiția indicilor cu bază mobilă că:
N
0
NN
1N
N
1
2
0
1
n
n
n
n...
n
n
n
nI ==
−
1.6. Medii ale seriilor cronologice
Seriile cronologice reprezintă serii de date distribuite temporal. Fie deci:
x=
Tk1 x...x...x
T...k...1
o serie de date în care xk reprezintă valoarea variabilei statistice înregistrată la
momentul de timp k, k= T,1 .
Dacă fenomenul nu are continuitate între momentele de timp (de exemplu, notele unui student în cadrul sesiunilor de examene 1,...,T) atunci media se calculează ca o simplă medie aritmetică:
T
x...xx T1 ++
=
Să considerăm acum: x=
Tk1
Tk1
x...x...x
t...t...t o serie de date în care
xk reprezintă valoarea variabilei statistice înregistrată la momentul de timp tk,
k= T,1 unde t1<...<tk<...<tT.
Dacă fenomenul are continuitate în intervalele de timp [ti,ti+1], i= 1T,1 −
atunci, considerând că el este reprezentat de o funcție x:[t1,tT]→R, t→x(t), media unei funcții pe un interval este definită în analiza matematică ca fiind:

Cătălin Angelo Ioan Statistică economică
50
( )
1T
t
t
tt
dttx
x
T
1
−=
∫
Avem acum două situații:
• momentele de timp sunt echidistante În această situație, considerăm t1=1,...,tk=k,...,tT=T și vom presupune că
variația fenomenului în interiorul unui interval este liniară.
Din formula de mai sus, rezultă:
( ) ( )
1T
dttx
1T
dttx
x
1T
1k
1k
k
T
1
−=
−=
∑ ∫∫−
=
+
Fig.39
Pe intervalul [k,k+1], ecuația dreptei CD este:
( ) 1kk
k
xx
xx
1kk
kt
+−
−=
+−
−
de unde:
( ) ( ) 1kkk1k kxx1kxxtx ++ −++−=
Introducând ecuația dreptei în integrala ( )∫+1k
k
dttx rezultă:
( )∫+1k
k
dttx = ( ) ( )∫+
++ −++−1k
k
1kkk1k dtkxx1kxxt =
( ) ( )( )k
1ktkxx1k
k
1k
2
txx 1kk
2
k1k
+−++
+− ++ =
( ) ( ) ( )( )( )k1kkxx1k2
k1kxx 1kk
22
k1k −+−++−+
− ++ =
( ) ( ) 1kkk1k kxx1k2
1k2xx ++ −++
+− =
2
xx 1kk ++ (punctul F din figură).
Revenind, avem deci:

Cătălin Angelo Ioan Statistică economică
51
( ) ( )
( ) ( )
.1T
2
xx...x
2
x
1T2
xx2x
1T2
xxxx
1T2
xx
1T2
xx
1T2
xx
x
T1T2
1
T
1T
2kk1T
1T
2kk
1T
2kk1
T
2pp
1T
1kk
1T
1k1k
1T
1kk
1T
1k
1kk
−
++++
=−
++
=−
+++
=−
+
=−
+
=−
+
=
−
−
=
−
=
−
=
=
−
=
−
=
+
−
=
−
=
+
∑∑∑
∑∑∑∑∑
Ca urmare a acestei demontrații, media unui set temporal de date echidistante (în timp) este:
1T2
xx...x
2
x
x
T1T2
1
−
++++=
−
• momentele de timp nu sunt echidistante
Din formula de mai sus, avem:
( ) ( )
1T
1T
1k
t
t
1T
t
t
tt
dttx
tt
dttx
x
1k
k
T
1
−=
−=
∑ ∫∫−
=
+
În final, media unui set temporal de date neechidistante (în timp) este:
1T1
T1T
1T1T2T
221
11
m...m
x2
mx
2
mm...x
2
mmx
2
m
x−
−−
−−
++
++
+++
+=
unde mk=tk+1-tk, k= 1T,1 − .
Se observă că, pentru momente de timp echidistante, avem mk=k+1-k=1 și
deci: 1T
2
xx...x
2
x
x
T1T2
1
−
++++=
−
- formula de mai sus.
2. Indicatori de poziție În studiul valorilor unei variabile statistice, de multe ori, pe lângă
caracteristicile numerice de tip medie, este foarte important de cunoscut distribuția acestora sub aspectul fie aglomerării/împrăștierii acestora, fie a grupării în jurul unei valori centrale.

Cătălin Angelo Ioan Statistică economică
52
2.1. Modul unei variabile statistice
Definiție
Considerând o variabilă statistică “x” ale cărei frecvențe absolute sunt:
x=
pk1
pk1
n...n...n
x...x...x numim modul sau valoare modală sau valoare
dominantă (notat Mo) acea valoare a lui x pentru care frecvența absolută (sau relativă) este cea mai mare.
În situația în care datele sunt reprezentate prin histograme, valoare modală (valorile modale) sunt determinate de maximele acestora.
Observație
În mod analog, se definește valoarea antimodală ca fiind cea corespunzătoare celei mai mici frecvențe absolute (relative).
În situația în care seria de distribuție este dată pe intervale egale (în cazul în care acestea nu sunt egale, se recompun intervalele, dar cu evidentă pierdere de informații) valoarea modală se determină astfel:
• identificăm mai întâi intervalul modal (corespunzător celei mai mari frecvențe de apariție);
• estimăm apoi valoarea modală astfel: o dacă în interiorul intervalului modal există simetrie în cadrul frecvențelor,
atunci valoarea modală este dată de centru acestuia; o dacă în interiorul intervalului modal nu există simetrie în cadrul frecvențelor,
atunci (fig.40) se procedează astfel: cum relativ la dreptunghiul xmxm+1CB valorile variabilei se pot situa oriunde, considerăm două cazuri extreme. Dacă acestea sunt toate situate în xm construim dreapta BD ce se constituie într-o interpolare liniară de la xm la prima valoare din intervalul următor: xm+1.
Ecuația dreptei BD este deci: 1mm
m
1mm
m
nn
nn
xx
xx
++ −
−=
−
− de unde:
1mm
1mmm1m
1mm
1mm
nn
nxnxn
nn
xxx
+
++
+
+
−
−+
−
−= . Analog, dacă acestea sunt toate situate în
xm+1 construim dreapta AC ce se constituie într-o interpolare liniară de la xm+1 la ultima valoare din intervalul anterior: xm. Ecuația dreptei AC este deci:
m1m
1m
1mm
m
nn
nn
xx
xx
−
−=
−
−
−
−
+
de unde:
m1m
mm1m1m
m1m
1mm
nn
nxnxn
nn
xxx
−
−+
−
−=
−
−+
−
+ . Intersecția celor două drepte va furniza
valoarea modală:
( ) ( )( ) ( )
−+−=−
−+−=−
−++−
++++
mm1m1m1mmm1m
1mmm1m1mm1mm
nxnxnxxxnn
nxnxnxxxnn

Cătălin Angelo Ioan Statistică economică
53
( ) ( ) ( )1mmm1mm1mm1m1mm nnxnnxxnnnn +−+−+ −+−=+−− . Notând:
∆1= 1mm nn −− , ∆2= 1mm nn +− obținem:
( ) m21m121 xxx ∆+∆=∆+∆ + de unde, valoarea modală (Mo) este:
Mo=21
m21m1 xx
∆+∆
∆+∆ + . Dacă notăm lățimea intervalului: h=xm+1-xm putem scrie
și:
Mo= hxxhx
21
1m
21
m21m1
∆+∆
∆+=
∆+∆
∆+∆+∆.
2.2. Mediana unei variabile statistice
Definiție
Considerând o variabilă statistică “x” ale cărei frecvențe relative sunt:
x=
pk1
pk1
f...f...f
x...x...x unde x1<...<xk<...<xp sau x1>...>xk>...>xp numim
mediană a lui x (notată cu Me) acea valoare a caracteristicii pentru care suma frecvențelor relative ale valorilor mai mari sau egale cu Me este egală cu suma frecvențelor relative ale valorilor mai mici sau egale cu Me. Altfel spus:
2
1ffejei Mx
jMx
i == ∑∑≥≤
Cu alte cuvinte, mediana reprezintă valoarea din “mijloc” a unei serii de date.
În situația unei serii simple de date: x=(x1<...<xk<...<xp) mediana se calculează determinând, în cazul p=2s+1=impar, valoarea din mijloc Me=xs+1, iar în cazul p=2s=par, media aritmetică a celor doi termeni centrali
Me=2
xx 1ss ++.
În situația în care x=
pk1
pk1
n...n...n
x...x...x cu (de exemplu)
x1<...<xk<...<xp se determină mai întâi frecvențele absolute cumulate pentru
fiecare valoare xk adică: Nk=∑=
k
1iin . Mediana reprezintă acea valoare
corespunzătoare primei frecvențe absolute cumulate ce este mai mare sau egală
decât 2
1np
1ii +∑
= =2
1N p +.

Cătălin Angelo Ioan Statistică economică
54
În situația în care x=
pk1
pk1
f...f...f
x...x...x cu (de exemplu)
x1<...<xk<...<xp se determină mai întâi frecvențele relative cumulate pentru
fiecare valoare xk adică: νk=∑=
k
1iif . Mediana reprezintă acea valoare
corespunzătoare primei frecvențe relative cumulate ce este mai mare sau egală
decât 2
1.
În situația în care seria de distribuție este dată pe intervale, mediana se determină astfel:
• identificăm mai întâi intervalul median (a cărui margine dreaptă este corespunzătoare primei frecvențe absolute cumulate ce este mai mare sau
egală decât 2
1N p + sau primei frecvențe relative cumulate ce este mai mare
sau egală decât 2
1);
• estimăm apoi mediana astfel: determinăm (fig.41) ecuația dreptei AB:
1mm
m
1mm
m
xx
xx
NN
NN
++ −
−=
−
−. Pentru N=
2
1N p + obținem:
1mm
mo
1mm
mp
xx
xM
NN
N2
1N
++ −
−=
−
−+
deci:
( )
1mm
1mmmp
me NN
xxN2
1N
xM+
+
−
−
−
+
+= . Dacă h= m1m xx −+ , cum
m1m NN −+ =∑+
=
1m
1iin -∑
=
m
1iin =nm+1 rezultă:
m1m
mp
me NN
N2
1N
hxM−
−+
+=+
=1m
mp
m n
N2
1N
hx+
−+
+
2.3. Mediala unei variabile statistice
Definiție
Considerând o variabilă statistică “x” ale cărei frecvențe absolute sunt:
x=
pk1
pk1
n...n...n
x...x...x unde x1<...<xk<...<xp sau x1>...>xk>...>xp numim
medială a lui x (notată cu Ml) acea valoare a caracteristicii pentru care suma (ponderată a) valorilor mai mari sau egale cu Ml este egală cu suma (ponderată a) valorilor mai mici sau egale cu Ml.

Cătălin Angelo Ioan Statistică economică
55
Cu alte cuvinte, mediala reprezintă valoarea din “mijloc” a sumei valorilor unei serii de date (ordonate crescător sau descrescător).
În situația unei serii simple de date: x=(x1<...<xk<...<xp) mediala se
calculează însumând până la un k= p,1 valorile variabilei: Sk=∑=
k
1iix și apoi
prima valoare a variabilei pentru care Sk este mai mare sau egală decât 2
Sp .
Dacă seria este reprezentată prin frecvențe absolute, atunci se
calculează Sk=∑=
k
1iii xn procedându-se ca mai sus.
În situația în care seria de distribuție este dată pe intervale, având
valorile vk, k= p,1 mediala se determină ca mai sus, prin interpolare liniară:
• identificăm mai întâi intervalul medial (a cărui margine dreaptă este corespunzătoare primei valori pentru care suma Sk este mai mare sau egală cu
2
S p );
• estimăm apoi mediala (ca și în cazul medianei), determinând (fig.42) ecuația
dreptei AB: 1mm
m
1mm
m
xx
xx
SS
SS
++ −
−=
−
−. Pentru S=
2
Sp obținem:
1mm
ml
1mm
mp
xx
xM
SS
S2
S
++ −
−=
−
− deci:
Sarcina de lucru 4 Considerând notele studenților la examenul de statistică: x=(5,8,9,4,10,7,8) să se calculeze mediala.

Cătălin Angelo Ioan Statistică economică
56
( )
1mm
1mmmp
ml SS
xxS2
S
xM+
+
−
−
−
+= . Dacă h= m1m xx −+ , cum m1m SS −+ =∑+
=
1m
1iiv -
∑=
m
1iiv =vm+1 rezultă:
m1m
mp
mo SS
S2
S
hxM−
−+=
+
=1m
mp
m v
S2
S
hx+
−+
2.4. Cuartile, decile, centile
Definiție
Considerând o variabilă statistică “x” ale cărei frecvențe absolute sunt:
x=
pk1
pk1
n...n...n
x...x...x unde x1<...<xk<...<xp sau x1>...>xk>...>xp numim
cuartile ale lui x (notate cu Q1, Q2, Q3) acele valori ale caracteristicii ce împart seria în patru părți egale (din punctul de vedere al frecvenței absolute).
Determinarea cuartilelor este asemănătoare cu cea a medianei unei variabile statistice.
În situația unei serii simple de date: x=(x1<...<xk<...<xp) cuartilele se calculează determinând valoarea din mijloc (în cazul p=impar) sau media aritmetică a valorilor mijlocii (în cazul p=par) ce va reprezenta cuartila Q2 și
apoi pentru seturile de valori x1<...<xs<Q2, respectiv Q2<xs+1<...<xp procedând analog pentru prima cuartilă Q1, respectiv cea de-a treia cuartilă Q3.
În situația în care x=
pk1
pk1
n...n...n
x...x...x cu x1<...<xk<...<xp se
determină mai întâi frecvențele absolute cumulate pentru fiecare valoare xk
adică: Nk=∑=
k
1iin . Vom avea: Q1 acea valoare corespunzătoare primei frecvențe
absolute cumulate ce este mai mare sau egală decât 4
1N p +, Q2=Me – acea
valoare corespunzătoare primei frecvențe absolute cumulate ce este mai mare
sau egală decât 2
1N p + și Q3 acea valoare corespunzătoare primei frecvențe
absolute cumulate ce este mai mare sau egală decât ( )
4
1N3 p +.

Cătălin Angelo Ioan Statistică economică
57
Dacă variabila statistică “x” are frecvențele relative date prin
distribuția: x=
pk1
pk1
f...f...f
x...x...x unde x1<...<xk<...<xp sau x1>...>xk>...>xp
atunci cuartilele se definesc prin:
4
1f
1i Qxi =∑
≤
, 2
1f
2i Qxi =∑
≤
, 4
3f
3i Qxi =∑
≤
în practică luând în considerare primele valori mai mari sau egale decât acestea.
În situația în care seria de distribuție este dată pe intervale, cuartilele se determină astfel:
• identificăm mai întâi intervalele cuartilice (corespunzătoare celor în care se află cuartilele teoretice de mai sus);
• estimăm apoi cuartilele ca și în cazul medianei:
m1m
mp
m1 NN
N4
1N
hxQ−
−+
+=+
, m1m
mp
m2 NN
N2
1N
hxQ−
−+
+=+
,
( )
m1m
mp
m3 NN
N4
1N3
hxQ−
−+
+=+
unde valorile xm, Nm, Nm+1 se referă la intervalul corespunzător fiecărei cuartile (în mod evident diferit).
Definiție
Considerând o variabilă statistică “x” ale cărei frecvențe absolute sunt:
x=
pk1
pk1
n...n...n
x...x...x unde x1<...<xk<...<xp sau x1>...>xk>...>xp numim
decile ale lui x (notate cu D1,D2,...,D9) acele valori ale caracteristicii ce împart seria în zece părți egale (din punctul de vedere al frecvenței absolute).
Determinarea decilelor este asemănătoare cu cea a medianei sau a cuartilelor unei variabile statistice.
În situația unei serii simple de date: x=(x1<...<xk<...<xp) decilele se calculează ca și în cazul cuartilelor.
În situația în care x=
pk1
pk1
n...n...n
x...x...x cu x1<...<xk<...<xp se
determină mai întâi frecvențele absolute cumulate pentru fiecare valoare xk

Cătălin Angelo Ioan Statistică economică
58
adică: Nk=∑=
k
1iin . Vom avea: Dk acea valoare corespunzătoare primei frecvențe
absolute cumulate ce este mai mare sau egală decât ( )
10
1Nk p +, k= 9,1 . Se
observă că D5=Q2=Me.
Dacă variabila statistică “x” are frecvențele relative date prin
distribuția: x=
pk1
pk1
f...f...f
x...x...x unde x1<...<xk<...<xp sau x1>...>xk>...>xp
atunci decilele se definesc prin:
10
1f
1i Dxi =∑
≤
, 10
2f
2i Dxi =∑
≤
, 10
3f
3i Dxi =∑
≤
etc.
în practică luând în considerare primele valori mai mari sau egale decât acestea.
În situația în care seria de distribuție este dată pe intervale, decilele se determină astfel:
• identificăm mai întâi intervalele decilice (corespunzătoare celor în care se află decilele teoretice de mai sus);
• estimăm apoi decilele ca și în cazul cuartilelor: ( )
m1m
mp
mk NN
N10
1Nk
hxD−
−+
+=+
, k= 9,1 unde valorile xm, Nm, Nm+1 se referă la
intervalul corespunzător fiecărei decile (în mod evident diferit).
Definiție
Considerând o variabilă statistică “x” ale cărei frecvențe absolute sunt:
x=
pk1
pk1
n...n...n
x...x...x unde x1<...<xk<...<xp sau x1>...>xk>...>xp numim
centile ale lui x (notate cu C1,C2,...,C99) acele valori ale caracteristicii ce împart seria în o sută de părți egale (din punctul de vedere al frecvenței absolute).
Determinarea centilelor este asemănătoare cu cea a medianei, a cuartilelor sau a decilelor unei variabile statistice.
În situația unei serii simple de date: x=(x1<...<xk<...<xp) decilele se calculează ca și în cazul cuartilelor sau decilelor.

Cătălin Angelo Ioan Statistică economică
59
În situația în care x=
pk1
pk1
n...n...n
x...x...x cu x1<...<xk<...<xp se
determină mai întâi frecvențele absolute cumulate pentru fiecare valoare xk
adică: Nk=∑=
k
1iin . Vom avea: Ck acea valoare corespunzătoare primei frecvențe
absolute cumulate ce este mai mare sau egală decât ( )100
1Nk p +, k= 99,1 . Se
observă că C50=D5=Q2=Me.
Dacă variabila statistică “x” are frecvențele relative date prin
distribuția: x=
pk1
pk1
f...f...f
x...x...x unde x1<...<xk<...<xp sau x1>...>xk>...>xp
atunci centilele se definesc prin:
100
1f
1i Cxi =∑
≤
, 100
2f
2i Cxi =∑
≤
, 100
3f
3i Cxi =∑
≤
etc.
în practică luând în considerare primele valori mai mari sau egale decât acestea.
În situația în care seria de distribuție este dată pe intervale, decilele se determină astfel:
• identificăm mai întâi intervalele centilice (corespunzătoare celor în care se află decilele teoretice de mai sus);
• estimăm apoi centilele ca și în cazul cuartilelor sau decilelor: ( )
m1m
mp
mk NN
N100
1Nk
hxC−
−+
+=+
, k= 99,1 unde valorile xm, Nm, Nm+1 se referă la
intervalul corespunzător fiecărei centile (în mod evident diferit).
Observație
De regulă, decilele și centilele se folosesc în cazul seriilor mari de date ce prezintă și variații considerabile ale valorilor statistice.

Cătălin Angelo Ioan Statistică economică
60
Test de autoevaluare 1. Să considerăm variabila statistică x:
xi ni
938 5
633 5
Rezumat Considerând o variabilă statistică “x” ale cărei valori observate sunt x1,...,xn,
n≥1, definim media aritmetică a acestora ca fiind:
n
x...xx n1 ++
= =n
xn
1kk∑
=
Considerând o variabilă statistică “x” ale cărei valori observate sunt x1,...,xn,
n≥1, definim media armonică a acestora ca fiind:
n1
h
x
1...
x
1n
x++
= =
∑=
n
1k kx
1
n
Considerând o variabilă statistică “x” ale cărei valori observate sunt x1,...,xn,
n≥1, definim media pătratică a acestora ca fiind:
n
x...xx
2n
21
2
++= =
n
xn
1k
2k∑
=
Considerând o variabilă statistică “x” ale cărei valori observate sunt x1,...,xn,
n≥1, definim media de ordin “p”, p∈N, p≥2 a acestora ca fiind:
ppn
p1
p n
x...xx
++= =
p
n
1k
pk
n
x∑=
Considerând o variabilă statistică “x” ale cărei valori pozitive observate sunt
x1,...,xn, n≥1, definim media geometrică a acestora ca fiind:
nn1g x...xx = = n
n
1kkx∏
=
Considerând o variabilă statistică “x” ale cărei frecvențe absolute sunt:
x=
pk1
pk1
n...n...n
x...x...x numim modul sau valoare modală sau valoare
dominantă (notat Mo) acea valoare a lui x pentru care frecvența absolută (sau relativă) este cea mai mare.

Cătălin Angelo Ioan Statistică economică
61
266 7
623 7
776 7
unde ni este frecvența absolută a lui xi. Să se calculeze:
a) media lui x;
b) media armonică a lui x;
c) media pătratică a lui x.
Răspunsuri şi comentarii la întrebările din testul de autoevaluare 1. a) 629,35 / b) 518,38 / c) 667,93
Bibliografie minimală Ioan C.A., ȘANSA – ÎNTRE FINIT ȘI INFINIT. Teoria probabilităților și Statistică, Editura Zigotto, Galați, 2017 Biji E.M., Lilea E., Roșca E., Vătui M., Statistică pentru economiști, Editura Economică, București, 2010 Isaic-Maniu A., Mitruț C., Voineagu V., Statistică, Editura Universitară, București, 2004

Cătălin Angelo Ioan Statistică economică
62
4. INDICATORII VARIAȚIEI
INDICATORII VARIAȚIEI 62 Rezumat 89
Teste de autoevaluare 89
Răspunsuri la întrebările din testele de autoevaluare 90
Bibliografie minimală 90
Obiective în termeni de competențe specifice:
La sfârşitul modulului, se va şti: Să calculați Amplitudinea absolută și cea relativă, Abaterea medie liniară, Dispersia și abaterea medie pătratică, Coeficientul de variație, Corelația și coeficientul de corelație, Variațiile intercuartilice, decilice și centilice, Coeficienții de asimetrie și de aplatizare
Timp mediu estimat pentru studiu individual: 6 ore
Determinarea indicatorilor tendinței centrale aduce un plus de informație în analiza seturilor de date statistice. Pe de altă parte însă, se pune problema relevanței acestora sub mai multe aspecte.
Primul dintre acestea se referă la omogenitatea datelor statistice. Un set foarte împrăștiat de date poate furniza, de
exemplu, o medie ce poate ca să nu fie semnificativă pentru fenomenul analizat.
Un exemplu foarte simplu este acela al unui grup de studenți (vom lua doi studenți pentru a nu ne înfunda în calcule sterile). Să presupunem că avem un grup G1 de doi studenți care au mediile generale în anul I: 6, respectiv 10. Un al doilea grup de studenți G2 are mediile generale în același an: 7, respectiv 9. Mediile fiecărui grup sunt egale cu 8. Un cadru didactic ce va seminariza în anul II va fi interesat de nivelul real al studenților din cele două grupe pentru a-și adapta metoda de predare. Dacă el va lua în considerare numai mediile lor, va rezulta că grupele sunt de aceeași factură (având amândouă media 8). Este însă vizibil faptul că prima grupă este mult mai eterogenă decât cea de a doua având un student foarte slab și unul foarte bun, în timp ce cea de a doua va avea doi studenți oarecum comparabili. Prin urmare, se pune problema determinării omogenității datelor statistice. Dacă în exemplul acesta analiza

Cătălin Angelo Ioan Statistică economică
63
este foarte simplă (fiind vizibilă cu ochiul liber), gândiți-vă ce se întâmplă atunci când există un set foarte mare de date! Un alt exemplu, în acest sens este nivelul PIB-ului pe cap de locuitor. Vom lua două țări cu un PIB/loc. apropiat și anume: Kuwait (locul 5 pe plan mondial în anul 2015, conform FMI) cu 70166 $/loc. și Novegia (locul 6 pe plan mondial în anul 2015, conform FMI) cu 68430 $/loc. Ca și medie, la nivel național, Kuwait-ul este deasupra Norvegiei. Pe de altă parte, este cunoscut faptul că în această țară există un număr de oameni extraordinar de bogați ce ridică în mod considerabil media. Pentru o imagine cât mai elocventă ar trebui luate în considerare toate datele referitoare la economiile în cauză, ceea ce ar conduce la prelucrarea unui număr imens de date și, implicit, folosirea unor metode statistice mult mai rafinate decât simpla medie.
Un alt aspect ce ar trebui luat în considerare este acela al factorilor aleatori ce pot influența semnificativ rezultatele unei analize statistice. Va trebui deci ca influența acestora în comportarea fenomenului să fie separată de cea a factorilor esențiali.
1. Indicatori simpli ai variației
1.1. Amplitudinea absolută și cea relativă
Definiții
Considerând o variabilă statistică “x” ale cărei valori observate sunt
x1,...,xn, n≥1 definim amplitudinea absolută a variației lui x ca fiind
Ax= in,1i
in,1i
xminxmax==
− deci diferența dintre cea mai mare valoare a lui x și cea
mai mică.
Definim amplitudinea relativă a variației lui x ca fiind ARx=x
A x deci
raportul dintre amplitudinea absolută și media variabilei x. Este evident că
amplitudinea relativă procentuală este ARx%=100⋅ARx.
Amplitudinea absolută a variației este utilă, de exemplu, la determinarea numărului optim al intervalelor de date care, ne reamintim
formula lui Sturges, este: mint=
+
−
Nlog1
xx
2
minmax =
+ Nlog1
A
2
x unde [a]
reprezintă partea întreagă a lui a∈R.
Un dezavantaj major al amplitudinii constă în faptul că ea ține seama numai de valorile extreme ale fenomenului analizat, acest lucru putând crea serioase distorsiuni în interpretare.

Cătălin Angelo Ioan Statistică economică
64
Revenind, un alt exemplu, mult mai simplu însă, este acela al unui elev “mai plinuț” ce are numai 9 și 10 pe linie, dar la educație fizică are nota 5 (neputând ca să alerge precum ceilalți colegi ai săi). Amplitudinea absolută ar da valoarea 10-5=5 ceea ce ar putea conduce la ideea unui elev foarte fluctuant. Concluzia ar fi evident falsă!
1.2. Abaterea individuală absolută și cea relativă
Definiții
Considerând o variabilă statistică “x” ale cărei valori observate sunt
x1,...,xn, n≥1 definim variabila abatere individuală absolută de la medie
corespunzătoare lui x ca fiind x
d =x- x deci diferența dintre valorile lui x și
media acesteia. Elementele lui dx se numesc abateri individuale absolute de la
medie.
Definim variabila abatere individuală relativă de la medie
corespunzătoare lui x ca fiind x
dr =x
dx
1 deci variabila ale cărei valori sunt
rapoartele dintre abaterile individuale absolute de la medie și media lui x. Elementele lui drx se numesc abateri individuale relative de la medie. Este
evident că x
dr %=100⋅x
dr va constitui variabila abatere individuală relativă
procentuală de la medie.
Definiții
Considerând o variabilă statistică “x” ale cărei valori observate sunt
x1,...,xn, n≥1 definim variabila abatere individuală absolută de la mediană
corespunzătoare lui x ca fiind eMd =x-Me deci diferența dintre valorile lui x și
mediana acesteia. Elementele lui eMd se numesc abateri individuale absolute
de la mediană.
Definim variabila abatere individuală relativă de la mediană
corespunzătoare lui x ca fiind eMdr =
eMe
dM
1 (dacă mediana este nenulă) deci
variabila ale cărei valori sunt rapoartele dintre abaterile individuale absolute de
la mediană și mediana lui x. Elementele lui eMdr se numesc abateri
individuale relative de la mediană. Este evident că eMdr %=100⋅
eMdr va
constitui variabila abatere individuală relativă procentuală de la mediană.

Cătălin Angelo Ioan Statistică economică
65
2. Indicatori sintetici ai variației
2.1. Abaterea medie liniară
Definiție
Considerând o variabilă statistică “x” definim abaterea medie liniară
de la medie a lui x ca fiind media modulului variabilei abatere individuală absolută de la medie.
Altfel spus, dacă variabila statistică “x” are valorile observate: x1,...,xn,
n≥1, abaterea medie liniară de la medie este:
xd =x
d =n
xxn
1ii∑
=
−
Dacă variabila statistică are frecvențele absolute:
x=
pk1
pk1
n...n...n
x...x...x atunci:
xd =x
d =
∑
∑
=
=
−
p
1ii
p
1iii
n
xxn
Dacă variabila statistică are frecvențele relative:
x=
pk1
pk1
f...f...f
x...x...x atunci
xd =x
d =
∑
∑
=
=
−
p
1ii
p
1iii
n
xxn=∑
∑=
=
−p
1iip
1jj
i xx
n
n=∑
=
−p
1iii xxf
Definiție
Considerând o variabilă statistică “x” definim abaterea medie liniară
de la mediană a lui x ca fiind media modulului variabilei abatere individuală absolută de la mediană.
Altfel spus, dacă variabila statistică “x” are valorile observate: x1,...,xn,
n≥1, abaterea medie liniară de la mediană este:
eMd =eMd =
n
Mxn
1iei∑
=
−

Cătălin Angelo Ioan Statistică economică
66
Dacă variabila statistică are frecvențele absolute:
x=
pk1
pk1
n...n...n
x...x...x atunci:
eMd =eMd =
∑
∑
=
=
−
p
1ii
p
1ieii
n
Mxn
Dacă variabila statistică are frecvențele relative:
x=
pk1
pk1
f...f...f
x...x...x atunci
eMd =eMd =
∑
∑
=
=
−
p
1ii
p
1ieii
n
Mxn=∑
∑=
=
−p
1ieip
1jj
i Mx
n
n=∑
=
−p
1ieii Mxf
2.2. Dispersia și abaterea medie pătratică
Definiție
Considerând o variabilă statistică “x” definim dispersia lui x (notată σ2
sau D) ca fiind pătratul mediei pătratice a abaterilor individuale absolute de la medie sau, altfel spus, media aritmetică a pătratelor abaterilor variabilei de la medie.
Cu alte cuvinte, dacă variabila statistică “x” are valorile observate:
x1,...,xn, n≥1, dispersia este:
σ2=( )
n
xxn
1i
2
i∑=
−
Dacă variabila statistică are frecvențele absolute:
x=
pk1
pk1
n...n...n
x...x...x atunci:
σ2=( )
∑
∑
=
=
−
p
1ii
p
1i
2
ii
n
xxn

Cătălin Angelo Ioan Statistică economică
67
Dacă variabila statistică are frecvențele relative:
x=
pk1
pk1
f...f...f
x...x...x atunci
σ2=( )
∑
∑
=
=
−
p
1ii
p
1i
2
ii
n
xxn= ( )∑
∑=
=
−p
1i
2
ip
1jj
i xx
n
n= ( )∑
=
−p
1i
2
ii xxf
Din definiția dispersiei, avem deci:
σ2=( )
n
xxn
1i
2
i∑=
−
=n
xxx2xn
1i
2n
1ii
n
1i
2i ∑∑∑
===
+−
=n
xnxx2x2n
1ii
n
1i
2i +− ∑∑
== =
2
n
1ii
n
1i
2i
xn
xx2
n
x+−
∑∑== =
22
n
1i
2i
xx2n
x+−
∑= =
2
n
1i
2i
xn
x−
∑= =
22 xx − unde 2x este
media lui x2 (media pătratelor valorilor lui x).
Dacă variabila statistică are frecvențele absolute:
x=
pk1
pk1
n...n...n
x...x...x atunci:
σ2=( )
∑
∑
=
=
−
p
1ii
p
1i
2
ii
n
xxn=
∑
∑∑∑
=
===
+−
p
1ii
p
1i
2
i
p
1iii
p
1i
2ii
n
xnxnx2xn=
2
p
1ii
p
1ii
p
1ii
p
1iii
p
1ii
p
1i
2ii
x
n
n
n
xnx2
n
xn
∑
∑
∑
∑
∑
∑
=
=
=
=
=
= +− =222 xx2x +− =
22 xx − - ca mai sus.
În mod analog, se demonstrează pentru distribuțiile cu frecvențe relative.
Dacă setul de date este împărțit în k clase de volum N1,...,Nk atunci dispersia se poate calcula astfel: se determină mediile și dispersiile pentru fiecare clasă, dispersia ansamblului fiind media ponderată a dispersiilor separate la care se adaugă dispersia mediilor parțiale față de media generală.
Avem deci (pentru fi – restricția unei variabile f la clasa i și )i(jx ,
j= iN,1 - valorile corespunzătoare ale lui fi):

Cătălin Angelo Ioan Statistică economică
68
if =i
N
1j
)i(j
N
xi
∑= , i= k,1 , f =
k1
N...N
1jj
N...N
xk1
++
∑++
= =∑∑
=
=
++
k
1i k1
i
i
N
1j
)i(j
N...N
N
N
xi
=
∑= ++
⋅k
1i k1
ii
N...N
)f(MN
și:
D(fi)=
( )
i
N
1j
2
i)i(
j
N
)f(Mxi
∑=
−
, i= k,1
Media ponderată a ansamblului dispersiilor este deci:
Dp(f)=k1
k
1iii
N...N
N)f(D
++
⋅∑=
Dispersia mediilor este:
δ(f)=( )
k1
k
1ii
2i
N...N
N)f(M)f(M
++
⋅−∑=
În final, dispersia căutată este:
Ds(f)=Dp(f)+δ(f)=( )
k1
k
1ii
2i
k1
k
1iii
N...N
N)f(M)f(M
N...N
N)f(D
++
⋅−
+++
⋅ ∑∑== =
( )∑=
+−+−++
k
1i
2i
2i
2i
2i
k1
i )f(M)f(M)f(M2)f(M)f(M)f(MN...N
N=
∑∑== ++
⋅+
++
⋅−
k
1i k1
2ii
k
1i k1
ii2
N...N
)f(MN
N...N
)f(MN)f(M2)f(M
Numim grad de determinare a structurării pe clase numărul:
R2=)f(D
)f(
s
δ
sau procentual: R2=)f(D
)f(
s
δ⋅100.

Cătălin Angelo Ioan Statistică economică
69
Acesta semnifică gradul de dependență a dispersiei în funcție de structura generală derivată din împărțirea pe clase.
De asemenea:
K2=1-R2=1-)f(D
)f(
s
δ=
)f(D
)f(D
s
p
se numește grad de nedeterminare a structurării pe clase și reprezintă gradul de dependență a dispersiei în funcție de structura internă a claselor.
Observație
În cazul unui număr redus de date, vom defini dispersia lui x ca fiind:
D(x)=( )
1N
xxN
1i
2
i
−
−∑=
Din inegalitatea dintre media aritmetică și cea pătratică, rezultă:
n
d x=
n
xxfn
1iii∑
=
−
≤
( )
n
fxxn
1i
2i
2
i∑=
−
≤
( )
n
fxxn
1ii
2
i∑=
−
=n
)x(D.
Prin urmare: xd ≤ )x(nD unde xd - abaterea medie liniară de la
medie a lui x.
Definiție
Considerând o variabilă statistică “x” definim abaterea medie pătratică a lui x ca fiind media pătratică a abaterilor individuale absolute de la medie.
Altfel spus, dacă variabila statistică “x” are valorile observate: x1,...,xn,
n≥1, abaterea medie pătratică este:
σ=
( )
n
xxn
1i
2
i∑=
−
Dacă variabila statistică are frecvențele absolute:
x=
pk1
pk1
n...n...n
x...x...x atunci:

Cătălin Angelo Ioan Statistică economică
70
σ=( )
∑
∑
=
=
−
p
1ii
p
1i
2
ii
n
xxn
Dacă variabila statistică are frecvențele relative:
x=
pk1
pk1
f...f...f
x...x...x atunci
σ=( )
∑
∑
=
=
−
p
1ii
p
1i
2
ii
n
xxn= ( )∑
∑=
=
−p
1i
2
ip
1jj
i xx
n
n= ( )∑
=
−p
1i
2
ii xxf
Observații
1. Abaterea medie pătratică este egală cu radicalul dispersiei; 2. Deoarece media pătratică este mai mare sau egală decât media aritmetică
rezultă că σ≥ xd (egalitatea având loc numai în cazul în care toate componentele sunt egale, adică în cazul variabilelor constante). Înainte de a continua să ne reamintim teorema lui Cebîșev care afirmă că fiind dată o variabilă aleatoare f şi L>0, atunci:
( )2
2 L
)f(
L
)f(DL)f(MfP
σ=≤≥− sau altfel:
( )2
L
)f(1L)f(MfP
σ−><−
Semnificația acestei teoreme este aceea (rezultând din faptul că
L)f(Mf <− ⇔ L)f(MfL)f(M +<<− ) că probabilitatea ca valorile unei
variabile aleatoare să fie în intervalul (M(f)-L, M(f)+L) este mai mare decât 2
L
)f(1
σ− . Considerând L=nσ(f) se obține faptul că probabilitatea ca valorile
unei variabile aleatoare să fie în intervalul (M(f)-nσ(f), M(f)+nσ(f)) este mai
mare decât 2n
11− . De aici, rezultă în mod evident că, odată cu creșterea lui n
probabilitatea este din ce în ce mai mare. Pe de altă parte, o valoare a lui n mare conduce la o lungime din ce în ce mai mare a intervalului de mai sus
(egală cu 2nσ(f)) ceea ce nu poate decât să ne îndepărteze de scopul analizelor probabilistice (sau statistice) de a poziționa cât mai precis valorile variabilelor aleatoare (statistice). Dacă n=1 este evident că teorema lui Cebîșev nu afirmă practic nimic important deoarece implică faptul că probabilitatea este mai mare decât 0 (ceea ce este absolut normal, din chiar definiția acesteia). Dacă n=2,

Cătălin Angelo Ioan Statistică economică
71
intervalul are lungimea 4σ(f) – rezonabilă de altfel, dar probabilitatea este mai
mare decât 1-4
1=0,75 deci peste 75% dintre valorile acesteia se vor situa între
limitele: M(f)-2σ(f) și M(f)+2σ(f). Din nou, în practică, nu este convenabil un astfel de rezultat deoarece probabilitățile situate în jurul lui 0,5 (50%) pot da naștere la concluzii contrare (fenomenul se poate întâmpla exact în aceeași măsură în care nu poate avea loc). De regulă, probabilitățile apropiate de 0 (până undeva la 0,2 – afirmație nedemonstrabilă, dar de bun simț) indică faptul că sunt puține șanse ca un fenomen să aibă loc, iar cele cu probabilități apropiate de 1 (de exemplu de la 0,8 în sus) indică faptul că sunt foarte multe șanse ca ulfenomen să aibă loc.
Dacă acum n=3, obținem P>1-9
1=0,89 și intervalul de valori: (M(f)-
3σ(f) și M(f)+3σ(f)). Regula celor 3σσσσ afirmă tocmai acest lucru și anume că în
intervalul (M(f)-3σ(f) și M(f)+3σ(f)) se vor găsi cel puțin 89% dintre valorile variabilei.
Se cuvine să facem aici o observație esențială. În cadrul teoremei lui Cebîșev, variabila f este arbitrară, neavând deci o expresie sau comportare preferențială.
În cazul distribuțiilor normale (gaussiene) se demonstrează că în
intervalul (M(f)-σ(f) și M(f)+σ(f)) se află aproximativ 68% din date, în (M(f)-
2σ(f) și M(f)+2σ(f)) – 95%, iar în (M(f)-3σ(f) și M(f)+3σ(f)) – 99,7%. Regula este cunoscută și sub numele de regula 68-95-99,7.
2.3. Coeficientul de variație
Definiție
Considerând o variabilă statistică “x” definim coeficientul de variație a
lui x (notat ν) ca fiind raportul dintre abaterea medie pătratică și media variabilei:
ν=x
σ
Observație
În situația în care nu se calculează abaterea medie pătratică, se poate
înlocui în formula de mai sus σ cu xd - abaterea medie liniară de la medie a lui
x și vom avea: x
d x
dx=ν .

Cătălin Angelo Ioan Statistică economică
72
Coeficientul de variație oferă indicii despre omogenitatea seriei statistice. Cu cât acest coeficient este mai mic, cu atât datele sunt mai grupate în jurul mediei. Dacă acest coeficient este mai mare de 35-40% se apreciază că datele trebuie defalcate pe grupe în funcție de variația altor caracteristici.
2.4. Momente
Definiții
Considerând o variabilă statistică “x” ale cărei valori observate sunt
x1,...,xp, p≥1, definim momentul inițial de ordin n al acestora ca fiind:
Mn=Mn(x)=p
x...x np
n1 ++
=p
xp
1i
ni∑
= = nx
adică media aritmetică a valorilor distribuției xn.
Considerând o variabilă statistică “x” a cărei distribuție de frecvențe
relative este: x=
pk1
pk1
f...f...f
x...x...x, p≥1, definim momentul inițial de
ordin n al lui “x” ca fiind:
Mn=Mn(x)= npp
n11 xf...xf ++ =∑
=
p
1i
nii xf = nx
adică media valorilor distribuției xn.
În cazul în care variabila este dată prin intermediul frecvențelor
absolute: x=
pk1
pk1
n...n...n
x...x...x, p≥1, din faptul că fk=
∑=
p
1ii
k
n
n, k= p,1
definim momentul inițial de ordin n al lui “x” ca fiind:
Mn=Mn(x)=p1
npp
n11
n...n
xn...xn
++
++=
∑
∑
=
=
p
1ii
p
1i
nii
n
xn= nx
adică media valorilor distribuției xn.
Observație
Din definițiile de mai sus, se observă că pentru n=1 se obține tocmai definiția mediei unei variabile statistice.
Definiții

Cătălin Angelo Ioan Statistică economică
73
Considerând o variabilă statistică “x” ale cărei valori observate sunt
x1,...,xp, p≥1 și un număr arbitrar α∈R, definim momentul ordinar de ordin n
relativ la αααα al acestora ca fiind:
Mn,α=Mn,α(x)=( ) ( )
p
x...x np
n1 α−++α−
=( )
p
xp
1i
ni∑
=
α−
= ( )nx α−
adică media aritmetică a valorilor distribuției (x-α)n.
Considerând o variabilă statistică “x” a cărei distribuție de frecvențe
relative este: x=
pk1
pk1
f...f...f
x...x...x, p≥1 și un număr arbitrar α∈R,
definim momentul ordinar de ordin n relativ la αααα al acestora ca fiind:
Mn,α=Mn,α(x)= ( ) ( )npp
n11 xf...xf α−++α− = ( )∑
=
α−p
1i
nii xf = ( )nx α−
adică media valorilor distribuției (x-α)n.
În cazul în care variabila este dată prin intermediul frecvențelor
absolute: x=
pk1
pk1
n...n...n
x...x...x, p≥1, α∈R, din faptul că fk=
∑=
p
1ii
k
n
n, k= p,1
definim momentul ordinar de ordin n relativ la αααα al lui “x” ca fiind:
Mn,α=Mn,α(x)=( ) ( )
p1
npp
n11
n...n
xn...xn
++
α−++α−=
( )
∑
∑
=
=
α−
p
1ii
p
1i
nii
n
xn= ( )nx α−
adică media valorilor distribuției (x-α)n.
Definiții
Considerând o variabilă statistică “x” ale cărei valori observate sunt
x1,...,xp, p≥1, definim momentul centrat de ordin n al acestora ca fiind:
µn=µn(x)=( ) ( )
p
xx...xxn
p
n
1 −++−=
( )
p
xxp
1i
n
i∑=
−
= ( )nxx −
adică media aritmetică a valorilor distribuției (x- x )n.

Cătălin Angelo Ioan Statistică economică
74
Considerând o variabilă statistică “x” a cărei distribuție de frecvențe
relative este: x=
pk1
pk1
f...f...f
x...x...x, p≥1 și un număr arbitrar α∈R,
definim momentul centrat de ordin n al acestora ca fiind:
µn=µn(x)= ( ) ( )n
pp
n
11 xxf...xxf −++− = ( )∑=
−p
1i
n
ii xxf = ( )nxx −
adică media valorilor distribuției (x- x )n.
În cazul în care variabila este dată prin intermediul frecvențelor
absolute: x=
pk1
pk1
n...n...n
x...x...x, p≥1, α∈R, din faptul că fk=
∑=
p
1ii
k
n
n, k= p,1
definim momentul centrat de ordin al lui “x” ca fiind:
µn=µn(x)=( ) ( )
p1
n
pp
n
11
n...n
xxn...xxn
++
−++−=
( )
∑
∑
=
=
−
p
1ii
p
1i
n
ii
n
xxn= ( )n
xx −
adică media valorilor distribuției (x- x )n.
Observații
1) Pentru n=1, momentul centrat de ordin 1 este nul, deoarece
µ1= xx − = xx − =0;
2) Pentru n=2, momentul centrat de ordin 2 este tocmai dispersia, deci µ2=σ2.
2.5. Coeficientul Gini
Statisticianul și sociologul italian Corrado Gini, analizând inegalitățile privind veniturile într-o societate a propus un indicator care să măsoare cât mai fidel împrăștierea datelor statistice.
Definiții
Considerând o variabilă statistică “x” cu frecvențele relative date prin
distribuția: x=
pk1
pk1
f...f...f
x...x...x, p≥1, definim coeficientul Gini al
acestora ca fiind:

Cătălin Angelo Ioan Statistică economică
75
G=x2
xxffp
1j,ijiji∑
=
−
=
∑
∑
=
=
−
p
1j,iii
p
1j,ijiji
xf2
xxff
=
∑
∑
=
<=
−
p
1j,iii
p
ji1j,i
jiji
xf
xxff
Dacă variabila statistică “x” are valorile observate: x1,...,xp, p≥1, atunci:
G=
∑
∑
=
=
−
p
1j,ii
p
1j,iji2
xp
2
xxp
1
=
∑
∑
=
=
−
p
1j,ii
p
1j,iji
xp2
xx
Se poate observa că, spre deosebire de restul indicatorilor (medie, abatere medie pătratică etc.) coeficientul Gini ține seama de toate diferențele dintre datele statistice.
Sarcina de lucru 5
Să considerăm două grupe de studenți care, în urma examenului de statistică au obținut următoarele rezultate:
Nota Grupa 1 Grupa 2
Frecvența absolută Frecvența absolută
3 1 2
4 2 1
5 5 3
6 4 7
7 3 8
8 7 6
9 1 4
10 2 1
Să se calculeze coeficientul Gini.

Cătălin Angelo Ioan Statistică economică
76
2.6. Corelația și coeficientul de corelație
Considerând două variabile statistice f și g cu distribuțiile:
f=
ννν n21
n21 xxx
L
L, g=
ηηη n21
n21 yyy
L
L
se numeşte corelația sau covarianța lui f și g:
Cfg=( )( )
n
gyfxn
1iii∑
=
−−
Avem:
Cfg= ( )∑=
+−−n
1iiiii gffygxyx
n
1= ∑
=
n
1iii yx
n
1- g
n
xn
1ii∑
= - fn
yn
1ii∑
= + f g =
∑=
n
1iii yx
n
1- f g - f g + f g = ∑
=
n
1iii yx
n
1- f g = ∑
=
n
1iii yx
n
1-
2
n
1ii
n
1ii
n
yx ∑∑== =
2
n
1ii
n
1ii
n
1iii
n
yxyxn ∑∑∑===
−
.
Definim coeficientul de corelație dintre f și g:
ρfg=)g()f(
C fg
σσ
Din formulele de mai sus, rezultă:
ρfg=2n
1ii
n
1i
2i
2n
1ii
n
1i
2i
2
n
1ii
n
1ii
n
1iii
n
y
n
y
n
x
n
x
n
yxyxn
−
−
−
∑∑∑∑
∑∑∑
====
===
=
2n
1ii
n
1i
2i
2n
1ii
n
1i
2i
n
1ii
n
1ii
n
1iii
yynxxn
yxyxn
−
−
−
∑∑∑∑
∑∑∑
====
===

Cătălin Angelo Ioan Statistică economică
77
Ca și în teoria probabilităților se arată că ρfg∈[-1,1], valorile lui ρ apropiate de 1 sau -1 indicând o legătură puternică directă, respectiv inversă între variabilele statistice f și g.
3. Indicatori ai aspectului distribuției
3.1. Variații intercuartilice, decilice și centilice
Fie o variabilă statistică “x” cu frecvențele relative date prin distribuția:
x=
pk1
pk1
f...f...f
x...x...x unde x1<...<xk<...<xp sau x1>...>xk>...>xp.
Dacă seria de date este absolut simetrică având forma (pentru p=2s+1=impar, pentru p=par procedându-se analog):
=
++
++
1s2q1sk1
1s2q1sk1
f...f...f...f...f
x...x...x...x...xx
unde: f1=f2s+1, f2=f2s,... (la modul general: fk=f2s+2-k, k= s,1 ), iar xk=xs+1-(s+1-
k)h, k= s,1 , xk=xs+1+(k-s-1)h, k= 1s2,2s ++ , h≠0 (termenii seriei sunt egal
depărtați față de cei anteriori, unde i-am exprimat în funcție de valoarea centrală pentru a simplifica toate calculele) atunci (reamintind faptul că
1f1s2
1kk =∑
+
=
):
x = ∑∑+
+=++
=
++1s2
2sjjj1s1s
s
1iii xfxfxf =
( )( ) ( )( )i1sj1s2
2sj1sj1s1s
s
1i1si h1sjxfxfhi1sxf
++=+
+=+++
=+ =−−+++−+− ∑∑
( )( ) ( )∑∑=
+++++=
+ +++−+−s
1i1si1s1s1s
s
1i1si ihxfxfhi1sxf =
( ) ( ) 1s1s
s
1ii1si1si1si xfihfhi1sfxff ++
=+++++ ++−+−+∑ =
( ) ( ) 1s1s
s
1ii1si1si1si xfihfhi1sfxff ++
=−++++ ++−+−+∑ =
( ) ( ) ( ) 1s1s
s
1jj
s
1ii
s
1ii1si1s xfj1sfhi1sfhffx ++
===+++ +−++−+−+ ∑∑∑ =

Cătălin Angelo Ioan Statistică economică
78
1s1s
s
1ii1s
s
1ii1s xfffx ++
=++
=+ +
+∑∑ = ( ) 1s1s1s1s xff1x ++++ +− = 1sx + .
Cum mediana reprezintă acea valoare a caracteristicii pentru care
2
1ffejei Mx
jMx
i == ∑∑≥≤
, iar, în cazul de față: ∑+
=
1s
1iif = ∑
+
+=
1s2
2siif rezultă că Me=xs+1.
Observăm deci că, pentru o serie de date absolut simetrică valoarea
medie x și mediana Me sunt egale.
Am văzut mai sus, de asemenea, că determinarea cuartilelor se face
prin formulele: 4
1f
1i Qxi =∑
≤
, 2
1f
2i Qxi =∑
≤
, 4
3f
3i Qxi =∑
≤
. În mod analog
demonstrației de mai sus, se arată că în cazul unei serii de date absolut
simetrice, în intervalele
=1
p,1ii Q,xmin , [ ]21 Q,Q , [ ]32 Q,Q și
= p,1ii3 xmax,Q se
găsesc exact 25% dintre valorile variabilei statistice. Același lucru se întâmplă și în cazul considerării decilelor sau centilelor (cu procentele de 10%, respectiv 1%).
Ca urmare a acestor considerații avem relațiile (pentru o serie de date absolut simetrică):
• Me-Q1=Q3-Me (din faptul că Me=Q2); • Me-D1=D9-Me (din faptul că Me=D5); • Me-C1=C99-Me (din faptul că Me=C50).
În situația în care relațiile de mai sus nu au loc, rezultă că datele prezintă o asimetrie.
Definiție
Se numește abatere intercuartilică media aritmetică a diferențelor dintre cuartilele consecutive:
( ) ( )2
MQQMQ e31e
d
−+−=
Din definiție, rezultă că: 2
QQQ 13
d
−= .
Cum abaterea intercuartilică este un indicator absolut, depinzând de ordinul de mărime al valorilor variabilei statistice, rezultă că el nu poate fi folosit în cadrul acțiunii de comparare a mai multor seri statistice.

Cătălin Angelo Ioan Statistică economică
79
Definiție
Se numește coeficient de variație intercuartilică raportul dintre abaterea intercuartilică și mediană:
e
dq M
QV =
Avem deci:
e
13q M2
QQV
−= =
2
13
Q2
QQ −
Din definiție, rezultă că o valoare mai mică a coeficientului de variație intercuartilică indică o tendință de simetrie a datelor mai mare.
În mod analog, avem:
Definiție
Se numește abatere interdecilică media aritmetică:
( ) ( )2
MDDMD e91e
d
−+−=
Din definiție, rezultă că: 2
DDD 19
d
−= .
Definiție
Se numește coeficient de variație interdecilică raportul dintre abaterea interdecilică și mediană:
e
dd M
DV =
Avem deci:
e
19d M2
DDV
−= =
5
19
D2
DD −
Definiție
Se numește abatere intercentilică media aritmetică:
( ) ( )2
MCCMC e991e
d
−+−=

Cătălin Angelo Ioan Statistică economică
80
Din definiție, rezultă că: 2
CCC 199
d
−= .
Definiție
Se numește coeficient de variație intercentilică raportul dintre abaterea intercentilică și mediană:
e
dc M
CV =
Avem deci:
e
199c M2
CCV
−= =
50
199
C2
CC −
În mod evident, variațiile interdecilice, respectiv intercentilice se folosesc atunci când există o asimetrie mare a datelor.
Sarcina de lucru 6
Să considerăm două grupe de studenți care, în urma examenului de statistică au obținut următoarele rezultate:
Nota Grupa 1 Grupa 2
Frecvența absolută Frecvența absolută
3 1 2
4 2 1
5 5 3
6 4 7
7 3 8
8 7 6
9 1 4
10 2 1
Să se studieze cu ajutorul coeficientului de variație intercuartilică simetria celor două distribuții.

Cătălin Angelo Ioan Statistică economică
81
3.2. Coeficienți de asimetrie
Pentru determinarea gradului în care o distribuție a unei variabile statistice se abate de la condiția de simetrie, în principiu s-ar putea trasa graficul acesteia (de exemplu, poligonul frecvențelor) și vizualizarea deplasării lui spre stânga (caz în care predomină valorile mici, iar seria statistică se spune că are asimetrie pozitivă) sau spre dreapta (caz în care predomină valorile mari, iar seria statistică se spune că are asimetrie negativă). Metoda nu este infailibilă din mai multe motive. Primul ar fi acela că, în cazul seturilor mari de date, graficul poate avea o complexitate mare și atunci va fi foarte dificil de apreciat vizual. Pe de altă parte, la seturi de date diferite, aspectul graficelor poate fi relativ asemănător, dar totuși asimetria să fie mai pronunțată în cazul unuia sau altuia.
În cazul distribuțiilor structurate pe intervale, se poate defini densitatea
de distribuție a frecvențelor:
• absolută: da=k
k
lung
n în situația frecvenței absolute corespunzătoare unui
interval de lungime lungk;
• relativă: dr=k
k
lung
f în situația frecvenței relative corespunzătoare unui interval
de lungime lungk. Din nou, în cazul seturilor lungi de date, acești indicatori nu oferă
informații suficiente pentru aprecierea formei distribuției.
Definiție
Se numește coeficient neparametric de asimetrie raportul:
σ
−= e
as
MxC
unde x - media variabilei, Me – mediana, iar σ - abaterea medie pătratică a acesteia.
Observație
Coeficientul de asimetrie ia valori în intervalul [-1,1]. O valoare absolută a acestuia cât mai apropiată de zero indică o asimetrie cât mai mică. Pe de altă parte, o valoare pozitivă a lui Cas (corespunzătoare inegalității
eMx > ) indică o deplasare spre stânga a datelor statistice. O valoare negativă
a lui Cas (corespunzătoare inegalității eMx < ) indică o deplasare spre dreapta
a datelor statistice.

Cătălin Angelo Ioan Statistică economică
82
Definiție
Se numește primul coeficient de asimetrie raportul:
σ
−= o1
as
MxC
unde x - media variabilei, Mo – modul, iar σ - abaterea medie pătratică a acesteia.
Observație
Acest prim coeficient de asimetrie (introdus de către Karl Pearson în anul 1895 în care valoarea modală este însă uneori dificil de determinat în cazul variabilelor simple) ia valori în intervalul [-1,1]. O valoare absolută a acestuia cât mai apropiată de zero indică o asimetrie cât mai mică. Pe de altă
parte, o valoare pozitivă a lui Cas (corespunzătoare inegalității oMx > ) indică
o deplasare spre stânga a datelor statistice. O valoare negativă a lui Cas
(corespunzătoare inegalității oMx < ) indică o deplasare spre dreapta a datelor
statistice.
Pentru repartițiile de frecvențe ce prezintă asimetrii moderate, are loc următoarea relație:
Mo- x ≈3(Me- x )
Înlocuind în definiția primului coeficient de asimetrie, obținem:
Definiție
Se numește al doilea coeficient de asimetrie raportul:
σ
−=
xM3C e2
as
unde x - media variabilei, Me – mediana, iar σ - abaterea medie pătratică a acesteia.
Definiție
Se numește coeficient de asimetrie ββββ1 (sau coeficientul lui Pearson de
asimetrie) raportul:
β1= 32
23
µ
µ
unde µ2 și µ3 sunt momentele centrate de ordin 2 (dispersia), respectiv de ordin 3.

Cătălin Angelo Ioan Statistică economică
83
Definiție
Se numește coeficient de asimetrie γγγγ1 (sau coeficientul lui Fisher de
asimetrie) raportul:
γ1=32
3
µ
µ
unde µ2 și µ3 sunt momentele centrate de ordin 2 (dispersia), respectiv de ordin 3.
Observație
Spre deosebire de coeficientul Pearson a cărui valoare este întotdeauna pozitivă, coeficientul Fisher va indica și sensul asimetriei setului de date statistice.
Definiție
Se numește coeficient Yule-Kendall:
B1=13
231
Q2QQ
−
−+
unde Q1,Q2 și Q3 sunt cuartilele corespunzătoare unei variabile statistice.
Observație
1) Să remarcăm faptul că pentru date pozitive: -1<B1<1. Într-adevăr, -1<B1 ⇔
13
231
Q2QQ1
−
−+<− ⇔ -Q3+Q1<Q1+Q3-2Q2 ⇔ Q2<Q3 – adevărat. De
asemenea: 1>B1 ⇔ 13
231
Q2QQ1
−
−+> ⇔ Q3-Q1>Q1+Q3-2Q2 ⇔ Q2>Q1 –
adevărat.
2) B1=0 implică faptul că distribuția este simetrică;
3) B1>0 implică existența unei asimetrii stângi;
4) B1<0 implică existența unei asimetrii drepte.
3.3. Coeficienți de aplatizare
Cum legea normală a lui Gauss stă la baza multor fenomene reale, dar și teoretice, se pune problema analizării comportării distribuției unei variabile statistice în raport cu aceasta.

Cătălin Angelo Ioan Statistică economică
84
Pe lângă asimetrie, de o importanță fundamentală este aplatizarea repartițiilor de frecvențe.
Definiție
Se numește coeficient de aplatizare ββββ2 (sau coeficientul lui Pearson de
aplatizare) raportul:
β2= 22
4
µ
µ
unde µ2 și µ4 sunt momentele centrate de ordin 2 (dispersia), respectiv de ordin 4.
Definiție
Se numește coeficient de aplatizare γγγγ2 (sau coeficientul lui Fisher de
aplatizare) raportul:
γ2=β2-3=22
4
µ
µ-3
unde µ2 și µ4 sunt momentele centrate de ordin 2 (dispersia), respectiv de ordin 4.
Observație
1) În cazul distribuției normale, β2=3, γ2=0;
2) Dacă β2>3 sau γ2>0 atunci distribuția are un vârf mai ascuțit decât cea normală, numindu-se leptokurtică (gr. leptos=subțire, kurtos=cocoșat)7;
3) Dacă β2<3 sau γ2<0 atunci distribuția are un vârf mai neted decât cea normală, numindu-se platikurtică (gr. platys=lat, kurtos=cocoșat);
4) Dacă β2=3 sau γ2=0 atunci distribuția este asemănătoare celei normale din punctul de vedere al aplatizării, numindu-se mezokurtică (gr. mesa=mijloc, kurtos=cocoșat).
4. Concentrarea distribuțiilor de frecvențe
Concentrarea distribuțiilor de frecvențe reprezintă situața aglomerării valorilor unei caracteristici în jurul unui indicator central.
Prima metodă de determinare a concentrării distribuțiilor presupune construirea curbei de concentrare Lorentz-Gini.
7 Isaic-Maniu A., Mitruț C., Voineagu V., Statistică, Editura Universitară, București, 2004
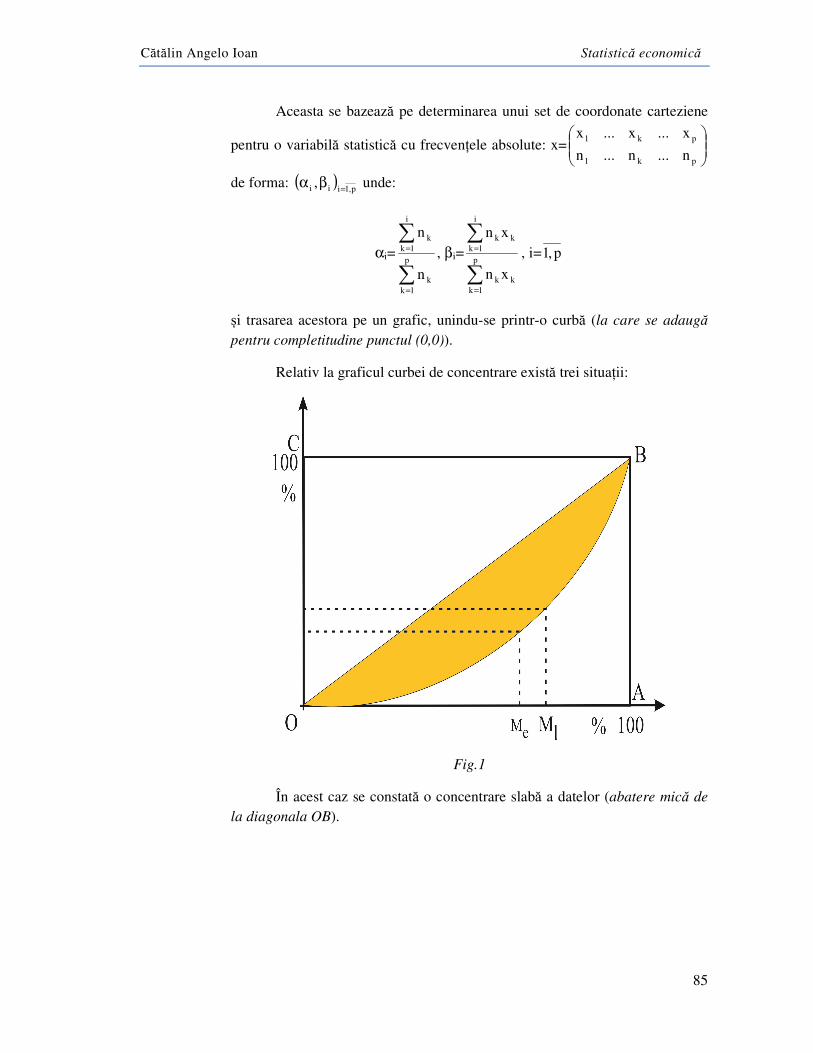
Cătălin Angelo Ioan Statistică economică
85
Aceasta se bazează pe determinarea unui set de coordonate carteziene
pentru o variabilă statistică cu frecvențele absolute: x=
pk1
pk1
n...n...n
x...x...x
de forma: ( ) p,1iii , =βα unde:
αi=
∑
∑
=
=
p
1kk
i
1kk
n
n, βi=
∑
∑
=
=
p
1kkk
i
1kkk
xn
xn, i= p,1
și trasarea acestora pe un grafic, unindu-se printr-o curbă (la care se adaugă pentru completitudine punctul (0,0)).
Relativ la graficul curbei de concentrare există trei situații:
Fig.1
În acest caz se constată o concentrare slabă a datelor (abatere mică de la diagonala OB).
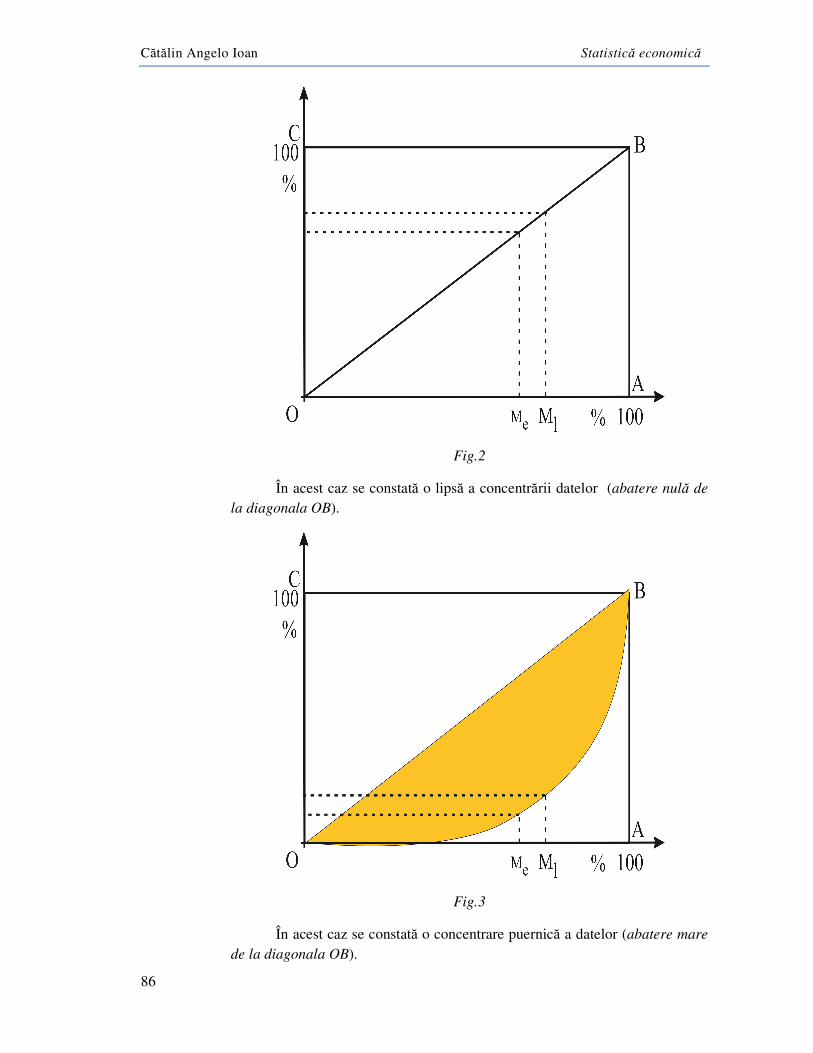
Cătălin Angelo Ioan Statistică economică
86
Fig.2
În acest caz se constată o lipsă a concentrării datelor (abatere nulă de la diagonala OB).
Fig.3
În acest caz se constată o concentrare puernică a datelor (abatere mare de la diagonala OB).

Cătălin Angelo Ioan Statistică economică
87
Pentru a obține un indicator numeric aferent curbei de concentrare Lorentz-Gini, vom defini indicele de concentrare Gini ca fiind:
IG=OAB aria
econcentrar de rafatasup
unde suprafața de concentrare este aria cuprinsă între curba de concentrare și diagonala pătratului OABC. Considerând latura acestuia egală cu 1 obținem:
IG= econcentrar de rafatasup2 ⋅
Cum aria suprafeței de concentrare este dificil de calculat, vom considera aria suprafeței cuprinsă între graficul curbei și axa orizontală (notată cu A) și deci:
IG=
− A
2
12 =1-2A
Dar, aria A se poate calcula aproximativ cu metoda trapezelor,
descompunându-se în trapezele Ti determinate de punctele (0,αi), (0,αi+1),
(αi+1,βi+1), (αi,βi), i= p,0 unde αi=βi=0.
Vom avea deci aria(Ti)= ( )i1i1ii
2α−α
β+β+
+ de unde:
IG=1- ( )( )∑−
=++ β+βα−α
1p
0i1iii1i
Ținând seama de formulele lui αi, respectiv βi avem:
IG=1- ∑∑
∑
∑
∑
∑
∑
∑
∑
∑∑
−
=
=
+
=
=
=
=
=
=
+
=
==
+
−−1p
1ip
1kkk
1i
1kkk
p
1kkk
i
1kkk
p
1kk
i
1kk
p
1kk
1i
1kk
p
1kkk
11p
1kk
1
xn
xn
xn
xn
n
n
n
n
xn
xn
n
n=
1- ∑∑∑
∑
∑∑
−
=
==
=+++
==
+
−1p
1ip
1kkk
p
1kk
i
1kkk1i1i1i
p
1kkk
p
1kk
121
xnn
xn2xnn
xnn
xn=
1-
∑∑
∑ ∑
==
−
= =+++
++
p
1kkk
p
1kk
1p
1i
i
1kkk1i1i1i1
21
xnn
xn2xnnxn
=1-
∑∑
∑ ∑∑
==
−
= =+
=
+
p
1kkk
p
1kk
1p
1i
i
1kkk1i
p
1ii
2i
xnn
xnn2xn

Cătălin Angelo Ioan Statistică economică
88
deci:
IG=1-
∑∑
∑ ∑∑
==
−
= =+
=
+
p
1kkk
p
1kk
1p
1i
i
1kkk1i
p
1ii
2i
xnn
xnn2xn
Un alt indicator de concentrare este abaterea dintre medială și
mediană. Definim:
∆M=Ml-Me
O valoare mare a lui ∆M indică o concentrare mai mare a datelor, pe când o valoare nulă implică faptul că distribuția este egalitară.
Cum ∆M se exprimă în unitățile de măsură ale datelor statistice (putând fi oricât de mare sau de mic) se preferă considerarea coeficientului de
concentrare definit prin:
∆rM=xA
M∆=
in,1i
in,1i
xminxmax
M
==−
∆
unde reamintim că Ax reprezintă amplitudinea absolută a variației lui x. Procentual avem:
∆M%=∆rM⋅100=xA
M100
∆⋅ =
in,1i
in,1i
xminxmax
M100
==−
∆⋅
Din definiție rezultă deci că ∆rM∈[0,1] (respectiv ∆M%∈[0,100]) și cu cât valorile acestor indicatori sunt mai apropiate de 0 cu atât concentrarea datelor este mai slabă, iar dacă indicatorul se apropie de 1 (respectiv 100) concentrarea datelor este mai puternică.
Un alt indicator este coeficientul abaterii medii Gini. El se definește ca fiind:
G=x2
D m
unde x este media variabilei statistice x, iar Dm reprezintă diferența medie calculată astfel:
• pentru o variabilă statistică “x” ale cărei valori observate sunt x1,...,xp, p≥1,
Dm=2
p
1iMei
p
riMx4e∑
=
−⋅−
unde eMr - rangul medianei în setul de date;

Cătălin Angelo Ioan Statistică economică
89
• pentru o variabilă statistică “x” a cărei distribuție de frecvențe absolute corespunzătoare intervalelor de lungimi egale: I1,...,Ip este:
x=
pk1
pk1
n...n...n
x...x...x (unde x1,...,xp sunt centrele intervalelor respective),
p≥1, Dm=2
p
1i
i
1kk
p
1kk
i
1kk
p
nnns2 ∑ ∑∑∑= ===
−
=
2
p
1i
p
1ikk
i
1kk
p
nns2 ∑ ∑∑= +==
⋅
unde s reprezintă lungimea intervalelor de variație I1,...,Ip.
Se arată că G∈[0,1], iar cu cât valorile lui G sunt mai apropiate de 0 cu atât concentrarea datelor este mai slabă, iar dacă indicatorul se apropie de 1, concentrarea datelor este mai puternică.
Test de autoevaluare 1. Studenții unei grupe, în urma examenului la disciplina matematică, au obținut următoarele rezultate:
Nota Frecvența absolută
3 1
Rezumat Considerând o variabilă statistică “x” ale cărei valori observate sunt x1,...,xn,
n≥1 definim amplitudinea absolută a variației lui x ca fiind
Ax= in,1i
in,1i
xminxmax==
− deci diferența dintre cea mai mare valoare a lui x și cea
mai mică.
Considerând o variabilă statistică “x” definim abaterea medie liniară de la
medie a lui x ca fiind media modulului variabilei abatere individuală absolută de la medie.
Considerând o variabilă statistică “x” definim dispersia lui x (notată σ2 sau D) ca fiind pătratul mediei pătratice a abaterilor individuale absolute de la medie sau, altfel spus, media aritmetică a pătratelor abaterilor variabilei de la medie.
Considerând o variabilă statistică “x” definim coeficientul de variație a lui x
(notat ν) ca fiind raportul dintre abaterea medie pătratică și media variabilei:
ν=x
σ

Cătălin Angelo Ioan Statistică economică
90
4 2
5 1
6 4
7 6
8 8
9 4
10 2
Să se calculeze coeficientul neparametric de asimetrie. 2. Studenții unei grupe, în urma examenului la disciplina statistică, au obținut următoarele rezultate:
Nota Frecvența absolută
3 1
4 2
5 5
6 4
7 6
8 7
9 3
10 1
Să se calculeze coeficienții de asimetrie β1 și γ1. Răspunsuri şi comentarii la întrebările din testul de autoevaluare
1- Coeficientul neparametric de asimetrie este: asC =-0,46
2- ββββ1=32
23
µ
µ
=0,054, γγγγ1=32
3
µ
µ
=-0,232
Bibliografie minimală Ioan C.A., ȘANSA – ÎNTRE FINIT ȘI INFINIT. Teoria probabilităților și Statistică, Editura Zigotto, Galați, 2017 Biji E.M., Lilea E., Roșca E., Vătui M., Statistică pentru economiști, Editura Economică, București, 2010 Isaic-Maniu A., Mitruț C., Voineagu V., Statistică, Editura Universitară, București, 2004

Cătălin Angelo Ioan Statistică economică
91
5. SONDAJUL STATISTIC
SONDAJUL STATISTIC 91
Rezumat 99
Test de autoevaluare 99
Răspunsuri la întrebările din testele de autoevaluare 100
Bibliografie minimală 100
Obiective în termeni de competențe specifice:
La sfârşitul modulului, se va şti: faptul că principalele tipuri de sondaje sunt:
• Sondajele aleatoare; • Sondajele dirijate; • Sondajele sistematice.
La rândul lor, sondajele aleatoare pot fi:
• sondaje simple; • sondaje stratificate; • sondaje de serii; • sondaje secvențiale; • sondaje în trepte.
Timp mediu estimat pentru studiu individual: 2 ore
În acțiunea de colectare a informațiilor un rol principal îl au sondajele statistice. Acestea presupun selectarea unu eșantion al populației investigate și apoi, după prelucrare, extrapolarea concluziilor la nivelul întregii colectivități.
Este evident faptul că o selectare eronată a eșantionului va conduce la distorsiuni mari ale concluziilor în raport cu realitatea care, adunate și cu erorile inerente ce apar în cadrul proceselor de colectare, pot conduce la viitoare decizii nerealiste.
Principalele tipuri de sondaje sunt:
• Sondajele aleatoare; • Sondajele dirijate;

Cătălin Angelo Ioan Statistică economică
92
• Sondajele sistematice. La rândul lor, sondajele aleatoare pot fi:
• sondaje simple; • sondaje stratificate; • sondaje de serii; • sondaje secvențiale; • sondaje în trepte.
În cadrul oricărui tip de sondaj, selectarea eșantionului poate fi realizată “cu repetiție” atunci când unitatea investigată este introdusă la loc în populație, putând fi eventual reselectată sau “fără repetiție” atunci când unitatea investigată este exclusă din populație, nemaiputând fi reselectată. Pentru a înțelege mai bine acest lucru, gândiți-vă la un controlor de calitate într-o fabrică. Dacă el se află în fața unei cutii cu piese și ia la întâmplare câte una, o măsoară și apoi pune la loc în cutie atunci selecția este repetată, dar dacă o pune într-un loc separat de celelalte piese atunci selecția va fi nerepetată. Este evident că, dacă populația statistică este de dimensiuni mari, posibilitatea de a alege de două ori același element este practic nulă, deci selecția se poate face repetat, cea nerepetată fiind, de regulă, mult mai lentă (culegerea unor elemente de identificare etc.). Dacă însă populația statistică este de dimensiuni relativ mici, selecția este aproape obligatoriu să fie nerepetată.
Ca și procedee de alegere a eșantioanelor pot fi remarcate cele de tip urnă în care extragerea unităților se face la întâmplare, dar după un anumit criteriu. Ca exemplu, am putea considera o echipă de baschet aleasă de către un profesor în prima lui zi de activitate. În acest caz, el va alege, de exemplu, toți băieții cu înălțimi de peste 1,80 m, le va scrie numele pe niște bilețele și apoi va extrage dintr-o urnă oarecare numărul de componenți ai echipei. Un alt procedeu poate fi cel al numerelor aleatoare în care unitățile sunt alese pe baza unui număr perfect arbitrar. Există în acest sens, tabele cu numere aleatoare (atenție, funcțiile de numere aleatoare furnizate de computere urmează o anumită regulă, deci nu sunt decât aparent la întâmplare!) obținute prin diverse procedee. O ultimă metodă de alegere este aceea a selectării unităților statistice la intervale de timp bine stabilite sau după un pas prestabilit. De exemplu, se pot alege unitățile din 100 în 100 sau în alte moduri.
Odată ales un eșantion se pune problema reprezentativității acestuia pentru colectivitatea statistică.
Să presupunem deci că avem o colectivitate generală structurată după un anumit criteriu și a cărei componență este de forma:

Cătălin Angelo Ioan Statistică economică
93
Criteriu Număr absolut
C1 N1
... ...
Cq Nq
Vom considera o selecție teoretică a datelor de p% din populația totală. Aceasta va avea deci structura:
Criteriu frecvența absolută
C1 100
pN 1 ⋅=n1
... ...
Cq 100
pN q ⋅=nq
Dacă vom considera o selecție arbitrară, dar care să aibă același volum
al datelor: ∑=
q
1iin cu frecvențele absolute m1,...,mq vom calcula abaterile de
structură di=mi-ni. În mod evident: ( ) 0nmnmdq
1ii
q
1ii
q
1iii
q
1ii =−=−= ∑∑∑∑
====
. Din
acest motiv, vom calcula suma abaterilor absolute de structură:
∑∑==
−=q
1iii
q
1ii nmd .
Se calculează coeficientul de realizare a structurii colectivității de selecție astfel:
K=
∑
∑
=
=
−
q
1ii
q
1iii
n
nm
Cu cât acest coeficient este mai apropiat de 0 rezultă că selecția este mai reprezentativă.
Eșantioanele de date se consideră reprezentative dacă erorile nu diferă mai mult de ±5%. În cazul de față, se observă că eșantionul 1 se încadrează bine în această condiție (1,9%).

Cătălin Angelo Ioan Statistică economică
94
Dacă nu dispunem de date relativ la structura exactă a colectivității, atunci se aleg mai multe eșantioane pentru a verifica în ce măsură media și abaterea medie pătratică sunt stabile. În acest caz, eroarea de eșantionare se va calcula ca diferență dintre media eșantionului și media tuturor mediilor eșantioanelor.
Revenind la problema eșantionării, să considerăm o selecție de “n” unități dintr-o populație statistică de volum N pentru care se obțin valorile
caracteristicii: x1,...,xn. Calculând media: n
xx
n
1ii∑
== și abaterea medie
pătratică: σ=( )
n
xxn
1i
2
i∑=
−
este evident faptul că la schimbarea eșantionului
este foarte probabil ca să se obțină rezultate diferite. Mai mult, cum eșantionul
nu reprezintă întreaga populație, acestea vor diferi de valorile exacte 0x ,
respectiv σ0.
Pentru a putea fi extinși la întreaga populație statistică (și deci a fi caracteristici pentru fenomenul studiat) indicatorii trebuie ca să satisfacă condițiile teoretice de a fi:
• estimații nedeplasate – adică valoarea medie x = 0x ; • consistente – adică indicatorul de sondaj să conveargă în probabilitate către cel
teoretic (corespunzător populației în ansamblu). Aceasta înseamnă că pentru o valoare a lui “n” mare, probabilitatea ca diferența absolută dintre indicatorul de sondaj și cel teoretic să fie mai mică decât un anumit prag tinde la 1;
• eficiente – adică abaterea medie pătratică a rezultatelor să fie minimă. Eficiența constă deci în faptul că un eșantion 1 va fi mai eficient decât un
eșantion 2 dacă 21 xx = și σ1<σ2. Ca urmare a acestor considerații putem vedea că valorile indicatorilor
din sondaje nu sunt decât valori aproximative ale celor reale. Prin urmare, în finalul analizei statistice nu se obțin rezultate exacte, ci intervale de valori care cuprind expresia “adevărată” a indicatorului. Intervalele de valori se numesc în
statistică: intervale de încredere (sau de estimație) și sunt de forma: (βs,βd).
Considerând un număr α∈[0,1], îl vom numi nivel de semnificație, iar P=1-α se va numi nivel de încredere. Intervalul de încredere va trebui ca să satisfacă
condiția (pentru indicatorul β):
P(βs<β<βd)=1-α
De regulă, nivelurile de încredere acceptate în analizele statistice sunt: 0,900; 0,950; 0,990 sau 0,999.

Cătălin Angelo Ioan Statistică economică
95
Trebuie remarcat faptul că lungimea intervalului de încredere: βd-βs este fundamentală, deoarece odată cu creșterea nivelului de încredere, crește și lungimea acestuia, deci și imprecizia rezultatelor.
1. Sondajul aleator simplu Un sondaj aleator simplu constă în faptul că orice unitate a populației
statistice poate fi inclusă cu aceeași probabilitate în eșantionul considerat.
Pentru un număr de k unităţi ale populaţiei investigate, fie fk – variabila aleatoare ce descrie rezultatele sondajului. Prin urmare, pentru un eșantion de volum n se va obține șirul de variabile aleatoare: V=(f1,...,fn) numit și vector
aleator de selecție. Pentru valori de selecție arbitrare xk ale variabilelor fk,
k= n,1 se obține un eșantion de valori ale lui f. Totalitatea n-uplelor posibile (în
urma atribuirii tuturor combinațiilor de valori ale lui fk) formează așa-numitul spațiu observațional.
Vom impune în cele ce urmează vectorilor aleatori de selecție ca toate componentele acestuia să fie independente între ele și să aibă aceeași repartiție cu variabila observabilă f.
Considerând un vector aleator de selecție, orice funcție continuă de componentele acestuia se numește funcție de selecție sau statistică.
Principalele funcții de selecție utilizate în statistică sunt8:
• Media: n
f...ff n1 ++
= ;
• Dispersia (varianța): σ2=( )
n
ffn
1k
2
k∑=
−
;
• Abaterea pătratică medie: σ=( )
n
ffn
1k
2
k∑=
−
;
• Varianța pentru volum redus de date: 2*σ =
( )
1n
ffn
1k
2
k
−
−∑= ;
• Abaterea pătratică medie pentru volum redus de date: σ*=( )
1n
ffn
1k
2
k
−
−∑= ;
• Momentul de ordin p: Mp(f)=n
f...f pn
p1 ++
;
8 Nenciu E., Gagea M., Lecții de econometrie, Editura Tehnopress, Iași, 2010

Cătălin Angelo Ioan Statistică economică
96
• Momentul absolut de ordin p: Ma,p(f)=n
f...fp
n
p
1 ++;
• Momentul centrat de ordinul p: Mn(f)=( )
n
ffn
1k
p
k∑=
−
;
• Coeficientul de asimetrie: γ1(f)=)f(
)f(M3
3
σ=
( )
( )n
ff
ff
3n
1k
2
k
n
1k
3
k
∑
∑
=
=
−
−
;
• Coeficientul de aplatizare: γ2(f)=)f(
)f(M4
4
σ=
( )
( )n
ff
ff
2n
1k
2
k
n
1k
4
k
−
−
∑
∑
=
= .
În cazul în care în procesul de investigare din punct de vedere statistic, exsită un vector aleator (f,g) și un sondaj aleator simplu, vom nota, pentru un număr de k unităţi ale populaţiei investigate, cu fk,gk – variabilele aleatoare ce descriu rezultatele sondajului.
Principalele funcții de selecție pentru vectori aleatori, utilizate în statistică, sunt:
• Corelația (covarianța): Cfg=( )( )
n
ggffn
1kkk∑
=
−−
;
• Coeficientul de corelație: ρfg=gf
fgC
σσ.
În cadrul unei distribuții normale, probabilitățile mediilor de selecție scad cu cât se îndepărtează de valoarea teoretică.
Considerând un scalar γ>0 se arată că:
( ) ( )γΦ=γσ+<<γσ−x
0x
xxxP
unde x - media de selecție, 0x - media întregii populații, x
σ – abaterea medie
pătratică corespunzătoare selecției, iar ( )γΦ = ∫γ
γ−
−
πdxe
2
1 2
x2
- funcția Gauss-
Laplace.

Cătălin Angelo Ioan Statistică economică
97
Intervalele de încredere corespunzătoare diverselor
niveluri de semnificație
γγγγ Interval de încredere Nivel de semnificație Nivel de încre-dere
1 ( )x
0x
xxx σ+<<σ− 0,682689=68,27% 31,73%
1,96 ( )
x0
x96,1xx96,1x σ+<<σ−
0,950004=95,00% 5,00%
2 ( )x
0x
2xx2x σ+<<σ− 0,9545=95,45% 4,55%
2,58 (
x0
x58,2xx58,2x σ+<<σ−
0,99012=99,01% 0,99%
3 ( )x
0x
3xx3x σ+<<σ− 0,9973=99,73% 0,27%
4 ( )x
0x
4xx4x σ+<<σ− 0,999937=99,993% 0,007%
5 ( )x
0x
5xx5x σ+<<σ− 0,999999=99,999% 0,001%
Se observă din tabel că odată cu creșterea nivelului de semnificație, lungimea intervalului de încredere se mărește.
Problema care se pune acum este cea a determinării valorii σ0 corespunzătoare abaterii medii pătratice a întregii populații statistice (evident, necunoscută).
Dacă selecția este repetată, se arată că: σ0= xnσ unde n este volumul
eșantionului statistic. Ca urmare a acestui fapt: n0
x
σ=σ se observă că odată
cu creșterea volumului eșantionului, eroarea de reprezentativitate scade.
Dacă selecția este nerepetată, se arată că: ( )1Nn
nN0x −
−σ=σ sau pentru
valori mari ale lui N (neglijându-l pe 1):
−σ=σ
N
n1
n
10x
unde N
reprezintă volumul întregii populații, iar n pe cel al eșantionului statistic.

Cătălin Angelo Ioan Statistică economică
98
Considerând funcția f:(0,∞)→R, ( )
−=
N
x1
x
1xf avem:
( ) ( )0
N
x1
x
1x2
1
xN
xNNNx
N
x1
x
12
1x'f
222
<
−
−=−−−
−
= deci f este
strict descrescătoare. Prin urmare, la o creștere a lui “n” eroarea de reprezentativitate scade.
Analizând cele două formule (corespunzătoare celor două tipuri de sondaje) se observă că dacă N este mare, iar n este mic, atunci:
−σ=σ
N
n1
n
10x
≈n0σ
deci cele două erori de reprezentativitate sunt
aproape egale. În acest caz, se poate deci utiliza sondajul repetat care, precum am menționat mai sus, conduce la o mai mare rapiditate în culegerea datelor.
Pe de altă parte: 0N
n> ⇔ 1
N
n1 <− ⇔
n
1
N
n1
n
1<
− deci eroarea de
reprezentativitate în cazul sondajului nerepetat este mai mică decât cea din cazul celui repetat.
Observație
În situația în care volumul eșantionului statistic este relativ mic, se
recomandă ca estimatorul x
σ să se calculeze pe baza formulei:
xσ =
( )
1n
xxn
1i
2
i
−
−∑=
Un ultim aspect care rebuie studiat este acela al alegerii volumului
eșantionului statistic. Pornind de la formula: ( ) ( )γΦ=γσ+<<γσ−x
0x
xxxP
am văzut că în cadrul sondajului repetat avem: n0
x
σ=σ deci eroarea
corespunzătoare unei valori γ va fi: n
xx 0x
0σ
γ=γσ<− . Considerând un
nivel maxim “ε” acceptat al erorii, va trebui deci ca: ε=σ
γn0 de unde:
2
20
2
nε
σγ= .

Cătălin Angelo Ioan Statistică economică
99
În situația sondajului nerepetat, avem:
−σ=σ
N
n1
n
10x
de unde:
−γσ=γσ<−
N
n1
n
1xx 0x
0 deci, ca mai sus: ε=
−γσ
N
n1
n
10 ⇔
20
2
2
Nn
nN
σγ
ε=
− ⇔ NnnN 22
022
02 ε=σγ−σγ ⇔ ( )nNN 2
0222
02 σγ+ε=σγ ⇔
20
22
20
2
N
Nn
σγ+ε
σγ= .
Din formulele de mai sus, se observă că valoarea 0σ reprezintă
abaterea medie pătratică a întregii colectivități. În situația în care este necunoscută ea va fi estimată.
Test de autoevaluare
1. Să considerăm un sondaj aleator simplu dintr-o populație totală egală cu 1000 relativ la o caracteristică x:
xi ni
2 10
5 15
7 20
9 8
Rezumat principalele tipuri de sondaje sunt:
• Sondajele aleatoare; • Sondajele dirijate; • Sondajele sistematice.
La rândul lor, sondajele aleatoare pot fi:
• sondaje simple; • sondaje stratificate; • sondaje de serii; • sondaje secvențiale; • sondaje în trepte.
Un sondaj aleator simplu constă în faptul că orice unitate a populației statistice poate fi inclusă cu aceeași probabilitate în eșantionul considerat.

Cătălin Angelo Ioan Statistică economică
100
13 17
Să se determine intervalele de încredere pentru media lui x în cazul sondajului repetat și apoi în cazul celui nerepetat, în situația unui prag de semnificație de 95%. Răspunsuri la întrebările din testul de autoevaluare 1- În cazul selecției repetate: (6,685;8,395), iar în cazul celei nerepetate, intervalul: (6,715;8,365) la un nivel de semnificație de 95%.
Bibliografie minimală Ioan C.A., ȘANSA – ÎNTRE FINIT ȘI INFINIT. Teoria probabilităților și Statistică, Editura Zigotto, Galați, 2017 Biji E.M., Lilea E., Roșca E., Vătui M., Statistică pentru economiști, Editura Economică, București, 2010 Isaic-Maniu A., Mitruț C., Voineagu V., Statistică, Editura Universitară, București, 2004

Cătălin Angelo Ioan Statistică economică
101
6. SERII CRONOLOGICE
SERII CRONOLOGICE 101 Rezumat 106
Test de autoevaluare 107
Răspunsuri şi comentarii la întrebările din testele de autoevaluare
108
Bibliografie minimală 108
Obiective în termeni de competențe specifice:
La sfârşitul modulului, se va şti: să se calculeze indicatorii relativi de dinamică ce se prezintă ca indici cu bază fixă sau indici cu bază mobilă.
să se determine indicele de tip Laspeyres
să se determine indicele de tip Paasche
să se determine indicele de tip Edgeworth
Timp mediu estimat pentru studiu individual: 2 ore
O serie cronologică reprezintă o serie de date ce prezintă evoluția temporală a unui fenomen. Analiza seriilor cronologice permite fie evidențierea comportării în trecut a fenomenului în sine, fie predicția comportării acestuia la momente ulterioare de timp. Dinamicitatea datelor unui anumit fenomen aduce elemente noi de analiză spre deosebire de seriile statice discutate în
capitolele precedente. Primul aspect ce trebuie avut în vedere la considerarea unei serii cronologice este determinarea unei scale de interval ce poate fi: zilnică, lunară, trimestrială sau anuală (evident, puteți ca să vă imaginați și alte perioade de timp...). Al doilea aspect constă în considerarea unei anumite caracteristici ce trebuie studiată care să fie compatibilă cu o posibilă evoluție temporală. O condiție esențială în cadrul seriilor cronologice este aceea a constanței spațiului și a structurii organizatorice.
Fie deci o serie cronologică x: x0,x1,...,xt,...
Am văzut în capitolele anterioare că pentru exprimarea numerică a dinamicității datelor cronologice există o erie de indici. Astfel indicatorii

Cătălin Angelo Ioan Statistică economică
102
relativi de dinamică se folosesc pentru analiza evoluției temporale a unui anumit fenomen, prezentându-se ca indici cu bază fixă sau indici cu bază
mobilă.
Indicele cu bază fixă al seriei x, corespunzător perioadei t se definește prin formula:
0
t0/t x
xI = , t≥0
iar indicele cu bază mobilă al serie x, corespunzător perioadei t se definește prin formula:
1t
t1t/t x
xI
−
− = , t≥1
Procentual avem, în mod evident:
100x
x%I
0
t0/t ⋅= , t≥0, 100
x
x%I
1t
t1t/t ⋅=
−
− , t≥1
Baza de comparație în cazul indicelui cu bază fixă, poate fi orice termen al seriei de date, dar, se recomandă, ca în cazul seriilor mici, aceasta să fie primul termen al seriei. În cadrul seriilor mai mari de 10 termeni, este recomandată divizarea acestora în grupe omogene și considerarea bazei de comparație (exceptând în mod evident prima grupă unde baza va fi primul termen) ca fiind ultimul termen al grupei anterioare.
Între indicii cu bază fixă și cei cu bază mobilă există determinări
reciproce. Astfel: 0/1t1t/t0
1t
1t
t
0
t0/t II
x
x
x
x
x
xI −−
−
−
===
de unde:
0/1t
0/t1t/t I
II
−
− = , t≥1
Reciproc, din relația de recurență 0/1t1t/t0/t III −−= rezultă succesiv:
0/1t1t/t0/t III −−= = 0/2t2t/1t1t/t III −−−− =...=
0/00/12t/1t1t/t II...II −−− . Cum însă: 1x
xI
0
00/0 == rezultă, în final:
=0/tI 0/12t/1t1t/t I...II −−− , , t≥1
Dacă schimbăm acum baza de comparație cu cea de-a “s” dată, se obține:

Cătălin Angelo Ioan Statistică economică
103
0/s
0/t
s
0
0
t
s
ts/t I
I
x
x
x
x
x
xI === , t,s≥0
respectiv:
0/ss/t0/t III =
Tot în categoria indicatorilor relativi de dinamică se încadrează ratele
de variație a acestora.
Astfel, rata de variație cu bază fixă se definește prin:
1I1x
x
x
xxR 0/t
0
t
0
0t0/t −=−=
−= , t≥0
iar rata de variație cu bază mobilă prin:
1I1x
x
x
xxR 1t/t
1t
t
1t
1tt1t/t −=−=
−= −
−−
−− , t≥1
Relativ la un moment de referință “s” avem:
1I1x
x
x
xxR s/t
s
t
s
sts/t −=−=
−=
de unde, cum 1R
1R
I
II
0/s
0/t
0/s
0/ts/t
+
+== rezultă:
1R
RR1
1R
1RR
0/s
0/s0/t
0/s
0/ts/t
+
−=−
+
+=
În mod analog cu situația indicilor se determină ratele procentuale:
100%I100R%R 0/t0/t0/t −=⋅= ,
100%I100R%R 1t/t1t/t1t/t −=⋅= −−−
Cu ajutorul acestor indici sau rate se pot reobține valorile absolute (în limita erorilor de rotunjire sau trunchiere) și anume:
00/tt xIx = , ( ) 00/tt xR1x += , t≥0
1t1t/tt xIx −−= , ( ) 1t1t/tt xR1x −−+= , t≥1
ss/tt xIx = , s0/s
0/tt x
1R
1Rx
+
+= , t,s≥0

Cătălin Angelo Ioan Statistică economică
104
O altă categorie de indici sintetici se folosește pentru analiza unei colectivități eterogene frunizând variația medie a indicatorului studiat.
Astfel, considerând un factor calitativ x și un factor cantitativ f la două perioade de timp t0 și t1 vom avea distribuțiile:
X0=
n0
k0
10
n0
k0
10
f...f...f
x...x...x și X1=
n
1k
111
n1
k1
11
f...f...f
x...x...x
Vom defini indicele de tip Laspeyres prin relația:
∑∑
=00
01L0/1 fx
fxI
unde prin x0 se înțeleg toate valorile k0x , k= n,1 și analog pentru x1, f0,
respectiv f1.
Analog, vom defini indicele de tip Paasche prin relația:
∑∑
=10
11P0/1 fx
fxI
unde prin x0 se înțeleg toate valorile k0x , k= n,1 și analog pentru x1, f0,
respectiv f1.
De asemenea, indicele de tip Edgeworth se definește prin relația:
( )( )∑
∑+
+=
010
011E0/1 ffx
ffxI
Aplicațiile acestor indici sunt utile în determinarea indicilor de inflație. Astfel, indicele Laspeyres consideră constant consumul din fiecare bun la nivelul anului de bază, luând în calcul prețul acestuia la momentul actual (la numărător) și la momentul de bază (la numitor). Indicele Paasche consideră constant consumul din fiecare bun dar la nivelul anului actual, luând în calcul prețul acestuia la momentul actual (la numărător) și la momentul de bază (la numitor).
În fine, asemenea, indicele Edgeworth consideră o medie a consumului din cele două perioade de timp (factorul de împărțire la 2 a fost simplificat) și la fel ca și în cazul celor doi indici anteriori, prețurile corespunzătoare.
Relativ la indicatorii medii, am văzut faptul că pentru un interval de timp [1,T], cu intervale echidistante, avem:

Cătălin Angelo Ioan Statistică economică
105
1T2
xx...x
2
x
x
T1T2
1
−
++++=
−
iar în cazul intervalelor de timp neechidistante:
1T1
T1T
1T1T2T
221
11
m...m
x2
mx
2
mm...x
2
mmx
2
m
x−
−−
−−
++
++
+++
+=
unde mk=tk+1-tk, k= 1T,1 − .
1. Ajustarea datelor statistice
Ajustarea statistică are o importanță fundamentală în analiza fenomenelor care prezintă un caracter sezonier pronunțat.
Eliminarea tulburărilor ocazionale permite analiza tendinței generale indiferent de eventualele lacune care ar putea afecta temporar fenomenul.
Pe de altă parte, din punctul de vedere al noilor date, considerăm că acestea trebuie să satisfacă un set de premise.
Pe de o parte, cantitatea de date translatate pe o perioadă de referință ar trebui să fie zero, deoarece, în caz contrar, ansamblul celor două seturi de date - originalul și cel modificat, ar conduce la rezultate generale diferite și, prin urmare, la concluzii diferite.
Pe de altă parte, într-o analiză de regresie (vezi capitolul următor), diferența dintre funcțiile de regresie corespunzătoare celor două seturi de date ar trebui să fie minimă.
Studiul mai multor metode de ajustare statistică relevă un aspect care conduce la o schimbare a datelor mai mult sau mai puțin justificată. Astfel, de exemplu, ajustările trimestriale sunt efectuate în condiții de mișcare relativă numai pentru datele din fiecare trimestru individual. În acest caz, totuși, este neglijabil fenomenul variației continue de la o perioadă la alta.
Metoda de ajustare pe care o propunem, în cele ce urmează, constă în determinarea celui mai bun transfer al datelor astfel încât variația totală, utilizând metoda celor mai mici pătrate, dintr-o perioadă în alta, să fie minimă.
Fie deci setul de date: ( ) kp,1iiy,i=
unde n=kp este numărul total de date
statistice și, de asemenea, fie mulțimile: Bj= ( ){ }p,1ss1jp =+− , j= k,1 , card
Bj=p.

Cătălin Angelo Ioan Statistică economică
106
Considerând o partiție a mulțimilor Bj, j= k,1 , that adică o grupare a lor
în k grupuri consecutive de lungime egală cu p, ne propunem determinarea
parametrilor ( )p,1jj =
β astfel încât, considerând un nou set de date: ( ) kp,1iiy~=
cu
ipsipsi yy~ β+= ++ , i= p,1 , s= 1k,0 − , suma pătratelor abaterilor datelor iy~ de la
1iy~ − să fie minimă.
Avem deci condiția:
( )
−∑
=−
n
2i
21ii y~y~min
Notând, pentru început:
( )
( )
=−=
−=
∑
∑−
=−++
−
=+
p,2j ,yyS
yyS
1k
0s1psjpsjj
1k
1spsps11
rezultă că, pentru p=4, obținem ajustările trimestriale, adică:
( )( ) ( )( )43211 S3k2kS2S3k6kS6
3k4k4
1−−+−+−
−=β
( )( ) ( ) ( )( )43212 S1k2S4k6S5k6kS2
3k4k4
1−+−+−−−
−=β
( )( ) ( ) ( )( )43213 S5k6S4k6S1k2kS2
3k4k4
1−+−−−−
−=β
( )( ) ( )( )43214 S3k6kS2S3k2kS6
3k4k4
1−−−−+
−=β
Rezumat O serie cronologică reprezintă o serie de date ce prezintă evoluția temporală a unui fenomen. Analiza seriilor cronologice permite fie evidențierea comportării în trecut a fenomenului în sine, fie predicția comportării acestuia la momente ulterioare de timp. Indicele cu bază fixă al seriei x, corespunzător perioadei t se definește prin
formula: 0
t0/t x
xI = , t≥0
Indicele cu bază mobilă al serie x, corespunzător perioadei t se definește prin
formula: 1t
t1t/t x
xI
−
− = , t≥1
Considerând un factor calitativ x și un factor cantitativ f la două perioade de timp t0 și t1 vom avea distribuțiile:

Cătălin Angelo Ioan Statistică economică
107
Test de autoevaluare
1. Să considerăm PIB trimestrial, neajustat sezonier, exprimat în prețuri medii ale anului 2000:
Data PIB (mil.lei)
Trimestrul I 2014 (y1) 26437,2
Trimestrul II 2014 (y2) 30157,2
Trimestrul III 2014 (y3) 38918,7
Trimestrul IV 2014 (y4) 39001,6
Trimestrul I 2015 (y5) 27612,3
Trimestrul II 2015 (y6) 31221,8
Trimestrul III 2015 (y7) 40412
Trimestrul IV 2015 (y8) 40570,7
X0=
n0
k0
10
n0
k0
10
f...f...f
x...x...x și X1=
n
1k
111
n1
k1
11
f...f...f
x...x...x
Vom defini indicele de tip Laspeyres prin relația:
∑∑
=00
01L0/1 fx
fxI
unde prin x0 se înțeleg toate valorile k0x , k= n,1 și analog pentru x1, f0,
respectiv f1.
Analog, vom defini indicele de tip Paasche prin relația:
∑∑
=10
11P0/1 fx
fxI
unde prin x0 se înțeleg toate valorile k0x , k= n,1 și analog pentru x1, f0,
respectiv f1.
De asemenea, indicele de tip Edgeworth se definește prin relația:
( )( )∑
∑+
+=
010
011E0/1 ffx
ffxI

Cătălin Angelo Ioan Statistică economică
108
Trimestrul I 2016 (y9) 28786,1
Trimestrul II 2016 (y10) 33082,8
Trimestrul III 2016 (y11) 42137,2
Trimestrul IV 2016 (y12) 42529,2
Să se ajusteze sezonier datele din tabelul de mai sus. Răspunsuri la întrebările din testul de autoevaluare 1 -
Data PIB (mil.lei)
Trimestrul I 2014 (y1) 33397
Trimestrul II 2014 (y2) 33575,3
Trimestrul III 2014 (y3) 33668,5
Trimestrul IV 2014 (y4) 33873,9
Trimestrul I 2015 (y5) 34572,1
Trimestrul II 2015 (y6) 34639,9
Trimestrul III 2015 (y7) 35161,8
Trimestrul IV 2015 (y8) 35443
Trimestrul I 2016 (y9) 35745,9
Trimestrul II 2016 (y10) 36500,9
Trimestrul III 2016 (y11) 36887
Trimestrul IV 2016 (y12) 37401,5
Bibliografie minimală Ioan C.A., ȘANSA – ÎNTRE FINIT ȘI INFINIT. Teoria probabilităților și Statistică, Editura Zigotto, Galați, 2017 Biji E.M., Lilea E., Roșca E., Vătui M., Statistică pentru economiști, Editura Economică, București, 2010 Isaic-Maniu A., Mitruț C., Voineagu V., Statistică, Editura Universitară, București, 2004

Cătălin Angelo Ioan Statistică economică
109
7. REGRESII
REGRESII 109 Rezumat 122
Teste de autoevaluare 122
Răspunsuri la întrebările din testele de autoevaluare 123
Bibliografie minimală 123
Obiective în termeni de competențe specifice:
La sfârşitul modulului, se va şti: să se determine o regresie liniară;
să se determine o regresie neliniară;
să se determine o regresie polinomială
Timp mediu estimat pentru studiu individual: 6 ore
Obiectul acestui capitol este acela de determinare a unor relații cauzale între o serie de variabile observabile ce derivă din derularea unor procese economice.
În esență se poate vorbi de două tipuri de variabile observabile: variabile exogene sau independente ce provin din exteriorul modelului econometric ce va fi elaborat și variabile
endogene sau dependente ce depind de cele exogene și care, în urma modelării, pot fi prognozate.
În cadrul unui model econometric, de o deosebită importanță este variabila reziduală ce are ca rol fie ajustarea unui model econometric, fie ameliorarea erorilor provenite din insuficiența numărului variabilelor exogene folosite în cadrul acestuia.
1. Regresia liniară simplă
Să considerăm, în cele ce urmează două seturi de date X=(xi)i∈I și
Y=(yi)i∈I unde I={1,...,n}. Pentru a face o alegere, vom presupune că X este variabilă exogenă, iar Y – endogenă. În plus, X este neconstantă.
Un model econometric liniar între X și Y constă în determinarea unei relații de forma:

Cătălin Angelo Ioan Statistică economică
110
Y=aX+b+u
unde a,b∈R, iar u este o variabilă aleatoare numită și variabilă reziduală.
Dacă primii doi termeni din expresia de mai sus: aX+b poartă numele de componentă deterministă a acestuia, ultimul: u – se numește componenta stochastică a acestuia.
Pentru fiecare pereche de date vom avea deci o relație de forma:
yi=axi+b+ui, i= n,1
unde ui este variabila reziduală corespunzătoare perechii (xi,yi) (ce, la rândul ei, provine din considerarea diferitelor eșantioane de date).
Pentru construcția modelului vom presupune o serie de condiții ce trebuie satisfăcute și anume:
• M(ui)=0 ∀i= n,1 – media fiecărei variabile reziduale (a abaterii modelului de
la funcția liniară) este nulă;
• variabilele reziduale au o repartiție normală de medie 0 (vezi condiția
anterioară) și aceeași dispersie D(ui)=σ2 ∀i= n,1 (ipoteza de
homoscedasticitate, spre deosebire de heteroscedasticitate atunci când dispersiile depind de i);
• jiuuC =0 ∀i≠j= n,1 – variabilele reziduale sunt necorelate (deci practic nu avem
o dependență între reziduuri). Cum ji uuC =M(uiuj)-M(ui)M(uj)=M(uiuj) (din
prima condiție), rezultă echivalența M(uiuj)=0;
• Xu iC =0 ∀i= n,1 - variabila exogenă nu este corelată cu variabilele reziduale;
• n
xlim
n
1ii∑
= și ( )
n
)X(Mxlim
n
1i
2i∑
=
−
există și sunt finite (în situația infinității
numărului de date). Pentru determinarea concretă a relației de regresie liniare, fie funcția
f:R→R, f(x)=ax+b, astfel încât:
∑=
−n
1i
2ii )y)x(f( =minimă
În mod normal ar trebui considerată o funcţie pentru care
∑=
−n
1iii y)x(f =minimă adică pentru care suma distanţelor între punctele date
şi punctele de aceleaşi abscise de pe graficul funcţiei să fie minimă. Cum însă funcţia modul este destul de dificil de analizat, s-a adoptat considerarea funcţiei anterioare.

Cătălin Angelo Ioan Statistică economică
111
Considerând F(a,b)=∑=
−+n
1i
2ii )ybax( , condiția de extrem local
reclamă ca necesitate satisfacerea condițiilor:
=∂
∂
=∂
∂
0b
F
0a
F
de unde:
=−+
=−+
∑
∑
=
=
0)ybax(2
0x)ybax(2
n
1iii
n
1iiii
După grupări, rezultă:
=+
=+
∑∑
∑∑∑
==
===n
1ii
n
1ii
n
1iii
n
1ii
n
1i
2i
ynbxa
yxxbxa
Determinantul sistemului este:
∆=nx
xx
n
1ii
n
1ii
n
1i
2i
∑
∑∑
=
== =2n
1ii
n
1i
2i xxn
− ∑∑
==
=n2D(X)≠0
Afirmația D(X)≠0 rezultă din neconstanța lui X.
Soluțiile sistemului sunt deci:
a=
nx
xx
ny
xyx
n
1ii
n
1ii
n
1i
2i
n
1ii
n
1ii
n
1iii
∑
∑∑
∑
∑∑
=
==
=
==
=2n
1ii
n
1i
2i
n
1ii
n
1ii
n
1iii
xxn
yxyxn
−
−
∑∑
∑∑∑
==
===

Cătălin Angelo Ioan Statistică economică
112
b=
nx
xx
yx
yxx
n
1ii
n
1ii
n
1i
2i
n
1ii
n
1ii
n
1iii
n
1i
2i
∑
∑∑
∑∑
∑∑
=
==
==
==
=2n
1ii
n
1i
2i
n
1ii
n
1iii
n
1ii
n
1i
2i
xxn
xyxyx
−
−
∑∑
∑∑∑∑
==
====
Pentru testarea condiției de minim local, vom calcula mai întâi derivatele parțiale de ordinul II:
2
2
a
F
∂
∂= ∑
=
n
1i
2ix2 ,
ba
F2
∂∂
∂= ∑
=
n
1iix2 ,
2
2
b
F
∂
∂=2n
Matricea Hessiană este:
HF=
∑
∑∑
=
==
n2x2
x2x2
n
1ii
n
1ii
n
1i
2i
iar determinanții diagonali principali: ∆1= ∑=
n
1i
2ix2 >0 (din neconstanța lui X),
∆2=2n
1ii
n
1i
2i x4xn4
− ∑∑
==
=4n2D(X)>0. Prin urmare diferențiala a doua d2F a lui
F este pozitiv definită, deci punctul (a,b) este de minim local.
Metoda expusă mai sus se numeşte metoda celor mai mici pătrate şi se datorează lui Gauss, regresia numindu-se liniară.
Observaţie
În cazul regresiei liniare, se observă că:
a=)X(D
C
xnx
yxnyxXY
n
1i
2i
2n
1ii
n
1iii
n
1ii
n
1ii
=
−
−
∑∑
∑∑∑
==
=== ,

Cătălin Angelo Ioan Statistică economică
113
)X(D
C)X(M)Y(M
)X(D
C)X(M)X(D)Y(M
xnx
yxyxxb
XY
XY
n
1i
2i
2n
1ii
n
1ii
n
1i
2i
n
1iii
n
1ii
−
=−
=
−
−
=
∑∑
∑∑∑∑
==
====
Ecuația regresiei liniare se mai poate scrie deci și sub forma:
Y=)X(D
CXY X+)X(D
C)X(M)Y(M XY− =
)X(D
CXY [X-M(X)]+M(Y)
unde X=(x1,...,xn) şi Y=(y1,...,yn).
De asemenea, ecuaţia regresiei se mai poate scrie:
)X(
)X(MX
)Y()X(
C
)Y(
)Y(MY XY
σ
−
σσ=
σ
−
sau altfel:
Y-M(Y)=ρXY)X(
)Y(
σ
σ[X-M(X)]
Coeficientul de corelaţie furnizează deci informaţii despre panta
regresiei liniare. Dacă ρXY>0 (cum σ(X),σ(Y)>0) rezultă că panta este
pozitivă, deci regresia este crescătoare, iar dacă ρXY<0 rezultă că regresia este descrescătoare.
Calculând abaterea E=∑=
−+n
1i
2ii )ybax( corespunzătoare regresiei
liniare, obţinem:
E=∑=
−+−
n
1i
2
iXY
iXY y)Y(M)X(M
)X(D
Cx
)X(D
C= ( )2
XY1)Y(nD ρ− .
Prin urmare, atunci când coeficientul de corelaţie este 1 sau -1 rezultă că E=0 ceea ce nu înseamnă altceva decât faptul că între variabile există o dependenţă liniară (rezultat, de altfel, cunoscut).
De asemenea, se observă că o apropiere a lui ρXY de 1 sau -1 implică o scădere a abaterii E, deci o simulare printr-o regresie liniară din ce în ce mai bună.

Cătălin Angelo Ioan Statistică economică
114
Revenind, obținem din cele de mai sus, faptul că parametrii a și b obținuți prin metoda celor mai mici pătrate sunt estimatori pentru modelul de regresie liniară simplă datorită faptului că ei depind de eșantionul de date ales.
1.1. Estimatorii regresiei liniare simple
Să considerăm, din nou modelul econometric:
Yi=aX+b+ui
unde a,b∈R sunt determinaţi ca mai sus, iar ui sunt variabile reziduale. Datorită caracterului aleator al lui ui rezultă că Yi sunt, de asemenea, variabile aleatoare.
Teoremă
Estimatorii a şi b se exprimă ca şi combinaţii liniare de variabilele Yi și au repartiții normale.
Teoremă
Estimatorii a şi b au următoarele proprietăți:
• M(a)=a;
• M(b)=b;
• D(a)=σ22n
1ii
n
1i
2i xxn
n
− ∑∑
==
;
• D(b)=σ22n
1ii
n
1i
2i
n
1i
2i
xxn
x
−
∑∑
∑
==
= ;
• Cab=σ2
∑∑
∑
==
=
−
n
1i
2i
2n
1ii
n
1ii
xnx
x.
Observație
Se arată că σ=2n
un
1i
2i
−
∑= - numită eroare standard a modelului de
regresie liniară simplă.

Cătălin Angelo Ioan Statistică economică
115
Definiţie
Considerând o funcţie de regresie Y=f(X) se defineşte raportul de
corelaţie ca fiind:
ηXY=( )
( )∑
∑
=
=
−
−
−n
1i
2i
n
1i
2ii
)Y(My
)x(fy1 ∈[0,1]
Observaţie
În cazul regresiei liniare avem ηXY=ρXY. Raportul de corelaţie dă măsura în care o anumită regresie aproximează fenomenul statistic considerat. Cu cât este mai aproape de 1, regresia este mai apropiată de valorile statistice considerate.
1.2. Intervale de încredere pentru regresia liniară simplă
Prin interval de încredere pentru un parametru ψ cu coeficientul de
încredere π0 (ce nu depinde de ψ) înțelegem un interval determinat de două
funcții de selecție α(f1,...,fn) și β(f1,...,fn) astfel încât:
P(α(f1,...,fn)≤ψ≤β(f1,...,fn))=π0
Cu cât diferența β(f1,...,fn)-α(f1,...,fn) este mai mică, iar π0 este mai
apropiat de 1 cu atât estimarea parametrului ψ este mai bună.
Considerând, din nou modelul econometric:
Yi=aX+b+ui
cu a,b∈R determinaţi ca mai sus, iar ui - variabile reziduale, se pun e problema determinării intervalelor de încredere pentru a, respectiv b.
După calcule ce depășesc obiectivele demersului de față, se arată că
intervalul de încredere pentru a este pentru probabilitatea π0:
+−
−π+
−π+ gta,gta
2n,2
12n,
2
1 00
unde:

Cătălin Angelo Ioan Statistică economică
116
g=
( )
−
− ∑∑
∑
==
=
2n
1ii
n
1i
2i
n
1i
2i
xxn2n
un
iar pentru b:
+−
−π+
−π+ htb,htb
2n,2
12n,
2
1 00
unde:
h=( ) 2n
1ii
n
1i
2i
n
1i
2i
n
1i
2i
xxn
x
2n
u
−
−∑∑
∑∑
==
==
tp,k fiind cuantila de ordin p a distribuției Student cu k grade de libertate (funcția T.INV din Excel).
Analog, intervalul de încredere pentru σ2 este pentru probabilitatea π0:
χχ −π−
=
−π+
=
∑∑
2n,2
12
n
1i
2i
2n,2
12
n
1i
2i
00
u,
u
χ2p,k fiind cuantila de ordin p a distribuției χ2 cu k grade de libertate (funcția
CHISQ.INV din Excel).

Cătălin Angelo Ioan Statistică economică
117
Sarcina de lucru 7
Fie tabelul de valori:
X Y 2 990
3 1210
4 1764
7 2955
9 3628
10 4129
13 5342
15 6131
16 6574
18 7379
19 7700
22 8897
a) Să se determine regresia liniară corespunzătoare datelor din tabelul de mai sus;
b) Să se estimeze estimarea pentru x=25;
c) Să se estimeze parametrul a pentru un coeficient de
încredere π0=0,98;
d) Să se estimeze parametrul b pentru un coeficient de
încredere π0=0,98;
e) Să se estimeze parametrul σ2 pentru un coeficient de încredere
π0=0,98.

Cătălin Angelo Ioan Statistică economică
118
2. Regresia polinomială
Să presupunem acum că f este o funcţie polinomială. Fie deci
f(x)=amxm+...+a1x+a0, x∈R cu coeficienţii necunoscuţi ai, i=0,...,m ce vor fi determinaţi în urma condiţiei ca:
∑=
−+++n
1i
2i0i1
mim )yaxa...xa( =minimă
Fie F(am,...,a0)=∑=
−+++n
1i
2i0i1
mim )yaxa...xa( .
Condiţia necesară de minim este: ka
F
∂
∂=0, k=0,...,m. Avem atunci:
∑=
−+++n
1ii0i1
mim
ki )yaxa...xa(x2 =0, k=0,...,m
de unde:
am∑=
+n
1i
kmix +...+a1∑
=
+n
1i
k1ix +a0∑
=
n
1i
kix =∑
=
n
1i
kii xy , k=0,...,m
Sistemul astfel obţinut are soluţiile:
∑∑∑∑
∑∑∑∑
∑∑∑
∑∑∑∑
∑∑∑∑
∑∑∑
==
+
=
−
=
==
+
==
+
==
−
=
===
−
=
====
+
==
−
=
=
n
1i
mi
n
1i
mki
n
1i
1m2i
n
1i
m2i
n
1ii
n
1i
1ki
n
1i
mi
n
1i
1mi
n
1i
ki
n
1i
1mi
n
1i
mi
n
1i
mi
n
1ii
mi
n
1i
1m2i
n
1i
m2i
n
1ii
n
1iii
n
1i
mi
n
1i
1mi
n
1ii
n
1i
1mi
n
1i
mi
k
xxxx
xxxx
nxxx
xyxxx
xyxxx
nyxx
a
1+k-col.m
LL
LLLLLL
LL
LL
LL
LLLLLL
LL
LL
, k=0,...,m
3. Regresii nepolinomiale
Pe lângă regresiile polinomiale prezentate mai sus, alte tipuri de regresii sunt:

Cătălin Angelo Ioan Statistică economică
119
• de tip putere: Y=aXb unde, după logaritmare avem: ln(Y)=ln(a)+ bln(X) şi deci, prin analogie cu regresia liniară, obţinem:
a=∑−
∑
∑∑−∑∑
==
====
n
1i
2i
2n
1ii
n
1ii
n
1i
2i
n
1iii
n
1ii
)x(lnnxln
yln)x(lnylnxlnxln
e , b=∑−
∑
∑−∑∑
==
===
n
1i
2i
2n
1ii
n
1iii
n
1ii
n
1ii
)x(lnnxln
ylnxlnnylnxln
• de tip exponenţial: Y=abX unde, după logaritmare avem: ln(Y)=ln(a)+Xln(b) şi deci:
a=∑−
∑
∑∑−∑∑
==
====
n
1i
2i
2n
1ii
n
1ii
n
1i
2i
n
1iii
n
1ii
xnx
ylnxylnxx
e , b=∑−
∑
∑−∑∑
==
===
n
1i
2i
2n
1ii
n
1iii
n
1ii
n
1ii
xnx
ylnxnylnx
e
• de tip hiperbolic: Y=a+X
b unde, prin analogie cu regresia liniară, obţinem:
a=
∑∑
∑∑∑∑
==
====
−
−
n
1i2i
2n
1i i
n
1ii
n
1i2i
n
1i i
in
1i i
x
1n
x
1
yx
1
x
y
x
1
, b=
∑∑
∑∑∑
==
===
−
−
n
1i2i
2n
1i i
n
1i i
in
1ii
n
1i i
x
1n
x
1
x
yny
x
1
4. Regresii în mai multe variabile
În cazul mai multor seturi de date: X1=(x11,...,x1n),..., Xp=(xp1,...,xpn), Y=(y1,...,yn) se pune, de asemenea, problema unei eventuale corelaţii a lui Y de
X1,...,Xp. Ne propunem determinarea constantelor a0,...,ap∈R astfel încât, considerând funcţia de regresie în mai multe variabile:
f(X1,...,Xp)=apXp+...+a1X1+a0
abaterea ∑=
−n
1i
2ii1pi )y)x,...,x(f( să fie minimă.
Avem deci:
F(a0,...,ap)=∑=
−+++n
1i
2i0i11pip )yaxa...xa( =minimă
Condiţia necesară de minim este: ka
F
∂
∂=0, k=0,...,p. Avem atunci:
∑=
−+++n
1ii0i11pipki )yaxa...xa(x2 =0 pentru k=p,...,1;

Cătălin Angelo Ioan Statistică economică
120
∑=
−+++n
1ii0i11pip )yaxa...xa(2 =0 pentru k=0
de unde:
∑∑∑∑====
=+++n
1ikii
n
1iki0
n
1ii1ki1
n
1ipikip xyxaxxa...xxa , k=p,...,1;
∑∑∑===
=+++n
1ii0
n
1ii11
n
1ipip ynaxa...xa , k=0
Sistemul astfel obţinut are soluţiile:
nxxx
xxxxxx
xxxxxx
nyxx
xxyxxx
xxyxxx
a
1+k-col.p
n
1iki
n
1ii,1p
n
1ipi
n
1ii,1p
n
1ikii,1p
n
1i
2i,1p
n
1ipii,1p
n
1ipi
n
1ikipi
n
1ii,1ppi
n
1i
2pi
n
1ii
n
1ii,1p
n
1ipi
n
1ii,1p
n
1ii,1pi
n
1i
2i,1p
n
1ipii,1p
n
1ipi
n
1ipii
n
1ii,1ppi
n
1i
2pi
k
LL
LLLLLL
LL
LL
LL
LLLLLL
LL
LL
∑∑∑
∑∑∑∑
∑∑∑∑
∑∑∑
∑∑∑∑
∑∑∑∑
==−
=
=−
=−
=−
=−
===−
=
==−
=
=
−
=
−
=
−
=
−
===
−
=
=
, k=0,...,p.
În particular pentru f(X1,X2)=a2X2+a1X1+a0 obţinem:
2xx
xxxx
xxxx
2xy
xxxy
xxxxy
a
n
1ii1
n
1ii2
n
1ii1
n
1i
2i1
n
1ii2i1
n
1ii2
n
1ii1i2
n
1i
2i2
n
1ii1
n
1ii
n
1ii1
n
1i
2i1
n
1ii1i
n
1ii2
n
1ii1i2
n
1ii2i
2
∑∑
∑∑∑
∑∑∑
∑∑
∑∑∑
∑∑∑
==
===
===
==
===
===
=
,
2xx
xxxx
xxxx
2yx
xxyxx
xxyx
a
n
1ii1
n
1ii2
n
1ii1
n
1i
2i1
n
1ii2i1
n
1ii2
n
1ii1i2
n
1i
2i2
n
1ii
n
1ii2
n
1ii1
n
1ii1i
n
1ii2i1
n
1ii2
n
1ii2i
n
1i
2i2
1
∑∑
∑∑∑
∑∑∑
∑∑
∑∑∑
∑∑∑
==
===
===
==
===
===
=
,

Cătălin Angelo Ioan Statistică economică
121
2xx
xxxx
xxxx
yxx
xyxxx
xyxxx
a
n
1ii1
n
1ii2
n
1ii1
n
1i
2i1
n
1ii2i1
n
1ii2
n
1ii1i2
n
1i
2i2
n
1ii
n
1ii1
n
1ii2
n
1ii1i
n
1i
2i1
n
1ii2i1
n
1ii2i
n
1ii1i2
n
1i
2i2
0
∑∑
∑∑∑
∑∑∑
∑∑∑
∑∑∑
∑∑∑
==
===
===
===
===
===
=
5. Serii clasificate prin ranguri
Considerând acum două variabile statistice X şi Y, să presupunem că ele nu pot fi măsurate direct, dar se pot clasifica prin ranguri. Rangurile celor două variabile se pot interpreta, la rândul lor, ca valori ale unor variabile statistice şi deci pot fi folosite la calculul unor coeficienţi de corelaţie.
Fie deci următorul tabel:
Indicator Rangul după variabila X Rangul după variabila Y
I1 r1 s1
... ... ...
In rn sn
Definiţie
Coeficientul lui Spearman se defineşte ca:
S=1-)1n(n
)sr(6
2
n
1i
2ii
−
−∑=
Observaţie
Există evident relaţia S∈[-1,1]. Aprecierea legăturii dintre cele două variabile este următoarea:
• dacă cele două serii de ranguri sunt identice atunci ri=si şi deci S=1;
• dacă cele două serii de ranguri sunt inverse atunci ri=sn+1-i şi deci S=-1. Definiţie
Coeficientul lui Kendall se defineşte ca:

Cătălin Angelo Ioan Statistică economică
122
K=)1n(n
)MP(2n
1iii
−
−∑=
Observaţie
Există evident relaţia K∈[-1,1]. Aprecierea legăturii dintre cele două variabile este următoarea:
• dacă cele două serii de ranguri sunt identice atunci K =1;
• dacă cele două serii de ranguri sunt inverse atunci K=-1.
Test de autoevaluare
1. Fie setul de date:
X Y
2 135
4 264
5 357
8 839
10 1132
Rezumat Un model econometric liniar între X și Y constă în determinarea unei relații de forma:
Y=aX+b+u
unde:
a=
nx
xx
ny
xyx
n
1ii
n
1ii
n
1i
2i
n
1ii
n
1ii
n
1iii
∑
∑∑
∑
∑∑
=
==
=
==
=2n
1ii
n
1i
2i
n
1ii
n
1ii
n
1iii
xxn
yxyxn
−
−
∑∑
∑∑∑
==
===

Cătălin Angelo Ioan Statistică economică
123
11 1460
14 2243
17 3152
20 4244
22 5062
23 5630
26 7185
a) Să se determine regresia polinomială de ordinul 2;
b) Să se realizeze estimația pentru x=27.
Răspunsuri la întrebările din testul de autoevaluare 1- a) y=10,02x2+10,34x+76,378; b) y=7663.
Bibliografie minimală Ioan C.A., ȘANSA – ÎNTRE FINIT ȘI INFINIT. Teoria probabilităților și Statistică, Editura Zigotto, Galați, 2017 Biji E.M., Lilea E., Roșca E., Vătui M., Statistică pentru economiști, Editura Economică, București, 2010 Isaic-Maniu A., Mitruț C., Voineagu V., Statistică, Editura Universitară, București, 2004










![12 JURNALUL NA}IONAL Joi, 11 decembrie 2014 Anun]uricurs, sau în copii legalizate. Rela]ii suplimentare la Secretarul comunei Mo[teni, tel. 0247-356.012. Anun] cu privire la organizarea](https://static.documente.net/doc/80x56/608c918903e1546cd71638e4/12-jurnalul-naional-joi-11-decembrie-2014-anunuri-curs-sau-n-copii-legalizate.jpg)

![Detalii - BZI.ro · PDF fileBUN~ ZIUA IA{I vine \n ajutorul t`u cu cele mai mici pre]uri de pe pia]` la anun]uri de mica publicitate, mare publicitate [i anun]uri proiect european](https://static.documente.net/doc/80x56/5a7a5aef7f8b9aec2d8c5493/detalii-bziro-ziua-iai-vine-n-ajutorul-tu-cu-cele-mai-mici-preuri-de-pe-pia.jpg)




