Page 1
Cuprins
INTRODUCERE ......................................................................................................... 1
CAPITOLUL 1 - SISTEME DISTRIBUITE, ASPECTE TEORETICE ........................ 3
1.1 Introducere în sisteme distribuite..................................................................................... 3
1.2 Comunicarea în sistemele distribuite ............................................................................... 6
1.3 Sincronizarea în sistemele distribuite............................................................................. 12 1.3.1 Sincronizarea ceasurilor .............................................................................................. 12 1.3.2 Excluziunea mutuală ................................................................................................... 14 1.3.3 Tranzacţiile.................................................................................................................. 16 1.3.4 Interblocajul în sistemele distribuite ........................................................................... 17
1.4 Consistenţa datelor........................................................................................................... 19 1.4.1 Replicare şi consistenţă. .............................................................................................. 19 1.4.2 Modele de consistenţă a datelor. ................................................................................. 19 1.4.3 Protocoale de distribuire şi consistenţă. ...................................................................... 21
1.5 Securitatea în sistemele distribuite ................................................................................. 23 1.5.1 Politici şi mecanisme de securitate.............................................................................. 23 1.5.2 Canale securizate......................................................................................................... 23 1.5.3 Controlul accesului..................................................................................................... 24
CAPITOLUL 2 - MODELUL SISTEMULUI INFOSTUDENT .................................... 25
1.1 Prezentare generală a aplicaţiei ...................................................................................... 25
1.2 Modelul de comunicare.................................................................................................... 28
1.3 Sincronizare ...................................................................................................................... 30
1.4 Replicarea şi consistenţa datelor..................................................................................... 33
1.5 Securitate........................................................................................................................... 34
CAPITOLUL 3 - IMPLEMENTAREA APLICAŢIEI................................................... 36
3.1 Structura aplicaţiei nod ................................................................................................... 36 3.1.1 Modulul de comunicare............................................................................................... 37 3.1.2 Modulul de procesare a mesajelor............................................................................... 41 3.1.3 Accesul la baza de date ............................................................................................... 44 3.1.4 Alte clase ..................................................................................................................... 45
3.2 Aplicaţia client .................................................................................................................. 47
CONCLUZII .............................................................................................................. 48
BIBLIOGRAFIE........................................................................................................ 51
Page 2
Introducere 1
Introducere
Sistemele de fişiere distribuite constituie o categorie aparte a sistemelor distribuite şi
oferă utilizatorilor săi facilităţi specifice unui sistem de fişiere transpuse într-o reţea de
calculatoare. Dintre facilităţile sistemelor de fişiere amintim: crearea de fişiere, deschiderea
sau închiderea fişierelor, crearea directoarelor, redenumirea fişierelor sau directoarelor,
ştergerea fişierelor sau directoarelor, scrierea sau citirea din fişiere, şi alele. Pentru
implementarea lor există mai multe alternative, alegerea uneia dintre ele făcându-se în funcţie
de scopul urmărit şi de restricţiile pe care trebuie să le respecte sistemul. Comunicarea se face
prin apelul procedurii la distanţă sau mesaje, iar modelul ales este, în general, unul de tip
client-server. Pentru accesul la fişiere se utilizează un model de tipul acces la distanţa în
cele mai multe din cazuri, dar există şi posibilitatea utilizării unui model bazat pe încărcare-
descărcare. În multe dintre ele nu există replicare, sau dacă totuşi există se face într-o formă
minimală. Spaţiul de nume este în general global, iar modul în care este asigurată securitatea
comunicaţiilor şi controlul accesului variază de la un sistem la altul. Sistemul distribuit
prezentat în continuare nu oferă toate facilităţile specifice sistemelor de fişiere, dar cu toate
acestea el poate fi inclus în această categorie.
Structura documentului
Capitolul 1 prezintă câteva chestiuni teoretice legate de sistemele distribuite. Începe
cu o introducere în problematica sistemelor distribuite, avantajelor şi dezavantajele lor în
comparaţie cu sistemele centralizate, câteva aspecte care trebuie avute în vedere la proiectarea
lor. În continuare este abordată problema comunicării în sistemele distribuite, se prezintă pe
scurt suportul de comunicare folosit şi câteva modele de comunicare client-server, RPC, RMI.
Urmează câteva noţiuni legate de sincronizarea ceasurilor, excluziunea mutuală, tranzacţii şi
interblocaj. În ceea ce priveşte replicarea datelor sunt prezentate câteva modele de consistenţă
şi protocoale pentru distribuirea şi asigurarea consistenţei datelor. Capitolul se încheie cu
prezentarea câtorva noţiuni legate de securitate: politici de securitate, canale securizate şi
controlul accesului.
Universitatea "Petru Maior" 2005
Capitolul 2 este dedicat modelului sistemului distribuit. Se prezintă modelul de
comunicare ales, arhitectura sistemului, stabilirea conexiunilor, structura mesajelor schimbate
în interiorul sistemului şi protocolul de comunicare. În continuare sunt descrise mecanismele
Page 3
Introducere 2
de sincronizare, replicarea şi consistenţa datelor, iar în final câteva chestiuni legate de
securitate mai exact autentificarea şi controlul accesului.
Capitolul 3 prezintă implementarea sistemului. Începe cu descrierea structurii
aplicaţiei nod, părţile componente, diagramele de clase pentru fiecare parte, descrierea
claselor, câteva diagrame de stare şi de colaborare între obiecte. Este prezentată structura
bazei de date şi modul în care se accesează datele. Capitolul se încheie cu prezentarea pe scurt
a aplicaţiei client, interfaţa dintre utilizator şi sistem.
Capitolul 4 conţine câteva concluzii legate de performanţele, fiabilitatea,
scalabilitatea, transparenţa şi securitatea sistemului.
Universitatea "Petru Maior" 2005
Anexele cuprind descrierea protocolului de comunicare, o prezentare detaliată a
mesajelor utilizate în sistem, diagrama de clase pentru aplicaţia nod, o diagramă de colaborare
pentru obiectele din aplicaţia nod, o diagramă de secvenţă pentru firele de execuţie, schema
conceptuală a bazei de date şi o scurtă prezentare a interfeţei grafice pentru aplicaţia client.
Page 4
Capitolul 1 - Sisteme distribuite, aspecte teoretice 3
Capitolul 1 - Sisteme distribuite, aspecte teoretice
1.1 Introducere în sisteme distribuite
La ora actuală asistăm la o revoluţie a sistemelor de calcul. Din 1945 când a început
istoria calculatoarelor până pe la mijlocul anilor 80 acestea erau nişte echipamente mari ca
dimensiune şi foarte costisitoare în exploatare. Două progrese importante ale tehnologiei au
pornit această revoluţie. Prima a fost dezvoltarea unor microprocesoare puternice şi ieftine în
acelaşi timp. Primele lucrau pe 8 biţi , dar în curând au apărut modele pe 16, 32 sau chiar 64
de biţi. Al doilea pas important a fost făcut prin dezvoltarea reţelelor de calculatoare de mare
viteză. Reţelele locale (LAN – Local Area Network) permit conectarea a zeci sau chiar sute
de calculatoare şi oferă posibilitatea ca o cantitate mică de informaţie să poată fi transmisă în
intervale de timp de ordinul milisecundelor. Reţelele pe arii extinse (WAN – Wide Area
Network) permit conectarea a milioane de calculatoare vitezele variind de la zeci de Kbps
până la 1 Gbps. Acest progres al tehnologiei a făcut posibilă crearea unor sisteme de calcul
alcătuite dintr-un număr mare de unităţi de procesare, conectate între ele printr-o reţea de
mare viteză, care au primit denumirea de sisteme distribuite.
De-a lungul timpului s-au dat mai multe definiţii pentru sistemele distribuite, dar sunt
contradictorii şi nesatisfăcătoare. O caracterizare simplă ar fi următoarea: un sistem distribuit
este o colecţie de calculatoare independente pe care utilizatorul le vede ca unul singur.
Definiţia are două aspecte importante, partea hardware este realizată din calculatoare
autonome, iar partea software trebuie să creeze impresia utilizatorului că lucrează cu un
singur calculator. Un exemplu ar fi sistemul informatic al unei bănci. Fiecare sucursală are pe
lângă staţiile de lucru un calculator central conectat cu celelalte sucursale şi cu sediul central
al băncii. Dacă tranzacţiile se pot efectua fără ca să conteze sucursala în care a fost deschis un
cont şi utilizatorul vede sistemul ca un întreg atunci se poate considera că avem de a face cu
un sistem distribuit.
Dacă este posibilă construirea unor sisteme distribuite asta nu înseamnă că ele
reprezintă cea mai bună soluţie pentru orice problemă. Întotdeauna trebuie studiate avantajele
şi dezavantajele lor în raport cu sistemele clasice, centralizate.
Universitatea "Petru Maior" 2005
Principalul avantaj al sistemelor distribuite faţă de cele centralizate este costul lor. S-a
demonstrat că mai multe procesoare mai puţin performante conectate între ele sunt mai ieftine
ca un singur procesor care oferă performanţe similare deci raportul performanţă/preţ este net
Page 5
Capitolul 1 - Sisteme distribuite, aspecte teoretice 4
superior în cazul sistemelor distribuite. Un alt avantaj ar fi faptul că mai multe procesoare
conectate pot oferi, în termeni absoluţi, performanţe pe care un singur procesor nu le va putea
oferi niciodată, indiferent de cost, din cauza restricţiilor tehnice pe care le impune tehnologia
actuală. Un astfel de procesor ar genera atât de multă căldură încât s-ar topi instantaneu.
Sistemele distribuite oferă o fiabilitate superioară sistemelor centralizate pentru că dacă o
componentă se defectează sistemul poate să funcţioneze în continuare, lucru imposibil pentru
un sistem centralizat. În cazul ideal defectarea a 5% din componente ar scădea performanţele
sistemului tot cu 5%. Pe termen lung dacă apare nevoia unei creşteri a performanţelor
sistemului aceasta se poate face uşor prin adăugarea de noi elemente de procesare fără să fie
nevoie de înlocuirea întregului sistem cu unul mai performant ca în cazul celui centralizat. Pe
lângă aceste aspecte economice şi practice sistemele distribuite oferă soluţia cea mai bună în
rezolvarea unor probleme care se pretează la prelucrare distribuită prin natura lor. Un
exemplu concludent ar fi un sistem de muncă în comun, care permite unui grup de oameni
situaţi în locaţii diferite să lucreze la aceeaşi sarcină fără ca distanţa dintre ei să fie un
impediment.
Cu toate avantajele pe care le oferă sistemele distribuite au şi unele dezavantaje.
Primul şi cel mai important îl reprezintă dificultatea implementării softului necesar pentru
funcţionarea unui astfel de sistem, dar pe măsură ce se vor face mai multe cercetări probabil
că aceste dificultăţi vor dispărea. O altă problemă este comunicarea în cadrul sistemului,
mesajele se pot pierde şi acest lucru trebuie luat în considerare în faza de proiectare, de
asemenea reţeaua de comunicare poate deveni supraîncărcată. În ambele situaţii sistemul nu
mai oferă performanţele pentru care a fost construit. Al treilea dezavantaj important este
dificultatea asigurării securităţii informaţiei. Sistemele distribuite permit un schimb foarte
uşor de informaţii, dar acest lucru este un avantaj şi un dezavantaj în acelaşi timp. Pe deoparte
înlesneşte comunicarea pe de altă parte poate oferi unor persoane accesul la informaţii pe care
nu ar trebui să le vadă. Cu toate acestea multă lume crede că sistemele distribuite oferă mai
multe avantaje decât dezavantaje şi este foarte probabil ca rolul lor în viitor să devină tot mai
important.
Există mai multe aspecte care trebuie avute în vedere atunci când se proiectează un
sistem distribuit:
Universitatea "Petru Maior" 2005
a) Transparenţa : utilizatorul trebuie să vadă sistemul ca pe un întreg şi nu trebuie să
cunoască detalii legate de arhitectura lui internă. Conceptul de transparenţă poate fi
aplicat mai multor aspecte ale sistemelor distribuite. Astfel putem vorbi despre:
Page 6
Capitolul 1 - Sisteme distribuite, aspecte teoretice 5
- transparenţa locaţiei: utilizatorul nu ştie locaţia resurselor pe care le
utilizează.
- transparenţa migraţiei: utilizatorul nu trebuie să ştie dacă anumite resurse
şi-au schimbat locaţia.
- transparenţa concurenţei: utilizatorul nu trebuie să observe existenţa altor
utilizatori care folosesc aceleaşi resurse.
- transparenţa paralelismului: utilizatorul nu trebuie să-şi dea seama că
sistemul conţine mai multe unităţi de procesare.
b) Flexibilitatea : este foarte importantă în cazul în care se observă că o anumită
soluţie aleasă nu este optimă. Trebuie ca ea să poată fi înlocuită cu uşurinţă fără
schimbări majore în arhitectura sistemului.
c) Fiabilitatea : este unul din scopurile iniţiale pentru care s-au dezvoltat sistemele
distribuite. Dacă una din componentele sistemului cedează acesta îşi poate continua
funcţionarea. Asigurarea fiabilităţii generează de multe ori probleme suplimentare. De
exemplu dacă se folosesc nişte copii de siguranţă a datelor pentru creşterea
disponibilităţii trebuie asigurată consistenţa şi siguranţa lor.
d) Performanţa : un sistem transparent, flexibil şi fiabil nu este util dacă nu oferă
performanţele dorite. Pentru măsurarea performanţelor se pot folosi diverse criterii cum
ar fi: timpul de răspuns, numărul de sarcini efectuate într-o oră sau încărcarea reţelei.
Viteza reţelei prin care sunt legate componentele sistemului este unul dintre principalii
factori care influenţează performanţa sistemului, de aceea numărul de mesaje trimise
trebuie redus la minim. Asigurarea fiabilităţii sistemului poate genera un număr mare de
mesaje prin reţea ceea ce poate duce la o scădere a performanţelor, de aceea trebuie
realizat un echilibru între fiabilitatea sistemului şi performanţa lui.
Universitatea "Petru Maior" 2005
e) Scalabilitatea : sistemul distribuit trebuie astfel proiectat încât să permită creşterea
nelimitată în dimensiuni. Algoritmii folosiţi trebuie astfel gândiţi încât să funcţioneze
într-un sistem oricât de mare.
Page 7
Capitolul 1 - Sisteme distribuite, aspecte teoretice 6
1.2 Comunicarea în sistemele distribuite
Diferenţa esenţială între un sistem centralizat şi unul distribuit este comunicarea. Un
sistem distribuit este alcătui din componente care trebuie să comunice între ele, suportul
pentru comunicare fiind oferit de reţelele de calculatoare. Există mai multe tipuri de reţele
fiecare cu propriile caracteristici, avantaje şi dezavantaje. La ora actuală cele mai cunoscute
tipuri de reţele sunt:
- LAN (Local Area Network): sunt reţele locale folosite pe distanţe mici 1-
2 km, oferă o rată de transfer mare 10-1000 Mbps şi un timp de întârziere
mic 1-10 ms.
- WAN (Wide Area Network): sunt reţele cu acoperire foarte mare
(continentală), oferă o rată de transfer mai mică decât reţelele locale 0.010
– 600 Mbps şi întârzieri mai mari 100-500 ms.
- MAN (Metropolitan Area Network): sunt reţele cu performanţe
intermediare, între LAN şi WAN, utilizabile pe distanţe medii 2-50 km, cu
rată de transfer de ordinul 1-150 Mbps şi întârzieri de 10 ms.
- Wireless: reţele fără fir care folosesc diverse tehnologii alternative pentru
transmisia datelor.
Pentru o comunicare coerentă este necesară existenţa unor reguli care să reglementeze
diversele aspecte ale acesteia. Organizaţia Internaţională pentru Standarde (ISO) a propus un
model de referinţă pentru comunicarea în care sunt identificate clar diversele nivele implicate
precum şi rolul fiecăruia. Acest model a fost denumit Open Systems Interconnection
Reference Model prescurtat (OSI) şi defineşte o serie de protocoale prin care sunt
formalizate regulile după care se face comunicarea. Modelul OSI, reprezentat în Fig. 1.1, este
organizat pe 7 nivele, fiecare fiind responsabil cu un anumit aspect al comunicării:
- nivelul fizic: este responsabil de transmiterea biţilor la nivel fizic, nivele de
tensiune pe firul de legătură.
- nivelul legătură date: este responsabil cu detecţia şi corecţia erorilor.
- nivelul reţea: asigură transferul datelor de la expeditor la destinatar într-o
reţea cu mai multe calculatoare; cel mai cunoscut protocol pentru acest
nivel este Internet Protocol (IP).
Universitatea "Petru Maior" 2005
- nivelul transport: asigură o comunicare sigură, fără pierderea datelor; există
două tipuri de protocoale pentru acest nivel, orientate pe conexiune cum ar
Page 8
Capitolul 1 - Sisteme distribuite, aspecte teoretice 7
fi Transmission Control Protocol (TCP) sau fără conexiune cum este
Universal Datagram Protocol (UDP).
- nivelul sesiune: oferă facilităţi pentru controlul dialogului şi sincronizare.
- nivelul prezentare: este responsabil cu semnificaţia datelor transmise.
- nivelul aplicaţie: protocolul de la acest nivel este dependent de aplicaţia
care comunică; exemple de protocoale sunt Hypertext Transfer Protocol
(HTTP) , File Transfer Protocol (FTP), SMTP etc.
Universitatea "Petru Maior" 2005
Toate aceste nivele pe care datele trebuie să le parcurgă produc o încărcare
suplimentară a reţelei prin informaţiile de control pe care le adaugă şi o creştere a timpului de
procesare. În sisteme distribuite această încărcare suplimentară nu face decât să reducă
performanţele de aceea multe sisteme folosesc doar nivelele inferioare ale modelului OSI.
Modelul de comunicare în reţea asigură transferul datelor dintr-un punct într-altul al
sistemului distribuit, dar nu oferă nici o informaţie despre cum ar trebui structurat şi organizat
acesta, de aceea este nevoie de un model al sistemului. În multe cazuri se alege pentru
sistemul distribuit un model client-server. Sistemele care adoptă acest model de organizare
Page 9
Capitolul 1 - Sisteme distribuite, aspecte teoretice 8
Universitatea "Petru Maior" 2005
sunt alcătuite dintr-un set de procese numite servere care oferă servicii utilizatorilor, numiţi
clienţi, comunicarea dintre ele realizându-se prin mesaje. Pe un calculator pot rula unul sau
mai multe procese, clienţi sau servere.
Acest model foloseşte un protocol de comunicare simplu, fără conexiune, de tipul
cerere/răspuns, ale cărui principale avantaje sunt simplitatea şi eficienţa. Clientul trimite o
cerere sub forma uni mesaj, iar serverul răspunde cu un alt mesaj care conţine datele cerute
sau un cod de eroare dacă operaţia cerută nu s-a putut efectua. Practic comunicarea între client
şi server poate fi redusă la doar două primitive trimitere şi primire. Ele pot fi cu sau fără
blocare. Într-un astfel de model trebuie ţinut cont de următoarele aspecte:
a) Adresarea: este necesară existenţa unui mecanism de identificare componentelor
unui sistem distribuit. În acest sens există mai multe abordări posibile. Prima ar fi ca fiecare
resursă din sistem să aibă un identificator de forma locatie.id_resursa, dar astfel se încalcă
principiul transparenţei locaţiei. A doua posibilitate este asocierea de adrese aleatoare
resurselor şi difuzarea unui mesaj în reţea când se doreşte localizarea lor. Această metodă
prezintă dezavantajul încărcării suplimentare a reţelei pe care o introduce. A treia posibilitate
o reprezintă folosirea unui server de nume care să conţină o asociere între un nume simbolic
şi adresa fiecărei resurse urmând ca ele să fie localizate pe baza acestui nume prin interogarea
serverului. Pentru o fiabilitate crescută serverul de nume trebuie replicat în mai multe locaţii
ceea ce generează o problemă suplimentară, asigurarea consistenţei datelor.
b) Primitive cu blocare sau fără blocare: primitivele trimitere şi primire amintite
mai sus pot să funcţioneze în două moduri sincron şi asincron. În cazul unei funcţionări
sincrone trimitere se blochează până când mesajul a fost transmis cu succes. Similar primire
se blochează, în momentul apelului, până când un mesaj este recepţionat. Dezavantajul
modului sincron vine din timpul de procesare irosit prin blocarea primitivelor. Dacă se alege
modul de funcţionare asincron primitivele trimitere şi primire returnează imediat urmând ca
Page 10
Capitolul 1 - Sisteme distribuite, aspecte teoretice 9
transmisia să se efectueze în fundal. În cazul acesta se pune problema determinării
momentului în care operaţia de trimitere sau primire s-a încheiat. Există mai multe posibilităţi
cum ar fi utilizarea unei primitive suplimentare prin care să poată fi interogată starea
transmisiunii sau a unui sistem de întreruperi, dar această soluţie face programarea şi
depanarea sistemului dificilă.
c) Primitive cu memorie tampon sau fără: dacă se optează pentru primitive fără
memorie tampon apare o problemă atunci când clientul trimite un mesaj şi la server nu a fost
apelată primitiva primire în prealabil. În acest caz mesajul este aruncat fără să fie procesat, iar
clientul după ce timpul de aşteptare a răspunsului expiră retransmite mesajul. Dacă clientul
este nevoit să retransmită mesajul de multe ori poate să presupună că serverul nu funcţionează
şi astfel comunicarea se întrerupe. Problema poate fi soluţionată prin crearea unei memorii
tampon în care să fie depuse, temporar, toate mesajele primite la sever, urmând ca de cate ori
se apelează primitiva primire să fie citit un mesaj salvat în memoria tampon. Singurul
dezavantaj al acestei soluţii este că spaţiul pentru memoria tampon este limitat şi când se
atinge capacitatea maximă de stocare se ajunge în situaţia iniţială.
d) Primitive fiabile: dacă se doreşte o comunicare sigură, fără pierderea mesajelor
trebuie implementat un mecanism care să realizeze acest lucru. Astfel după fiecare mesaj
trimis trebuie aşteptat ca destinatarul să confirme primirea lui. Protocolul iniţial se modifică,
în loc de doua mesaje se folosesc patru. Clientul trimite un mesaj cu o cerere, serverul
răspunde cu un mesaj de confirmare, severul răspunde la cererea clientului, iar clientul
confirmă primirea răspunsului printr-un mesaj.
O variantă simplificată a protocolului utilizează doar trei mesaje şi foloseşte răspunsul ca o
confirmare a primirii mesajului cerere.
Universitatea "Petru Maior" 2005
Deşi modelul client-server este o modalitate bună de structurare şi organizare a unui
sistem distribuit, există şi alte posibilităţi. O alternativă des întâlnită este apelul procedurii la
Page 11
Capitolul 1 - Sisteme distribuite, aspecte teoretice 10
distanţă (RPC – Remote Procedure Call). Prin intermediul acestui mecanism un proces de
pe un calculator poate să apeleze o procedură de pe alt calculator în mod total transparent
pentru programator. Din punctul de vedere al programatorului un apel de procedură la distanţă
nu diferă cu nimic faţă de un apel local.
Cel care face posibilă această transparenţă este reziduul (stub), prezent atât pe partea
de sever cât şi pe partea de client. În momentul în care la client se face un apel de procedură
reziduul este responsabil cu preluarea argumentelor, împachetarea lor într-un mesaj şi
transmiterea lor la server după care blochează procesul până la sosirea rezultatului. Reziduul
de pe partea severului extrage argumentele din mesaj şi apelează efectiv procedura dorită
urmând ca la obţinerea rezultatului să-l includă într-un mesaj pe care îl transmite înapoi
clientului. Reziduul client extrage rezultatul apelului din mesaj şi-l returnează apelantului.
Schimbul de mesaje între cele două reziduuri este invizibil programatorului, care nu trebuie să
facă decât un apel simplu de procedură.
Universitatea "Petru Maior" 2005
Transmiterea argumentelor poate ridica o serie de probleme. Una dintre ele ar fi
diferenţa de reprezentarea a datelor de pe platforma client faţă de platforma server.
Reziduurile trebuie să cunoască aceste diferenţe şi să realizeze conversiile necesare. Pentru
aceasta procedurile trebuie descrise într-un limbaj comun, IDL (Interface Device
Language), prin care se specifică numărul argumentelor, dimensiunea şi tipul lor. Într-un
apel de procedură clasic există două posibilităţi pentru modul de transmitere al argumentelor
prin valoare sau prin referinţă. La fel şi în cazul apelului de procedură la distanţă există
aceste două posibilităţi, dar un apel prin referinţă este mai dificil de implementat. Conţinutul
memoriei spre care indică adresa transmisă ca argument este copiat, inclus în mesaj şi
transmis severului. Când se obţine răspunsul reziduul clientului copiază valoarea respectivă în
spaţiul de memorie indicat de argumentul iniţial. Deşi această metodă funcţionează pentru
tipuri de date simple ea nu se poate aplica unor structuri de date mai complexe.
Page 12
Capitolul 1 - Sisteme distribuite, aspecte teoretice 11
Dintre erorile posibile într-un apel de procedură la distanţă amintim: clientul nu poate
localiza serverul, mesajul cerere de la client pierdut, mesajul răspuns de la server pierdut,
serverul cade după ce a primit cererea sau clientul cade după ce a trimis cererea. Fiecare
dintre aceste situaţii are anumite particularităţi şi metode specifice de tratare. În general
apelul procedurilor la distanţă foloseşte mecanismul excepţiilor pentru semnalarea şi tratarea
erorilor.
Modelul de comunicare bazat pe apelul procedurii la distanţă este eficient şi des folosit
în cazul sistemelor distribuite reducând într-o oarecare măsură complexitatea inerentă a
modelului de comunicare bazat pe mesaje, dar cu toate acestea mai există încă probleme în
special cu asigurarea unei transparenţe totale. Unele aspecte ale programării clasice încă nu
pot fi transpuse în mecanismul apelului de procedură la distanţă, ca de exemplu variabilele
globale.
Programarea obiectuală si-a dovedit eficienţa în aplicaţiile nedistribuite, iar principiile
ei au fost aplicate şi în cazul programării sistemelor distribuite, astfel s-a născut apelul
obiectelor la distanţa (Remote Object Invocation). Principala caracteristică a unui obiect
este faptul că încapsulează o stare şi defineşte o serie de metode care o pot modifica.
Metodele sunt disponibile prin intermediul unei interfeţe. În cazul obiectelor distribuite există
o separare între starea obiectului care este salvată pe un calculator şi interfeţele lui care pot fi
plasate pe alte calculatoare. Când un client doreşte să acceseze un obiect distribuit o
implementare a interfeţei obiectului numită proxy se încarcă în spaţiul de adrese al clientului,
similar cu reziduul din cazul apelului de procedură la distanţă. Acest proxy este responsabil
de transmiterea argumentelor la distanţă şi primirea valorii returnate. Principala caracteristică
a obiectelor distribuite este că starea lor nu este distribuită, ea există pe un singur calculator,
iar interfeţele obiectului sunt distribuite.
Universitatea "Petru Maior" 2005
Page 13
Capitolul 1 - Sisteme distribuite, aspecte teoretice 12
1.3 Sincronizarea în sistemele distribuite
În orice sistem care realizează o procesare a datelor în paralel trebuie să existe o
sincronizare între procese. Dacă procesele rulează pe acelaşi calculator aceasta se poate face
uşor utilizând semafoare, dar dacă procesele rulează pe calculatoare diferite, cum se întâmplă
în cazul unui sistem distribuit, trebuie utilizate alte metode.
1.3.1 Sincronizarea ceasurilor
În multe din aceste metode pentru sincronizarea proceselor timpul joacă un rol foarte
important. Cum într-un sistem distribuit nu există un ceas unic sau altă sursă globală de aflare
a timpului este necesară existenţa unui mecanism de sincronizare a ceasurilor din sistem în
caz contrar putând apărea situaţii ambigue din punct de vedere al desfăşurării lor în timp.
Unul dintre algoritmii folosiţi pentru sincronizare pleacă de la următoarele premise: nu
este necesar ca sincronizarea să fie absolută (adică dacă două procese nu comunică, ele nu
trebuie sincronizate în timp) şi procesele nu trebuie să cadă de acord asupra timpului exact, ci
doar asupra ordinii de desfăşurare a evenimentelor. Datorită ultimei premise, care spune că
timpul în sistem nu trebuie să coincidă cu cel real, ci doar să asigure cauzalitatea
evenimentelor ceasurile sistemului au primit denumirea de ceasuri logice. Algoritmul are la
bază relaţia a→b ( a se întâmplă înainte de b) care este adevărată numai atunci când
evenimentul a este plasat în timp înaintea lui b. De exemplu dacă a reprezintă transmiterea
unui mesaj şi b recepţionarea lui atunci relaţia a→b este adevărată deoarece transmiterea
mesajului durează un interval finit de timp.
Universitatea "Petru Maior" 2005
Page 14
Capitolul 1 - Sisteme distribuite, aspecte teoretice 13
În Fig. 1.5a sunt reprezentate trei procese care comunică şi momentele de timp la care
sunt transmise mesajele. Se observă uşor ce se poate întâmpla când ceasurile lor nu sunt
sincronizate. Mesajul C este transmis de procesul P3 la momentul 60 şi este recepţionat de
procesul P2 la momentul 56, similar mesajul D este transmis la momentul 64 şi recepţionat la
momentul 54, înainte de a fi transmis conform ceasului procesului P1. În Fig. 1.5b este
prezentată soluţia oferită de algoritm pentru această situaţie anormală. Astfel de câte ori se
primeşte un mesaj ceasul sistemului este ajustat în funcţie de cel al sistemului care l-a
transmis, iar dacă ţinem cont că timpul se scurge într-o singură direcţie ajustarea se face
totdeauna prin adăugare şi niciodată prin scădere. Mai există o regulă, între două evenimente
succesive trebuie să există o diferenţă de cel puţin o unitate de timp, deci la fiecare transmisie
sau recepţie a unui, mesaj ceasul se incrementează cu o unitate. Multe sisteme distribuite
folosesc acest algoritm pentru asigurarea unei ordini a evenimentelor şi evitarea ambiguităţii.
Deşi metoda prezentată mai sus este suficientă în multe cazuri, există şi sisteme în care
valoarea reală a ceasului este importată, de exemplu sistemele care lucrează în timp real. În
aceste cazuri se utilizează ceasuri fizice a căror sincronizare se face prin alte metode.
Sincronizarea se face în două etape: în primul rând un nod al sistemului trebuie să fie
sincronizat cu UTC (Universal Coordinated Time), apoi celelalte noduri trebuie să fie la
rândul lor sincronizate cu acesta. Pentru prima fază există la dispoziţie mai multe soluţii
tehnice cum ar fi sateliţii sau diverse emiţătoare de unde radio special construite în acest scop.
Pentru partea a doua a procesului de sincronizare a ceasurilor au fost dezvoltaţi mai mulţi
algoritmi toţi bazându-se pe acelaşi model al sistemului. Conform modelului fiecare
calculator are un cronometru (timer) care cauzează o întrerupere de H ori pe secundă, la
fiecare întrerupere se incrementează un contor a cărui valoare iniţială C0 a fost stabilită de
comun acord. Dacă notăm UTC cu t atunci valoarea ceasului pe un anumit calculator se
calculează ca o funcţie de t pe baza valorii contorului C. În cazul ideal ( ) 1=dt
tdC , dar în
realitate există o abatere şi relaţia devine ( ) ρρ +≤≤− 11dt
tdC , unde ρ este abaterea maximă
garantată de producătorul circuitului electronic. Dacă se impune condiţia ca diferenţa maximă
între oricare două ceasuri din sistem să fie δ atunci intervalul de timp între două sincronizări
succesive trebuie să fie de cel mult ρδ2
secunde.
Universitatea "Petru Maior" 2005
Algoritmul lui Christian este aplicabil sistemelor care au un ceas sincronizat cu
UTC, scopul fiind sincronizarea celorlalte ceasuri. Nodul sincronizat UTC se numeşte de
Page 15
Capitolul 1 - Sisteme distribuite, aspecte teoretice 14
time sever şi de câte ori primeşte un mesaj cerere de la un nod al sistemului are datoria să
răspundă cât mai repede posibil cu un mesaj care conţine valoarea ceasului real urmând ca
nodul care a făcut cererea iniţială să-şi ajusteze ceasul dacă este nevoie. Pentru a elimina
eroarea introdusă de timpul de propagare se măsoară intervalul de timp scurs între momentul
trimiterii cererii T0 şi momentul primirii răspunsului T1. Timpul de propagare al mesajului se
aproximează ca jumătatea acestui interval 2
01 TT −. Pentru o precizie mai mare se poate lua in
calcul şi timpul de tratare a cererii de către server I, astfel relaţia de mai sus devine
201 ITT −−
. Tot pentru mărirea preciziei se pot face mai multe măsurători ale timpului de
propagarea şi apoi utilizarea unei medii aritmetice a valorilor obţinute. Ţinând cont de direcţia
unică de curgere a timpului ajustarea ceasurilor se face doar prin deplasare înainte, deci dacă
ceasul care trebuie ajustat este înainte faţă de timpul real el va fi încetinit până când atinge
valoarea corectă şi nu este deplasat înapoi direct la valoarea corectă.
Algoritmul Berkeley se foloseşte în sistemele în care nu există un nod sincronizat
UTC. În acest caz time server-ul nu mai are un rol pasiv ci unul activ. În mod periodic
interoghează toate nodurile, iar acestea răspund trimiţând valoarea ceasurilor. Pe baza
rezultatelor primite severul calculează o medie pe care o transmite înapoi nodurilor urmând ca
acestea să-şi ajusteze ceasurile corespunzător.
Dezavantajul celor doi algoritmi prezentaţi mai sus este că ambii se bazează pe un
element central, time server-ul, care poate distruge tot mecanismul de sincronizare în cazul
unei defecţiuni. Există şi algoritmi distribuiţi pentru sincronizarea ceasurilor. Unul dintre ele
funcţionează în felul următor: toate nodurile sistemului difuzează mesaje care conţin valoarea
ceasului propriu, la intervale prestabilite de timp, iar pe baza mesajelor primite de la celelalte
noduri îşi ajustează la rândul lor ceasul, după o anumită regulă.
Sincronizarea ceasurilor este utilă în multe situaţii cum ar fi controlul retransmisiei
mesajelor în cazul căderii unor calculatoare sau pentru menţinerea consistenţei copiilor locale
ale datelor.
1.3.2 Excluziunea mutuală
Universitatea "Petru Maior" 2005
Excluziunea mutuală este utilă pentru a controla accesul la resursele folosite în comun
de mai multe procese. În sistemele centralizate este realizată uşor prin definirea unor secţiuni
critice cu ajutorul semafoarelor. În cazul sistemelor distribuite secţiunile critice sunt mai
dificil de implementat.
Page 16
Capitolul 1 - Sisteme distribuite, aspecte teoretice 15
O abordare posibilă în realizarea excluziunii mutuale este simularea modului de
realizare într-un sistem centralizat. De câte ori un proces doreşte să intre în secţiunea critică
trebuie să ceară permisiunea unui coordonator, care poate să permită sau nu accesul. Dacă în
momentul cererii alt proces utilizează resursa cererea este adăugată într-o coadă şi accesul
este permis când resursa devine disponibilă. Această metodă de control al accesului este uşor
de implementat şi necesită un număr mic de mesaje: cerere drept acces, acordare acces şi
eliberare resursa. Din existenţa unui element central, coordonatorul, derivă anumite
dezavantaje cum ar fi: căderea nodului respectiv duce la căderea întregului mecanism de
control al accesului şi în sistemele mari încărcarea asupra coordonatorului ar deveni
considerabil de mare ceea ce poate duce la scăderea performanţelor. Alegerea unui nod
coordonator se poate face în mod dinamic prin utilizarea a diverşi algoritmi pe bază de vot.
Secţiunile critice pot fi implementate şi folosind un algoritm distribuit. Se pleacă de la
următoarele premise: există o ordine bine determinată a evenimentelor din sistem, cu alte
cuvinte pentru oricare două mesaje se poate determina cu exactitate care dintre ele a fost
transmis primul şi transmiterea mesajelor este fiabilă. De câte ori un proces intenţionează să
intre într-o secţiune critică trebuie mai întâi să obţină permisiunea celorlalte procese din
sistem. Pentru aceasta transmite un mesaj cerere tuturor nodurilor din sistem inclusiv lui
însuşi, aşteaptă până când primeşte acceptul de la toate şi apoi intră în secţiunea critică. Când
un proces primeşte o cerere de permisiune există trei posibilităţi:
- dacă procesul nu este în secţiunea critică şi nu intenţionează să intre trimite
un mesaj de acceptare.
- dacă procesul este deja în secţiunea critică nu trimite un mesaj de
acceptare, ci adaugă cererea într-o coadă.
- dacă procesul nu este în secţiunea critică, dar intenţionează să intre,
compară momentul în care a transmis mesajul celălalt proces cu momentul
în care a transmis el mesajul de cerere şi cel care a transmis primul câştigă
dreptul de a intra.
Universitatea "Petru Maior" 2005
Când procesul iese din secţiunea critică trimite un mesaj de acceptare tuturor proceselor din
coada de aşteptare şi apoi o goleşte. Punctul slab al acestui algoritm este imposibilitatea
diferenţierii între căderea unui nod şi intrarea lui în secţiunea critică. Dacă un nod a căzut el
nu va putea trimite un mesaj de acceptare când este transmisă o cerere, în consecinţă celelalte
noduri vor considera că secţiunea critică este ocupată. Problema poate fi rezolvată prin
introducerea unui mesaj suplimentar, opusul acceptării unei cereri, refuzul ei. Astfel se poate
determina dacă un nod a căzut sau este în secţiunea critică. Un alt dezavantaj este că numărul
Page 17
Capitolul 1 - Sisteme distribuite, aspecte teoretice 16
mare de mesaje necesare, 2(n-1) unde n este numărul nodurilor, pentru fiecare intrare în
secţiunea critică vor conduce la o încărcare suplimentară a reţelei. Acest algoritm nu este mai
eficient decât cel anterior prezentat, dar demonstrează posibilitatea unei abordări distribuite a
problemei secţiunii critice.
O abordare complet diferită este întâlnită în algoritmul Token Ring. Nodurile
sistemului sunt organizate sub forma unui inel, ordinea nu contează, important este ca fiecare
să-şi cunoască vecinii.
Dreptul de a intra în secţiunea critică îl are
doar nodul care deţine token-ul. Când se
iese din secţiunea critică token-ul este
transmis mai departe următorului nod din
inel. Astfel un nod care doreşte accesul în
secţiunea critică nu are decât să aştepte
până când primeşte dreptul.
Problema în cazul acestui algoritm este dificultatea detecţiei pierderii token-ului. Cum
timpul scurs până la întoarcerea lui într-un nod nu este limitat acesta nu poate fi un criteriu
pentru detecţia pierderii. În consecinţă s-a impus trimiterea unei confirmări de către nodul
care primeşte token-ul către cel care l-a deţinut anterior. Astfel se poate face şi detecţia
nodurilor căzute, iar pentru a fi posibilă eliminarea lor din inel nodurile trebuie să conţină şi
informaţii despre structura acestuia.
Fiecare din cei trei algoritmi prezintă avantaje şi dezavantaje alegerea unuia făcându-
se în funcţie de lungimea secţiunilor critice şi frecvenţa cu care sunt utilizate.
1.3.3 Tranzacţiile
Tranzacţiile oferă o abstractizare la un nivel mai înalt, care ascunde de programator
necesitatea excluziunii mutuale şi lucrul cu secţiunile critice, astfel încât acesta se poate
concentra asupra scopului sistemului distribuit. Modelul tranzacţiilor a fost preluat din lumea
afacerilor unde este des utilizat.
Universitatea "Petru Maior" 2005
O tranzacţie se desfăşoară în mai multe etape. Pentru început un proces anunţă că
doreşte să realizeze o tranzacţie împreună cu unul sau mai multe procese. Se negociază
opţiuni, se creează obiecte şi se realizează operaţiile necesare. Când toată munca a fost
terminată iniţiatorul tranzacţiei anunţă că doreşte ca toate schimbările făcute să devină
permanente. Dacă celelalte procese participante sunt de acord starea sistemului este salvată,
Page 18
Capitolul 1 - Sisteme distribuite, aspecte teoretice 17
dar dacă cel puţin unul refuză sau din cauza unei erori nu poate fi de acord, sistemul este adus
în starea iniţială, din momentul în care a început tranzacţia.
Pentru a putea utiliza tranzacţii într-un sistem distribuit trebuie să fie implementate
următoarele primitive:
- ÎNCEPUT_TRANZACŢIE: delimitează începutul tranzacţiei.
- SFÂRŞIT_TRANZACŢIE: marchează sfârşitul tranzacţiei şi
permanentizarea schimbărilor făcute.
- ANULARE_TRANZACŢIE: anulează toate schimbările făcute până în
acel punct şi readuce sistemul în starea iniţială.
Operaţiile dintre ÎNCEPUT_TRANZACŢIE şi SFÂRŞIT_TRANZACŢIE se efectuează toate,
corect, sau deloc.
Tranzacţiile au patru proprietăţi esenţiale. Ele sunt:
- atomice: ele se execută în totalitate sau deloc, sunt indivizibile, iar stările
intermediare sunt invizibile din exterior.
- consistente: constantele sistemului nu sunt modificate, chiar dacă în timpul
executării tranzacţiei, pentru o perioadă scurtă de timp, există modificări la
sfârşitul tranzacţiei ele sunt aduse în starea iniţială.
- izolate (serializabile): chiar dacă două tranzacţii se desfăşoară simultan
rezultatul final arată ca şi cum ele s-ar fi desfăşurat secvenţial.
- durabilă: din momentul în care tranzacţia s-a încheiat schimbările făcute
devin permanente, starea anterioară nu mai poate fi restaurată.
Există şi posibilitatea unor tranzacţii imbricate când o tranzacţie este alcătuită din mai
multe subtranzacţii. În acest caz subtrazancţiile nu mai sunt durabile pentru că dacă tranzacţia
de la nivelul cel mai înalt este anulată schimbările făcute de acestea sunt şi ele anulate.
1.3.4 Interblocajul în sistemele distribuite
Interblocajul în sistemele distribuite este similar cu cel din sistemele centralizate,
doar că este mai dificil de prevenit, detectat şi rezolvat. Există patru metode pentru tratarea
lui:
a) Ignorarea: nu se implementează nici un mecanism pentru detectarea sau prevenirea
interblocajului.
Universitatea "Petru Maior" 2005
b) Detecţia: s-au dezvoltat mai mulţi algoritmi pentru detectarea interblocajului în
sistemele distribuite. Algoritmul centralizat imită algoritmul pentru detectarea
interblocajului utilizat în sistemele centralizate. Fiecare nod construieşte un graf cu procesele
Page 19
Capitolul 1 - Sisteme distribuite, aspecte teoretice 18
şi resursele pe care le conţine. De asemenea un nod coordonator reuneşte toate aceste grafuri
într-un graf al sistemului. De câte ori detectează circuite, poate să oprească anumite procese
pentru evitarea interblocajului. Nodurile comunică coordonatorului schimbările apărute în
grafurile proprii pentru ca graful sistemului să fie actualizat. Pot apărea probleme însă când
mesajele de actualizare nu sosesc în ordinea în care au fost transmise şi coordonatorul
detectează interblocaje false. Problema poate fi rezolvată prin utilizarea unei metode de
ordonare a mesajelor, dar aceasta implică existenţa unui timp global şi de aici necesitatea unor
algoritmi de sincronizarea a ceasurilor sistemului. Există şi algoritmi distribuiţi pentru
detectarea interblocajului, dar în cazul acestora s-a demonstrat că teoria diferă mult de
practică şi de multe ori metodele propuse nu sunt eficiente.
c) Prevenţia: se poate face prin utilizarea mai multor tehnici. De exemplu un proces
nu poate utiliza decât o resursă la un anumit moment sau blocarea tuturor resurselor necesare
se face la început şi nu pe parcurs sau procesul este obligat să elibereze toate resursele pe care
le blochează atunci când cere una nouă. Aceste metode sunt greu de utilizat în practică de
aceea au fost dezvoltaţi algoritmi care se bazează pe tranzacţii sau pe timpul global.
d) Evitarea: este dificil de realizat în practică şi nu se utilizează în sistemele
distribuite.
Universitatea "Petru Maior" 2005
Page 20
Capitolul 1 - Sisteme distribuite, aspecte teoretice 19
1.4 Consistenţa datelor
1.4.1 Replicare şi consistenţă.
O chestiune importantă în sistemele distribuite este replicarea datelor, principalele
motive pentru aplicarea ei fiind creşterea fiabilităţii şi creşterea performanţelor sistemelor.
Replicarea poate duce la îmbunătăţirea fiabilităţii pentru că dacă există mai multe
copii ale datelor atunci când una din ele devine indisponibilă sistemul poate să funcţioneze în
continuare folosind copiile rămase. În plus oferă şi o protecţie împotriva datelor incorecte,
dacă din diverse motive una dintre copii conţine o eroare se pot accesa toate replicile existente
şi se va lua în considerare valoarea conţinută de majoritatea.
Al doilea motiv pentru replicarea datelor ar fi creşterea performanţelor sistemului şi se
aplică atunci când este necesară o scalare a acestuia, pe criterii numerice sau geografice. Dacă
o anumită resursă este utilizată de mulţi clienţi crearea unei replici a ei va creşte semnificativ
performanţele prin reducerea timpul de acces. De asemenea într-un sistem distribuit pe o zonă
geografică de dimensiuni mari plasarea unei replici a datelor mai aproape de client va reduce
timpul de acces.
Cu toate că replicarea oferă multe avantaje ea aduce cu sine şi o problemă destul de
importantă, asigurarea consistenţei datelor. Dacă există mai multe copii ale unei date
modificarea uneia dintre ele trebuie propagată şi la celelalte. De aici apare o dilemă, pe de o
parte replicarea produce o creştere a performanţelor şi a fiabilităţii, iar pe de altă partea
necesitatea asigurării consistenţei duce la o scăderea a performanţelor datorită creşterii
traficului în reţea şi necesităţii implementării unor mecanisme de sincronizare a replicilor. În
realitate, de cele mai multe ori, soluţia este relaxarea restricţiilor de consistenţă. În ce măsură
se poate face acest lucru depinde foarte mult de natura datelor precum şi de scopul lor.
1.4.2 Modele de consistenţă a datelor.
Universitatea "Petru Maior" 2005
În mod tradiţional consistenţa datelor a fost discutată în contextul operaţiilor de
scriere/citire asupra unor date utilizate în comun de mai multe procese, date disponibile prin
diverse mijloace. Se pleacă de la ipoteza că fiecare proces are o copie locală a datelor şi toate
operaţiile de scriere (cele care modifică datele) sunt propagate la toate copiile. Un model de
consistenţă defineşte un set de reguli care, dacă sunt respectate de toate procesele, sistemul
va funcţiona corect. În mod normal în urma unei operaţii de citire, procesul care o execută, se
aşteaptă să obţină o valoare în care este reflectată ultima operaţie de scriere efectuată asupra
datelor. În absenţa unui ceas global este dificil de stabilit care operaţie de scriere a avut loc
Page 21
Capitolul 1 - Sisteme distribuite, aspecte teoretice 20
ultima. În consecinţă fiecare model restricţionează valorile pe care le poate returna operaţia de
citire. Cum era de aşteptat modelele cu restricţii mai mici sunt mai uşor de implementat, dar
nu sunt foarte performante, iar modelele cu restricţii mai mari sunt mai dificil de implementat,
dar oferă performanţe mai bune.
În continuare sunt prezentate pe scurt cele mai cunoscute modele de consistenţă şi
câteva din caracteristicile lor:
a) Consistenţa strictă: este modelul ideal, cel mai strict şi se defineşte prin condiţia ca
orice operaţie de citirea asupra unei date x să returneze valoarea corespunzătoare celei mai
recente operaţii de scriere asupra lui x. Condiţia este naturală şi evidentă, dar implică
existenţa unui timp global absolut, dificil de obţinut.
b) Consistenţa secvenţială: este o consistenţă mai slabă decât cea strictă şi se bazează
pe condiţia ca toate operaţiile făcute, de către toate procesele, asupra datelor, să se execute în
mod secvenţial, iar operaţiile făcute de un anumit proces să apară în această secvenţă în
ordinea specificată de programul procesului respectiv. În cadrul acestui model nu se ia în
considerare momentul execuţiei unor acţiuni, ci doar ordinea în care sunt executate.
c) Consistenţa liniară: este mai slabă decât consistenţa strictă, dar mai puternică decât
cea secvenţială. Presupune existenţa unor ceasuri sincronizate şi atribuirea unor mărci de timp
fiecărei operaţii. La condiţia impusă pentru consistenţa secvenţială se mai adaugă una care
impune ca la stabilirea ordinii operaţiilor să se ţină cont şi de marca lor de timp.
d) Consistenţa cauzală: reprezintă o relaxare a restricţiilor consistenţei secvenţiale prin
faptul că se face distincţie între evenimentele care sunt legate printr-o relaţie de cauzalitate şi
celelalte. Condiţia impusă în cadrul acestui model este ca operaţiile de scriere care pot fi
legate printr-o relaţie de cauzalitate să fie văzute de toate procesele în aceeaşi ordine. Alte
operaţii de scriere pot fi văzute în ordine diferită de către diverse procese.
Universitatea "Petru Maior" 2005
e) Consistenţa FIFO: în acest caz se renunţă la restricţia impusă pentru consistenţa
cauzală ca evenimentele legate printr-o relaţie de cauzalitate să fie văzute în aceeaşi ordine de
Page 22
Capitolul 1 - Sisteme distribuite, aspecte teoretice 21
toate procesele singura condiţie impusă fiind ca operaţiile de scriere executate de un anumit
proces să fie văzute de către celelalte procese în ordinea în care au fost executate. Operaţiile
de scriere din procese diferite pot fi văzute în orice ordine.
f) Consistenţa slabă: s-a introdus pentru a evita necesitatea actualizării replicilor cu
rezultatele intermediare ale unei operaţii mai lungi şi se realizează prin asocierea unor
variabile de sincronizare datelor. O variabilă de sincronizare S are asociată o singură
operaţie sincronizează(S) care propagă toate modificările făcute de un proces asupra copiei
locale a datelor în tot sistemul şi invers. Modelele de consistenţă slabă au trei proprietăţi:
accesul la variabilele de sincronizare este consistent secvenţial, nici o operaţie asupra unei
variabile de sincronizare nu este permisă până când operaţiile de scriere anterioare nu s-au
terminat peste tot şi nici o operaţie de citire sau scriere asupra datelor nu este permisă până
când toate operaţiile de sincronizare anterioare nu s-au încheiat.
1.4.3 Protocoale de distribuire şi consistenţă.
Protocoalele de distribuire descriu modul în care modificările asupra datelor sunt
propagate în sistemul distribuit, indiferent de modelul de consistenţă ales. O problemă de
design a sistemelor distribuite este stabilirea amplasării replicilor, a momentului în care se
creează şi de către cine. Astfel se disting mai multe categorii de replici:
- permanente: sunt cele create iniţial şi există pe tot parcursul funcţionării
sistemului.
- iniţiate de server: sunt copii ale datelor create în mod dinamic de către
proprietarul lor, în timpul funcţionării sistemului, pentru creşterea
performanţelor în cazul unor cereri mari.
- iniţiate de client: sunt copii locale ale datelor create de client pentru
reducerea timpului de acces; se pretează foarte bine cazurilor când
majoritatea operaţiilor efectuate asupra datelor sunt cele de citire; clientul
este responsabil pentru asigurarea consistenţei datelor.
Universitatea "Petru Maior" 2005
O altă chestiune care ţine de designul sistemului distribuit este ce anume să se transmită
replicilor şi aici există trei posibilităţi: propagarea unor notificări de modificare a datelor
(copiile sunt informate că există modificări), transferul datelor de la o copie la alta
(modificările asupra datelor sunt transferate direct) şi propagarea operaţiilor de actualizare
(exista o serie de operaţii de actualizare definite asupra datelor astfel spre replici se transmite
doar care operaţie trebuie efectuată). În ceea ce priveşte protocoalele de actualizare se disting
două categorii: protocoale iniţiate de server şi protocoale iniţiate de client. În cazul celor din
Page 23
Capitolul 1 - Sisteme distribuite, aspecte teoretice 22
prima categorie propagarea modificărilor către replici se face fără cererea acestora şi se aplică
mai ales replicilor stabile şi a celor iniţiate de server. Protocoalele din a doua categorie se
aplică replicilor iniţiate de client, iar actualizarea se face, dacă este nevoie, atunci când
clientul accesează datele.
Protocoalele de consistenţă descriu modul de implementare al unui anumit model de
consistenţă. Cele mai cunoscute sunt protocoalele bazate pe copie primară. Un astfel de
protocol este descris în figura următoare.
Modificarea datelor se face în mai multe etape: în primul rând este modificată copia locală,
urmează ca modificarea făcută să se propage în tot sistemul, prima data la serverul care deţine
copia primară, apoi la serverele care deţin copii de siguranţă. Operaţia de modificare se
încheie când clientul primeşte confirmarea că toate replicile au fost actualizate. În tot acest
timp clientul este blocat. Deşi protocolul funcţionează bine şi asigură consistenţa, el este
foarte lent. Există însă şi o variantă a lui în care clientul este deblocat după ce copia locală a
fost modificată urmând ca replicile să fie actualizate în fundal.
Universitatea "Petru Maior" 2005
Page 24
Capitolul 1 - Sisteme distribuite, aspecte teoretice 23
1.5 Securitatea în sistemele distribuite
1.5.1 Politici şi mecanisme de securitate
Securitatea într-un sistem de calcul poate fi privită ca încercarea de a proteja serviciile
şi datele pe care le oferă de ameninţările venite din exterior. Ameninţările pot lua diverse
forme cum ar fi: interceptarea comunicaţiilor, întreruperea unor servicii oferite (prin acţiuni
răuvoitoare), modificarea neautorizată a datelor existente sau adăugarea neautorizată a unor
date noi.
În contextul securităţii sistemelor de calcul există două elemente importante: politicile
de securitate şi mecanismele de securitate. O politică de securitate descrie cu exactitate ce
acţiuni sunt permise pentru toate entităţile de sistem (utilizatori, servicii, calculatoare etc.), iar
odată ce a fost definită o politică de securitate se pot alege mecanismele prin care ea va fi
impusă. Printre cele mai importante mecanisme de securitate sunt următoarele:
- criptarea: asigură confidenţialitatea oferind posibilitatea ca datele să fie
astfel convertite încât un posibil atacator să nu le înţeleagă; în acelaşi timp
asigură şi integritatea permiţând detecţia unor modificări neautorizate.
- autentificarea: este folosită pentru a verifica identitatea unui utilizator,
client, etc. şi se face înainte ca să i se permită acestuia utilizarea unui
serviciu sau accesarea unor date.
- autorizarea: după ce un client este autentificat se verifică dacă respectivul
este autorizat să execute operaţiile pe le doreşte.
- auditul: este un mecanism prin care se înregistrează toate acţiunile
clienţilor; nu oferă protecţie împotriva atacurilor, dar în schimb dacă
acestea se întâmplă totuşi poate contribui la descoperirea identităţii
atacatorului.
1.5.2 Canale securizate
Universitatea "Petru Maior" 2005
În practică securitatea într-un sistem distribuit se reduce la două aspecte majore:
securitatea comunicaţiilor şi autorizarea. Pentru protejarea comunicaţiilor există canalele
securizare care asigură confidenţialitatea şi integritatea mesajelor transmise.
Confidenţialitatea şi integritatea trebuie să coexiste, ele nu sunt utile separat, pentru că este
inutil să cunoşti sursa mesajului dacă nu poţi să fii sigur că mesajul este corect la fel cum este
inutil să fii sigur de corectitudinea mesajului dacă nu-i cunoşti sursa. Prima etapă care trebuie
Page 25
Capitolul 1 - Sisteme distribuite, aspecte teoretice 24
parcursă pentru stabilirea unui canal securizat este autentificarea părţilor. În figura următoare
este prezentat un algoritm de autentificare bazat pe cheie secretă.
A şi B sunt cele două părţi care vor să
stabilească un canal securizat, K este
cheia secretă cunoscută de ambele părţi.
Primul mesaj este transmis de A şi prin
el îşi specifică identitatea. B răspunde
prin transmiterea unei “provocări” Rb, de
obicei un număr, pe care A îl criptează
folosind cheia secretă K şi îl transmite
înapoi. Ţinând cont că doar A şi B
cunosc valoarea cheii secrete
după decriptare B poate fi sigur că A este de cealaltă parte a canalului. Urmează ca A să
transmită la rândul ei o provocare la care dacă B va răspunde corect autentificarea se
consideră încheiată. Problema acestui algoritm este scalabilitatea, în cazul sistemelor mari
trebuie să existe o mulţime de chei, de aceea se poate utiliza un centru de distribuire cheilor
care să se ocupe de administrarea şi distribuirea lor.
După ce identităţile părţilor care comunică au fost stabilite trebuie asigurate
confidenţialitatea şi integritatea canalului. Confidenţialitatea, adică protecţia împotriva altor
părţi răuvoitoare care interceptează mesajele transmise, este asigurată relativ uşor prin
criptare cu cheie publică sau secretă, dar integritatea canalului, adică protecţia mesajelor
împotriva modificării este mai greu de asigurat. O soluţie ar fi semnătura digitală aplicată
mesajelor, care poate fi verificată şi astfel stabilită validitatea mesajului. Semnăturile digitale
pot fi ataşate mesajelor în mai multe moduri, o variantă destul de populară fiind folosirea unui
sistem de criptare cu cheie publică cum este RSA.
1.5.3 Controlul accesului
Într-un model de comunicare client-server după ce canalul securizat a fost stabilit
clientul poate să trimită serverului o serie de cereri pe care acesta să le execute. O cere a
clientului este executată doar dacă acesta are drepturile de acces necesare. Verificarea
dreptului de acces poartă numele de controlul accesului, iar acordarea drepturilor de acces se
numeşte autorizare. Pentru implementarea controlului accesului se poate utiliza un model
simplu ca cel prezentat în figura următoare.
Universitatea "Petru Maior" 2005
Page 26
Capitolul 1 - Sisteme distribuite, aspecte teoretice 25
Elementele principale prezente în acest model sunt subiecţii şi obiectele pe care
aceştia doresc să le acceseze. Subiecţii pot fi procese care acţionează în numele unor
utilizatori sau chiar alte obiecte care au nevoie de anumite servicii. Obiectele încapsulează o
anumită stare şi pun la dispoziţia subiecţilor o serie de metode care pot fi invocate prin
intermediul unei interfeţe. Controlul accesului constă în stabilirea căror metode ale unui
obiect pot fi invocate de un anumit subiect.
Administrarea drepturilor de acces poate fi făcută cu ajutorul unei matrici de control
al accesului în care se regăsesc toate obiectele şi toţi subiecţii. Fiecare rând corespunde unui
subiect şi fiecare coloană unui obiect. Dacă notăm matricea cu M atunci intrarea M(s,o) din
matrice conţine operaţiile pe care le poate executa subiectul s asupra obiectului o. Această
abordare poate fi ineficientă deoarece nu toţi subiecţii doresc să acceseze un anumit obiect de
aceea există alternativa ca fiecare obiect să aibă o listă de control al accesului care conţine
toţi subiecţii care au nevoie să acceseze obiectul respectiv. Totuşi aceste liste pot avea
dimensiuni considerabile în cazul sistemelor mari, iar o metodă de reducere a dimensiunii lor
este definirea unor domenii de protecţie. Un domeniu de protecţie este un set de perechi
(obiect, drepturi de acces) fiecare specificând ce operaţii pot fi executate asupra unui anumit
obiect. Se pot defini şi grupuri de acces pentru fiecare din ele fiind definite un set de drepturi
de acces. De câte ori un subiect doreşte să acceseze un obiect se verifică dacă grupul din care
face parte permite acest lucru şi în consecinţă i se permite sau i se interzice accesul.
Universitatea "Petru Maior" 2005
Page 27
Capitolul 2 – Modelul sistemului InfoStudent 25
Capitolul 2 - Modelul sistemului InfoStudent
1.1 Prezentare generală a aplicaţiei
InfoStudent este un sistem distribuit destinat în principal uzului studenţilor şi permite
utilizatorilor săi schimbul de fişiere într-un mod controlat şi organizat. Utilizatorii înregistraţi
sunt organizaţi într-o structură ierarhică de grupuri (de tip arbore) şi au posibilitatea să
publice, caute sau să acceseze fişierele existente. În diagrama UML din figura următoare este
prezentat sistemul din punctul de vedere al utilizatorului său.
Se disting doi actori Utilizatorul şi Administratorul, fiecare cu un set de acţiuni pe
care le poate executa. Se observă că există nişte acţiuni comune de aceea a fost creat actorul
Membru care este o generalizare a celorlalţi doi actori.
Acţiunile comune sunt următoarele:
- autentificare: se face pe baza unui nume de utilizator şi o parolă.
Universitatea "Petru Maior" 2005
- schimbare parola: odată ce s-a autentificat un membru poate să-şi schimbe
parola de acces.
Page 28
Capitolul 2 – Modelul sistemului InfoStudent 26
- publicare fişier: toţi membrii pot să publice fişiere care vor putea fi ulterior
accesate de ceilalţi membrii; nu se pot publica două fişiere simultan de
către acelaşi utilizator, operaţiile trebuie făcute consecutiv.
- căutare fişier: un membru poate să caute un anumit fişier pe baza pe baza
descrierii sale, după anumite cuvinte cheie; căutarea va returna toate
rezultatele care conţin cel puţin unul din cuvintele cheie.
- descărcare fişier: dacă fişierul căutat a fost găsit utilizatorul îl poate
descărca dacă grupul din care face parte îi permite acest lucru; utilizatorii
nu pot descărca două fişiere simultan.
- actualizare fişier: poate fi făcută doar de proprietarul fişierului, chiar dacă
este descărcat în momentul respectiv de alţi utilizatori; dacă operaţia de
actualizare s-a încheiat cu succes toate descărcările următoare vor accesa
versiunea actualizată a fişierului.
Utilizatorul are o singură acţiune specifică, ştergere fişier publicat, prin care poate să
şteargă un anumit fişier cu condiţia ca utilizatorul respectiv să fie proprietarul lui, adică cel
care l-a publicat iniţial.
Acţiuni specifice administratorilor (utilizatorii membri ai grupului “admin”):
- înregistrare utilizator: un administrator poate adăuga înregistra un nou
utilizator; informaţiile necesare sunt: nume utilizator, parola, grupul din
care face parte utilizatorul, o adresa de email prin care să poată fi contactat;
operaţia de înregistrare poate eşua dacă numele dorit este deja folosit sau
dacă grupul specificat nu există.
- ştergere utilizator: administratorii pot să şteargă utilizatori din tabelul
utilizatorilor înregistraţi şi astfel să nu le mai permită accesul; fişierele
publicate de utilizatorul respectiv vor fi în continuare disponibile.
- creare grup: se pot crea grupuri noi, care vor fi adăugate în structura
ierarhică existentă; la crearea unui nou grup trebuie specificate numele
noului grup şi numele grupului părinte din arborele existent; operaţia poate
eşua dacă grupul există deja sau dacă grupul părinte nu există.
Universitatea "Petru Maior" 2005
- ştergere grup: grupurile existente se pot şterge cu o condiţie să nu aibă
descendenţi în structura arborescentă a grupurilor; în momentul în care un
grup este şters toţi membri săi precum şi fişierele destinate grupului
respectiv vor fi mutate în grupul părinte.
Page 29
Capitolul 2 – Modelul sistemului InfoStudent 27
- schimbare grup utilizator: administratorii pot schimba grupul din care face
parte un utilizator.
- ştergere fişier: administratorii au posibilitatea să şteargă orice fişier
publicat indiferent cine este proprietarul.
Atributele fişierelor sunt:
- identificator unic: atribuit în momentul publicării.
- nume: la numele specificat de proprietarul său se adaugă automat data şi
ora la care a fost publicat pentru a da posibilitatea altor utilizatori să vadă
dacă există o versiune mai nouă decât cea descărcată de ei.
- proprietar: utilizatorul care a publicat fişierul respectiv.
- grup destinaţie: grupul ai cărui membri au dreptul să descarce fişierul.
- descriere: o scurtă descriere a fişierului după care se vor face operaţiile de
căutare.
Universitatea "Petru Maior" 2005
Page 30
Capitolul 2 – Modelul sistemului InfoStudent 28
1.2 Modelul de comunicare
Sistemul InfoStudent este alcătuit din mai multe noduri conectate între ele şi aplicaţii
client conectate la noduri reprezentând interfaţa dintre utilizatori şi sistem. Arhitectura
sistemului este prezentată în figura de mai jos.
Numărul de noduri este stabilit la pornirea sistemului şi nu se poate modifica în mod
dinamic pe parcursul funcţionării acestuia. Numărul de aplicaţii client conectate la un nod nu
este prestabilit, el variază pe parcursul funcţionării, dar este limitat din raţiuni de
implementare. Tot din aceste motive este limitat şi numărul maxim de noduri din sistem.
Aplicaţiile client nu pot fi conectate la mai mult de două noduri simultan, nodul la care se face
conectarea iniţială pentru autentificare şi apoi dacă este cazul o nouă conexiune este stabilită
cu nodul care conţine fişierul pe care utilizatorul doreşte să-l descarce.
Universitatea "Petru Maior" 2005
Comunicarea se face prin mesaje utilizând protocolul TCP/IP, iar modelul de
comunicare este unul de tip client-server. Legăturile dintre noduri, precum şi dintre
aplicaţiile client şi noduri, sunt bidirecţionale, bazate pe conexiune şi se realizează prin
SOCKET. Numărul de conexiuni este unde n este numărul de noduri din sistem, ele se
stabilesc iniţial, pe baza unui fişier unic, prezent în toate nodurile. Acest fişier conţine
adresele tuturor nodurilor, sortate după un anumit criteriu şi fiecare nod iniţiază conexiuni cu
toate nodurile aflate în această listă pe o poziţie superioară, astfel primul nod din listă va iniţia
n – 1 conexiuni, iar ultimul nici una. Aplicând acest algoritm simplu se vor realiza toate
2nC
Page 31
Capitolul 2 – Modelul sistemului InfoStudent 29
conexiunile necesare, iar dacă pe parcursul funcţionării una dintre conexiuni va fi întreruptă
nodul care a iniţiat-o va încerca restabilirea ei.
În cadrul modelului ales aplicaţiile nod joacă un dublu rol atât de server cât şi de
client. În relaţia cu aplicaţiile client joacă rolul de server, iar în relaţiile cu celelalte noduri
joacă rolul de sever sau de client, după caz. Severele din sistem au responsabilitatea de a
primi cererile clienţilor, sub forma unor mesaje, iar după ce acţiunea cerută a fost executată să
comunice clientului rezultatele tot printr-un mesaj.
Structura mesajelor este următoarea:
- lungimea mesajului: un număr întreg reprezentând lungimea în octeţi
mesajului.
- destinatar: un identificator intern al destinatarului mesajului.
- expeditor: un identificator intern al expeditorului mesajului.
- identificator mesaj: un număr întreg prin care să poată fi identificat tipul
mesajului;
- lungime parametru: fiecare mesaj poate să aibă un parametru, iar acest
câmp conţine lungimea în octeţi a parametrului.
- parametru: parametrul mesajului, specific fiecărui tip de mesaj.
Ţinând cont că legăturile din sistem sunt bazate pe conexiune câmpurile destinatar şi
expeditor ale mesajului nu vor conţine o adresă IP, ci un identificator al nodului sau clientului
respectiv, care nu este nevoie să fie unic în sistem, dar care este unic în cadrul unui nod. Sunt
definite 26 de mesaje, o prezentare detaliată a lor se găseşte în tabelul din Anexa 1. Tot acolo
este descris şi protocolul de comunicare între client şi server. Ca alternative de comunicare ar
fi fost apelul procedurii la distanţa sau apelul obiectelor la distanţa. În aceste cazuri
transmiterea mesajelor între noduri s-ar fi realizat automat, iar comunicarea s-ar fi rezumat la
nişte apeluri de procedură. Ţinând cont de arhitectura sistemului şi de scopul său am
considerat modelul client-server ca fiind cel mai potrivit.
Universitatea "Petru Maior" 2005
Page 32
Capitolul 2 – Modelul sistemului InfoStudent 30
1.3 Sincronizare
În multe sisteme distribuite utilizatorii sunt în situaţia de a utiliza în comun mai multe
resurse, de aceea se impune existenţa unor mecanisme pentru sincronizarea accesului la
acestea. În cazul sistemului InfoStudent resursele utilizate în comun sunt fişierele publicate,
iar sincronizarea accesului se face printr-un obiect denumit File Access Manager prezent în
fiecare nod.
După cum se observă şi din figură înainte de a putea accesa un anumit fişier, fie pentru citire,
fie pentru scriere, clientul trebuie să obţină permisiunea printr-o operaţie de blocare. Există
două tipuri de blocare, pentru citire (în cazul unei descărcări) sau pentru scriere (în cazul
ştergerii). Dacă un fişier a fost blocat pentru citire atunci toate încercările ulterioare de a-l
bloca pentru scriere vor eşua, dar el va putea fi blocat pentru citire, deci doi utilizatori diferiţi
pot să descarce un fişier în acelaşi timp. În schimb dacă fişierul a fost blocat pentru scriere
nici o altă încercare de blocare ulterioara, indiferent dacă este pentru citire sau pentru scriere,
nu va reuşi. Dacă nu s-ar realiza sincronizarea accesului există posibilitatea ca proprietarul
unui fişier să încerce ştergerea acestuia în timp ce este descărcat de un alt utilizator, situaţie ce
poate conduce la apariţia unor erori sau inconsistenţe în aplicaţia nod.
Universitatea "Petru Maior" 2005
În aceste condiţii dacă un fişier este accesat in mod frecvent de mulţi utilizatori s-ar
putea ajunge în situaţia în care proprietarul doreşte să-l şteargă şi să nu i se permită acest
lucru. Din acest motiv s-a oferit posibilitatea ca dacă fişierul nu poate fi şters măcar să poată
fi actualizat pentru această operaţie nefiind nevoie de blocarea lui. Operaţiile asupra fişierelor
descărcare, ştergere, actualizare nu se fac utilizând numele acestuia ca referinţă, ci folosind
Page 33
Capitolul 2 – Modelul sistemului InfoStudent 31
identificatorul unic atribuit în momentul publicării şi adăugării fişierului în baza de date. Când
se execută o operaţie de actualizare a unui fişier, după ce acesta a fost transferat cu succes de
la aplicaţia client la nod, se face asocierea în baza de date între numele sub care este salvat
noul fişier şi identificatorul vechiului fişier. Astfel, în condiţiile în care accesul la baza de date
are caracter atomic, toate operaţiile următoare se vor face asupra noii versiuni a fişierului şi
din acest motiv nu este nevoie de blocarea lui în momentul actualizării. Dacă fişierul vechi
este descărcat în acest timp de alt utilizator operaţia va continua normal ca şi cum nimic nu s-
ar fi schimbat.
O altă situaţie în care se impun măsuri de sincronizare apare în momentul căutării unui
fişier. Odată cu creşterea în dimensiuni a sistemului se va produce o creştere a numărului de
noduri şi inevitabil vor apărea întârzieri mai mari ale mesajelor în primul rând datorită
creşterii traficului în reţea şi în al doilea rând datorită creşterii încărcării aplicaţiilor nod.
Acelaşi lucru se poate întâmpla când legătura din noduri este asigurată de o reţea cu viteză de
transfer mai mică. Să presupunem că utilizatorul doreşte să facă o căutare în sistem, el va
introduce nişte cuvinte cheie şi va lansa căutarea. Un mesaj de tipul SEARCH, conţinând
cuvintele cheie după care se face căutarea ca parametri, va fi trimis către nodul la care este
conectată aplicaţia client, iar prin intermediul acestuia se va propaga în tot sistemul. Pe
măsură ce se găsesc fişiere care corespund cerinţelor utilizatorului mesaje de tipul
SEARCH_RESULT, fiecare conţinând un singur rezultat, se vor transmite spre nodul care a
iniţiat căutarea şi de acolo spre aplicaţia client unde vor fi vizualizate rezultatele de utilizator.
Din cauza timpilor de propagarea mai mari sau a unor noduri care procesează cererile mai lent
există posibilitatea ca până ce toate mesajele SEARCH_RESULT ajung la aplicaţia client,
utilizatorul să lanseze o nouă căutare după alte cuvinte cheie. În această situaţie utilizatorul s-
ar putea să aibă surpriza să obţină nişte rezultate care să nu corespundă cu criteriile de căutare
stabilite de el. Pentru evitarea acestor probleme mesajele SEARCH şi SEARCH_RESULT au
câte un parametru numit id_căutare, un număr întreg. Când aplicaţia client trimite un mesaj
SEARCH completează acest parametru şi salvează numărul respectiv. Toate rezultatele
căutării vor avea acelaşi număr ca parametru astfel aplicaţia client îl poate compara cu
numărul salvat pentru ultima căutare şi astfel se poate distinge un rezultat mai vechi de unul
pentru căutarea în curs. Id_căutare poate fi privit ca o marcă de timp a operaţiei de căutare
urmând ca marca de timp a rezultatelor să fie comparate cu cea a ultimei căutări lansate şi
astfel cele expirate să fie ignorate.
Universitatea "Petru Maior" 2005
Tot din motive de sincronizare fiecare mesaj de tip DOWNLOAD_DATA sau
UPLOAD_DATA, schimbat în timpul descărcării respectiv publicării fişierelor, are câte un
Page 34
Capitolul 2 – Modelul sistemului InfoStudent 32
parametru numit număr_pachet reprezentând numărul pachetului trimis de la nod respectiv
de la aplicaţia client. Numărătoarea pachetelor se face independent atât la client cât şi la
server astfel de câte ori se detectează o neconcordanţă între numărul pachetului recepţionat şi
numărul pachetului aşteptat se trage concluzia că s-a pierdut un pachet sau ordinea în care au
ajuns este greşită şi se iau măsuri în consecinţă. Este un mecanism simplu care asigură
protecţia necesară împotriva apariţiei fişierelor corupte.
Universitatea "Petru Maior" 2005
Page 35
Capitolul 2 – Modelul sistemului InfoStudent 33
1.4 Replicarea şi consistenţa datelor
Majoritatea datelor utilizate de sistem sunt salvate doar într-un singur nod fără a fi
replicate şi în alte locaţii. Acesta este cazul fişierelor sau al informaţiilor legate de utilizator,
cum ar fi numele, parola, grupul din care face parte, etc. Din această cauză se impune o
restricţie, aceea ca fiecare utilizator să se conecteze tot timpul la nodul în care a fost
înregistrat. Dacă fişierul pe care utilizatorul doreşte să-l descarce se află în alt nod şi trebuie
realizată o nouă conexiune cu nodul respectiv aceasta se poate face chiar dacă utilizatorul nu
este înregistrat acolo, deoarece conexiunile pentru descărcarea fişierelor nu necesită
autentificare. Fişierele vor fi publicate doar în nodul la care este conectat şi unde este
înregistrat utilizatorul. Pentru că fişierele şi datele de înregistrare ale utilizatorilor nu sunt
replicate fiabilitatea sistemului este mai redusa, în cazul căderii unui nod utilizatorii
înregistraţi acolo nu vor mai putea utiliza sistemul şi nici fişierele publicate de ei nu vor mai fi
disponibile.
Singurele date replicate sunt o parte a structurii ierarhice de grupuri. Astfel toate
nodurile pornesc cu aceeaşi structură iniţială de grupuri urmând ca la această să se adauge pe
parcursul funcţionării sistemului grupuri specifice utilizatorilor nodului respectiv.
Modificările ulterioare ale structurii de grupuri nu vor fi propagate în restul nodurilor. O
posibilă structură iniţială specifică mediului universitar este prezentată în figura următoare.
Este o structură aplicabilă în orice universitate, care apoi se poate particulariza după
preferinţele şi specificul utilizatorilor fiecărui nod. Această abordare permite utilizatorilor să
controleze accesul la fişierele publicate. Astfel dacă se alege ca grup destinaţie un grup
specific nodului unde au fost publicate, fişierele vor fi accesibile doar utilizatorilor nodului
(“comunităţii locale”), în schimb dacă se alege un grup predefinit, prezent în toate nodurile,
fişierul va fi disponibil tuturor utilizatorilor sistemului.
Universitatea "Petru Maior" 2005
Replicarea fiind stabilă, nu a fost nevoie de implementarea unor mecanisme de
propagare a modificărilor sau de asigurare a consistenţei datelor.
Page 36
Capitolul 2 – Modelul sistemului InfoStudent 34
1.5 Securitate
Sistemul InfoStudent este destinat în principal uzului studenţilor, nu este o aplicaţie
comercială şi nici nu este destinată schimbului de informaţii cu caracter confidenţial din acest
motiv politica de securitate definită nu este foarte strictă, iar mecanismele de securitate sunt
minimale. Comunicarea se face prin canale normale, nesecurizate, fără criptare cu un protocol
de autentificare simplu, fără cheie secretă. Pentru autentificare aplicaţia client trimite către
nod un mesaj de tipul REQ_AUTHENTICATE cu numele utilizatorului şi parola ca
parametri. Dacă numele utilizatorului a fost găsit şi parola corespunde nodul răspunde cu un
mesaj AUTHENTICATED. Dacă numele utilizatorului nu a fost găsit nodul răspunde cu un
mesaj INCORRECT_NAME, iar dacă numele a fost găsit dar parola nu corespunde se trimite
un mesaj INCORRECT_PASSWD.
După ce autentificarea a fost făcută utilizatorul poate să utilizeze sistemul.
Pentru controlul accesului a fost definită structura ierarhică de grupuri menţionată
anterior. Pe baza acesteia se controlează accesul utilizatorilor la fişierele publicate precum şi
operaţiile pe care le pot efectua. Utilizatorii nu pot descărca un anumit fişier decât dacă fac
parte direct sau prin moştenire din grupul căruia îi este destinat fişierul respectiv. Apartenenţa
prin moştenire se referă la faptul că un grup din structura arborescentă moşteneşte drepturile
grupului părinte, deci cu cât grupul destinaţie al unui fişier va fi mai aproape de rădăcina
arborelui cu atât va fi accesibil unui număr mai mare de utilizatori.
Universitatea "Petru Maior" 2005
În ceea ce priveşte operaţiile pe care le pot efectua utilizatorii în cadrul structurii
predefinite de grupuri se distinge un grup special admin, utilizatorii care fac parte din el fiind
consideraţi administratori ai sistemului. Ei au anumite drepturi pe care utilizatorii obişnuiţi nu
le au cum ar fi: posibilitatea de a modifica structura de grupuri, posibilitatea de a vizualiza
lista utilizatorilor înregistraţi, posibilitatea de a şterge sau înregistra utilizatori şi posibilitatea
de a şterge orice fişier publicat. De asemenea anumite operaţii, cum ar fi actualizarea, nu sunt
permise decât proprietarilor fişierelor.
Page 37
Capitolul 3 – Implementarea aplicaţiei 36
Capitolul 3 - Implementarea aplicaţiei
Atât aplicaţia nod cât şi aplicaţia client sunt scrise în limbajul C++ şi rulează pe
platforme Windows. Aplicaţia nod rulează ca serviciu şi utilizează funcţiile din Windows
API (Application Programming Interface) pentru accesarea facilităţilor oferite de sistemul de
operare. Aplicaţia client, interfaţa dintre utilizator şi sistem, a fost scrisă utilizând clasele puse
la dispoziţie de Microsoft în pachetul MFC (Microsoft Foundation Classes). Datele aplicaţiei
(lista utilizatorilor înregistraţi, lista fişierelor publicate, structura de grupuri, etc. ) sunt salvate
într-o bază de date, iar SGBD-ul folosit (Sistem de Gestiune a Bazelor de Date) este
Microsoft SQL Server. Conectarea la baza de date şi accesarea datelor se face utilizând
funcţiile ODBC (Open Data Base Conectivity), încapsulate într-o structură de clase specifică
aplicaţiei. Pentru că s-a folosit ODBC ca standard de conectare teoretic aplicaţia ar putea
utiliza orice SGBD pentru care există un driver ODBC.
3.1 Structura aplicaţiei nod
Din punct de vedere al funcţionării se pot distinge 3 componente mari, după cum se
vede şi din figura următoare. Diagrama de clase pentru aplicaţie se găseşte în Anexa 2.
Universitatea "Petru Maior" 2005
Page 38
Capitolul 3 – Implementarea aplicaţiei 37
Modulul de comunicare este responsabil cu administrarea tuturor conexiunilor şi cu primirea
şi transmiterea mesajelor. Modulul de procesare a mesajelor este componenta cea mai
importantă responsabilă cu satisfacerea cererilor formulate de clienţi, indiferent de natura lor,
alte noduri sau aplicaţii client. Modulul de acces la baza de date facilitează conectarea
aplicaţiei la baza de date şi permite acesteia efectuarea de operaţii asupra datelor.
3.1.1 Modulul de comunicare
Are în centru o instanţă a clasei CommunicationThread, un fir de execuţie
responsabil cu acceptarea conexiunilor iniţiate de aplicaţiile client, iniţierea de conexiuni cu
alte noduri din sistem, transmiterea mesajelor recepţionate modulului de procesare a
mesajelor şi trimiterea mesajelor către aplicaţiile client şi nodurile conectate.
După cum se poate observa şi din diagrama de mai sus clasa CommunicationThread
moşteneşte clasa MsgThread care la rândul ei moşteneşte clasa Thread. Aceasta din urmă
încapsulează o parte din funcţionalitatea legată de fire de execuţie prezentă în Windows API.
Universitatea "Petru Maior" 2005
Este o clasă abstractă care permite claselor derivate
crearea şi lansarea unui fir de execuţie. Membrul
m_hThread, de tipul HANDLE, este un număr întreg
utilizat de sistemul de operare pentru identificarea firului
de execuţie, iar membrii m_bIsRunning şi m_bRun
sunt utilizaţi pentru stabilirea stării şi controlul firului de
execuţie. Pentru lansarea unui fir de execuţie trebuie
derivată o clasă din Thread, suprascrisă metoda Run(),
instanţiată clasa, apoi pe rând se vor apela metodele
Page 39
Capitolul 3 – Implementarea aplicaţiei 38
Create() şi Start(). Firul de execuţie astfel creat va rula până când metoda Run() îşi va
încheia execuţia sau până când va fi apelată metoda Stop(). Starea firului de execuţie poate fi
interogată în orice moment apelând metoda IsRunning(). În figura de mai jos sunt prezentate
stările posibile pentru obiectul de tip Thread şi tranziţiile dintre stări.
Clasa MsgThread este tot o clasă abstractă care extinde clasa Thread şi oferă în plus
o coadă de mesaje, funcţionarea firului de execuţie depinzând de mesajele pe care le primeşte.
Membrul m_MsgQueue este structură de
tip coadă în care se pot adăuga mesaje
apelând metoda PostMessage(). Din cauză
că această coadă de mesaje poate fi accesată
din mai multe fire de execuţie este nevoie
de un mecanism de sincronizare, astfel s-a
introdus semaforul m_hSemaphore. În
metoda Run() există o buclă infinită care la
fiecare iteraţie verifică dacă există mesaje
în coadă şi în momentul în care găseşte
unul îl extrage şi apelează metoda
Universitatea "Petru Maior" 2005
OnMessage() definită în clasele derivate, această metodă fiind apelată pentru fiecare mesaj
din coadă. Execuţia firului se opreşte când se apelează metoda Stop() moştenită din clasa
Thread sau după ce se apelează funcţia PostQuitMessage() şi toate mesajele existente la
momentul respectiv au fost extrase. Datorită buclei infinite existente în metoda Run() atunci
când nu există mesaje în coadă firul va rula în continuu şi va ocupa tot timpul de procesor
Page 40
Capitolul 3 – Implementarea aplicaţiei 39
alocat aplicaţiei. Pentru a evita acest lucru s-a mai introdus un semafor m_DASemaphore
care va bloca firul de execuţie atunci când nu există mesaje în coadă.
Clasa Socket încapsulează funcţionalitatea legată de socket-uri prezentă în Windows
API. Fiecare obiect Socket are asociat un fir de execuţie moştenit de la clasa Thread
responsabil cu primirea datelor şi cu acceptarea conexiunilor noi în cazul în care socket-ul
ascultă un port.
Clasa conţine un membru m_hSocket de tipul
SOCKET reprezentând descriptorul obţinut de
la sistemul de operare în momentul în care a
fost creat obiectul socket. Membrii
m_bIsListening şi m_bIsConnected sunt
folosiţi pentru a determina dacă un socket
ascultă un port sau dacă este conectat. Pentru
crearea unui socket trebuie derivată o clasă din
Socket în care să fie suprascrise metodele
OnAccept(), OnClose(), OnError(),
OnSend(), OnReceive(), apoi după instanţiere
trebuie apelată metoda Create(). Din acest
moment există două posibilităţi: socket-ul
ascultă un port caz în care trebuie legat de port
apelând Bind() şi apoi se apelată metoda
Listen() sau socket-ul este utilizat pentru
crearea unei conexiuni cu alt socket caz în care se apelează metoda Connect() cu adresa
acelui socket ca argument. Din momentul în care conexiunea este stabilită de câte ori vor fi
recepţionate date firul de execuţie asociat socket-ului va apela metoda OnReceive() în care se
poate apela Receive() pentru citirea datelor. În cazul în care apare o eroare sau conexiunea
este închisă din cealaltă parte se apelează metodele OnError(), respectiv OnClose().
Trimiterea datelor se face apelând metoda Send(), închiderea conexiunii cu metoda
CloseSocket(), iar acceptarea unei conexiuni noi cu metoda Accept(). Metodele Send() şi
Connect() sunt cu blocare, Receive() nu este cu blocare dacă se apelează în OnReceive().
Universitatea "Petru Maior" 2005
Fiecare aplicaţie client sau nod conectat are asociat un identificator unic, iar clasa
CommunicationSocket derivată din Socket are un membru m_uId în care este salvat. Acest
identificator va fi ulterior utilizat în câmpurile expeditor şi destinatar ale mesajelor.
Destinatarul este completat în modulul de procesare al mesajelor, iar expeditorul mesajelor
Page 41
Capitolul 3 – Implementarea aplicaţiei 40
primite este completat în metoda OnReceive() a obiectului CommunicationSocket, în
momentul în care este recepţionat mesajul.
Clasele ClientServerSocket şi NodeServerSocket sunt derivate din Socket şi două
instanţe ale lor ascultă două porturi pentru cereri de conexiune venite de la aplicaţiile client şi
respectiv de la alte aplicaţii nod. De câte ori există o cerere de conexiune din partea unei
aplicaţii client sau a unei alte aplicaţii nod este interogată instanţa clasei
CommunicationThread, dacă poate fi acceptată noua conexiune şi în cazul unui răspuns
afirmativ obiectul de tipul CommunicationSocket nou creat este adăugat în lista obiectelor
socket. CommunicationThread conţine două asemenea liste una pentru conexiuni cu
aplicaţii client m_ClientList şi una pentru conexiuni cu alte noduri m_NodeList.
Adăugarea sau scoaterea din listă a obiectelor
socket se face cu metodele AddClient() şi
RemoveClient() pentru conexiunile cu
aplicaţiile client respectiv cu metodele
AddNode() şi RemoveNode() pentru
conexiunile cu alte noduri. Altă
responsabilitate a firului de execuţie este
trimiterea mesajelor pentru către aplicaţiile
client sau nodurile conectate, acest lucru se
face în metodele OnClientMessage() şi
OnNodeMessage(). Din lista obiectelor este
ales obiectul socket prin care este conectat
destinatarul mesajului, în funcţie de
identificatorul citit din câmpul destinatar,
apoi datele sunt transmise apelând metoda
Send(). Mesajele primite de la clienţii
conectaţi sunt trimise mai departe
Universitatea "Petru Maior" 2005
modulului de procesare a mesajelor. Conectarea la alte noduri din sistem se face apelând
metoda ConnectToNodes() în care se citeşte dintr-un fişier lista sortată a adreselor nodurilor,
se stabilesc nodurile de pe poziţii superioare poziţiei nodului curent şi se stabilesc conexiuni
cu ele. Dacă stabilirea uneia din conexiuni eşuează se afişează un mesaj de eroare. Clasa
CommunicationSocket are un membru m_bLocallyInitiated care primeşte valoarea true
atunci când nodul curent a iniţiat conexiunea. În cazul în care se întrerupe o conexiune cu un
Page 42
Capitolul 3 – Implementarea aplicaţiei 41
nod, dacă acel membru este setat true, se încearcă restabilirea conexiunii, în caz contrar se
aşteaptă refacerea conexiunii de către celălalt nod.
3.1.2 Modulul de procesare a mesajelor
Clasa cea mai importantă este MsgProcThread a cărei instanţă este un fir de execuţie,
după cum sugerează şi numele.
Pentru fiecare aplicaţie client sau nod conectat obiectul MsgProcThread conţine un
obiect de tipul ClientTaskThread sau NodeTaskThread responsabil cu procesarea
mesajelor venite de la clientul respectiv.
Membrii m_ClientTasks şi m_NodeTasks
sunt listele în care sunt salvate aceste obiecte.
Metodele OnNodeAccepted() şi
OnNodeDisconnect() sunt apelate de câte ori
se creează o nouă conexiune cu un nod sau o
aplicaţie client, iar în ele sunt create obiectele
NodeTaskThread sau ClientTaskThread şi
sunt adăugate în listă. Similar când o
conexiune se întrerupe este apelată una din
Universitatea "Petru Maior" 2005
metodele OnNodeDisconnect() sau OnClientDisconnect() care distrug firul de execuţie şi
scot obiectul din listă.
Page 43
Capitolul 3 – Implementarea aplicaţiei 42
Firul de execuţie ClientTaskThread procesează mesajele primite de la aplicaţiile
client.
Fiecare obiect conţine o instanţă a clasei
Member, m_pMember, care încapsulează
informaţiile despre utilizatorul conectat.
Clasa moşteneşte de la TaskThread un
membru m_uId, în care este salvat
identificatorul obiectului socket prin care este
conectată aplicaţia folosită de utilizator. Cu
ajutorul acestui identificator se face asocierea
între obiectul socket şi firul responsabil de
procesarea mesajelor venite de la utilizatorul
respectiv. Membrii m_uDownloadingFileId
şi m_uDownloadingFileLockKey se
folosesc în timpul descărcării fişierelor.
m_pUploadingFileName conţine numele
fişierului în curs de publicare, iar
m_pUploadingFilePath calea completă a
fişierului pe disc. Se observă că există câte o metodă de tipul On…() pentru fiecare mesaj
care poate fi primit de la aplicaţia client. În momentul în care se primeşte un mesaj de la client
se apelează metoda OnClientMessage() în care se citeşte tipul mesajului şi apoi se apelează
metoda de tratare a cererii respective. Tratarea cererilor se face apelând metode ale claselor
Member pentru operaţii specifice tuturor utilizatorilor, Admin pentru operaţii specifice
administratorilor sau User pentru alte operaţii. Cele trei clase sunt prezentate în Anexa 3.
Se poate observa că metoda DeleteLocalFile() există în ambele clase Admin şi User,
de aici ar veni întrebarea logică de ce nu a fost definită în clasa Member ? Răspunsul este:
pentru că cele două metode sunt puţin diferite datorită drepturilor pe care le au utilizatorii.
Dacă în cazul administratorilor aceştia pot să şteargă orice fişier, utilizatorii obişnuiţi pot face
acest lucru doar dacă ei sunt proprietarii acelui fişier. Astfel în metoda din clasa User, înainte
de ştergerea fişierului se face o verificare suplimentară, dacă într-adevăr utilizatorul este şi
proprietarul fişierului respectiv.
Universitatea "Petru Maior" 2005
Clasa NodeTaskThread este similară clasei ClientTaskThread şi este responsabilă
de procesarea mesajelor primite de la alte noduri.
Page 44
Capitolul 3 – Implementarea aplicaţiei 43
Mai există o clasă în cadrul acestui modul, FileAccessManager, şi rolul ei este acela
de a sincroniza accesul mai multor clienţi la acelaşi fişier.
Clasa are un membru numit m_List care este o listă de structuri AccessMode, fiecare
dintre ele conţinând identificatorul fişierului, tipul de acces şi un număr întreg unic numit
cheie. De câte ori un utilizator doreşte să acceseze un fişier fie pentru citire (descărcare) sau
pentru scriere (ştergere) el trebuie mai întâi să se asigure că nu intră în conflict cu un alt
utilizator care accesează fişierul în acelaşi timp. Pentru aceasta înainte de orice utilizare
fişierul trebuie blocat. În acest scop se utilizează metoda Lock(), care primeşte ca argumente
identificatorul fişierului şi operaţia pentru care este blocat (citire sau scriere). Dacă un fişier
este blocat pentru citire toate încercările ulterioare de a-l bloca pentru scriere vor eşua. Dacă
fişierul este blocat pentru scriere toate încercările de blocare ulterioare vor eşua, indiferent de
operaţia dorită. Dacă blocarea s-a realizat cu succes în argumentul rLockKey se obţine un
număr (cheie) care va fi utilizat mai târziu pentru deblocarea fişierului, cu metoda Unlock().
Prin acest mecanism simplu se evită probleme care pot apărea atunci când un utilizator
descarcă fişierul şi în acelaşi timp proprietarul său încearcă să-l şteargă.
În diagrama din Anexa 4 este prezentat modul în care colaborează diferitele obiecte
din aplicaţie pentru executarea unei sarcini, autentificarea unui utilizator în acest caz. Se
observă cum un mesaj recepţionat de obiectul CommunicationSocket este transmis mai
departe către obiectul CommunicationThread, care la rândul lui îl transmite obiectului
MsgProcThread. În firul de procesare a mesajelor se citeşte câmpul expeditor al mesajului şi
se identifică firul de execuţie care procesează mesajele primite de la clientul respectiv. După
ce a fost identificat mesajul îi este transferat şi acesta trece la procesarea lui. Răspunsul ia
forma unui alt mesaj care parcurge acelaşi drum în sens invers şi în cele din urmă va ajunge la
socket-ul din aplicaţia client.
Universitatea "Petru Maior" 2005
În Anexa 5 este prezentată secvenţa de pornire a principalelor fire de execuţie din
aplicaţie, CommunicationThread şi MsgProcThread. Primul fir creat şi lansat în execuţie
Page 45
Capitolul 3 – Implementarea aplicaţiei 44
este cel responsabil de procesarea mesajelor, urmează firul dedicat comunicaţiei şi în cele din
urmă sunt create şi trecute în starea de ascultare cele două obiecte socket responsabile cu
acceptarea cererilor de conexiune venite de la aplicaţiile client şi de la celelalte noduri din
sistem. Oprirea firelor de execuţie şi terminarea aplicaţiei se face în ordine inversă celei în
care au fost pornite.
3.1.3 Accesul la baza de date
În cadrul sistemului InfoStudent fiecare nod este conectat la o bază de date în care sunt
salvate informaţii despre utilizatorii înregistraţi, informaţii despre fişierele publicate şi
structura ierarhică de grupuri. Schema conceptuală a bazei de date, structura tabelelor şi
scriptul SQL pentru crearea ei se găseşte în Anexa 6. Cele mai importante tabele sunt
Member, File, şi Group. Tabelul Member conţine informaţii despre utilizatorii înregistraţi
numele, parola şi adresa de email. Mai exista o coloană deleted prin care se marchează ca
şters utilizatorul respectiv. Această coloană a fost introdusă pentru că la ştergerea unui
utilizator intrarea corespunzătoare din tabel nu este ştearsă. Ştergerea ei nu este posibilă
datorită constrângerilor de tip cheie străină existente în tabelul File care nu permit ştergerea
unui utilizator dacă există fişiere publicate de el. Cum la ştergerea unui utilizator fişierele
publicate de el sunt în continuare disponibile a fost aleasă această soluţie de compromis.
Tabelul Group conţine structura ierarhică de grupuri, iar tabelul File conţine informaţii
despre fişierele publicate. Celelalte două tabele FileGroup şi MemberGroup au fost
generate prin transformarea legăturilor în faza de proiectare a bazei de date.
Accesul la baza de date se face utilizând clasele din figura de mai jos.
Universitatea "Petru Maior" 2005
Clasa DataBase realizează conexiunea efectivă cu baza de date, iar clasele derivate
din RecordSet sunt folosite pentru manipularea datelor.
Page 46
Capitolul 3 – Implementarea aplicaţiei 45
Clasa DataBase conţine două variabile membre de tip SQLHANDLE, una pentru
mediul de conectare m_hEnv şi una pentru conexiune m_hDbc, folosite de driver-ul ODBC
pentru identificarea mediului de lucru şi a conexiunii. Conectarea la o sursa de date ODBC se
face apelând metoda Connect() cu numele acesteia ca argument. Starea conexiunii se verifică
cu ajutorul metodei IsConnected().
RecordSet este o clasă abstractă dedicată manipulării datelor. Conţine un membru de
tip SQLHANDLE m_hStmt folosit de driver-ul ODBC pentru identificarea instrucţiunii
SQL. Pentru manipularea datelor trebuie derivată o clasă din RecordSet, suprascrisă metoda
Bind(), apoi după instanţiere se apelează Create() şi ExecSQL() pentru executarea unei
instrucţiuni SQL. Rezultatele execuţiei instrucţiunii se obţin cu metoda
GetAffectedRowCount() în cazul inserării, actualizării sau ştergerii datelor şi cu metodele
GetFirstRow(), GetNextRow() pentru instrucţiunile de interogare. Mai există încă cinci clase
derivate din RecordSet câte una pentru fiecare tabel din baza de date. Definiţia lor poate fi
văzută în Anexa 7.
3.1.4 Alte clase
Universitatea "Petru Maior" 2005
În diagrama de clase pentru aplicaţia nod mai există şi alte clase care nu au fost
menţionate anterior. Toate clasele din aplicaţie moştenesc direct sau indirect clasa Error.
Aceasta are un singur membru, un număr întreg m_LastError, două metode SetLastError()
şi GetLastError() şi este folosită pentru semnalarea şi identificarea erorilor. De câte ori apare
o eroare într-un obiect un cod asociat erorii respective este setat în variabila membră
m_LastError.
Page 47
Capitolul 3 – Implementarea aplicaţiei 46
Clasa Message încapsulează informaţii legate de mesajele utilizate pentru
comunicarea din sistem: destinatar, expeditor, identificator mesaj, parametru. Mai conţine
două metode Msg2Str() şi Str2Msg() folosite la serializarea câmpurilor mesajului pentru a
putea fi trimise prin socket.
Clasa File încapsulează informaţii legate de fişierele publicate.
Universitatea "Petru Maior" 2005
Page 48
Capitolul 3 – Implementarea aplicaţiei 47
3.2 Aplicaţia client
Aplicaţia client este interfaţa dintre utilizator şi sistemul distribuit InfoStudent. Este
relativ simplă şi a fost implementată folosind clase din MFC (Microsoft Foundation Classes).
În diagrama de mai jos sunt prezentate clasele aplicaţiei.
Clasa CWinApp face parte din MFC, iar instanţa clasei derivate din ea,
CInfoStudentClientApp, este numită obiect aplicaţie şi este folosita de sistemul de operare
pentru a rula aplicaţia. Clasa CDialog încapsulează o fereastră de dialog specifică sistemului
de operare Windows şi toate clasele derivate din ea sunt folosite pentru crearea ferestrelor
care alcătuiesc interfaţa grafică prin intermediul căreia utilizatorul interacţionează cu
aplicaţia. Clasa CAsyncSocket încapsulează un socket asincron şi prin clasa derivată din ea
CCommSocket se realizează comunicarea cu aplicaţia nod. Clasa Message este identică cu
cea prezentată anterior.
Ferestrele aplicaţiei şi funcţionalitatea lor sunt prezentate în Anexa 8.
Universitatea "Petru Maior" 2005
Page 49
Concluzii 48
Concluzii
Sistemul InfoStudent se aseamănă cel mai mult cu un sistem de fişiere distribuit, el
permiţând utilizatorilor săi folosirea în comun a unor fişiere. Chiar dacă nu oferă o viziune
asupra tuturor fişierelor din sistem şi nu oferă multe din facilităţile specifice sistemelor de
fişiere el poate fi inclus în categoria sistemelor de fişiere distribuite.
Comunicarea se face prin mesaje folosind protocolul TCP/IP, iar modelul ales este
unul de tip client-server. Ar fi existat alternativele RPC sau RMI, care ar fi ascuns
programatorului partea de comunicare efectiva şi l-ar fi scutit de multe sarcini cum ar fi
administrarea conexiunilor, serializarea datelor şi transmiterea lor prin reţea. Dată fiind
arhitectura sistemului InfoStudent modelul ales pare cel mai potrivit chiar dacă este mai
dificil de implementat.
Transparenţa sistemului există în cazul accesului şi căutării fişierelor, utilizatorul
nefiind conştient de locaţia acestora. La asigurarea transparenţei contribuie şi aplicaţia client
deoarece descărcarea fişierelor se face prin crearea unei noi conexiuni cu nodul în care a fost
publicate, iar acest lucru se face în fundal fără ca utilizatorul să fie conştient. Arhitectura
sistemului nu este transparentă însă, utilizatorul fiind conştient de existenţa mai multor noduri
datorită restricţiei impuse ca un utilizator să se conecteze la sistem tot timpul prin nodul în
care a fost înregistrat. Această restricţie apare datorită faptului că datele referitoare la
utilizatori nu sunt replicate. Arhitectura sistemului este din nou expusă utilizatorului prin
faptul că structura de grupuri nu este unică în toate nodurile. O parte a ei este prezentă în tot
sistemul, dar restul grupurilor sunt specifice nodurilor în care au fost create.
Universitatea "Petru Maior" 2005
Lipsa replicării aduce cu sine două dezavantaje importante. Primul din ele ar fi
scăderea fiabilităţii sistemului deoarece odată ce un nod nu mai funcţionează toate fişiere
publicate nu vor mai fi disponibile, iar utilizatorii înregistraţi în acel nod nu vor mai putea
utiliza sistemul, ei neputându-se conecta prin alte noduri. Totuşi absenţa centralizării unor
elemente vitale face ca restul sistemului să poată funcţiona în continuare. Al doilea dezavantaj
este scăderea performanţelor sistemului o dată cu creşterea numărului de utilizatori. Dacă un
număr mare de utilizatori doresc să acceseze acelaşi fişier toţi se vor conecta la acelaşi nod,
crescând foarte mult încărcarea acestuia. Lipsa replicării conduce deci la apariţia unor secţiuni
înguste în fiecare nod. Totuşi există şi un avantaj acesta fiind simplificarea semnificativă a
implementării sistemului deoarece dacă nu se face replicarea datelor nu trebuie implementate
mecanisme pentru propagarea modificărilor sau asigurare a consistenţei.
Page 50
Concluzii 49
Sistemul este scalabil, adăugarea unor noduri noi se poate face fără probleme şi astfel
încărcarea nodurilor se poate reduce prin creşterea numărului lor odată cu creşterea
numărului de utilizatori. Numărul maxim de noduri şi de utilizatori ai sistemului este limitat
doar de numărul de conexiuni care se pot realiza. Numărul de conexiuni este la rândul lui
limitat de numărul firelor de execuţie pe care le poare crea un proces. Pentru fiecare client sau
nod conectat aplicaţia nod creează două fire de execuţie, unul pentru obiectul socket şi celălalt
pentru procesarea mesajelor primite de la clientul sau nodul respectiv. Numărul de fire de
execuţie pe care le poate crea un proces este limitat doar de dimensiunea spaţiului virtual de
memorie al procesului şi depinde de dimensiunea stivei create pentru un fir de execuţie. Mai
există şi un număr redus de fire necesare pentru funcţionarea aplicaţiei nod care sunt create
indiferent de numărul de conexiuni. Cunoscându-se aceste date se poate face o estimare
aproximativa a numărului maxim de conexiuni pe care le poate accepta un nod şi în cazul
sistemului de operare Windows acesta este de ordinul miilor.
Securitatea sistemului este minimală pentru că nu este o aplicaţie comercială şi nici nu
este destinat schimbului de informaţii secrete. Comunicarea nu se face prin canale securizate,
există doar o autentificare simplă fără folosirea unui algoritm cu cheie secretă sau a altui
mecanism de securitate. Controlul accesului la fişiere se face pe baza structurii de grupuri şi
în plus există un grup special, administratorii sistemului, ai cărui membri pot efectua anumite
operaţii interzise celorlalţi utilizatori. Securitatea bazei de date este asigurată de SGBD-ul
folosit.
Sistemul ar putea fi îmbunătăţit prin replicarea structurii de grupuri în toate nodurile
sau prin salvarea ei într-un singur nod astfel încât toţi utilizatorii să aibă aceeaşi viziune
asupra grupurilor din sistem. Dacă se adoptă soluţia replicării în fiecare nod trebuie
implementat un mecanism de propagare a modificărilor şi asigurarea consistenţei, aceasta
fiind cel puţin una secvenţială. Salvarea structurii de grupuri într-un singur nod elimină
necesitatea asigurării consistenţei, dar va aduce şi o scădere considerabilă a fiabilităţii pentru
că în cazul căderii nodului respectiv sistemul nu va mai putea funcţiona.
O altă îmbunătăţire considerabilă ar fi eliminarea restricţiei ca utilizatorii să se
conecteze tot timpul prin acelaşi nod. Pentru aceasta informaţiile legate de utilizatori ar trebui
să fie cunoscute global, în toate nodurile. Problemele care pot apărea sunt similare cu cele
descrise mai sus la structura de grupuri. Aceste două îmbunătăţiri prezentate pe lângă
avantajele oferite utilizatorilor contribuie şi la asigurarea transparenţei sistemului.
Universitatea "Petru Maior" 2005
Pentru creşterea fiabilităţii s-ar putea realiza şi o replicare a fişierelor, dar dificultatea
asigurării consistenţei şi scăderea în performanţe datorată propagării modificărilor (mai ales în
Page 51
Concluzii 50
cazul fişierelor de dimensiuni mai mari) nu justifică acest lucru. De asemenea s-ar putea
aduce îmbunătăţiri în ceea ce priveşte securitatea sistemului, dar ţinând de scopul şi destinaţia
lui, definirea şi aplicarea unei politici de securitate mai stricte nu este necesară.
Universitatea "Petru Maior" 2005
Page 52
Bibliografie 51
Bibliografie
1. Andrew S. Tanenbaum, Maarten van Steen – Distribuited systems, principles and
paradigms; Prentice Hall 2002.
2. Andrew S. Tanenbaum – Reţele de calculatoare, ediţia a treia; Computer Press
AGORA 1998.
3. Grady Booch, James Rumbaugh, Ivar Jacobson – The Unified Modeling Language
User Guide; Addison Wesley 1998.
4. Object Management Group – UML 2.0 Superstructure Specification; October 2004
5. Slobodan Kalajdziski - Unified Modeling Language Tutorial
6. Robert Dollinger – Baze de date şi gestiunea tranzacţiilor; Editura albastră 1999.
7. Jeff Prosise – Programming Windows with MFC, second edition; Microsoft Press
1999.
8. Microsoft – Microsoft Developer Network, Platform SDK Documentation.
Universitatea "Petru Maior" 2005
Page 53
Anexa 1 - Descrierea mesajelor folosite şi a protocolului de comunicare I
Tipuri de mesaje utilizate în sistemul InfoStudent.
Universitatea "Petru Maior" 2005
Id. Tip mesaj Parametru Descriere
1 REQ_AUTHENTICATE nume_utilizator\0parolă\0
Trimis de la aplicaţia client către nod imediat după conectare, pentru
autentificare.
2 AUTHENTICATED nume_utilizator\0parolă\0 Trimis de la nod către
aplicaţia client pentru a confirma autentificarea.
3 INCORRECT_NAME nume_utilizator\0parolă\0
Trimis de la nod către aplicaţia client dacă
numele utilizatorului nu este corect.
4 INCORRECT_PASSWD nume_utilizator\0parolă\0
Trimis de la nod către aplicaţia client dacă
parola specificată pentru utilizatorul respectiv nu
este corectă.
5 SEARCH
id_căutare(1 oct.) rezervat(4 oct.)
cuv1'\0'cuv2'\0'...cuvn'\0'
Trimis de la aplicaţia client către nod când se
caută un fişier.
6 SEARCH_RESULT
id_căutare(1 oct.) rezervat(4 oct.) id_fişier(4 oct.)
adresa_nod'\0' nume_fişier'\0' descriere'\0'
grup_destinaţie'\0' proprietar'\0'
Trimis de la nod către aplicaţia client pentru
fiecare fişier care corespunde criteriilor de
căutare.
7 DOWNLOAD id_fişier(4 oct.)
număr_pachet (4 oct. 0 pentru primul pachet)
Trimis de aplicaţia client către nod când se doreşte descărcarea unui fişier.
8 DOWNLOAD_DATA
id_fişier(4 oct.) număr_pachet (4 oct.) pachete_fişier (4 oct.)
pachet_fişier
Fişierele descărcate se împart în pachete, fiecare din ele fiind trimise într-
un mesaj de acest tip. Trimis de la nod la
aplicaţia client.
9 DOWNLOAD_FINISH id_fişier(4 oct.)
număr_pachet (4 oct.)
Trimis de la nod la aplicaţia client când
descărcarea fişierului este completă.
10 CHANGE_PASSWORD parolă\0
Trimis de la aplicaţia client la nod când utilizatorul doreşte schimbarea parolei.
Page 54
Anexa 1 - Descrierea mesajelor folosite şi a protocolului de comunicare II
Universitatea "Petru Maior" 2005
11 PASSWORD_CHANGED parolă\0
Trimis de la nod către aplicaţia client dacă
schimbarea parolei s-a făcut cu succes.
12 GET_GROUPS -
Trimis de la aplicaţia client către nod pentru
obţinerea listei grupurilor existente.
13 GROUPS id_group(4oct.) nume \0 id_părinte(4oct.)
Trimis de la nod către aplicaţia client; conţine
lista grupurilor
14 CHANGE_USER_GROUP nume_utilizator\0 nume_grup_nou\0
Trimis de la aplicaţia client către nod pentru a schimba grupul din care face parte un utilizator.
16 ADD_GROUP nume_grup_nou\0 nume_grup_părinte\0
Trimis de la aplicaţia client către nod pentru
adăugarea unui nou grup.
17 REMOVE_GROUP nume_grup\0 Trimis de la aplicaţia client către nod pentru ştergerea unui grup.
18 MESSAGE mesaj\0
Trimis de la nod către aplicaţia client pentru a
informa utilizatorul despre rezultatul unei
acţiuni.
19 UPLOAD_DATA nume_fişier\0 număr_pachet
(4 oct., 0 pentru primul pachet) pachet_fişier
Trimis de la aplicaţia client către nod în timpul
publicării unui fişier.
20 UPLOAD număr_pachet (4 oct.)
Trimis de la nod către aplicaţia client, în timpul
publicării, când următorul pachet dintr-un
fişier poate fi trimis.
21 UPLOAD_FINISH grup_destinaţie\0 desc\0
Trimis de la aplicaţia client către nod când
operaţia de publicarea a unui fişier s-a încheiat.
22 UPDATE_FINISH id_fişier (4 oct.)
Trimis de la aplicaţia client către nod când
actualizarea unui fişier s-a încheiat.
23 GET_USERS -
Trimis de la aplicaţia client către nod când se
doreşte lista utilizatorilor înregistraţi.
24 USERS nume_utilizator\0 grup_utilizator\0 email_utilizator\0
Trimis de la nod către aplicaţia client; conţine
lista utilizatorilor înregistraţi.
Page 55
Anexa 1 - Descrierea mesajelor folosite şi a protocolului de comunicare III
25 ADD_USER nume_utilizator\0 parolă \0
grup_utilizator\0 email_utilizator\0
Trimis de la aplicaţia client către nod pentru înregistrarea unui nou
utilizator.
26 DELETE_USER nume_utilizator\0
Trimis de la aplicaţia client către nod pentru ştergerea unui utilizator
înregistrat.
27 DELETE_FILE id_fişier (4 oct.) nume_fişier\0
Trimis de la aplicaţia client către nod pentru ştergerea unui fişier.
Protocol de comunicare.
1. Autentificare: imediat după conectare aplicaţia client trimite către nod un mesaj de tipul REQ_AUTHENTICATE cu numele utilizatorului şi parola ca parametri. Nodul răspunde cu un mesaj AUTHENTICATED dacă numele utilizatorului a fost găsit în baza de date şi parola specificată este corectă, cu un mesaj INCORRECT_NAME dacă numele utilizatorului nu a fost găsit în baza de date şi cu un mesaj INCORRECT_PASSWD dacă numele utilizatorului a fost găsit, dar parola specificată nu corespunde.
2. Căutare: după autentificare aplicaţia client trimite un mesaj de tipul SEARCH cu parametri id_căutare şi cuvintele cheie după care se face căutarea. Rolul parametrului id_căutare este descris la modelul aplicaţiei în partea de sincronizare. Dacă au fost găsite fişiere care să corespundă criteriilor de căutare pentru fiecare fişier găsit nodul va trimite aplicaţiei client un mesaj de tipul SEARCH_RESULT cu descrierea fişierului ca parametru. Căutarea se face în tot sistemul nodul la care este conectată aplicaţia client transmiţând mesajul SEARCH tuturor nodurilor la care este conectat.
Universitatea "Petru Maior" 2005
Page 56
Anexa 1 - Descrierea mesajelor folosite şi a protocolului de comunicare IV
3. Descărcare: dacă în urma căutării s-au obţinut rezultate satisfăcătoare utilizatorul poate să descarce un fişier. În acest caz aplicaţia client trimite către nodul unde a fost publicat fişierul un mesaj de tipul DOWNLOAD cu id-ul fişierului şi număr_pachet 0 ca parametri prin care cere transmiterea primului pachet din fişier. După ce descărcarea începe nodul trimite un mesaj de tipul DOWNLOAD_DATA, care conţine o parte din fişier, la fiecare mesaj de tipul DOWNLOAD primit de la client. Primul mesaj DOWNLOAD_DATA conţine şi numărul total de pachete care vor fi transmise. În momentul în care tot fişierul a fost transmis nodul încheie descărcarea cu un mesaj de tipul DOWNLOAD_FINISH.
4. Schimbare parola: după autentificare utilizatorul are opţiunea de a-şi schimba parola de acces. În această situaţia aplicaţia client trimite nodului un mesaj de tip CHANGE_PASSWORD cu noua parolă ca parametru. Dacă operaţia de schimbare a parolei s-a încheiat cu succes nodul răspunde cu un mesaj PASSWORD_CHANGED.
5. Interogare ierarhie grupuri: utilizatorii pot vizualiza ierarhia de grupuri. În acest scop aplicaţia client trimite un mesaj GET_GROUPS, iar nodul răspunde cu un mesaj GROUPS, care conţine structura ierarhică de grupuri.
6. Schimbare grup utilizator: dacă un administrator doreşte schimbarea grupului din care face parte un utilizator aplicaţia client trimite un mesaj CHANGE_USER_GROUP cu numele utilizatorului şi numele noului grup ca parametri. Nodul răspunde printr-un mesaj de tipul MESSAGE prin care informează utilizatorul asupra rezultatului operaţiei.
Universitatea "Petru Maior" 2005
Page 57
Anexa 1 - Descrierea mesajelor folosite şi a protocolului de comunicare V
7. Adăugare sau ştergere grup: administratorii pot adăuga sau şterge grupuri din ierarhia existentă. Aplicaţia client va trimite un mesaj ADD_GROUP cu parametrii nume_grup_nou, nume_grup_părinte, respectiv REMOVE_GROUP cu parametru nume_grup. Nodul răspunde cu un mesaj de tipul MESSAGE.
8. Publicare fişier: dacă utilizatorul doreşte să publice un fişier aplicaţia client trimite un mesaj UPLOAD_DATA cu număr_pachet = 0 şi primul pachet din fişier ca parametri. După fiecare astfel de mesaj primit nodul răspunde cu un mesaj UPLOAD cu număr_pachet + 1 ca parametru prin care cere următorul pachet din fişier. În momentul în care tot fişierul a fost transmis aplicaţia client trimite un mesaj UPLOAD_FINISH prin care informează nodul că tot fişierul a fost transmis. Acest ultim mesaj conţine şi informaţiile despre fişier, grup destinaţie, descriere etc.
9. Actualizare fişier: se desfăşoară la fel ca operaţia de publicare cu excepţia ultimului mesaj care în acest caz este de tipul UPDATE_FINISH. 10. Interogare listă membrii: administratorii pot vizualiza lista utilizatorilor înregistraţi. Aplicaţia client trimite un mesaj GET_USERS, iar nodul răspunde cu un mesaj USERS care conţine lista tuturor utilizatorilor.
11. Adăugare sau ştergere utilizator: administratorii pot să adauge sau să şteargă utilizatori. Aplicaţia client trimite un mesaj ADD_USER cu numele utilizatorului, parola şi grupul din care face parte ca parametri, respectiv un mesaj DELETE_USER cu numele utilizatorului ca parametru. Nodul răspunde cu un mesaj de tipul MESSAGE prin care anunţă dacă operaţia s-a încheiat cu succes sau nu.
Universitatea "Petru Maior" 2005
Page 58
Anexa 1 - Descrierea mesajelor folosite şi a protocolului de comunicare VI
Universitatea "Petru Maior" 2005
12. Ştergere fişier: utilizatorii pot şterge fişiere publicate, pentru aceasta aplicaţia client trimite un mesaj DELETE_FILE cu id-ul fişierului şi numele fişierului ca parametru, iar nodul răspunde cu un mesaj de tipul MESSAGE.
Page 59
Anexa 2 – Diagrama de clase pentru aplicaţia Nod I
Universitatea "Petru Maior" 2005
Page 60
Anexa 3 – Clasele Member, Admin şi User I
Universitatea "Petru Maior" 2005
Page 61
Anexa 4 – Diagrama de colaborare a firelor de execuţie I
Universitatea "Petru Maior" 2005
Page 62
Anexa 5 – Secvenţa de pornire a firelor de execuţie I
Universitatea "Petru Maior" 2005
Page 63
Anexa 5 – Secvenţa de pornire a firelor de execuţie II
Universitatea "Petru Maior" 2005
Page 64
Anexa 6 – Structura bazei de date II
Schema conceptuală a bazei de date este prezentată în figura următoare.
După transformarea legăturilor se obţine următoarea schemă logică.
Universitatea "Petru Maior" 2005
În continuare este prezentată structura tabelelor
Page 65
Anexa 6 – Structura bazei de date III
- Member:
- id NUMERIC(9) UNIQUE PRIMARY KEY - name VARCHAR(25) NOT NULL - password VARCHAR(25) NOT NULL - email VARCHAR(25) NOT NULL - deleted CHAR(1) NOT NULL DEFAULT ‘n’
- Group:
- id NUMERIC(9) UNIQUE PRIMARY KEY - name VARCHAR(25) NOT NULL - parent_id NUMERIC(9) FOREIGN KEY
- File:
- id NUMERIC(9) UNIQUE PRIMARY KEY - name VARCHAR(50) NOT NULL - owner_id FOREIGN KEY - desc VARCHAR(250) NOT NULL
- MemberGroup:
- id_member NUMERIC(9) FOREIGN KEY - id_group NUMERIC(9) FOREIGN KEY
- FileGroup:
- id_file NUMERIC(9) FOREIGN KEY - id_group NUMERIC(9) FOREIGN KEY
Scriptul SQL pentru crearea bazei de date: IF EXISTS (SELECT name FROM master.dbo.sysdatabases WHERE name = N'InfoStudent') DROP DATABASE [InfoStudent] GO CREATE DATABASE [InfoStudent] ON (NAME = N'InfoStudent_Data', FILENAME = N'D:\temp\scoala\diploma\Lucrare - InfoStudent\DataBase\InfoStudent_Data.MDF' , SIZE = 2, FILEGROWTH = 1) LOG ON (NAME = N'InfoStudent_Log', FILENAME = N'D:\temp\scoala\diploma\Lucrare - InfoStudent\DataBase\InfoStudent_Log.LDF' , SIZE = 1, FILEGROWTH = 1) COLLATE SQL_Latin1_General_CP1_CI_AS GO exec sp_dboption N'InfoStudent', N'autoclose', N'false' GO exec sp_dboption N'InfoStudent', N'bulkcopy', N'false' GO exec sp_dboption N'InfoStudent', N'trunc. log', N'false' GO exec sp_dboption N'InfoStudent', N'torn page detection', N'true' GO
Universitatea "Petru Maior" 2005
exec sp_dboption N'InfoStudent', N'read only', N'false'
Page 66
Anexa 6 – Structura bazei de date IV
GO exec sp_dboption N'InfoStudent', N'dbo use', N'false' GO exec sp_dboption N'InfoStudent', N'single', N'false' GO exec sp_dboption N'InfoStudent', N'autoshrink', N'false' GO exec sp_dboption N'InfoStudent', N'ANSI null default', N'false' GO exec sp_dboption N'InfoStudent', N'recursive triggers', N'false' GO exec sp_dboption N'InfoStudent', N'ANSI nulls', N'false' GO exec sp_dboption N'InfoStudent', N'concat null yields null', N'false' GO exec sp_dboption N'InfoStudent', N'cursor close on commit', N'false' GO exec sp_dboption N'InfoStudent', N'default to local cursor', N'false' GO exec sp_dboption N'InfoStudent', N'quoted identifier', N'false' GO exec sp_dboption N'InfoStudent', N'ANSI warnings', N'false' GO exec sp_dboption N'InfoStudent', N'auto create statistics', N'true' GO exec sp_dboption N'InfoStudent', N'auto update statistics', N'true' GO use [InfoStudent] GO if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[FK_FileGroup_File]') and OBJECTPROPERTY(id, N'IsForeignKey') = 1) ALTER TABLE [dbo].[FileGroup] DROP CONSTRAINT FK_FileGroup_File GO if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[FK_FileGroup_Group]') and OBJECTPROPERTY(id, N'IsForeignKey') = 1) ALTER TABLE [dbo].[FileGroup] DROP CONSTRAINT FK_FileGroup_Group GO if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[FK_Group_Group]') and OBJECTPROPERTY(id, N'IsForeignKey') = 1) ALTER TABLE [dbo].[Group] DROP CONSTRAINT FK_Group_Group GO if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[FK_MemberGroup_Group]') and OBJECTPROPERTY(id, N'IsForeignKey') = 1) ALTER TABLE [dbo].[MemberGroup] DROP CONSTRAINT FK_MemberGroup_Group GO if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[FK_File_Member]') and OBJECTPROPERTY(id, N'IsForeignKey') = 1) ALTER TABLE [dbo].[File] DROP CONSTRAINT FK_File_Member
Universitatea "Petru Maior" 2005
GO
Page 67
Anexa 6 – Structura bazei de date V
if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[FK_MemberGroup_Member]') and OBJECTPROPERTY(id, N'IsForeignKey') = 1) ALTER TABLE [dbo].[MemberGroup] DROP CONSTRAINT FK_MemberGroup_Member GO if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[FileGroups]') and OBJECTPROPERTY(id, N'IsView') = 1) drop view [dbo].[FileGroups] GO if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[MemberGroups]') and OBJECTPROPERTY(id, N'IsView') = 1) drop view [dbo].[MemberGroups] GO if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[File]') and OBJECTPROPERTY(id, N'IsUserTable') = 1) drop table [dbo].[File] GO if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[FileGroup]') and OBJECTPROPERTY(id, N'IsUserTable') = 1) drop table [dbo].[FileGroup] GO if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[Group]') and OBJECTPROPERTY(id, N'IsUserTable') = 1) drop table [dbo].[Group] GO if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[Member]') and OBJECTPROPERTY(id, N'IsUserTable') = 1) drop table [dbo].[Member] GO if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[MemberGroup]') and OBJECTPROPERTY(id, N'IsUserTable') = 1) drop table [dbo].[MemberGroup] GO CREATE TABLE [dbo].[File] ( [id] [numeric](18, 0) IDENTITY (1, 1) NOT NULL , [name] [varchar] (50) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL , [owner_id] [numeric](18, 0) NOT NULL , [desc] [varchar] (250) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL ) ON [PRIMARY] GO CREATE TABLE [dbo].[FileGroup] ( [id_file] [numeric](18, 0) NOT NULL , [id_group] [numeric](18, 0) NOT NULL ) ON [PRIMARY] GO CREATE TABLE [dbo].[Group] ( [id] [numeric](18, 0) IDENTITY (1, 1) NOT NULL , [name] [varchar] (25) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL , [parent_id] [numeric](18, 0) NOT NULL
Universitatea "Petru Maior" 2005
) ON [PRIMARY]
Page 68
Anexa 6 – Structura bazei de date VI
GO CREATE TABLE [dbo].[Member] ( [id] [numeric](18, 0) IDENTITY (1, 1) NOT NULL , [name] [varchar] (25) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL , [password] [varchar] (25) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL , [email] [varchar] (25) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL , [deleted] [char] (1) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL ) ON [PRIMARY] GO CREATE TABLE [dbo].[MemberGroup] ( [id_member] [numeric](18, 0) NOT NULL , [id_group] [numeric](18, 0) NOT NULL ) ON [PRIMARY] GO ALTER TABLE [dbo].[File] WITH NOCHECK ADD CONSTRAINT [PK_File] PRIMARY KEY CLUSTERED ( [id] ) ON [PRIMARY] GO ALTER TABLE [dbo].[FileGroup] WITH NOCHECK ADD CONSTRAINT [PK_FileGroup] PRIMARY KEY CLUSTERED ( [id_file], [id_group] ) ON [PRIMARY] GO ALTER TABLE [dbo].[Group] WITH NOCHECK ADD CONSTRAINT [PK_Group] PRIMARY KEY CLUSTERED ( [id] ) ON [PRIMARY] GO ALTER TABLE [dbo].[Member] WITH NOCHECK ADD CONSTRAINT [PK_Member] PRIMARY KEY CLUSTERED ( [id] ) ON [PRIMARY] GO ALTER TABLE [dbo].[MemberGroup] WITH NOCHECK ADD CONSTRAINT [PK_MemberGroup] PRIMARY KEY CLUSTERED ( [id_member], [id_group] ) ON [PRIMARY] GO ALTER TABLE [dbo].[Group] WITH NOCHECK ADD CONSTRAINT [DF_Group_parent_id] DEFAULT (1) FOR [parent_id]
Universitatea "Petru Maior" 2005
GO
Page 69
Anexa 6 – Structura bazei de date VII
ALTER TABLE [dbo].[Member] WITH NOCHECK ADD CONSTRAINT [DF_Member_deleted] DEFAULT ('n') FOR [deleted] GO ALTER TABLE [dbo].[File] ADD CONSTRAINT [FK_File_Member] FOREIGN KEY ( [owner_id] ) REFERENCES [dbo].[Member] ( [id] ) GO ALTER TABLE [dbo].[FileGroup] ADD CONSTRAINT [FK_FileGroup_File] FOREIGN KEY ( [id_file] ) REFERENCES [dbo].[File] ( [id] ), CONSTRAINT [FK_FileGroup_Group] FOREIGN KEY ( [id_group] ) REFERENCES [dbo].[Group] ( [id] ) GO ALTER TABLE [dbo].[Group] ADD CONSTRAINT [FK_Group_Group] FOREIGN KEY ( [parent_id] ) REFERENCES [dbo].[Group] ( [id] ) GO ALTER TABLE [dbo].[MemberGroup] ADD CONSTRAINT [FK_MemberGroup_Group] FOREIGN KEY ( [id_group] ) REFERENCES [dbo].[Group] ( [id] ), CONSTRAINT [FK_MemberGroup_Member] FOREIGN KEY ( [id_member] ) REFERENCES [dbo].[Member] ( [id] ) GO SET QUOTED_IDENTIFIER ON GO
Universitatea "Petru Maior" 2005
SET ANSI_NULLS ON
Page 70
Anexa 6 – Structura bazei de date VIII
GO CREATE VIEW dbo.FileGroups AS SELECT dbo.[File].name, dbo.[Group].name AS Expr1 FROM dbo.[File] INNER JOIN dbo.FileGroup ON dbo.[File].id = dbo.FileGroup.id_file INNER JOIN dbo.[Group] ON dbo.FileGroup.id_group = dbo.[Group].id GO SET QUOTED_IDENTIFIER OFF GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO SET ANSI_NULLS ON GO CREATE VIEW dbo.MemberGroups AS SELECT dbo.Member.name, dbo.[Group].name AS Expr1 FROM dbo.Member INNER JOIN dbo.MemberGroup ON dbo.Member.id = dbo.MemberGroup.id_member INNER JOIN dbo.[Group] ON dbo.MemberGroup.id_group = dbo.[Group].id AND NOT [Member].[deleted] = 'y' GO SET QUOTED_IDENTIFIER OFF GO SET ANSI_NULLS ON GO declare @v_root_id numeric(9) set @v_root_id = 0; insert into [Group] ([name]) values ('user'); select @v_root_id = [Group].[id] from [Group] where [Group].[name] = 'user' if @v_root_id > 0 begin update [Group] set [parent_id] = @v_root_id where [id] = @v_root_id insert into [Group] ([name], [parent_id]) values ('admin', @v_root_id);
Universitatea "Petru Maior" 2005
insert into [Group] ([name], [parent_id])
Page 71
Anexa 6 – Structura bazei de date IX
values ('prof', @v_root_id); insert into [Group] ([Group].[name], [Group].[parent_id]) values ('stud', @v_root_id); end declare @v_admin_id numeric(9) set @v_admin_id = 0; declare @v_member_id numeric(9) set @v_member_id = 0; select @v_admin_id = [Group].[id] from [Group] where [Group].[name] = 'admin' if @v_admin_id > 0 begin insert into [Member] ([name], [password], [email], [deleted]) values ('administrator', 'parola', '[email protected] ', 'n'); select @v_member_id = [Member].[id] from [Member] where [Member].[name] = 'administrator' if @v_member_id > 0 begin insert into [MemberGroup] (id_member, id_group) values (@v_member_id, @v_admin_id) end end
Universitatea "Petru Maior" 2005
Page 72
Anexa 7 – Clasele MemberSet, FileSet, GroupSet, MemberGroupSet şi FileGroupSet II
Universitatea "Petru Maior" 2005
Fereastra principală a aplicaţiei
Page 73
Anexa 8 – Ferestrele aplicaţiei client II
Universitatea "Petru Maior" 2005
Fereastră ierarhie grupuri
Page 74
Anexa 8 – Ferestrele aplicaţiei client III
Fereastră publicare fişier
Universitatea "Petru Maior" 2005
Fereastră listă utilizatori
Page 75
Anexa 8 – Ferestrele aplicaţiei client IV
Universitatea "Petru Maior" 2005















































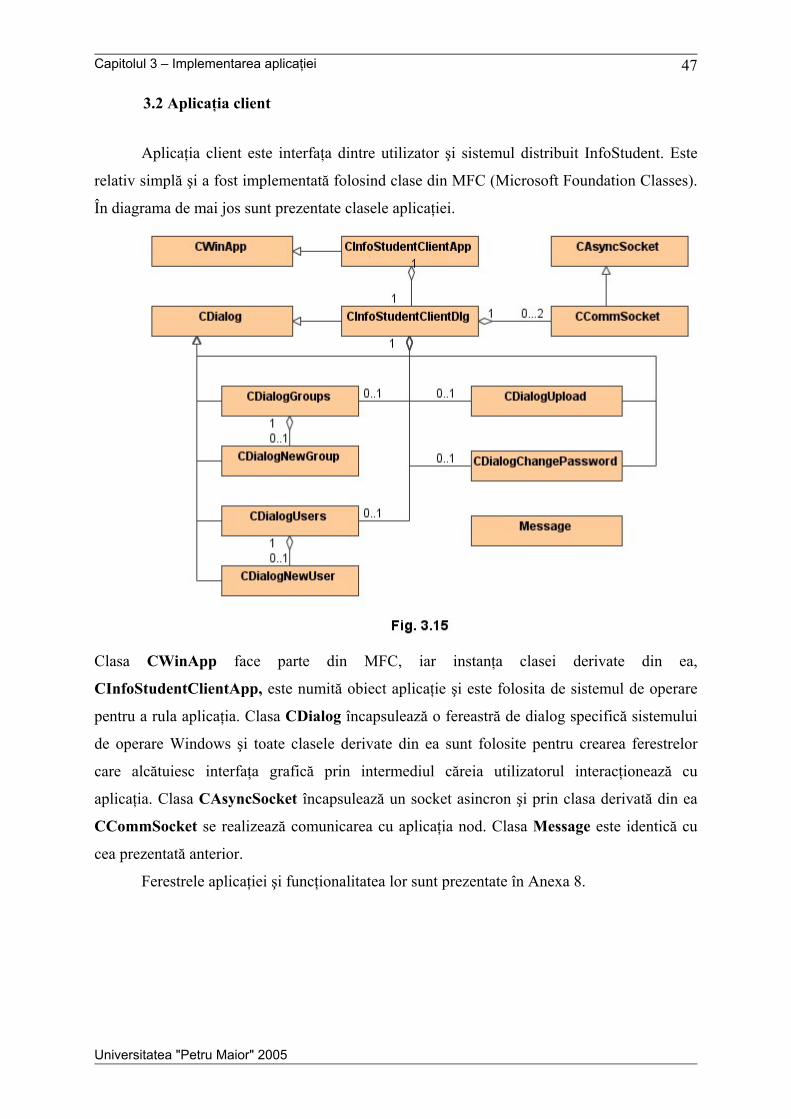




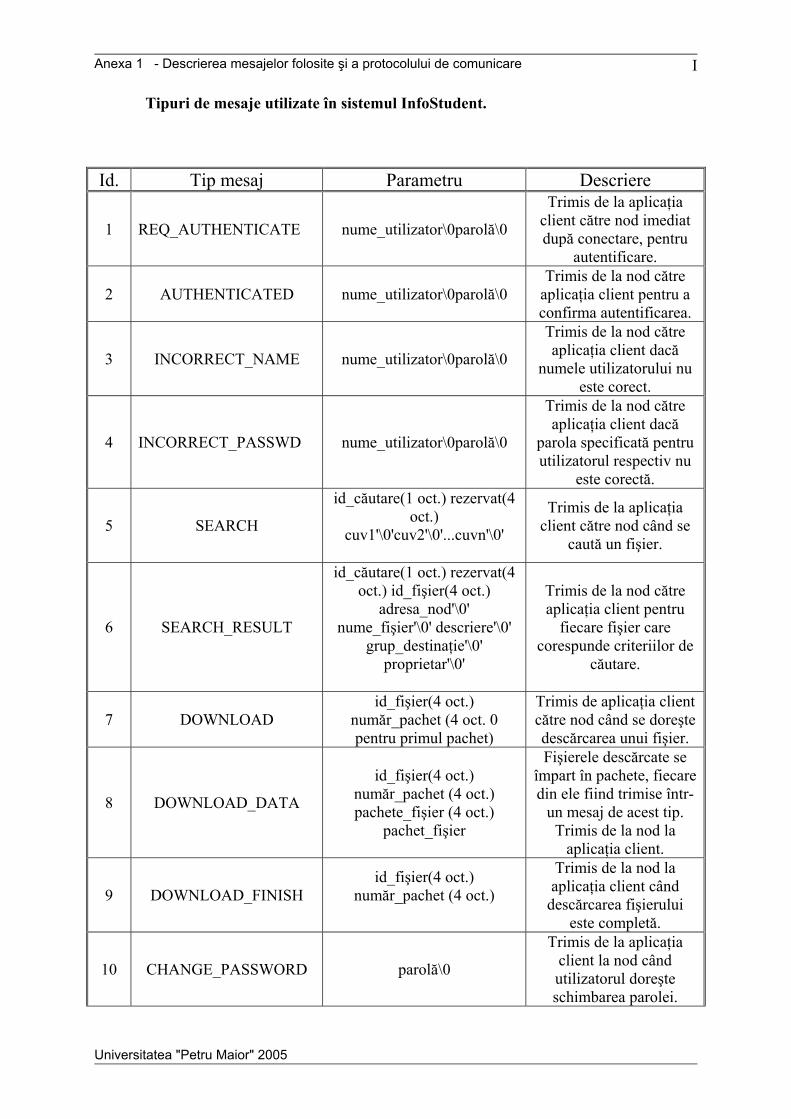
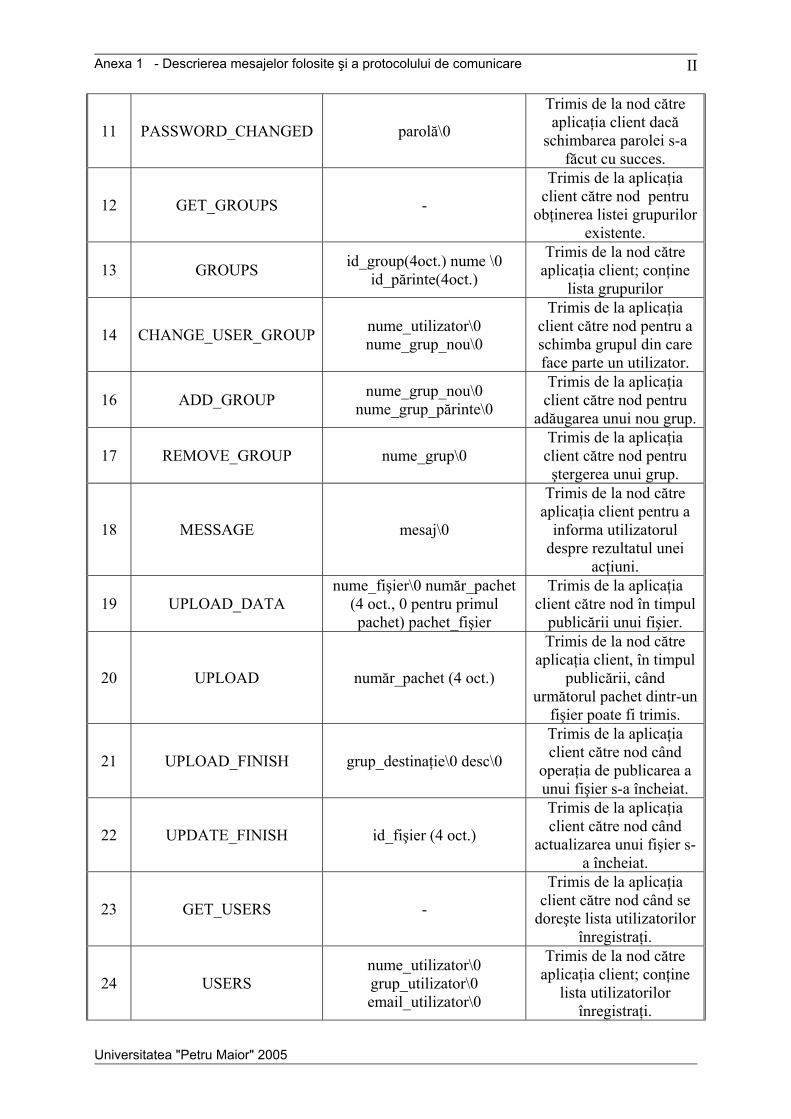




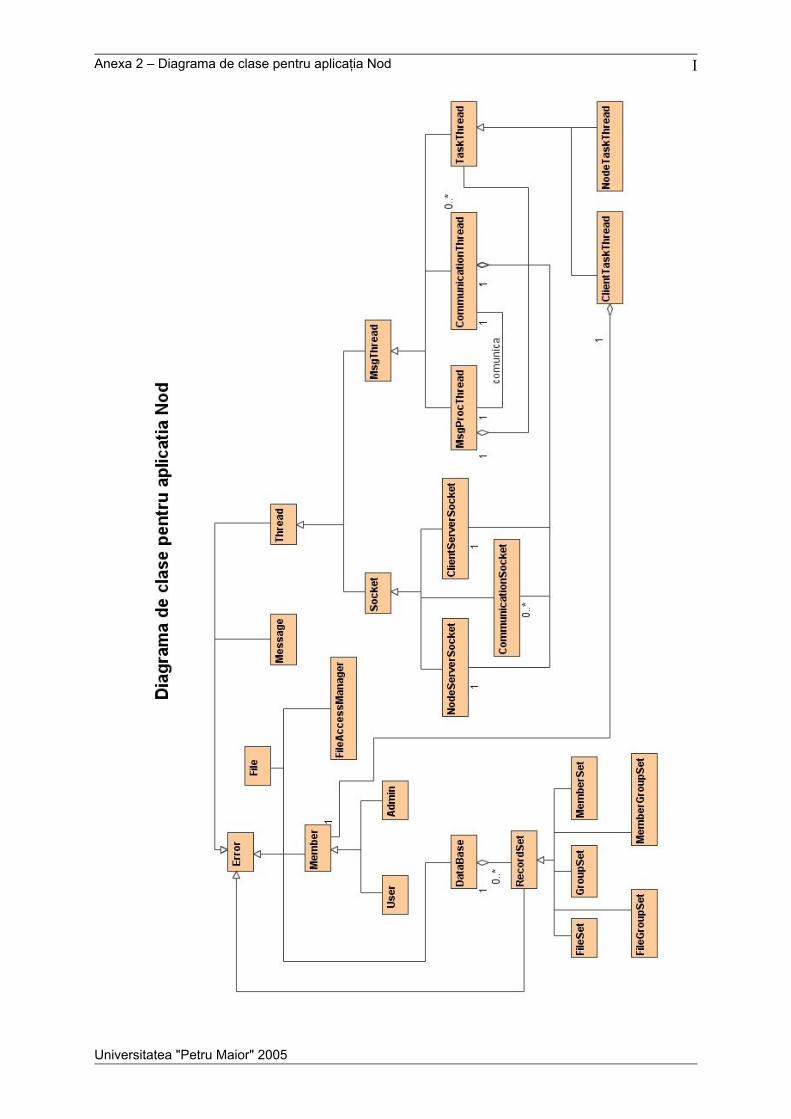

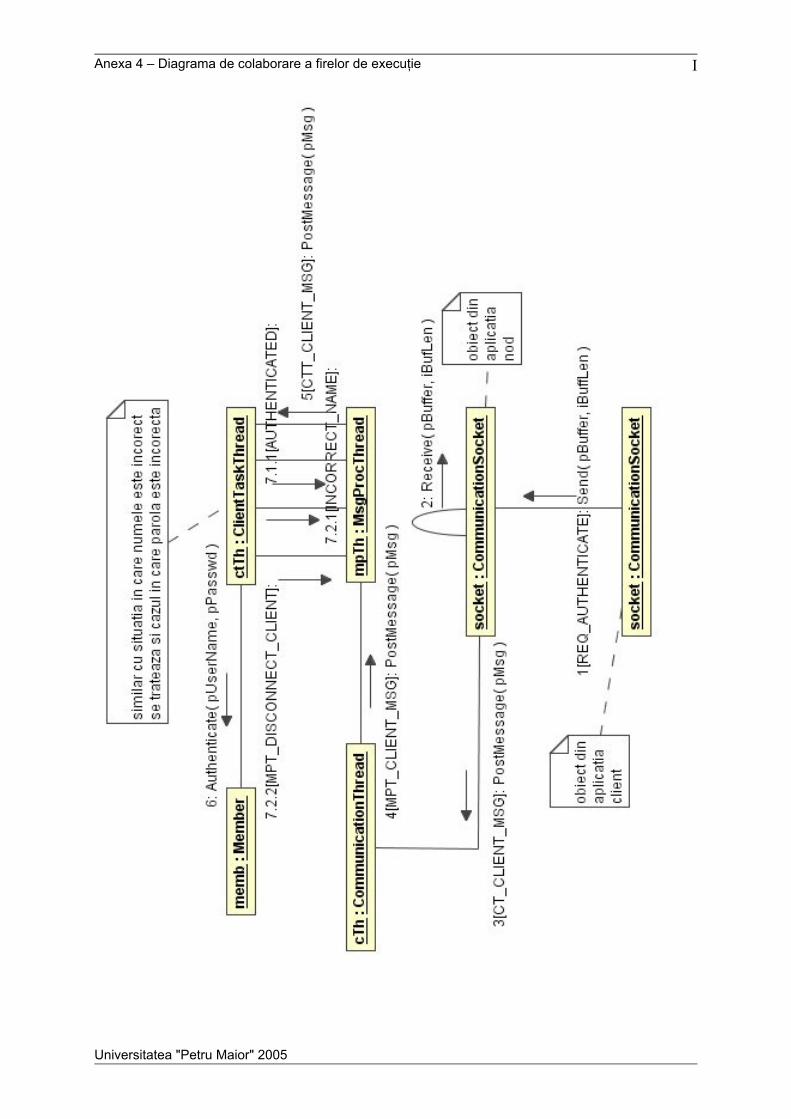
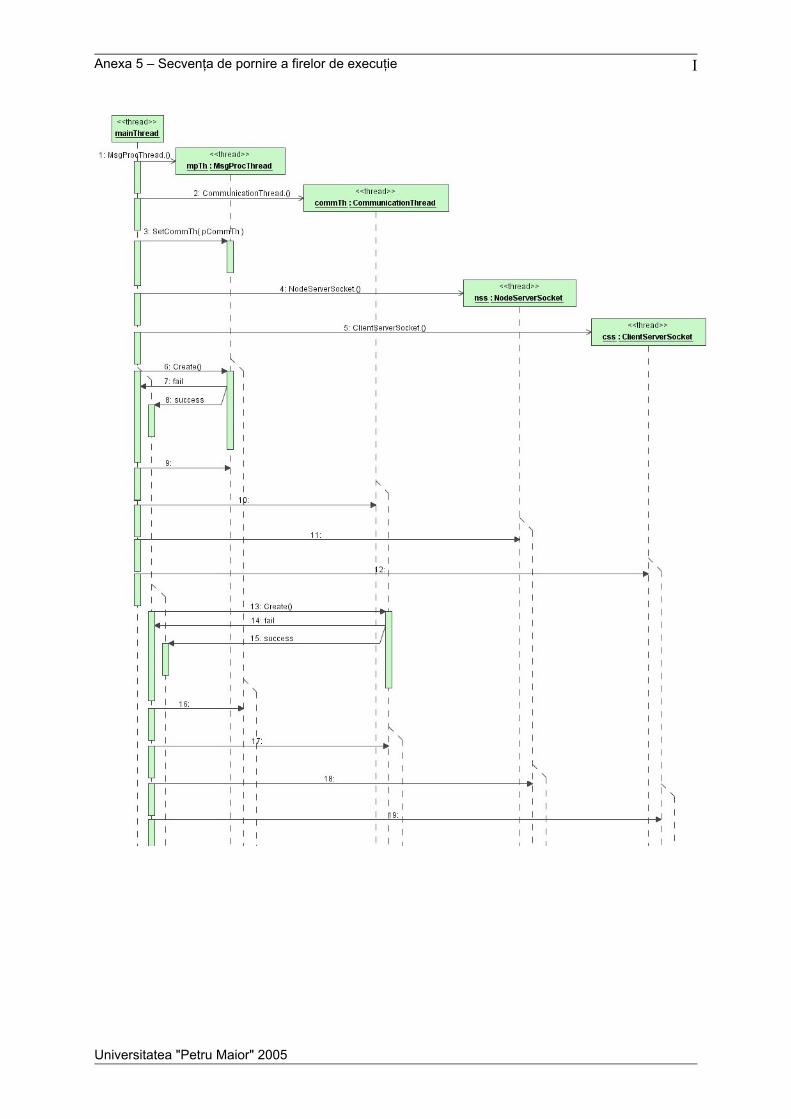

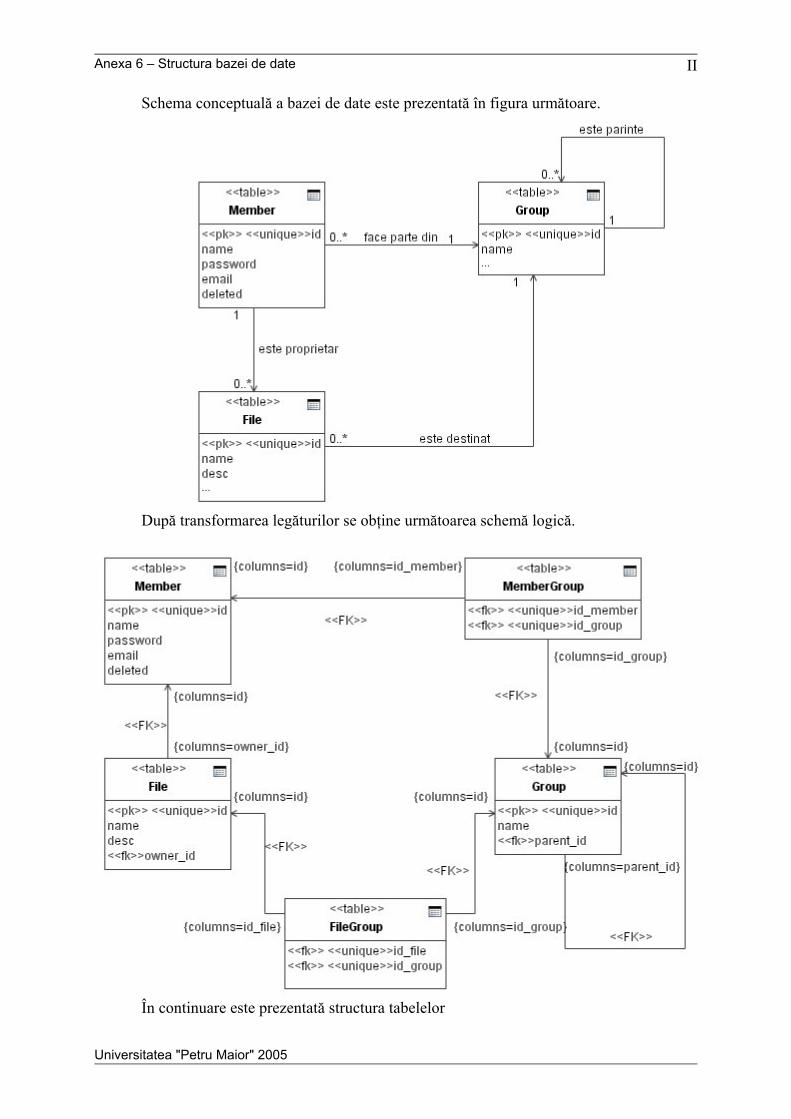









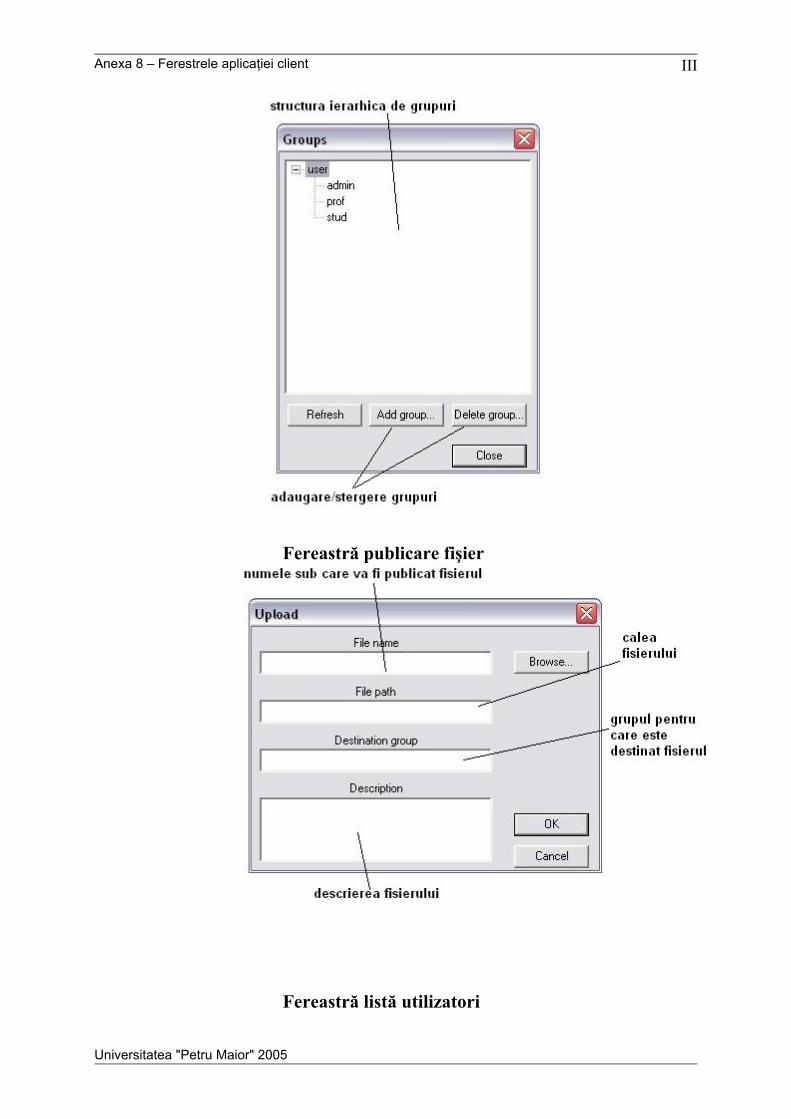



![fisiere [Autoguardado]](https://static.documente.net/doc/80x56/55cf8f01550346703b97e8d0/fisiere-autoguardado.jpg)














