Introducere în Informatică Capitolul 6. Organizarea datelor Introducere Procesarea datelor se poate face doar în condiţiile în care sunt organizate în structuri bine definite. Modul de organizare al datelor diferă în funcţie de locul unde sunt memorate (stocate), adică în memoria internă sau în memoria externă. Aşa cum este deja cunoscut, într-un sistem de calcul electronic, informaţiile respectiv datele sunt reprezentate sub formă codificată. Ele sunt memorate fie în locaţii succesive (adresabile) din memoria internă (RAM şi/sau ROM), fie în memoria externă (reprezentată de discurile hard, discurile flexibile, casetele magnetice, CD-uri etc.). Din aceste considerente datele sunt organizate diferit, după cum se află în memoria internă sau în cea externă, aşa cum se poate vedea şi în figura alăturată. (Fig. 6.1.). 65
Transcript
Introducere în Informatică
Capitolul 6. Organizarea datelor
Introducere
Procesarea datelor se poate face doar în condiţiile în care sunt organizate în structuri bine definite. Modul de organizare al datelor diferă în funcţie de locul unde sunt memorate (stocate), adică în memoria internă sau în memoria externă.
Aşa cum este deja cunoscut, într-un sistem de calcul electronic, informaţiile respectiv datele sunt reprezentate sub formă codificată. Ele sunt memorate fie în locaţii succesive (adresabile) din memoria internă (RAM şi/sau ROM), fie în memoria externă (reprezentată de discurile hard, discurile flexibile, casetele magnetice, CD-uri etc.). Din aceste considerente datele sunt organizate diferit, după cum se află în memoria internă sau în cea externă, aşa cum se poate vedea şi în figura alăturată. (Fig. 6.1.).
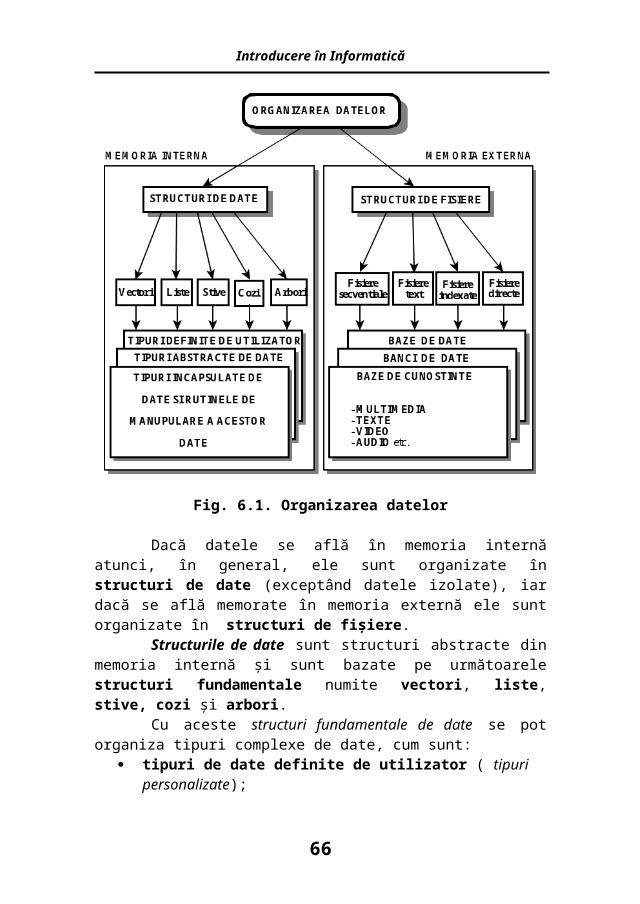
Fig. 6.1. Organizarea datelor
65
Introducere în Informatică
Dacă datele se află în memoria internă atunci, în general, ele sunt organizate în structuri de date (exceptând datele izolate), iar dacă se află memorate în memoria externă ele sunt organizate în structuri de fişiere.
Structurile de date sunt structuri abstracte din memoria internă şi sunt bazate pe următoarele structuri fundamentale numite vectori, liste, stive, cozi şi arbori.
Cu aceste structuri fundamentale de date se pot organiza tipuri complexe de date, cum sunt:
tipuri de date definite de utilizator ( tipuri personalizate); tipuri abstracte de date (TAD) complexe; tipuri încapsulate de date şi rutinele de manipulare a acestor
date.Structurile de fişiere se compun din următoarele structuri
fundamentale de fişiere: fişiere secvenţiale; fişiere de text (un caz particular de fişiere secvenţiale); fişiere indexate; fişiere directe.
Cu aceste structuri fundamentale de fişiere se pot structura , în memoria externă, tipuri mai complexe:
baze de date; bănci de date; baze de cunoştinţe.
Oricare din produsele informatice complexe, conţin doar o parte din structura de organizare a datelor, prezentată anterior, cu toate acestea fundamentele trebuie neapărat cunoscute.
6.1. Vectori
Datele în memoria internă sunt memorate ca o înşiruire de celule (octeţi), care formează nişte tablouri de celule numite vectori. Elementele componente ale vectorului pot fi individualizate printr-unul sau mai mulţi indici. În funcţie de indicii fiecărui vector se apreciază complexitatea acestuia. Astfel, dacă vectorul are un singur indice, avem de-a face cu un vector unidimensional şi este alcătuit dintr-o succesiune liniară de elemente v(i), unde i = 1,2, ... ,n.
Trebuie reţinut că se foloseşte următoarea convenţie de indici: anumite limbaje de programare (PACAL, FORTRAN, COBOL etc.) folosesc indici care sunt iniţializaţi cu valoarea numerică 1, iar în alte limbaje (C, C++, JAVA etc.) Indicii sunt iniţializaţi cu valoarea numerică 0. Dacă vectorii au doi sau mai mulţi indici atunci avem de-a face cu vectori multidimensionali. Vectorii care au doi indici se mai numesc vectori
66
Fig. 6.4. Memorarea „column major order” a elementelor unei matrice
Introducere în Informatică
bidimensionali, matrice cu două dimensiuni sau tablouri. Convenţia de iniţializare a indicilor rămâne valabilă şi în cazul vectorilor multidimensionali şi depinde, aşa cum s-a văzut, de limbajul de programare folosit.
Fig. 6.2. Vector unidimensional
Având în vedere că memoria internă are o structură liniară şi nu una matricială ori spaţială, elementele vectorului bidimensional pot fi memorate fie linie după linie, fie coloană după coloană. Astfel exprimat, un vector bidimensional poate fi memorat în ordinea liniilor (row major order) sau în ordinea coloanelor (column major order).
Din cele două figuri care urmează se poate vedea foarte clar structura liniară a memoriei interne a calculatorului şi modul în care se liniarizează introducerea elementelor unei matrice. Dacă elementele matrice sunt stocate (memorate) linie cu linie, şi cunoaştem poziţia primului element
67
Introducere în Informatică
al primei linii, atunci valoarea numerică n (numărul de coloane), şi dacă dorim să ne poziţionăm la începutul elementului a(j,i), va trebui să ne deplasăm cu : (n x (j -1)) + (i - 1) poziţii, pentru a ajunge la elementul dorit. Această expresie de poziţionare, pe începutul elementului a(j,i), se numeşte polinom de adresă (address polinomial) pentru elementul a(j,i).
Pentru a face calcule cu valorile elementelor matricei, fiecare element trebuie identificat, pe baza polinomului de adresă, în spaţiul liniar - unidimensional - al memoriei interne. Căutarea după linii sau după coloane a elementelor matricei îi revine în exclusivitate programatorului, făcând parte integrantă din algoritmul implementat prin programul de calcul proiectat.
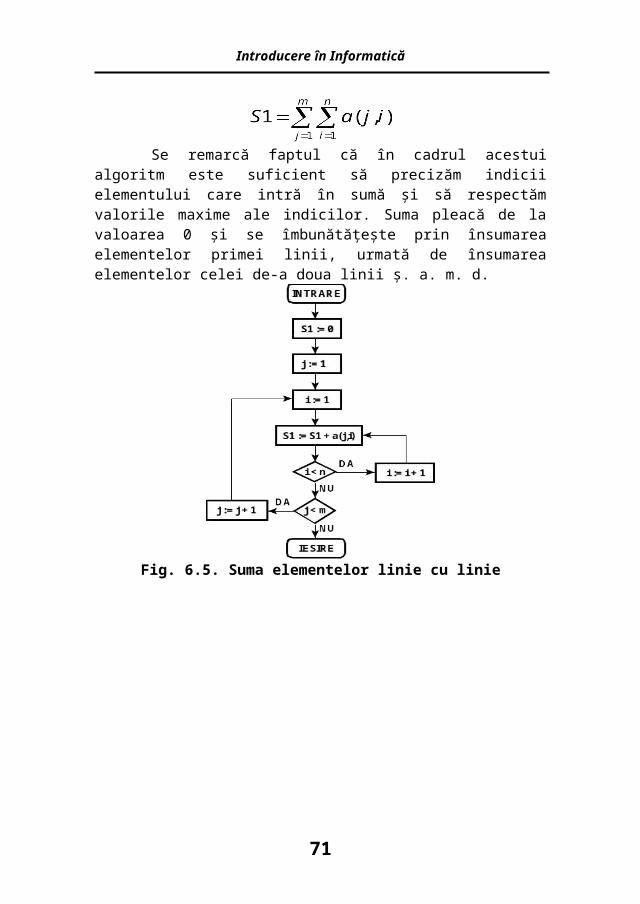
Într-un prim exemplu, să presupunem că memorarea elementelor unei matrice s-a făcut linie cu linie şi că dorim să adunăm toate aceste elemente, în ordinea în care au fost memorate. În acest caz va trebui să aplicăm algoritmul:
S1:=0pentru j=1 la m cu pas 1 pentru i=1 la n cu pas 1
S1:=S1+a(j,i) sfârşit-pentrusfârşit-pentru
Pentru o mai sintetică prezentare a algoritmului am reprezentat grafic cele arătate anterior. În acest mod se realizează suma dublă:
Se remarcă faptul că în cadrul acestui algoritm este suficient să precizăm indicii elementului care intră în sumă şi să respectăm valorile
68
Fig. 6.3. Memorarea „row major order” a elementelor unei matrice
Introducere în Informatică
maxime ale indicilor. Suma pleacă de la valoarea 0 şi se îmbunătăţeşte prin însumarea elementelor primei linii, urmată de însumarea elementelor celei de-a doua linii ş. a. m. d.
Fig. 6.5. Suma elementelor linie cu linie
Fig. 6.6. În cazul memorării coloană cu coloană
Desigur şi pentru calculul poziţiei unui element a(j,i), în cazul memorării coloană cu coloană, se poate face un calcul de adresă cu ajutorul
69
Introducere în Informatică
polinomului de adresă. Polinomul de adresă pentru elementul a(j,i), în cazul memorării coloană cu coloană, este dat de expresia:
(m x (i - 1)) + (j - 1)poziţii care trebuie să le parcurgem, pentru a ne poziţiona pe elementul a(j,i), raportat la primul element al matricei.
Pe baza polinoamelor de adresă se scriu subprograme (rutine software) care convertesc cererile de elemente, în care trebuie precizat numărul liniei şi coloanei, şi se obţin locaţii - în cadrul blocului liniar de memorie - care conţin valorile elementelor matricei. În multe limbaje acest lucru este transparent pentru programator, el trebuind să specifice numai indicii elementului cu care lucrează.
În al doilea exemplu, să presupunem că memorarea elementelor unei matrice s-a făcut coloană cu coloană şi că dorim de asemenea să adunăm toate aceste elemente, în ordinea în care au fost memorate. În acest caz va trebui să aplicăm algoritmul reprezentat grafic în Fig.6.6. şi exprimat în pseudocod ca:
S2:=0pentru i=1 la n cu pas 1 pentru j=1 la m cu pas 1
S2:=S2+a(j, i) sfârşit-pentrusfârşit-pentru
Algoritmul realizează suma dublă:
Se remarcă, şi aici, faptul că în cadrul acestui algoritm este suficient să precizăm indicii elementului care intră în sumă şi să respectăm valorile maxime ale indicilor. Suma pleacă de la valoarea 0 şi se îmbunătăţeşte prin însumarea elementelor primei coloane, urmată de însumarea elementelor celei de-a doua coloane ş. a. m. d.
În mod evident cele două sume sunt egale (S1 = S2), lucru care demonstrează că dacă se face o corectă gestiune a indicilor, elementelor componente ale matricei, rezultatele obţinute sunt corecte.
Dacă vectorul bidimensional reprezintă o matrice pătrată n = m. Elementele diagonalei principale sunt caracterizate de proprietatea i = j, prin urmare elementele acestei diagonale sunt a(i, i). Elementele diagonalei secundare au proprietatea j = n - 1 + i, deci elementele acestei diagonale sunt a(n-i+1,i).
70
Introducere în Informatică
Vă propun, ca temă de analizat, să alcătuiţi algoritmii pentru însumarea elementelor de deasupra diagonalei principale, suma celor de sub diagonala principală. La fel şi pentru diagonala secundară.
Vectorii multidimensionali sunt caracterizaţi de mai mulţi indici, elementele vectorilor x-dimensionali fiind memoraţi în spaţiul liniar al memoriei, în segmente imbricate, după următorul algoritm (să-i zicem de citire şi memorare):
pentru i=1 la n cu pas 1 j=1 la m cu pas 1
k=1 la p cu pas 1 l=1 la r cu pas 1.........................citeşte a(i, j, k, l, ...) (<---------->) x- indecşisfârşit-pentru
sfârşit-pentrusfârşit-pentru
sfârşit-pentru
Valoarea maximă a numărului de indici x, depinde de limbajul utilizat.
Dacă de exemplu avem un vector x-dimensional conţinând elementele unui “cub” din spaţiul cu x-dimensiuni, atunci n=m=p=r= .... Elementele de pe prima diagonală au proprietatea I=j=k=l= ..., iar cele de pe a doua diagonală au proprietatea n-k+1=j=k=l= ... ş. a. m. d. Identificarea elementelor “cubului” revine programatorului, iar specificarea lor se face prin precizarea indicilor, de forma: a(i,j,k,l,...).
Vectorii sunt structuri statice deoarece înainte de a fi populat (să fie memorate elementele vectorului) trebuie cunoscut numărul lui de elemente si se alocă spaţiu contiguu de memorie pentru toate elementele, indiferent dacă sunt utilizate sau nu, fără a-i mai putea schimba dimensiunile.
Vectorii sunt un caz particular de liste numite liste contigue.
6.2. Liste Vectorii au un singur mare neajuns, acela că forma (numărul de
indici) şi dimensiunile (valorile maxime ale indicilor) sunt fixe, simularea lor în memoria internă rezumându-se la calculul adresei reale a elementelor ce compun vectorul. Pentru o eficientă utilizare a memoriei interne, este nevoie de o structură dinamică, cu formă şi dimensiuni variabile. O asemenea
71
Introducere în Informatică
structură ne conduce la conceptul de listă, concept strict legat de acela de pointer. Să explicăm mai întâi noţiunea de pointer.
Prin pointer sau indicator de adresă1 se înţelege un element reprezentând o adresă, pe baza căreia pot fi referite (legate) componentele unei structuri de date din memoria internă (liste, arbori, cozi etc.).
Locaţiile memoriei interne ale unui sistem de calcul electronic sunt identificate prin adrese numerice, numite adrese reale de memorie, care pot fi calculate şi dintr-o adresă simbolică. Calcularea adresei duce la obţinerea, fără probleme, a unui element căutat, prin citirea valorii elementului de la adresa calculată. Dar cum adresele sunt şi ele valori numerice, înseamnă că le putem memora şi pe ele în memoria internă. Ajungem astfel în situaţia că un element este memorat la o anumită locaţie de memorie, iar adresa locaţiei într-o altă zonă distinctă de memorie2. Aşa cum utilizatorul are acces la locaţia unde se găseşte elementul memorat, tot la fel are acces şi la locaţia unde este memorată adresa sa, adică la pointer-ul elementului. Lucrul cu pointer-ii permit programatorului să-i construiască propriile “reţele” de date.
O listă este o structură liniară şi dinamică de date care are următoarele caracteristici:a) liniaritate, proprietate caracterizată de faptul că elementele care o formează au o poziţie bine determinată în cadrul structurii, respectând următoarele reguli:
are un element unic numit primul element, element de început sau capul listei;
are un element unic numit ultimul element, elementul de sfârşit sau coada listei;
fiecare element, cu excepţia ultimului, are un element succesor; fiecare element, cu excepţia primului, are un element predecesor.
1 T. Popescu .c. - Dicionar de informatic, Editura tiinific i enciclopedic, Bucureti, 1981, p.1712 Pentru celelalte structuri din memoria intern nu mai facem precizarea unde se afl i vom subânelege c în memoria intern, pentru economie de spaiu tipografic
72
Fig. 6.7. Exemplu de listă circulară înlănţuită după autorul Mihai Eminescu
Introducere în Informatică
b) dinamicitate, proprietate care rezultă din faptul că numărul de elemente al listei se modifică în timp, în sensul că se pot adăuga sau şterge elemente în sau din listă. Asta înseamnă că în memoria internă sunt ocupate atâtea locaţii câte sunt necesare pentru memorarea elementelor curente.
Lista este o structură dinamică şi prin faptul că iniţial ea poate fi vidă, deci poate să nu conţină nici un element, prin urmare spaţiul de memorie alocat ei este nul. Dar pe măsură ce trebuie populată (memorate elementele listei) cu noi elemente care se introduc în listă, în aceiaşi măsură se alocă (şi ocupă spaţiu liniar de memorie pentru includerea în listă, în ordinea populării cu aceste elemente. Teoria spune, că nu există absolut nici o restricţie privitoare la locul de introducere a unui element nou, deci poate fi inclus oriunde în listă. O altă operaţie care poate fi făcută cu elementele unei liste este aceia de scoatere a unui element din listă (ştergerea unui element), lucru care presupune refacerea legăturilor (modificarea pointer-ilor) între elementul anterior şi cel posterior elementului scos din listă.
Fiecare element al listei este format din două părţi:a. o parte folosită pentru memorarea informaţiilor propriu-zise ale
elementului, numită articol (record) sau nod (node);b. o parte utilizată pentru memorarea pointer-ului către elementul
următor din listă, în cazul listelor simplu înlănţuite, sau pentru memorarea a doi pointer-i (unul către elementul succesor şi altul pentru cel predecesor), în cazul listelor dublu înlănţuite.
Elementele listei sunt răspândite în spaţiul liniar al memoriei interne fără a fi dispuse, neapărat, în mod contiguu. Altfel spus, lista este fragmentată în blocuri, legate între ele prin pointer-i şi distribuite în tot spaţiul de memorie. Datorită sistemului de înlănţuire prin pointer-i (adrese), acest mod de organizare se numeşte listă înlănţuită (linked list).
În mod natural, pentru a şti de unde începe lista, trebuie rezervată o locaţie de memorie în care se păstrează adresa primului articol al listei, fiind o adresă înseamnă că este un pointer numit pointer cap de listă (head pointer). Citirea unei liste de la primul element până la coada listei se numeşte traversarea listei, citirea listei sau parcurgerea listei. Pentru a traversa lista trebuie să începem de la locaţia indicată de pointer-ul cap de listă, unde vom găsi conţinutul primului articol şi pointer-ul la articolul următor. Conţinutul pointerului ne va conduce la cel de-al doilea articol ş.a.m.d, până vom ajunge la ultimul element care reprezintă sfârşitul listei.
Sfârşitul listei este rezolvat printr-un pointer cu valoare specială (de obicei valoarea 0) numit pointer NIL, plasat în zona de pointer a ultimului element, şi care este o combinaţie de biţi uşor de testat (depistat).
În general listele se clasifică în: liste contigue; liste înlănţuite:
73
Introducere în Informatică
liste simplu înlănţuite; liste dublu înlănţuite; liste circulare.
Listele contigue sunt listele care nu conţin pointer-i şi au dimensiune fixă, fiind de fapt nişte vectori, care de obicei se folosesc în procesarea şirurilor de caractere.
Listele simplu înlănţuite posedă pointer cap de listă, conţinutul nodului, pointer spre nodul succesor (liste directe) sau pointer spre nodul predecesor (liste inverse) şi coada listei cu pointer-ul NIL. (Fig. 6.8.).
Listele dublu înlănţuite au elemente care conţin obligatoriu două pointer-e, unul spre elementul succesor iar al doilea spre elementul predecesor şi desigur conţinutul nodului.
Listele circulare sunt acele liste, simplu sau dublu înlănţuite, la care pointerul NIL este egal cu pointerul cap de listă.
Asupra listelor, în general, se pot efectua următoarele operaţii: inserare, care constă în introducerea unui element nou în listă; ştergere, care constă în eliminarea unui element din listă; parcurgere (traversare, inspectare sau citire), care constă în citirea
şi eventual procesarea , începând de la primul şi până la ultimul element al listei.
Pentru a parcurge o listă se foloseşte o locaţie de memorie în care se memorează pointer-ul nodului curent, numit cursor. De obicei inserarea
74
Fig. 6.8. Listă simplu înlănţuită
Fig. 6.9. Inserarea unui articol după cursor într-o listă înlănţuită
Introducere în Informatică
sau ştergerea unui element se face după poziţia curentă a cursorului. (Fig. 6.9. şi Fig. 6.10.).
Operaţia de inserare este ceva mai simplă şi ea se poate uşor intui.Mai complicată este operaţia de ştergerea, deoarece trebuie ţinută
evidenţa elementelor din listă care este mai complicată. Datele aflate în aceste blocuri de memorie devin inutile, prin urmare ele pot fi utilizate la memorarea unor noi articole ce trebuie inserate. Cea mai răspândită tehnică de reutilizare este ceia de a ţine evidenţa blocurilor disponibile într-o listă nouă (listă secundară) care să conţină blocurile eliberate prin ştergere din listă (lista principală). Noua listă secundară ţine evidenţa blocurilor eliminate din lista principală, disponibile pentru utilizare ulterioară. Are loc aşadar, un proces de reutilizare la inserare în lista principală, a blocurilor “orfane” aflate în gestiunea listei secundare. Acest proces de colectare a spaţiului de memorie se numeşte colectarea reziduurilor (garbage collection) şi este o componentă esenţială a sistemului de memorare dinamică. Dacă spaţiul ocupat de elementele şterse nu este recuperat într-o listă secundară, atunci spaţiul disponibil se restrânge odată cu noile inserări de elemente, până la ocuparea întregului spaţiu de memorie. Această pierdere de memorie (absolut nejustificată) este cunoscută sub denumirea de scurgere de memorie (memory leak).
6.3. Stive
Listele înlănţuite permit inserarea unui element sau ştergerea lui din orice poziţie a listei.
Listele contigue permit mult mai greu aceste operaţii, în sensul că ştergerea unui element presupune deplasarea spre “stânga” a tuturor
75
Fig. 6.10. Ştergerea dintr-o listă înlănţuită, la cursor
Introducere în Informatică
predecesorilor cu un articol, iar inserarea unui element presupune deplasarea spre “dreapta” a tuturor succesorilor şi inserarea articolului în locul liber creat. Cam dificile operaţii mai ales în cazul listelor contigue mari! Mult mai uşor ar fi să inserăm sau să ştergem un articol în coada listei. În acest mod am ajuns la o nouă structură care poartă numele de stivă(stack)3.
Stiva este un caz particular de listă contiguă la care operaţiile de inserare şi/sau ştergere se efectuează în coada listei, coada listei numindu-se vârful stivei (top stack) iar capul listei numindu-se baza stivei (base stack). Accesul este limitat doar la vârful stivei şi operaţiunea de inserare a unui element în vârful stivei se numeşte operaţie push (operaţie de încărcare a stivei), iar ştergerea unui element din vârful stivei se numeşte operaţie pop (operaţie de descărcare a stivei). Datorită particularităţilor ei stiva este o structură de date de tip LIFO (Last-Input First-Output), adică ultimul element venit în stivă este primul care pleacă. Deci, ultimul element încărcat în stivă este primul element care va fi descărcat din stivă. Exemple clasice întâlnite în realitate sunt stivele de cărţi (ultima aşezată este prima luată din stivă), stiva de tăvi la o cantină cu autoservire, sectorul de cartuşe al pistolului automat (ultimul cartuş introdus în sector este primul extras) etc.
În domeniul nostru de interes, exemplul devenit clasic este cel al apelului procedurilor imbricate (Fig. 6.11. ). Atunci când un program principal apelează o procedură, trebuie să memorăm adresa de revenire în programul principal (adresa primei instrucţiuni ce se va executa, după revenirea din procedură), să executăm prima instrucţiune din procedură, apoi restul de instrucţiuni conform algoritmului implementat de procedură.
Fig. 6.11. Apelul procedurilor imbricate
3J. Gleen Brookshear Introducere în informatică Ed.Teora, Bucureşti, 1998, p.305
76
Introducere în Informatică
Programul sau procedura care apelează se numeşte program apelant sau procedură apelantă. Subprogramul sau procedura care este apelată se numeşte subprogram apelat sau procedură apelată.
Memorarea adresei de revenire în programul apelant se face într-o stivă, (Fig. 6.12), în primul rând prin incrementarea automată a vârfului stivei (SP - stack pointer) şi apoi prin memorarea primului element al stivei. Pentru a şti în fiecare moment care este baza stivei (base pointer-BP) se utilizează o locaţie de memorie de tip pointer, în care se memorează valoarea bazei. Aceiaşi tehnică se utilizează şi pentru vârful stivei rezervându-se o locaţie de memorie specială pentru memorarea lui. Atunci când stiva este goală SP < BP, lucru care arată că stiva nu conţine nici un element memorat în ea. De altfel, această relaţie este utilizată în a testa dacă o stivă este goală sau nu. Incrementarea automată a vârfului stivei se face pentru a pregăti memorarea următorului element în stivă, deci pentru a pregăti stocarea următoarei adrese de revenire. În cazul procedurilor imbricate (încuibărite) procesul continuă din aproape în aproape până la apelarea ultimei proceduri. La revenirea din procedurile apelate în cele apelante, procesul se desfăşoară invers.
77
Fig. 6.12. Încărcarea şi descărcarea stivei în cazul apelării a n proceduri
Introducere în Informatică
Memorarea elementelor stivei la apelul procedurilor se numeşte încărcarea stivei, iar procesul de revenire în procedura apelantă prin recuperarea adresei de revenire se numeşte descărcarea stivei.
Dacă notăm cu RP adresa de revenire în programul principal, cu R1 adresa de revenire în procedura P1, ... , cu Ri adresa de revenire în procedura Pi, ... , cu Rn-1 adresa de revenire în procedura Pn-1 din procedura Pn, şi de asemenea dacă notăm cu A1 apelul procedurii P1, cu A2 apelul procedurii P2, ... , cu Ai apelul procedurii Pi, ... , cu An apelul procedurii Pn, atunci şirul de “paşi” de apel A1, A2, ... , Ai, ... , An indică ordinea de invocare a procedurilor, iar şirul de “paşi” de revenire Rn-1, Rn-2, ... , Ri, ... , R2, R1, RP indică ordinea de revenire din proceduri. Aceasta înseamnă că pentru a memora “paşii” de revenire, la nivelul imediat superior, trebuie încărcată stiva în ordinea RP, R1, R2, ... , Ri, ... , Rn-2, Rn-1, plecând de la baza stivei. Evoluţia valori pointer-ului SP asigură parcurgerea în ambele sensuri a stivei.
La revenirea din procedurile apelate se efectuează mai întâi decrementarea vârfului de stivă SP, pregătindu-se procesul de descărcare a stivei, apoi se face descărcarea propriu-zisă. Ordinea de descărcare va fi dată de şirul Rn-1, Rn-2, ... , Ri, ... , R2, R1, RP. Incrementarea şi decrementarea pointer-ului de stivă se face cu lungimea necesară pentru memorarea adresei de revenire.
Un alt exemplu ar fi acela al afişării şi/sau imprimării, în ordine inversă, a conţinutului unei liste înlănţuite. Stiva se încarcă începând de la capul de listă, apoi se încarcă pointer-ul primului nod ş.a.m.d., iar descărcarea se utilizează pentru afişarea şi/sau imprimarea nodului aflat în vârful stivei, reprezentând coada listei, apoi decrementându-se anterior vârful stivei vom putea afişa şi/sau imprima penultimul nod ş.a.m.d.
Din punct de vedere matematic, cel mai natural mod de a reprezenta o stivă, este să implementăm într-o tehnică secvenţială utilizând un tablou. Să notăm acest tablou STIVA = { S(1), S(2), ..., S(i), ..., S(n) }unde n este numărul maxim de noduri, S(1) este zona de memorare a primului nod, S(2) al doilea nod, etc., iar S(n) este ultimul nod al stivei, care uneori se mai notează cu S(top) şi unde top este o variabilă (de tip printer sau de tip indice) care indică ultimul nod inserat. În faza iniţială top=0.
78
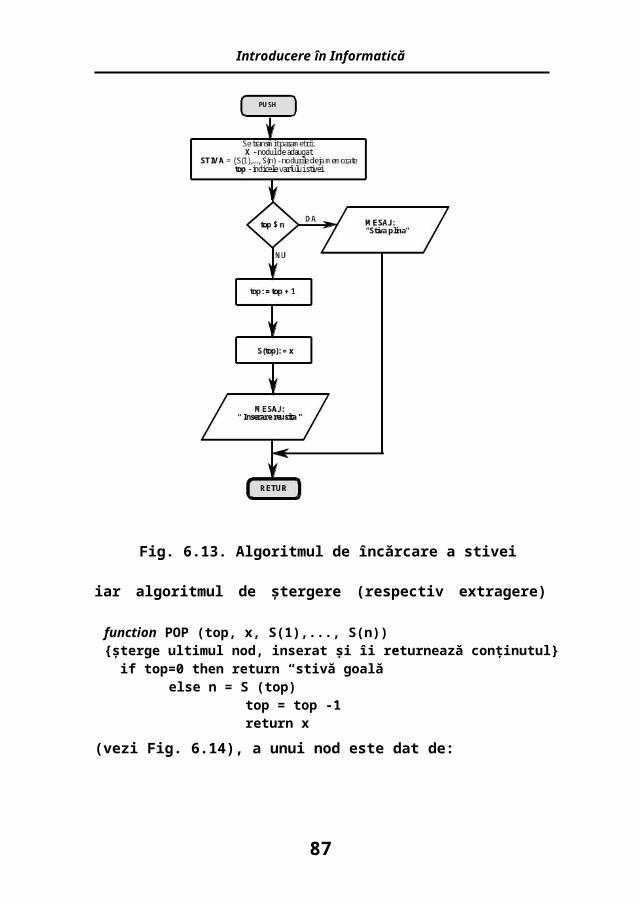
function PUSH (top, x, S(1), S(2),..., S(n))
{adaugă nodul x în stivă}if top=n then return “stivă plină” else top = top +1 S(top)= x return “inserare reuşită “endif
Introducere în Informatică
Având în vedere considerentele anterioare, algoritmul general de inserare (încărcare)4 într-o stivă este:
Fig. 6.13. Algoritmul de încărcare a stivei
iar algoritmul de ştergere (respectiv extragere) (vezi Fig. 6.14), a unui nod este dat de:
4R. Andonic, I. Gârbacea - Algoritmi fundamentali, o perspectivă C++, Editura Libris Cluj-Napoca, 1995, pp. 39.
79
function POP (top, x, S(1),..., S(n)){şterge ultimul nod, inserat şi îi returnează conţinutul} if top=0 then return “stivă goală”
else n = S (top)top = top -1return x
endif
Introducere în Informatică
Fig. 6.14. Algoritmul de descărcare a stivei
6.4. Cozi
Un alt caz particular de listă este coada. Coada este o listă liniară în care inserarea unui element se face la începutul listei iar ştergerea unui element se face din coada listei. Datorită acestei particularităţi coada este o structură de date de tip FIFO (Fairst-Input First-Output), adică ultimul element venit în coadă este ultimul care pleacă din ea. Acest lucru este echivalent cu un sistem în care politica de servire este “în ordinea sosirii”. Zona din coadă în care se inserează un element se numeşte cap (head) iar capătul de la care sunt eliminate elementele se numeşte coadă (tail). Pentru a nu cădea în “păcatul” folosirii unei formulări de genul coada cozii, în continuare, vom folosi termenii de început şi sfârşit al cozii. Coada foloseşte un bloc contiguu de celule de memorie la fel ca şi în cazul stivei. Pentru gestiunea cozii se foloseşte un pointer de început şi un pointer de sfârşit al acesteia.
Din punct de vedere matematic, cel mai natural mod de a reprezenta o coadă este să implementăm o listă liniară COADA= {C(1), C(2),..., C(n)} unde n este numărul de noduri al cozii. Pentru parcurgerea cozii să presupunem că folosim variabila tail care conţine indicele locaţiei predecesoare primei locaţii ocupate şi variabila head care conţine indicele locaţiei ultim ocupate. Relaţia tail = head se realizează dacă şi numai dacă
80
Introducere în Informatică
coada este vidă. Înaintea populării cozii (iniţial) există relaţia matematică: head = tail = 0.
În aceste condiţii, inserarea unui nod şi extragerea (ştergerea) unui nod în/din coadă necesită acelaşi timp, deoarece algoritmii utilizaţi sunt similari, diferind doar variabilele actualizate.
Algoritmul de inserare într-o coadă este:
function INSERT- COADA (x, head, tail, C(1), C(2), ..., C(n)) {inserarea nodului x în capul cozii}
head = (head +1) mod nif head = tail then return “coadă plină”
C (head) = xreturn “succes”
Fig. 6.15. Algoritmul de inserare în coadă
iar algoritmul de extragere5 (ştergere) din coadă este:
function EXTRAGERE-COADA(x, head, tail, C(1), ..., C(n)){ şterge nodul din coada listei şi-l returnează }
5ibidem, pag. 40.
81
Introducere în Informatică
if head = tail then return “coadă vidă” tail = (tail +1) mod n x = C (tail)
return x
Fig. 6.16. Algoritmul de extragere din coadă
Se observă că atât coada plină cât şi coada vidă se determină cu head = tail. Pentru a evita confuziile din cele n celule ale vectorului C se folosesc numai n-1 locaţii, prin urmare se pot implementa cozi cu cel mult n-1 noduri.
Ca o primă implementare să luăm cazul în care dorim să efectuăm operaţii de ştergere sau inserare de articole, la ambele capete (extremităţi) ale structurii de tip coadă. Pentru aceasta avem nevoie de doi pointeri: unul pentru începutul cozii şi unul pentru sfârşitul ei.
Să presupunem că la început, coada este vidă (goală sau nepopulată). În acest prim caz pointerul de început este identic ca valoare cu pointerul de sfârşit. La fiecare operaţie de inserţie sau ştergere se actualizează pointerii de gestiune a cozii.
Pe măsură ce se efectuează ştergeri, zone de memorie adiacente capetelor cozii rămân libere. În acest fel apare următoarea problemă: coada se deplasează “asemeni unui sloi de gheaţă, prin memoria internă, alternând
82
Introducere în Informatică
(prin suprascriere) alte date care urmează după zona rezervată cozii. Această problemă apare datorită tendinţei de adăugare de articole după ultimul articol înscris în coadă şi actualizarea pointerului de sfârşit al cozii. Procedând “mecanic” se poate ajunge până la ocuparea întregii memorii RAM. Această “foame” de memorie nu se datorează creşterii excesive a numărului de articole adăugate, ci mai degrabă procedurii de acces mai puţin performante.
O soluţie la această problemă este conceperea unei cozi de dimensiuni moderate, dar care să posede atributul de coadă dinamică, uşor adaptabilă, prin reocuparea articolelor disponibilizate prin ştergere. În acest fel datele vor “migra” în interiorul zonei alocate cozii, materializând conceptul de structură înlănţuită denumită coadă circulară. Din punct de vedere conceptual, coada circulară simulează fenomenul de buclă circulară în blocul de memorie alocat cozii.
6.5. Arbori
Pentru a putea înţelege structura de tip arbore trebuie mai întâi să definim noţiunea de graf.
Un graf orientat neordonat (pe care-l notăm cu G) este o pereche (N,R), unde N este mulţimea de noduri (elemente, puncte) ale grafului iar R este o relaţie în N (relaţia se mai numeşte conexiune, arc, muchie, latură sau linie). În concluzie, graful G este definit ca o mulţime finită, nevidă de noduri N şi o mulţime R de perechi de noduri distincte. Un graf orientat se reprezintă ca în figura 6.18.
În această figură Ni cu i = 1,2,..., n sunt nodurile grafului, iar perechile (Ni, Nj) sunt arcele grafului, cu orientarea dinspre Ni înspre Nj.
Fie arcul (Ni, Nj) al grafului G. În acest caz nodul din care iese săgeata, adică Ni, se numeşte predecesorul nodului Nj în care intră săgeata arcului orientat, iar Nj se numeşte succesorul lui Ni. Pentru o mai mare claritate, nodurilor şi/sau arcelor unui graf li se ataşează o informaţie de explicitare numită etichetă.
Mulţimea nodurilor {N1, N2, ...Nl} dintr-un graf constituie un drum de lungime l, dacă (Ni, Ni +1) cu i = 1,2,..., l - 1 sunt arce ale grafului. Dacă toate nodurile Ni sunt distincte, atunci mulţimea {N1, N2, ...Nl} se numeşte cale. Dacă există o cale de la N i la Nj, se spune că Nj este accesibil din Ni. Distanţa dintre două noduri ale unui graf este egală cu lungimea căii celei mai scurte dintre acestea6.
Graful fără nici un ciclu se numeşte graf aciclic. Se numeşte ciclu (sau circuit) o cale (Ni, Ni+1,..., Nj) în care Ni = Nj. Pentru oricare nod aparţinând unui graf se poate defini:
6T. Popescu ş.c. - Dicţionar de informatică, Ed. Ştiinţifică şi encic., Bucureşti 1981, pag. 160.
83
Introducere în Informatică
1. i-gradul, care reprezintă numărul de arce care intră în acel nod;2. e-gradul, reprezentat de numărul de arce care ies din nod.
Nodul pentru care i-gradul este 0 (zero) se numeşte nod de bază, deoarece în acel nod nu intră nici un arc. Nodul care are e-gradul 0 se numeşte nod terminal (sau frunză).
Cele mai utilizate grafuri în informatică7 sunt:a) - graful bipartit (sau graful bicolorabil - în engleză: bicolorable graph)
este graful în care mulţimea N a nodurilor poate fi împărţită în două submulţimi NA şi NB cu proprietatea că fiecare arc al grafului uneşte un nod din NA cu un nod din NB; această proprietate poate fi realizată dacă, şi numai dacă, toate ciclurile grafului sunt de lungime pară;
b) - graful biconectat (în engleză: biconnected graph) este graful care are proprietatea că orice pereche de noduri face parte dintr-un ciclu;
c) - graful complet (în engleză: complete graph) este graful în care fiecare nod aparţinând mulţimii N este conectat prin câte un arc cu toate celelalte noduri ale grafului;
d) - graful conectat (în engleză: connected graph) este graful care are proprietatea că oricare două noduri sunt conectate printr-o cale;
e) - graful de stare (în engleză: state graph) este graful care reprezintă evoluţia unei maşini secvenţiale în spaţiul stărilor, nodurile reprezentând stările distincte ale maşinii iar arcele reprezentând tranziţiile de la un nod la altul;
f) - graful etichetat (în engleză: labelled graph) este graful în care fiecărui nod i se atribuie o etichetă (un nume de nod);
g) - graful Eulerian (în engleză: Eulerian graph) este graful care conţine un drum ce trece prin fiecare arc numai o singură dată;
h) - graful Hamiltonian (în engleză: Hamiltonian graph) este graful care conţine o cale ce trece prin fiecare nod numai o singură dată;
i) - graful orientat (în engleză: oriented graph) este graful în care perechile de noduri (Ni, Nj) sunt ordonate în succesiunea Ni spre Nj;
j) - graful de tip arbore (în engleză: tree graph) A = (N,R) care este un graf orientat aciclic, având un nod rădăcină şi toate celelalte noduri având i-gradul unitar (egal cu 1).
Dintre toate aceste grafuri, cele mai utilizate sunt grafurile de tip arbore sau simplu arbore.
Un arbore A este un graf orientat aciclic8 A = (N,R), cu următoarele două proprietăţi:
7ibidem8T. Popescu ş.c. - Dicţionar de informatică, Editura Ştiinţifică şi Enciclopedică, Bucureşti 1981, pag. 30.
84
Introducere în Informatică
Fig. 6.18. Graf orientat
Fig. 6.19. Arbore binar elementar
1. în mulţimea nodurilor N există un singur nod r N care are i-
gradul zero, numit nod rădăcină;
2. toate celelalte noduri ale arborelui au i-gradul unitar (egal cu 1), şi orice nod Ni r este accesibil din r.
Pentru orice arbore distingem următoarele: ordinul unui nod este e-gradul nodului în cauză; ordinul unui arbore este reprezentat de ordinul
maxim dintre nodurile componente ale sale; nivelul unui nod este:
85
Introducere în Informatică
i. 0 pentru nodul rădăcină ;ii. i +1 pentru descendenţii direcţi ai nodurilor
aflate pe nivelul i.Dacă nodul Nj este accesibil din nodul Ni, aşa cum se vede în
figura anterioară, vom spune că j este descendentul (sau fiul) lui i. În plus secvenţa de noduri (Ni, Ni+1, ...,Nj) reprezintă o cale de la i la j care are lungimea egală cu numărul de noduri ale căii minus 1. În particular, dacă lungimea căii este egală cu 1, vom spune că j este descendentul (sau fiul) direct a lui i, sau că i este predecesorul (părinte) direct a lui j. Dacă lungimea celei mai lungi căi a arborelui A este l, atunci h = l +1 poartă numele de înălţime a arborelui. Prin convenţie, la un nod pot fi conectaţi zero sau mai mulţi subarbori.
Fie A = (N,R) un arbore, atunci A` = ( N`,R`) este un subarbore dacă sunt satisfăcute relaţiile:
1. N` (mulţimea vidă);2. N` N 3. R`= N` x N R
iar pentru orice i N` - N nu există nici un nod j N` astfel încât i să fie descendentul lui j.
Orice rădăcină a unui subarbore este un nod dominant al subarborelui şi prin urmare rădăcina arborelui este nod dominant al întregului arbore. De asemenea, un nod care este conectat la zero subarbori se numeşte nod terminal sau nod frunză. În cazul arborilor, în loc de nod se mai foloseşte şi noţiunea de vârf.
De asemenea, sunt foarte importanţi arborii de căutare, care pentru orice nod neterminal i, căruia îi este asociată informaţia având cheia a i, satisface condiţiile:
dacă aj este cheia unui nod din subarborele stâng dominat de i, atunci există relaţia: ai > aj ;
dacă aj este cheia unui nod din subarborele drept dominat de i, atunci există relaţia: ai < aj .
Într-un arbore binar, numărul maxim de vârfuri de adâncime K este 2K. Un arbore binar care are înălţimea h, are cel mult 2h+1 -1 vârfuri. Dacă are exact 2h+1 -1 vârfuri avem de-a face cu un arbore plin.
Un arbore complet se obţine dintr-un arbore binar plin cu înălţimea h, având n noduri, prin eliminarea vârfurilor de la n+1, n+2, ..., 2h+1
-1. Acest tip de arbore se poate reprezenta secvenţial un vector în memorie. Terminarea arborelui făcându-se cu pointer-ii NIL.
86
Introducere în Informatică
Fig. 6.20. Reprezentarea prin pointeri (adrese) a unui arbore binar
Implementarea unui arbore binar în memoria internă se poate face în două moduri:
prin utilizarea pointerilor de legătură, care reprezintă adresa fiului stâng sau a fiului drept, caz în care nu este obligatoriu ca celulele de reprezentare a nodurilor să fie într-o zonă de memorie contiguă;
prin utilizarea unui vector, caz în care celulele de reprezentare a nodurilor trebuie să fie obligatoriu într-o zonă de memorie contiguă.(a doua reprezentare este mai puţin economică din cauza celulelor neocupate (cazul arborilor neplini)).
Pentru exemplificare să luăm arborele prezentat în figura 6.21. De asemenea, sunt foarte importanţi arborii de căutare, care pentru
orice nod neterminal i, căruia îi este asociată informaţia având cheia a i, satisface condiţiile:
dacă aj este cheia unui nod din subarborele stâng dominat de i, atunci există relaţia: ai > aj ;
dacă aj este cheia unui nod din subarborele drept dominat de i, atunci există relaţia: ai < aj .
Acest arbore poate fi implementat prin utilizarea pointerilor de legătură ca în figura 6.21, iar ca vector figura 6.22.
87
Introducere în Informatică
Fig. 6.21. Organizarea în memorie utilizându-se pointeri
Fig. 6.22. Exemplu de arbore binar(simetric)
Aşa cum se observă, în acest ultim caz, dacă arborele nu este complet multe elemente ale vectorului nu vor conţine informaţii, ceea ce înseamnă că spaţiul de memorie este folosit dezavantajos. Fiecare din metodele anterioare au avantajele şi dezavantajele lor, rămânând la aprecierea programatorului care metodă să fie implementată pentru fiecare caz în parte. Metoda implementată, împreună cu zona de stocare a arborelui, trebuie să formeze un pachet care creează posibilitatea ca utilizatorul să lucreze cu arborele, fără ca atenţia să-i fie distrasă de detaliile de implementare a arborelui în sine.
88
Introducere în Informatică
Asupra unui arbore, în general, se pot efectua prelucrări care se clasifică în două categorii:
prelucrări care afectează structura arborelui, cum sunt: inserări sau eliminări de noduri;
prelucrări care se fac asupra informaţiilor din nodurile arborelui, cum sunt: tipărirea informaţiilor asociate tuturor nodurilor ce compun arborele sau actualizarea acestor informaţii.
Toate aceste prelucrări necesită inspectarea nodurilor ce compun arborele, într-o ordine bine stabilită. Această inspectare se numeşte parcurgerea arborelui într-o ordine de tratare a nodurilor.
În general un arbore binar poate fi considerat ca fiind format dintr-un nod rădăcină (pe care-l notăm R) şi doi subarbori binari, unul fiind subarborele stâng (notat cu S) şi altul fiind subarborele drept (notat cu D). Numim acest arbore ca arbore binar elementar (figura 6.23).
Parcurgerea arborelui binar elementar se poate face în trei moduri distincte, în funcţie de ordinea de tratare:
Aceste modalităţi de parcurgere sunt prezentate grafic în figura 6.24.
a)preordine-RSD b)inordine-SRD c)postordine-SDR
Fig. 6.24. Parcurgerea arborelui binar elementar
Având în vedere că S şi D sunt la rândul lor arbori, înseamnă că cele trei metode de parcurgere sunt definite recursiv, specificându-se faptul că parcurgerea arborelui vid nu determină nici un fel de prelucrare.
89
Introducere în Informatică
Parcurgerea unui arbore duce la o tratare secvenţială a nodurilor care compun arborele, dinspre “nodul precedent” înspre “nodul următor” supus operaţiei de prelucrare, menţionând că nodul supus prelucrării nu mai este întotdeauna acelaşi cu “predecesorul” sau “succesorul” direct din structura arborelui.
Să luăm ca exemplu un arbore de reprezentare a expresiei:(a*b - c) / (d + e*f )
a cărui reprezentare se dă în figura 6.25.
Fig.6.25. Arborele ce reprezintă expresia (c*b - c)/ (d+e*f)
Dacă folosim cele trei metode de parcurgere vom obţine următoarele forme de şiruri:
1. - RSD: / -* abc + d*ef - forma prefixată; 2. - SRD: a * b - c / d + e *f - forma infixată;3. - SDR: ab * c - def * + / - forma postfixată;
6.6. Fişiere
Un fişier este o colecţie organizată de înregistrări9, memorat pe un anumit suport de informaţii. Colecţia de înregistrări este omogenă atât din punct de vedere al structurii şi naturii informaţiilor, cât şi al cerinţelor de prelucrare a lor.
Suportul de informaţie se numeşte volum, dacă conţine mai multe fişiere. Orice fişier este individualizat printr-un nume de fişier (file name). Începutul şi sfârşitul fiecărui fişier este marcat pe suport prin:
- BOF - Begin Of File - marcajul de început al fişierului;
9T. Popescu S.C. - Dicţionar de informatică, Editura Ştiinţifică şi Enciclopedică, Bucureşti, 1981, p.139.
90
Introducere în Informatică
- EOF - End Of File - marcajul de sfârşit de fişier (^Z la fişierele ASCII).
Fişierul se compun din mai multe blocuri, fiecare bloc se compune din mai multe înregistrări de acelaşi tip şi fiecare înregistrare se compune din mai multe câmpuri, care sunt de fapt date individuale. Acest lucru este reprezentat schematic în figura 6.26.
Înregistrările conţinute de un fişier sunt de două feluri:- înregistrări fizice sau înregistrări la nivel de bloc;- înregistrări logice sau la nivel de articol.
O înregistrare fizică este unitatea de transfer între dispozitivul periferic pe care se afla volumul şi memoria internă RAM, sub controlul microprocesorului. Orice operaţie de intrare-ieşire în fişier, se fac la nivel de bloc. Adică, o modificare în articolul Ak al blocului Bj. Adică, o modificare în articolul Ak al blocului Bj, presupune citirea întregului bloc Bj într-o zonă tampon (numită buffer), modificarea articolului, după care se reînscrie întregul Bj conţinând modificările ce s-au efectuat. Din punct de vedere al utilizatorului, acest lucru este transparent. Sarcina citirii/scrierii blocului (înregistrării fizice) revenind sistemului de gestiune a fişierelor, care o execută automat, componentă care aparţine sistemului de operare.
O înregistrare logică este unitatea de informaţie pe care o procesează programul. În cadrul programului se are acces la un anumit articol (numit şi acces la nivel logic, sau acces logic), respectiv la toate componentele acestuia la nivel inferior: câmpuri şi date ce compun un câmp.
Suporturile de informaţii pot fi de diferite capacităţi de memorare. De aceea, un volum poate conţine mai multe fişiere, un fişier, ori (în cazul
91
Fig. 6.26. Structura unui volum care conţine n fişiere
Introducere în Informatică
disketelor) un fişier este memorat pe mai multe volume sau mai multe fişiere pe mai multe volume. Din acest punct de vedere există cazurile:
monofişier - monovolum (când este memorat un singur fişier pe un singur volum);
monofişier - multivolum (când este memorat un singur pe mai multe volume, în general diskete);
multifişier - monovolum (când sunt memorate mai multe fişiere pe un singur volum, cazul cel mai întâlnit la discurile fixe);
multifişier - multivolum (când mai multe fişiere sunt memorate pe mai multe volume, caz întâlnit cel mai adesea la dischete).
Orice fişier are şi el viaţa lui, marcată de următoarele faze: crearea fişierului; popularea fişierului; actualizarea fişierului; întreţinerea fişierului; ştergerea fişierului;
Pentru a avea acces la înregistrările logice ale unui fişier, trebuie ca mai întâi fişierul să fie deschis (open), apoi se populează sau actualizează înregistrările solicitate de utilizator, iar în final fişierul trebuie închis (close). Deschiderea fişierului se poate face în: citire (input), scriere (output), sau citire-scriere (input-output sau actualizare).
Crearea fişierului se face la prima deschidere în scriere (output), a fişierului ce se doreşte a fi creat. La deschiderea în scriere se consultă FAT (File Allocation File) adică tabela de alocare a fişierelor, pentru a se determina dacă fişierul al cărui nume a fost indicat de utilizator, există sau nu, în directorul curent. Dacă există se emite un mesaj de eroare, iar dacă nu se creează o înregistrare în FAT, care reţine numele fişier creat.