28
Cautare peste siruri problema cautarea naiva algoritmul Knuth-Morris-Pratt algoritmul Boyer-Moore algoritmul Rabin-Karp cazul mai multor pattern-uri expresii regulate
| Date post: | 25-Oct-2015 |
| Category: |
Documents |
| Upload: | cornelius-paul-asoltanei |
| View: | 167 times |
| Download: | 4 times |

Cautare peste siruri
problema
cautarea naiva
algoritmul Knuth-Morris-Pratt
algoritmul Boyer-Moore
algoritmul Rabin-Karp
cazul mai multor pattern-uri
expresii regulate

Tipul de date abstract String
obiecte: siruri de elemente apartinind unui tip abstract Character
operatii
• inserarea unui subsir
• eliminarea unui subsir
• concatenarea a doua siruri
• regasirea unui sir ca subsir al altui sir
– sirul in care se cauta se numeste subiect; il notam
s[0..n-1]
– sirul a carui aparitie este cautata in subiect se numeste
“pattern”; il notam p[0..m-1]

Cautare naiva: proprietati
nu necesita preprocesare;
spatiu suplimentar: O(1);
totdeauna deplaseaza “pattern”-ul cu o unitate la dreapta;
comparatiile pot fi facute in orice ordine;
complexitatea cautarii: O(mn)
numarul mediu de comparatii intre caractere: 2n .
s
p
≠

Cautarea naiva: algoritm
function pmNaiv(s, n, p, m)
begin
i -1
while (i < n-m) do
i i+1
j 0
while (s[i+j] = p[j]) do
if (j = m-1)
then return i
else j j+1
return -1
end

Algoritmul KMP: proprietati
realizeaza comparatiile de la stanga la dreapta;
preprocesare in timpul O(m) cu spatiu suplimentar O(m);
complexitatea timp a cautarii: O(n+m) (independent de
marimea alfabetului);
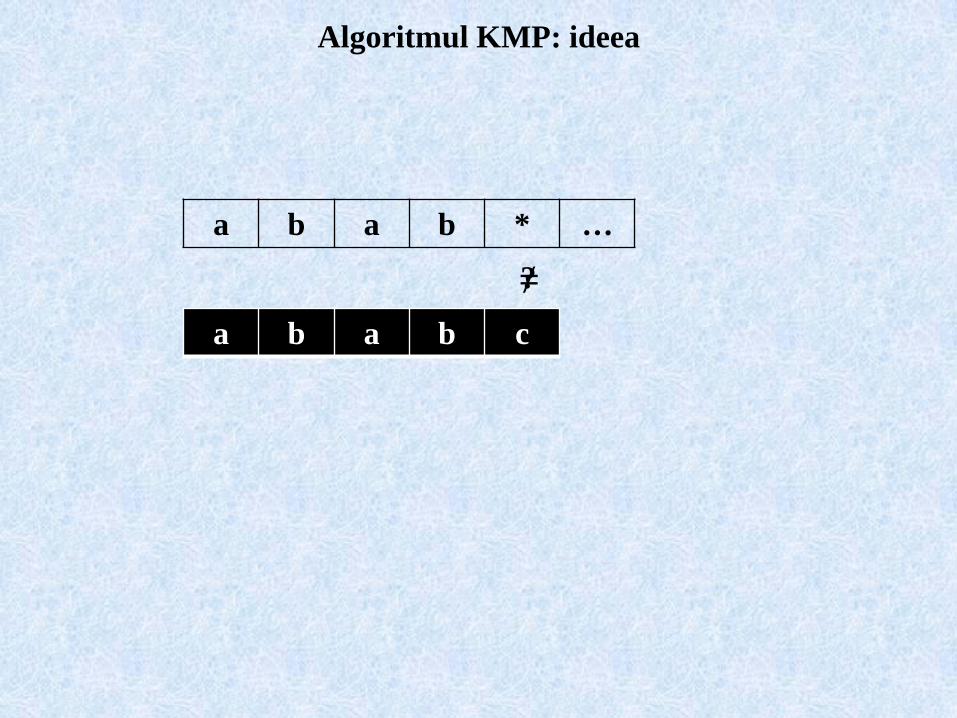
Algoritmul KMP: ideea
a b a b * …
a b a b c
≠?
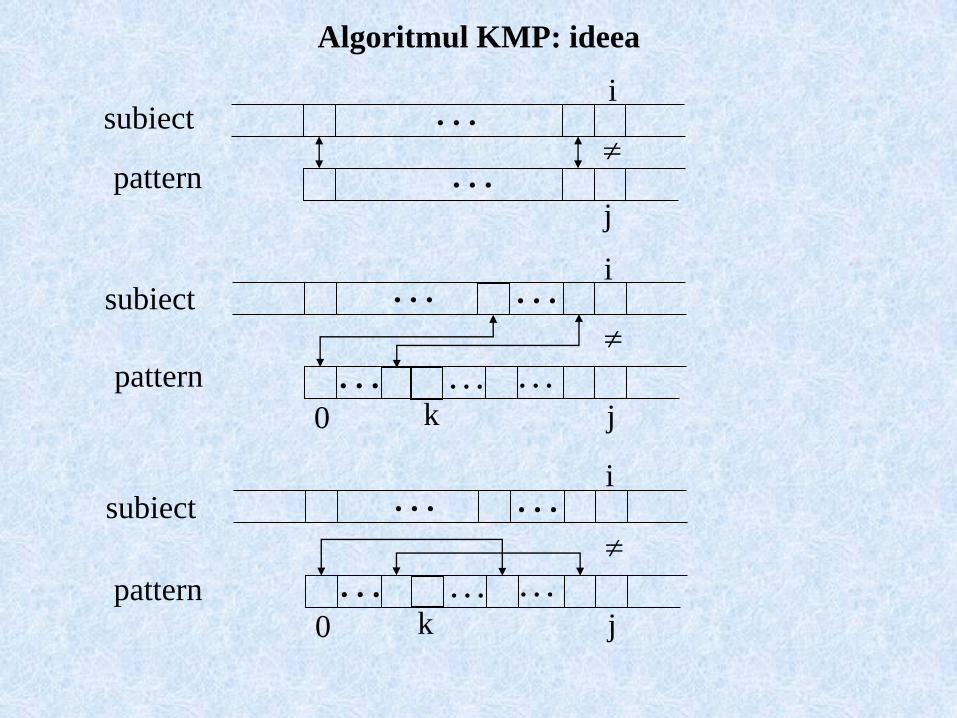
Algoritmul KMP: ideea
subiect
pattern
i
j
. . .
. . .
subiect
pattern
i
jk0
. . . . . .
. . . . . . . . .
subiect
pattern
jk0
. . . . . .
. . . . . . . . .
i

Terminologie
prefix
p[0..k-1]
sufix
p[j-1..j-k]
“bordura” (border)
prefixul de lungime k = sufixul de lungime k
functia esec
f[j] = k ddaca ce mai lata bordura a lui p[0..j-1] are latimea k

Algoritmul KMP: functia esec
procedure determinaFctEsec(p,m,f)
begin
f[0] -1
for j 1 to m-1 do
k f[j-1]
while (k -1 and p[j-1] p[k]) do
k f[k]
f[j] k+1
end
Analiza: timpul in cazul cel mai nefavorabil O(m)
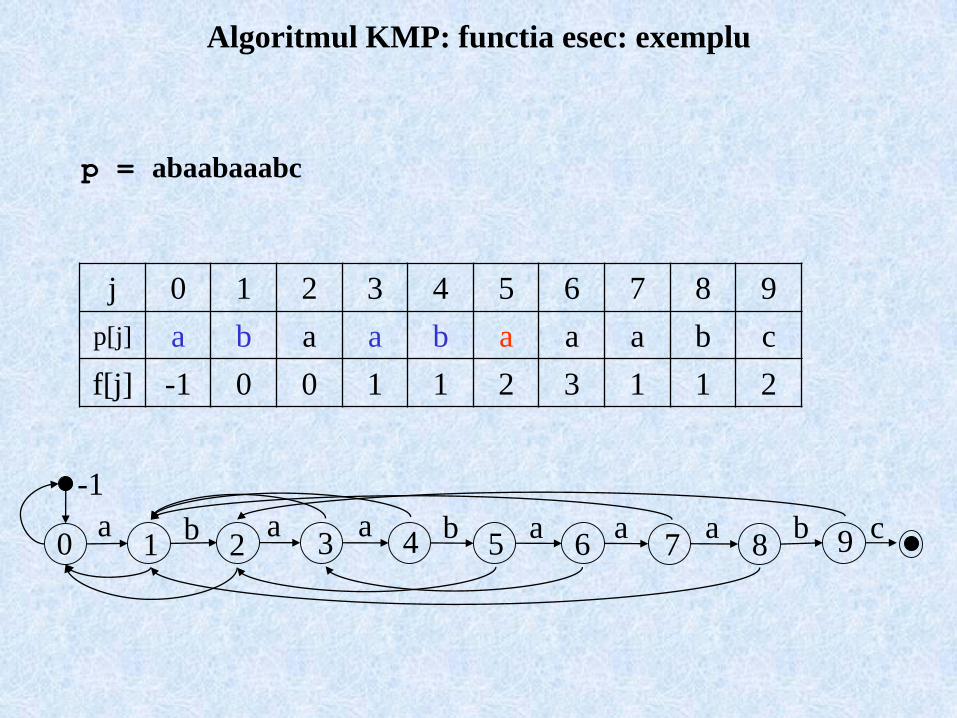
Algoritmul KMP: functia esec: exemplu
p = abaabaaabc
50 1 2 3 4 6 7 8a b a a b a a a b c9
-1
j 0 1 2 3 4 5 6 7 8 9
p[j] a b a a b a a a b c
f[j] -1 0 0 1 1 2 3 1 1 2

Algoritmul KMP
function KMP(s, n, p, m, f)
begin
i 0
j 0
while (i < n) do
while (j -1 and s[i] p[j])do
j f[j]
if (j = m-1)
then return i-m+1
else i i+1
j j+1
return -1
end
Analiza: timpul in cazul cel mai nefavorabil O(2n) – numarul total de
executii ale buclei interioare while este <= numarul de incrementari ale
lui j (incrementarea lui j are loc inafara buclei)

Algoritmul Boyer-Moore: proprietati
comparatiile sunt realizate de la dreapta la stanga;
preprocesare in timpul O(km) si spatiu suplimentar O(k),
unde k = #Character;
complexitatea timp a cautarii: O(mn);
3n comparatii de caractere in cazul cel mai nefavorabil pentru
un “pattern” neperiodic;
cea mai buna performanta: O(n / m) .
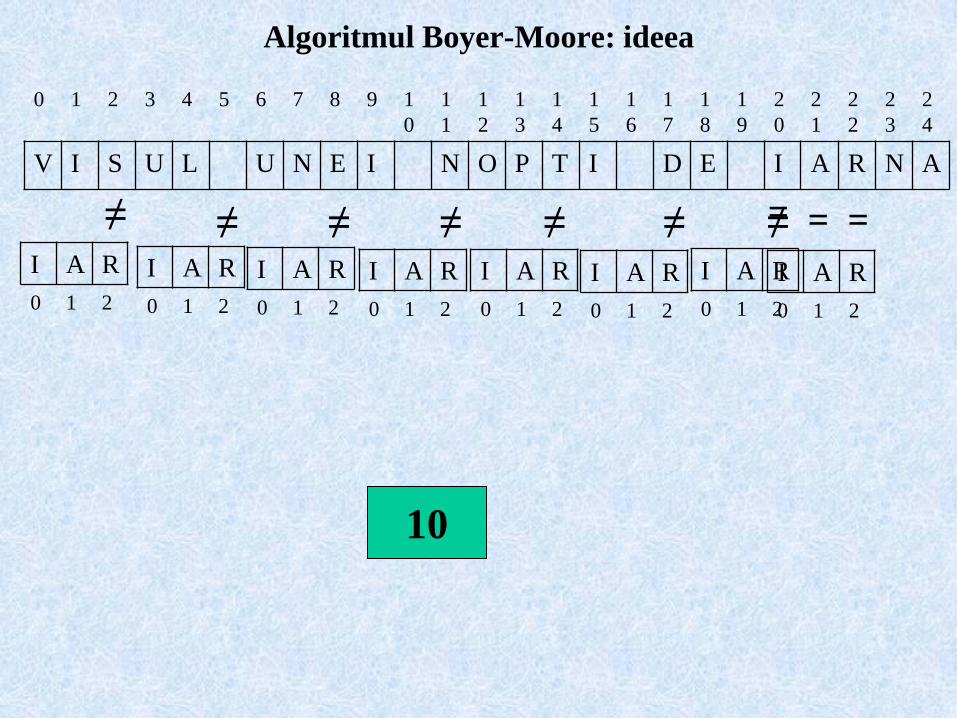
Algoritmul Boyer-Moore: ideea
0 1 2 3 4 5 6 7 8 9 1
0
1
1
1
2
1
3
1
4
1
5
1
6
1
7
1
8
1
9
2
0
2
1
2
2
2
3
2
4
V I S U L U N E I N O P T I D E I A R N A
I A R
0 1 2
I A R
0 1 2
I A R
0 1 2
I A R
0 1 2
I A R
0 1 2
I A R
0 1 2
I A R
0 1 2
I A R
0 1 2
≠ ≠ ≠ ≠ ≠ ≠ ≠ ===
012345678910

Algoritmul Boyer-Moore: functia salt
cazul cind caracterul apare o singura data in pattern
AMAR
MAR
salt[A] = 1
cazul cind caracterul apare de mai multe ori in pattern
SAMAR
AMAR
salt[A] = 1
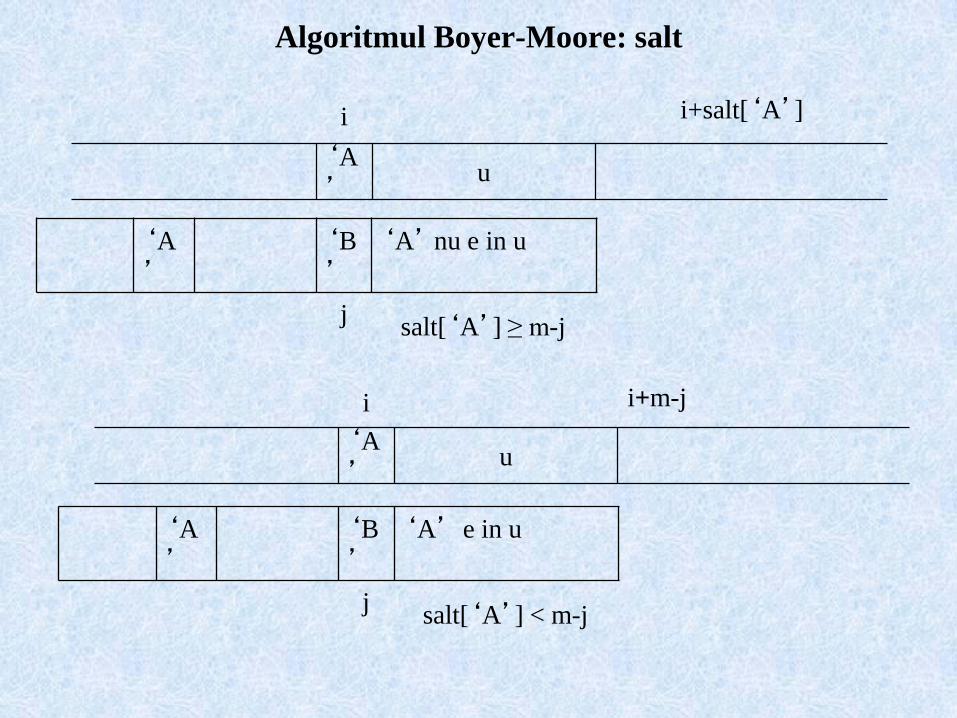
Algoritmul Boyer-Moore: salt
i+salt[‘A’]i
u‘A
’
‘A
’‘B
’‘A’ nu e in u
jsalt[‘A’] ≥ m-j
i+m-ji
u‘A
’
‘A
’‘B
’‘A’ e in u
jsalt[‘A’] < m-j

Algoritmul Boyer-Moore
function BM(s, n, p, m, salt)begin
i m-1; j m-1repeat
if (s[i] = p[j])then i i-1
j j-1else
if (m-j) > salt[s[i]]then i i+m-jelse i i+salt[s[i]]j m-1
until (j<0 or i>n-1)if (j<0)then return i+1else return -1
end

Algoritmul Rabin-Karp: proprietati
utilizeaza o functie “hash”;
preprocesare in timpul O(m) si spatiu suplimentar O(1);
cautare in timpul O(mn);
timpul mediu: O(n+m) .
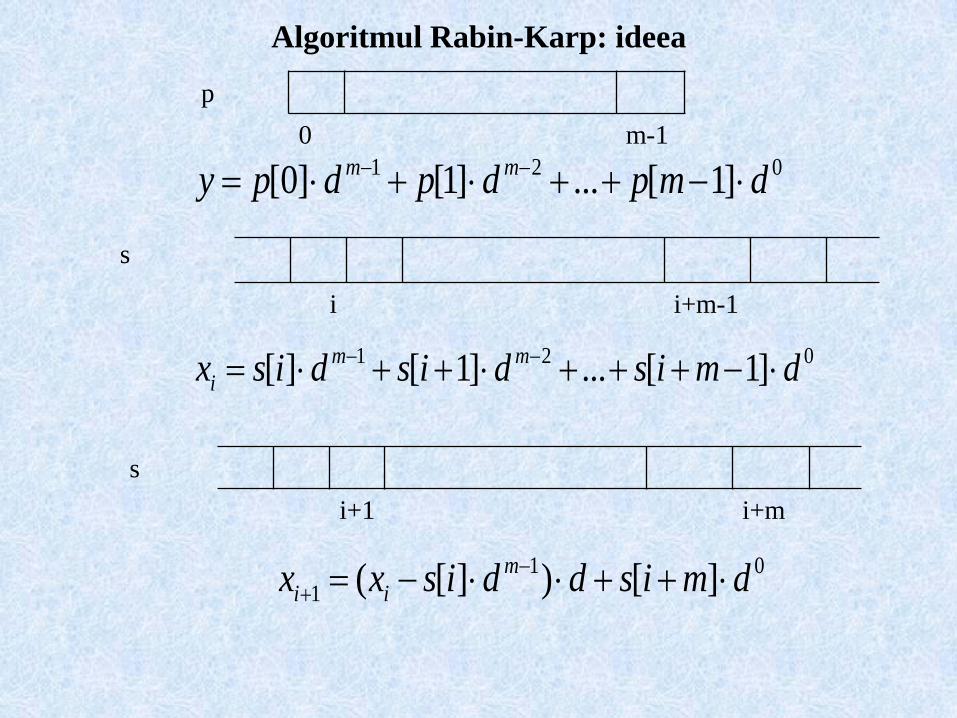
Algoritmul Rabin-Karp: ideea
021 ]1[...]1[]0[ dmpdpdpy mm
021 ]1[...]1[][ dmisdisdisx mm
i
01
1 ][)][( dmisddisxx m
ii
0 m-1
p
i i+m-1
s
i+1 i+m
s

Algoritmul Rabin-Karp
function RK(s, n, p, m)
begin
dlam1 1
for i 1 to m-1 do dlam1 (d*dlam1)%q
hp 0
for i 0 to m-1 do hp (d*hp+index(p[i]))%q
hs 0
for i 0 to m-1 do hs (d*hs+index(s[i]))%q
i 0
while (i < n-m) do
if (hp = hs and equal(p, s, m, i))
then return i
hs (hs+d*q-index(s[i])*dlam1)%q
hs (d*hs+index(s[i+m]))%q
i i+1
return -1
end

Algoritmul Rabin-Karp: implementare C
#define REHASH(a, b, h) ((((h)-(a)*d) << 1) (b))int RK(char *p, int m, char *s, int n) {
long d, hs, hp, i, j; /* Preprocesare */ for (d = i = 1; i < m; ++i)
d = (d << 1); for (hp = hs = i = 0; i < m; ++i) {
hp = ((hp << 1) + p[i]);hs = ((hs << 1) + s[i]);
}/* Cautare */i = 0; while (i <= n-m) {
if (hp == hs && memcmp(p, s + i, m) == 0)return i;
hs = REHASH(s[i], s[i + m], hs);++i;
} return -1;
}
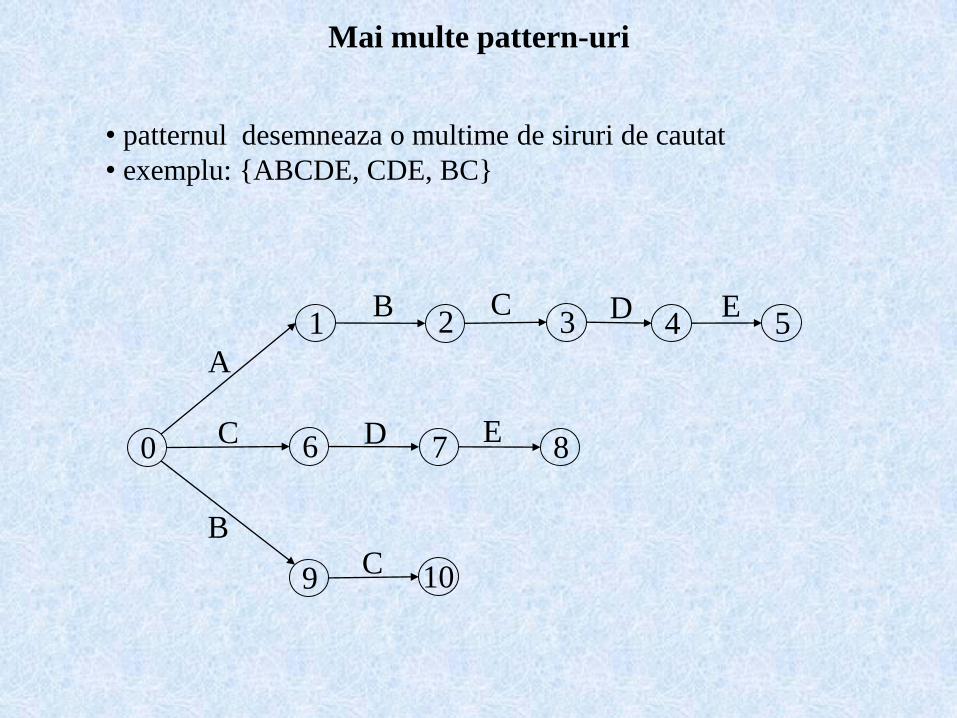
Mai multe pattern-uri
0
1 2 3 4 5
6 7 8
9 10
A
B C D E
C D E
BC
• patternul desemneaza o multime de siruri de cautat
• exemplu: {ABCDE, CDE, BC}
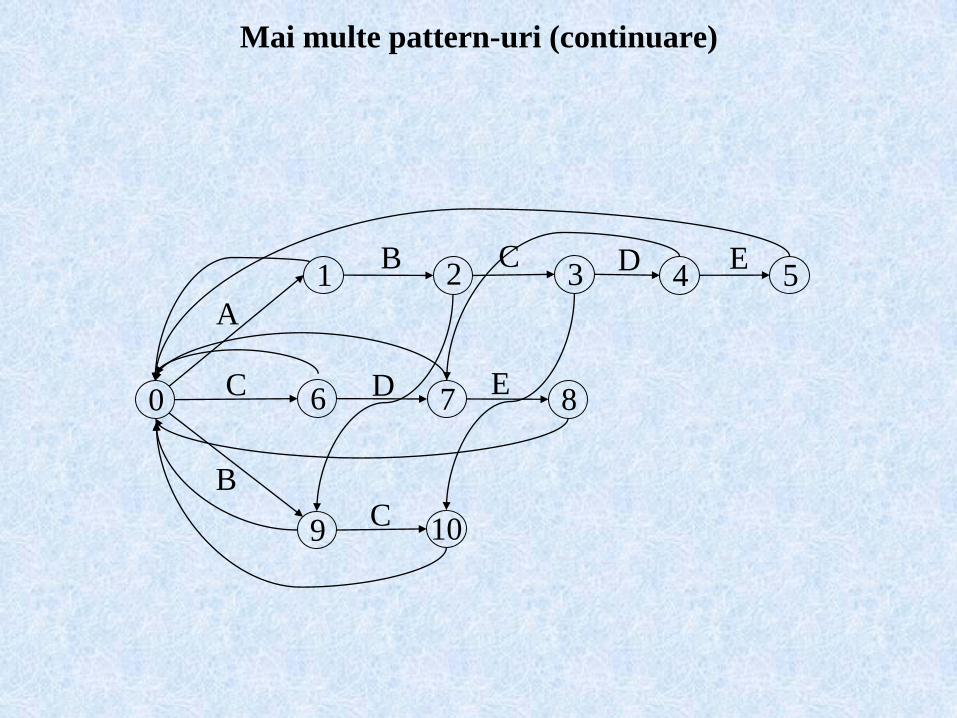
Mai multe pattern-uri (continuare)
0
1 2 3 4 5
6 7 8
9 10
A
B C D E
C D E
BC

Expresii regulate
patternul desemneaza o multime infinita de siruri de cautat =
limbajul generat de o expresie regulata
definitia expresiilor regulate peste A
<expr_reg> ::= a | ε | empty
| (expr_regexpr_reg)
| (expr_reg + expr_reg)
| expr_reg*
limbajul definit de expresiile regulate
L(a) = {a}
L(ε) = {ε}
L(empty) = Ø
L(e1e2) = L(e1)L(e2) = {uv | u L(e1), v L(e2)}
L(e1+e2) = L(e1) L(e2)
L(e*) = iL(ei) = iL(e)i
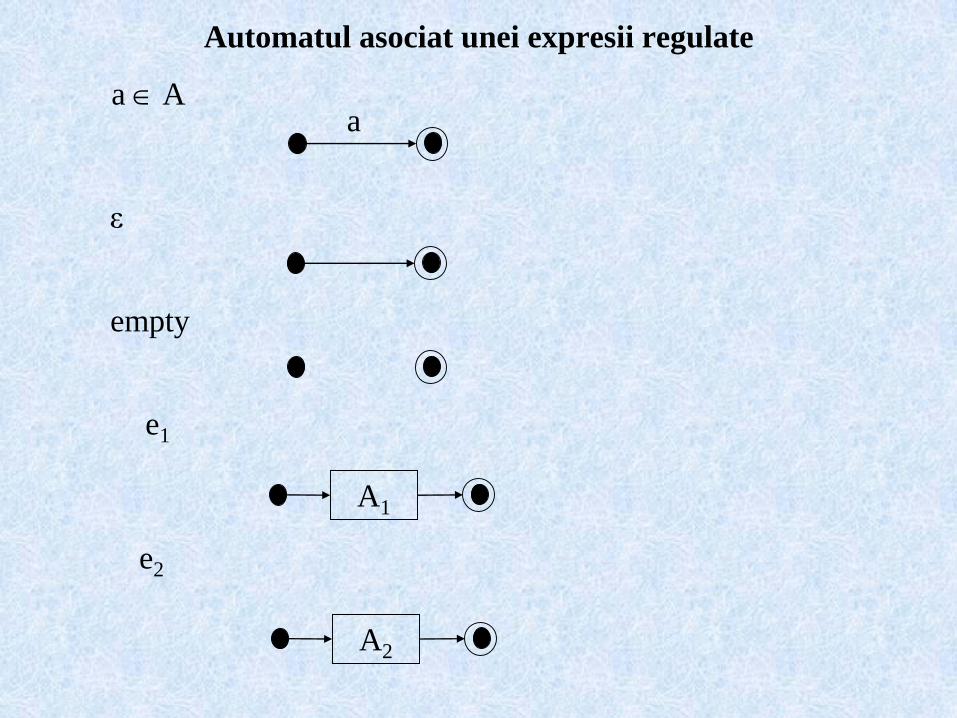
Automatul asociat unei expresii regulate
a
A1
A2
a A
e1
e2
ε
empty
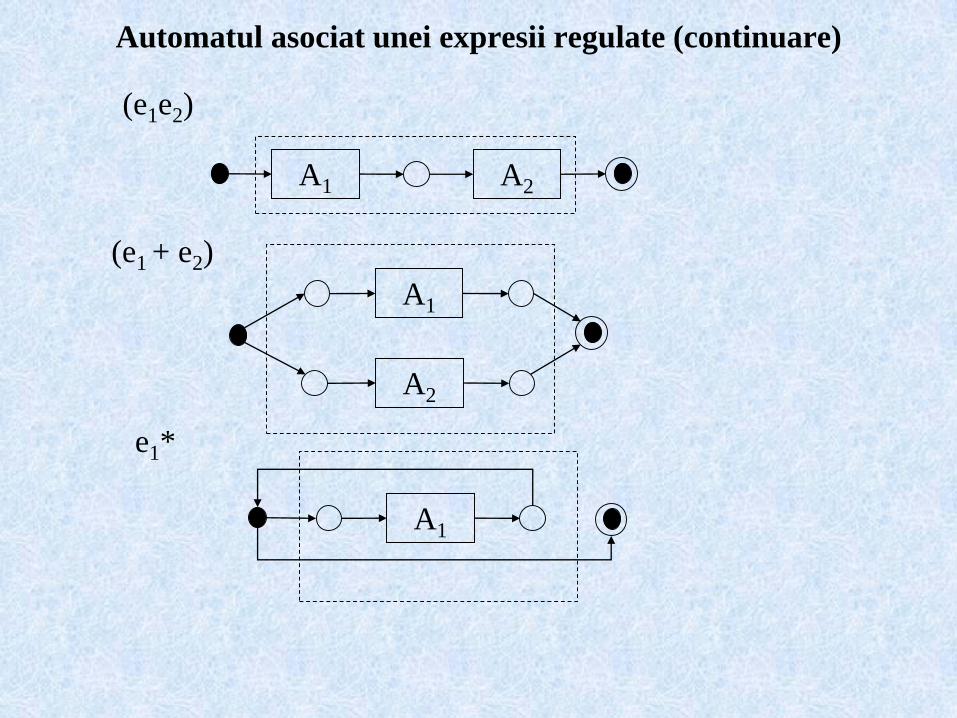
Automatul asociat unei expresii regulate (continuare)
A1
A2
A1
(e1e2)
(e1 + e2)
e1*
A1 A2
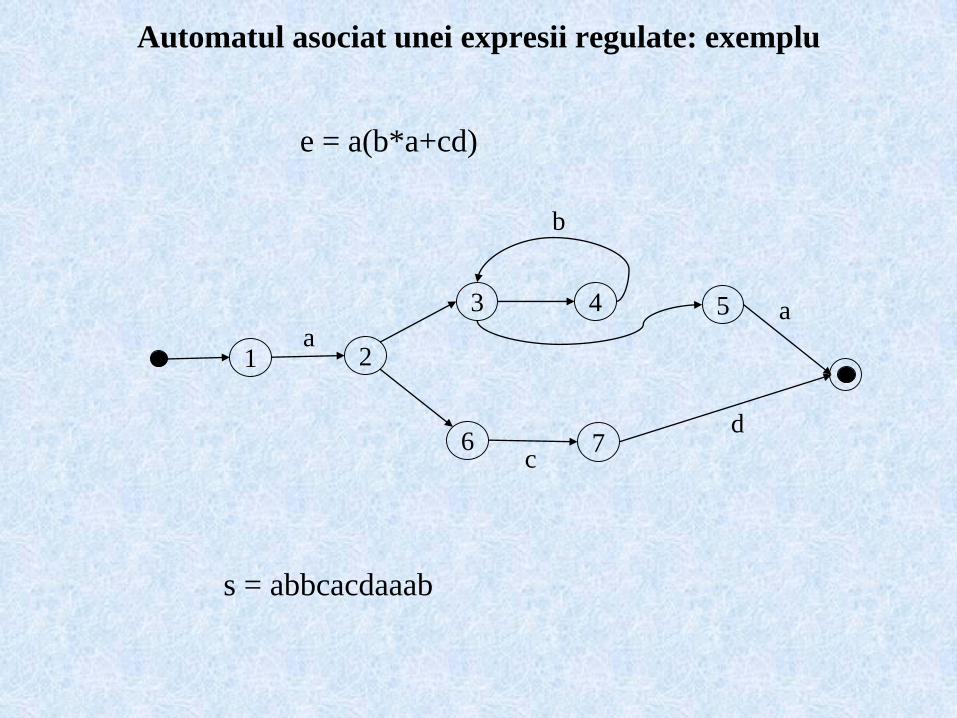
Automatul asociat unei expresii regulate: exemplu
e = a(b*a+cd)
s = abbcacdaaab
1 2
3 4 5
76
a
b
c
d
a

Algoritm de cautare – structuri de date
D = coada cu restrictii la iesire, unde inserarile se pot face si la
inceput si la sfarsit iar stegerile/citirile numai la inceput.
q = starea curenta a automatului,
j pozitia curenta in textul s, i pozitia in textul s de inceput a
"pattern"-ului curent
Simbolul # va juca rolul de delimitator (el poate fi inlocuit cu
starea invalida -1).
Initial avem D = (#), q = 1 (prima stare dupa starea initiala 0),
i = j = 1.

Algoritm de cautare: pasul curent
Daca
din q pleaca doua arce neetichetate , atunci insereaza la inceput in D
destinatiile celor doua arce;
din q pleaca un singur arc etichetat cu s[j] atunci insereaza la sfarsitul
lui D destinatia arcului;
q este delimitatorul # atunci:
daca D = Ø, atunci incrementeaza i, j devine noul i, insereaza # in
D si atribuie 1 lui q (aceasta corespunde situatiei cand au fost
epuizate toate posibilitatile de a gasi in text o aparitie a unui sir
specificat de "pattern" care incepe la pozitia i);
daca D ≠ Ø, atunci incrementeaza j si insereaza # la sfarsitul lui D;
q este starea finala atunci s-a gasit o aparitie a unui sir specificat de
"pattern" care incepe la pozitia i.
Extrage starea de la inceputul lui D si o memoreaza in q, dupa care reia
pasul curent.

















